Adapting sample size in particle filters through KLD-resampling
This letter provides an adaptive resampling method. It determines the number of particles to resample so that the Kullback-Leibler distance (KLD) between distribution of particles before resampling and after resampling does not exceed a pre-specified…
Authors: Tiancheng Li, Shudong Sun, Tariq Pervez Sattar
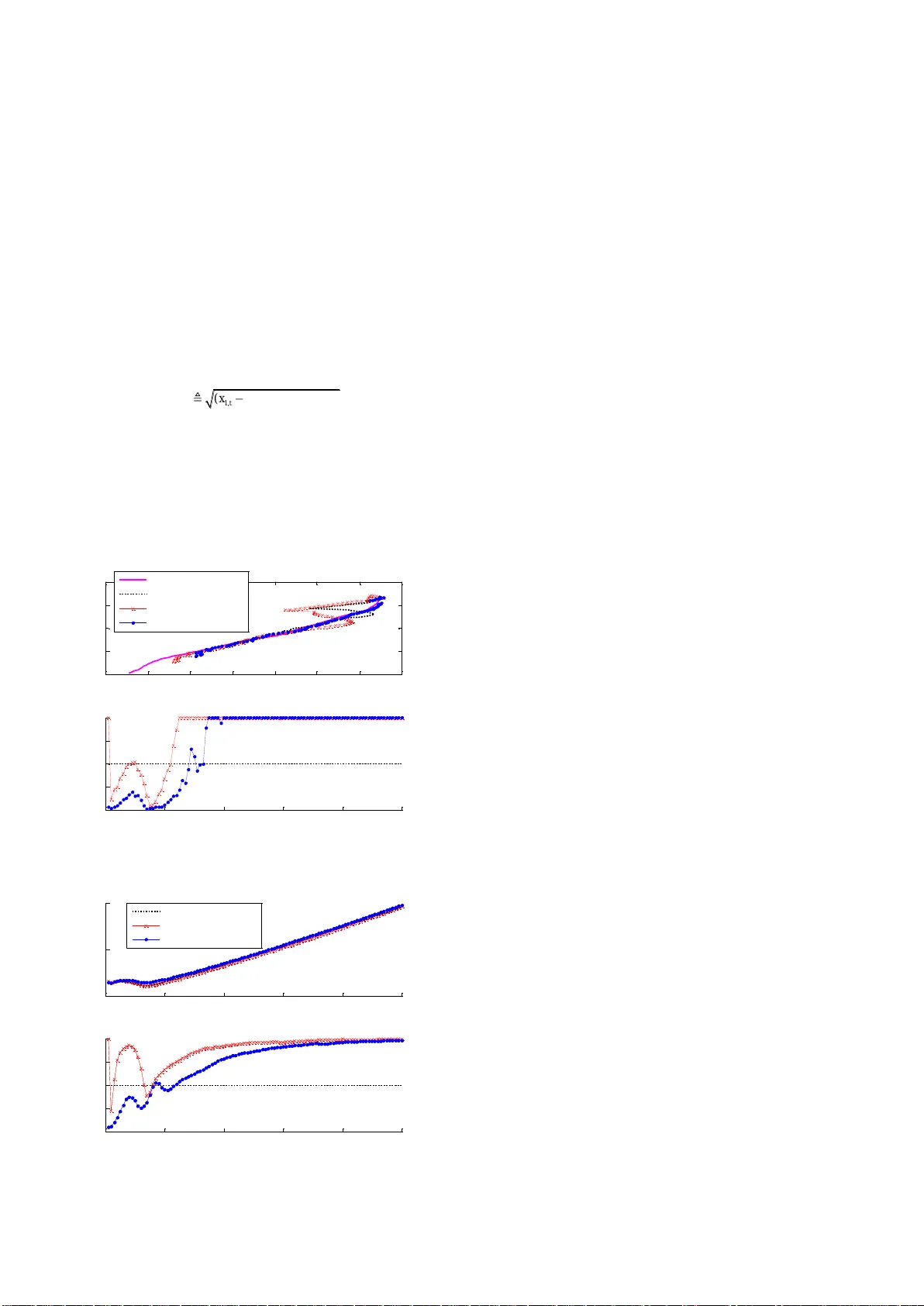
1 Ad a p ti n g s a m p l e s i ze i n p ar t i c l e f i l t er s t h r o u g h K L D-r e s a mp l i n g T . Li , S. Sun and T. Sattar This letter pro vides a n adaptive res ampling method. It determines the number of particles t o re sample so that the Kullback – Leibler distance (KLD ) between dis tribution o f part icles before re sampling and af ter resampling doe s not excee d a pre-specifi ed error bound. The b asis of the method is the same as Fox’s KLD-sampli ng but implemented differently . The KLD-sampl ing assumes that s amples are coming from the t rue posterior distribution and ignores a ny mismatch between the true and the propo sal distrib ution. In contrast, we incorporate the KL D measure in to the resampling in which the distri bution of interest is just the posterior distri bution . That is to say, for sample size adjustme nt, it is more theoretical ly rigorous and practical ly flexible to measure the fit of the distributio n represented by weighted particles based on KLD during resampling than in sampling. Simulations of target tracking demonstrate the efficiency of o ur method. Introduction: The parti cle filter (PF) ha s b een widely applied for nonlinear filtering due to its abilit y to carry multiple h ypothe ses relaxing the l inearity and Gau ssian a ssumptions. However, there are still c hallenge s for PFs, such as spe cification of the sample s ize. Most existing particle filters use a fixed num ber of sa mples. Ho wever, since the complexity of th e posterior distribution can vary drastically over time, the sample size s hould adjust online according to requirem ents of the system. One primary challenge in the application of particle filters is the design of an efficient me thod for sample size adjustmen t [1 , 2]. The KLD provides a means to measure the fit of the distribution represented by weighted particles. It is used to determine the minimum number of particles needed to mainta in the approximation quality in the sampling process, namely the KLD-sa mpling [3] . However, the samples are assum ed to be coming f rom the true posterior distribution, which is actually not true . As a n alternative , this letter applies the KLD measure in the resa mpling p rocess thereby t he distribution of interest is just the posterior distribution. Our approach provides a similar ability to adjust the sa mple size as the KLD-sa mpling and i s more theoretical ly rigor ous and practically flexible . KLD-sampling: The KLD (als o known as relative entropy ) between t he proposal ( q ) and true ( p ) distributio ns is defined in d iscrete form as () ( ) ( ) log ( ) ( ) l og ( ) () KL xx px d p q p x W x q x W x qx (1) where W ( x ) = p ( x )/ q ( x ). It is derived in [3 ] to determine the required number N of samples so that, wi th probability 1 − δ , the Kullback – Leibler distance b etween sample-based maximum lik elihood estimate (MLE) and the distribution of interest is less than a pre-specifie d error bound thre shold ε , i.e. 2 1 , 1 1 2 k N (2) where k is the number of bins with supp ort, the quantises of the chi- square distribution is defined as 22 1 1 , 1 ( ) 1 kk P (3) To sa ve computation ((3) need s to be re -calculated online whenev er a new pa rticle is sampled), 2 1 , 1 k can b e approximated by the Wilson- Hilferty transform ation, which yields 3 1 1 2 2 ( 1 ) 2 9( 1 ) 9( 1 ) k Nz kk , (4) where z 1- δ is the upper quart ile of the s tandard normal distribution. For typical value s of δ , the values of z 1- δ are available in standard tables. This result giv es the sa mple size needed to approxim ate a discrete distribution with an upper bound ε on the KL-distance. It i s incorporate d into the sa mpling process namely the KLD s ampling [3], in which the predictive belief state is used as the estimate of the underlying posterior. This, howeve r, is actually n ot the case of particle f ilters where the samples c ome from the proposal distr ibution . As a result of this, t he output of the KLD-sampling approach is based on statistical bound s of the appr oximation quality of s amples that are actually drawn from t he proposal distribution rather t han the t rue posterior d istribution. The mismatch between the true and the proposal distribution is ignored, s ee also [ 4, 5 ]. To avoid the mism atch , we apply t he result of (4) in the resampling pr ocess to de termine th e to tal numbe r of par ticles to resample . That is, we divide the particles (of the posterior distributio n ) into bins and count the number k of bins in which at least one particle is resampled to determine the total number of particles to resample . Compared with the KLD-sampling, our approach (referred to as KLD- resampling) applies the result giv en in ( 4) to adjust the sample size in the resampling process rather th an in the sampling process. Our a pproach : Th ere are two part s to th e K LD-resampling app roach which is d escribed as in algorithm 1 . One is to resample particles according to their weights one b y one (individu ally and independently) until the required sam ple si ze (4) is satisfied. In the other part , the number k of bins wit h support (in which at least one p article is resampled) and (4 ) are updated ev ery time a new particle is (re)sampled. Except the resampling step, the other pa rts of the PF, i.e. the sequential importance sampling fr amework, do not need to change. Similar to the KLD-sampling, the particles are sa mpled one by one individually un til the required amo unt is achieved that is determin ed based on the KLD measure of the fit of the un derlying distrib ution of particles . The ad vantage of our a pproach over t he KLD-sampling is that the underlying distri bution of our approach is just the posterior distribution while in t he latter it is the predictive belief . The disadvantage of the KLD measure is t hat the particles need to be divided into bins i n their s tate space, wh ich ca n be h igh ly in efficient when t he state is o f high d imension. Fo r simplicity, w e propose to divide the primary dimensions onl y, a s pr oposed in [ 6]. In this case, t he bin will be of low dim ensionalities, see e.g. the simu lation below. Simulation : The e fficiency of the KLD measure for s ample siz e adjustment f or the particle filter has b een demon strated in the application of, but not limited to, mobile robot localization see [ 3, 4, 5]. For the sake of evaluating the s ample size adjusting ability of our approach, we study the benchmark model of maneuvering target tracking. The tar get moves in the 2-dimension al plane according to a second orde r state space model 2 1, 1 2 2, 1 T 0 0 T / 2 0 0 1 0 0 T0 0 0 1 T 0 T / 2 0 0 0 1 0T t tt t v xx v (5) where x t =[ x 1, t , x 2, t , x 3, t , x 4, t ] T , [ x 1, t , x 3, t ] T is the x - y position while [ x 2, t , x 4, t ] T is the v elocity at t ime t and the sampling period T =1. The pr ocess noise { v 1, t }, { v 2, t } are mutually independent zero-mean Gaussian white noise with resp ective standard deviation σ v 1 =0.001 and σ v 2 =0.001. The bearing-only me asurement for an observe r at the origin is given by 1 , 3, ar cta n / t t t t x x w (6) Algorithm 1: KLD-resampling Inputs: bound ε and δ , bin size, m aximum num ber of samples N max Initialization : k =0; i =0; N = 1; all bins are zero-resam pled; while ( i ≤ N and i ≤ N max ) do Randomly sele ct one particle from the underlying particle set according to the we ight (e.g. Multinomial resam pling) : i := i +1 if (the new resam pled particle comes from n on - resampled bin b ) do Update the num ber of resampled bin: k := k +1 b : = resam pled Update the required nu mber N of particle by ( 4) end end 2 where w t is zero-mean Gaussia n white noise with the standard deviation σ w 1 =0.005. The initial state of the tar get is x 0 = [−0.05, 0 .001, 0 .7, −0.055] T , and prior to the m easurements the state mean and sta ndard deviations are assumed to be x 0 = [0 .0, 0.0, 0.4 , −0.05] T , σ 1 =0.5, σ 2 =0.005, σ 3 =0.3, σ 4 =0.01. To note, the para mete rs of bound ε and δ , and esp ecially the bin size are ad -hoc, and in practi ce it is necessary to carefully choose them to obtain the desired results. As suggested in [3], we use boun d parameters e =0.15, δ = 0.01. More i mportantly, to save c omputation we divide the b ins only in the 2-D position space and the bin size is c hosen by considering of the s ystem noise variance. We c hoose the bi n siz e as the smaller of the standard deviations of the d ynamics and the measurement, i.e. [0.001, 0.001]. Th e starting sample size is 1000 for all filters and the maximum sample size f or KLD a daptive mechanism is 2000. The tracking scene and the sample siz e variation in one trial are given in Figure 1. T he mean tra cking positi on error and sample size of each filter of t otal 1000 trials are given in Figure 2 . The track ing position error is the Euler distance between the estimate and th e true position of the target which is defin ed as 22 1 , 1 , 3, 3, ˆˆ ( ) ( ) t t t t er ro r x x x x (7) where 1 , 3, ˆˆ [ , ] T tt xx is the x - y position estimate of the target at time t . The results show t hat the KL D-resampling PF obtains quite close estimation accuracy to th e KLD-sampling P F an d the basic particle filter. The KLD-resampling method can adjust the sample size efficiently as the KLD-sampling approach , as shown that when the estimation quality is reduced, more part icles are generated. We conjecture t hat similar results will b e obtained by the KLD-resampling in the context of mo bile robot localization. Fig. 1 The target tracking sc ene and sample size variatio n in one trial Fig. 2 The mean tracking error an d sample size of 1000 trials Conclusion: An adaptive resampling method called KLD-resampling is proposed that dete rmines the number of par ticles to resample based on the Kullb ack – Leibler measure of the fit of the posterior dist ribution represented by weighted par ticles. Our approach is based on the same theoretical grou nd a s F ox’s KL D-sampling b ut is m ore theoretical ly rigor ous and practical ly flexible. The si mulation in the context of maneuvering target tracking has dem onstrated that our a pproach can efficiently adju st the sample size. Acknowledgments: This w ork was sup ported by th e National Natural Science Found ation of China (Grant No. 51075337). Tiancheng Li and Shudong Sun ( The S chool of Mechatronics, Northwestern Polytechnic al University, Xi’an, 7 10072, China. ) E-mail: lit3@lsbu.ac.uk Tariq P. Sattar ( London South B ank University, London, SE1 0AA , UK ) T. Li is also with Lond on South Bank University . References 1 Straka O. and Simandl M. : ‘ A survey of s ample size adaptation techniques for particle filters, ’ 15th IFAC Symposium on System Identification, 2009, 15 , pp. 1358-1363. 2 Cornebise J., Moulines É. and Olsson J. : ‘ Adaptive methods for sequential i mportance sampling with application to sta te space models, ’ Statistics and Com puting, 2008, 18 , (4), pp. 461-480. 3 Fo x D.: ‘ Adapting the sample size in parti cle filters th rough KLD- sampling, ’ Int. J. Robotics Re s. , 2003, 22 , ( 12 ), pp. 985-1003. 4 Kwo k C ., Fox D ., and Meila M.: ‘Adaptive real -time particle filters for robot localiz ation,’ IEEE International Confe rence on Robotics a nd Automation, 2003, 2 , pp. 2836-2841. 5 Soto A.: ‘ Self adaptive Particle Filt er, ’ Proceedings of International Joint Conferen ces on Artificial Intelligence, 2005, pp.1398-1406. 6 Li T., Satt ar T. P., a nd Sun S.: ‘Determin istic resam pling: unbiased sampling to avoid sample i mpoverishment in particle f ilters,’ Signal Processing, 2012, 92 , (7), pp. 1637-1645. -0. 7 -0.6 -0. 5 -0.4 -0.3 -0. 2 -0. 1 0 -6 -4 -2 0 2 X (position ) Y (position) T ru e t raj e ctor y SI R-PF KLD -sampl in g PF KLD -resam plin g PF 0 20 40 60 80 100 0 500 1000 1500 2000 T ime Number of part icl es used 0 20 40 60 80 100 0 0.5 1 T ime Mean posi tion er ror 0 20 40 60 80 100 0 500 1000 1500 2000 T ime Mean number of pa rt icl es SI R-PF KLD -sampl in g PF KLD -resam plin g PF
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment