Ad hoc Cloud Computing: From Concept to Realization
This paper presents the first complete, integrated and end-to-end solution for ad hoc cloud computing environments. Ad hoc clouds harvest resources from existing sporadically available, non-exclusive (i.e. primarily used for some other purpose) and unreliable infrastructures. In this paper we discuss the problems ad hoc cloud computing solves and outline our architecture which is based on BOINC.
💡 Research Summary
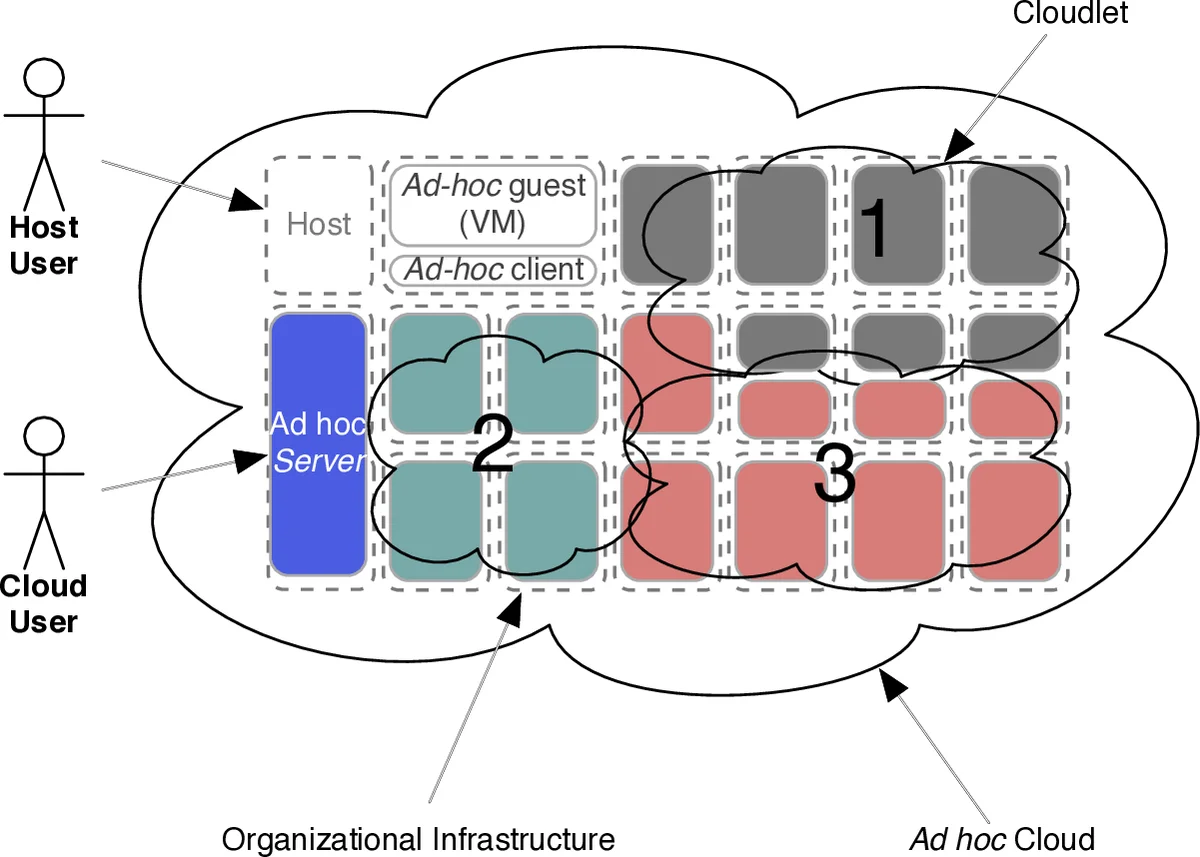
This paper introduces and details the first comprehensive prototype for “Ad hoc Cloud Computing,” a paradigm that constructs cloud services by harvesting underutilized computing resources from pre-existing, non-dedicated, and unreliable infrastructures such as personal computers, office workstations, or organizational networks. The core challenge lies in managing these transient resources to provide a reliable cloud platform.
The authors propose a novel architecture built upon the well-established volunteer computing platform, BOINC (Berkeley Open Infrastructure for Network Computing). The key innovation is the integration of virtualization into this model, creating a system called V-BOINC. In this system, user-submitted jobs do not run directly on the host machines. Instead, each participating host runs a lightweight virtual machine (VM), and all computational tasks are executed securely within these isolated VM environments. This addresses critical concerns about security, host process interference, and the need for specific software dependencies for diverse workloads.
The system operates through a central Ad hoc Server and Ad hoc Clients installed on each donor host. A cloud user submits a job (application and data) via a web interface to the server. The server hosts two core services: a “Job Service” for handling user tasks and a “VM Service” for managing the virtualized infrastructure. The server’s scheduler assigns incoming jobs to VMs based on a calculated host reliability score. This score is derived from historical data including the number of jobs previously completed versus assigned, and the count of host and guest VM failures.
To ensure job continuity in the face of host churn or failure—a fundamental requirement for an ad hoc cloud—the system implements a snapshot-based checkpointing mechanism. The Ad hoc Client on each host periodically captures snapshots of the running VM. These snapshots are then distributed in a Peer-to-Peer (P2P) fashion among other reliable hosts in the network. If a host fails, the server detects the absence and orchestrates the restoration of the latest VM snapshot on a different, available host, allowing the job to resume from its last saved state with minimal data loss.
Furthermore, the Ad hoc Client actively monitors resource usage (CPU, memory) on the host machine. It dynamically adjusts the resources allocated to the VM to ensure that the cloud job does not severely impact the primary tasks of the host user, adhering to the principle of low interference.
The paper successfully demonstrates a transition from a user-centric volunteer computing model to a server-controlled cloud provisioning model. The prototype proves the feasibility of creating a Platform-as-a-Service (PaaS) offering from unreliable, donated resources. The authors conclude by outlining future work, which includes extending the system to Wide Area Networks (WANs), enhancing security models, and optimizing the scheduling and snapshotting mechanisms for larger-scale deployments.
Comments & Academic Discussion
Loading comments...
Leave a Comment