An Evolutionary Algorithm to Learn SPARQL Queries for Source-Target-Pairs: Finding Patterns for Human Associations in DBpedia
Efficient usage of the knowledge provided by the Linked Data community is often hindered by the need for domain experts to formulate the right SPARQL queries to answer questions. For new questions they have to decide which datasets are suitable and i…
Authors: J"orn Hees, Rouven Bauer, Joachim Folz
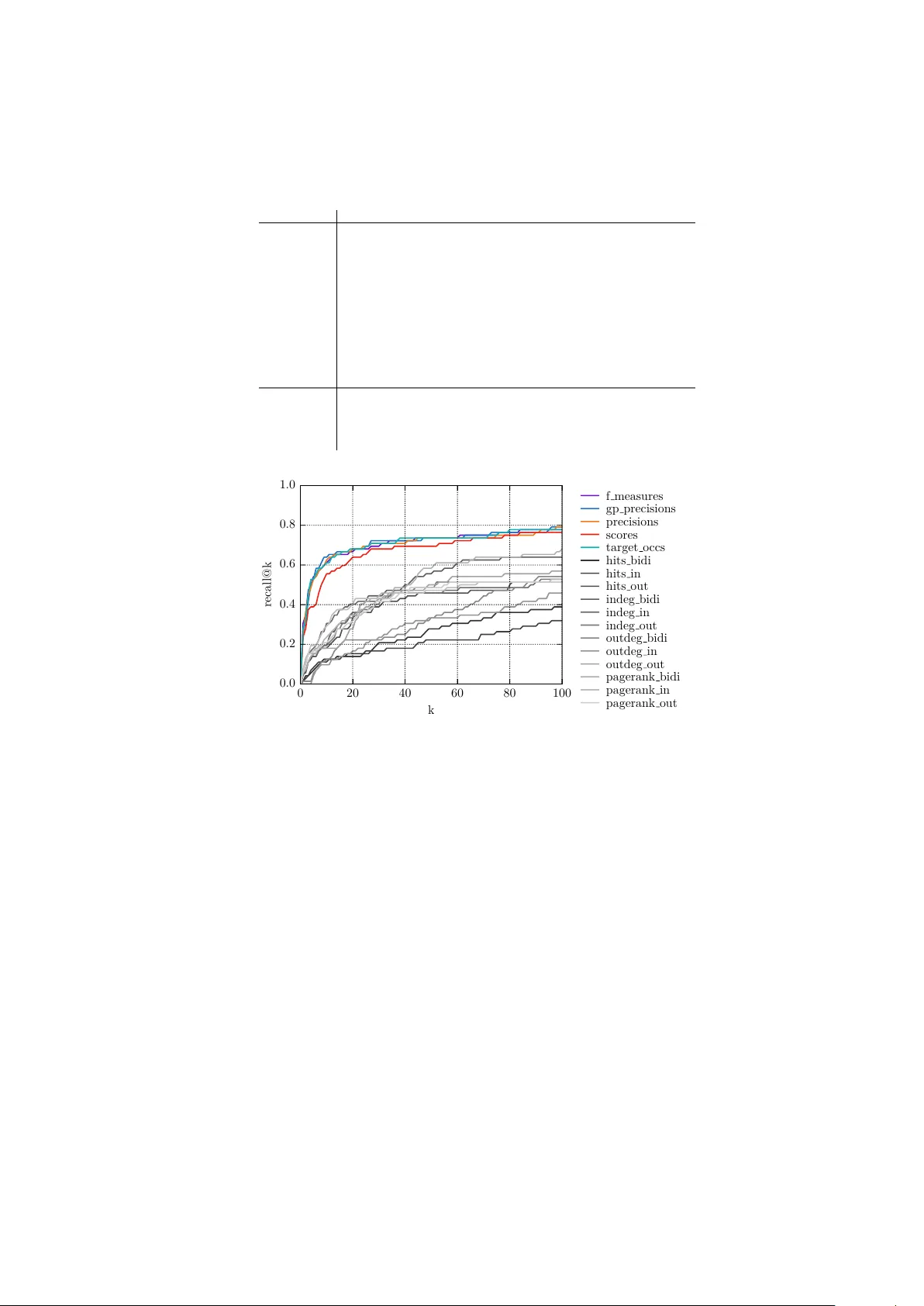
An Ev olutionary Algorithm to Learn SP AR QL Queries for Source-T arget-P airs Finding P atterns for Human Asso ciations in DBp edia Jörn Hees, Rouv en Bauer, Joachim F olz, Damian Borth, and Andreas Dengel 1 Computer Science Departmen t, Universit y of Kaiserslautern, Germany 2 Kno wledge Management Departmen t, DFKI GmbH, Kaiserslautern, German y {firstname.lastname} @dfki.de Abstract. Efficien t usage of the knowledge provided by the Linked Data comm unity is often hindered b y the need for domain exp erts to form ulate the right SP AR QL queries to answer questions. F or new questions they ha ve to decide which datasets are suitable and in which terminology and mo delling st yle to phrase the SP ARQL query . In this w ork we present an evolutionary algorithm to help with this chal- lenging task. Giv en a training list of source-target no de-pair examples our algorithm can learn patterns (SP ARQL queries) from a SP AR QL endp oin t. The learned patterns can be visualised to form the basis for further inv estigation, or they can b e used to predict target no des for new source no des. Amongst others, w e apply our algorithm to a dataset of several hundred h uman asso ciations (suc h as “circle - square”) to find patterns for them in DBp edia. W e show the scalability of the algorithm by running it against a SP AR QL endp oin t loaded with > 7 . 9 billion triples. F urther, w e use the resulting SP AR QL queries to mimic human associations with a Mean A v erage Precision (MAP) of 39 . 9% and a Recall @10 of 63 . 9% . 1 In tro duction The Seman tic W eb [1] and its Link ed Data [2] mo vemen t hav e brough t us many great, interlink ed and freely a v ailable machine readable RDF [13] datasets, often summarized in the Linking Op en Data Cloud 3 . Being extracted from Wikip edia and spanning many different domains, DBp edia [3] forms one of the most cen tral and b est interlink ed of these datasets. Nev ertheless, even with all this easily a v ailable data, using it is still very c hallenging: F or a new question, one needs to kno w about the av ailable datasets, whic h ones are b est suited to answer the question, kno w ab out the wa y kno wledge is mo delled inside them and which vocabularies are used, b efore ev en attempting to formulate a suitable SP ARQL 4 query to return the desired information. The noise of real w orld datasets adds even more complexity to this. 3 http://lod- cloud.net/ 4 https://www.w3.org/TR/rdf- sparql- query/ In this pap er w e presen t a graph pattern learning algorithm that can help to identify SP AR QL queries for a relation R b et ween node pairs ( s, t ) ∈ R in a giv en knowledge graph G 5 , where s is a source node and t a target no de. R can for example be a simple relation suc h as “given a capital s return its country t ” R cc or a complex one such as “given a stim ulus s return a resp onse t that a h uman would asso ciate” R ha . T o learn queries for R from G , without any prior kno wledge ab out the mod- elling of R in G , w e allow users to compile a ground truth set of example source-target-pairs G T ⊆ R as input for our algorithm. F or example, for re- lation R cc b et w een capital cities and their countries, the user could generate a ground truth list G T = { ( dbr:Berlin , dbr:Germany ), ( dbr:Paris , dbr:France ), ( dbr:Oslo , dbr:Norway ) } . Given G T and the DBp edia SP ARQL endp oin t 6 , our graph pattern learner then learns a set of graph patterns g pl ( G T , G ) such as: g p 1 : { ?source dbo:country ?target } g p 2 : { ?target dbo:capital ?source. ?target a dbo:Country } In this pap er, a graph pattern g p ∈ g pl ( G T , G ) ⊂ GP is an instance of the infinite set of SP ARQL basic graph patterns 7 GP . Eac h g p has a corresp onding SP ARQL ASK and SELECT query . W e denote their execution against G as ASK( g p ) and SELECT( gp ) . The graph patterns can contain SP ARQL v ariables, out of whic h we reserve ?source and ?target as sp ecial ones. A mapping Φ can be used to bind v ariables in g p b efore execution. The resulting learned patterns can either b e insp ected or b e used to predict targets b y selecting all bindings for ?target given a source no de s i : prediction g p ( s i ) = SELECT ? targ et ( φ ? source : = s i ( g p )) F or example, giv en the source no de dbr:London the pattern g p 1 can be used to predict dbr:United_Kingdom ∈ prediction g p 1 ( dbr:London ) . The remainder of this pap er is structured as follows: W e present related work in Section 2, b efore describing our graph pattern learner in detail in Section 3. In Sections 4 and 5 we will then briefly describ e visualisation and prediction tec hniques b efore ev aluating our approach in Section 6. 2 Related W ork T o the best of our knowledge, our algorithm is the first of its kind. It is unique in that it can learn a set of SP ARQL graph patterns for a given input list of source-target-pairs directly from a given SP ARQL endp oin t. A dditionally , it can cop e with scenarios in which there is not a single pattern that cov ers all source- target-pairs. 5 F or our purp ose G is a set of RDF triples, typically accessible via a given SP ARQL endp oin t. 6 http://dbpedia.org/sparql 7 https://www.w3.org/TR/sparql11- query/#BasicGraphPatterns Man y other algorithms exist, which learn vector space represen tations from kno wledge graphs. An excellent ov erview of such algorithms can b e found in [17]. W e are how ever not aw are that any of these algorithms hav e the ability of returning a list of SP ARQL graph patterns that cov er an input list of source- target-pairs. There are other approac hes that help form ulating SP AR QL queries, mostly in an in teractiv e fashion such as RelFinder [10,11] or AutoSP ARQL [15]. Their fo cus ho wev er lies on finding relationships b et ween a short list of en tities (not source-target-pairs) or interactiv ely form ulating SP ARQL queries for a list of en tities of a single kind. They cannot deal with entities of different kinds. W rt. SP AR QL pattern learning, there is an approac h for pattern based fea- ture construction [14] that focuses on learning SP ARQL patterns to use them as features for binary classification of en tities. It can answer questions such as: does an en tity belong to a predefined class? In con trast to that, our approac h fo cuses on learning patterns b et ween a list of source-target-pairs for en tit y prediction: giv en a source en tit y predict target en tities. T o sim ulate target en tity prediction for a single given source with binary classification, one would need to train n classifiers, one for n p oten tial target en tities. In the con text of mining patterns for h uman associations and Linked Data, w e previously fo cused on collecting datasets of semantic asso ciations directly from humans [9,6], ranking existing facts according to asso ciation strengths [7,8] and mapping the Edinburgh Asso ciative Thesaurus [12] to DBp edia [5]. None of these previous works directly fo cused on identifying existing patterns for h uman asso ciations in existing datasets. 3 Ev olutionary Graph P attern Learner The outline of our graph pattern learner is similar to the generic outline of ev olutionary algorithms: It consists of individuals (in our case SP ARQL graph patterns g p i ∈ GP ), which are ev aluated to calculate their fitness. The fitter an individual is, the higher its chance to survive and reac h the next generation. The individuals of a generation are also referred to as p opulation. In each generation there is a chance to mate and m utate for each of the individuals. A p opulation can contain the same individual (graph pattern) sev eral times, causing fitter individuals to hav e a higher chance to mate and mutate o ver sev eral generations. As mentioned in the introduction, the training input of our algorithm is a list of ground truth source-target-pairs g tp i = ( s i , t i ) ∈ G T . Due to size limitations, w e will fo cus on the most important aspects of our algorithm in the following. F or further detail please see our website 8 where you can find the source-co de, visualisation and other complementary material. 8 https://w3id.org/associations 3.1 Co verage Before describing the realisation of the comp onen ts of our evolutionary learner, w e wan t to introduce our concept of cov erage. W e sa y that a graph pattern g p i co vers, models or fulfils a source-target-pair ( s j , t j ) if the ev aluation of its SP ARQL ASK query returns true: ASK( φ ?source : = s i , ?target : = t i ( g p )) Our algorithm is not limited to learning a single best pattern for a list of ground truth pairs, but it can learn multiple patterns which together cov er the list. W e realise this by inv oking our ev olutionary algorithm in sev eral runs . In eac h run a full evolutionary algorithm is executed (with all its generations). After each run the resulting patterns are added to a global list of results. In the follo wing runs, all ground truth pairs whic h are already cov ered by the patterns from previous runs b ecome less rewarding for a newly learnt pattern to co ver. Ov er its runs our algorithm will thereby re-fo cus on the left-ov ers, which allows us to maximise the cov erage of all ground truth pairs with go o d graph patterns. 3.2 Fitness In order to ev aluate the fitness of a pattern, we define the following dimensions to capture what mak es a pattern “go o d”. – High r e c al l : A go od pattern fulfils as many of the giv en ground truth pairs G T as p ossible: gt_matc hes g p = |{ ( s i , t i ) ∈ G T | ASK( φ ? source : = s i , ? targ et : = t i ( g p )) }| recall g p = gt_matc hes g p |G T | – High pr e cision : A go o d pattern should also b e precise. F or each individual ground truth pair ( s i , t i ) ∈ G T w e can define the precision as: precision g p (( s i , t i )) = |{ t i | t i ∈ prediction g p ( s i ) }| | prediction g p ( s i ) | The target t i should b e in the returned result list and if p ossible nothing else. In other w ords, w e are not searching for patterns that return thousands of p oten tially wrong target for a given source. Over all ground truth pairs, we can define the a v erage precision for g p via the inv erse of the a verage result lengths: a vg result length g p = avg ( s i ,t i ) | prediction g p ( s i ) | precision g p = ( avg result length g p ) − 1 – High gain : A pattern discov ered in run r is b etter if it cov ers those ground truth pairs g tp ∈ G T that aren’t cov ered with high precisions in previous runs ( g p 0 ∈ r un q ) already: gain run r ,g p = X g tp max { 0 , precision g p ( g tp ) − max ∀ q 2 (cf. Section 3.2). Notable Learned Graph P atterns Due to the page limit, we will briefly men tion only 3 notable patterns from the resulting learned patterns in this pap er. W e in vite the reader to explore the full results online 12 with the in teractive visualisation presen ted in Section 4. The three notable patterns we w an t to presen t here are: { ?source gold:hypernym ?target } { ?source dbo:wikiPageWikiLink ?target. ?target dbo:wikiPageWikiLink ?source } { ?source dbo:wikiPageWikiLink ?target. ?v0 skos:exactMatch ?v1. ?v1 dbprop:industry ?target } The first tw o are in tuitively understandable patterns whic h typically are amongst the top patterns. The first one shows that human asso ciations often seem to b e represented via gold:hypernym in DBp edia (the resp onse is often a hy- p ern ym (broader term) for the stim ulus). The second one shows that asso ciations often corresp ond to bidirectionally linked Wikip edia articles. The third pattern 11 The full dataset is av ailable at https://w3id.org/associations . 12 https://w3id.org/associations represen ts a whole class of intra-dataset learning by making use of a connection of the ?target to Bab elNet’s skos:exactMatch . Prediction & F usion Strategies Ev aluation As h uman asso ciations are not readily mo delled in DBp edia, it is difficult to assess the quality of the learned patterns g p directly . Hence, we ev aluate the qualit y indirectly via their prediction qualit y on the test-set G T test . F or each of the ( s t , t t ) ∈ G T test w e generate a ranked target list r tpl s t = [ tp 1 , . . . , tp n ] of target predictions tp i . The list is the result of one of the fusion v arian ts (cf. Section 5.2) after clustering (cf. Section 5.1). F or ev aluation, w e can then chec k the rank r t of t t in r tpl s t (lo wer ranks are b etter). If t t / ∈ r tpl s t , we set r t = ∞ . An example of a ranked target prediction list (for the fusion metho d pr e ci- sions ) for source s t = dbr:Sled is the ranked list: r tpl dbr:Sled = [ dbr:Snow , dbr:Christmas , dbr:Deer , dbr:Kite , dbr:Transport , dbr:Donkey , dbr:Ice , dbr:Ox , dbr:Obelisk , dbr:Santa_Claus ]. In this case the ground truth target t t = dbr:Snow is at rank r t = 1 . As we can see most of the results are relev an t as asso ciations to humans. Nevertheless, for the purp ose of our ev aluation, we will only consider the single t t corresp onding to a s t as relev an t and all other tp i as irrelev an t. Based on the ranked result lists, we can calculate the Recall@k 13 , Mean A verage Precision (MAP) and Normalised Discounted Cumulativ e Gain of the v arious fusion v arian ts ov er the whole test set G T test , as can b e seen in T able 1 and Figure 2. W e also calculate these metrics for sev eral baselines, which try to predict the target no des from the 1-neighbourho o d (bidirectionally , incoming or outgoing) b y selecting the neighbour with the highest PageRank, HITS score, in- and out- degree [18,19]. As can b e seen, all our fusion strategies significantly outp erform the baselines. 