Inverse Reinforcement Learning in Swarm Systems
Inverse reinforcement learning (IRL) has become a useful tool for learning behavioral models from demonstration data. However, IRL remains mostly unexplored for multi-agent systems. In this paper, we show how the principle of IRL can be extended to h…
Authors: Adrian v{S}ov{s}ic, Wasiur R. KhudaBukhsh, Abdelhak M. Zoubir
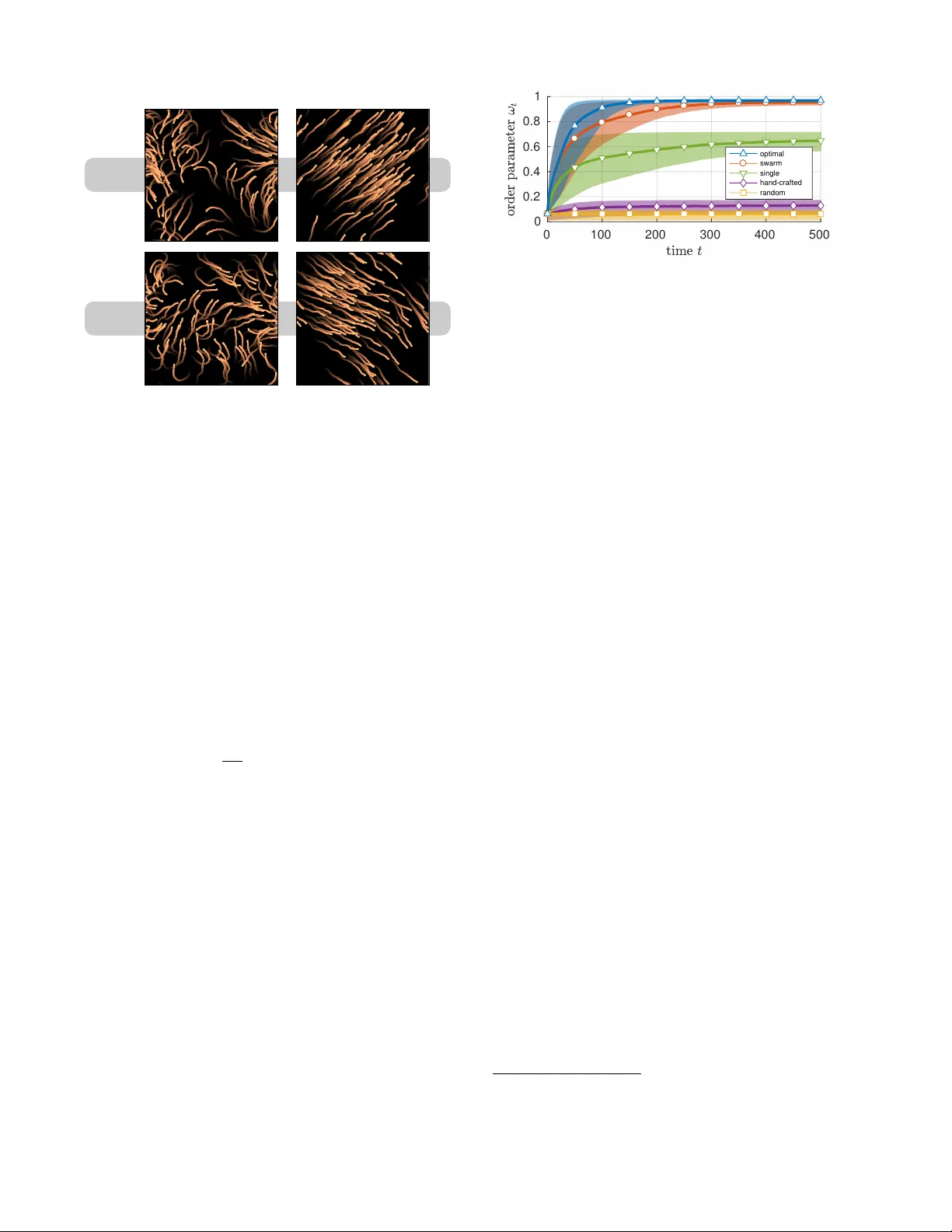
In ver se Reinf or cement Learning in Swarm Systems Adrian Šoši ´ c, W asiur R. KhudaBukhsh, Abdelhak M. Zoubir and Heinz K oeppl Depar tment of Electr ical Engineering and Information T echnology T echnische Univ ersität Dar mstadt, Germany ABSTRA CT In v erse reinforcemen t learning (IRL) has become a useful tool for lea rning beha vioral m o dels from demonstration data. Ho w ever, IRL remains mostly unexplored for m ulti-agen t systems. In this paper, we show how the principle of IRL can be extended to homogeneous large-scale problems, in- spired b y the collectiv e sw arming behavior of natural sys- tems. In particular, w e make the following con tributions to the field: 1) W e introduce the swarMDP framework, a sub- class of decentralized partially observ able Marko v decision processes endo w ed with a swarm c haracterization. 2) Ex- ploiting the inherent homogeneity of this framework, we re- duce the resulting m ulti-agen t IRL problem to a single-agen t one b y pro ving that the agen t-specific v alue functions in thi s model coincide. 3) T o solv e the corresp onding control prob- lem, we prop ose a no vel heterogeneous learning sc heme that is particularly tailored to the swarm setting. Results on tw o example systems demonstrate that our framew ork is able to produce meaningful lo cal reward mo dels from whic h w e can replicate the observ ed global system dynamics. K eywords in v erse reinforcemen t learning; m ulti-agen t systems; sw arms 1. INTR ODUCTION Emergence and the ability of self-organization are fascinat- ing characteristics of natural systems with interact ing agents. Without a central con troller, these systems are inherently robust to failure while, at the same time, they sho w remark- able large-scale dynamics that allow for fast adaptation to c hanging environmen ts [5, 6]. In terestingly , for large system sizes, it is often not the complexit y of the individual agen t, but the (lo cal) coupling of the agents that predominantl y gears the final system dynamics. It has b een show n [22, 31], in fact, that even relativ ely simple local dynamics can re- sult in v arious kinds of higher-order complexity at a global scale when coupled through a net w ork with many agents. Unfortunately , the complex relationship betw een the global behavior of a system and its lo cal implemen tation at the agen t level is not well understo od. In particular, it remains unclear when – and how – a global system ob jective can b e Appears in: Pro c. of the 16th International Conferenc e on Autonomous A gents and Multiagent Systems (AAMAS 2017), S. Das, E. Durfe e, K. L arson, M. Winikoff (eds.), May 8–12, 2017, S˜ ao Paulo, Brazil . Copyrigh t c 2017, Internat ional F oundation for Autonomous Agents and Multiagent Systems (www.ifaamas.org). All rights reserved. encoded in terms of lo cal rules, and what are the require- men ts on the complexit y of the individual agent in order for the collective to fulfill a certain task. Y et, this under- standing is key to man y of to da y’s and future applications, suc h as distributed sensor netw orks [13], nanomedicine [8], programmable matter [9], and self-assem bly systems [33]. A promising concept to fill this missing link is inv erse re- inforcemen t learning (IRL), whic h provides a data-driven framew ork for learning b eha vioral models from exp ert sys- tems [34]. In the past, IRL has b een applied successfully in many disciplines and the learned mo dels were rep orted to ev en outp erform the exp ert system in sev eral cases [1, 16, 27]. Unfortunately , IRL is mostly unexplored for multi- agen t systems; in fact, there exist only few mo dels which transfer the concept of IRL to systems with more than one agen t. One such example is the work presented in [ 18], where the authors extended the IRL principle to non-co operative m ulti-agen t problems in order to learn a joint reward mo del that is able to explain the system b eha vior at a global scale. Ho w ever, the authors assume that all agents in the netw ork are contro lled by a central mediator, an assumption which is clearly inappropriate for self-organizing systems. A de- cen tralized solution was later presented in [25] but the pro- posed algorithm is based on the simplifying assumption tha t all agents are informed about the global state of the system. Finally , the authors of [7] presen ted a m ulti-agen t framew ork based on mechani sm design, which can be used to refine a giv en reward mo del in order to promote a certain system behavior. Ho w ever, the framework is not able to learn the rew ard structure en tirely from demonstration data. In contrast to previous work on m ulti-agen t IRL, w e do not aspire to find a general solution for the entire class of m ulti-agen t systems; instead, w e fo cus on the important sub- class of homogeneous systems or swarms . Motiv ated by the abov e-men tioned questions, w e present a scalable IRL so- lution for the sw arm setting to learn a single lo c al reward function which explains the glob al behavior of a swarm, and whic h can be used to reconstruct this b eha vior from local in- teractions at the agent level. In particular, w e make the fol- lo wing con tributions: 1) W e introduce the swarMDP , a for- mal framework to compactly describe homogeneous multi- agen t con trol problems. 2) Exploiting the inheren t homo- geneit y of this framew ork, we show that the resulting IRL problem can b e effectiv ely reduced to the single-agent case. 3) T o solve the corresp onding control problem, we prop ose a no v el heterogeneous learning scheme that is particularly tailored to the swarm setting. W e ev aluate our framew ork on tw o well-kno wn system mo dels: the Ising mo del and the Vicsek mo del of self-propelled particles. The results demon- strate that our framework is able to pro duce meaningful re- w ard mo dels from which we can learn lo cal controllers that replicate the observ ed global system dynamics. 