Generalized Nonconvex Nonsmooth Low-Rank Minimization
As surrogate functions of $L_0$-norm, many nonconvex penalty functions have been proposed to enhance the sparse vector recovery. It is easy to extend these nonconvex penalty functions on singular values of a matrix to enhance low-rank matrix recovery…
Authors: Canyi Lu, Jinhui Tang, Shuicheng Yan
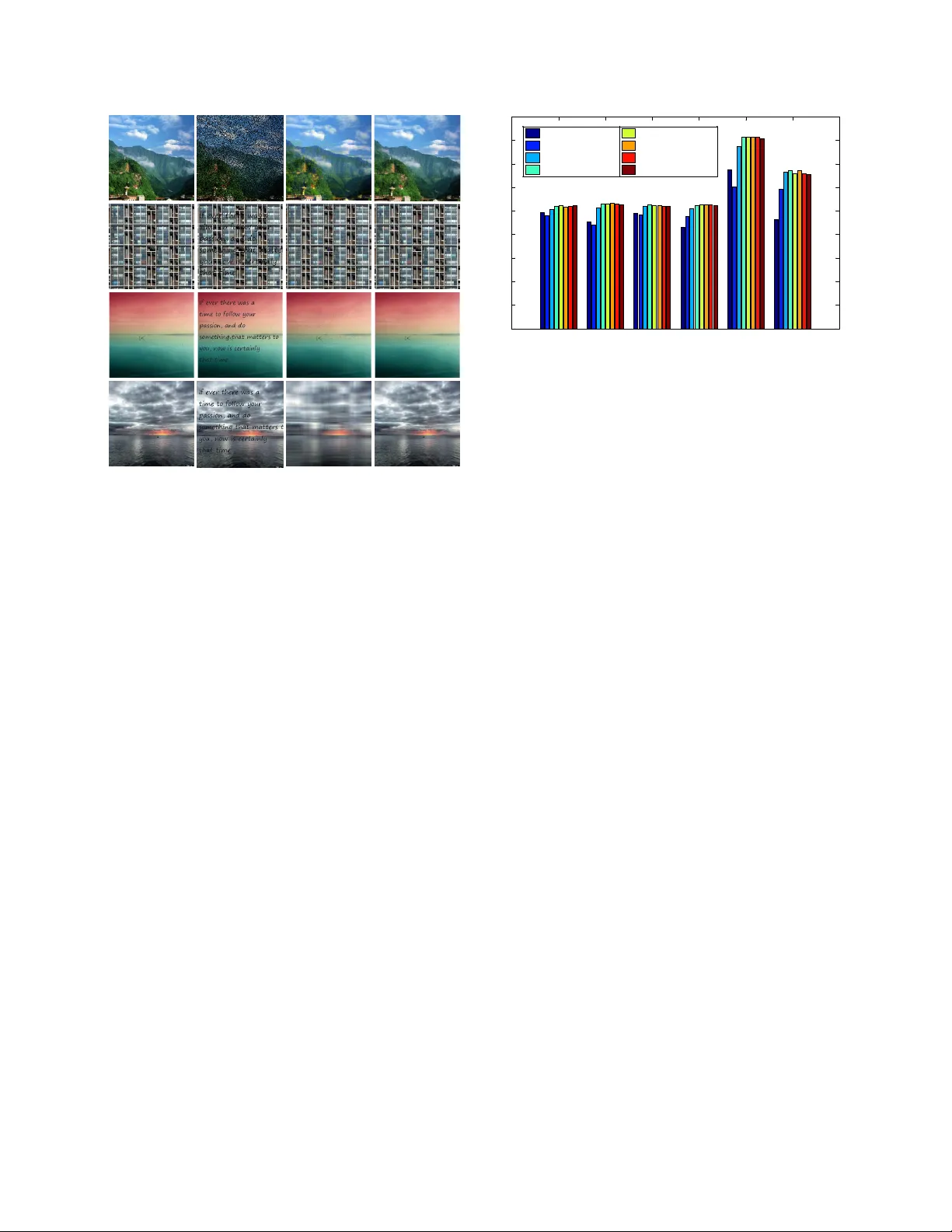
Generalized Noncon vex Nonsmooth Lo w-Rank Minimization Canyi Lu 1 , Jinhui T ang 2 , Shuicheng Y an 1 , Zhouchen Lin 3 , ∗ 1 Department of Electrical and Computer Engineering, National Uni versity of Sing apore 2 School of Computer Science, Nanjing Uni versity of Science and T echnology 3 K ey Laboratory of Machine Perception (MOE), School of EECS, Peking Uni versity canyilu@gmail.com, jinhuitang@mail.njust.edu.cn, eleyans@nus.edu.sg, zlin@pku.edu.cn Abstract As surr ogate functions of L 0 -norm, many nonconve x penalty functions have been pr oposed to enhance the sparse vector reco very . It is easy to extend these nonconve x penalty functions on singular values of a matrix to enhance low- rank matrix reco very . However , dif fer ent fr om conve x op- timization, solving the noncon vex low-r ank minimization pr oblem is muc h mor e c hallenging than the nonconve x sparse minimization problem. W e observe that all the ex- isting noncon vex penalty functions ar e concave and mono- tonically incr easing on [0 , ∞ ) . Thus their gradients are decr easing functions. Based on this pr operty , we pr opose an Iteratively Reweighted Nuclear Norm (IRNN) algorithm to solve the noncon vex nonsmooth low-r ank minimization pr oblem. IRNN iter atively solves a W eighted Singular V alue Thr esholding (WSVT) pr oblem. By setting the weight vector as the gradient of the concave penalty function, the WSVT pr oblem has a closed form solution. In theory , we pr ove that IRNN decr eases the objective function value monoton- ically , and any limit point is a stationary point. Extensive experiments on both synthetic data and r eal imag es demon- strate that IRNN enhances the low-rank matrix r ecovery compar ed with state-of-the-art conve x algorithms. 1. Introduction This paper aims to solve the following general noncon- ve x nonsmooth lo w-rank minimization problem min X ∈ R m × n F ( X ) = m X i =1 g λ ( σ i ( X )) + f ( X ) , (1) where σ i ( X ) denotes the i -th singular value of X ∈ R m × n (we assume m ≤ n in this work). The penalty function g λ and loss function f satisfy the follo wing assumptions: A1 g λ : R → R + is continuous, concav e and monotoni- cally increasing on [0 , ∞ ) . It is possibly nonsmooth. ∗ Corresponding author . 0 2 4 6 0 1 2 3 θ Penalty g( θ ) 0 2 4 6 0 50 100 150 200 θ Supergradient ∂ g( θ ) (a) L p Penalty [ 11 ] 0 2 4 6 0 0.5 1 1.5 2 θ Penalty g( θ ) 0 2 4 6 0 0.5 1 θ Supergradient ∂ g( θ ) (b) SCAD Penalty [ 10 ] 0 2 4 6 0 1 2 3 θ Penalty g( θ ) 0 2 4 6 0 0.5 1 1.5 θ Supergradient ∂ g( θ ) (c) Logarithm Penalty [ 12 ] 0 2 4 6 0 0.5 1 1.5 2 θ Penalty g( θ ) 0 2 4 6 0 0.5 1 θ Supergradient ∂ g( θ ) (d) MCP Penalty [ 23 ] 0 2 4 6 0 0.5 1 1.5 2 θ Penalty g( θ ) 0 2 4 6 0 0.5 1 θ Supergradient ∂ g( θ ) (e) Capped L 1 Penalty [ 24 ] 0 2 4 6 0 0.5 1 1.5 2 θ Penalty g( θ ) 0 2 4 6 0 0.5 1 1.5 2 θ Supergradient ∂ g( θ ) (f) ETP Penalty [ 13 ] 0 2 4 6 0 0.5 1 1.5 2 θ Penalty g( θ ) 0 2 4 6 0 0.2 0.4 0.6 0.8 θ Supergradient ∂ g( θ ) (g) Geman Penalty [ 15 ] 0 2 4 6 0 0.5 1 1.5 2 θ Penalty g( θ ) 0 2 4 6 0 0.2 0.4 0.6 0.8 θ Supergradient ∂ g( θ ) (h) Laplace Penalty [ 21 ] Figure 1: Illustration of the popular noncon vex surrogate func- tions of || θ || 0 (left), and their super gradients (right). All these penalty functions share the common properties: concav e and monotonically increasing on [0 , ∞ ) . Thus their supergradients (see Section 2.1 ) are nonnegati ve and monotonically decreasing. Our proposed general solver is based on this ke y observation. A2 f : R m × n → R + is a smooth function of type C 1 , 1 , i.e., the gradient is Lipschitz continuous, ||∇ f ( X ) − ∇ f ( Y ) || F ≤ L ( f ) || X − Y || F , (2) for any X , Y ∈ R m × n , L ( f ) > 0 is called Lipschitz constant of ∇ f . f ( X ) is possibly noncon ve x. A3 F ( X ) → ∞ iff || X || F → ∞ . 1 T able 1: Popular noncon vex surrogate functions of || θ || 0 and their supergradients. Penalty Formula g λ ( θ ) , θ ≥ 0 , λ > 0 Supergradient ∂ g λ ( θ ) L p [ 11 ] λθ p ( ∞ , if θ = 0 , λpθ p − 1 , if θ > 0 . SCAD [ 10 ] λθ, if θ ≤ λ, − θ 2 +2 γ λθ − λ 2 2( γ − 1) , if λ < θ ≤ γ λ, λ 2 ( γ +1) 2 , if θ > γ λ. λ, if θ ≤ λ, γ λ − θ γ − 1 , if λ < θ ≤ γ λ, 0 , if θ > γ λ. Logarithm [ 12 ] λ log( γ +1) log( γ θ + 1) γ λ ( γ θ +1) log( γ +1) MCP [ 23 ] ( λθ − θ 2 2 γ , if θ < γ λ, 1 2 γ λ 2 , if θ ≥ γ λ. ( λ − θ γ , if θ < γ λ, 0 , if θ ≥ γ λ. Capped L 1 [ 24 ] ( λθ, if θ < γ , λγ , if θ ≥ γ . λ, if θ < γ , [0 , λ ] , if θ = γ, 0 , if θ > γ . ETP [ 13 ] λ 1 − exp( − γ ) (1 − exp( − γ θ )) λγ 1 − exp( − γ ) exp( − γ θ ) Geman [ 15 ] λθ θ + γ λγ ( θ + γ ) 2 Laplace [ 21 ] λ (1 − exp( − θ γ )) λ γ exp( − θ γ ) Many optimization problems in machine learning and computer vision areas fall into the formulation in ( 1 ). As for the choice of f , the squared loss f ( X ) = 1 2 ||A ( X ) − b || 2 F , with a linear mapping A , is widely used. In this case, the Lipschitz constant of ∇ f is then the spectral radius of A ∗ A , i.e., L ( f ) = ρ ( A ∗ A ) , where A ∗ is the adjoint operator of A . By choosing g λ ( x ) = λx , P m i =1 g λ ( σ i ( X )) is exactly the nuclear norm λ P m i =1 σ i ( X ) = λ || X || ∗ . Problem ( 1 ) resorts to the well known nuclear norm regularized problem min X λ || X || ∗ + f ( X ) . (3) If f ( X ) is con ve x, it is the most widely used con ve x relax- ation of the rank minimization problem: min X λ rank ( X ) + f ( X ) . (4) The abov e lo w-rank minimization problem arises in many machine learning tasks such as multiple cate gory classifi- cation [ 1 ], matrix completion [ 20 ], multi-task learning [ 2 ], and low-rank representation with squared loss for subspace segmentation [ 18 ]. Ho wev er , solving problem ( 4 ) is usu- ally dif ficult, or ev en NP-hard. Most previous works solv e the con ve x problem ( 3 ) instead. It has been proved that un- der certain incoherence assumptions on the singular v alues of the matrix, solving the con vex nuclear norm regularized problem leads to a near optimal low-rank solution [ 6 ]. Ho w- ev er, such assumptions may be violated in real applications. The obtained solution by using nuclear norm may be sub- optimal since it is not a perfect approximation of the rank function. A similar phenomenon has been observed in the con vex L 1 -norm and nonconv ex L 0 -norm for sparse vector recov ery [ 7 ]. In order to achie ve a better approximation of the L 0 - norm, many nonconv ex surrogate functions of L 0 -norm hav e been proposed, including L p -norm [ 11 ], Smoothly Clipped Absolute De viation (SCAD) [ 10 ], Logarithm [ 12 ], Minimax Concave Penalty (MCP) [ 23 ], Capped L 1 [ 24 ], Exponential-T ype Penalty (ETP) [ 13 ], Geman [ 15 ], and Laplace [ 21 ]. T able 1 tabulates these penalty functions and Figure 1 visualizes them. One may refer to [ 14 ] for more properties of these penalty functions. Some of these non- con vex penalties have been extended to approximate the rank function, e.g. the Schatten- p norm [ 19 ]. Another non- con vex surrogate of rank function is the truncated nuclear norm [ 16 ]. For nonconv ex sparse minimization, se veral algorithms hav e been proposed to solve the problem with a noncon ve x regularizer . A common method is DC (Difference of Con- ve x functions) programming [ 14 ]. It minimizes the non- con vex function f ( x ) − ( − g λ ( x )) based on the assumption that both f and − g λ are conv ex. In each iteration, DC pro- gramming linearizes − g λ ( x ) at x = x k , and minimizes the relaxed function as follo ws x k +1 = arg min x f ( x ) − ( − g λ ( x k )) − v k , x − x k , (5) where v k is a subgradient of − g λ ( x ) at x = x k . DC pro- gramming may be not very efficient, since it requires some other iterativ e algorithm to solv e ( 5 ). Note that the updating rule ( 5 ) of DC programming cannot be extended to solve the low-rank problem ( 1 ). The reason is that for concav e g λ , − P m i =1 g λ ( σ i ( X )) does not guarantee to be con ve x w .r .t. X . DC programming also fails when f is nonconv ex in problem ( 1 ). Another solver is to use the proximal gradient algorithm which is originally designed for con vex problem [ 3 ]. It re- quires computing the proximal operator of g λ , P g λ ( y ) = arg min x g λ ( x ) + 1 2 ( x − y ) 2 , (6) in each iteration. Howe ver , for nonconv ex g λ , there may not exist a general solver for ( 6 ). Even if ( 6 ) is solvable, dif fer- ent from con ve x optimization, ( P g λ ( y 1 ) − P g λ ( y 2 ))( y 1 − y 2 ) ≥ 0 does not always hold. Thus we cannot perform 2 P g λ ( · ) on the singular values of Y directly for solving P g λ ( Y ) = arg min X m X i =1 g λ ( σ i ( X )) + || X − Y || 2 F . (7) The noncon vexity of g λ makes the noncon vex lo w-rank minimization problem much more challenging than the noncon vex sparse minimization. Another related work is the Iterati vely Reweighted Least Squares (IRLS) algorihtm. It has been recently extended to handle the noncon vex Schatten- p norm penalty [ 19 ]. Actu- ally it solves a relaxed smooth problem which may require many iterations to achiev e a lo w-rank solution. It cannot solve the general nonsmooth problem ( 1 ). The alternativ e updating algorithm in [ 16 ] minimizes the truncated nuclear norm by using a special property of this penalty . It contains two loops, both of which require computing SVD. Thus it is not very efficient. It cannot be extended to solve the general problem ( 1 ) either . In this work, all the existing noncon vex surrogate func- tions of L 0 -norm are extended on the singular values of a matrix to enhance low-rank recovery . In problem ( 1 ), g λ can be any existing noncon ve x penalty function sho wn in T able 1 or any other function which satisfies the assump- tion ( A1 ). W e observe that all the existing nonconv ex sur- rogate functions are conca ve and monotonically increas- ing on [0 , ∞ ) . Thus their gradients (or supergradients at the nonsmooth points) are nonnegati ve and monotonically decreasing. Based on this ke y fact, we propose an Itera- tiv ely Reweighted Nuclear Norm (IRNN) algorithm to solve problem ( 1 ). IRNN computes the proximal operator of the weighted nuclear norm, which has a closed form solution due to the nonnegati ve and monotonically decreasing su- pergradients. In theory , we prov e that IRNN monotonically decreases the objective function value, and any limit point is a stationary point. T o the best of our knowledge, IRNN is the first w ork which is able to solve the general problem ( 1 ) with con vergence guarantee. Note that for noncon- vex optmization, it is usually very difficult to pr ove that an algorithm con verges to stationary points . At last, we test our algorithm with se veral noncon vex penalty functions on both synthetic data and real image data to show the ef- fectiv eness of the proposed algorithm. 2. Nonconv ex Nonsmooth Low-Rank Mini- mization In this section, we present a general algorithm to solve problem ( 1 ). T o handle the case that g λ is nonsmooth, e.g., Capped L 1 penalty , we need the concept of supergradient defined on the concav e function. 1 1 1 g( ) T x v x x 1 x 2 x 2 3 2 g( ) T x v x x 2 2 2 g( ) T x v x x g( ) x Figure 2: Supergraidients of a concav e function. v 1 is a super - gradient at x 1 , and v 2 and v 3 are supergradients at x 2 . 2.1. Supergradient of a Conca ve Function The subgradient of the con ve x function is an extension of gradient at a nonsmooth point. Similarly , the supergradi- ent is an extension of gradient of the concave function at a nonsmooth point. If g ( x ) is conca ve and dif ferentiable at x , it is known that g ( x ) + h∇ g ( x ) , y − x i ≥ g ( y ) . (8) If g ( x ) is nonsmooth at x , the supergradient extends the gradient at x inspired by ( 8 ) [ 5 ]. Definition 1 Let g : R n → R be concave. A vector v is a super gradient of g at the point x ∈ R n if for every y ∈ R n , the following inequality holds g ( x ) + h v , y − x i ≥ g ( y ) . (9) All super gradients of g at x are called the superdif ferential of g at x , and are denoted as ∂ g ( x ) . If g is differentiable at x , ∇ g ( x ) is also a supergradient, i.e., ∂ g ( x ) = {∇ g ( x ) } . Figure 2 illustrates the supergradients of a concave function at both differentiable and nondif ferentiable points. For concave g , − g is con ve x, and vice versa. From this fact, we have the following relationship between the super- gradient of g and the subgradient of − g . Lemma 1 Let g ( x ) be concave and h ( x ) = − g ( x ) . F or any v ∈ ∂ g ( x ) , u = − v ∈ ∂ h ( x ) , and vice versa. The relationship of the supergradient and subgradient shown in Lemma 1 is useful for exploring some properties of the supergradient. It is kno wn that the subdiffierential of a con vex function h is a monotone operator, i.e., h u − v , x − y i ≥ 0 , (10) for any u ∈ ∂ h ( x ) , v ∈ ∂ h ( y ) . The superdifferential of a concav e function holds a similar property , which is called antimonotone operator in this work. Lemma 2 The super differ ential of a concave function g is an antimonotone operator , i.e., h u − v , x − y i ≤ 0 , (11) for any u ∈ ∂ g ( x ) , v ∈ ∂ g ( y ) . 3 This can be easily prov ed by Lemma 1 and ( 10 ). Lemma 2 is a key lemma in this work. Supposing that the assumption ( A1 ) holds for g ( x ) , ( 11 ) indicates that u ≥ v , for any u ∈ ∂ g ( x ) and v ∈ ∂ g ( y ) , (12) when x ≤ y . That is to say , the supergradient of g is mono- tonically decreasing on [0 , ∞ ) . T able 1 shows some usual concav e functions and their supergradients. W e also visual- ize them in Figure 1 . It can be seen that the y all satisfy the assumption ( A1 ). Note that for the L p penalty , we further define that ∂ g (0) = ∞ . This will not af fect our algorithm and conv ergence analysis as shown latter . The Capped L 1 penalty is nonsmooth at θ = γ , with the superdifferential ∂ g λ ( γ ) = [0 , λ ] . 2.2. Iteratively Reweighted Nuclear Norm In this subsection, we show ho w to solve the general non- con vex and possibly nonsmooth problem ( 1 ) based on the assumptions ( A1 )-( A2 ). F or simplicity of notation, we de- note σ i = σ i ( X ) and σ k i = σ i ( X k ) . Since g λ is concave on [0 , ∞ ) , by the definition of the supergradient, we ha ve g λ ( σ i ) ≤ g λ ( σ k i ) + w k i ( σ i − σ k i ) , (13) where w k i ∈ ∂ g λ ( σ k i ) . (14) Since σ k 1 ≥ σ k 2 ≥ · · · ≥ σ k m ≥ 0 , by the antimonotone property of supergradient ( 12 ), we ha ve 0 ≤ w k 1 ≤ w k 2 ≤ · · · ≤ w k m . (15) This property is important in our algorithm shown latter . ( 13 ) motiv ates us to minimize its right hand side instead of g λ ( σ i ) . Thus we may solve the following relax ed problem X k +1 = arg min X m X i =1 g λ ( σ k i ) + w k i ( σ i − σ k i ) + f ( X ) = arg min X m X i =1 w k i σ i + f ( X ) . (16) It seems that updating X k +1 by solving the abo ve weighted nuclear norm problem ( 16 ) is an extension of the weighted L 1 -norm problem in IRL1 algorithm [ 7 ] (IRL1 is a special DC programming algorithm). Howe ver , the weighted nu- clear norm is nonconv ex in ( 16 ) (it is con vex if and only if w k 1 ≥ w k 2 ≥ · · · ≥ w k m ≥ 0 [ 8 ]), while the weighted L 1 -norm is con vex. Solving the nonconv ex problem ( 16 ) is much more challenging than the con ve x weighted L 1 -norm problem. In fact, it is not easier than solving the original problem ( 1 ). Algorithm 1 Solving problem ( 1 ) by IRNN Input: µ > L ( f ) - A Lipschitz constant of ∇ f ( X ) . Initialize: k = 0 , X k , and w k i , i = 1 , · · · , m . Output: X ∗ . while not con verge do 1. Update X k +1 by solving problem ( 18 ). 2. Update the weights w k +1 i , i = 1 , · · · , m , by w k +1 i ∈ ∂ g λ σ i ( X k +1 ) . (17) end while Instead of updating X k +1 by solving ( 16 ), we linearize f ( X ) at X k and add a proximal term: f ( X ) ≈ f ( X k ) + h∇ f ( X k ) , X − X k i + µ 2 || X − X k || 2 F , where µ > L ( f ) . Such a choice of µ guarantees the con- ver gence of our algorithm as sho wn latter . Then we update X k +1 by solving X k +1 = arg min X m X i =1 w k i σ i + f ( X k ) + h∇ f ( X k ) , X − X k i + µ 2 || X − X k || 2 F = arg min X m X i =1 w k i σ i + µ 2 X − X k − 1 µ ∇ f ( X k ) 2 F . (18) Problem ( 18 ) is still noncon vex. Fortunately , it has a closed form solution due to ( 15 ). Lemma 3 [ 8 , Theor em 2.3] F or any λ > 0 , Y ∈ R m × n and 0 ≤ w 1 ≤ w 2 ≤ · · · ≤ w s ( s = min( m, n )) , a glob- ally optimal solution to the following pr oblem min λ s X i =1 w i σ i ( X ) + 1 2 || X − Y || 2 F , (19) is given by the weighted singular value thr esholding X ∗ = U S λ w ( Σ ) V T , (20) wher e Y = U Σ V T is the SVD of Y , and S λ w ( Σ ) = Diag { ( Σ ii − λw i ) + } . It is w orth mentioning that for the L p penalty , if σ k i = 0 , w k i ∈ ∂ g λ ( σ k i ) = {∞} . By the updating rule of X k +1 in ( 18 ), we have σ k +1 i = 0 . This guarantees that the rank of the sequence { X k } is nonincreasing. 4 Iterativ ely updating w k i , i = 1 , · · · , m , by ( 14 ) and X k +1 by ( 18 ) leads to the proposed Iterativ ely Reweighted Nuclear Norm (IRNN) algorithm. The whole procedure of IRNN is sho wn in Algorithm 1 . If the Lipschitz constant L ( f ) is not known or computable, the backtracking rule can be used to estimate µ in each iteration [ 3 ]. 