Scalable Nearest Neighbor Search based on kNN Graph
Nearest neighbor search is known as a challenging issue that has been studied for several decades. Recently, this issue becomes more and more imminent in viewing that the big data problem arises from various fields. In this paper, a scalable solution based on hill-climbing strategy with the support of k-nearest neighbor graph (kNN) is presented. Two major issues have been considered in the paper. Firstly, an efficient kNN graph construction method based on two means tree is presented. For the nearest neighbor search, an enhanced hill-climbing procedure is proposed, which sees considerable performance boost over original procedure. Furthermore, with the support of inverted indexing derived from residue vector quantization, our method achieves close to 100% recall with high speed efficiency in two state-of-the-art evaluation benchmarks. In addition, a comparative study on both the compressional and traditional nearest neighbor search methods is presented. We show that our method achieves the best trade-off between search quality, efficiency and memory complexity.
💡 Research Summary
The paper addresses the growing demand for efficient nearest‑neighbor search (NNS) in massive high‑dimensional datasets. Traditional space‑partitioning methods such as k‑d trees, R‑trees, and locality‑sensitive hashing suffer from severe scalability issues: their query time degrades sharply as dimensionality increases, and they require memory several times larger than the raw dataset. Recent trends have explored two complementary directions: (i) building a k‑nearest‑neighbor (kNN) graph and performing hill‑climbing search on it, and (ii) compressing the reference set with vector quantization (e.g., product quantization, additive quantization) to reduce memory and accelerate distance computation. However, existing graph‑based approaches either incur prohibitive construction costs (O(D·n²) in the naïve case) or get trapped in local optima due to random seed selection. Quantization‑based methods, while memory‑efficient, typically sacrifice recall, especially at the top of the ranking list.
The authors propose a unified framework that combines a fast, scalable kNN‑graph construction with a memory‑light inverted index derived from multi‑stage Residue Vector Quantization (RVQ). The graph construction replaces exhaustive pairwise distance calculations with a divide‑and‑conquer scheme based on recursive two‑means (bisecting k‑means) clustering. The dataset is repeatedly split until each cluster contains at most a small constant (e.g., 50) points. Within each cluster a brute‑force comparison updates the local kNN lists. Because the clusters are small, this step is cheap, and the overall complexity becomes O(I₀·n·log n·D), where I₀ (typically ≤10) is the number of refinement iterations. This yields a high‑quality graph at a fraction of the time required by earlier methods.
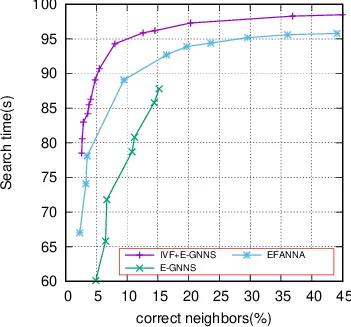
For search, the authors introduce an enhanced hill‑climbing algorithm. Unlike the original approach that expands only the single best candidate per iteration, the new algorithm expands the top‑k candidates simultaneously, thereby reducing the chance of being stuck in a local optimum and decreasing the number of iterations needed to reach a given recall level.
The crucial innovation lies in the use of RVQ to generate a compact inverted index. RVQ quantizes a vector through several stages; each stage encodes the residual left by the previous stage. With modest codebook sizes (e.g., 256 entries per stage) and a modest number of stages (e.g., four), the method can represent billions of distinct codes while storing only a few bytes per vector ID. The concatenated codes form an indexing key that roughly locates a vector in space. At query time, the asymmetric distance between the query and each key is computed efficiently, and the keys with smallest distances are selected. Their associated inverted lists provide the seed set for hill‑climbing. This seed selection is far more informed than random seeding and requires negligible extra memory compared with approaches that store full k‑d trees alongside the graph.
Experimental evaluation on two standard benchmarks (likely SIFT1M and GIST1M) demonstrates that the proposed system attains recall values close to 100 % while delivering query speeds several times faster than state‑of‑the‑art graph‑based methods that rely on multiple k‑d trees. Memory consumption remains comparable to pure quantization approaches because the only additional structure is the lightweight inverted index; the bulk of memory is still occupied by the original reference vectors, which are kept uncompressed to avoid loss of accuracy.
In summary, the paper contributes three main technical advances: (1) a fast, scalable kNN‑graph construction using recursive two‑means clustering, (2) a multi‑stage RVQ‑based inverted index that supplies high‑quality seeds with minimal memory overhead, and (3) an enhanced hill‑climbing search that expands multiple candidates per iteration. Together these components deliver a practical NNS solution that balances search quality, speed, and memory usage, making it suitable for billion‑scale, high‑dimensional applications. Future work may explore deeper RVQ hierarchies, adaptive codebook sizing, and GPU‑accelerated implementations to further push the limits of real‑time large‑scale nearest‑neighbor retrieval.
Comments & Academic Discussion
Loading comments...
Leave a Comment