Exploiting Consistency Theory for Modeling Twitter Hashtag Adoption
Twitter, a microblogging service, has evolved into a powerful communication platform with millions of active users who generate immense volume of microposts on a daily basis. To facilitate effective categorization and easy search, users adopt hashtags, keywords or phrases preceded by hash (#) character. Successful prediction of the spread and propagation of information in the form of trending topics or hashtags in Twitter, could help real time identification of new trends and thus improve marketing efforts. Social theories such as consistency theory suggest that people prefer harmony or consistency in their thoughts. In Twitter, for example, users are more likely to adopt the same trending hashtag multiple times before it eventually dies. In this paper, we propose a low-rank weighted matrix factorization approach to model trending hashtag adoption in Twitter based on consistency theory. In particular, we first cast the problem of modeling trending hashtag adoption into an optimization problem, then integrate consistency theory into it as a regularization term and finally leverage widely used matrix factorization to solve the optimization. Empirical experiments demonstrate that our method outperforms other baselines in predicting whether a specific trending hashtag will be used by users in future.
💡 Research Summary
**
The paper tackles the problem of predicting future adoption of trending Twitter hashtags by integrating a social‑psychological principle—Consistency Theory—into a low‑rank weighted matrix factorization framework. Consistency Theory posits that individuals prefer harmony in their beliefs and actions; applied to Twitter, it suggests that a user who has used a particular hashtag before is more likely to reuse it later.
Data Collection and Pre‑processing
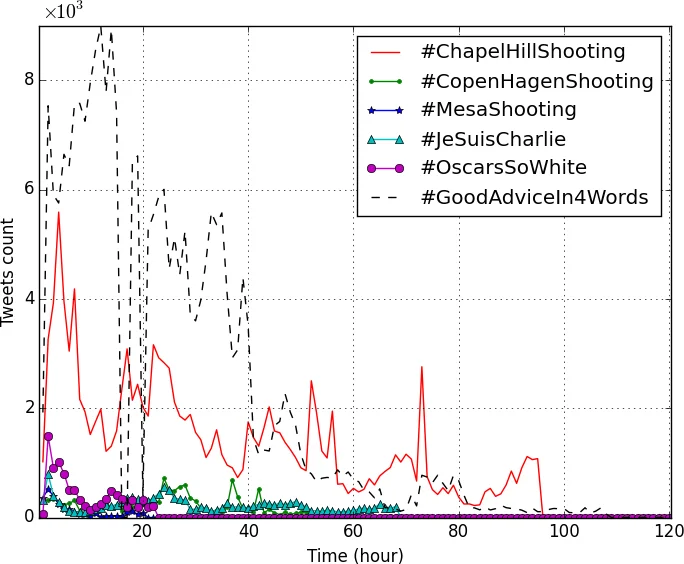
The authors collected tweets related to six distinct trending hashtags that each peaked for less than a week between January and March 2015 using Twitter’s 1 % streaming API. The dataset comprises 425,731 tweets from 212,062 users, yielding a user‑time matrix X∈ℝ^{N×M} (N ≈ 212 k users, M ≈ 120 hourly time slots). The matrix is extremely sparse (≈ 0.99 sparsity) because only about 8 % of tweets contain hashtags.
Empirical Validation of Consistency
To verify the consistency hypothesis, the authors construct two vectors: h_cu, counting how many times each user repeats the same hashtag, and h_cr, counting repetitions between a user and a random other user. A two‑sample t‑test yields a p‑value of 2.53 × 10⁻⁴⁹ (α = 0.01), strongly rejecting the null hypothesis that users do not repeat hashtags more than random pairs. This statistical evidence justifies embedding consistency into the predictive model.
Model Formulation
The core model approximates X by the product of two low‑rank non‑negative matrices U∈ℝ^{N×d} (user latent factors) and V∈ℝ^{M×d} (time latent factors), i.e., X ≈ UVᵀ. Three key components are added to the standard weighted matrix factorization loss:
-
Observation mask W – an indicator matrix where w_{ij}=1 if x_{ij} is known (training data) and 0 otherwise, ensuring that only observed entries influence the loss.
-
Consistency regularizer – µ‖G⊙(1 − UVᵀ)‖_F², where G is a time‑attenuation matrix. For each user row, the first time a ‘1’ appears (first adoption) receives a weight of 1; subsequent time slots receive decreasing weights 1/(M − j + 1). This captures two phenomena: (a) the desire for consistency (the model is penalized if UVᵀ deviates from 1 after the first adoption) and (b) the natural decay of a trend over time.
-
L2 regularization – γ₁‖U‖_F² + γ₂‖V‖_F² to prevent overfitting.
The full objective is:
min_{U,V} ‖W⊙(X − UVᵀ)‖_F² + γ₁‖U‖_F² + γ₂‖V‖_F² + µ‖G⊙(1 − UVᵀ)‖_F²
Optimization
Because U and V are coupled, the authors employ Alternating Least Squares (ALS). Holding V fixed, they compute the gradient ∂L/∂U (Equation 7) and update U via a gradient step with learning rate λ; similarly for V (Equation 8). The dominant computational cost per iteration is O(N_x d + N M d), where N_x is the number of non‑zero entries in X and d is the latent dimension. Convergence is declared when the objective change falls below a threshold or a maximum iteration count is reached.
Baselines and Evaluation
Four baselines are compared:
- WMF – the same factorization without the consistency term (µ = 0).
- ARMA – a classic autoregressive moving‑average time‑series model applied to each hashtag’s hourly count.
- First‑order Markov Chain – a two‑state (0/1) model estimating transition probabilities from the sparse X.
- Random – random binary predictions for test entries.
The evaluation metric is Root Mean Square Error (RMSE) computed on a held‑out test set of user‑time pairs.
Results
Across all six hashtags, the proposed method (named hCWMF) achieves the lowest RMSE, outperforming WMF by a noticeable margin, and dramatically beating ARMA, Markov, and Random baselines. The improvement over WMF demonstrates that the consistency regularizer adds predictive power beyond pure collaborative filtering. The attenuation matrix G further refines predictions by down‑weighting later time slots, reflecting the natural decay of trending topics.
Discussion and Limitations
The authors acknowledge several constraints:
- The model assumes a single decay curve per user based on the first adoption, which may be insufficient for hashtags that experience multiple resurgence peaks.
- External events (news cycles, political developments) that drive hashtag popularity are not explicitly modeled.
- The 1 % streaming API introduces sampling bias; results may differ with full‑firehose data.
Future Work
Potential extensions include:
- Learning adaptive attenuation schedules or multi‑peak decay functions.
- Incorporating textual content, user network structure, or external event streams into a joint model.
- Developing an online ALS variant for real‑time prediction on streaming data.
Conclusion
By grounding a matrix factorization model in Consistency Theory and augmenting it with a time‑attenuation mechanism, the paper presents a novel, empirically validated approach for forecasting hashtag reuse on Twitter. The method bridges social‑psychological insight and scalable machine‑learning techniques, offering a promising tool for marketers, crisis managers, and researchers interested in information diffusion on social media.
Comments & Academic Discussion
Loading comments...
Leave a Comment