2. THE SW ARMDP MODEL By analogy with the characteristics of natural systems, w e c haracterize a swarm system as a collection of agents with the following tw o properties: Homogeneit y: All agen ts in a swarm share a com- mon architecture (i.e. they ha v e the same dynamics, degrees of freedom and observ ation capabilities). As suc h, they are assumed to b e interc hangeable. Lo calit y: The agents can observe only parts of the system within a certain range, as determined by their observ ation capabilities. As a consequence, their deci- sions depend on their current neigh borho od only and not on the whole swarm state. In principle, an y system with these prop erties can be de- scribed as a decentralized partially observ able Mark o v deci- sion pro cess (Dec-POMDP) [21]. Ho w ever, the homogene- it y property , which turns out to be the key ingredien t for scalable inference, is not explicitly captured b y this mo del. Since the n umber of agen ts con tained in a sw arm is t ypically large, it is thus conv enient to switch to a more compact sys- tem representation that exploits the system symmetries. F or this reason, we introduce a new sub-class of Dec- POMDP models, in the following referred to as swarMDPs (Fig. 1), which explicitly implement s a homogeneous agent arc hitecture. An agen t in this model, whic h w e call a swarm- ing agent , is defined as a tuple A : = ( S , O , A , R, π ), where: • S , O , A are sets of lo cal states, observ ations and ac- tions, resp ectiv ely . • R : O → R is an agent-lev el reward function. • π : O → A is the lo cal p olicy of the agent which later serv es as the decentralized control la w of the swarm. F or the sake of simplicit y , we consider only reactiv e p olicies in this pap er, where π is a function of the agent’s current observ ation. Note, how ev er, that the extension to more gen- eral p olicy mo dels (e.g. b elief state policies [11] or such that operate on observ ation histories [21]) is straightforw ard. With the definition of the swarming agen t at hand, we define a swa rMDP as a tuple ( N , A , T , ξ ), where: • N is the num b er of agents in the system. • A is a swarming agent protot ype as defined ab o ve. • T : S N × A N × S N → R is the global transition model of the system. Although T is used only implicitly later on, w e can access the conditional probabili ty that the system reaches state ˜ s = ( ˜ s (1) , . . . , ˜ s ( N ) ) when the agen ts p erform the join t action a = ( a (1) , . . . , a ( N ) ) at state s = ( s (1) , . . . , s ( N ) ) as T ( ˜ s | s, a ), where s ( n ) , ˜ s ( n ) ∈ S and a ( n ) ∈ A represen t the lo cal states and the lo cal action of agent n , resp ectiv ely . • ξ : S N → O N is the observ ation mo del of the system. s t s t +1 o ( n ) t o ( n ) t +1 a ( n ) t a ( n ) t +1 r ( n ) t r ( n ) t +1 N N T ξ ( n ) ξ ( n ) π π R R Figure 1: The sw arMDP mo del visualized as a Bay esian net w ork using plate notation. In con trast to a Dec-POMDP , the mo del explicitly enco des the homogeneit y of a swarm. The observ ation mo del ξ tells us which parts of a given sys- tem state s ∈ S N can be observed b y whom. More precisely , ξ ( s ) = ( ξ (1) ( s ) , . . . , ξ ( N ) ( s )) ∈ O N denotes the ordered set of lo cal observ ations passed on to the agents at state s . F or example, in a sc hool of fish, ξ ( n ) could be the local alignmen t of a fish to its immediate neighbors (see Section 4.1). Note that the agen ts hav e no access to their lo cal states s ( n ) ∈ S but only to their lo cal observ ations o ( n ) = ξ ( n ) ( s ) ∈ O . It should be men tioned that the observ ation model can be also defined lo cally at the agen t level, since the observ a- tions are agent-related quan tities. How ev er, this would still require a global notion of connectivity b et w een the agents , e.g. pro vided in the form of a dynamic graph whic h defines the time-v arying neigh borho od of the agen ts. Using a global observ ation model, we can enco de all prop erties in a single ob ject, yielding a more compact system description. Y et, w e need to constrain our mo del class to those mo dels which respect the homogeneit y (and t hu s the in terc hangeabilit y) of the agen ts. T o be precise, a v alid observ ation model needs to ensure that agent n receives agen t m ’s local observ ation (and vice v ersa) if w e in terc hange their lo cal states. Mathemati- cally , this means that an y permutation of s ∈ S N m ust result in the same permutation of ξ ( s ) – otherwise, the underlying system is not homogeneous. The same property has to hold for the transition model T . A generalization to sto c hastic observ ations is p ossible but not considered in this paper. 3. IRL IN SW ARM SYSTEMS In contrast to existing w ork on IRL, our goal is not to de- v elop a new specialized algorithm that solves the IRL prob- lem in the swarm case. On the contrary , we sho w that the homogeneit y of our mo del allo ws us to reduce the mu lti- agen t IRL problem to a single-agent one, for whic h we can apply a whole class of existing algorithms. This is p ossible since, at its heart, the underlying control problem of the sw arMDP is intrinsicall y a single-agent problem b ecause all agen ts share the same policy . 1 In the subsequent sections, w e show that this symmetry prop ert y also translates to the v alue functions of the agen ts. Algorithmically , w e exploit the fact that most existing IRL methods, suc h as [2, 19, 20, 24, 29, 35], share a common generic form (Algorithm 1), whic h in v olv es three main steps [17]: 1) p olicy up date 2) v alue estimation and 3) reward update. The important detail to 1 How ev er, the decentralized nature of the problem remains! note is that only the first t w o steps of this pro cedure are system-specific while the third step is, in fact, indep enden t of the target system (see references listed ab o ve for details). Consequen tly , our problem reduces to finding swarm-based solutions for the first tw o steps such that the ov erall pro ce- dure returns a “meaningful” rew ard mo del in the IRL con- text. The follo wing sections discuss these steps in detail. Algorithm 1: Generic IRL Input: exp ert data D , MDP without reward function 0: Initialize rew ard function R { 0 } for i = 0 , 1 , 2 , ... 1: P olicy up date: Find optimal policy π { i } for R { i } 2: V alue estimation: Compute corresp onding v alue V { i } 3: Rew ard up date: Giv en V { i } and D , compute R { i +1 } 3.1 Policy Update W e start with the p olicy up date step, where w e are faced with the problem of learning a suitable system p olicy for a giv en reward function. F or this purpose, we first need to define a suitable learning ob jectiv e for the sw arm setting in the context of the IRL pro cedure. In the next paragraphs, w e show that the homogeneity property of our mo del natu- rally induces such a learning ob jective, and w e furthermore presen t a simple l earning strategy to optimize this ob jectiv e. 3.1.1 Private V alue & Bellman Optimality Analogous to the single-agen t case [28], w e define the private value of an agent n at a swarm state s ∈ S N under p olicy π as the exp ected sum of discoun ted rewards accumulated by the agent ov er time, given that all agents execute π , V ( n ) ( s | π ) : = E " ∞ X k =0 γ k R ( ξ ( n ) ( s t + k )) | π , s t = s # , (1) Herein, γ ∈ [0 , 1) is a discount factor, and the exp ectation is with resp ect to the random system tra jectory starting from s . Note that, due to the assumed time-homogeneity of the transition mo del T , the ab o v e definition of v alue is, in fact, independen t of an y particular starting time t . Denoting further b y Q ( n ) ( s, a | π ) the state-action v alue of agent n at state s for the case that all agents execute p olicy π , except for agent n who performs action a ∈ A once and follo ws π thereafter, we obtain the following Bellman equations: V ( n ) ( s | π ) = R ( ξ ( n ) ( s )) + γ X ˜ s ∈S N P (˜ s | s, π ) V ( n ) ( ˜ s | π ) , Q ( n ) ( s, a | π ) = R ( ξ ( n ) ( s )) + γ X ˜ s ∈S N P ( n ) ( ˜ s | s, a, π ) V ( n ) ( ˜ s | π ) . Here, P ( ˜ s | s, π ) denotes the probabilit y of reaching swarm state ˜ s from s when every agent performs policy π and, anal- ogously , P ( n ) ( ˜ s | s, a, π ) denotes the probabilit y of reaching sw arm state ˜ s from state s if agen t n chooses action a and al l other agents execute p olicy π . Note that b oth these ob jects are implicitly defined via the transition model T . 3.1.2 Local V alue Unfortunately , the v alue function in Eq. (1) is not lo cally plannable b y the agents since they hav e no access to the global sw arm state s . F rom a control p erspective, we thus require an alternativ e notion of optimality that is based on local i nformation only a nd, hence, computable by the agents . Analogous to the belief v alue in single-agent systems [1 4, 15], w e therefore introduce the follo wing lo c al value function , V ( n ) t ( o | π ) : = E P t ( s | o ( n ) = o,π ) h V ( n ) ( s | π ) i , whic h represents the expected return of agent n under con- sideration of its current local observ ation of the global sys- tem state. In our next prop osition, w e highlight tw o key properties of this quantit y: 1) It is not only lo cally plannable but also reduces the multi-agen t problem to a single-agent one in the sense that all lo cal v alues coincide. 2) In con- trast to the priv ate v alue, the lo cal v alue is time-dep enden t because the conditional probabilities P t ( s | o ( n ) = o, π ), in general, dep end on time. Ho we ver, it con verges to a station- ary v alue asymptotically under suitable conditions. Prop osition 1. Consider a swarMDP as define d ab ove and the sto chastic pr o c ess { S t } ∞ t =0 of the swarm state induc e d by the system p olicy π . If the initial state distribution of the system is invariant under p ermutation 2 of agents, al l lo c al value functions ar e identic al, V ( m ) t ( o | π ) = V ( n ) t ( o | π ) ∀ m, n. (2) In this c ase, we may drop the agent index and denote the c ommon lo c al value function as V t ( o | π ) . If, furthermor e, it holds that S t a.s. − − → S for some S with law P and the comm on lo cal value function is c ontinuous almost everywher e (i.e. its set of disc ontinuity p oints is P -nul l) and b ounde d ab ove, then the lo c al value function V t ( o | π ) wil l c onverge to a limit, V t ( o | π ) → V ( o | π ) , (3) wher e V ( o | π ) = E P ( s | o ( n ) = o,π ) h V ( n ) ( s | π ) i . Pr oof. Fix an y tw o agents, say agent 1 and 2. F or these agen ts, define a p erm utation op eration σ : S N → S N as σ ( s ) : = ( s (2) , s (1) , s (3) , . . . , s ( N ) ) , where s = ( s (1) , s (2) , s (3) , . . . , s ( N ) ). Due to the homogene- it y of the system, i.e. since R ( ξ (1) ( s )) = R ( ξ (2) ( σ ( s ))) and P (˜ s | s, π ) = P ( σ ( ˜ s ) | σ ( s ) , π ), it follows immediately that V (1) ( s | π ) = V (2) ( σ ( s ) | π ) ∀ s . This essentially means: the v alue assigned to agen t 1 at sw arm st ate s is the same as the v alue that would be assigned to agen t 2 if we in terc hanged their lo cal states, i.e. at state σ ( s ). Note that this is effec- tiv ely the same as renaming the agen ts. The homogeneity of the system ensures that the symmetry of the initial state distribution P 0 ( s ) is main tained at all subsequent p oin ts in time, i.e. P t ( s | π ) = P t ( σ ( s ) | π ) ∀ s, t . In particular, it holds that P t ( s | o (1) = o, π ) = P t ( σ ( s ) | o (2) = o, π ) ∀ s, t and, accordingly , V (1) t ( o | π ) − V (2) t ( o | π ) = E P t ( s | o (1) = o,π ) h V (1) ( s | π ) i − E P t ( s | o (2) = o,π ) h V (2) ( s | π ) i = X s ∈S N P t ( s | o (1) = o, π ) V (1) ( s | π ) . . . . . . − P t ( σ ( s ) | o (2) = o, π ) V (2) ( σ ( s ) | π ) = 0 , 2 Since we assume that the agents are interc hangeable, it follows nat- urally to consider only p erm utation-in v ariant initial distributions. learning iterations Figure 2: Snapshots of the prop osed learning scheme applied to the Vicsek mo del (Section 4.1). The agents are divided in to a greedy set ( ) and an exploration set ( ) to facilitate the exploration of lo cally desynchronized sw arm states. The size of the exploration set is reduced ov er time to gradually transfer the system into a homogeneous stationary b eha vior. whic h shows that the local v alue functions are identi cal for all agen ts. T reating the v alue as a random v ariable and using the fact that it is con tin uous almost everywhere, it follows that V ( n ) ( S t | π ) a.s. − − → V ( n ) ( S | π ) since S t a.s. − − → S . As w e assume the function to b e finite, i.e. | V ( n ) ( S t | π ) | < V ∗ for some V ∗ ∈ R , it holds by conditional dominated con- v ergence theorem [4] that E h V ( n ) ( S t | π ) | o ( n ) = o, π i → E h V ( n ) ( S | π ) | o ( n ) = o, π i , i.e. V t ( o | π ) → V ( o | π ). 3.1.3 Heter ogeneous Q-learning With the lo cal v alue in Eq. (2 ), w e ha v e introduced a system- wide p erformance measure whic h can b e ev aluated at the agen t level and, hence, can b e used by the agen ts for lo cal planning. Y et, its computation inv olv es the ev aluation of an expectation with respect to the current swarm state of the system. This requires the agen ts to maintain a b elief ab out the global system state at an y p oin t in time to co ordinat e their actions, which itself is a hard problem. 3 Ho w ever, for man y swarm-related tasks (e.g. consensus problems [26]), it is sufficient to optimize the stationary b eha vior of the system. This is, in fact, a muc h easier task since it allows us to forget ab out the temporal asp ect of the problem. In this section, we present a comparably simple learning method, sp ecifically tailored to the sw arm setting, whic h solv es this task by optimizing the system’s stationary v alue in Eq. (3). Similar to the lo cal v alue function, we start b y defining a lo cal Q-function for each agent, Q ( n ) t ( o, a | π ) : = E P t ( s | o ( n ) = o,π ) h Q ( n ) ( s, a | π ) i , whic h assesses the qualit y of a particular action play ed b y agen t n at time t . F ollo wing the same line of argument as before, one can show that these Q-functions are again iden tical for all agen ts and, moreov er, that they conv erge to the following asymptotic v alue function, Q ( o, a | π ) = E P ( s | o ( n ) = o,π ) h Q ( n ) ( s, a | π ) i , (4) whic h can be understoo d as the state-action v alue of a generic agen t that is coupled to a stationary field generated by and executing p olicy π . In the followin g, we p ose the task of optimizing this Q-function as a game-theoretic one. T o b e 3 In principle, this is possible since – in con trast to a Dec-POMDP – each agent knows the p olicy of the other agents. precise, w e consider a hypothetical game b et w een eac h agen t and the environmen t surrounding it, where the agent pla ys the optimal response to this stationary field, π R ( o | π ) : = arg max a ∈A Q ( o, a | π ) , and the en vironmen t reacts with a new s warm behavior gen- erated by this p olicy . By definition, an y optimal system policy π ∗ describes a fixed-point of this game, π R ( o | π ∗ ) = π ∗ ( o ) , whic h motiv ates the following iterative learning scheme: Starting with an arbitrary initial p olicy , we run the sys- tem un til it reaches its stationary b eha vior and estimate the corresponding asymptotic Q-function. Based on this Q- function, we up date the system p olicy according to the best response operator defined ab o v e. The up dated p olicy , in turn, induces a new swarm behavior for which w e estimate a new Q-function, and so on. As so on as w e reach a fixed- point, the system has arrived at an optimal b eha vior in the form of a symmetric Nash equilibrium where all agents col- lectiv ely execute a p olicy which, for each agent individually , pro vides the optimal resp onse to the other agents’ b eha vior. Ho w ever, the following practical problems remain: 1) In general, it can b e time-consuming to wait for the system to reach its stationary b eha vior at each iteration of the al- gorithm. 2) At stationarity , w e need a wa y to estimate the corresponding stationary Q-function. Note that this inv olv es both estimating the Q-v alues of actions that are dictated b y the curren t policy as well as Q-v alues of actions that deviate from the current b eha vior, whic h requires a certain amount of exploratory mo v es. As a solution to b oth problems, w e propose the following heter o gene ous le arning scheme , whic h artificially breaks the symmetry of the system by separating the agents into tw o disjoin t groups: a greedy set and an ex- ploration set. While the agen ts in the greedy set provide a reference behavior in the form of the optimal response to the curren t Q-function shared betw een all agent s, the agents in the exploration set randomly explore the quality of different actions in the context of the curren t system p olicy . A t eac h iteration, the gathered experience of all agents is processed sequen tially via the following Q-up date [32], ˆ Q ( o ( n ) t , a ( n ) t ) ← (1 − α ) ˆ Q ( o ( n ) t , a ( n ) t )+ α r ( n ) t + γ max a ∈A ˆ Q ( o ( n ) t +1 , a ) , with learning rate α ∈ (0 , 1). Ov er time, more and more Q ( o, a | π ) π ( o ) n { o ( n ) t , a ( n ) t , r ( n ) t , o ( n ) t +1 } N n =1 o t (a) (b) (c) Figure 3: Pictorial description of the proposed learning sc heme. (a) The next p olicy is obtained from the current estimate of the system’s stationary Q-function. (b) Hetero- geneous one-step transition of the system. (c) The estimate of the Q-function is updated based on the new exp erience. Algorithm 2: Heterogeneous Q-Learning Input: swarMDP without p olicy π 0: Initialize shared Q-function, learning rate and fraction of exploring agen ts (called the temp erature) for i = 0 , 1 , 2 , ... 1: Separate the sw arm into exploring and greedy agents according to the current temp erature 2: Based on the current swarm state and Q-function, select actions for all agen ts 3: Iterate the system and collect rewards 4: Update the Q-function based on the new exp erience 5: Decrease the learning rate and the temperature exploring agents are assigned to the greedy set so that the system is gradually transferred into a homo gene ous station- ary regime and thereby smoothly guided to w ards a fixed- point policy (see Figure 2). Herein, the learning rate α nat- urally reduces the influence of exp erience acquired at early (non-sync hronized) stages of the system, which allows us to update the system p olicy without ha ving to wait until the sw arm conv erges to its stationary behavior. The heterogeneit y of the system during the l earning phase ensures that also lo cally desynchronized swarm states are w ell-explored (together with their local Q-v alues) so that the agen ts can learn adequate resp onses to out-of-equilibrium situations. This phenom enon is b est illustrated b y the agen t constellation in third sub-figure of Figure 2. It sho ws a situ- ation that is highly unlikely under a homogeneous learning sc heme as it requires a series of consecutiv e exploration steps b y only a few agen ts while all their neighbors need to b e- ha v e consisten tly optimally at the same time. The final pro- cedure, which can b e in terpreted as a mo del-free v arian t of policy iteration [12] in a non-stationary environme nt, is sum- marized in Algorithm 2, to gether with a pictorial description of the main steps in Fig. 3. While we cannot provide a con- v ergence proof at this stage, the algorithm conv erged in all our simulations and generated p olicies with a p erformance close to that of the exp ert system (see Section 4). 3.2 V alue Estimation In the last section, we hav e shown a wa y to implement the policy up date in Algorithm 1 based on lo cal information ac- quired at the agent level. Next, we need to assign a suitable v alue to the obtained p olicy which allows a comparison to the exp ert b eha vior in the subsequent rew ard up date step. 3.2.1 Global V alue The comparison of the learned b eha vior and the exp ert b e- ha vior should take place on a global level, since we w an t the updated reward function to cause a new system b eha vior whic h mimics the expert b eha vior glob al ly . Therefore, we in troduce the follo wing glob al value , V ( n ) | π : = E P 0 ( s ) h V ( n ) ( s | π ) i , whic h represents the exp ected return of an agen t under π , a ve raged o v er all p ossible initial states of the sw arm. F rom the system symmetry , i.e. since P 0 ( s ) = P 0 ( σ ( s )), it follo ws immediately that this global v alue is independent of the spe- cific agent under consideration, V ( m ) | π = V ( n ) | π ∀ m, n. Hence, the global v alue should b e considered as a system- related p erformance measure (as opp osed to an agent-specific property), which ma y b e utilized for the rew ard up date in the last step of the algorithm . W e can construct an un biased estimator for this quantit y from an y lo cal agent tra jectory , ˆ V ( n ) | π = ∞ X t =0 γ t R ( ξ ( n ) ( s t )) = ∞ X t =0 γ t r ( n ) t . (5) Since all lo cal estimators are iden tically distributed, we can increase the accuracy of our estimate by considering the in- formation provided by the whole sw arm, ˆ V | π = 1 N N X n =1 ˆ V ( n ) | π = 1 N N X n =1 ∞ X t =0 γ t r ( n ) t . (6) Note, ho w ev er, that the lo cal estimators are not indepen- den t since all agents are correlated through the system pro- cess. Nevertheless, due to the lo cal coupling structure of a sw arm, this correlation is caused only lo c al ly , which means that the correlation b et ween an y tw o agents will drop when their topological distance increases. W e demonstrate this phenomenon for the Vicsek model in Section 4.1. 3.3 Reward Update The last step of Algorithm 1 consists in up dating the esti- mated reward function. Dep ending on the single-agen t IRL framew ork in use, this inv olv es an algorithm-specific opti- mization pro cedure, e.g. in the form of a quadratic program [2, 20] or a gradient-based optimization [19, 35]. F or our ex- periments in Section 4, we follow the max-margin approach presen ted in [2]; ho wev er, the pro cedu re can b e replaced with other v alue-based methods (see Section 3). F or this purp ose, the lo cal reward function is represented as a linear combination of observ ational features, R ( o ) = w > φ ( o ), with weigh ts w ∈ R d and a given feature function φ : O → R d . The feature weigh ts after the i th iteration of Algorithm 1 are then obtained as w { i +1 } = arg max w : || w || 2 ≤ 1 min j ∈{ 1 ,...,i } w > ( µ E − µ ( j ) ) . where µ E and { µ ( j ) } i j =1 are the fe atur e exp e ctations [2] of the expert p olicy and the learned policies up to iteration i . Sim- ulating a one-shot learning experiment, we estimate these quan tities from a single system tra jectory based on Eq. (6), ˆ µ ( π ) = 1 N N X n =1 ∞ X t =0 γ t φ ( ξ ( n ) ( s t )) . where the state sequence ( s 0 , s 1 , s 2 , . . . ) is generated using the resp ectiv e p olicy π . F or more details, we refer to [2]. 1 2 3 4 5 6 unconnected 0 0.1 0.2 0.3 topological distance uncertainty coefficient t=10 t=20 t=40 t=60 t=80 t=100 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 unconnected 0 0.1 0.2 0.3 topological distance uncertainty coefficient t=10 t=20 t=40 t=60 t=80 t=100 (a) Uncertaint y co efficien t for the interaction radii ρ = 0 . 125 (left) and ρ = 0 . 05 (righ t). The v alues are based on a k ernel density estimate of the joint distribution of t w o agen ts’ headings. − 150 ◦ − 120 ◦ − 90 ◦ − 60 ◦ − 30 ◦ +150 ◦ +120 ◦ +90 ◦ +60 ◦ +30 ◦ ± 180 ◦ ± 0 ◦ (b) Learned reward mo del. Figure 4: Sim ulation results for the Vicsek model. (a) The system’s uncertaint y co efficien t as a function of the topological distance b et w een tw o agents, estimated from 10000 Monte Carlo runs of the exp ert system. (b) Learned reward mo del as a function of an agent’s lo cal misalignmen t, av eraged ov er 100 Monte Carlo exp erimen ts. Dark color indicates high reward. 4. SIMULA TION RESUL TS In this section, we provide simulation results for tw o differ- en t system types. F or the p olicy up date, the initial num ber of exploring agents is set to 50% of the population size and the learning rate is initialized close to 1. Both quan tities are con trolled b y a quadratic decay which ensures that, at the end of the learning perio d, i.e. after 200 iterations, the learn- ing rate reac hes zero and there are no exploring agents left. Note that these parameters are by no means optimized; yet, in our exp erimen ts we observ ed that the learning results are largely insensitive to the particular choice of v alues. Since the agents’ observ ation space is one-dimensional in both ex- periments, we use a simple tabular represen tation for the learned Q-function; for higher-dimension al problems, one needs to resort to function approximation [12]. Videos can be found at http://www.spg.tu- darm stadt.de/aamas2017 . 4.1 The V icsek Model First, w e test our framework on the Vicsek model of self- propelled particles [30]. The mo del consists of a fixed n um- ber of particles, or agents, living in the unit square [0 , 1] × [0 , 1] with p eriodic boundary conditions . Eac h agent n mo v es with a constant absolute velocity v and is characterized b y its location x ( n ) t and orien tation θ ( n ) t in the plane, as sum- marized b y the lo cal state v ariable s ( n ) t : = ( x ( n ) t , θ ( n ) t ). The time-v arying neighborho od structure of the agents is deter- mined by a fixed in teraction radius ρ . A t eac h time instan ce, the agents’ orien tations get synchronously updated to the a ver age orien tation of their neigh bors (including themselves) with additive random p erturbations { ∆ θ ( n ) t } , θ ( n ) t +1 = h θ ( n ) t i ρ + ∆ θ ( n ) t , x ( n ) t +1 = x ( n ) t + v ( n ) t . (7) Herein, h θ ( n ) t i ρ denotes the mean orien tation of all agent s within the ρ -neighborho od of agent n at time t , and v ( n ) t = v · [cos θ ( n ) t , sin θ ( n ) t ] is the velocity vector of agent n . Our goal is to learn a model for this expert b eha vior from recorded agen t tra jectories using the proposed framework. As a simple observ ation mechanism, w e let the agen ts in our model compute the angular distance to the a v erage orien ta- tion of their neigh bors, i.e. o ( n ) t = ξ ( n ) ( s t ) : = h θ ( n ) t i ρ − θ ( n ) t , giving them the ability to monitor their lo cal misalignmen t. F or simplicity , we discretize the observ ation space [0 , 2 π ) in to 36 equally-sized interv als (Fig. 6), corresp onding to the features φ (Section 3.3). F urthermore, we coarse-grain the space of p ossible direction changes to [ − 60 ◦ , − 50 ◦ , . . . , 60 ◦ ], resulting in a total of 13 actions av ailable to the agents. F or the experiment, w e use a system size of N = 200, an interac- tion radius of ρ = 0 . 1 (if not stated otherwise), an absolute v elo cit y of v = 0 . 1, a discoun t factor of γ = 0 . 9, and a zero- mean Gaussian noise mo del for { ∆ θ ( n ) t } with a standard deviation of 10 ◦ . These parameter v alues are chosen such that the expert system operates in an ordered phase [30]. Local Coupling & Redundancy In Section 3.2.1 w e claimed that, due to the lo cal coupling in a swarm, the correlation betw een any tw o agen ts will de- crease with growing topological distance. In this section, we substan tiate our claim b y analyzing the coupling strength in the system as a function of the top ological distance b et w een the agen ts. As a measure of (in-)dependence, we emplo y the unc ertainty c o efficient [23], a normalized version of the mu- tual information, which reflects the amoun t of information w e can predict about an agent’s orien tation b y observing that of another agent. As opp osed to linear correlation, this measure is able to capture non-linear dep endencies and is, hence, more meaningful in the cont ext of the Vicsek mo del whose state dynamics are inheren tly non-linear. Figure 4(a) depicts the result of our analysis which nicely rev eals the spatio-temp oral flo w of information in the sys- tem. It confirms that the mutual information exc hange be- t ween the agents strongly dep ends on the strength of their coupling whic h is determined by 1) their topological distance and 2) the num ber of connecting links (seen from the fact that, for a fixed distance, the dependence grows with the in- teraction radius). W e also see that, for increasing radii, the dependence gro ws even for agents that are temp orarily not connected through the system, due to the increasing c hances of having b een connected at some earlier stage. Learning Results An inheren t problem with any IRL approach is the assess- men t of the extracted reward function as there is typically no ground truth to compare with. The simplest w a y to chec k the plausibility of the result is b y sub jective insp ection: since a system’s reward function can b e regarded as a concise de- scription of the task b eing p erformed, the estimate should optimal learned transien t stationary Figure 5: Illustrative tra jectories of the Vicsek mo del gener- ated under the optimal policy and a learned policy . A color- coding scheme is used to indicate the temp oral progress. 0 100 200 300 400 500 0 0.2 0.4 0.6 0.8 1 optimal swarm single hand-crafted random Figure 6: Slop es of the order parameter ω t in the Vicsek model. F rom top to bottom, the curves show the results for the expert p olicy , the learned IRL p olicy , the result we get when the feature exp ectations are estimated from just one single ag ent , for a hand-crafted rew ard function, and for random p olicies. F or the optimal policy , w e show the em- pirical mean and the corresp onding 10% and 90% quantiles, based on 10000 Mon te Carlo runs. F or the learned policies, w e instead show the av erage o v er 100 conditional quan tiles (since the outcome of the learning pro cess is random), eac h based on 100 Monte Carlo runs with a fixed policy . explain the observed system b eha vior reasonably w ell. As w e can see from Figure 4(b), this is indeed the case for the obtained result. Although there is no “true” rew ard mo del for the Vicsek system, we can see from the system equa- tions in (7) that the agents tend to align o v er time. Clearly , suc h dynamics can b e induced b y giving higher rew ards for sync hronized states and low er (or negativ e) rew ards for mis- alignmen t. Insp ecting further the induced system dynamics (Fig. 5), we observe that the algorithm is able to repro duce the behavior of the expert system, both during the transient phase and at stationarity . Note that the absolute direction of trav el is not imp ortan t here as the mo del considers only relativ e angles b et w een the agents. Finally , we compare the results in terms of the or der p ar ameter [30], which pro vides a measure for the total alignment of the swarm, ω t : = 1 N v N X n =1 v ( n ) t ∈ [0 , 1] , with v alues close to 1 indicating strong sync hronization of the system. Figure 6 depicts its slop e for differen t system policies, including the expert p olicy and the learned ones. F rom the result, we can see a considerable p erformance gain for the prop osed v alue estimation scheme (Eq. (6)) as com- pared to a single-agent approac h (Eq. (5)). This again con- firms our findings from the previous section since the in- crease in p erformance has to stem from the additional infor- mation pro vided by the other agen ts. As a further reference, w e also show the result for a hand-crafted reward mo del, where we provide a p ositiv e reward only if the lo cal obser- v ation of an agen t falls in the discretization in terv al cen tered around 0 ◦ misalignmen t. As we can see, the learned rewa rd model significantly outperforms the ad-ho c solution. 4.2 The Ising Model In our second exp erimen t, we apply the IRL framew ork to the well-kno wn Ising mo del [10] which, in our case, con- sists of a finite grid of atoms (i.e. agents ) of size 100 × 100. Eac h agen t has an individual spin q ( n ) t ∈ { +1 , − 1 } which, together with its p osition on the grid, forms its local state, s ( n ) t : = ( x ( n ) , y ( n ) , q ( n ) t ). F or our exp erimen t, we consider a static 5 × 5-neigh borho od system, meaning that eac h agent in teracts only with its 24 closest neighbors (i.e. agents with a maximu m Chebyshe v distance of 2). Based on this neigh- borho od structure, we define the global system energy as E t : = N X n =1 X m ∈N n 1 ( q ( n ) t 6 = q ( m ) t ) = N X n =1 E ( n ) t , where N n and E ( n ) t are the neigh borho od and lo cal energy con tribution of agen t n , and 1 ( · ) denotes the indicator func- tion. Lik e the order parameter for the Vicsek model, the global energy serves as a measure for the total alignment of the system, with zero energy indicating complete state sync hronization. In our experiment, w e consider tw o p ossi- ble actions av ailable to the agents, i.e. ke ep the curr ent spin and flip the spin . The syst em dynamics are c hosen suc h that the agent transitions to the desired state with probabilit y 1. As b efore, we giv e the agen ts the ability to monitor their local misalignment, this time provided in the form of their individual energy con tributions, i.e. o ( n ) t = ξ ( n ) ( s t ) : = E ( n ) t . A meaningful goal for the system is to rea ch a global state configuration of minimum energy . Again, w e are interested in learning a b eha vioral mo del for this task from exp ert tra- jectories. In this case, our expert system p erforms a lo cal ma jorit y voti ng using a policy which lets the agents adopt the spin of the ma jority of their neighbors. Essentially , this policy implements a syn ch ronous v ersion of the iter ate d c on- ditional mo des algorithm [3], whic h is guaran teed to trans- late the system to a state of lo cally minimum energy . Figures 7 and 8 depict, respectively , the learned mean rew ard function and the slop es of the global energy for the differen t p olicies. As in the previous example, the extracted rew ard function explains the expert b eha vior w ell 4 and w e 4 Note that assigning a neutral reward to states of high lo cal energy is reasonable, since a strong lo cal misalignment indicates high synchro- nization of the opposite spin in the neigh borho od. 0 6 12 18 24 -0.5 0 0.5 1 Figure 7: Learned reward function for the Ising model, a v- eraged ov er 100 Mon te Carlo experiments. 0 0.2 0.4 0.6 0.8 1 10 0 10 1 10 2 10 3 random hand-crafted single swarm optimal Figure 8: Slop es of the global energy E t in the Ising mo del. The graphs are analogous to those in Figure 6. observ e the same qualitative performance improv emen t as for the Vicsek system, both when compared to the single- agen t estimation sc heme and to the hand-crafted mo del. 5. CONCLUSION & DISCUSSION Our ob jectiv e in this p aper has b een to extend the concept of IRL to homogeneous multi-agen t systems, called swarms, in order to learn a lo cal rew ard function from observed global dynamics that is able to explain the emergen t b eha vior of a system. By exploiting the homogeneit y of the newly in- troduced swarMDP mo del, w e show ed that b oth v alue es- timation and policy up date required for the IRL procedure can b e p erformed based on local exp erience gathered at the agen t level. The so-obtained reward function was pro vided as input to a nov el learning scheme to build a local p olicy model which mimics the exp ert b eha vior. W e demonstrated our framew ork on t w o types of system dynamics where w e ac hiev ed a p erformance close to that of the exp ert system. Nev ertheless, there remain some op en questions. In the process of IRL, we ha ve tacitly assumed that the expert b e- ha vior can b e reconstructed based on lo cal interactions. Of course, this is a reasonable assumption for self-organizing systems which naturally op erate in a decentralized manner. F or arbitrary expert systems, how ev er, we cannot exclude the p ossibilit y that the agents are instructed by a central con troller which has access to the global system state. This brings us back to the follo wing questions: When is it possible to reconstruct global b eha vior based on lo cal information? If it is not possible for a given task, ho w w ell can w e appro x- imate the cen tralized solution b y optimizing local v alues? In an attempt to understand the ab o ve men tioned ques- tions, we prop ose the follo wing c haracterization of the re- w ard function that would make a local p olicy optimal in a sw arm. T o this end, w e en umerate the sw arm stat es and ob- serv ations by S N = { s i } K i =1 and O = { o i } L i =1 , resp ecti vely . F urthermore, we fix an agen t n and define matrices P o and { P a } |A| a =1 , where [ P o ] ij = P ( s j | o ( n ) = o i , π ) and [ P a ] ij = P ( n ) ( s j | s i , a, π ). Finally , w e represent the rew ard function as a vector, i.e. R = ( R ( ξ ( n ) ( s 1 )) , . . . , R ( ξ ( n ) ( s K ))) T . Prop osition 2. Consider a swarm ( N , A , T , ξ ) of agents A = ( S , O , A , R, π ) and a disc ount factor γ ∈ [0 , 1) . Then, a po licy π : O → A given by π ( o ) : = a 1 is optimal 5 with r espe ct to V ( o | π ) if and only if the rewar d R satisfies P o ( P a 1 − P a )( I − γ P a 1 ) − 1 R ≥ 0 ∀ a ∈ A . (8) 5 W e can ensure that π ( o ) = a 1 by renaming actions accordingly [20]. Pr oof. Expressing Eq. (1) using v ector notation, w e get V s | π = ( I − γ P a 1 ) − 1 R , where V s | π = ( V ( n ) ( s 1 | π ) , . . . , V ( n ) ( s K | π )) T . According to Prop. 1, the corresp ondi ng limiting v alue function is V ( o | π ) = K X i =1 P ( s i | o ( n ) = o, π ) V ( n ) ( s i | π ) . Rewritten in v ector notation, w e obtain V o | π = P o V s | π , (9) where V o | π = ( V ( o 1 | π ) , . . . , V ( o L | π )) T . No w, π ( o ) = a 1 is optimal if and only if for all a ∈ A , o ∈ O Q ( n ) ( o, a 1 | π ) ≥ Q ( n ) ( o, a | π ) ⇔ K X i =1 P ( s i | o ( n ) = o, π ) K X j =1 P ( n ) ( s j | s i , a 1 , π ) V ( n ) ( s j | π ) ≥ K X i =1 P ( s i | o ( n ) = o, π ) K X j =1 P ( n ) ( s j | s i , a, π ) V ( n ) ( s j | π ) ⇔ P o ( P a 1 − P a ) V s | π ≥ 0 ⇔ P o ( P a 1 − P a )( I − γ P a 1 ) − 1 R ≥ 0 . Remark. F ol lowing a similar derivation as in [20], we ob- tain the char acterization set with r esp e ct to V s | π as ( P a 1 − P a )( I − γ P a 1 ) R ≥ 0 . (10) Notice that, as Eq. (10) implies Eq. (8), an R that mak es π ( o ) optimal for V s | π , also mak es it optimal for V o | π . There- fore, denoting b y R L and R G the solution sets corresponding to the lo cal and global v alues V o | π and V s | π , we conclude R G ⊆ R L , with equalit y in the trivial case where observ ation o is suffi- cien t to determine the swarm state s . It is therefore imme- diate that, as long as there is uncertaint y ab out the swarm state, local planning can only gu aran tee globa lly optimal be- ha vior in an a v erage sense as pronounced by P o (see Eq. (9)). Acknowledgment W. R. Kh udaBukhsh was supp orted by the German Research F oundation (DFG) within the Collaborative Research Cen- ter (CRC) 1053 – MAKI. H. Ko eppl ackno wledges the sup- port of the LOEWE Research Priority Program CompuGene. REFERENCES [1] P . Abbeel, A. Coates, and A. Y. Ng. Autonomous helicopter aerobatics through apprenticeship learning. The International Journal of Ro b otics R ese arch , 2010. [2] P . Abbeel and A. Y. Ng. Apprenticeship learning via in v erse reinforcement learning. In Pr o c. 21st International Confer enc e on Machine L ea rning , page 1, 2004. [3] J. Besag. On the statistical analysis of dirty pictures. Journal of the R oyal Statistic al Soci ety. Series B (Metho dolo gic al) , pages 259–302, 1986. [4] P . Billingsley . Conver genc e of pr oba bility me asur es . John Wiley & Sons, 2013. [5] J. Buhl, D. Sumpter, I. D. Couzin, J. J. Hale, E. Despland, E. Miller, and S. J. Simpson. F rom disorder to order in marc hing lo custs. Scienc e , 312(5778):1402–1406, 2006. [6] I. D. Couzin. Collective cognition in animal groups. T r ends in c ogni tive scienc es , 13(1):36–43, 2009. [7] L. Dufton and K. Larson. Multiagent policy teac hing. In Pr o c. 8th International Confer enc e on A utonomous A gents and Multiagent Systems , 2009. [8] R. A. F reitas. Current status of nanomedicine and medical nanorob otics. Journal of Computational and The oreti c al Nanoscienc e , 2(1):1–25, 2005. [9] S. C. Goldstein, J. D. Campb ell, and T. C. Mowry . Programmable matter. Computer , 38(6):99–101, 2005. [10] E. Ising. Beitrag zur Theorie des Ferromagnetismus. Zeitschrift f ¨ ur Physik , 31(1):253–258, 1925. [11] L. P . Kaelbling, M. L. Littman, and A. R. Cassandra. Planning and acting in partially observ able stochastic domains. Artificial intel ligenc e , 101(1):99–134, 1998. [12] M. G. Lagoudakis and R. Parr. Least-squares p olicy iteration. Journal of Machine L e arning R ese ar ch , 4(Dec):1107–1149, 2003. [13] V. Lesser, C. L. Ortiz J., and M. T am be. Distribute d sensor networks: a multiagent p ersp e ctive , volume 9. Springer Science & Business Media, 2012. [14] F. S. Melo. Exploiting lo calit y of in teractions using a policy-gradient approach in multiagen t learning. In Pr oc. 18th Euro p e an Confer enc e on Artificia l Intel ligenc e , page 157, 2008. [15] N. Meuleau, L. Peshkin, K.-E. Kim, and L. P . Kaelbling. Learning finite-state controllers for partially observ able environm ent s. In Pr o c. 15th Confer enc e on Unc ertainty in Artificial Intel ligenc e , pages 427–436, 1999. [16] D. Michie, M. Bain, and J. Ha y es-Mic hes. Cognitive models from subcognitive skills. IEE Contr ol Engine ering Series , 44:71–99, 1990. [17] B. Michini and J. P . How. Bay esian nonparametric in v erse reinforcement learning. In Machine L e arning and Know le dge Disc overy in Datab ases , pages 148–163. Springer, 2012. [18] S. Natara jan, G. Kunapuli, K. Judah, P . T adepalli, K. Kersting, and J. Sha vlik. Multi-agent inv erse reinforcemen t learning. In Pr o c. 9th International Confer enc e on Machine Le arning and Applic ations , pages 395–400, 2010. [19] G. Neu and C. Szepesv ari. Apprenticeshi p learning using inv erse reinforcement learning and gradien t methods. In Pro c. 23r d Confer enc e on Unc ertainty in Ar tificial Intel ligenc e , pages 295–302, 2007. [20] A. Y. Ng and S. Russell. Algorithms for inv erse reinforcemen t learning. In Pr o c. 17th International Confer enc e on Machine Le arning , pages 663–670, 2000. [21] F. A. Olieho ek. De c entr alize d POMDPs , pages 471–503. Springer, 2012. [22] E. Omel’chenk o, Y. L. Maistrenko, and P . A. T ass. Chimera states: the natural link b et w een coherence and incoherence. Physic al r eview letters , 100(4):044105, 2008. [23] W. H. Press. Numeric al r e cip es 3r d e dition: The art of scientific c omputing . Cam bridge Universit y Press, 2007. [24] D. Ramachand ran and E. Amir. Bay esian inv erse reinforcemen t learning. In Pr o c. 20th International Joint Confer enc e on Artific al Intel ligenc e , pages 2586–2591, 2007. [25] T. S. Reddy , V. Gopikrishna, G. Zaruba, and M. Hub er. Inv erse reinforcemen t learning for decen tralized non-co operative mu ltiagen t systems. In Pr oc. International Confer enc e on Systems, Man, and Cyb ernetics , pages 1930–1935, 2012. [26] W. Ren, R. W. Beard, and E. M. A tkins. A surv ey of consensus problems in multi-agen t co ordina tion. In Pr oc. Americ an Contr ol Confer enc e , pages 1859–1864, 2005. [27] C. Sammut, S. Hurst, D. Kedzier, D. Michie, et al. Learning to fly . In Pr o c. 9th International Workshop on Machine L e arning , pages 385–393, 1992. [28] R. S. Sutton and A. G. Barto. R einfor c ement le arning: an intr o duction , v olume 1. MIT press Cam bridge, 1998. [29] U. Syed and R. E. Schapire. A game-theoretic approac h to appren ticeship learning. In A dvanc es in Neur al Information Pr o c essing Systems , pages 1449–1456, 2007. [30] T. Vicsek, A. Czir´ ok, E. Ben-Jacob, I. Cohen, and O. Sho c het. Nov el type of phase transition in a system of self-driven particles. Physic al r eview letters , 75(6):1226, 1995. [31] T. Vicsek and A. Zafeiris. Collective motion. Physics R eports , 517(3):71–140, 2012. [32] C. W atkins and P . Day an. Q-learning. Machine le arning , 8(3-4):279–292, 1992. [33] G. M. Whitesides and B. Grzyb o wski. Self-assem bly at all scales. Scienc e , 295(5564):2418–2421, 2002. [34] S. Zhifei and E. M. Jo o. A survey of in v erse reinforcemen t learning tec hniques. International Journal of Intel ligent Computing and Cyb ernetics , 5(3):293–311, 2012. [35] B. D. Ziebart, A. L. Maas, J. A. Bagnell, and A. K. Dey . Maximum entrop y inv erse reinforcemen t learning. In Pr oc. 23r d Confer ence on A rtificial Intel ligenc e , pages 1433–1438, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment