Content-Based Table Retrieval for Web Queries
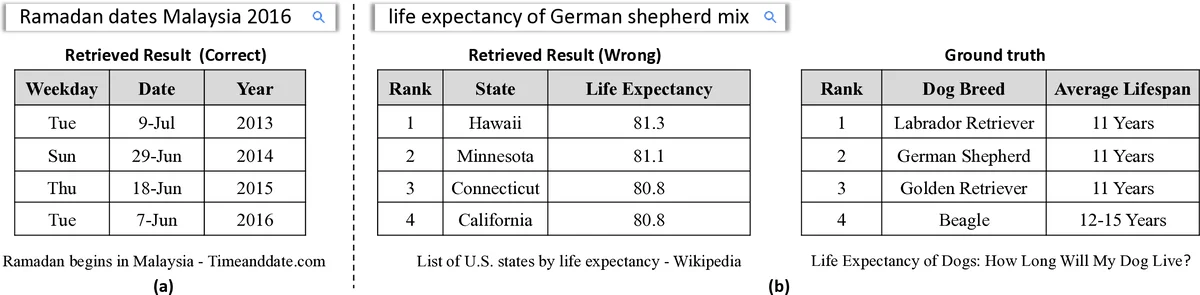
Understanding the connections between unstructured text and semi-structured table is an important yet neglected problem in natural language processing. In this work, we focus on content-based table retrieval. Given a query, the task is to find the most relevant table from a collection of tables. Further progress towards improving this area requires powerful models of semantic matching and richer training and evaluation resources. To remedy this, we present a ranking based approach, and implement both carefully designed features and neural network architectures to measure the relevance between a query and the content of a table. Furthermore, we release an open-domain dataset that includes 21,113 web queries for 273,816 tables. We conduct comprehensive experiments on both real world and synthetic datasets. Results verify the effectiveness of our approach and present the challenges for this task.
💡 Research Summary
The paper addresses the problem of retrieving a relevant web table given a natural‑language query, a task the authors term “content‑based table retrieval.” Unlike prior work that relies on surrounding text or page‑rank signals, this study focuses on the intrinsic content of tables—specifically their headers, cells, and caption. To tackle the problem, the authors propose a two‑stage ranking pipeline.
In the first stage, a fast candidate generation step uses the classic Okapi BM25 algorithm. Tables are represented as a plain‑text concatenation of their captions and headers, while queries are treated as bag‑of‑words. BM25 scores are computed efficiently, and the top‑K (e.g., 50 or 100) tables are passed to the second stage.
The second stage performs a fine‑grained relevance assessment using both handcrafted features and neural‑network models, and finally combines them with a learning‑to‑rank algorithm (LambdaMART). The handcrafted features operate at three linguistic levels:
- Word‑level overlap – two variants (f_wmt, f_wmq) count shared words between query and a table aspect, weighted by inverse document frequency.
- Phrase‑level paraphrase – a statistical‑machine‑translation (SMT) phrase table is extracted from a bilingual corpus; the probability that a query phrase and a table phrase translate to the same target phrase yields a paraphrase similarity score (f_pp).
- Sentence‑level embeddings – the authors employ CDSSM (a convolutional deep semantic model) to obtain sentence vectors for query and table aspects, and also compute a simple average‑word‑embedding cosine similarity (f_s2).
For the neural component, the query is encoded with a bidirectional GRU, producing a fixed‑length vector v_q. Table aspects are handled as external memories:
- Headers – each header cell is embedded; an attention mechanism computes a weighted sum (v_header) based on similarity to v_q.
- Cells, rows, columns – three separate memories (M_cel, M_row, M_col) are built. Each cell is an embedding; row and column vectors are obtained by weighted averaging of the cells belonging to the same row or column. The same attention‑based module (NN₁) scores query‑header, query‑cell, query‑row, and query‑column interactions.
- Caption – encoded with another bidirectional GRU, concatenated with v_q, and passed through a linear layer with softmax (NN₂).
All these scores become features for LambdaMART, which learns a non‑linear combination of the features via gradient‑boosted regression trees. The final relevance score for a query‑table pair is the weighted sum of leaf values across all trees.
A major contribution of the work is the release of a large, publicly available dataset called WebQueryTable. It contains 21,113 real web queries extracted from a commercial search engine’s logs, each paired with tables harvested from the top‑ranked web pages (273,816 Wikipedia tables in total). Human annotators labeled each query‑table pair as relevant or not, providing a realistic benchmark for table retrieval. The authors also evaluate on the synthetic WikiTableQuestions dataset to test domain transfer.
Experiments compare several configurations: (i) BM25 alone, (ii) LambdaMART with only handcrafted features, (iii) the neural‑network matcher alone, and (iv) a hybrid that concatenates both feature sets. Results show that the hybrid model consistently outperforms the others in MAP and NDCG@5/10, confirming that handcrafted lexical cues and deep semantic matching are complementary. Ablation studies reveal that removing any of the three table aspects (header, cell/row/column, caption) degrades performance, underscoring the importance of modeling the full table structure.
The paper also discusses limitations. Irregular tables (missing headers, varying row lengths) are excluded; handling them would require more sophisticated preprocessing. Cell‑type information (numeric, dates, units) is not explicitly modeled, which could improve fine‑grained matching. Finally, the authors note that integrating large pre‑trained language models (e.g., BERT, T5) and exploring end‑to‑end training are promising future directions.
In summary, the authors present a well‑engineered, two‑stage retrieval system that combines efficient candidate generation with rich, multi‑level matching. By releasing a sizable real‑world dataset and demonstrating strong empirical gains, the work establishes a solid baseline for future research on semantic table search and opens avenues for richer table understanding, irregular table handling, and integration with modern pre‑trained models.
Comments & Academic Discussion
Loading comments...
Leave a Comment