End-to-End Neural Ad-hoc Ranking with Kernel Pooling
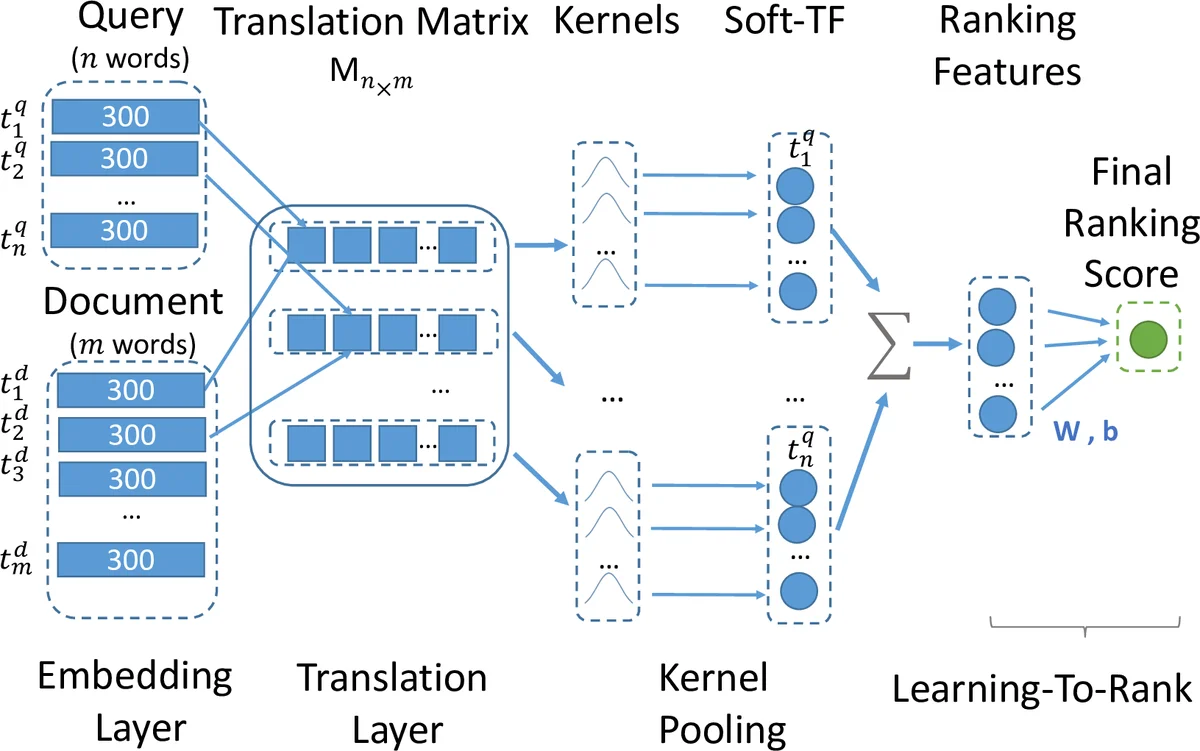
This paper proposes K-NRM, a kernel based neural model for document ranking. Given a query and a set of documents, K-NRM uses a translation matrix that models word-level similarities via word embeddings, a new kernel-pooling technique that uses kernels to extract multi-level soft match features, and a learning-to-rank layer that combines those features into the final ranking score. The whole model is trained end-to-end. The ranking layer learns desired feature patterns from the pairwise ranking loss. The kernels transfer the feature patterns into soft-match targets at each similarity level and enforce them on the translation matrix. The word embeddings are tuned accordingly so that they can produce the desired soft matches. Experiments on a commercial search engine’s query log demonstrate the improvements of K-NRM over prior feature-based and neural-based states-of-the-art, and explain the source of K-NRM’s advantage: Its kernel-guided embedding encodes a similarity metric tailored for matching query words to document words, and provides effective multi-level soft matches.
💡 Research Summary
The paper introduces K‑NRM (Kernel‑based Neural Ranking Model), a novel end‑to‑end neural architecture for ad‑hoc document ranking. K‑NRM starts by mapping each query and document token into a low‑dimensional embedding vector (dimension L). Using cosine similarity, it builds a translation matrix M where each entry Mᵢⱼ represents the similarity between the i‑th query word and the j‑th document word. This matrix captures fine‑grained word‑level interactions without having to learn a separate similarity for every word pair, dramatically reducing the number of parameters (|V|·L instead of |V|²).
The core contribution is a kernel‑pooling layer that transforms the translation matrix into a set of ranking features. A collection of K radial basis function (RBF) kernels, each defined by a mean μₖ and width σₖ, is applied to every row of M. For a given query word, each kernel computes a soft count of document words whose similarity falls near its μₖ; the log‑sum of these soft counts across all query words yields a K‑dimensional feature vector ϕ(M). By adjusting μ and σ, the model can focus on exact matches (μ≈1, σ→0), loose semantic matches (μ≈0.5), or any intermediate similarity level.
These features are fed into a simple learning‑to‑rank layer: f(q,d)=tanh(wᵀϕ(M)+b). The parameters w and b, together with the word embeddings, are learned jointly from click‑derived pairwise relevance judgments using a hinge loss: max(0,1−f(q,d⁺)+f(q,d⁻)). Back‑propagation flows from the loss through the ranking layer, the kernel‑pooling, the translation matrix, and finally to the embeddings. Crucially, the kernels act as “forces” that pull word‑pair similarities toward their μₖ if the pair should contribute positively to relevance, or push them away otherwise. This mechanism produces kernel‑guided embedding learning, whereby the embedding space is reshaped to encode multi‑level soft‑match patterns that best separate relevant from non‑relevant documents.
Experiments are conducted on a large Chinese commercial search engine log (≈35 M sessions, 96 K distinct queries). The dataset is split into 95 K training queries and 1 K head‑query test set; additional tail‑query tests evaluate robustness. Relevance labels are derived from three click‑based signals: DCTR, TACM, and raw clicks. Baselines include traditional BM25, representation‑based neural models (DSSM, CDSSM), and interaction‑based models (DRMM, MatchPyramid).
Across all evaluation scenarios (in‑domain, cross‑domain, raw clicks) K‑NRM consistently outperforms baselines, achieving up to 65 % relative improvement in NDCG@10 on head queries. Ablation studies reveal that removing the kernel layer or freezing the embeddings dramatically degrades performance, confirming that both components are essential. Varying the number of kernels shows diminishing returns after about 11 kernels, while too few kernels limit the model’s ability to capture nuanced similarity levels.
Key strengths of K‑NRM are:
- Parameter efficiency – only word embeddings are learned, avoiding the combinatorial explosion of pairwise similarity parameters.
- Multi‑level soft‑match representation – RBF kernels provide differentiable, density‑estimation‑style counts at multiple similarity thresholds, bridging the gap between exact term matching and pure semantic similarity.
- End‑to‑end optimization with click data – the model directly aligns its embedding space with user relevance signals, eliminating the need for handcrafted features.
- Interpretability – each kernel’s μₖ can be inspected to understand which similarity bands the model relies on.
Limitations include the need to pre‑define kernel means and widths (which may be domain‑specific), the quadratic memory cost of the translation matrix for long documents, and the reliance on click data that can be biased by position or presentation effects.
Future work suggested by the authors involves learning kernel parameters jointly with the rest of the network, applying matrix compression or sampling techniques to reduce computational overhead, extending the framework to multimodal inputs (e.g., images, audio), and testing transferability across languages and specialized domains such as biomedical or legal search.
In summary, K‑NRM demonstrates that a carefully designed kernel‑pooling mechanism can effectively guide embedding learning, yielding a powerful, interpretable, and scalable neural ranking model that substantially advances the state of the art in ad‑hoc information retrieval.
Comments & Academic Discussion
Loading comments...
Leave a Comment