Report of the HPC Correctness Summit, Jan 25--26, 2017, Washington, DC
Maintaining leadership in HPC requires the ability to support simulations at large scales and fidelity. In this study, we detail one of the most significant productivity challenges in achieving this goal, namely the increasing proclivity to bugs, especially in the face of growing hardware and software heterogeneity and sheer system scale. We identify key areas where timely new research must be proactively begun to address these challenges, and create new correctness tools that must ideally play a significant role even while ramping up toward exacale. We close with the proposal for a two-day workshop in which the problems identified in this report can be more broadly discussed, and specific plans to launch these new research thrusts identified.
💡 Research Summary
The “Report of the HPC Correctness Summit” (January 25‑26 2017, Washington, DC) presents a comprehensive diagnosis of the growing correctness crisis in high‑performance computing (HPC) and outlines a multi‑year research roadmap to address it. The authors begin by identifying four systemic drivers of the crisis: (1) hardware heterogeneity (CPUs, GPUs, Xeon‑Phi, non‑volatile memory, etc.) that introduces divergent performance and floating‑point behavior; (2) massive scale, where millions of MPI ranks and threads must be coordinated, exposing bugs only at exascale; (3) non‑intuitive behavior caused by power‑saving features, weak memory models, and dynamic voltage/frequency scaling; and (4) cognitive overload, as modern applications combine SPMD, task parallelism, runtime systems, code generation, and adaptive execution, making manual reasoning infeasible.
The report defines the correctness problem as the gap between a formal specification (mathematical model, precision guarantees, resource contracts) and verification that an implementation respects that specification. It stresses that correctness depends not only on user code but also on libraries and runtimes (MPI, OpenMP, numerical libraries), whose undocumented or underspecified semantics can cause deadlocks, crashes, or silent numerical errors.
Current state‑of‑the‑art techniques are surveyed under three headings: static analysis, dynamic analysis, and formal methods. Static analysis tools aim to catch MPI tag misuse, data‑race potentials, and floating‑point precision violations at compile time. Dynamic analysis tools (e.g., race detectors, tracing frameworks) capture nondeterministic interactions during execution, while formal methods (model checking, theorem proving) provide mathematical guarantees for algorithms, compilers, and libraries. The report also discusses anomaly‑detection approaches based on machine‑learning analysis of logs and the limitations of traditional print‑based debugging at extreme scale.
Four research thrusts are proposed. 1) Static Methods – develop scalable static analysis pipelines tailored to runtime systems, numerical algorithms, and specification languages; verify compilers and critical libraries; and create domain‑specific specification frameworks. 2) Dynamic Methods – build lightweight, scalable tracing and replay mechanisms that can operate on exascale runs, enabling deterministic replay of nondeterministic bugs. 3) Debugging – integrate stack‑trace race analysis, fault injection, and “scale‑in‑simulation” techniques into user‑friendly IDEs, reducing the time to isolate bugs that currently consume months of effort. 4) Pragmatic Thrusts – foster community‑wide best‑practice repositories, bug‑report databases, and DSLs that encapsulate correct usage patterns; organize verification competitions and workshops to disseminate tools.
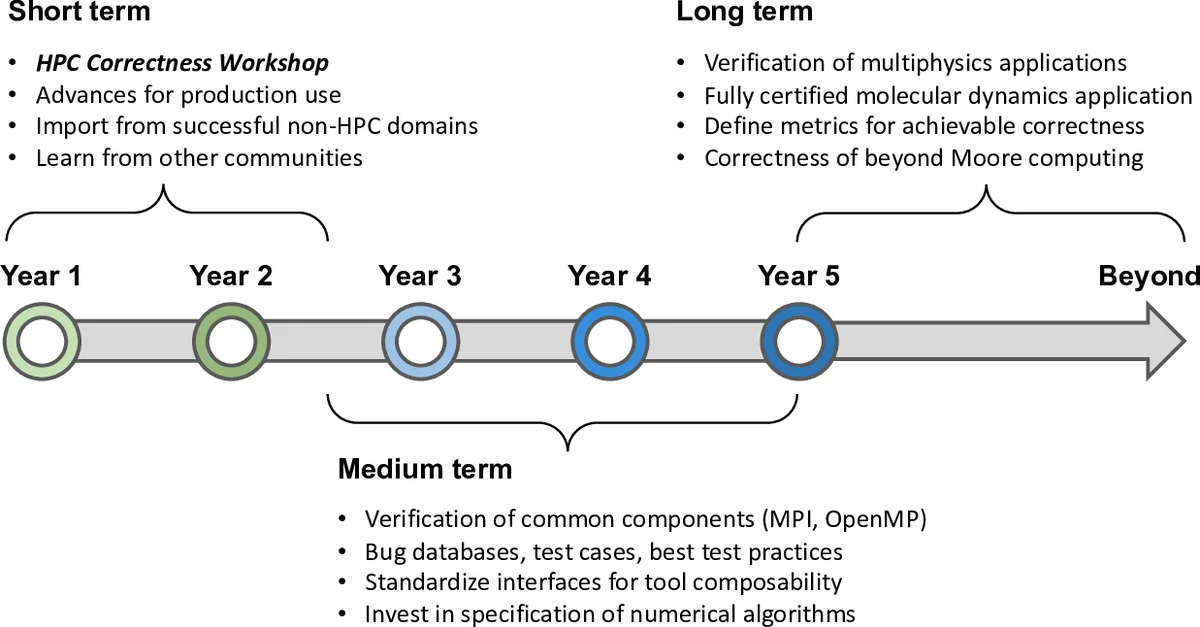
The roadmap is divided into short‑term (1‑2 years), medium‑term (2‑5 years), and long‑term (5 + years) milestones. In the short term, prototype static analyzers and dynamic race detectors will be released, along with case studies on verified molecular‑dynamics and multiphysics codes. The medium term targets formal verification of compiler/runtime components and the production of fully certified scientific applications. The long‑term vision includes establishing a DOE‑wide verification infrastructure, regular HPC correctness workshops, and annual competitions that drive the adoption of verified software across the exascale ecosystem.
In conclusion, the authors warn that without coordinated investment, the increasing complexity of exascale hardware and software will outpace developers’ ability to ensure correctness, jeopardizing scientific credibility and wasting valuable computational resources. They call for a concerted effort among government, academia, and industry to develop the next generation of correctness tools, standards, and community practices that will keep HPC trustworthy as it scales toward exascale and beyond.
Comments & Academic Discussion
Loading comments...
Leave a Comment