Robust reputation-based ranking on multipartite rating networks
The spread of online reviews, ratings and opinions and its growing influence on people’s behavior and decisions boosted the interest to extract meaningful information from this data deluge. Hence, crowdsourced ratings of products and services gained a critical role in business, governments, and others. We propose a new reputation-based ranking system utilizing multipartite rating subnetworks, that clusters users by their similarities, using Kolmogorov complexity. Our system is novel in that it reflects a diversity of opinions/preferences by assigning possibly distinct rankings, for the same item, for different groups of users. We prove the convergence and efficiency of the system and show that it copes better with spamming/spurious users, and it is more robust to attacks than state-of-the-art approaches.
💡 Research Summary
The paper addresses the growing importance of crowdsourced ratings in e‑commerce, streaming, and the collaborative economy, highlighting the need for robust methods to aggregate these ratings in the presence of spam and malicious attacks. Traditional aggregation techniques such as the simple arithmetic average (AA) treat all users equally, making them vulnerable to manipulation and incapable of capturing multimodal rating distributions. Weighted‑average approaches improve robustness but still operate on a bipartite user‑item graph, ignoring relationships among users and the possibility that different user groups may have distinct preferences.
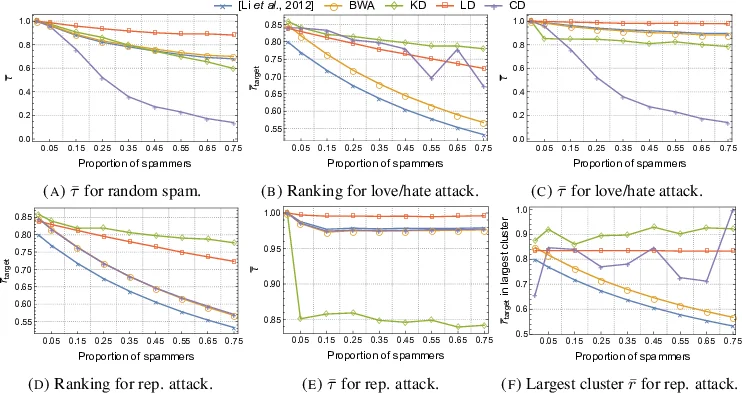
To overcome these limitations, the authors propose a reputation‑based ranking framework built on a multipartite graph. The core idea is to first cluster users based on the similarity of their rating patterns, then compute separate item rankings for each cluster. Three similarity measures are introduced: (1) Linear Distance (LD), which normalizes the absolute differences of common ratings; (2) Kolmogorov Distance (KD), which approximates Kolmogorov complexity by compressing each user’s rating string and taking the absolute difference of compressed lengths; and (3) Normalized Compression Distance (CD), a well‑known metric from information theory. An adjacency matrix S is constructed by thresholding the chosen similarity measure with a parameter α; connected components of the resulting graph define the user clusters (sub‑networks).
Within each sub‑network, an iterative algorithm updates item rankings r and user reputations c. The ranking update g_R computes a weighted average of ratings, where each rating is multiplied by the current reputation of the rater (Equation 3.1). The reputation update h_R evaluates how closely a user’s ratings align with the current item rankings, using either the average, maximum, or minimum deviation across the items the user has rated (Equation 3.2). A decay function f_λ,s controls the penalty severity; three forms are considered: a constant λ, an exponential decay λ·(1‑e^{‑x²}), and a logistic variant λ·(1‑1/(1+e^{‑x})). The authors focus on the constant decay for most experiments, referring to the resulting scheme as Bipartite Weighted Average (BWA).
A key theoretical contribution is the proof of convergence for the entire class of algorithms defined by the iteration (2.1). By treating the reputation and ranking vectors as elements of a Banach space and assuming that g_R and h_R are Lipschitz continuous with constants η_g and η_h, the composition g_R∘h_R becomes a contraction with constant η = η_g·η_h. If η < 1, Banach’s Fixed‑Point Theorem guarantees a unique fixed point and exponential convergence (Theorems 1 and 2). The authors further derive concrete conditions for the specific functions used: choosing λ < 1/ΔR ensures that the Lipschitz constant of the reputation update is bounded by λ·ΔR < 1, making the overall iteration a contraction.
Experimental evaluation uses both real‑world rating datasets and synthetic attack scenarios. Metrics include Mean Absolute Error (MAE), rank correlation, and robustness against varying proportions of spam users. Results show that LD‑based clustering yields the best resistance to random noisy spam, while KD offers slightly better protection against targeted attacks on specific items. Both outperform traditional weighted‑average baselines, reducing MAE by roughly 10–15 % and achieving rank correlations above 0.85. Moreover, the multipartite approach produces distinct rankings for each user cluster, effectively capturing multimodal preferences that a single global ranking would obscure.
From a computational standpoint, LD and KD can be computed in O(|U|·|O|) time, whereas CD incurs additional overhead due to compression, making LD/KD more suitable for large‑scale, real‑time recommendation systems. The paper concludes that integrating user similarity via Kolmogorov‑inspired measures into a multipartite reputation framework substantially enhances both accuracy and robustness, and it suggests future work on dynamic clustering, temporal evolution of reputations, and extensions to item‑side clustering.
Comments & Academic Discussion
Loading comments...
Leave a Comment