Cooperative Kernels: GPU Multitasking for Blocking Algorithms (Extended Version)
There is growing interest in accelerating irregular data-parallel algorithms on GPUs. These algorithms are typically blocking, so they require fair scheduling. But GPU programming models (e.g.\ OpenCL) do not mandate fair scheduling, and GPU schedulers are unfair in practice. Current approaches avoid this issue by exploiting scheduling quirks of today’s GPUs in a manner that does not allow the GPU to be shared with other workloads (such as graphics rendering tasks). We propose cooperative kernels, an extension to the traditional GPU programming model geared towards writing blocking algorithms. Workgroups of a cooperative kernel are fairly scheduled, and multitasking is supported via a small set of language extensions through which the kernel and scheduler cooperate. We describe a prototype implementation of a cooperative kernel framework implemented in OpenCL 2.0 and evaluate our approach by porting a set of blocking GPU applications to cooperative kernels and examining their performance under multitasking. Our prototype exploits no vendor-specific hardware, driver or compiler support, thus our results provide a lower-bound on the efficiency with which cooperative kernels can be implemented in practice.
💡 Research Summary
The paper addresses a fundamental limitation of current GPU programming models when executing blocking (synchronization‑heavy) irregular data‑parallel algorithms. Such algorithms—e.g., work‑stealing queues and frontier‑based graph traversals—require global barriers or mutexes that assume fair scheduling of work‑groups. However, OpenCL, CUDA, and HSA specifications provide no guarantees about work‑group fairness, and existing drivers rely on an implicit “occupancy‑bound” execution model: once a work‑group occupies a compute unit it retains exclusive access until completion. This model yields fairness only among already‑occupied units; any additional work‑groups must wait, which can cause deadlock at global barriers or indefinite spin‑waiting on mutexes when the scheduler is unfair.
Recognizing that vendors are unlikely to formally adopt occupancy‑bound execution (due to power‑management, pre‑emptive multitasking, and the high cost of full pre‑emption), the authors propose cooperative kernels, an extension to the GPU programming model that explicitly encodes fairness requirements. A kernel is marked as cooperative and may invoke two new primitives:
-
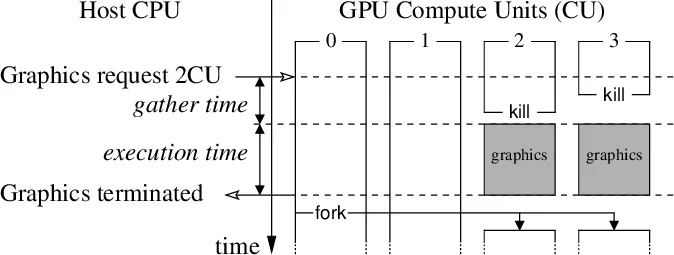
over_kill– a work‑group voluntarily yields its compute‑unit resources to the scheduler. The scheduler may pre‑empt the group without saving its state (the group simply stops executing). This enables the GPU to free resources for higher‑priority tasks such as graphics rendering, satisfying soft real‑time constraints. -
request_fork– a work‑group signals that the kernel would benefit from additional parallelism. The scheduler, if resources are available, launches new work‑groups that join the computation at the point of the call.
These primitives establish a contract: the scheduler must fairly schedule all active work‑groups of a cooperative kernel, while the kernel must call over_kill often enough to allow timely resource reclamation. Conversely, the scheduler should honor request_fork requests whenever possible, thereby preserving performance. Importantly, the model avoids the heavy cost of generic pre‑emption because over_kill does not require saving registers, shared memory, or cache state.
The authors implement a prototype entirely in software on top of OpenCL 2.0, requiring no vendor‑specific hardware, driver, or compiler extensions. The host maintains a pool of work‑group identifiers; over_kill returns an identifier to the pool, and request_fork draws from it. Existing kernels can be transformed by inserting the two calls at natural synchronization points (e.g., before a global barrier or after a mutex acquisition loop). The implementation is backward compatible: if a driver ignores the new primitives, the kernel behaves like a regular OpenCL kernel.
Evaluation uses two representative blocking algorithms:
- Work‑stealing queue – each work‑group processes tasks from its own queue and steals from others when empty, protected by atomic mutexes.
- Frontier‑based graph traversal – processes graph levels with global barriers between levels.
Both were ported to cooperative kernels and run on a modern GPU alongside a concurrent graphics workload. Results show:
- Performance parity with the traditional occupancy‑bound approach when the number of work‑groups does not exceed compute units.
- Low gather time (≈20‑30 µs) for releasing and reacquiring resources via
over_kill/request_fork, which is acceptable for maintaining smooth frame rates. - Robust multitasking: graphics frame rates degrade by less than 5 % even when the GPU is heavily used by the cooperative kernel.
- Comparison with hardware pre‑emption (Nvidia Pascal): the software‑only cooperative kernel achieves >80 % of the efficiency of a hand‑tuned pre‑emptive implementation, demonstrating that the approach is viable even without hardware support.
The paper highlights several key contributions: (1) a language‑level abstraction that guarantees fair scheduling for blocking algorithms, (2) a practical OpenCL‑based implementation that works on current hardware, and (3) an empirical study showing that cooperative kernels enable efficient GPU multitasking without sacrificing performance. The authors discuss alternative semantics, potential compiler assistance for inserting the primitives automatically, and future directions such as integrating with upcoming hardware pre‑emption features or extending the model to other accelerator architectures.
In summary, cooperative kernels provide a clean, portable solution to the long‑standing problem of executing blocking irregular algorithms on GPUs. By allowing kernels to explicitly cooperate with the scheduler, they reconcile the need for fairness with the desire for multitasking and power‑aware operation, paving the way for more reliable and flexible GPU‑accelerated applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment