Exploring the Design Space of Deep Convolutional Neural Networks at Large Scale
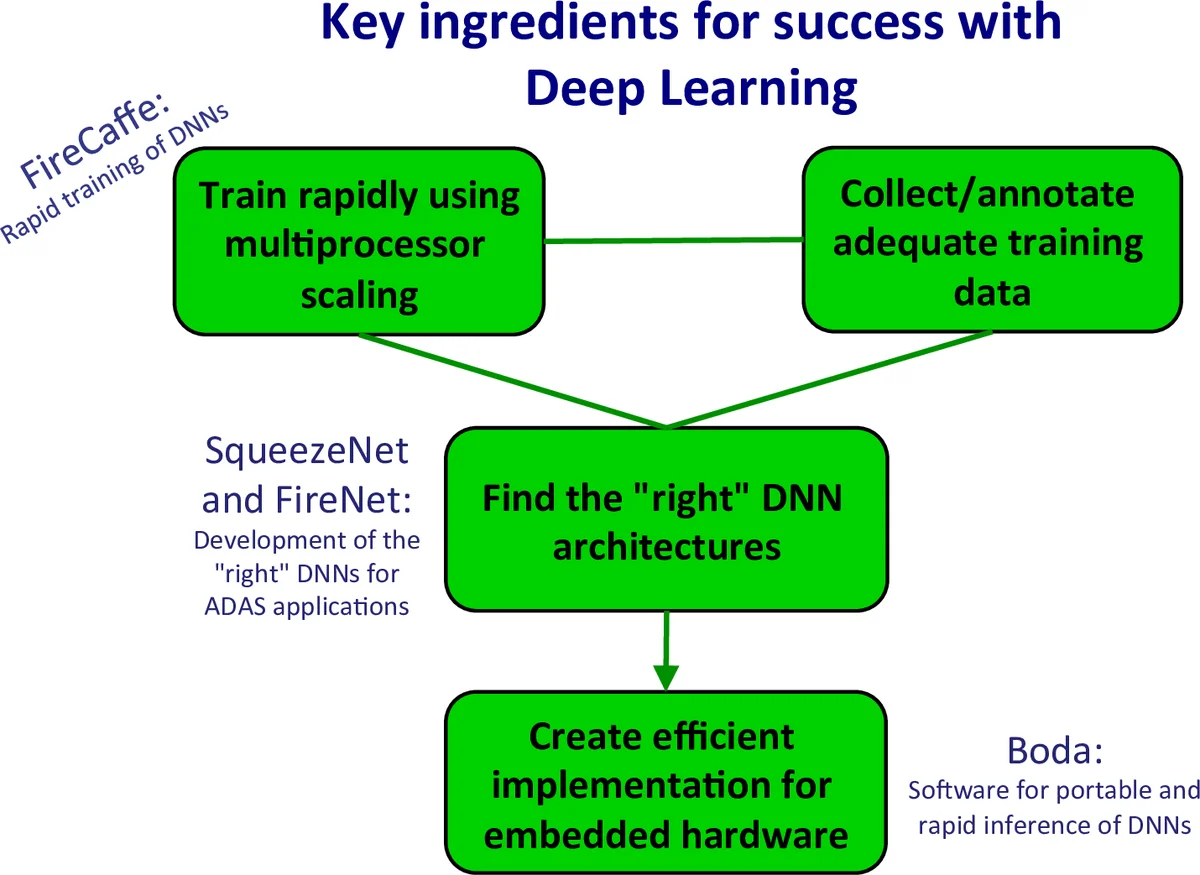
In recent years, the research community has discovered that deep neural networks (DNNs) and convolutional neural networks (CNNs) can yield higher accuracy than all previous solutions to a broad array of machine learning problems. To our knowledge, there is no single CNN/DNN architecture that solves all problems optimally. Instead, the “right” CNN/DNN architecture varies depending on the application at hand. CNN/DNNs comprise an enormous design space. Quantitatively, we find that a small region of the CNN design space contains 30 billion different CNN architectures. In this dissertation, we develop a methodology that enables systematic exploration of the design space of CNNs. Our methodology is comprised of the following four themes. 1. Judiciously choosing benchmarks and metrics. 2. Rapidly training CNN models. 3. Defining and describing the CNN design space. 4. Exploring the design space of CNN architectures. Taken together, these four themes comprise an effective methodology for discovering the “right” CNN architectures to meet the needs of practical applications.
💡 Research Summary
The dissertation “Exploring the Design Space of Deep Convolutional Neural Networks at Large Scale” presents a comprehensive methodology for systematically navigating the immense architectural space of modern CNNs. Recognizing that no single network can optimally solve every problem, the author introduces the MESCAL framework, which consists of four interrelated themes: (1) careful selection of benchmarks and performance metrics, (2) rapid training of CNN models on large‑scale compute clusters, (3) precise definition and quantification of the CNN design space, and (4) systematic exploration of that space to discover architectures that meet real‑world constraints.
In the first theme, the work argues that practical applications require more than accuracy; they also demand constraints on FLOPs, memory footprint, latency, power consumption, and training cost. The author therefore proposes a multi‑metric evaluation suite that includes a novel “accuracy‑per‑training‑cost” measure, enabling fair comparison across diverse tasks such as ImageNet classification, COCO detection, and speech recognition.
The second theme focuses on scaling training to dozens of GPUs. The dissertation describes the FireCaffe system, which combines a parameter‑server architecture with reduction‑tree communication to overlap computation and communication. Experiments demonstrate that ResNet‑50 can be trained on ImageNet in under 90 minutes using a 32‑GPU cluster, and that similar speed‑ups are achievable on heterogeneous CPU‑GPU systems through careful minibatch scheduling and memory‑efficient data pipelines.
The third theme provides a rigorous taxonomy of CNN building blocks—convolution, pooling, normalization, and activation—and models each block’s dimensions (channel count, filter size, stride, padding). By distinguishing local changes (modifying a single layer) from global changes (altering network depth, width, or topology), the author quantifies how each parameter impacts FLOPs, parameter count, memory bandwidth, and ultimately inference latency. A theoretical estimate suggests that the explored sub‑space already contains on the order of 30 billion distinct architectures.
The fourth theme puts the taxonomy into practice. Two levels of exploration are performed. At the micro‑architecture level, the “Fire” module (a 1×1 squeeze followed by a mix of 1×1 and 3×3 expand convolutions) is used as a composable unit; exhaustive combinations reveal Pareto fronts between parameter efficiency and accuracy. At the macro‑architecture level, the dissertation introduces SqueezeNet, a network designed to achieve AlexNet‑level accuracy with 50× fewer parameters. By varying the “squeeze ratio,” “fire ratio,” and overall network depth, SqueezeNet attains 57.5 % top‑1 accuracy on ImageNet with only 1.2 M parameters, making it suitable for real‑time inference on mobile devices. Additional experiments systematically scale channel counts, input resolutions, and filter sizes to map the boundaries of the design space, providing concrete data on how each scaling decision affects performance and resource usage.
The final chapters summarize contributions: (i) an open‑source, high‑throughput training framework (FireCaffe), (ii) a mathematically grounded model of CNN design variables and their performance implications, (iii) the SqueezeNet architecture that demonstrates extreme model compression without catastrophic loss of accuracy, and (iv) a clear argument that design‑space exploration must balance accuracy with deployment constraints such as memory, compute budget, and power. The dissertation also outlines future work, including automated architecture search using reinforcement learning or Bayesian optimization and tighter hardware‑software co‑design loops. Overall, the work provides a practical roadmap for researchers and engineers to navigate the vast CNN design landscape, emphasizing that the “right” network is one that satisfies the full spectrum of real‑world requirements rather than merely achieving the highest benchmark score.
Comments & Academic Discussion
Loading comments...
Leave a Comment