3. Con vergence Analysis In this section, we give the con vergence analysis for the IRNN algorithm. W e will show that IRNN decreases the objectiv e function v alue monotonically , and an y limit point is a stationary point of problem ( 1 ). W e first recall the fol- lowing well-kno wn and fundamental property for a smooth function in the class C 1 , 1 . Lemma 4 [ 4 , 3 ] Let f : R m × n → R be a continuously dif- fer entiable function with Lipschitz continuous gradient and Lipschitz constant L ( f ) . Then, for any X , Y ∈ R m × n , and µ ≥ L ( f ) , f ( X ) ≤ f ( Y ) + h X − Y , ∇ f ( Y ) i + µ 2 || X − Y || 2 F . (21) Theorem 1 Assume that g λ and f in problem ( 1 ) satisfy the assumptions ( A1 )-( A2 ). The sequence { X k } gener ated in Algorithm 1 satisfies the following pr operties: (1) F ( X k ) is monotonically decr easing. Indeed, F ( X k ) − F ( X k +1 ) ≥ µ − L ( f ) 2 || X k − X k +1 || 2 F ≥ 0; (2) lim k →∞ ( X k − X k +1 ) = 0 ; (3) The sequence { X k } is bounded. Proof . First, since X k +1 is a global solution to problem ( 18 ), we get m X i =1 w k i σ k +1 i + h∇ f ( X k ) , X k +1 − X k i + µ 2 || X k +1 − X k || 2 F ≤ m X i =1 w k i σ k i + h∇ f ( X k ) , X k − X k i + µ 2 || X k − X k || 2 F . It can be rewritten as h∇ f ( X k ) , X k − X k +1 i ≥ − m X i =1 w k i ( σ k i − σ k +1 i ) + µ 2 || X k − X k +1 || 2 F . (22) Second, since the gradient of f ( X ) is Lipschitz continuous, by using Lemma 4 , we hav e f ( X k ) − f ( X k +1 ) ≥h∇ f ( X k ) , X k − X k +1 i − L ( f ) 2 || X k − X k +1 || 2 F . (23) Third, since w k i ∈ ∂ g λ ( σ k i ) , by the definition of the super- gradient, we hav e g λ ( σ k i ) − g λ ( σ k +1 i ) ≥ w k i ( σ k i − σ k +1 i ) . (24) Now , summing ( 22 ), ( 23 ) and ( 24 ) for i = 1 , · · · , m , to- gether , we obtain F ( X k ) − F ( X k +1 ) = m X i =1 g λ ( σ k i ) − g λ ( σ k +1 i ) + f ( X k ) − f ( X k +1 ) ≥ µ − L ( f ) 2 || X k +1 − X k || 2 F ≥ 0 . (25) Thus F ( X k ) is monotonically decreasing. Summing all the inequalities in ( 25 ) for k ≥ 1 , we get F ( X 1 ) ≥ µ − L ( f ) 2 ∞ X k =1 || X k +1 − X k || 2 F , (26) or equiv alently , ∞ X k =1 || X k − X k +1 || 2 F ≤ 2 F ( X 1 ) µ − L ( f ) . (27) In particular, it implies that lim k →∞ ( X k − X k +1 ) = 0 . The boundedness of { X k } is obtained based on the assumption ( A3 ). Theorem 2 Let { X k } be the sequence generated in Algo- rithm 1 . Then any accumulation point X ∗ of { X k } is a stationary point of ( 1 ). Proof . The sequence { X k } generated in Algorithm 1 is bounded as shown in Theorem 1 . Thus there exists a matrix X ∗ and a subsequence { X k j } such that lim j →∞ X k j = X ∗ . From the f act that lim k →∞ ( X k − X k +1 ) = 0 in Theorem 1 , we hav e lim j →∞ X k j +1 = X ∗ . Thus σ i ( X k j +1 ) → σ i ( X ∗ ) for i = 1 , · · · , m . By the choice of w k j i ∈ ∂ g λ ( σ i ( X k j )) and Lemma 1 , we ha ve − w k j i ∈ ∂ − g λ ( σ i ( X k j )) . By the upper semi-continuous property of the subdifferential [ 9 , Proposition 2.1.5], there exists − w ∗ i ∈ ∂ ( − g λ ( σ i ( X ∗ ))) such that − w k j i → − w ∗ i . Again by Lemma 1 , w ∗ i ∈ ∂ g λ ( σ i ( X ∗ )) and w k j i → w ∗ i . Denote h ( X , w ) = P m i =1 w i σ i ( X ) . Since X k j +1 is optimal to problem ( 18 ), there exists G k j +1 ∈ ∂ h ( X k j +1 , w k j ) , such that G k j +1 + ∇ f ( X k j ) + µ ( X k j +1 − X k j ) = 0 . (28) Let j → ∞ in ( 28 ), there exists G ∗ ∈ ∂ h ( X ∗ , w ∗ ) , such that 0 = G ∗ + ∇ f ( X ∗ ) ∈ ∂ F ( X ∗ ) . (29) Thus X ∗ is a stationary point of ( 1 ). 5 4. Extension to Other Problems Our proposed IRNN algorithm can solve a more general low-rank minimization problem as follo ws, min X m X i =1 g i ( σ i ( X )) + f ( X ) , (30) where g i , i = 1 , · · · , m , are concave, and their super- gradients satisfy 0 ≤ v 1 ≤ v 2 ≤ · · · ≤ v m , for an y v i ∈ ∂ g i ( σ i ( X )) , i = 1 , · · · , m . The truncated nuclear norm || X || r = P m i = r +1 σ i ( X ) [ 16 ] satisfies the above as- sumption. Indeed, || X || r = P m i =1 g i ( σ i ( X )) by letting g i ( x ) = ( 0 , i = 1 , · · · , r , x, i = r + 1 , · · · , m. (31) Their supergradients are ∂ g i ( x ) = ( 0 , i = 1 , · · · , r , 1 , i = r + 1 , · · · , m. (32) The con ver gence results in Theorem 1 and 2 also hold since ( 24 ) holds for each g i . Compared with the alternating up- dating algorithms in [ 16 ], which require double loops, our IRNN algorithm will be more efficient and with stronger con vergence guarantee. More generally , IRNN can solve the follo wing problem min X m X i =1 g ( h ( σ i ( X ))) + f ( X ) , (33) when g ( y ) is conca ve, and the follo wing problem min X w i h ( σ i ( X )) + || X − Y || 2 F , (34) can be cheaply solved. An interesting application of ( 33 ) is to extend the group sparsity on the singular values. By dividing the singular values into k groups, i.e., G 1 = { 1 , · · · , r 1 } , G 2 = { r 1 + 1 , · · · , r 1 + r 2 − 1 } , · · · , G k = { P k − 1 i r i + 1 , · · · , m } , where P i r i = m , we can de- fine the group sparsity on the singular values as || X || 2 ,g = P k i =1 g ( || σ G i || 2 ) . This is exactly the first term in ( 33 ) by letting h be the L 2 -norm of a vector . g can be noncon- ve x functions satisfying the assumption ( A1 ) or specially the con vex absolute function. 5. Experiments In this section, we present several experiments on both synthetic data and real images to validate the ef fectiveness of the IRNN algorithm. W e test our algorithm on the matrix completion problem min X m X i =1 g λ ( σ i ( X )) + 1 2 ||P Ω ( X − M ) || 2 F , (35) 20 22 24 26 28 30 32 34 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Rank Frequency of Sucess ALM IRNN-Lp IRNN-SCA D IRNN-Logarithm IRNN-MCP IRNN-ETP (a) random data without noise 15 20 25 30 35 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 Rank Relative Er ror APGL IRNN - Lp IRNN - SCA D IRNN - Logarithm IRNN - MCP IRNN - ETP (b) random data with noise Figure 3: Comparison of matrix recovery on (a) random data without noise, and (b) random data with noise. where Ω is the set of indices of samples, and P Ω : R m × n → R m × n is a linear operator that keeps the entries in Ω un- changed and those outside Ω zeros. The gradient of squared loss function in ( 35 ) is Lipschitz continuous, with a Lips- chitz constant L ( f ) = 1 . W e set µ = 1 . 1 in Algorithm 1 . For the choice of g λ , we test all the penalty functions listed in T able 1 except for Capped L 1 and Geman, since we find that their reco very performances are sensiti ve to the choices of γ and λ in different cases. For the choice of λ in IRNN, we use a continuation technique to enhance the low-rank matrix reco very . The initial value of λ is set to a larger value λ 0 , and dynamically decreased by λ = η k λ 0 with η < 1 . It is stopped till reaching a predefined target λ t . X is initialized as a zero matrix. F or the choice of parame- ters (e.g., p and γ ) in the noncon ve x penalty functions, we search it from a candidate set and use the one which obtains good performance in most cases 1 . 5.1. Low-Rank Matrix Recov ery W e first compare our noncon vex IRNN algorithm with state-of-the-art con vex algorithms on synthetic data. W e conduct two experiments. One is for the observ ed matrix M without noise, and the other one is for M with noise. For the noise free case, we generate the rank r matrix M as M L M R , where M L ∈ R 150 × r , and M R ∈ R r × 150 are generated by the Matlab command randn . 50% elements of M are missing uniformly at random. W e compare our algorithm with Augmented Lagrange Multiplier (ALM) 2 [ 17 ] which solves the noise free problem min X || X || ∗ s.t. P Ω ( X ) = P Ω ( M ) . (36) For this task, we set λ 0 = ||P Ω ( M ) || ∞ , λ t = 10 − 5 λ 0 , and η = 0 . 7 in IRNN, and stop the algorithm when ||P Ω ( X − M ) || F ≤ 10 − 5 . For ALM, we use the default parameters in the released codes. W e ev aluate the recov- ery performance by the Relativ e Error defined as || ˆ X − 1 Code of IRNN: https://sites.google.com/site/canyilu/ . 2 Code: http://perception.csl.illinois.edu/matrix- rank/ sample_code.html . 6 (1) (2) (a) Original Image (b) Noisy Image (c) APGL (d) LMa Fit (e) TNNR - ADMM (f) I RNN - L p (g) IRNN - SCAD Figure 4: Comparison of image recovery by using dif ferent matrix completion algorithms. (a) Original image. (b) Image with Gaussian noise and text. (c)-(g) Recov ered images by APGL, LMaFit, TNNR-ADMM, IRNN- L p , and IRNN-SCAD, respectiv ely . Best viewed in × 2 sized color pdf file. M || F / || M || F , where ˆ X is the recov ered solution by a cer- tain algorithm. If the Relativ e Error is smaller than 10 − 3 , ˆ X is regarded as a successful recov ery of M . W e repeat the experiments 100 times with the underlying rank r v ary- ing from 20 to 33 for each algorithm. The frequency of success is plotted in Figure 3a . The legend IRNN- L p in Figure 3a denotes the L p penalty function used in problem ( 1 ) and solv ed by our proposed IRNN algorithm. It can be seen that IRNN with all the noncon vex penalty functions achiev es much better recov ery performance than the con- ve x ALM algorithm. This is because the nonconv ex penalty functions approximate the rank function better than the con- ve x nuclear norm. For the noisy case, the data are generated by P Ω ( M ) = P Ω ( M L M R ) +0.1 × randn . W e compare our algorithm with con vex Accelerated Proximal Gradient with Line search (APGL) 3 [ 20 ] which solves the noisy problem min X λ || X || ∗ + 1 2 ||P Ω ( X ) − P Ω ( M ) || 2 F . (37) For this task, we set λ 0 = 10 ||P Ω ( M ) || ∞ , and λ t = 0 . 1 λ 0 in IRNN. All the chosen algorithms are run 100 times with the underlying rank r lying between 15 and 35. The rela- tiv e errors can be ranging for each test, and the mean er- rors by dif ferent methods are plotted in Figure 3b . It can be seen that IRNN for the noncon ve x penalty outperforms the con ve x APGL for the noisy case. Note that we cannot conclude from Figure 3 that IRNN with L p , Logarithm and ETP penalty functions always perform better than SCAD and MCP , since the obtained solutions are not globally op- timal. 5.2. A pplication to Image Recovery In this section, we apply matrix completion for image recov ery . As shown in Figure 4 , the real image may be corrupted by dif ferent types of noises, e.g., Gaussian noise 3 Code: http://www.math.nus.edu.sg/ ˜ mattohkc/NNLS.html . or unrelated text. Usually the real images are not of lo w- rank, but the top singular v alues dominate the main in- formation [ 16 ]. Thus the corrupted image can be recov- ered by low-rank approximation. For color images which hav e three channels, we simply apply matrix completion for each channel independently . The well known Peak Signal-to-Noise Ratio (PSNR) is employed to ev aluate the recov ery performance. W e compare IRNN with some other matrix completion algorithms which have been applied for this task, including APGL, Low-Rank Matrix Fitting (LMaFit) 4 . [ 22 ] and T runcated Nuclear Norm Regulariza- tion (TNNR) [ 16 ]. W e use the solver based on ADMM to solve a subproblem of TNNR in the released codes (denoted as TNNR-ADMM) 5 . W e try to tune the parameters to be optimal of the chosen algorithms and report the best result. In our test, we consider two types of noises on the real images. The first one replaces 50% of pixels with random values (sample image (1) in Figure 4 (b)). The other one adds some unrelated texts on the image (sample image (2) in Figure 4 (b)). Figure 4 (c)-(g) sho w the reco vered images by different methods. It can be observed that our IRNN method with dif ferent penalty functions achie ves much bet- ter recovery performance than APGL and LMaFit. Only the results by IRNN- L p and IRNN-SCAD are plotted due to the limit of space. W e further test on more images and plot the results in Figure 5 . Figure 6 shows the PSNR val- ues of dif ferent methods on all the test images. It can be seen that IRNN with all the e valuated noncon vex functions achiev es higher PSNR values, which verifies that the non- con vex penalty functions are effecti ve in this situation. The noncon vex truncated nuclear norm is close to our methods, but its running time is 3 ∼ 5 times of that for ours. 6. Conclusions and Future W ork In this work, the nonconv ex surrogate functions of L 0 - norm are extended on the singular values to approximate 4 Code: http://lmafit.blogs.rice.edu/ . 5 Code: https://sites.google.com/site/zjuyaohu/ . 7 I m age r ec ov er y by A P G L lp I m age r ec ov er y by A P G L lp I m age r ec ov er y by A P G L lp ( 3 ) ( 4 ) ( 5 ) ( 6 ) (a) Original Image (b) Noisy Image (c) APGL (d) IRNN - L p Figure 5: Comparison of image recov ery on more images. (a) Original images. (b) Images with noises. Recovered images by (c) APGL, and (d) IRNN- L p . Best viewed in × 2 sized color pdf file. the rank function. It is observed that all the existing non- con vex surrogate functions are conca ve and monotonically increasing on [0 , ∞ ) . Then a general solver IRNN is pro- posed to solve problem ( 1 ) with such penalties. IRNN is the first algorithm which is able to solve the general noncon- ve x low-rank minimization problem ( 1 ) with con ver gence guarantee. The nonconv ex penalty can be nonsmooth by using the super gradient at the nonsmooth point. In theory , we proved that any limit point is a local minimum. Ex- periments on both synthetic data and real images demon- strated that IRNN usually outperforms the state-of-the-art con vex algorithms. An interesting future work is to solv e the nonconv ex lo w-rank minimization problem with affine constraint. A possible way is to combine IRNN with Alter- nating Direction Method of Multiplier (ADMM). Acknowledgements This research is supported by the Singapore National Research Foundation under its International Research Cen- tre @Singapore Funding Initiati ve and administered by the IDM Programme Of fice. Z. Lin is supported by NSF of China (Grant nos. 61272341, 61231002, and 61121002) and MSRA. References [1] Y . Amit, M. Fink, N. Srebro, and S. Ullman. Uncov ering shared structures in multiclass classification. In ICML , 2007. [2] A. Argyriou, T . Evgeniou, and M. Pontil. Con vex multi-task feature learning. Machine Learning , 2008. Image (1) Image (2) Image (3) Image (4) Image (5) Image (6) 0 5 10 15 20 25 30 35 40 45 PSNR APGL LMaFit TNNR - ADM M IRNN - Lp IRNN - SCAD IRNN - Logarithm IRNN - MCP IRNN - ETP Figure 6: Comparison of the PSNR values by different matrix completion algorithms. [3] A. Beck and M. T eboulle. A fast iterati ve shrinkage-thresholding algorithm for linear in verse problems. SIAM Journal on Imaging Sciences , 2009. [4] D. P . Bertsekas. Nonlinear progr amming . Athena Scientific (Belmont, Mass.), 2nd edition, 1999. [5] K. Border . The supergradient of a concave function. http://www.hss. caltech.edu/ ˜ kcb/Notes/Supergrad.pdf , 2001. [Online]. [6] E. Cand ` es and T . T ao. The power of conve x relaxation: Near-optimal matrix completion. IEEE T ransactions on Information Theory , 2010. [7] E. Cand ` es, M. W akin, and S. Boyd. Enhancing sparsity by reweighted ` 1 min- imization. Journal of F ourier Analysis and Applications , 2008. [8] K. Chen, H. Dong, and K. Chan. Reduced rank regression via adaptiv e nuclear norm penalization. Biometrika , 2013. [9] F . Clarke. Nonsmooth analysis and optimization. In Proceedings of the Inter- national Congr ess of Mathematicians , 1983. [10] J. Fan and R. Li. V ariable selection via nonconcav e penalized likelihood and its oracle properties. Journal of the American Statistical Association , 2001. [11] L. Frank and J. Friedman. A statistical view of some chemometrics regression tools. T echnometrics , 1993. [12] J. Friedman. Fast sparse regression and classification. International Journal of F orecasting , 2012. [13] C. Gao, N. W ang, Q. Y u, and Z. Zhang. A feasible nonconve x relaxation ap- proach to feature selection. In AAAI , 2011. [14] G. Gasso, A. Rakotomamonjy , and S. Canu. Recovering sparse signals with a certain family of nonconv ex penalties and DC programming. IEEE T ransac- tions on Signal Pr ocessing , 2009. [15] D. Geman and C. Y ang. Nonlinear image recovery with half-quadratic regular- ization. TIP , 1995. [16] Y . Hu, D. Zhang, J. Y e, X. Li, and X. He. Fast and accurate matrix completion via truncated nuclear norm regularization. TP AMI , 2013. [17] Z. Lin, M. Chen, L. W u, and Y . Ma. The augmented lagrange multiplier method for exact recovery of a corrupted low-rank matrices. UIUC T echnical Report UILU-ENG-09-2215, T ech. Rep. , 2009. [18] G. Liu, Z. Lin, S. Y an, J. Sun, Y . Y u, and Y . Ma. Robust recovery of subspace structures by low-rank representation. TP AMI , 2013. [19] K. Mohan and M. Fazel. Iterati ve reweighted algorithms for matrix rank mini- mization. In JMLR , 2012. [20] K. T oh and S. Y un. An accelerated proximal gradient algorithm for nuclear norm regularized linear least squares problems. P acific Journal of Optimization , 2010. [21] J. Trzasko and A. Manduca. Highly undersampled magnetic resonance image reconstruction via homotopic ` 0 -minimization. TMI , 2009. [22] Z. W en, W . Y in, and Y . Zhang. Solving a lo w-rank f actorization model for matrix completion by a nonlinear successive over -relaxation algorithm. Math- ematical Pr ogramming Computation , 2012. [23] C. Zhang. Nearly unbiased variable selection under minimax concave penalty . The Annals of Statistics , 2010. [24] T . Zhang. Analysis of multi-stage conve x relaxation for sparse regularization. JMLR , 2010. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment