A Faster Method to Estimate Closeness Centrality Ranking
Closeness centrality is one way of measuring how central a node is in the given network. The closeness centrality measure assigns a centrality value to each node based on its accessibility to the whole network. In real life applications, we are mainly interested in ranking nodes based on their centrality values. The classical method to compute the rank of a node first computes the closeness centrality of all nodes and then compares them to get its rank. Its time complexity is $O(n \cdot m + n)$, where $n$ represents total number of nodes, and $m$ represents total number of edges in the network. In the present work, we propose a heuristic method to fast estimate the closeness rank of a node in $O(\alpha \cdot m)$ time complexity, where $\alpha = 3$. We also propose an extended improved method using uniform sampling technique. This method better estimates the rank and it has the time complexity $O(\alpha \cdot m)$, where $\alpha \approx 10-100$. This is an excellent improvement over the classical centrality ranking method. The efficiency of the proposed methods is verified on real world scale-free social networks using absolute and weighted error functions.
💡 Research Summary
The paper addresses the computational bottleneck associated with ranking nodes by closeness centrality in large networks. Traditional approaches require computing the closeness centrality of every node, which entails a breadth‑first search (BFS) from each vertex and results in a time complexity of O(n·m) (n = number of nodes, m = number of edges). This cost is prohibitive for modern, massive, and often dynamic graphs such as online social networks, collaboration networks, and communication graphs.
Key Insight
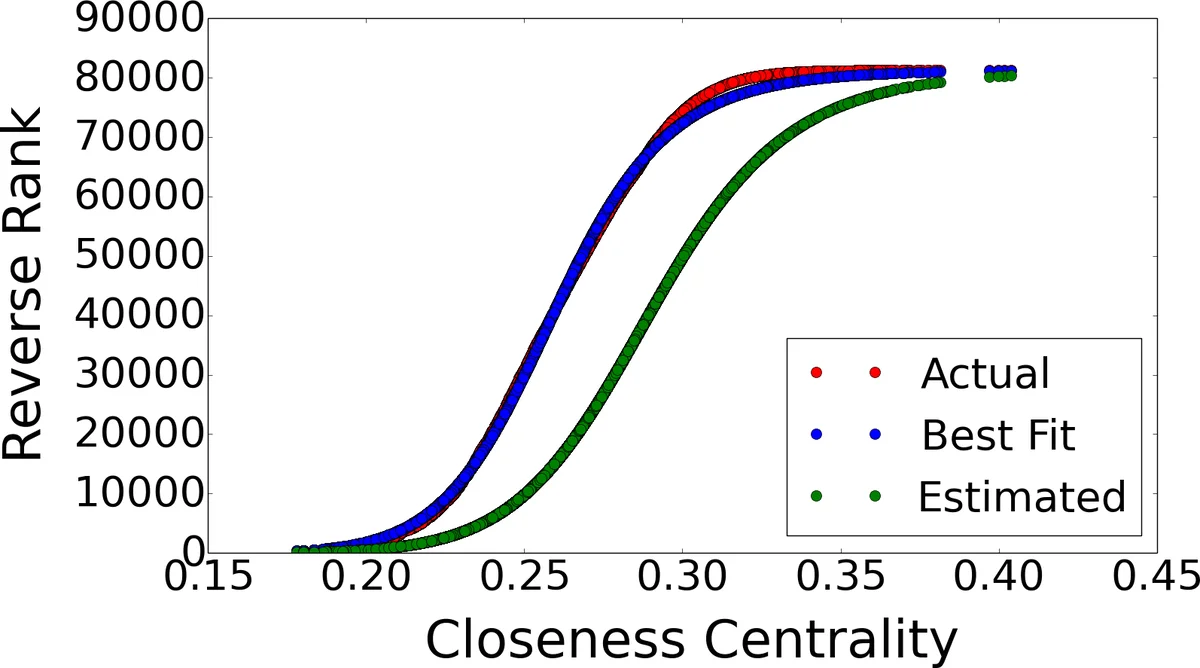
Empirical analysis of several real‑world scale‑free networks reveals a consistent pattern: the relationship between a node’s reverse rank (rank 1 for the smallest closeness value, rank n for the largest) and its closeness centrality follows a sigmoid (S‑shaped) curve. The authors model this relationship using a four‑parameter logistic function:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment