Achieving Privacy in the Adversarial Multi-Armed Bandit
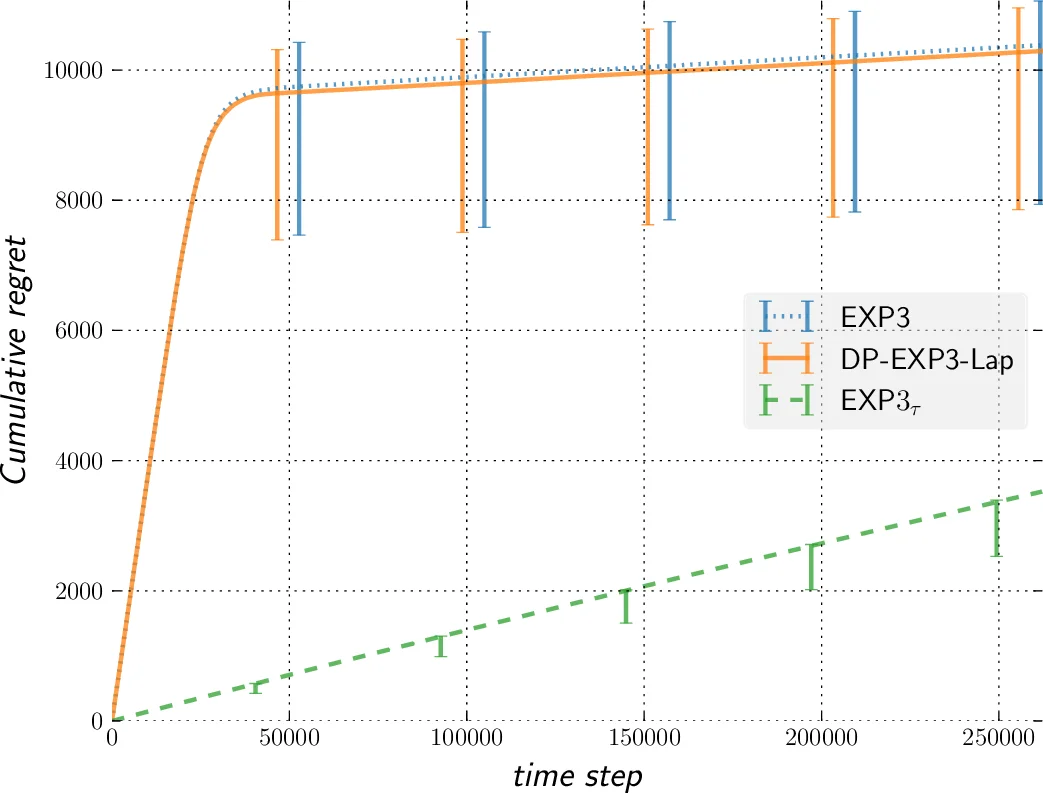
In this paper, we improve the previously best known regret bound to achieve $\epsilon$-differential privacy in oblivious adversarial bandits from $\mathcal{O}{(T^{2/3}/\epsilon)}$ to $\mathcal{O}{(\sqrt{T} \ln T /\epsilon)}$. This is achieved by combining a Laplace Mechanism with EXP3. We show that though EXP3 is already differentially private, it leaks a linear amount of information in $T$. However, we can improve this privacy by relying on its intrinsic exponential mechanism for selecting actions. This allows us to reach $\mathcal{O}{(\sqrt{\ln T})}$-DP, with a regret of $\mathcal{O}{(T^{2/3})}$ that holds against an adaptive adversary, an improvement from the best known of $\mathcal{O}{(T^{3/4})}$. This is done by using an algorithm that run EXP3 in a mini-batch loop. Finally, we run experiments that clearly demonstrate the validity of our theoretical analysis.
💡 Research Summary
The paper addresses the problem of achieving differential privacy in the adversarial multi‑armed bandit (MAB) setting while maintaining low regret. In the standard adversarial MAB, an agent repeatedly selects one of K arms and receives a reward in
Comments & Academic Discussion
Loading comments...
Leave a Comment