Demystifying Neural Style Transfer
Neural Style Transfer has recently demonstrated very exciting results which catches eyes in both academia and industry. Despite the amazing results, the principle of neural style transfer, especially why the Gram matrices could represent style remains unclear. In this paper, we propose a novel interpretation of neural style transfer by treating it as a domain adaptation problem. Specifically, we theoretically show that matching the Gram matrices of feature maps is equivalent to minimize the Maximum Mean Discrepancy (MMD) with the second order polynomial kernel. Thus, we argue that the essence of neural style transfer is to match the feature distributions between the style images and the generated images. To further support our standpoint, we experiment with several other distribution alignment methods, and achieve appealing results. We believe this novel interpretation connects these two important research fields, and could enlighten future researches.
💡 Research Summary
The paper revisits the seminal neural style transfer (NST) method introduced by Gatys et al. (2016) and asks a fundamental question: why does the Gram matrix of convolutional feature maps capture artistic style so effectively? The authors answer this by casting NST as a domain‑adaptation problem. They prove mathematically that matching Gram matrices between a generated image and a style reference is exactly equivalent to minimizing the Maximum Mean Discrepancy (MMD) with a second‑order polynomial kernel. In other words, the “style loss” used in NST is a specific instance of a distribution‑alignment objective that measures the distance between the feature‑distribution of the generated image and that of the style image.
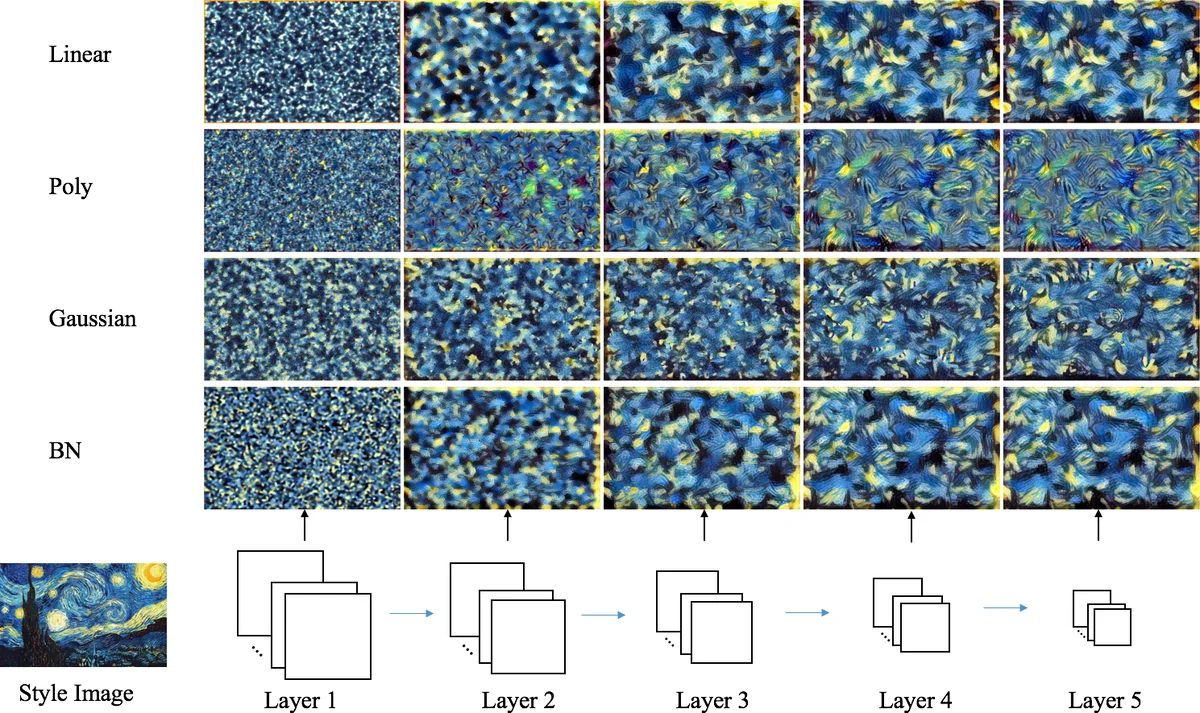
Building on this insight, the paper explores three alternative MMD‑based style losses and one batch‑normalization (BN) statistics‑matching loss. The alternatives are: (1) linear‑kernel MMD (k(x,y)=xᵀy), which aligns only first‑order statistics and is computationally cheap; (2) polynomial‑kernel MMD with a constant term (k(x,y)=(xᵀy+c)²), a generalization of the original Gram‑matrix loss; (3) Gaussian‑kernel (RBF) MMD, which maps features into an infinite‑dimensional space and can capture richer style characteristics. For the Gaussian case the authors adopt an unbiased estimator that scales linearly with the number of feature samples. The BN‑based loss aligns per‑channel means and standard deviations, effectively matching the first two moments of each feature channel without constructing Gram matrices.
Experiments are conducted on VGG‑19 using the same content layer (relu4_2) and style layers (relu1_1 through relu5_1) as the original NST. The authors first perform “style reconstruction” where only the style loss is active (α=0) and show that each of the four methods can recover the visual appearance of the reference style, albeit with different granularity across layers. They then vary the style‑to‑content weighting factor β (expressed as γ in the paper) to illustrate the classic trade‑off: higher γ yields stronger stylization but more content distortion. Results indicate that linear‑kernel MMD achieves comparable visual quality to the original Gram‑matrix loss while requiring far fewer computations, making it attractive for real‑time or mobile scenarios. The polynomial kernel reproduces the classic NST results, confirming the theoretical equivalence. The Gaussian kernel produces smoother color transitions and more nuanced textures, suggesting that richer kernels can encode subtler stylistic cues. The BN‑based loss converges quickly and is the simplest to implement, yet it sometimes falls short in reproducing fine‑grained textures compared with the higher‑order methods.
The paper’s contributions are threefold: (1) a rigorous derivation linking Gram‑matrix style loss to MMD with a second‑order polynomial kernel; (2) a unified view of NST as feature‑distribution alignment, opening the door to a variety of kernel‑based or moment‑matching strategies; (3) empirical validation that alternative distribution‑matching losses can produce aesthetically pleasing stylizations, sometimes with lower computational cost.
By reframing style transfer as domain adaptation, the work suggests several promising research directions: exploring multi‑layer joint MMD objectives, learning kernel parameters jointly with the stylization network, extending the framework to video, 3‑D data, or other modalities where distribution alignment is key, and designing lightweight, kernel‑flexible modules for real‑time applications. The paper thus bridges two previously separate research communities—neural style transfer and domain adaptation—and provides a solid theoretical foundation for future innovations in artistic image synthesis.
Comments & Academic Discussion
Loading comments...
Leave a Comment