7 Conclusion & Outlo ok In this pap er we presented an evolutionary graph pattern learner. The algorithm can successfully learn a set of patterns for a giv en list of source-target-pairs from a SP ARQL endp oin t. The learned patterns can b e used to predict targets for a giv en source. W e use our algorithm to identify patterns in DBpedia for a dataset of human asso ciations. The prediction quality of the learned patterns after fusion reaches a Recall @ 10 of 63.9 % and MAP of 39.9 %, and significantly outperforms Page- Rank, HITS and degree based baselines. The algorithm, the used datasets and the interactiv e visualisation of the results are a v ailable online 14 . In the future, w e plan to enhance our algorithm to support Literals in the input source-target-pairs, whic h will allo w us to learn patterns directly from 13 W e don’t pro vide Precision@k, as it degenerates to Recall@k /k due to the fact that w e only hav e 1 relev ant target per result of any ( s t , t t ) . 14 https://w3id.org/associations T able 1. Recall@k, MAP and NDCG for our fusion v arian ts and against baselines. Recall@1 Recall@2 Recall@3 Recall@4 Recall@5 Recall@10 MAP NDCG outdeg in 0.000 0.000 0.000 0.000 0.042 0.097 0.029 0.105 outdeg out 0.069 0.125 0.153 0.153 0.167 0.181 0.126 0.209 outdeg bidi 0.014 0.014 0.014 0.014 0.056 0.125 0.045 0.131 indeg in 0.056 0.111 0.153 0.167 0.181 0.306 0.129 0.207 indeg out 0.056 0.125 0.153 0.153 0.153 0.194 0.121 0.200 indeg bidi 0.042 0.069 0.111 0.139 0.139 0.194 0.104 0.205 pagerank in 0.069 0.125 0.153 0.194 0.194 0.292 0.140 0.219 pagerank out 0.056 0.097 0.153 0.153 0.167 0.208 0.117 0.195 pagerank bidi 0.056 0.069 0.111 0.139 0.153 0.236 0.113 0.219 hits in 0.014 0.028 0.042 0.069 0.083 0.111 0.046 0.095 hits out 0.056 0.056 0.111 0.125 0.153 0.181 0.102 0.181 hits bidi 0.014 0.042 0.042 0.056 0.069 0.125 0.050 0.110 scores 0.236 0.278 0.375 0.389 0.389 0.556 0.323 0.413 gp precisions 0.250 0.319 0.417 0.500 0.528 0.639 0.365 0.457 precisions 0.250 0.361 0.444 0.486 0.528 0.625 0.371 0.460 target o ccs 0.278 0.319 0.458 0.528 0.528 0.611 0.381 0.466 f measures 0.306 0.347 0.472 0.500 0.542 0.611 0.399 0.479 0 20 40 60 80 100 k 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 recall@k f measures gp precisions precisions scores target o ccs hits bidi hits in hits out indeg bidi indeg in indeg out outdeg bidi outdeg in outdeg out pagerank bidi pagerank in pagerank out Fig. 2. Recall @ k ov er the different fusion v arian ts and against baselines. lists of textual inputs. F urther, w e are inv estigating m utations, for example to in tro duce FILTER constrain ts. W e also plan to inv estigate the effects of including negativ e samples (curren tly we only use p ositiv e samples and treat ev erything else as negativ e). A dditionally , we plan to employ more adv anced late fusion techniques, in order to learn when to trust the prediction of which pattern. As this idea is conceptually close to interpreting the learned patterns as a feature vector (with understandable and executable patterns to generate target candidates), w e plan to inv estigate com binations of our algorithm with approaches that learn vector space represen tations from knowledge graphs. This work was supp orted b y the Universit y of Kaiserslautern CS PhD schol- arship program and the BMBF pro ject MOM (Grant 01IW15002). References 1. Berners-Lee, T., Hendler, J., Lassila, O.: The Semantic W eb Scientific American 284(5), 34–43 (2001) 2. Bizer, C., Heath, T., Berners-Lee, T.: Linked Data - The Story So F ar. In ternational Journal on Semantic W eb and Information Systems 5(3), 1–22 (2009) 3. Bizer, C., Lehmann, J., Kobilaro v, G., Auer, S., Beck er, C., Cyganiak, R., Hell- mann, S.: DBpedia - A crystallization p oin t for the W eb of Data. W eb Semantics: Science, Services and Agents on the W orld Wide W eb 7(3), 154–165 (2009) 4. F ortin, F.A., De Rain ville, F.M., Gardner, M.A., Parizeau, M., Gagné, C.: DEAP: Ev olutionary Algorithms Made Easy. Journal of Mac hine Learning Research 13, 2171–2175 (2012) 5. Hees, J., Bauer, R., F olz, J., Borth, D., Dengel, A.: Edinburgh Asso ciativ e The- saurus as RDF and DBpedia Mapping. The Seman tic W eb: In: ESWC SE. Springer, Heraklion, Crete, Greece (2016) 6. Hees, J., Khamis, M., Biedert, R., Ab dennadher, S., Dengel, A.: Collecting Links b et w een Entities Ranked by Human Asso ciation Strengths. In: ESWC. v ol. 7882, pp. 517–531. Springer LNCS, Montpellier, F rance (2013), 7. Hees, J., Roth-b erghofer, T., Biedert, R., Adrian, B., Dengel, A.: BetterRelations: Using a Game to Rate Linked Data T riples. In: KI 2011: Adv ances in Artificial In telligence. pp. 134–138. Springer (2011) 8. Hees, J., Roth-Berghofer, T., Biedert, R., Adrian, B., Dengel, A.: BetterRelations: Collecting Association Strengths for Linked Data T riples with a Game. In: Search Computing, v ol. 7538, pp. 223–239. Springer LNCS (2012) 9. Hees, J., Roth-Berghofer, T., Dengel, A.: Link ed Data Games: Simulating Human Asso ciation with Link ed Data. In: L W A. pp. 255–260. Kassel, Germany (2010) 10. Heim, P ., Hellmann, S., Lehmann, J., Lohmann, S., Stegemann, T.: RelFinder: Rev ealing Relationships in RDF Kno wledge Bases. In: SAMT 2009. LNCS, vol. 5887, pp. 182–187. Springer, Graz, Austria (2009) 11. Heim, P ., Lohmann, S., Stegemann, T.: Interactiv e Relationship Discov ery via the Seman tic W eb. In: ESW C 2010. LNCS, pp. 303–317. Springer, Heraklion, Greece 12. Kiss, G.R., Armstrong, C., Milroy , R., Piper, J.: An asso ciative thesaurus of English and its computer analysis. In: The Computer and Literary Studies, pp. 153–165. Edin burgh Universit y Press, Edinburgh, UK (1973) 13. Klyne, G., Carroll, J.J.: Resource Description F ramework (RDF): Concepts and Abstract Syn tax (2004), http://www.w3.org/TR/rdf- concepts/ 14. L a wrynowicz, A., Potoniec, J.: Pattern based feature construction in semantic data mining. Int. J. on Sem W eb and Information Systems (IJSWIS) 10(1), 27–65 (2014) 15. Lehmann, J., Bühmann, L.: AutoSP AR QL: Let users query your kno wledge base. In: ESW C. LNCS, v ol. 6643, pp. 63–79. Springer, Heraklion, Crete, Greece (2011) 16. McCusk er, J.P .: W ebSig: A Digital Signature F ramework for the W eb. Ph.D. thesis, Rensselaer P olytechnic Institute, T roy , NY (2015) 17. Nic kel, M., Murphy , K., T resp, V., Gabrilovic h, E.: A Review of Relational Machine Learning for Kno wledge Graphs pp. 1–23 (2015) 18. Reddy , D., Kn uth, M., Sac k, H.: DBpedia GraphMeasures (2014), http:// semanticmultimedia.org/node/6 19. Thalhammer, A., Rettinger, A.: P ageRank on Wikip edia: T o wards General Imp or- tance Scores for Entities. In: Know@LOD&CoDeS 2016. CEUR-WS Proceedings.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment