OpenNMT: Open-Source Toolkit for Neural Machine Translation
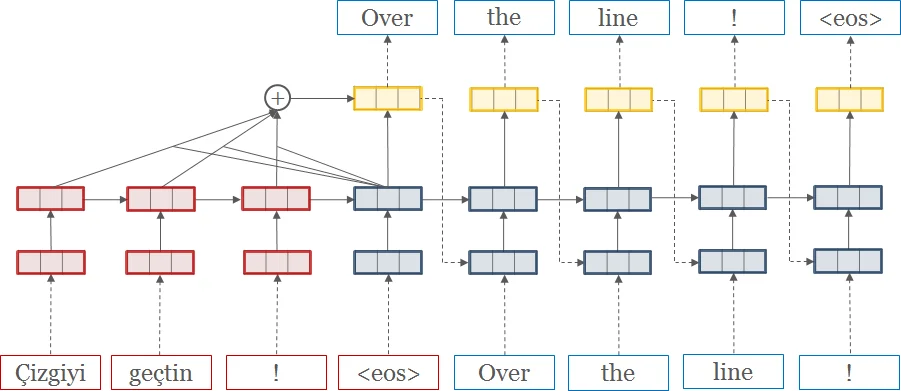
We describe an open-source toolkit for neural machine translation (NMT). The toolkit prioritizes efficiency, modularity, and extensibility with the goal of supporting NMT research into model architectures, feature representations, and source modalities, while maintaining competitive performance and reasonable training requirements. The toolkit consists of modeling and translation support, as well as detailed pedagogical documentation about the underlying techniques.
💡 Research Summary
OpenNMT is an open‑source toolkit designed to serve both research and production needs in neural machine translation (NMT). The authors present it as a response to the growing demand for a shared, well‑documented, and extensible implementation that can rival the impact of earlier SMT toolkits such as Moses and CDec. The paper is organized around three primary design goals: system efficiency, code modularity, and model extensibility.
System efficiency is tackled through two main innovations. First, the authors implement an external memory‑sharing mechanism that analyses the computation graph before training and aggressively re‑uses intermediate buffers across time steps. In practice this reduces GPU memory consumption by roughly 70 % for the default model, allowing larger batch sizes and faster convergence. Second, OpenNMT supports multi‑GPU data‑parallel training with both synchronous and asynchronous modes. Experiments on up to eight GPUs show a six‑fold speed‑up per epoch in synchronous mode, while asynchronous SGD yields a modest loss in convergence efficiency but a 3.5× overall reduction in wall‑clock training time.
The toolkit is written in Lua/Torch and has a parallel Python/PyTorch implementation, both released under the permissive MIT license. The Lua version consists of about 4 K lines of code, while the Python version is under 1 K lines, making the codebase approachable for newcomers. A vibrant GitHub community, an active discussion forum, and a live demo further lower the barrier to entry.
Code modularity is achieved by cleanly separating core model logic from optimizations, preprocessing, and I/O. The authors demonstrate this modularity with two case studies. In factored translation, the model predicts both a word and auxiliary features (e.g., case, POS) at each step. OpenNMT allows this by swapping the input encoder and output generator modules without touching the central training loop. In the attention case study, the default global attention can be replaced with local, sparse‑max, hierarchical, or even structured attention mechanisms simply by providing a new attention module that conforms to the same interface. This plug‑and‑play design enables rapid prototyping of novel ideas.
Extensibility is highlighted through multimodal experiments. The toolkit can replace the source RNN with a deep convolutional network for image‑to‑text tasks, or with a pyramidal encoder for speech‑to‑text, requiring less than 500 additional lines of code. Moreover, OpenNMT includes utilities for loading pretrained word embeddings, performing Byte‑Pair Encoding (BPE), and exporting learned embeddings for external analysis tools such as TensorBoard.
Benchmark results are presented on the WMT15 English‑German dataset and compared against the widely used Nematus system. Using a 2‑layer 500‑unit LSTM with 300‑dimensional embeddings, OpenNMT achieves higher BLEU scores (0.2–1.1 points improvement) while processing 1.2–1.5× more source tokens per second during training. In a multilingual setting involving French, Spanish, Portuguese, Italian, and Romanian, a single joint model outperforms 20 independently trained bilingual models by 3–6 BLEU points on average, illustrating the benefits of parameter sharing across languages.
Beyond translation, the authors note successful applications to sentence summarization (matching ROUGE‑1 scores of prior work) and subtitle‑style language modeling, further proving the toolkit’s flexibility.
In conclusion, OpenNMT delivers a compact, well‑documented, and highly configurable NMT platform that balances research agility with production‑grade performance. Its open‑source nature, community support, and emphasis on efficiency, modularity, and extensibility make it a valuable resource for anyone working on neural sequence‑to‑sequence problems.
Comments & Academic Discussion
Loading comments...
Leave a Comment