DeepProf: Performance Analysis for Deep Learning Applications via Mining GPU Execution Patterns
Deep learning applications are computation-intensive and often employ GPU as the underlying computing devices. Deep learning frameworks provide powerful programming interfaces, but the gap between source codes and practical GPU operations make it difficult to analyze the performance of deep learning applications. In this paper, through examing the features of GPU traces and deep learning applications, we use the suffix tree structure to extract the repeated patten in GPU traces. Performance analysis graphs can be generated from the preprocessed GPU traces. We further present \texttt{DeepProf}, a novel tool to automatically process GPU traces and generate performance analysis reports for deep learning applications. Empirical study verifies the effectiveness of \texttt{DeepProf} in performance analysis and diagnosis. We also find out some interesting properties of Tensorflow, which can be used to guide the deep learning system setup.
💡 Research Summary
The paper addresses the growing difficulty of performance analysis for deep learning applications that rely heavily on GPUs, especially when using high‑level frameworks such as TensorFlow. Although TensorFlow’s APIs hide the complexity of CUDA kernel launches, memory copies, and stream management, this abstraction creates a large “execution gap” between the concise source code and the massive, asynchronous GPU operations that actually run. Existing profiling tools—CPU‑centric profilers, NVIDIA’s NVProf, or TensorFlow’s timeline—either cannot capture GPU‑specific behavior or produce raw traces that are too large and unintelligible for most deep‑learning developers.
To bridge this gap, the authors propose DeepProf, a novel tool that automatically processes raw GPU traces, extracts repeated execution patterns, and generates intuitive performance analysis reports. The core idea is to treat the ordered sequence of GPU operations (kernel launches, memcpy, memset, etc.) as a string and build a suffix‑tree over it. Because a suffix tree stores all suffixes in O(n) space, it enables linear‑time detection of repeated substrings, which correspond to the per‑iteration execution of a deep‑learning training loop. The method first normalizes each trace entry by its name, start time, duration, stream ID, and other attributes, then sorts operations within each CUDA stream (operations in a stream are issued in order). By concatenating the sorted streams and feeding the result into the suffix‑tree, DeepProf can locate the boundaries of each iteration even when there is slight timing jitter, using an approximate matching algorithm.
Once iteration‑level patterns are identified, DeepProf computes a set of metrics for each pattern: total kernel execution time, memory‑transfer volume, per‑stream concurrency, and throughput. These metrics are visualized as timeline graphs, heat‑maps of stream utilization, and summary tables that highlight bottlenecks such as (1) “graph growth” – the inadvertent addition of new nodes to the TensorFlow data‑flow graph inside a training loop, which forces a full graph re‑initialization each iteration; (2) stream imbalance, where one stream dominates the GPU while others remain idle; and (3) excessive host‑to‑device or device‑to‑host copies that waste bandwidth.
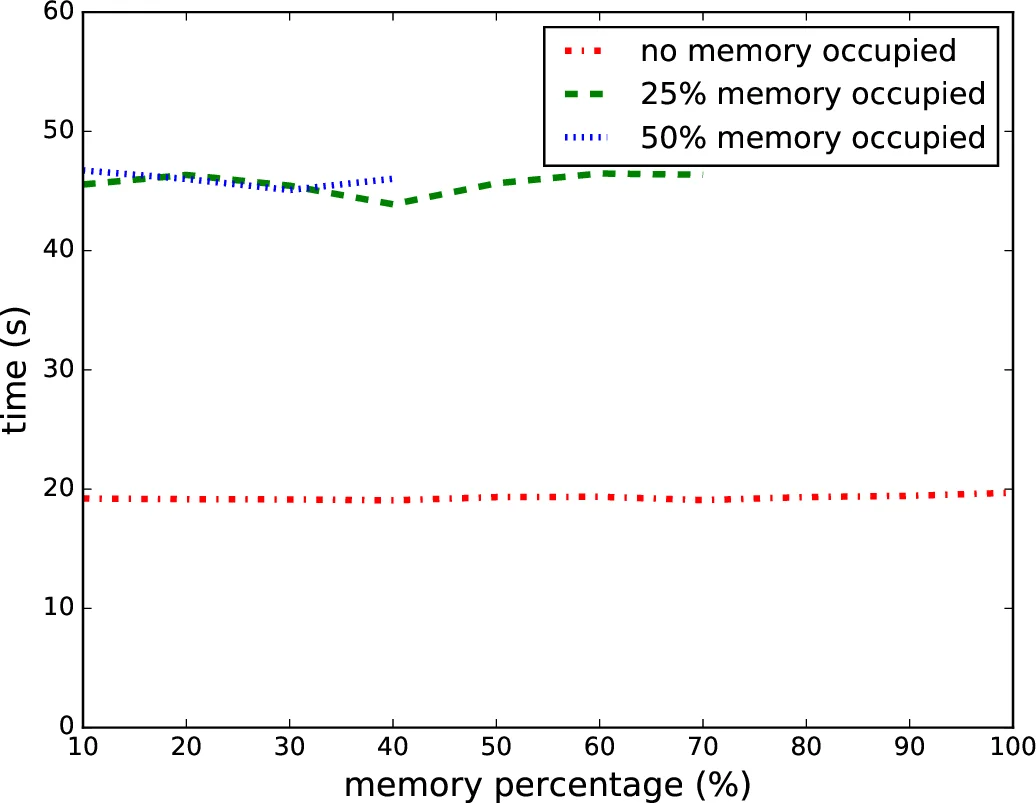
The authors evaluate DeepProf on several representative TensorFlow models (CNN on MNIST, LSTM‑based RNN, GAN, and a ResNet‑like architecture) across two GPU platforms (NVIDIA GTX 1080Ti and RTX 2080). The case studies reveal concrete performance issues: graph growth contributed up to 15 % overhead per iteration; re‑balancing streams reduced kernel waiting time by ~20 %; and reducing unnecessary memcpy operations increased overall throughput by up to 1.5×. Moreover, by comparing the same model on different GPUs, DeepProf quantifies how memory‑bandwidth limits dominate on older hardware, leading to practical recommendations such as adjusting batch size or consolidating small copies.
The paper’s contributions are fourfold: (1) an O(n)‑time, O(n)‑space algorithm for mining repeated GPU execution patterns using suffix trees; (2) a systematic method for mapping low‑level CUDA operations back to high‑level deep‑learning iterations; (3) an end‑to‑end tool (DeepProf) that produces developer‑friendly visual reports; and (4) empirical evidence of previously undocumented TensorFlow execution properties that can guide system configuration. The authors acknowledge that the current implementation focuses on single‑loop programs; handling multi‑loop or dynamically‑generated graphs (e.g., in PyTorch or TensorFlow eager execution) remains future work. Nonetheless, DeepProf demonstrates that automated pattern mining of GPU traces can substantially lower the barrier for deep‑learning engineers to diagnose and optimize their applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment