Discrete Denoising with Shifts
We introduce S-DUDE, a new algorithm for denoising DMC-corrupted data. The algorithm, which generalizes the recently introduced DUDE (Discrete Universal DEnoiser) of Weissman et al., aims to compete with a genie that has access, in addition to the no…
Authors: ** Y. Weissman, A. Orlitsky, N. Merhav
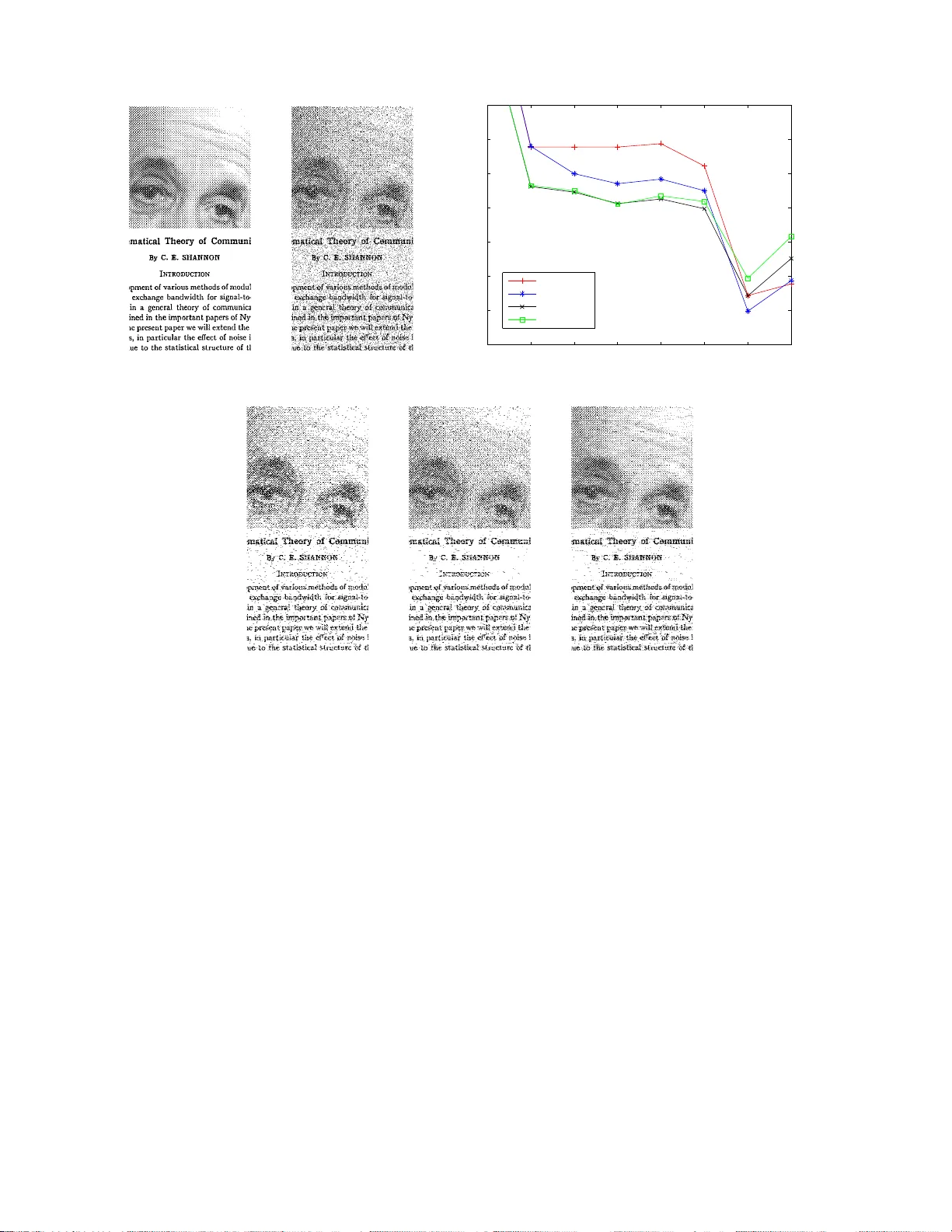
Discrete Denoising with Shifts ∗ T aesup Mo on Tsac h y W eissman Marc h 4, 2022 Abstract W e int r oduce S-DUDE, a new algorithm for denoising DMC-corrupted data . The algor ithm, whic h generalizes the recently intro duced DUDE (Discrete Universal DEnoise r ) of W eissman et al., aims to comp ete with a genie tha t has acces s, in addition to the noisy data, also to the underlying clean da ta, and can choo se to switch, up to m times, b et ween sliding window denois ers in a wa y that minimizes the overall loss. When the underlying data for m an individual sequence, we show tha t the S-DUDE per forms essentially as w ell as this genie , pro vided that m is sub-linear in the size of the data. When the clean data is emitted by a piecewise stationary pro cess, we show that the S- DUDE achieves the optimum distribution-dep endent p erforma nc e , provided that the same sub-linearity condition is imp osed on the nu mber of switc hes. T o further substantiate the universal optimality of the S-DUDE, w e s ho w that when the num b er of switches is allo wed to g row linearly with the size of the data, any (sequence of ) scheme(s) fails to co mpete in the ab ov e senses. Using dynamic programming, w e derive an efficient implementation of the S-DUDE, whic h has co mplex ity (time and memory) gro wing only linearly with the data size and the num ber o f switches m . P r eliminary exper imen tal results are prese nted, suggesting that S-DUDE has the capacit y to significa n tly impro ve on the p erformance attained by the origina l DUDE in applications where the nature of the data abruptly changes in time (or space), as is often the c a se in practice. Index T erm s - Discr ete denoising , comp etitiv e analysis , individual s equence, universal algo rithms, piecewise statio nary pro cesses, dynamic pro gramming, discrete memoryles s channel (DMC), switching exp erts, forward-backw ar d r ecursions. 1 In tro duction Discrete denoising is the problem of reconstructing the comp onen ts of a finite-alphab et sequence based on the entir e observ ation of its Discrete Memoryless Ch an n el (DMC)-corrupted version. The qualit y of the reconstruction is ev aluate d via a user-sp ecified (single-letter) loss fu n ction. Universal discrete denoising, in whic h no s tatisti cal or other p r op erties are kn o wn a priori ab out th e underlying clean data and the goal is to attain optimum p erf ormance, w as consid ered and solv ed in [1]. The main pr oblem setting there is the “semi-sto c hastic” one, in which the un derlying signal is assumed to b e an “individual sequ ence,” and the ran d omness is due s olely to the c han n el noise. I n this setting, it is unreasonable to exp ect to attain the b est p erformance among all the denoisers in th e world, since for ev ery giv en sequ ence, there exists a denoiser that reco v ers all the s equence comp onen ts p erfectly . T hus, [1] limits th e comparison class, a.k.a. exp ert class, and uses the comp etitiv e analysis approac h. Sp ecificall y , it is sho wn that regardless of what the u n derlying individu al sequence ma y b e, the Discrete Universal DEnoiser (DUDE) essen tially attains the p erformance of the b est sliding window denoiser that would b e c hosen by a genie w ith access to the ∗ Authors are with the Department of Electrical Engineering, S tanford Universit y , Stanford, CA 94305, USA . T. W eissman is also with the Department of Electrical Engineering, T ec h n ion, Haifa 32000, Israel. E-mails: { tsmoon , tsachy } @stanford .edu . This work was partial ly supp orted b y NSF aw ards 051214 0 and 054653 5, and by a Samsung sc holarship. underlying clean sequence, in add ition to the observ ed noisy s equence. This semi-stochastic setting result is sho w n in [1] to imply th e sto c h astic setting result, i.e., th at for any u nderlying stationary s ignal, the DUDE attains the optimal distrib ution-dep endent p erformance. The setting of an arbitrary ind ividual sequence, com bin ed with comp etitiv e analysis, has b een v ery p opular in man y other research areas, esp ecially for pr oblems of sequ ential d ecision-making. Examples include unive r sal compression [4], univ ersal prediction [5 ], universal fi ltering [2], rep eat ed game pla ying [6, 7, 8], universal p ortfolios [9], online learning [10, 11], zero-dela y co ding [12 , 13], and m uc h more. A comprehensiv e account of this lin e of researc h can b e f ound in [14]. Th e b eaut y of th is approac h is the fact that it leads to the construction of schemes that p erform, on eve r y individual sequence, essen tially as w ell as the b est in a class of exp erts, which is the p erformance of a genie that h ad h indsigh t on the entire sequence b efore selecting his actions. Moreo ver, if the exp ert class is judiciously c hosen, the relativ e sense of su c h a p erformance guarantee s can, in many cases, imply optimum p erf orm ance in absolute sen ses as w ell. One extension to this ap p roac h is comp etition with an exp ert class and a genie that has the freedom to form a c omp ound action, which b reaks the sequence in to a certain (limited) num b er of segmen ts, applies differen t exp erts in eac h segmen t, and ac hiev es an ev en b etter p erformance o v erall. Note that the optimal segmen tation of the s equence and the c h oice of the b est exp ert in eac h segmen t is also determin ed by hind - sigh t. Clearly , comp eting with the b est comp ound actio n is more c hallenging, s ince the num b er of p ossible comp ound actions is exp onential in the sequence length n , and the brute-force v anilla implemen tation of the ordinary universal sc heme requires prohibitive complexit y . Ho we ver, clev er schemes with linear com- plexit y that successfully track the b est segmen ts and exp erts h a v e b een devised in man y different areas, suc h as online learning, univ ersal prediction [15, 16], u niv ersal compression [17, 18], online linear regression [19], unive r sal p ortfolios [20 ], and zero-dela y lossy source co ding [22]. In this pap er, w e expand the idea of comp oun d actio n s and apply it to the discrete denoising pr oblem. The motiv ation of this exp ansion is natural: the charac teristics of the underlying data in the denoising problem often tend to b e time- or sp ace- v arying. In this case, determining the b est segmen tation and the b est exp ert for eac h segment r equires complete kn o wledge of b oth clean and noisy sequences. Therefore, whereas the chall enge in sequen tial d ecision-making problems is to trac k the shift of th e b est exp ert based on the past, true obs erv ation, the c h allenge in the denoising problem is to learn the shift based on the en tire, but noisy , obser v ation. W e extend DUDE to meet this c h allenge and pro vide resu lts that p arallel and strengthen those of [1]. Sp ecifically , we introd u ce the S-DUDE and show firs t that, for every underlying noiseless sequence, it attains the p erformance of the b est comp ound finite-order sliding window denoiser (concretely defi n ed later), b oth in exp ectation and in a high probabilit y sens e. W e dev elop our sc heme in the semi-sto chastic setting as in [1]. The to olb o x for the constr u ction and analysis of our sc heme d ra ws on ideas d ev elop ed in [2]. W e circum ven t the difficult y of not kno w ing th e exact tru e loss by using an ob s erv able u n biased estimate of it. This kind of an estimate h as prov ed to b e ve ry useful in [2] and [3] to d evise sc hemes for filtering and for denoising with dynamic contexts. Building on this semi-sto c hastic setting r esult, we also establish a sto c hastic setting result, which can b e though t of as a generalization and strengthening of the sto c h astic setting results of [1], from the w orld of stationary p ro cesses to that of piecewise stationary pro cesses. Our sto c hastic setting h as connections to other areas, suc h as c hange-p oin t dete ction p roblems in statistics [23, 24] and switc hin g linear dynamical systems in machine learnin g and signal pro cessing [25, 26]. Both of these lines of researc h share a common app roac h with S -DUDE, in that they try to learn the change of the u nderlying time-v arying parameter or state of sto c hastic mo dels, b ased on noisy observ ations of the parameter or state. O ne difference is that, wh ereas our goal is the noncausal estimation, i.e., denoising, of the general underlying piecewise statio n ary pro cess, th e change- p oin t detection p roblems mainly fo cus on sequ entially detecting the time p oin t where the c hange of mo del happ ened. Another difference is in 2 that the switc hing linear dynamical systems fo cus on a sp ecia l class of underlying pro cesses, th e linear dynamical system. In add ition, they d eal with con tinuous-v alued signals, wh ereas our fo cus is the discrete case, with finite-alphab et signals. As we explain in d etail, the S-DUDE can b e pr actic ally implemen ted u sing a t wo- p ass algorithm with complexit y (b oth space and time) linear in the sequence length and the n umb er of switc hes. W e also present initial exp erimenta l results that demonstrate the S-DUD E’s p oten tial to outp erform the DUDE on b oth sim ulated and real data. The remainder of the p ap er is organized as follo ws. S ectio n 2 p ro vides the notation, preliminaries and bac kground for the pap er; in Section 3 we presen t our sc heme and establish its strong unive rs alit y p rop erties via an analysis of its p erformance in the semi-sto c hastic setting. Sectio n 4 establishes the unive r salit y of our sc heme in a f ully stochastic setting, where the underlying noiseless sequence is emitted by a piecewise stationary p ro cess. Algorithmic asp ects and complexit y of the actual implemen tation of th e sc heme is considered in Section 5, and some exp erimen tal results are displa y ed in Sectio n 6. I n Section 7 we conclud e with a summary of our findin gs and some p ossible futu re researc h directions. 2 Notation, Preliminaries, and Motiv ation 2-A Notation W e use a com b ination of notati on of [1] and [2]. Let X , Z , ˆ X denote, resp ectiv ely , the alphab et of the clean, noisy , and reconstructed sources, w hic h are assu med to b e finite. As in [1] and [2], the noisy s equ ence is a DMC-corrupted v ersion of th e clean one, w here the c hannel matrix Π = { Π( x, z ) } x ∈X ,z ∈Z , Π( x, z ) denoting the probability of a noisy symb ol z w hen the und er lyin g clean sym b ol is x , is assumed to b e known and fixe d throughout the pap er, and of f ul l r ow r ank. The z -th column of Π will b e denoted as π z . Upp er case letters will denote random v ariables as usu al; lo wer case letters will denote either individu al determin istic quan tities or sp ecific realizations of rand om v ariables. Without loss of ge n eralit y , the elemen ts of a ny fi nite set V w ill b e iden tified with { 0 , 1 , · · · , |V | − 1 } . W e let V ∞ denote the set of one-sided in fi nite sequ ences with V -v alued comp onen ts, i.e., v ∈ V ∞ is of the form v = ( v 1 , v 2 , · · · ) , v i ∈ V , i ≥ 1. F or v ∈ V ∞ , let v n = ( v 1 , · · · , v n ) and v n m = ( v m , · · · , v n ). F urtherm ore, we let v n \ t denote the sequence v t − 1 v n t +1 . R V is a sp ace of |V | -dimensional column ve ctors with r eal-v alued comp onen ts in d exed by the elemen ts of V . Th e a -th comp onent of q ∈ R V will b e denoted by either q a or q [ a ]. Sub scripting a ve ctor or a matrix by “max” w ill repr esent the difference b et ween the m axim um and minim um of all its comp onents. Thus, f or example, if Γ is a |Z | × |X | matrix, then Γ max stands for max x ∈X ,z ∈Z Γ( z , x ) − min x ∈X ,z ∈Z Γ( z , x ) (in particular, if the comp onent s of Γ are nonn egat ive and Γ( z , x ) = 0 for some z and x , then Γ max = m ax z ∈Z ,z ∈X Γ( z , x ).) In addition, 1 {·} denotes an ind icato r of the ev ent in s ide {·} . Generally , let the finite sets Y , A b e, resp ectiv ely , a source alphab et and an actio n space. F or a general loss function l : Y × A → R , a Bayes r esp onse for ζ ∈ R Y under the loss function l is giv en as b l ( ζ ) = arg m in a ∈A ζ T · L a , (1) where L a denotes the col u mn of the matrix of the loss function l corresp onding to the a -th ac tion, and ties are resolv ed lexicographically . The corresp onding Bayes envelop e is denoted as U l ( ζ ) = min a ∈A ζ T · L a . (2) Note that when ζ is a probabilit y , namely , it has non-negativ e comp onent s su mming to one, U l ( ζ ) is the minim u m ac h iev able exp ected loss (as measured und er the loss f unction l ) in guessin g the v alue of Y ∈ Y whic h is distributed acco r ding to ζ . Th e asso ciated optimal guess is b l ( ζ ). 3 An n -blo ck denoiser is a collection of n mappings ˆ X n = { ˆ X t } 1 ≤ t ≤ n , where ˆ X t : Z n → ˆ X . W e assu me a giv en loss fun ction Λ : X × ˆ X → [0 , ∞ ), w here the maximum single-letter loss is denoted by Λ max , and λ ˆ x denotes the ˆ x -th column of the loss matrix. The normalized cum ulativ e loss of the denoiser ˆ X n on the individual sequence pair ( x n , z n ) is represente d as L ˆ X n ( x n , z n ) = 1 n n X t =1 Λ( x t , ˆ X t ( z n )) . In w ord s, L ˆ X n ( x n , z n ) is the normalized (p er-sym b ol) loss, as measured und er the loss fun ction Λ, when using the denoiser ˆ X n and when the obser ved noisy sequence is z n while the und er lyin g clean one is x n . The notation L ˆ X n is extended for 1 ≤ i ≤ j ≤ n , L ˆ X n ( x j i , z n ) = 1 j − i + 1 j X t = i Λ( x t , ˆ X t ( z n )) denoting the normalized (p er-symbol) loss b etw een (and including) lo cations i and j . No w, consider the set S = { s : Z → ˆ X } , whic h is th e (fin ite) set of mapp ings that take Z into ˆ X . W e refer to element s of S as “single-sym b ol denoisers”, since eac h s ∈ S can b e thought of as a ru le for estimating X ∈ X on the basis of Z ∈ Z . No w, for an y s ∈ S , an unbiased estimato r for Λ( x, s ( Z )) (based on Z only), w here x is a deterministic symb ol and Z is the outpu t of th e DMC when the inp ut is x , can b e obtained as in [2]. First, pic k a fu n ction h : Z → R X with the prop erty that, for a, b ∈ X , E a h b ( Z ) = X z ∈Z h b ( z )Π( a, z ) = δ ( a, b ) , 1 , if a = b 0 , otherwise , (3) where E a denotes exp ectation ov er the c h annel outpu t Z when the underlying c hann el input is a , an d h b ( z ) denotes the b -th comp onent of h ( z ). Let H denote the |Z | × |X | m atrix wh ose z -th ro w is h T ( z ), i.e., H ( z , b ) = h b ( z ). T o see that our assumption of a c hannel matrix with fu ll ro w rank guaran tees the existence of suc h an h , note that (3) can equiv alent ly b e stated in matrix form as Π H = I , (4) where I is the |X | × |X | iden tit y matrix. Thus, e.g., an y H of the form H = Γ T (ΠΓ T ) − 1 , for an y Γ such that ΠΓ T is in ve r tib le, satisfies (4). In p articular, Γ = Π is a v alid c h oice (ΠΠ T is in ve r tib le, since Π is of full ro w rank) corresp onding to the Moore-P enr ose generalize d inv erse [27]. No w , for an y s ∈ S , ρ ( s ) ∈ R X denotes the column ve ctor with x -th comp onen t ρ x ( s ) = X z Λ( x, s ( z ))Π( x, z ) = E x Λ( x, s ( Z )) . (5) In words, ρ x ( s ) is the exp ected loss using th e sin gle-symbol denoiser s , w hile the underlying sy mb ol is x . Considering S as an actio n space alphab et, we defin e a loss fu nction ℓ : Z × S → R as ℓ ( z , s ) = h ( z ) T · ρ ( s ) . (6) W e observe f rom (3) and (5) th at ℓ ( Z, s ) is an u n biased estimate of Λ( x, s ( Z )) since E x ℓ ( Z, s ) = E x h ( Z ) T · ρ ( s ) = X x ′ E x h x ′ ( Z ) ρ x ′ ( s ) = X x ′ δ ( x, x ′ ) ρ x ′ ( s ) = ρ x ( s ) = E x Λ( x, s ( Z )) ∀ x ∈ X . (7) 4 F or ξ ∈ R Z , let B H ( ξ , · ) ∈ S b e defined b y B H ( ξ , z ) = arg min ˆ x ξ T · H · [ λ ˆ x ⊙ π z ] , (8) where, for ve ctors v 1 and v 2 of equal dimensions, v 1 ⊙ v 2 denotes the v ector obtained b y comp onen t-wise m ultiplication. Note that, similarly as in [2, (88),(8 9) ], B H ( ξ , · ) = arg min s ∈S X z ξ T · H · [ λ s ( z ) ⊙ π z ] = arg min s ∈S ξ T · H · ρ ( s ) = arg min s ∈S X z ξ z · [ h T ( z ) · ρ ( s )] = arg min s ∈S X z ξ z · ℓ ( z , s ) = b ℓ ( ξ ) . (9) Th u s, B H ( ξ , · ) is a Ba yes resp onse for ξ u nder the loss function ℓ defined in (6). 2-B Preliminaries In this section, w e summ arize the results from [1] and motiv ate the approac h underlying the construction of our new class of denoisers. Analogo us ly as in [2], the n -b lock d enoiser ˆ X n = { ˆ X t } 1 ≤ t ≤ n can b e associated with F n = { F t } 1 ≤ t ≤ n , where F t : Z n \ t → S is defined as follo ws: F t ( z n \ t , · ) is the s in gle-sym b ol denoiser in S satisfying ˆ X t ( z n ) = F t ( z n \ t , z t ) ∀ z t . (10) Therefore, w e can adopt the view that at eac h time t , an n -blo c k denoiser is c ho osing a sin gle-sym b ol denoiser based on all th e noisy sequence comp onents b ut z t , and applying that single-sym b ol denoiser on z t to yield the t -th reconstruction ˆ x t . Conv er s ely , an y sequen ce of mappin gs in to sin gle-sym b ol denoisers F n defines a denoiser ˆ X n , again via (10). W e will adhere to this viewp oin t in wh at follo ws. One sp ecial class of wid ely used n -blo c k d enoisers is that of k -th order “sliding w indo w” den oisers, whic h we denote b y ˆ X n, S k . Su c h denoisers are of the form ˆ X s k t ( z n ) = s k ( z t + k t − k ) , t = k + 1 , · · · , n − k , (11) where s k is an elemen t of S k = { s k : Z 2 k + 1 → ˆ X } , the (finite) set of mapp ings from Z 2 k + 1 in to ˆ X . 1 W e also refer to s k ∈ S k as a “ k -th order denoiser”. Note that S 0 = S . F rom the definition (11), it follo ws that ˆ X s k i ( z n ) = ˆ X s k j ( z n ) whenev er z i + k i − k = z j + k j − k . (12) F ollo wing the asso ciation in (10), we can adopt an alternativ e view that the k -th order sliding windo w denoiser chooses a single-sym b ol denoiser s k ( z t − 1 t − k , z t + k t +1 , · ) ∈ S at time t on the b asis of the conte xt, and ˆ X s k t ( z n ) = s k ( z t − 1 t − k , z t + k t +1 , z t ). W e denote c t , ( z t − 1 t − k , z t + k t +1 ) as a (t wo- sid ed) context for z t , and define the set of all p ossible k -th order con texts, C k , { ( u − 1 − k , u k 1 ) : ( u − 1 − k , u k 1 ) ∈ Z 2 k } . T hen, for giv en z n and for eac h c ∈ C k , w e defin e T ( c ) , t : c t = c , k + 1 ≤ t ≤ n − k = { t : ( z t − 1 t − k , z t + k t +1 ) = c , k + 1 ≤ t ≤ n − k , (13) 1 The v alue of ˆ X s k t ( z n ) for t ≤ k and t > n − k is defined, for concreteness and simplicit y , as an arbitrary fix ed sym b ol in ˆ X . 5 the set of ind ices where the con text equ als c . No w , an equiv alen t interpretatio n for (12) is that for eac h c ∈ C k , the k -th order sliding w indo w denoiser emp lo ys a time-in v arian t sin gle-sym b ol denoiser, s k ( c , · ), at all p oin ts t ∈ T ( c ). In other words, the sequence z n is partitio n ed into the su bsequences asso ciated with the v arious conte xts, and on eac h suc h sub sequence a time-in v arian t single-sym b ol scheme is emplo y ed. In [1], for in tegers k ≥ 0 and n > 2 k , the k -th ord er m inim um loss of ( x n , z n ) is defined b y D k ( x n , z n ) , min ˆ X n ∈ ˆ X n, S k L ˆ X n ( x n − k k +1 , z n ) = min s k ∈S k 1 n − 2 k n − k X t = k + 1 Λ( x t , s k ( c t , z t )) . (14) The identit y of the elemen t s k ∈ S k that ac hieves (14) dep en ds not only on z n , bu t also on x n , since (14) can b e expressed as 1 n − 2 k X c ∈ C k min s ∈S X τ ∈T ( c ) Λ( x τ , s ( z τ )) , and at eac h time t , the b est k -th order sliding windo w d enoiser that ac h ieves (14) will emplo y the s in gle- sym b ol denoiser arg min s ∈S X τ ∈T ( c t ) Λ( x τ , s ( z τ )) , (15) whic h is determined from th e join t empirical distrib ution of pairs { ( x τ , z τ ) : τ ∈ T ( c t ) } . It was shown in [1 ] that, despite the lac k of kno wledge of x n , D k ( x n , Z n ) is ac hiev able in a sense made precise b elo w, in the limit of gro wing n , b y a sc heme that only h as access to Z n . Th is scheme is dub b ed in [1] as the Discrete Universal DEn oiser (DUDE), ˆ X n,k univ . The algorithm is defined by ˆ X k univ , t ( z n ) = B H ( m ( z n , z t − 1 t − k , z t + k t +1 ) , z t ) , (16) where m ( z n , c ) is the v ector of counts of the app earance s of the v arious sym b ols within the con text c along the sequence z n . That is, for all β ∈ Z , m ( z n , ˜ z − 1 − k , ˜ z k 1 ) is the |Z | -dimensional column vect or whose β -th comp onen t is m ( z n , ˜ z − 1 − k , ˜ z k 1 )[ β ] = { t : k + 1 ≤ t ≤ n − k , z t + k t − k = ˜ z − 1 − k β ˜ z k 1 } , namely , the num b er of app earances of ˜ z − 1 − k β ˜ z k 1 along the sequence z n . The main result of [1] is the follo wing theorem, p ertaining to the semi-sto c hastic setting of an individu al sequence x = ( x 1 , x 2 , . . . ) corrupted b y a DMC that yields the stochasti c n oisy sequence Z = ( Z 1 , Z 2 , . . . ). Theorem 1 ([1, The or em 1]) T ake k = k n satisfying k n |Z | 2 k n = o ( n / log n ) . Then, for al l x ∈ X ∞ , the se quenc e of denoisers { ˆ X n,k n univ } define d in (16) satisfies: a) lim n →∞ h L ˆ X n,k n univ ( x n , Z n ) − D k n ( x n , Z n ) i = 0 a.s. b) E h L ˆ X n,k n univ ( x n , Z n ) − D k n ( x n , Z n ) i = O r k n |Z | 2 k n n ! . 6 Theorem 1 w as further sho wn in [1] to imply the un iversalit y of the DUDE in the fully stochastic setting where the underlying sequ ence is emitted by a stationary source (and the go al is to attain the p erformance of the optimal distribution-dep end en t denoiser). F rom (16), it is apparent that the DUDE ends up employing a k -th order slidin g window denoiser (where th e sliding win d o w sc h eme the DUDE c h o oses dep end s on z n ). Moreo ve r , (9) implies that, at eac h time t , DUDE is merely emplo ying the single-sym b ol denoiser B H ( m ( z n , z t − 1 t − k , z t + k t +1 ) , · ) ∈ S , whic h can b e obtained by find ing the Ba yes resp onse b ℓ m ( z n , z t − 1 t − k , z t + k t +1 ) or, equiv alently , the mapping in S giv en b y arg min s ∈S X τ ∈T ( c t ) ℓ ( z τ , s ) , (17) where ℓ ( z , s ) is th e loss fu nction defin ed in (6). By comparing (15) with (17), and from Theorem 1, w e observ e that wo r k in g with the estimated loss ℓ ( z τ , s ) in lieu of the genie-aided Λ( x τ , s ( z τ )) allo ws us to essen tially ac h iev e the genie-aided p erformance in (14). 2-C Motiv ation Our motiv ation f or this pap er is b ased on the observ ation that the k -th order sliding win d o w denoisers ignore the time-v aryin g nature of the underlyin g sequence x n . That is, as discussed ab ov e, for time instances with the same co ntexts, the single-sym b ol denoiser emplo yed along the asso ciated sub sequence is time-in v arian t. In other words, for eac h t , only the empirical distribution of the sequ ence { ( x τ , z τ ) : τ ∈ T ( c t ) } m atters, but its order of co mp ositio n , i.e., its time-v ary in g nature, is not co n s idered. It is clear, ho wev er, that when the c haracteristics of the underlying clean sequence x n are c h anging, the (normalized) cumulativ e loss that is ac hiev ed by sliding window denoisers that can shift from one ru le to another along th e sequence may b e s tr ictly lo wer (b etter) than (14). W e no w d evise and analyze our new scheme that ac h iev es this more am bitious target p erformance. 3 The Shifting Denoiser (S-DUDE) In this sectio n , w e deriv e our new class of d enoisers and analyze their p erformance. In Subs ection 3-A, w e b egin with the simplest case, comp eting with sh ifting sym b ol- by-sym b ol den oisers, or, in other w ords, shifting 0-th order denoisers. The argumen t is generalized to sh ifting k -th order d enoisers in Subsection 3-B, and the framew ork and r esu lts include Subsection 3-A as a sp ecia l case. W e will u se the notatio n S 0 , instead of S , for consistency in denoting the class of single-symbol d en oisers. Throu gh ou t this section, we assume the semi-sto c hastic setting. 3-A Switc hing b et ween sym b ol-b y-sym b ol ( 0 -th or der) denoisers Consider an n -tuple of single-sym b ol denoisers S = { s 1 , · · · , s n } ∈ S n 0 . Th en, as men tioned in Section 2-B, for suc h S , we can d efine the asso ciated n -blo c k denoiser ˆ X n, S as ˆ X S t ( z n ) = s t ( z t ) . (18) Note that in this case, the single-sym b ol denoiser applied at eac h time m ay dep end on the time t (but not on z n \ t , as would b e the case for a general denoiser). W e also d enote the estimated normalized cumulativ e loss as ˜ L S ( z n ) , 1 n n X t =1 ℓ ( z t , s t ) , (19) whose prop erty is giv en in the follo win g lemma, which parallels [2, T heorem 4]. 7 Lemma 1 Fix ǫ > 0 . F or fixe d S ∈ S n 0 , and al l x n ∈ X n , P L ˆ X n, S ( x n , Z n ) − ˜ L S ( Z n ) > ǫ ≤ exp − n 2 ǫ 2 L 2 max and (20) P ˜ L S ( Z n ) − L ˆ X n, S ( x n , Z n ) > ǫ ≤ exp − n 2 ǫ 2 L 2 max , (21) wher e L max = Λ max + ℓ max . In w ords, the lemma sho ws that for ev ery S ∈ S n 0 , the estimate d loss ˜ L S ( Z n ) is concen trated around the true loss L ˆ X n, S ( x n , Z n ) with high pr obabilit y , as n b ecomes large, regardless of the un derlying sequen ce x n . Pr o of of L emma 1: See App end ix 8-A. No w, let th e in teger 0 ≤ m ≤ ⌊ n 2 ⌋ denote the maxim um num b er of sh ifts allo wed along the sequence. Then, define a set S n 0 ,m ⊆ S n 0 as S n 0 ,m = n S ∈ S n 0 : n X t =2 1 { s t − 1 6 = s t } ≤ m o , (22) namely , S n 0 ,m is the set of n -tuples of single-sym b ol denoisers with at most m shifts from one map p ing to another. 2 Analogously to (14), for the class of n -block denoisers ˆ X n, S with S ∈ S n 0 ,m , w e define D 0 ,m ( x n , z n ) , min S ∈S n 0 ,m L ˆ X n, S ( x n , z n ) = min S ∈S n 0 ,m 1 n n X t =1 Λ( x t , s t ( z t )) , (23) whic h is the minim u m normalized cumulativ e loss that can b e ac hiev ed for ( x n , z n ) by the sequence of n single-sym b ol denoisers that allo w at most m sh ifts. Our goal in this section is to b uild a univ ersal sc h eme that only has access to Z n , but still essen tially ac hiev es D 0 ,m ( x n , Z n ). As hin ted b y the DUDE, w e bu ild our univ ersal scheme by working with the estimated loss. That is, define ˆ S = ˆ S ( z n ) , arg min S ∈S n 0 ,m ˜ L S ( z n ) , (24) and our (0 , m )-Shifting Discrete Universal DEnoiser (S-DUDE), ˆ X n, 0 ,m univ , is defined as ˆ X n, ˆ S . It is clear that, b y definition, L ˆ X n, ˆ S ( x n , z n ) ≥ D 0 ,m ( x n , z n ) for all x n and z n , but we can also show that, with high probabilit y , L ˆ X n, ˆ S ( x n , Z n ) do es n ot exceed D 0 ,m ( x n , Z n ) by m u c h, as stated in the follo wing theorem. Theorem 2 L et ˆ X n, 0 ,m univ b e define d as ˆ X n, ˆ S , wher e ˆ S is give n in (24). Then, for al l ǫ > 0 and x n ∈ X n , P L ˆ X n, 0 ,m univ ( x n , Z n ) − D 0 ,m ( x n , Z n ) > ǫ ≤ 2 exp − n h ǫ 2 2 L 2 max − 2 n h m n + ( m + 1) ln N n oi , wher e h ( x ) = − x ln x − (1 − x ) ln (1 − x ) for 0 ≤ x ≤ 1 , and N = |S | = |Z | | ˆ X | . In p articular, the right-hand side of the ine quality is exp onential ly smal l, pr ovide d m = o ( n ) . 2 Note that, when m = 0, S n 0 , 0 is t h e set of constant n -tu ples consisting of t he same single-sym b ol denoiser. 8 R emark: It is reasonable to exp ect this theorem to hold, giv en Lemm a 1. That is, since, for fixed S ∈ S n 0 ,m , ˜ L S ( Z n ) is concen trated on L ˆ X n, S ( x n , Z n ), it is plausible that ˆ S that ac hieve s min S ∈S n 0 ,m ˜ L S ( Z n ) will hav e a loss L ˆ X n, ˆ S ( x n , Z n ) close to min S ∈S n 0 ,m L ˆ X n, S ( x n , Z n ), i.e., D 0 ,m ( x n , Z n ). Pr o of of The or em 2: See App endix 8-B. 3-B Switc hing b et ween k -th order denoisers No w, w e extend the result from Sub sectio n 3-A to the case of sh ifting b et ween k -th order d en oisers. T he argumen t parallels that of Sub sectio n 3-A. Let { s k ,t } n − k t = k + 1 b e an arbitrary sequence of the k -th order denoiser mappings, i.e., s k ,t ∈ S k for k + 1 ≤ t ≤ n − k . No w , for giv en z n , define an ( n − 2 k )-tuple of ( k -th order denoiser induced) single-sym b ol d enoisers S k ( z n ) , { s k ,t ( c t , · ) } n − k t = k + 1 ∈ S n − 2 k 0 , (25) where, to recall, c t = ( z t − 1 t − k , z t + k t +1 ), and s k ,t ( c t , · ) is the single-sym b ol denoiser induced from s k ,t ∈ S k and c t . F or br evity of n otation, we w ill sup press the dep endence on z n in S k ( z n ) and denote it as S k . Th en , as in (18), w e define the associated n -blo c k denoiser ˆ X n, S k as 3 ˆ X S k t ( z n ) = s k ,t ( c t , z t ) . (26) In addition, extending (19), the estimated normalized cumulativ e loss is giv en as ˜ L S k ( z n ) = 1 n − 2 k n − k X t = k + 1 ℓ ( z t , s k ,t ( c t , · )) . (27) Then, we ha ve the follo wing lemma, whic h parallels Lemma 1. Lemma 2 Fix ǫ > 0 . F or any fixe d se que nc e { s k ,t } n − k t = k + 1 , and al l x n ∈ X n , Pr L ˆ X n, S k ( x n − k k +1 , Z n ) − ˜ L S k ( Z n ) > ǫ ≤ ( k + 1) exp − 2( n − 2 k ) ǫ 2 ( k + 1) L 2 max ! and (28) Pr ˜ L S k ( Z n ) − L ˆ X n, S k ( x n − k k +1 , Z n ) > ǫ ≤ ( k + 1) exp − 2( n − 2 k ) ǫ 2 ( k + 1) L 2 max ! , (29) wher e L max = Λ max + ℓ max . R emark: Note that w hen k = 0, this lemma coincides with Lemma 1. Th e pro of of this lemma com bines Lemma 1 and the de-in terlea ving argumen t in the pro of of [1, Theorem 2]. Namely , we de-in terlea v e Z n in to ( k + 1) subs equ ences consisting of symb ols separated by blo c ks of k symb ols, and exploit the conditional indep endence of sym b ols in eac h subsequ en ce, giv en all sym b ols not in that subsequ ence, to use Lemma 1. Pr o of of L emma 2: See App end ix 8-C. No w, for an int eger 0 ≤ m ≤ ⌊ n − 2 k 2 ⌋ and giv en z n , let n ( c ) , |T ( c ) | , and m ( c ) , min { n ( c ) , m } for c ∈ C k . Th en, an alogously as in (22), w e d efi ne S n k ,m ( z n ) = n S k ( z n ) ∈ S n − 2 k 0 : { s k ,τ ( c , · ) } τ ∈T ( c ) ∈ S n ( c ) 0 ,m ( c ) for all c ∈ C k o . (30) 3 Again, the v alue of ˆ X S k t ( z n ) for t ≤ k an d t > n − k can be defined as an arbitrary fi x ed symb ol, since it will be inconsequential in subsequent devel opment. 9 In w ord s , S n k ,m ( z n ) is th e set of ( n − 2 k )-tuples of ( k -th order denoiser indu ced) single-sym b ol denoisers that allo w at m ost m ( c ) shifts within the subs equence { t : t ∈ T ( c ) } for eac h con text c ∈ C k . 4 Again, for brevit y , the dep endence on z n in S n k ,m ( z n ) is suppr essed , and we write s im p ly S n k ,m . It is wo rth n oting th at S n k ,m is a larger class than the class of k -th order ‘sliding w indo w’ denoisers that are allo wed to sh ift at most m times. The reason is th at in S n k ,m , the shift within eac h su bsequence asso ciated with eac h con text can o ccur at an y time, regardless of the shifts in other subsequences, whereas in the latter class, the shifts in eac h sub sequence o ccur together with other s hifts in other subsequences. F or inte gers k ≥ 0 and n > 2 k , we n o w define, for the class of n -blo c k denoisers ˆ X n, S with S ∈ S n k ,m , D k ,m ( x n , z n ) , m in S ∈S n k,m L ˆ X n, S ( x n − k k +1 , z n ) = min S ∈S n k,m 1 n − 2 k n − k X t = k + 1 Λ( x t , s k ,t ( c t , z t )) , (31) the minimum normalized cum ulative loss of ( x n , z n ) that can b e ac hiev ed by the sequence of k -th ord er denoisers that allo w at most m s h ifts within eac h con text. No w, to bu ild a legitimate (n on genie-aided) unive rs al sc heme ac hieving (31) on the basis of Z n only , we defi ne ˆ S k ,m = arg min S ∈S n k,m ˜ L S ( z n ) , (32) and the ( k , m )-S-DUDE, ˆ X n,k ,m univ , is defin ed as ˆ X n, ˆ S k,m . Note that w hen m = 0, ˆ X n, ˆ S k,m coincides with the DUDE in [1]. The follo wing theorem generalizes Theorem 2 to the case of general k ≥ 0. Theorem 3 L et ˆ X n,k ,m univ b e given b y ˆ X n, ˆ S k,m , wher e ˆ S k ,m is define d in (32). Then, for al l ǫ > 0 and x n ∈ X n , Pr L ˆ X n,k,m univ ( x n − k k +1 , Z n ) − D k ,m ( x n , Z n ) > ǫ (33) ≤ 2( k + 1) exp − ( n − 2 k ) · h ǫ 2 2( k + 1) L 2 max − 2 |Z | 2 k · n h m n − 2 k + ( m + 1) ln N n − 2 k oi ! , (34) wher e h ( x ) = − x ln x − (1 − x ) ln(1 − x ) for 0 ≤ x ≤ 1 , and N = |S | = |Z | | ˆ X | . R emark: No te that when k = 0, this theorem coincides with Theorem 2. Similarly to the wa y Th eo- rem 2 was plausib le giv en Lemma 1, Theorem 3 can b e exp ecte d giv en Lemma 2, since ˆ S k ,m ac hiev es min S ∈S n k,m ˜ L S ( Z n ), and we exp ect L ˆ X n, ˆ S k,m ( x n − k k +1 , Z n ) to b e close to D k ,m ( x n , Z n ) fr om the concen tration of ˜ L S ( Z n ) to L ˆ X n, S ( x n − k k +1 , Z n ) for all S ∈ S n k ,m . Pr o of of The or em 3: See App endix 8-D. F rom Theorem 3, we n o w easily obtain one of the main results of the pap er, which extends Th eorem 1 from the case m = 0 to the case of general 0 ≤ m ≤ ⌊ n − 2 k 2 ⌋ . That is, the follo w ing theorem asserts that, for every u n derlying sequ ence x ∈ X ∞ , our ( k , m )-S-DUDE p erforms essen tially as well as the b est shifting k -th order denoiser that allo ws at most m shifts within eac h con text, b oth in high probabilit y and exp ectation sense, pro vided a growth condition on k and m is satisfied. Theorem 4 Supp ose k = k n and m = m n ar e such that the right-hand side of (34) is summable in n . Then, for al l x ∈ X ∞ , the se quenc e of denoisers { ˆ X n,k ,m univ } satisfies 4 When m = 0, S n k, 0 ( z n ) b ecomes the set of n -block k -th order ‘sliding windo w’ denoisers. 10 a) lim n →∞ h L ˆ X n,k,m univ ( x n , Z n ) − D k ,m ( x n , Z n ) i = 0 a . s . (35) b) F or any δ > 0 , E h L ˆ X n,k,m univ ( x n , Z n ) − D k ,m ( x n , Z n ) i = O r k n |Z | 2 k n m n n 1 − δ ! . (36) R emark: It will b e seen in Claim 1 b elo w th at th e stipulation in the theorem implies lim n →∞ k n |Z | 2 k n m n n 1 − δ = 0, w hic h, when combined with (36), implies th at the exp ected d ifference on the left h and side of (36) v an- ishes w ith in creasing n . That in itself, ho w eve r, can easil y b e deduced from (35) and b ounded conv ergence. The more significan t v alue of (36) is in pr o viding a rate of con vergence resu lt for the ‘redund ancy’ in the S-DUDE’s p erformance, as a fu nction of both k and m . In particular, n ote that for an y η > 0, O ( n − 1 / 2+ η ) is ac h iev able pro vided k n = c log n and m n = n ξ , for small enough p ositiv e constants c, ξ . In what follo ws , we sp ecify the maximal gro w th rates for k = k n and m = m n under whic h the summabilit y condition stipulated in Theorem 4 holds. Claim 1 a) Maximal gr owth r ate for k : The summability c ondition in The or em 4 is satisfie d pr ovide d k n = c 1 log n with c 1 < 1 2 log |Z | and m n gr ows at any sub-p olynomial r ate. On the other hand, the c ondition is not satisfie d for k n = c 1 log n with any c 1 ≥ 1 2 log |Z | , even when m is fixe d (not gr owing with n ). b) Maximal gr owth r ate f or m : The summability c ondition in The or em 4 is satisfie d for any sub-line ar gr owth r ate of m n , pr ovide d k n is taken to incr e ase suffic i ently slow ly that k n |Z | 2 k n = o (( n/m n ) 1 − δ ) for some δ > 0 . On the other hand, the c ondition is not satisfie d whenever m n gr ows line arly with n , even when k is fixe d. Pr o of of Claim 1 : See App end ix 8-E. Pr o of of The or em 4: See App endix 8-F. 3-C A “st r ong conv erse” In Claim 1, we ha ve sho w n the n ecessit y of m = o ( n ) for the condition required in Theorem 4 to hold. Ho w ever, w e can pro ve the necessit y of m = o ( n ) in a muc h s tr onger sense, describ ed in the follo wing theorem. Theorem 5 Supp ose that X = ˆ X , that Λ( x, ˆ x ) ≥ 0 for al l x, ˆ x with e qu ality if and only i f x = ˆ x , and that Π( x, z ) > 0 for al l x, z . If m = Θ( n ) , then f or any se quenc e of denoisers { ˆ X n } , ther e exists x ∞ ∈ X ∞ such that lim sup n →∞ E L ˆ X n ( x n , Z n ) − D 0 ,m ( x n , Z n ) > 0 . (37) R emark: The theorem establishes the fact that wh en m = o ( n ) do es not hold, namely , w hen m = Θ( n ), not only do es the almost sur e con v ergence in Theorem 4 n ot hold but, in fact, even the m u c h w eake r con v ergence in exp ectation would fail. F u rther, it shows that this w ould b e the case for any sequ ence of denoisers, n ot necessarily the S-DUDE. F urtherm ore, (37) features D 0 ,m ( x n , Z n ), p ertaining to comp etition 11 with a genie that shif ts among single-sym b ol denoisers so, a fortiori , it implies that for an y fixed k > 0 or k that gro ws with n , lim sup n →∞ E L ˆ X n ( x n , Z n ) − D k ,m ( x n , Z n ) > 0 (38) also h olds since, by definition, D 0 ,m ( x n , z n ) ≥ D k ,m ( x n , z n ) for all x n , z n and k ≥ 0. Therefore, the theorem asserts that for any sequ en ce of d enoisers to comp ete with D k ,m ( x n , Z n ), eve n in exp ectatio n sense, m = o ( n ) is n ecessary . Finally , we men tion that the cond itions stipulated in the statemen t of the theorem regarding th e loss function and the c h annel can b e considerably relaxed without compromising the v alidit y of the theorem. These conditions are made to allo w for the simple pro of that we giv e in App endix 8-G. 4 The Sto c hastic Setting In [1], the semi-sto c hastic setting result, [1, Th eorem 1], w as sho wn to imply the result for the stochastic setting as w ell. That is, when the u nderlying data form a stationary pro cess, [1 , S ectio n VI] sho ws that the DUDE attains optimum distribution-dep endent p erformance. Analogously , w e can no w use the results from the semi-sto c hastic setting of the p r evious section to generalize th e results of [1, Section VI] and sho w that our S-DUDE attains optimum distribu tion-dep enden t p erformance w hen the underlyin g data form a piecewise stationary pro cess. W e first defi n e th e precise notion of th e class of piecewise stationary pro cesses in Sub section 4-A, and d iscuss the ric hn ess of this class in Su bsection 4-B. Subs ectio n 4-C giv es the main result of this section: the sto c hastic setting optimalit y of the S -DUDE. 4-A Definition o f the class of pro cesses P { m n } Let P (1) X , · · · , P ( M ) X b e a finite collecti on of M probability d istributions of stationary pro cesses, with com- p onen ts taking the v alues in X . Let A b e a pro cess with comp onents taking the v alues in { 1 , . . . , M } . Then, a piecewise statio n ary pro cess X is generated b y shifting b et ween the M pro cesses in a wa y sp ecified b y the “switching pro cess” A , as w e now describ e. First, denote r ( A n ) as the num b er of sh if ts that hav e o ccurred along the n -tuple A n , i.e., r ( A n ) , n − 1 X j =1 1 { A j 6 = A j +1 } . Th u s, there are r ( A n ) + 1 “blo cks” in A n , where eac h b lock is a tuple of constan t v alues that are different from the v alues of ad j acen t blo c ks. No w, for eac h 1 ≤ i ≤ r ( A n ) + 1, we define τ i ( A n ) , inf { t : P t j =1 1 { A j 6 = A j +1 } = i } if 1 ≤ i ≤ r ( A n ) n if i = r ( A n ) + 1 as the last time instance of the i -th blo c k in A n . In add ition, define τ 0 ( A n ) , 0. Clearly , r ( A n ) and τ i ( A n ) dep end on A n and, th us , are random v ariables. Ho wev er, for brevit y , we sup press the dep end en ce on A n when there is no confusion, and wr ite simply r and τ i , resp ectiv ely . Using these defin itions, and b y d enoting P A n as the n -th ord er marginal distribution of A , w e define a piecewise stationary pro cess X by charact erizing its n -th order marginal distrib u tion P X n as P X n ( X n = x n ) = X a n P A n ( a n ) P ( X n = x n | A n = a n ) = X a n P A n ( a n ) r +1 Y i =1 P ( a τ i ) X ( x τ i τ i − 1 +1 ) , (39) 12 for eac h n . The corresp ond ing d istribution of the pro cess X is d en oted a s P X . 5 In w ord s , X is constructed b y follo wing one o f the M p r obabilit y distributions in eac h blo c k, switc hing from one to another d ep ending on A . F urther m ore, conditioned on the realization of A , eac h stationary blo c k is indep endent of other blo c ks, ev en if the d istribution of distinct blo c ks is the same. Th is prop ert y of conditional in dep endence is reasonable for mo deling many types of data arising in practice, since we can think of the M distrib utions as differen t ‘mo des’; if the pro cess return s to the same m od e, it is reasonable to mo del the new blo c k as a new indep endent reali zation of that same distrib ution. In other words, the ‘mo de’ ma y represent the kin d of ‘texture’ in a certain r egion of th e data, but t w o d ifferen t regions with the same ‘texture’ should ha ve indep endent realizations from the texture-generating source. Our notion of a piecewise stationary pr o cess almost co in cides with that develo p ed in [21]. The m ain difference is that w e allo w an arbitrary d istribution for the pro cess A . No w, we define P { m n } to b e the class of all p ro cess distributions that can b e constructed as in (39) for some M , some collec tion P (1) X , · · · , P ( M ) X of stationary pr ocesses, and some switc hing pr ocess A whose n umb er of shifts satisfies r ( A n ) ≤ m n a.s. ∀ n. (40) In w ord s , a p ro cess X b elongs to 6 P { m n } if and only if it can b e formed by sw itc h ing b etw een a finite collect ion of in dep endent pro cesses in w hic h the num b er of switc hes by time n do es not exceed m n . 4-B Ric hness of P { m n } In this subsection, w e examine how rich the class P { m n } is, in terms of the gro wth rate m n and the existence of denoising sc h emes that are univ ersal with resp ect to P { m n } . Firs t, giv en an y d istr ibution on a noiseless n -tuple, P X n , w e defin e D ( P X n , Π ) , m in ˆ X n ∈D n E L ˆ X n ( X n , Z n ) , (41) where D n is the class of al l n -b lo ck denoisers. Th e exp ectation on the righ t-hand side of (41) assumes that X n is generated from P X n and that Z n is the output of the DMC, Π , wh ose inp ut is X n . Thus, D ( P X n , Π ) is the optim um denoising p erformance (in the s en se of exp ected p er -symb ol loss) attai n able when the source distribution P X n is kno wn. What happ ens when the source distribu tion is un k n o wn? T heorem 3 of [1] established the fact that 7 lim n →∞ h E L ˆ X n DUDE ( X n , Z n ) − D ( P X n , Π ) i = 0 for all stationary P X . (42) Note that our newly-defined cla ss of pro cesses, P { m n } , is simply the class o f all stationary pr o cesses if one tak es th e sequence m n to b e m n ≡ 0 f or all n . Thus, assu ming m n ≡ 0, (42) is equiv alen t to lim n →∞ h E L ˆ X n DUDE ( X n , Z n ) − D ( P X n , Π ) i = 0 for all P X ∈ P { m n } . (43) A t the other extreme, when m n = n , P { m n } consists of all p ossible (not necessarily stationary) pr ocesses. W e can observe this equiv alence by ha ving M = |X | pro cesses eac h b e a constan t pro cess at a d ifferen t sym b ol in X , and creating an y pro cess b y switching to the appropriate symb ol. In this case, n ot only do es 5 { P X n } n ≥ 1 is readily verified t o b e a consisten t family of distributions and, thus, by Kolmogoro v’s extension theorem, uniquely d efines the distribution of the process X . 6 The phrase “the p rocess X b elongs to P { m n } ” is shorthand for “the distribution of the p rocess X , P X , b elongs to P { m n } ”. 7 When P X is stationary , the limit lim n →∞ D ( P X n , Π ) △ = D ( P X , Π ) was shown to exist in [1]. Thus, (42) w as equiv alently stated as lim n →∞ E L ˆ X n DUDE = D ( P X , Π ) in [1, Theorem 3]. 13 (43) not hold for the DUDE, but cle arly (43) cannot hold un der any sequ ence of denoisers. In other w ords, P { m n } is far to o ric h to allo w for the existence of sc hemes that are unive r s al with resp ect to it. It is ob vious then that P { m n } is s ignifi can tly ric her than the family of stationary pro cesses whenev er m n gro ws with n . It is of in terest then to id en tify the maximal gro wth rate of m n that allo ws for the existence of s chemes that are un iversal with resp ect to P { m n } , and to find such a un iversal sc heme. In what follo ws, we offer a complete answer to these questions. Sp ecifically , we show th at if th e gro wth rate of m n allo w s for the existence of any sc heme which is unive r sal with resp ect to P { m n } , the S-DUDE is unive rs al, to o. 4-C Univ ersalit y of S-DUDE Here, w e state our sto c hastic setting r esult, whic h establishes the universali ty of ( k , m )-S-DUDE with resp ect to the class P { m n } . Theorem 6 L et k = k n and m = m n satisfy the gr owth r ate c ondition stipulate d in The or em 4, in addition to lim n →∞ k n = ∞ . Then, the se quenc e of denoisers { ˆ X n,k ,m univ } define d in Se ction 3 satisfy lim n →∞ h E L ˆ X n,k,m univ ( X n , Z n ) − D ( P X n , Π ) i = 0 for al l P X ∈ P { m n } . (44) R emark 1: Recall that, as noted in Claim 1, m n = o ( n ) together with appropriately slo wly gro wing k = k n is sufficien t to guarante e th e gro wth rate condition stipulated in Theorem 4. Hence, by Theorem 6, m = o ( n ) and the sufficien tly slo wly gro wing k = k n suffices for (44) to h old. Therefore, Theorem 6 implies the existence of schemes that are unive r sal with resp ect to P { m n } wheneve r m n increases sublinearly in n . S ince, as discussed in Sub section 4-B, no un iv ersal scheme exists for P { m n } when m n is linear in n , we conclude that the su b-linearit y of m n is the n ecessary and suffi cien t cond ition for a unive rs al sc h eme to exist with resp ect to P { m n } . Moreo v er, Theorem 6 establishes th e strong sense of optimalit y of the S-DUDE, as it sho ws that wheneve r P { m n } is u niv ersally “comp etable”, the S-DUDE do es the job. This fact is somewhat analogous to th e situation in [21], where the op timalit y of th e universal lossless co ding sc heme present ed therein for piecewise stationary sources w as established under the condition that m = o ( n ). R emark 2: A p oin t w ise result lim n →∞ L ˆ X n,k,m univ ( X n , Z n ) − D ( P X n , Π ) = 0 a.s. for all P X ∈ P { m n } , w hic h is analogous to [1, Th eorem 4], can also b e deriv ed. Ho wev er, we omit such a result here since the details required for stating it rigorously w ould b e conv oluted, and its added v alue o v er the strong p oint-wise result w e ha v e already established in th e semi-stochasti c setting would b e little. Pr o of of The or em 6: See App endix 8-H. 5 Algorithm and Complexit y 5-A An E fficien t I mplemen tation of S-DUDE In the preceding tw o sectio n s, w e ga ve strong asymptotic p erformance guaran tees for the new class of sc hemes, the S-DUDE. Ho w ev er, the question regarding the pr actical implementat ion o f (32), i.e ., obtaining ˆ S k ,m = arg min S ∈S n k,m ˜ L S ( z n ) , for fi xed k , m and n remains and, at first glance, may seem to b e a difficult com b in atorial optimization problem. In this s ectio n , we devise an efficien t t w o-pass algorithm, wh ich yields (32) and p erform s denoising 14 with linear complexit y in the sequence length n . A r ecur sion similar to th at in the firs t pass of the algorithm w e p resen t app ears also in the study of trac king the b est exp ert in on-line learning [15, 16]. F rom th e d efinition of S n k ,m , (30 ), we can see that obtaining (32) is equiv alen t to obtaining the b est com bination of single-sym b ol denoisers with at m ost m ( c ) shifts that minimizes the cumulativ e estimated loss along { t : t ∈ T ( c ) } , for eac h c ∈ C k . Th u s, our pr ob lem br eaks do wn to | C k | indep end en t p roblems, eac h b eing a problem of comp eting with the b est combinatio n of sin gle-sym b ol sc h emes allo wing m switc hes. T o describ e an algorithm that implemen ts this parallelization efficien tly , we first define v ariables. F or ( k , m )-S-DUDE, let I = m + 1 , J = N + 1, where N = |S | = |Z | | ˆ X | . Th en, a matrix M t ∈ R I × J is defined for k + 1 ≤ t ≤ n − 2 k , where M t ( i, j ) f or 1 ≤ i ≤ I and 1 ≤ j ≤ J − 1 represents the minim u m (un-normalized) cumulat ive estimated loss of the sequence of sin gle-sym b ol denoisers along the time index { τ : τ ≤ t, c τ = c t } , allo w ing at most ( i − 1) shifts b et ween single-sym b ol denoisers and applying s t = j . Moreo v er, M t ( i, J ), for 1 ≤ i ≤ I , is the sym b ol-by-sym b ol denoiser that attains the minimum v alue of the i -th row of M t , i.e., arg min 1 ≤ j ≤ J − 1 M t ( i, j ). A time p oin ter T ∈ R D , where D = | C k | = |Z | 2 k , is defined to store the closest time index that has the same con text as current time, during the first and second pass. That is, T ( c t ) , max { τ : τ < t, c τ = c t } , when fir st pass min { τ : τ > t, c τ = c t } , when second pass (45) W e also define r ∈ R D and q ∈ R D as v ariables for s torin g the p ointe r en ab lin g our sc heme to follo w the b est com bination of single-sym b ol denoisers du r ing the second pass. Th us , the total m emory size required is O ( mN n + |Z | 2 k ) = O ( mn ) (assumin g that k satisfies the gro wth rate stipulated in the p revious sec tions, whic h imp lies |Z | 2 k = o ( n )). Our tw o-pass algorithm has ingredien ts from b oth th e DUDE and from the forward-bac kw ard recur s ions of hidden Mark o v mo dels [28] and , in fact, the algorithm b ecomes equiv alen t to DUDE wh en m = 0. The first pass of the algorithm ru ns forward from t = k + 1 to t = n − k , and u p dates the elemen ts of M t recursiv ely . The recur sions hav e a natural d ynamic programming stru ctur e. F or 2 ≤ i ≤ I , 1 ≤ j ≤ J − 1, M t ( i, j ) is determined by M t ( i, j ) = ℓ ( z t , j ) + min n M T ( c t ) ( i, j ) , M T ( c t ) ( i − 1 , M T ( c t ) ( i − 1 , J )) o , (46) that is, adding the curren t loss to the b est cumulativ e loss up to T ( c t ) along { τ : τ < t, c τ = c t } . When i = 1, th e second term in the minimum of (46) is n ot defined, and M t ( i, j ) just b ecome s ℓ ( z t , j )+ M T ( c t ) ( i, j ). The v alidit y of (46) can b e verified by ob s erving that there are tw o p ossible cases in ac h ieving M t ( i, j ): either the ( i − 1)-th shift to the single-sym b ol denoiser j o ccurred b efore t , or it o ccurred at time t . W e can see that th e first term in the minimum of (46) corresp onds to the former case; the second term corresp onds to the latter. Obviously , the min im um of these t wo (where ties ma y b e resolv ed arbitrarily), leads to the v alue of M t ( i, j ) as in (46). After up d ating al l M t ’s dur in g the first pass, the second p ass runs bac kwa rd s from t = n − k to t = k + 1, and extracts ˆ S k ,m from { M t } n − 2 k t = k + 1 b y follo wing the b est sh ifting b et wee n single-sym b ol denoisers. Th e actual denoising (i.e., assem b ling the reconstruction sequence ˆ X n ) is also p erformed in that pass. The p ointers r ( c t ) and q ( c t ) are up d ated recur siv ely , and they trac k the b est sh ifting p oint and com bination of single-sym b ol denoisers, resp ectiv ely , for eac h of the s u bsequences asso ciate d with the v arious con texts. A succinct d escription of the algo rithm is p ro vided in Algorithm 1. The time complexit y of the algo r ith m is readily seen to b e O ( mn ) as wel l. 15 Algorithm 1 T he ( k , m )-Sh ifting Discrete Denoising Algorithm Require: M t ( i, j ) ∈ R I × J , k + 1 ≤ t ≤ n − 2 k, 1 ≤ i ≤ I , 1 ≤ j ≤ J , T ∈ R D , r ∈ R D , q ∈ R D , L ∈ R Ensure: ˆ S k = { s k ,t ( c t , · ) } n − 2 k t = k + 1 in (32) and the denoised output { ˆ x t } n − k t = k + 1 τ ( c ) ⇐ φ for all c ∈ C k for t = k + 1 to n − 2 k do if T ( c t ) = φ then M t ( i, j ) ⇐ ℓ ( z t , j ) for 1 ≤ i ≤ I , 1 ≤ j ≤ J − 1 M t ( i, J ) ⇐ arg min 1 ≤ j ≤ J − 1 M t ( i, j ) for 1 ≤ i ≤ I else M ∗ T ( c t ) ( i, j ) ⇐ M T ( c t ) ( i, j ) for i = 1, 1 ≤ j ≤ J − 1 min M T ( c t ) ( i, j ) , M T ( c t ) ( i − 1 , M T ( c t ) ( i − 1 , J )) for 2 ≤ i ≤ I , 1 ≤ j ≤ J − 1 M t ( i, j ) ⇐ M ∗ T ( c t ) ( i, j ) + ℓ ( z t , j ) for 1 ≤ i ≤ I , 1 ≤ j ≤ J − 1 M t ( i, J ) ⇐ arg min 1 ≤ j ≤ J − 1 M t ( i, j ) for 1 ≤ i ≤ I end if T ( c t ) ⇐ t end for T ( c ) ⇐ φ for all c ∈ C k for t = n − 2 k to k + 1 do if T ( c t ) = φ then r ( c t ) ⇐ I , q ( c t ) ⇐ M t ( r ( c t ) , J ) else L ⇐ M T ( c t ) ( r ( c t ) , q ( c t )) − ℓ ( z t , q ( c t )) if L < M t ( r ( c t ) , q ( c t )) then r ( c t ) ⇐ r ( c t ) − 1, q ( c t ) ⇐ M t ( r ( c t ) , J ) end if end if T ( c t ) ⇐ t , s k ,t ( c t , · ) ⇐ q ( c t ) ˆ x t ⇐ s k ,t ( c t , z t ) end for 5-B Extending the S-DUDE to Multi-Dimensiona l Data As n oted, our algorithm is essenti ally sep arately emplo ying the same algorithm to comp ete with the b est shifting s ingle-sym b ol denoisers, on eac h subsequen ce associated with eac h con text. The o v erall algorithm is the resu lt of parallelizing the op erations of the sc h emes for the different subsequ ences, wh ic h allo ws for a more efficien t implemen tation than if these sc hemes we re to b e r un completely indep endently of one another. Th is charac teristic of run ning the same algorithm in p arallel along eac h sub sequence enables us to extend S-DUDE to the case of multi-dimensional data: r un the same algorithm along eac h sub sequence asso ciate d with eac h (this ti me m ulti-dimensional) conte xt. It should b e noted, ho wev er , that the extension of the S-DUDE to the m ultidimensional case is not as straigh tforward as the extension of the DUDE wa s, since, wh ereas the DUDE’s outp u t is indep end en t of the ord ering of the data within eac h con text, this ordering may b e very significant in its effect on the output and, hence, the p erformance of S-DUDE. Therefore, the choic e of a sc heme f or scannin g the data and capturin g its lo cal spatial stationarit y , e.g., P eano-Hilb ert scanning [29], is an imp ortant ingredien t in extend in g S-DUDE to the den oising of multi- dimensional d ata. Find ings from th e recen t study on u n iv ersal scann in g rep orted in [3 0 , 31] c an b e brought to b ear on suc h an extension. 16 6 Exp erimen tation In this section, we rep ort some preliminary exp erimen tal resu lts obtained b y app lying S -DUDE to sev eral kinds of noise-corrupted data. 6-A Image denoising In this subsection, we r ep ort some exp erimen tal results of d enoising a b inary image under the Hamming loss function. The first and most simp listic exp erimen t is with the 400 × 400 blac k-and-white bin ary im age sho wn in Figure 1. The first figure is the clea n und erlying image. The image is passed through a binary symmetric c hannel (BSC) with crossov er pr obabilit y δ = 0 . 1, to obtain the noisy image (second image in Figure 1). Note that in this case, there are on ly four symb ol-by-sym b ol den oisers, namely , S = { 0 , 1 , z , ¯ z } , represent in g alw ays-sa y-0, alw ays-sa y-1, sa y-what-y ou-see, and fl ip-what-y ou-see, resp ect ively . The th ird image in Figure 1 is the DUDE output with k = 0 , and the last image is the output of our S-DUDE with k = 0 , m = 1. Th e DUDE with k = 0 is comp etes with the b est time-in v arian t symb ol-b y-sym b ol denoiser Figure 1: 400 × 400 binary images. whic h, in this case, is the say-what-y ou-see d en oiser, since the empirical distribution of the clean image is (0 . 5 , 0 . 5) and δ = 0 . 1. Th u s, the DUDE outp u t is the same as the noisy image; h ence, no denoising is p erformed. Ho wev er, it is clear that, for this image, the b est comp ound action of the sym b ol-b y-symb ol denoisers is alw ays-sa y-0 for th e first half and then a shift to alw ays-sa y-1 for the remainder. W e can see that our (0 , 1)-S-DUDE successfully captures this shift from th e noisy observ ations, and results in p erfe ct denoising with zero bit errors. No w, we mo ve on to a more realistic examp le. The fir st image in Figure 2, a concate n ation of a half- toned Einstein image (300 × 300) and scanned Shann on’s 1948 pap er (300 × 300), is the clean image. W e pass the image through a binary symmetric channel (BSC) with crosso ver probability δ = 0 . 1, to obtain the second noisy image, whic h we raster scan and employ the S-DUDE on the r esulting one-dimensional sequence. Since the tw o concatenated images are of a v ery differen t nature, we exp ect our S-DUDE to p erform b etter than the DUDE, b ecause it is designed to adapt to the p ossibilit y of emplo ying different sc hemes in different regions of the data. The plot shows the p erformance of our ( k , m )-S-DUDE with v arious v alues of k and m . T he horizonta l axis reflects k , and the v ertical axis r epresen ts the ratio of bit error p er symbol (BER) to δ = 0 . 1 . Eac h curv e represen ts the BER of sc h emes with differen t m = 0 , 1 , 2 , 3. Note that m = 0 corresp onds to the DUDE. W e can see th at S-DUDE with m > 0 mostly dominates the DUDE, with an ad d itional BER redu ction of ∼ 11 %, includ ing when k = 6, the b est k v alue for th e DUDE. The b ottom three fi gures sh o w th e d enoised images with ( k , m ) = (4 , 0) , (4 , 2) , (6 , 1) , ac hieving BERs of δ × (0 . 744 , 0 . 6630 , 0 . 4991), resp ectiv ely . Thus, in this examp le, (4 , 2)-S-DUDE achiev es an additional BER reduction of 11% ov er th e DUDE with k = 4, and the o v erall b est p erformance is ac hiev ed b y (6 , 1)-S- DUDE. Giv en th e nature of the image, whic h is a concatenat ion of t wo completely differen t types of images, eac h reasonably uniform in texture, it is not su r prising to fi nd that the S-DUDE w ith m = 1 p erforms the b est. 17 0 1 2 3 4 5 6 7 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 k Bit error rate/ δ Bit error rate plot for (k,m) S−DUDE m=0 (DUDE) m=1 m=2 m=3 Figure 2: Clean and noisy images, the bit error rate plot for ( k , m )-S-DUDE, and th r ee denoised outputs for ( k , m ) = (4 , 0) , (4 , 2) , (6 , 1), r esp ectiv ely . 6-B State estimation for a switc hing binary hidden Marko v pro cess Here, w e giv e a sto c h astic setting exp eriment. A switc hing binary hidd en Mark ov pro cess in th is example is defined as a binary symmetric Mark o v c hain obs erv ed through a BSC, where the transition probabilities of the Marko v c hain switc hes ov er time. Th e goal of a denoiser here is to estimate the underlying Marko v c hain b ased on the noisy ou tp ut. In our example, we construct a simple switc hing binary hidden Mark o v pro cess of length n = 10 6 , in whic h the transition probabilit y of the underlyin g binary symmetric Mark o v source switc hes from p = 0 . 0 1 to p = 0 . 2 at the midp oint of the sequence, and the crosso v er probability of BSC is δ = 0 . 1. T hen, w e estimate the state of the un derlying Mark o v c hain b ased on the BSC output. The go o dness of th e estimation is again m easur ed by the Hamming loss, i.e., the fraction of errors made. Slightly b etter than the optimal Ba yesian distribution-dep endent p erformance for this case can b e obtained b y emplo ying the forw ard -b ac kward recursion s c heme, incorp orating the v arying transition probabilities with the help of a genie that kno ws the exact lo cation of the c hange in the pro cess distrib ution. Figure 3 p lots the BER of ( k , m )-S-DUDE w ith v arious k and m , compared to the genie-aided Ba ye s optimal BER. The horizont al 18 axis represents k , and the tw o curves refer to m = 0 (DUDE) and m = 1. The v ertical axis is the ratio of BER to δ = 0 . 1. 0 1 2 3 4 5 6 0.4 0.5 0.6 0.7 0.8 0.9 1 k Bit error rate/ δ Bit error rate plot for (k,m)−S−DUDE m=0 (DUDE) m=1 Bayes Figure 3: BER for s witc hing binary hidd en Mark o v pro cess ( δ = 0 . 1 , n = 10 6 ). The switc h of th e under lyin g binary Mark ov c hain o ccurs wh en t = 5 × 10 5 , from the transition probab ility p = 0 . 01 to p = 0 . 2. W e can observe th at the optimal Bay esian BER is (lo we r b ounded b y) 0 . 4865 × δ . The b est p er f ormance of the DUDE wa s ac hiev ed when k = 6 with a BER of 0 . 5738 × δ , whic h is far ab o v e (18% more than) th e optimal BER. It is clear that, despite the size of the data, the DUDE fails to conv erge to the optimum, as it is confined to b e emplo ying the same sliding-wind o w sc heme thr oughout th e wh ole data. Ho wev er, w e can see that the (4 , 1)-S-DUDE achiev es a BER of . 4979 × δ , whic h is within 2 . 3% of the optimal BER. This example shows that our S-DUDE is comp etent in attaining the optimum p erforman ce f or a class ric her th an that of the statio n ary pro cesses. Sp ecifical ly , it attains the optimum p erformance for piecewise stationary pro cesses, on whic h the DUDE generally fails. 7 Conclusion and S ome F uture Directions Inspired by the DUDE algo rith m , we ha ve d ev elop ed a generalizatio n that accommod ates switching b e- t we en sliding windo w rules. W e h a ve sho wn a strong s emi-stoc h astic setting result for our n ew scheme in comp eting w ith shifting k -th ord er denoisers. This result implies a sto c h astic setting r esult as well , asserting that the S-DUDE asymp totica lly attains the optimal distribution-dep endent p erformance for the case in wh ic h the und erlying data is piecewise stationary . W e also describ ed an efficient low-c omplexity implemen tation of the algorithm, and presen ted some simple exp eriment s that demonstrate the p oten tial b enefits of emplo ying S -DUDE in p ractice . There are sev eral fu ture researc h dir ections r elate d to this w ork. The S-DUDE can b e thought of as a generalizat ion of the DUDE, with the introdu ction of a new comp onent captured by the n on-negativ e in teger parameter m . Many p r evious extensions of the DUDE, such as the settings of c hannel w ith memory[34], c hannel uncertaint y [33 ], applications to c hannel deco ding[37], discrete-input, con tinuous-output data[35], denoising of analog data[32], and d ecoding in the Wyner-Ziv prob lem[36], ma y stand to b enefit from a revision that would incorp orate the viewp oin t of switc hing b etw een time-in v arian t sc h emes. P articularly , 19 extending S-DUDE to the case where the th e d ata are analog as in [32] will b e non-trivial and in teresting from b oth a theoretical and a p ractica l viewp oin t. In addition, as mentioned in Section 5, an extension of the S-DUDE to the case of m ulti-dimensional d ata is not as straigh tforward as the extension of the DUDE w as. Suc h an extension should pro ve interesting and pr actic ally imp ortan t. Finally , it would b e usefu l to devise guidelines, in the sp irit of those in [38 , 3], for the choic e of k and m b ased on n and the noisy observ ation sequen ce z n . Ac kno wledgmen ts The fir s t author is grateful to Professor Manfred W armuth for introdu cing him to a substanti al amoun t of related w ork on th e exp ert trac kin g problems in online learning. 8 App endix 8-A Pro of of Lemma 1 W e fir st establish the fact th at for all x n ∈ X n , and for fixed S ∈ S n 0 , n n L ˆ X n, S ( x n , Z n ) − ˜ L S ( Z n ) o n ≥ 1 is a { Z n } -martingale. This is not hard to see by follo wing: E n [ L ˆ X n, S ( x n , Z n ) − ˜ L S ( Z n )] Z n − 1 = E n X t =1 Λ( x t , s t ( Z t )) − n X t =1 ℓ ( Z t , s t ) Z n − 1 = ( n − 1)[ L ˆ X n − 1 , S ( x n − 1 , Z n − 1 ) − ˜ L S ( Z n − 1 )] + E Λ( x n , s n ( Z n )) − ℓ ( Z n , s n ) Z n − 1 = ( n − 1)[ L ˆ X n − 1 , S ( x n − 1 , Z n − 1 ) − ˜ L S ( Z n − 1 )] , (47) where (47) follo ws from the fact that Z n is indep en d en t of Z n − 1 , and E Λ( x n , s n ( Z n )) = E ℓ ( Z n , s n ). Therefore, L S ( x n , Z n ) − ˜ L S ( Z n ) is a normalized sum of b ounded martingale differences; therefore the inequalities (20) and (21) follo w directly from the Ho effding-Azuma inequalit y [14 , Lemma A.7]. 8-B Pro of of Theorem 2 Consider follo wing chain of inequalities: P L ˆ X n, ˆ S ( x n , Z n ) − D 0 ,m ( x n , Z n ) > ǫ = P max S ∈S n 0 ,m L ˆ X n, ˆ S ( x n , Z n ) − L ˆ X n, S ( x n , Z n ) > ǫ ≤ X S ∈S n 0 ,m P L ˆ X n, ˆ S ( x n , Z n ) − L ˆ X n, S ( x n , Z n ) > ǫ (48) ≤ X S ∈S n 0 ,m P L ˆ X n, ˆ S ( x n , Z n ) − ˜ L ˆ S ( Z n ) > ǫ/ 2 | {z } (i) + X S ∈S n 0 ,m P ˜ L ˆ S ( Z n ) − L ˆ X n, S ( x n , Z n ) > ǫ/ 2 | {z } (ii) , (49) 20 where (48 ) follo ws from th e union b ound, and (49 ) follo ws fr om adding an d subtracting ˜ L ˆ S ( Z n ), and the union b ound . F or term (i) in (49), (i) ≤ X S ∈S n 0 ,m P max S ∈S n 0 ,m L ˆ X n, S ( x n , Z n ) − ˜ L S ( Z n ) > ǫ/ 2 (50) ≤ X S ∈S n 0 ,m X S ∈S n 0 ,m exp − n ǫ 2 2 L 2 max , (51) where (50) follo ws from L ˆ X n, ˆ S ( x n , Z n ) − ˜ L ˆ S ( Z n ) ≤ max S ∈S n 0 ,m L ˆ X n, S ( x n , Z n ) − ˜ L S ( Z n ) , and (51) follo ws from the union b ound and (20). Similarly , f or term (ii) in (49), (ii) ≤ X S ∈S n 0 ,m P ˜ L S ( Z n ) − L ˆ X n, S ( x n , Z n ) > ǫ/ 2 (52) ≤ X S ∈S n 0 ,m exp − n ǫ 2 2 L 2 max , (53) where (52) follo ws fr om ˜ L ˆ S ( Z n ) ≤ ˜ L S ( Z n ) a.s., and (53) follo ws from (21). Therefore, con tinuing (49), w e obtain (49) ≤ 2 X S ∈S n 0 ,m X S ∈S n 0 ,m exp − n ǫ 2 2 L 2 max = 2 h m X k =0 n − 1 k N ( N − 1) k i 2 exp − n ǫ 2 2 L 2 max (54) ≤ 2 exp − n h ǫ 2 2 L 2 max − 2 h m n − 2( m + 1) ln N n i , (55) where (54) fol lows from |S n 0 ,m | = P m k =0 n − 1 k N ( N − 1) k , and (55) follo ws from |S n 0 ,m | ≤ N m +1 exp nh ( m n ) . Hence, the theorem is prov ed. 8-C Pro of of Lemma 2 W e will prov e (28 ) since the pro of of (29) is essen tially iden tical. As in [1], defin e I d , { t : k + 1 ≤ t ≤ n − k , t ≡ d mo d ( k + 1) } , whose cardinalit y is denoted n d = ⌊ ( n − d − k ) / ( k + 1) ⌋ . Then, by denoting C t = ( Z t − 1 t − k , Z t + k t +1 ), w e start the c hain of in equalitie s, Pr L ˆ X n, S k ( x n − k k +1 , Z n ) − ˜ L S k ( Z n ) > ǫ ≤ Pr k X d =0 X τ ∈I d n Λ x τ , s k ,τ ( C τ , Z τ ) − ℓ Z τ , s k ,τ ( C τ , · ) o > ( n − 2 k ) ǫ ! (56) ≤ k X d =0 Pr X τ ∈I d n Λ x τ , s k ,τ ( C τ , Z τ ) − ℓ Z τ , s k ,τ ( C τ , · ) o > ( n − 2 k ) γ d ǫ ! , (57) 21 where (56) follo ws f r om the triangle in equalit y , (57) follo ws from the union b ound, and { γ d } is a set of nonnegativ e constan ts (to b e sp ecified later) satisfying P d γ d = 1. In the sequ el, for simplicit y , w e will denote Λ x τ , s k ,τ ( C τ , Z τ ) and ℓ Z τ , s k ,τ ( C τ , · ) in (48) as Λ τ and ℓ τ , resp ecti vely . Now, the collec tion of random v ariables Z ( d ) is defined to b e Z ( d ) , { Z t : 1 ≤ t ≤ n, t / ∈ I d } , and z ( d ) ∈ Z n − n d denotes a particular realization of Z ( d ). Th en, by conditioning, w e hav e (57) ≤ k X d =0 X z ( d ) ∈Z n − n d Pr( Z ( d ) = z ( d ))Pr X τ ∈I d Λ τ − ℓ τ > ( n − 2 k ) γ d ǫ Z ( d ) = z ( d ) ! , (58) and let P d denote the conditional probabilit y of (58 ). No w, conditioned on Z ( d ) = z ( d ), { Z τ } τ ∈I d are all indep endent, and the sum m ation in P d b eomes X τ ∈I d n Λ x τ , s k ,τ ( c τ , Z τ ) − ℓ Z τ , s k ,τ ( c τ , · ) o , whic h is the sum of the absolute differences of the true and estimated losses of the sym b ol- by-sym b ol denoisers s k ,τ ( c τ , · ) o ve r τ ∈ I d . Th u s, we can app ly (20), and obtain P d = Pr X τ ∈I d Λ τ − ℓ τ > n d · ( n − 2 k ) γ d ǫ n d Z ( d ) = z ( d ) ! ≤ exp − 2( n − 2 k ) 2 γ 2 d ǫ 2 L 2 max n d . (59) F ollo wing [1], w e c h oose γ d = √ n d P j √ n j , and from th e Cauc hy-Sc h wartz inequalit y and P d n d = n − 2 k , w e arriv e at n d γ 2 d ≤ ( k + 1) k X d =0 n d = ( k + 1)( n − 2 k ) , and, hence, P d ≤ exp − 2( n − 2 k ) ǫ 2 ( k + 1) L 2 max . (60) Therefore, plugging (60) into (58), we fi nally ha ve (58) ≤ ( k + 1) exp − 2( n − 2 k ) ǫ 2 ( k + 1) L 2 max , whic h p r o v es the lemma. 22 8-D Pro of of Theorem 3 The pro of resem bles that of Theorem 2. Consid er Pr L ˆ X n, ˆ S k,m ( x n − k k +1 , Z n ) − D k ,m ( x n , Z n ) > ǫ = P max S ∈S n k,m L ˆ X n, ˆ S k,m ( x n − k k +1 , Z n ) − L ˆ X n, S ( x n − k k +1 , Z n ) > ǫ ≤ X S ∈S n k,m P L ˆ X n, ˆ S k,m ( x n − k k +1 , Z n ) − L ˆ X n, S ( x n − k k +1 , Z n ) > ǫ (61) ≤ X S ∈S n k,m n P L ˆ X n, ˆ S k,m ( x n − k k +1 , Z n ) − ˜ L ˆ S k,m ( Z n ) > ǫ 2 + P ˜ L ˆ S k,m ( Z n ) − L ˆ X n, S ( x n − k k +1 , Z n ) > ǫ 2 o (62) ≤ 2( k + 1) X S ∈S n k,m X S ∈S n k,m exp − ( n − 2 k ) ǫ 2 2( k + 1) L 2 max (63) = 2( k + 1) m ( c ) X k =0 n ( c ) − 1 k N ( N − 1) k 2 | C k | exp − ( n − 2 k ) ǫ 2 2( k + 1) L 2 max , (64) where (61 )-(62 ) follo w similarly as in (48)-(49); (63) follo ws fr om arguments similar to (50), (52), and Lemma 2 (whic h pla ys the r ole that Lemma 1 pla y ed there); and (64) follo ws from |S n k ,m | = ( P m ( c ) k =0 n ( c ) − 1 k N ( N − 1) k | C k | . No w , for all c ∈ C k , m ( c ) X k =0 n ( c ) − 1 k N ( N − 1) k ≤ N m +1 exp n ( c ) h m ( c ) n ( c ) ≤ N m +1 exp ( n − 2 k ) h m ( c ) n − 2 k (65) ≤ N m +1 exp ( n − 2 k ) h m n − 2 k , (66) where (65 ) is based on the fact that exp( nh ( m n )) is an in creasing fu nction in n , and (66) follo ws fr om m ≤ ⌊ n − 2 k 2 ⌋ . Therefore, toget h er with | C k | = |Z | 2 k , w e hav e (64) ≤ 2( k + 1) exp − ( n − 2 k ) · h ǫ 2 2( k + 1) L 2 max − 2 |Z | 2 k · n h m n − 2 k + ( m + 1) ln N n − 2 k oi , (67) whic h p r o v es the theorem. 8-E Pro of of Claim 1 F or part a), to sho w the necessit y first, s u pp ose c 1 ≥ 1 2 log |Z | . Th en, fr om |Z | 2 k = n 2 k log |Z | log n , we ha ve 2 |Z | 2 k · { h ( m n − 2 k ) + ( m +1) ln N n − 2 k } = Ω n 2 k log |Z | log n ( m n ) 1 − δ , whic h will gro w to infi nit y as n gro ws, ev en when m is fixed. Therefore, the r igh t-hand side of (34) is not summable. On the other h and, k = c 1 log n with c 1 < 1 2 log |Z | is readily v erified to suffice for th e summability , p r o vided that m = m n gro ws at an y sub-p olynomial rate, i.e., gro ws more s lo w ly than n α for an y α > 0 (e.g., c 2 log n ). F or part b ), to sho w the necessit y , sup p ose m = Θ( n ). Then, h ( m n − 2 k ) + ( m +1) ln N n − 2 k = Θ(1), and, th us, for s u fficien tly small ǫ , ǫ 2 2( k +1) L 2 max − |Z | 2 k · h m n − 2 k + ( m +1) log N n − 2 k < 0 ev en for k fixed. Therefore, the 23 righ t-hand side o f (34) is not summable. Hence, m = o ( n ) is necessary for the summabilit y . F or sufficiency , supp ose m = m n is an y rate, suc h that lim n →∞ m n n = 0. Th en , ǫ 2 2( k + 1) L 2 max − 2 |Z | 2 k · n h m n − 2 k + ( m + 1) log N n − 2 k o = 1 k n ǫ 2 2(1 + 1 k L 2 max ) − 2 k |Z | 2 k · O m n n 1 − δ o . (68) Th u s, if k gro ws suffi ciently slo wly that k |Z | 2 k = o ( n m n ) 1 − δ , then (68) b ecomes p ositiv e for sufficiently large n , and the right -hand side of (34) b ecomes summable. 8-F Pro of of Theorem 4 First, denote the random v ariable A n k ,m , L ˆ X n,k,m univ ( x n − k k +1 , Z n ) − D k ,m ( x n , Z n ). Then, f or p art a), w e hav e L ˆ X n,k,m univ ( x n , Z n ) − D k ,m ( x n , Z n ) ≤ 2 k Λ max n + A n k ,m a.s. Since the maximal rate for k is c 1 log n as sp ecified in Claim 1, lim n →∞ 2 k Λ max n = 0. F urthermore, from the summabilit y condition on k and m , Th eorem 3, and the Borel-Cant elli lemma, we get lim n →∞ A n k ,m = 0 with probabilit y 1, whic h prov es part a). T o pro ve p art b ), note that, for an y ǫ > 0, E L ˆ X n,k,m univ ( x n , Z n ) − D k ,m ( x n , Z n ) ≤ 2 k Λ max n + E ( A n k ,m ) = 2 k Λ max n + E ( A n k ,m | A n k ,m ≤ ǫ ) P r ( A n k ,m ≤ ǫ ) + E ( A n k ,m | A n k ,m > ǫ ) P r ( A n k ,m > ǫ ) ≤ 2 k Λ max n + ǫ + Λ max · P r ( A n k ,m > ǫ ) ≤ 2 k Λ max n + ǫ + Λ max · (righ t-hand sid e of (34)) . (69) F rom the pro of of Claim 1, the condition of Th eorem 4 r equires k = k n and m = m n to satisfy lim n →∞ k n |Z | 2 k n ( m n n ) 1 − δ = 0 . Therefore, if w e set ǫ 2 = Θ( k n |Z | 2 k n ( m n n ) 1 − δ ) with su fficien tly large constan t then, from (68), w e can see that the righ t-hand side of (34) will deca y almost exp onenti ally , whic h is m uc h faster th an Θ( k n |Z | 2 k n ( m n n ) 1 − δ ). Hence, from (69), we conclude that E ( A n k ,m ) = O q k n |Z | 2 k n ( m n n ) 1 − δ , whic h r esults in part b). 8-G Pro of of Theorem 5 The fact that m = Θ( n ) implies the existence of α > 0, s uc h that m ≥ nα for all sufficien tly large n . Let X b e the pr ocess formed b y concatenating i.i.d. blo c ks of length ⌈ 1 /α ⌉ , eac h blo c k consisting of the s ame rep eated sym b ol c h osen uniform ly from X . The fir s t observ ation to n ote is that, for all n large enough that m ≥ nα , D 0 ,m ( X n , Z n ) = 0 a.s. (70) This is b ecause, by constru ction, X n is, with probabilit y 1, piecewise constan t w ith constancy sub -blo c ks of length, at least, ⌈ 1 /α ⌉ . Thus, a genie with access to X n can c ho ose a s equence of symb ol-by-sym b ol 24 sc hemes (in fact, ignoring the n oisy sequence), with less than nα (and, therefore, less than m ) switc h es, that p erf ectly r eco ver X n (and, therefore, by our assumption on the loss fun ction, suffers zero loss). O n the other hand, the assum ptions on the loss function and the c hann el imp ly that, for the pro cess X jus t constructed, lim sup n →∞ min ˆ X n E L ˆ X n ( X n , Z n ) > 0 , (71) since ev en th e Ba yes-optima l sc heme for this pro cess incurs a p ositiv e loss, with a p ositive pr obabilit y , on eac h ⌈ 1 /α ⌉ sup er-sym b ol. Thus, we get E n lim sup n →∞ E L ˆ X n ( X n , Z n ) − D 0 ,m ( X n , Z n ) | X n o (72) ≥ lim sup n →∞ E L ˆ X n ( X n , Z n ) − D 0 ,m ( X n , Z n ) (73) = lim sup n →∞ E L ˆ X n ( X n , Z n ) (74) ≥ lim sup n →∞ min ˆ X n E L ˆ X n ( X n , Z n ) > 0 , (75) where (73) follo ws fr om F atou’s lemma; (74) follo ws from (70 ); an d (75) follo w s from (71 ). In particular, there must b e one particular individu al sequence x ∈ X ∞ for wh ic h the expression insid e the curled b rac k ets of (72) is p ositiv e, i.e., lim sup n →∞ E L ˆ X n ( X n , Z n ) − D 0 ,m ( X n , Z n ) | X n = x n > 0 , (76) whic h is equiv alen t to (37 ). 8-H Pro of of Theorem 6 First, by adding and sub tracting the same term s , we obtain E L ˆ X n,k,m univ ( X n , Z n ) − D ( P X n , Π ) = E L ˆ X n,k,m univ ( X n , Z n ) − min S ∈S n k,m E L ˆ X n, S ( X n , Z n ) | {z } (i) + min S ∈S n k,m E L ˆ X n, S ( X n , Z n ) − D ( P X n , Π ) | {z } (ii) . (77) W e will consider term (i) and term (ii) separately . F or term (i), (i) = E L ˆ X n,k,m univ ( X n , Z n ) − min S ∈S n k,m E L ˆ X n, S ( X n , Z n ) ≤ 2 k Λ max n + n − 2 k n · h E L ˆ X n,k,m univ ( X n − k k +1 , Z n ) − min S ∈S n k,m E L ˆ X n, S ( X n − k k +1 , Z n ) i (78) ≤ 2 k Λ max n + n − 2 k n · E h L ˆ X n,k,m univ ( X n − k k +1 , Z n ) − min S ∈S n k,m L ˆ X n, S ( X n − k k +1 , Z n ) i (79) ≤ 2 k Λ max n + E h L ˆ X n,k,m univ ( X n − k k +1 , Z n ) − D k ,m ( X n , Z n ) i , (80) where (78 ) follo ws from upp er b ounding and omitting the losses for time instances t ≤ k and t > n − k in the first and second terms of (i), resp ectiv ely; (79) f ollo ws from exc hanging the m inim um with the exp ectation, and (80) follo ws fr om th e definition (31) and n − 2 k n ≤ 1. 25 F or term (ii), we b ound th e fir st term in (ii) as min S ∈S n k,m E L ˆ X n, S ( X n , Z n ) ≤ 2 k ( m + 1)Λ max n + 1 n min S ∈S n k,m E E h r +1 X i =1 τ i − k X j = τ i − 1 + k +1 Λ( X j , s k ,j ( Z j + k j − k )) A n i , ( 81) b y upp er b ounding the losses with Λ max on the b oun dary of the shifting p oint s. No w, let P X j | Z l i ,A n ∈ R |X | denote the |X | -dimensional p robabilit y v ector whose x -th comp onent is P r ( X j = x | Z l i , A n ). Th en , we can b ound the second term in (81) by the follo win g c hain of in equalities: 1 n min S ∈S n k,m E E h r +1 X i =1 τ i − k X j = τ i − 1 + k +1 Λ( X j , s k ,j ( Z j + k j − k )) A n i (82) = 1 n E r +1 X i =1 τ i − k X j = τ i − 1 + k +1 min s k ∈S k E h Λ( X j , s k ( Z j + k j − k )) A n i (83) = 1 n E r +1 X i =1 τ i − k X j = τ i − 1 + k +1 X z k − k ∈Z 2 k +1 P ( Z j + k j − k = z k − k | A n ) min ˆ x ∈ ˆ X E h Λ( X j , ˆ x ) | Z j + k j − k = z k − k , A n i (84) = 1 n E r +1 X i =1 τ i − k X j = τ i − 1 + k +1 X z k − k ∈Z 2 k +1 P ( Z j + k j − k = z k − k | A n ) U Λ ( P X j | Z j + k j − k = z k − k ,A n ) (85) = 1 n E r +1 X i =1 τ i − k X j = τ i − 1 + k +1 E U Λ ( P X j | Z j + k j − k ,A n ) A n ] = 1 n E r +1 X i =1 τ i − k X j = τ i − 1 + k +1 E U Λ ( P ( A τ i ) X 0 | Z k − k ) | A n (86) ≤ 1 n E r +1 X i =1 τ i X j = τ i − 1 +1 E U Λ ( P ( A τ i ) X 0 | Z k − k ) | A n , (87) where (83) follo ws fr om th e stationarit y of the distribution in eac h blo c k as we ll as the fact that the com bination of the b est k -th ord er sliding win do w denoiser for eac h blo c k is in S n k ,m and ac h iev es th e minim u m in (82); (84) follo ws from conditioning; (85) follo ws f rom the definition (2); (86) follo ws from the stationarit y of the d istribution in eac h i -th blo c k; and (87) follo ws from adding more nonnegativ e terms. F or the second term in (ii), w e first defin e n i ( A n ) , τ i ( A n ) − τ i − 1 ( A n ) as the length of the i -th b lock, for 1 ≤ i ≤ r ( A n ) + 1. Obviously , n i ( A n ) also dep ends on A n , and, thus, is a r andom v ariable, but we again supp ress A n for brevity and denote it as n i . T h en, similar to the fi r st 26 term ab o v e, w e obtain D ( P X n , Π ) = min ˆ X n ∈D n E L ˆ X n ( X n , Z n ) = 1 n min ˆ X n ∈D n E E h r +1 X i =1 τ i X j = τ i − 1 +1 Λ( X j , ˆ X j ( Z n )) A n i = 1 n E r +1 X i =1 τ i X j = τ i − 1 +1 min ˆ X : Z n → ˆ X E h Λ( X j , ˆ X ( Z n )) A n i = 1 n E r +1 X i =1 τ i X j = τ i − 1 +1 min ˆ X : Z n i → ˆ X E h Λ( X j , ˆ X ( Z τ i τ i − 1 +1 )) A n i (88) = 1 n E r +1 X i =1 τ i X j = τ i − 1 +1 E U Λ ( P X j | Z τ i τ i − 1 +1 ,A n ) A n = 1 n E r +1 X i =1 τ i X j = τ i − 1 +1 E U Λ ( P ( A τ i ) X 0 | Z n i − j 1 − j ) A n (89) ≥ 1 n E r +1 X i =1 τ i X j = τ i − 1 +1 E U Λ ( P ( A τ i ) X 0 | Z ∞ −∞ ) A n , (90) where (88) foll ows from the cond itional ind ep endence b etw een different bloc ks , giv en A n ; (89) follo w s fr om the stationarit y of the d istribution in eac h blo c k, and (90) follo ws from [1, Lemma 4(1)]. Therefore, from (81),(87), and (90), we obtain ( b ) = min S ∈S n k,m E L ˆ X n, S ( X n , Z n ) − D ( P X n , Π ) ≤ 2 k ( m + 1)Λ max n + 1 n E r +1 X i =1 τ i X j = τ i − 1 +1 E U Λ ( P ( A τ i ) X 0 | Z k − k ) | A n − E U Λ ( P ( A τ i ) X 0 | Z ∞ −∞ ) A n = 2 k ( m + 1)Λ max n + E r +1 X i =1 n i n · n E U Λ ( P ( A τ i ) X 0 | Z k − k ) | A n − E U Λ ( P ( A τ i ) X 0 | Z ∞ −∞ ) A n o . (91) No w, observ e that, regardless of A n , the sequence of num b ers { n i n } r +1 i =1 form a prob ab ility distribution, since P r +1 i =1 n i n = 1 and n i n ≥ 0 for all i , with p robabilit y 1. Then, based on th e fact that the a verag e is less than the maxim u m , we obtain the further upp er b ound (91) ≤ 2 k ( m + 1)Λ max n + E max i ∈{ 1 , ··· ,M } n E U Λ ( P ( i ) X 0 | Z k − k ) − E U Λ ( P ( i ) X 0 | Z ∞ −∞ ) o . (92) The r emaining argument to pro v e the theorem is to sho w that the upp er b ounds (80 ) and (92) con verge to 0 as n tend s to infin it y . First, from the giv en condition on k = k n and m = m n , the maximal allo wable gro wth rate for k is k = c 1 log n , whic h leads to lim n →∞ 2 k Λ max n = 0. I n addition, th e condition requires m = o ( n ), and k to b e sufficien tly slo w, such that k |Z | 2 k = o ( n m ) 1 − δ , whic h implies k = o ( n m ). Th er efore, lim n →∞ 2 k ( m +1)Λ max n = 0. F ur thermore, from conditioning on X n , b ou n ded conv ergence theorem, and part 27 b) of Theorem 4, we obtain lim n →∞ E [ L ˆ X n,k,m univ ( X n − k k +1 , Z n ) − D k ,m ( X n , Z n )] = 0. T h us, w e h a v e lim sup n →∞ h E L ˆ X n,k,m univ ( X n , Z n ) − D ( P X n , Π ) i ≤ lim sup n →∞ E max i ∈{ 1 , ··· ,M } n E U Λ ( P ( i ) X 0 | Z k − k ) − E U Λ ( P ( i ) X 0 | Z ∞ −∞ ) o ≤ E lim sup n →∞ max i ∈{ 1 , ··· ,M } n E U Λ ( P ( i ) X 0 | Z k − k ) − E U Λ ( P ( i ) X 0 | Z ∞ −∞ ) o (93) = 0 , (94) where (93) follo ws fr om the rev erse F atou’s lemma, and (94) follo w s fr om [1 , Lemma 4(2)] and M b eing finite. Since it is clear that lim in f n →∞ [ E L ˆ X n,k,m univ ( X n , Z n ) − D ( P X n , Π )] ≥ 0 by definition of D ( P X n , Π ), the theorem is prov ed. R emark: As in [1, Th eorem 3], the conv ergence rate in (44) ma y dep end on P X , and ther e is no v anishing upp er b ound on this rate that holds for all P X ∈ P { m n } . How ever, we can glean some ins ight into the con v ergence rate from (i) and (ii): wh ereas the term (i) is un iformly upp er b ound ed for all P X ∈ P { m n } , 8 the rate at wh ic h term (ii) v anishes d ep ends on P X . In general, w e obs erv e that the slo w er the rate of increase of k = k n , the faster the con verge n ce in (i), but the con verge nce in (ii) is slo w er. With resp ect to the rate of incr ease of m n , the slo wer it is, th e faster th e con verge nce in (i), but wh ether or not the con v ergence in (ii) is accelerated b y a slo wer rate of in cr ease of m n ma y dep end on the u nderlying pro cess distribution P X . References [1] T. W eissman, E. Ordentl ich, G. Seroussi, S. V er d ´ u, and M. W ein b erger, “Univ ersal discrete denoising: Kno wn channel,” IEEE T r ans. Inform. The ory , 51(1):5-2 8, J an 2005 [2] T. W eissman, E. Or d en tlic h, M. W ein b erger, A. Somekh-Baruc h, and N. Merha v, “Univ ersal fi ltering via prediction,” IEE E T r ans. Inform. The ory , 53(4 ):1253-126 4, Apr 200 7 [3] E. Ordentlic h, M. W ein b erger, and T. W eissman , “Multi-directional con text sets with applications to unive rs al denoising and compression,” Pr o c e e dings of IEEE Int. Symp. Inform. Ther oy , 1270-127 4, Sep 2005 [4] J. Ziv and A. Lemp el, “Compression of individu al sequences v ia v ariable-rate cod ing,” IEEE T r ans. Inform. The ory , 24(5):530- 536, Sep 1978 [5] N. Merhav and M. F eder, “Universal p rediction,” IEEE T r ans. Inform. The ory , 44(6):21 24-2147, Oct 1998 [6] D. Blac kwell , “Con trolled random wa lks”, P r o c e e dings International Congr ess of Mathematicians , 3:336- 338, 1956. Amsterd am: North Holland [7] D. Blac kwell , “An analog of the minimax theorem for vect or pa yoffs” , Pacific J. Math , 6:1-8, 1956 8 Recall part b ) of Theorem 4, where a uniform b ound (un iform in the u n derlying indiv idual sequence) on E ˆ L ˆ X n,k,m univ ( x n , Z n ) − D k,m ( x n , Z n ) ˜ w as pro v id ed in the semi-sto chasti c setting. Clearly , in the stochastic setting the same b ound h olds on E ˆ L ˆ X n,k,m univ ( X n , Z n ) − D k,m ( X n , Z n ) ˜ , reg ardless of the distribution of X n . 28 [8] J. Hannan, “App ro ximation to Ba y es risk in rep eated play ,” Contributions to the The ory of Games , v ol.I I I:97-139, Pr inceton, NJ: P r inceton Univ. Press, 1957 [9] E. Or den tlic h and T. Cov er, “The cost of ac hieving the b est p ortfolio in hind sigh t,” Mathematics of Op er ations R ese ar ch , 23(4):96 0-982, Nov 1998 [10] N. Littlestone and M. K. W armuth ,“The weigh ted ma jority algorithm,” Information and Computa- tion , 108(2):21 2-261 F eb 1994. [11] V. V o vk, “Aggreg ating strategies,” Pr o c. 3r d Annu. Workshop on Computatio nal L e arning The ory , 371-3 82, Morgan Kauffm an, S an Mate o, CA 1990 [12] A. Gy orgy , T. Lind er, and G. Lugosi, “Efficien t algorithms and minimax b oun ds f or zero-dela y lossy source co ding,” IEEE T r ans. Signal Pr o c essing , 52(8): 2337-2347 , Aug 2004 [13] S . Matloub an d T. W eissman, “Univ ersal zero-dela y joint sour ce-c hann el co ding,” IEEE T r ans. Inform. The ory , 52(12 ):5240-525 0, Dec 2006 [14] N. Cesa-Bianc hi and G. Lugosi, “Prediction, learning, and games,” Cambridge University Pr ess , 2006 [15] M. Herbster and M. K. W armuth ,“T r ac kin g the b est exp ert,” in the sp ecial issu e on context sensitivit y and concept dr ift of the Journal of Machine L e arning , V ol. 32(2):151 -178, Aug 1998 [16] O. Bousquet and M. K. W arm u th, “T racking a small set of exp erts by mixin g past p osteriors,” in a sp ecial issue of Journal of Machine L e arning R ese ar ch for C O L T 2001, v ol. 3:363-39 6, No v 2002 [17] G. I . Shamir and N. Merha v, “Lo w-complexit y sequentia l lossless co din g for piecewise-stati onary memoryless sources,” IEEE T r ans. Inform. The ory , 45(5):1498 -1519, 1999. [18] F.M.J. Willems, “Co ding for b inary ind ep enden t piecewise ident ically distribu ted source,” IEEE T r ans. Inform. The ory , 42(6):2210- 2217, 1996 [19] S .S . Kozat and A.C. Singer, “Univ ersal p iecewise constan t and least squ ares prediction,” to app ear in IEEE T r ans. on Signal Pr o c essing , 200 7 [20] Y. Singer, “Swithcing p ortfolios,” P r o c e e dings of the 14th Confer enc e on U nc ertainty in Art ific i al Intel lgie nc e , p p.1498- 1519, 1998 [21] G. I . Shamir and D. J. C ostello , J r., “On the redun dancy of univ ersal lossless codin g for general piecewise stationary sources”, Communic ations in Information and Systems , V ol. 1(3):305 -332, Sep 2001 [22] A. Gy¨ orgy , T. Lind er, and G. Lugosi, “T racking the b est quan tizer,” Pr o c. Int. Symp. Inform. The ory , 1163- 1167, Sep 2005 [23] D. S iegm u nd, “Confidence sets in c hange-p oint problems,” Int. Statist. R eview 56, 31-48 , 1989 [24] D. Siegm und and E .S . V enk atraman, “Using the generalized lik eliho o d ratio statistic for sequen tial detection of a c h ange-point,” Ann. Statist. 23, 255–27 1, 1995 [25] S . M. Oh, J. M. Rehg, and F. Dellae rt, “P arameterized duration mo deling for switching linear dyn amic systems,” IEEE Int. Conf. on Computer Vision and Pattern R e c o gnition (CVPR) , NYC, 2006 [26] B. Mesot and D. Barb er, “Switc h ing linear dynamical sy s tems for noise robust sp eec h recognition,” IEEE T r ans. on A udio, Sp e e ch and L anguage Pr o c essing , 15(6): 1850-1858 , Aug 2007 29 [27] P . Lancaster and M. Tism enetsky , “The theory of matrices,” Orlando, FL: A c ademic , 1985 [28] Y. Eph r aim and N. Merha v, “Hidd en Mark ov pro cesses,” IEEE T r ans. Inform. The ory , v ol. 48:1518- 1569, Jun e 2002. [29] A. Lemp el and J. Ziv, “Compression of t w o-dimensional data,” IEE E T r ans. Inf orm. The ory , vol. 32(1): 2-8, Jan 1986 [30] A. Cohen, N. Merha v, and T . W eissman, “Scanning and s equen tial decision m aking for multi- dimensional data - Part I : the noiseless Case,” to app ear in IEE E T r ans. Inform. The ory. [31] A. Cohen, N. Merha v, and T . W eissman, “Scanning and s equen tial decision m aking for multi- dimensional data - Part I I: the noisy case,” sub mitted to IEE E T r ans. Inform. The ory , Ma y 2007 [32] K. Siv aramakrishnan and T. W eissman, “Univ ersal denoising of discrete-time con tin u ous-amplitude signals,” submitted to IEEE T r ans. Inform. The ory , a v ailable at http://w ww.stanford .edu/~tsachy/ieee_it_draft.pdf [33] G. M. Gemelos, S. Sigurjonsson, T. W eissman, “Univ ersal minimax discr ete denoising und er c h an n el uncertain ty ,” IEEE T r ans. Inform. The ory , 52(8):347 6-3497, 2006 [34] R. Zhang and T. W eissman, “Discrete denoising for channels with memory ,” Communic ations in Information and Systems (CIS) , 5(2):257.28 8, 2005 [35] A. Dem b o and T. W eissman, “Univ ersal denoising for the finite-input-general-output c hannel,” IEEE T r ans. Inform. The ory , 51(4):1507- 1517, Apr il 2005 [36] S . Jalali, S. V erd ´ u and T. W eissman, “A unive rs al Wyner-Ziv s c heme for discrete sources,” Pr o c. IEEE Int. Symp. Inform. The ory , Nice, F rance, July 2007 [37] E. O rden tlic h , G. Serou s si, S. V erd ´ u, and K. Viswanathan, “Unive r s al algorithms for channel deco ding of uncompressed sources,” Su bmitted to IEEE T r ans. Inform. The ory , 2006 [38] J. Y u and S. V erd ´ u, “Sc hemes for bidirectional mo deling of discrete stationary sour ces,” IEEE T r ans. Inform. The ory , 52(11):478 9.4807, 2006 30
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment