Exploring the Imposition of Synaptic Precision Restrictions For Evolutionary Synthesis of Deep Neural Networks
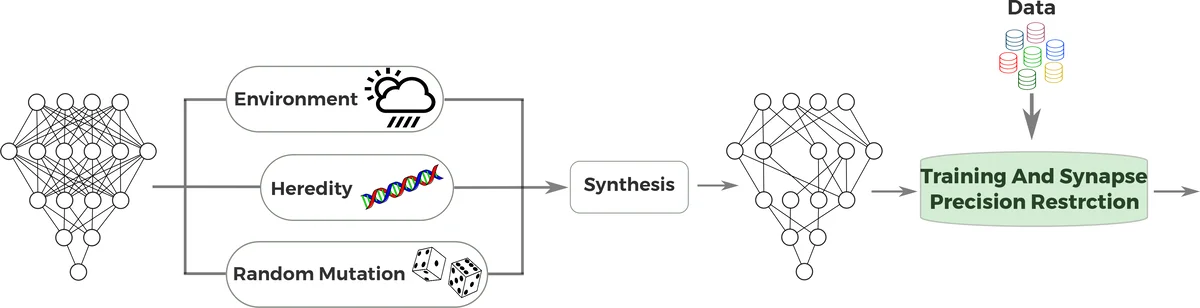
A key contributing factor to incredible success of deep neural networks has been the significant rise on massively parallel computing devices allowing researchers to greatly increase the size and depth of deep neural networks, leading to significant improvements in modeling accuracy. Although deeper, larger, or complex deep neural networks have shown considerable promise, the computational complexity of such networks is a major barrier to utilization in resource-starved scenarios. We explore the synaptogenesis of deep neural networks in the formation of efficient deep neural network architectures within an evolutionary deep intelligence framework, where a probabilistic generative modeling strategy is introduced to stochastically synthesize increasingly efficient yet effective offspring deep neural networks over generations, mimicking evolutionary processes such as heredity, random mutation, and natural selection in a probabilistic manner. In this study, we primarily explore the imposition of synaptic precision restrictions and its impact on the evolutionary synthesis of deep neural networks to synthesize more efficient network architectures tailored for resource-starved scenarios. Experimental results show significant improvements in synaptic efficiency (~10X decrease for GoogLeNet-based DetectNet) and inference speed (>5X increase for GoogLeNet-based DetectNet) while preserving modeling accuracy.
💡 Research Summary
The paper investigates how imposing synaptic precision restrictions can improve the efficiency of deep neural networks (DNNs) synthesized through an evolutionary deep‑intelligence framework. Traditional DNNs achieve high accuracy by scaling up size and depth, but this growth brings prohibitive computational, memory, and energy costs, especially in resource‑constrained settings such as embedded devices. Inspired by biological observations of stochastic synaptogenesis and energy‑driven loss of sensory systems, the authors extend a previously proposed probabilistic evolutionary synthesis method (Shafiee et al., 2016) with a new constraint: after each generation’s training at full 32‑bit precision, the offspring network’s weights are forced into 16‑bit half‑precision. This half‑precision representation becomes part of the “DNA” for the next generation, encouraging the synthesis process to produce networks that are both sparser and lower‑precision.
Mathematically, the genetic encoding is expressed as a conditional probability P(S_g | W_{g‑1}) where S_g denotes the architecture (including binary existence of each synapse) at generation g, and W_{g‑1} are the weights of the previous generation. An environmental factor F(α) encodes resource constraints (e.g., memory budget, energy limit). The synthesis probability is approximated by P(S_g) ≈ P(S_g | W_{g‑1})·F(α). By setting F(α) to favor sparsity and by quantizing the trained weights to half‑precision, the framework mimics natural selection under metabolic pressure.
The experimental evaluation targets object detection on the Parse‑27k dataset using a GoogLeNet‑based DetectNet model. All experiments run on an NVIDIA Jetson TX1, leveraging TensorRT’s accelerated half‑precision kernels. Over 13 evolutionary generations, the authors observe a ten‑fold reduction in the number of synapses (from roughly 1.2 M to 0.12 M) and a five‑fold increase in inference speed (from ~7 fps to ~37 fps). Crucially, detection performance remains stable: precision improves marginally by ~2 % while recall drops by a similar margin, indicating that the loss of numerical resolution does not materially degrade the model’s predictive capability.
The study’s contributions are threefold. First, it demonstrates that a probabilistic evolutionary synthesis pipeline can incorporate hardware‑aware constraints (precision, sparsity) without resorting to classic genetic operators such as crossover or mutation. Second, it provides empirical evidence that half‑precision quantization, when coupled with an evolutionary pressure toward sparsity, yields networks that are both memory‑light and computationally fast, making them suitable for edge devices. Third, it validates the biological analogy that metabolic pressures (here, computational budget) can drive the emergence of efficient neural architectures.
Limitations include the exclusive focus on 16‑bit quantization; lower bit‑width regimes (8‑bit or binary) remain unexplored. The experiments are confined to a single computer‑vision task, so generalization to other domains (e.g., speech, NLP) is not yet demonstrated. Moreover, the environmental factor F(α) is manually set rather than learned, leaving room for more sophisticated, possibly reinforcement‑learning‑based, resource‑aware adaptation.
Future work suggested by the authors involves (a) dynamic precision scheduling where the bit‑width can vary across layers or generations, (b) evolving the connectivity topology itself (beyond weight sparsity) to discover novel lightweight architectures, and (c) integrating direct power‑measurement feedback into F(α) to close the loop between hardware consumption and evolutionary pressure. By pursuing these directions, the evolutionary synthesis framework could become a powerful, automated tool for generating DNNs that meet stringent real‑world constraints while preserving the high accuracy that has made deep learning so successful.
Comments & Academic Discussion
Loading comments...
Leave a Comment