Data Access for LIGO on the OSG
During 2015 and 2016, the Laser Interferometer Gravitational-Wave Observatory (LIGO) conducted a three-month observing campaign. These observations delivered the first direct detection of gravitational waves from binary black hole mergers. To search for these signals, the LIGO Scientific Collaboration uses the PyCBC search pipeline. To deliver science results in a timely manner, LIGO collaborated with the Open Science Grid (OSG) to distribute the required computation across a series of dedicated, opportunistic, and allocated resources. To deliver the petabytes necessary for such a large-scale computation, our team deployed a distributed data access infrastructure based on the XRootD server suite and the CernVM File System (CVMFS). This data access strategy grew from simply accessing remote storage to a POSIX-based interface underpinned by distributed, secure caches across the OSG.
💡 Research Summary
The paper describes how the LIGO Scientific Collaboration, during its first observing run (O1) in 2015‑2016, built a scalable data‑access infrastructure on the Open Science Grid (OSG) to support the PyCBC gravitational‑wave search pipeline. The analysis of O1 required processing several petabytes of non‑public frame data, with each PyCBC job reading one or two 400 MB files at an average sustained rate of about 1 Mbps. The original solution relied on a centralized Hadoop Distributed File System (HDFS) at the University of Nebraska and GridFTP for data transfer. While this approach could theoretically support the estimated 10 000 cores, practical issues emerged: each GridFTP connection consumed ~128 MB of RAM due to an embedded Java VM, leading to memory exhaustion when thousands of jobs started simultaneously; the need to manually throttle job start rates introduced inefficiencies; and the system could not gracefully handle the heterogeneous performance of remote sites.
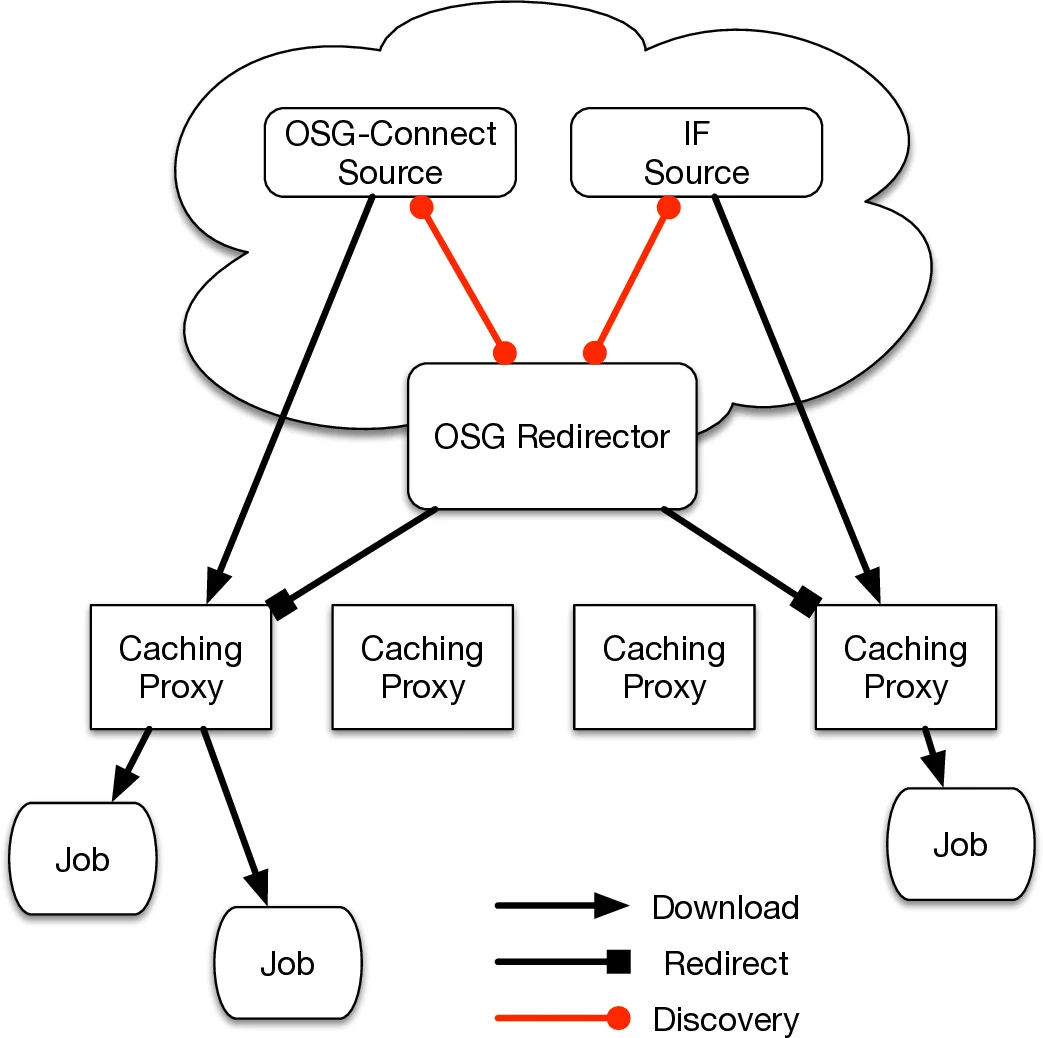
To overcome these limitations, the authors migrated to an XRootD‑based data federation complemented by the StashCache caching layer. XRootD provides a lightweight, multithreaded server capable of handling thousands of low‑throughput connections with minimal memory overhead. StashCache proxies, geographically distributed across the United States, act as intermediate caches: a job first contacts the nearest proxy; if the requested file is cached, it is served locally, otherwise the proxy queries the OSG redirector to locate the authoritative source (the Nebraska HDFS) and streams the data. This design dramatically reduces network latency, balances load, and eliminates the need for manual job‑rate throttling.
In parallel, the authors extended the CernVM‑File System (CVMFS) – traditionally used for public software distribution – to support large, non‑public scientific datasets. By integrating CVMFS with the XRootD federation, they offered a POSIX‑compatible namespace, allowing PyCBC jobs to access data as if it resided on a local filesystem. This abstraction hides the complexity of remote streaming from end users and simplifies workflow management.
The infrastructure was further tested with non‑OSG resources. At the Texas Advanced Computing Center (TACC) Stampede cluster, which lacks CVMFS, the team used rsync to mirror required CVMFS repositories onto a scratch filesystem and employed Globus Transfer for a one‑time copy of the O1 data. Because Stampede’s batch system did not natively support the GlideinWMS pilot model, a custom startup script using the srun command launched a pilot on each node of a multi‑node job, enabling the use of up to 10 000 Stampede cores. Later, European VIRGO sites operating under the EGI framework were added by simply registering their pilot hosts, demonstrating the solution’s portability.
Operational results showed that, at peak, more than 25 000 cores could be allocated to a single PyCBC workflow, with data‑access latency reduced to a few seconds and no observable memory bottlenecks on the central storage. The XRootD‑CVMFS‑StashCache stack proved robust against variable site performance and eliminated the need for per‑site data replicas, thereby reducing operational overhead for LIGO.
The authors conclude by outlining plans to evolve the system into a multi‑tenant, globally federated data‑management platform that could serve other data‑intensive scientific collaborations. Their work illustrates how a combination of lightweight data‑transfer protocols (XRootD), hierarchical caching (StashCache), and POSIX‑style distribution (CVMFS) can turn a heterogeneous, opportunistic grid into a reliable, high‑throughput data‑processing environment.
Comments & Academic Discussion
Loading comments...
Leave a Comment