Compressing DMA Engine: Leveraging Activation Sparsity for Training Deep Neural Networks
Popular deep learning frameworks require users to fine-tune their memory usage so that the training data of a deep neural network (DNN) fits within the GPU physical memory. Prior work tries to address this restriction by virtualizing the memory usage of DNNs, enabling both CPU and GPU memory to be utilized for memory allocations. Despite its merits, virtualizing memory can incur significant performance overheads when the time needed to copy data back and forth from CPU memory is higher than the latency to perform the computations required for DNN forward and backward propagation. We introduce a high-performance virtualization strategy based on a “compressing DMA engine” (cDMA) that drastically reduces the size of the data structures that are targeted for CPU-side allocations. The cDMA engine offers an average 2.6x (maximum 13.8x) compression ratio by exploiting the sparsity inherent in offloaded data, improving the performance of virtualized DNNs by an average 32% (maximum 61%).
💡 Research Summary
The paper addresses the fundamental limitation of GPU memory capacity that hampers the training of large deep neural networks (DNNs). Existing solutions such as virtualized DNN (vDNN) mitigate this issue by offloading activation maps from GPU memory to CPU memory and prefetching them when needed. While vDNN reduces the on‑GPU memory footprint, it suffers from severe performance degradation when the time required to move data over the PCIe link exceeds the time spent on forward and backward computation. As GPU compute libraries (e.g., cuDNN) become faster, the overlap window between computation and data transfer shrinks, leading to average overheads of 31 % (up to 52 %) for vDNN.
The authors observe that activation maps generated during training are highly sparse because ReLU layers zero‑out a large fraction of values. Empirical measurements on several convolutional networks (AlexNet, VGG, GoogLeNet, etc.) show per‑layer average activation densities typically between 10 % and 30 %, and this sparsity remains relatively stable throughout training. This insight motivates a compression‑based approach: if the sparse activation data can be compressed before transmission, the effective data volume over PCIe can be dramatically reduced.
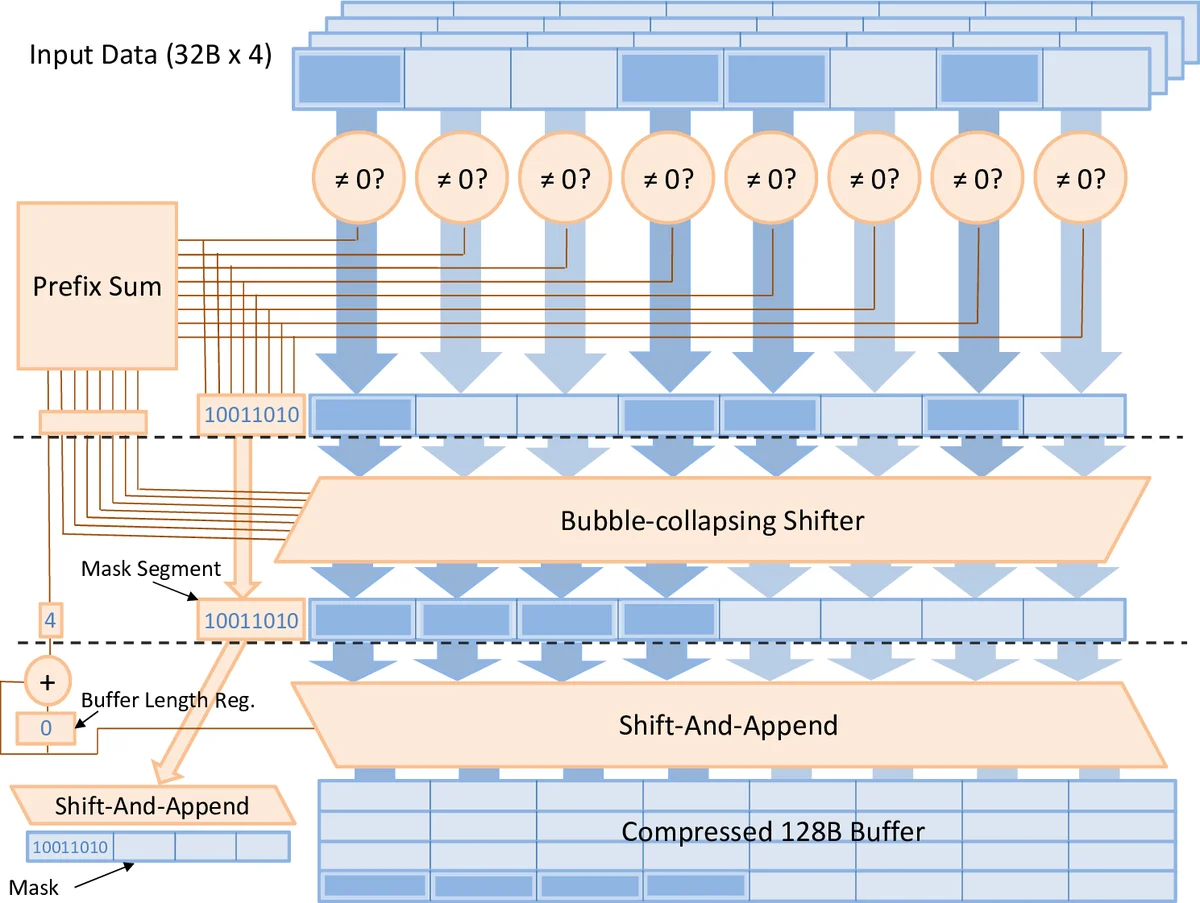
To exploit this, the paper introduces a compressing DMA engine (cDMA). cDMA extends the compression/decompression units already present in modern GPU memory controllers, avoiding substantial hardware redesign. When data are read from GPU DRAM for offloading, the cDMA pipeline performs on‑the‑fly zero‑run‑length encoding (or a similar lightweight scheme) that removes zero entries and packs the remaining non‑zero values into a dense bitstream. The compressed stream is then sent over PCIe to CPU memory. When the data are needed again for back‑propagation, the engine decompresses the stream back into the original activation layout. Because compression and decompression occur at memory‑controller speed, they can keep pace with the PCIe bandwidth, ensuring that the effective transfer rate equals “PCIe bandwidth × compression ratio”.
Experimental results demonstrate an average compression ratio of 2.6× (maximum 13.8×) across the evaluated networks. This reduction translates into an average 32 % performance improvement over vDNN (up to 61 % in the best case). The gains are most pronounced for models whose activation memory far exceeds the GPU’s physical capacity, confirming that cDMA effectively alleviates the PCIe bottleneck. The approach is less beneficial for recurrent networks that rely on sigmoid or tanh activations (e.g., LSTM, GRU), where sparsity is much lower.
In summary, the paper shows that leveraging activation sparsity through a hardware‑aware compression DMA engine can simultaneously achieve memory scalability and high performance for DNN training. The solution is compatible with existing GPU architectures, incurs minimal design overhead, and paves the way for training ever larger models as interconnect bandwidths continue to improve (e.g., PCIe 5.0, NVLink).
Comments & Academic Discussion
Loading comments...
Leave a Comment