Commonly Uncommon: Semantic Sparsity in Situation Recognition
Semantic sparsity is a common challenge in structured visual classification problems; when the output space is complex, the vast majority of the possible predictions are rarely, if ever, seen in the training set. This paper studies semantic sparsity in situation recognition, the task of producing structured summaries of what is happening in images, including activities, objects and the roles objects play within the activity. For this problem, we find empirically that most object-role combinations are rare, and current state-of-the-art models significantly underperform in this sparse data regime. We avoid many such errors by (1) introducing a novel tensor composition function that learns to share examples across role-noun combinations and (2) semantically augmenting our training data with automatically gathered examples of rarely observed outputs using web data. When integrated within a complete CRF-based structured prediction model, the tensor-based approach outperforms existing state of the art by a relative improvement of 2.11% and 4.40% on top-5 verb and noun-role accuracy, respectively. Adding 5 million images with our semantic augmentation techniques gives further relative improvements of 6.23% and 9.57% on top-5 verb and noun-role accuracy.
💡 Research Summary
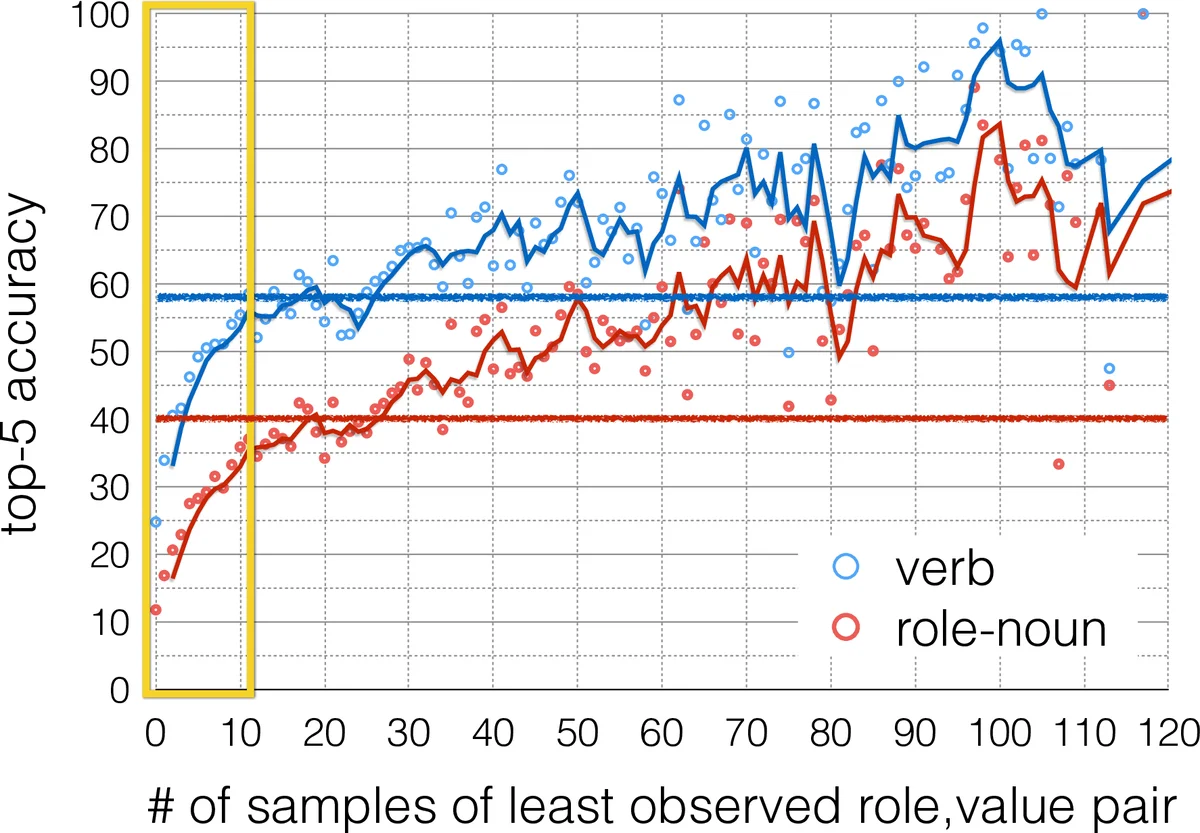
The paper tackles a fundamental obstacle in structured visual classification—semantic sparsity—where the combinatorial space of possible outputs (verbs, roles, nouns) is vastly larger than what can be covered by any training set. In the imSitu situation‑recognition benchmark, 35 % of required verb‑role‑noun predictions appear fewer than ten times during training, and even a single rare pair dramatically degrades overall accuracy. To address this, the authors introduce two complementary solutions.
First, they redesign the Conditional Random Field (CRF) used for situation prediction with a compositional tensor potential. Instead of learning a separate linear regressor for every (verb, role, noun) triple, they embed nouns (dₙ ∈ ℝᵐ) and roles (via matrices H(v,e) ∈ ℝ^{p×o}) into low‑dimensional spaces (m = o = 32) and combine them with the global image feature gᵢ ∈ ℝᵖ (p = 1024) through a three‑way outer product weighted by a global tensor C ∈ ℝ^{m×o×p}. The resulting score φₑ(v,e,n,i) is the sum over all tensor entries, effectively sharing noun representations across all roles and verbs while keeping the number of learnable parameters modest. This compositional design enables the model to generalize to unseen or rarely seen noun‑role combinations because the same noun embedding contributes to every role.
Second, the authors exploit the strong language‑vision link in situation recognition to generate additional training data automatically. They convert each annotated situation into a set of partial textual templates (e.g., “man carrying”, “man carrying baby”) and use these as queries for Google Image Search. The retrieved images are labeled only with the partial situation that generated the query, leaving many role slots unfilled. To train on such noisy, partially observed data, they maximize a marginal likelihood that sums over all possible completions of the missing roles. After an initial pre‑training phase on the web data, they apply a self‑training loop: the current model scores all web images, the top‑k images per unique partial situation are kept, and the model is re‑trained. This iterative filtering progressively reduces noise while preserving the benefit of massive data augmentation.
Experiments on the imSitu dataset demonstrate the efficacy of each component and their combination. The tensor‑based CRF alone improves top‑5 verb accuracy by 2.11 % and top‑5 noun‑role accuracy by 4.40 % relative to the baseline CRF. Adding 5 million web‑collected images with the marginal‑likelihood pre‑training yields further gains of 6.23 % (verb) and 9.57 % (noun‑role). Importantly, for rare role‑noun pairs the relative improvement reaches 8.76 % across all metrics, confirming that the approach directly mitigates semantic sparsity.
The paper also provides extensive ablations: removing regression parameters for infrequent triples, mixing regression with the tensor potential, and varying embedding dimensions. Larger embedding sizes improve performance but increase training time, so the authors settle on 32‑dimensional embeddings as a practical trade‑off.
In summary, the work makes three key contributions: (1) a novel compositional CRF that shares noun representations across roles via a tensor product, (2) a systematic method for generating and leveraging weakly labeled web images through language‑driven queries, and (3) a self‑training scheme that refines noisy web data. The combined system sets a new state‑of‑the‑art on imSitu, especially in the low‑frequency regime, and offers a blueprint for addressing semantic sparsity in other structured vision tasks such as video event detection or multi‑label object recognition.
Comments & Academic Discussion
Loading comments...
Leave a Comment