Versatility of nodal affiliation to communities
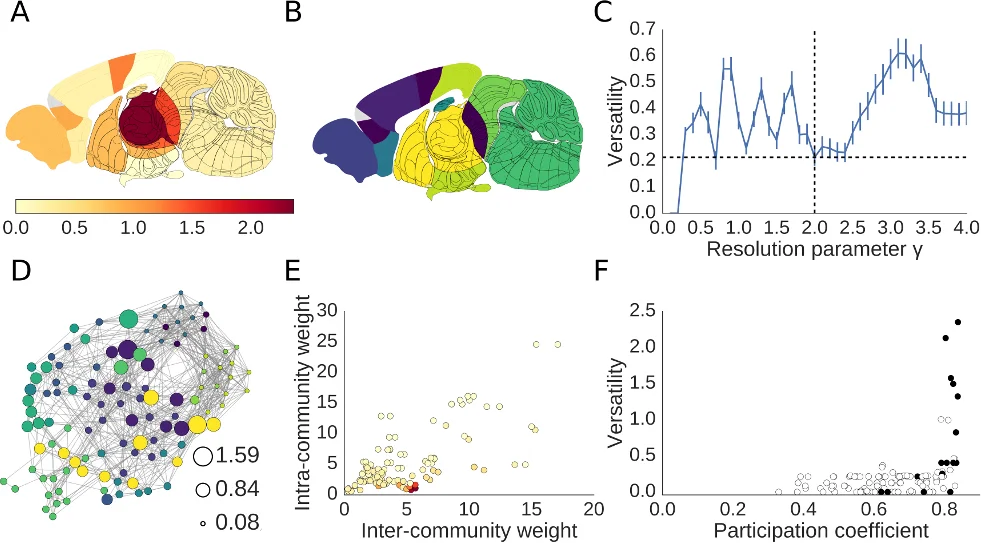
Graph theoretical analysis of the community structure of networks attempts to identify the communities (or modules) to which each node affiliates. However, this is in most cases an ill-posed problem, as the affiliation of a node to a single community is often ambiguous. Previous solutions have attempted to identify all of the communities to which each node affiliates. Instead of taking this approach, we introduce versatility, $V$, as a novel metric of nodal affiliation: $V \sim 0$ means that a node is consistently assigned to a specific community; $V \gg 0$ means it is inconsistently assigned to different communities. Versatility works in conjunction with existing community detection algorithms, and it satisfies many theoretically desirable properties in idealised networks designed to maximise ambiguity of modular decomposition. The local minima of global mean versatility identified the resolution parameters of a hierarchical community detection algorithm that least ambiguously decomposed the community structure of a social (karate club) network and the mouse brain connectome. Our results suggest that nodal versatility is useful in quantifying the inherent ambiguity of modular decomposition.
💡 Research Summary
The paper addresses a fundamental challenge in network community detection: the ambiguity of assigning nodes to a single community. While many algorithms produce a deterministic partition, real‑world networks often exhibit nodes that can belong plausibly to multiple groups, making the modular decomposition ill‑posed. Existing remedies—overlapping community methods, multilayer probabilistic models, or consensus clustering—either add considerable methodological complexity or fail to provide an intuitive measure of how certain a node’s community assignment truly is.
To fill this gap, the authors introduce versatility (V), a node‑level metric that quantifies the consistency of community affiliation across repeated runs of a stochastic community detection algorithm. The procedure is straightforward: run the chosen algorithm many times on the same graph, record for each pair of nodes (i, j) whether they share a community (a(i,j)=1) or not (a(i,j)=0), and estimate the co‑assignment probability pᵢⱼ = E
Comments & Academic Discussion
Loading comments...
Leave a Comment