Algorithm-Directed Crash Consistence in Non-Volatile Memory for HPC
Fault tolerance is one of the major design goals for HPC. The emergence of non-volatile memories (NVM) provides a solution to build fault tolerant HPC. Data in NVM-based main memory are not lost when the system crashes because of the non-volatility nature of NVM. However, because of volatile caches, data must be logged and explicitly flushed from caches into NVM to ensure consistence and correctness before crashes, which can cause large runtime overhead. In this paper, we introduce an algorithm-based method to establish crash consistence in NVM for HPC applications. We slightly extend application data structures or sparsely flush cache blocks, which introduce ignorable runtime overhead. Such extension or cache flushing allows us to use algorithm knowledge to \textit{reason} data consistence or correct inconsistent data when the application crashes. We demonstrate the effectiveness of our method for three algorithms, including an iterative solver, dense matrix multiplication, and Monte-Carlo simulation. Based on comprehensive performance evaluation on a variety of test environments, we demonstrate that our approach has very small runtime overhead (at most 8.2% and less than 3% in most cases), much smaller than that of traditional checkpoint, while having the same or less recomputation cost.
💡 Research Summary
The paper addresses the challenge of achieving crash‑consistent state in high‑performance computing (HPC) systems that use non‑volatile memory (NVM) as main memory. While NVM retains data after power loss, volatile CPU caches break the guarantee that the data stored in NVM reflects the most recent program state. Traditional solutions rely on redo/undo logging or periodic checkpoint/restart, which require extensive data copying, metadata management, and full cache flushing, leading to substantial runtime overhead—often 4‑5× slower for memory‑intensive kernels.
The authors propose an algorithm‑directed approach that eliminates most of this overhead by (1) modestly extending application data structures with lightweight metadata, and (2) selectively flushing only those cache blocks that are critical for consistency. Crucially, the method leverages invariant properties inherent to the algorithms themselves to reason about data correctness after a crash. Three representative algorithms are examined:
-
Conjugate Gradient (CG) iterative solver – CG maintains orthogonality between the search direction vector p and the matrix‑vector product q (pᵢ₊₁ᵀ·qᵢ = 0) and an exact residual relationship (rᵢ₊₁ = b – A·zᵢ₊₁). By adding tiny markers to the vectors and flushing only when these invariants may be violated, the system can detect whether p, q, and z are consistent in NVM after a crash. If an invariant fails, the missing vector can be recomputed from the others, avoiding a full checkpoint.
-
Dense matrix multiplication with Algorithm‑Based Fault Tolerance (ABFT) – ABFT embeds checksums (row and column sums) into the matrix data. The checksums are inexpensive (≈1 % extra work) but provide a powerful consistency test: after a crash, the checksum can be compared with the computed sums of the matrix blocks stored in NVM. Any discrepancy pinpoints the corrupted block, which can then be recomputed locally. This eliminates the need for redo logs.
-
Monte‑Carlo (MC) simulation – MC algorithms are statistically tolerant, yet certain intermediate results (e.g., random seeds, accumulated tallies) are critical. The authors identify these “critical intermediates” and flush only them, leaving the bulk of the random data in cache. Upon restart, the algorithm can continue using the preserved intermediates, and the statistical nature of MC masks minor inconsistencies.
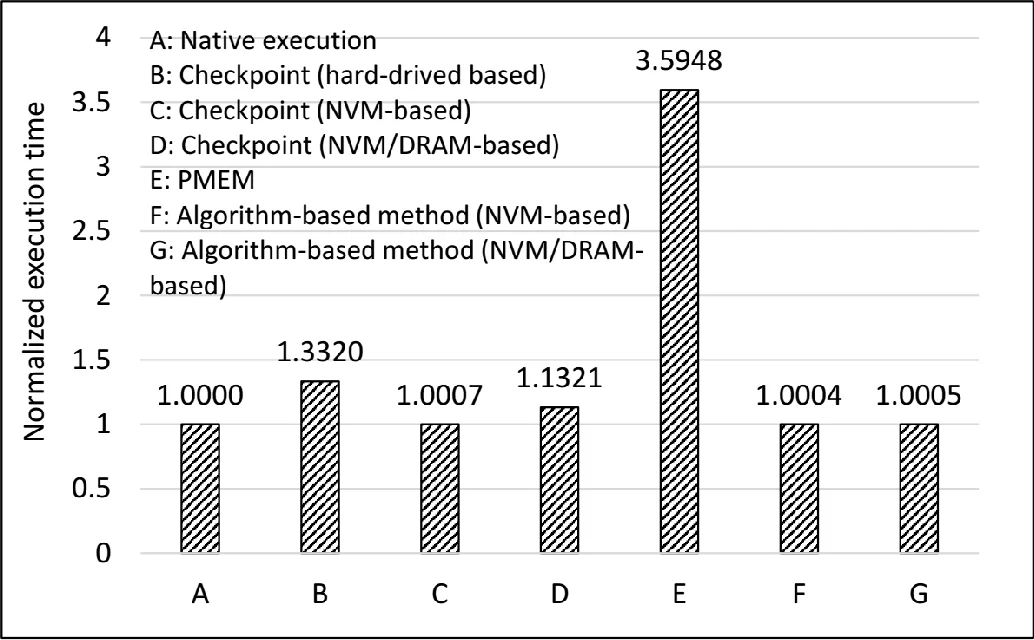
To evaluate the approach, the authors built a PIN‑based “crash emulator” that intercepts memory accesses, simulates an LRU cache, and records the latest values in both cache and NVM. They also used the Quartz NVM emulator to model a memory system with 1/8 DRAM bandwidth and 4× DRAM latency, as well as a heterogeneous NVM/DRAM configuration with a 32 MB DRAM cache. Seven execution scenarios were compared: native run, checkpoint to local disk, checkpoint to NVM‑only, checkpoint to heterogeneous NVM/DRAM, Intel PMEM library, and the proposed algorithm‑directed method on both NVM‑only and heterogeneous systems.
Results show that the algorithm‑directed technique incurs an average runtime overhead of only 2‑3 % and never exceeds 8.2 % even in worst‑case configurations. Traditional checkpointing incurs 10‑30 % overhead due to data copying and full cache flushing. Re‑computation cost after a crash is minimal because most data remain consistent in NVM, especially for large problem sizes where the working set far exceeds cache capacity. Compared with Intel’s PMEM library, the proposed method achieves comparable or lower recomputation cost while delivering significantly lower runtime overhead.
The paper’s contributions are threefold: (1) introducing a lightweight, algorithm‑aware mechanism for crash consistency in NVM‑based HPC; (2) demonstrating that recomputation cost varies with cache effects but can be kept low for realistic workloads; (3) showing that, with modest software changes, NVM can replace or substantially reduce traditional checkpointing in future exascale systems.
In conclusion, by exploiting algorithmic invariants and performing targeted cache flushes, the authors provide a practical path toward fault‑tolerant HPC on emerging non‑volatile memories, achieving near‑native performance with minimal additional complexity. Future work includes extending the technique to a broader set of algorithms and validating the approach on real NVM hardware.
Comments & Academic Discussion
Loading comments...
Leave a Comment