A survey of Community Question Answering
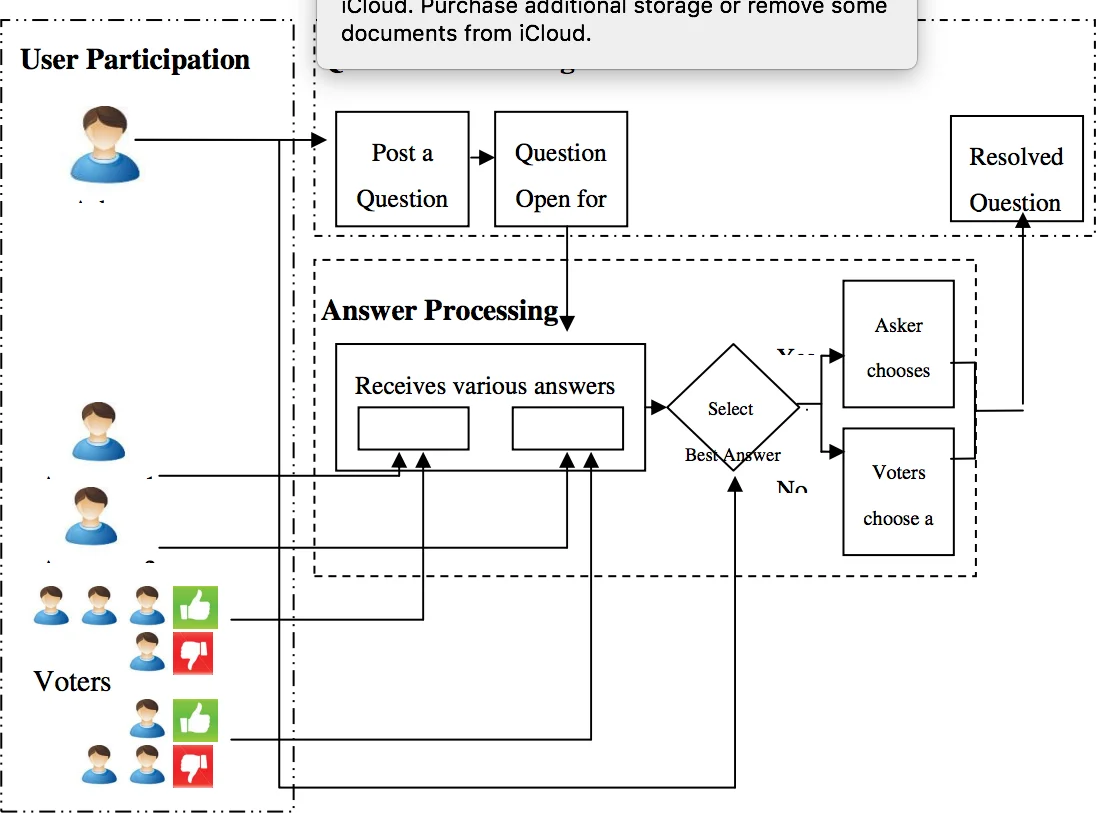
With the advent of numerous community forums, tasks associated with the same have gained importance in the recent past. With the influx of new questions every day on these forums, the issues of identifying methods to find answers to said questions, or even trying to detect duplicate questions, are of practical importance and are challenging in their own right. This paper aims at surveying some of the aforementioned issues, and methods proposed for tackling the same.
💡 Research Summary
The paper provides a comprehensive survey of the research landscape surrounding Community Question Answering (cQA) systems, which have become increasingly prominent with the rise of platforms such as Yahoo! Answers, Stack Overflow, and Quora. It begins by distinguishing cQA from traditional Question Answering (QA). While conventional QA typically deals with short, factoid queries answered from a structured knowledge base, cQA involves multi‑sentence, often noisy user‑generated questions, a diverse set of user‑provided answers, and rich auxiliary signals such as up‑votes, down‑votes, and answerer reputation. This fundamental difference gives rise to two primary research problems: (1) Question Semantic Matching (detecting duplicate or semantically similar questions) and (2) Question‑Answer Ranking/Retrieval (selecting the most appropriate answer from a pool).
For Question Semantic Matching, the survey first outlines classic lexical approaches. Okapi BM25 treats questions as bags of words and computes an asymmetric similarity score based on inverse document frequency; the final similarity is the average of the two directional scores. The Translation Language Model (TransLM) reframes the problem as a probabilistic translation task, estimating P(q₁|q₂) and P(q₂|q₁) and averaging them to bridge the lexical gap. Both methods rely heavily on token overlap and therefore struggle when paraphrases use different vocabularies.
To overcome these limitations, the paper reviews embedding‑based and neural attention techniques. Word‑embedding methods map each token to a dense vector (e.g., Word2Vec) and aggregate them via averaging, sum, or an LSTM encoder, optionally feeding the resulting sentence representation into a multilayer perceptron for similarity prediction. Parikh et al. (2016) introduced a token‑alignment attention model that constructs an affinity matrix between two questions, normalizes it row‑wise and column‑wise with softmax, and produces attention‑weighted token representations. The final question vectors are obtained by summing these representations, concatenated, and passed through a dense layer to output a similarity score. This approach captures fine‑grained interactions beyond simple bag‑of‑words.
For Question‑Answer Ranking, the same lexical baselines (BM25, TransLM) are shown to be insufficient because the lexical overlap between a question and a good answer is often minimal. Consequently, the survey details several neural architectures. Convolutional Neural Networks (CNNs) generate fixed‑size embeddings for both questions and answers; a max‑margin loss (or binary cross‑entropy) is used to separate correct from incorrect answer pairs. Bi‑directional LSTMs (Bi‑LSTM) encode contextual information before a CNN layer, and attention mechanisms allow the model to focus on answer tokens most relevant to the question representation. Qiu and Huang (2015) further extend this idea with a deep CNN that employs multiple k‑max pooling layers and a tensor‑based interaction layer, enabling both additive and multiplicative interactions between question and answer vectors. The scoring function combines these interactions, and the model can be adapted for both answer selection and question similarity tasks.
Experimental evaluation spans three benchmark datasets. The TREC QA dataset (factoid questions) is used for answer ranking, reporting Mean Average Precision (MAP) and Mean Reciprocal Rank (MRR). Yahoo! Answers provides a large real‑world cQA corpus (312 K QA pairs) for both duplicate detection and answer retrieval, with metrics such as Precision@1 (P@1), MAP, and Precision@10 (P@10). The Quora Question Pairs dataset (≈ 404 K labeled pairs) serves as a massive testbed for duplicate detection, supplemented by a Kaggle competition test set. Results consistently show that lexical baselines achieve modest scores (P@1 around 30–40 %). In contrast, embedding‑based CNNs, Convolutional Neural Tensor Networks (CNTN), and especially QA‑LSTM variants with attention attain P@1 scores above 70 %, with the best model (QA‑LSTM/CNN with Attention) reaching 82 % on the Yahoo! Answers duplicate detection task. Similar trends appear in answer ranking, where deep CNNs and attention‑augmented models outperform traditional methods by a large margin.
The discussion emphasizes the inherent “lexical gap” problem in cQA: questions and answers often use different vocabularies despite being semantically related. Consequently, simple token overlap is insufficient, and models that capture semantic similarity via dense embeddings and attention mechanisms are essential. The authors also note that cQA offers abundant side information (vote counts, user reputation, temporal signals) that can be integrated into multi‑modal models, a promising direction for future work. Moreover, most surveyed approaches rely on supervised learning with extensive labeled data; the paper suggests exploring weakly supervised, semi‑supervised, or self‑supervised techniques to reduce annotation costs.
In summary, the survey systematically categorizes the evolution of cQA research from early information‑retrieval methods to modern deep learning architectures, provides empirical comparisons across major datasets, and highlights both the successes of neural models and the open challenges—lexical gap, data sparsity, and effective use of meta‑data—that remain for the community to address.
Comments & Academic Discussion
Loading comments...
Leave a Comment