Multi-task Recurrent Model for Speech and Speaker Recognition
Although highly correlated, speech and speaker recognition have been regarded as two independent tasks and studied by two communities. This is certainly not the way that people behave: we decipher both speech content and speaker traits at the same ti…
Authors: Zhiyuan Tang, Lantian Li, Dong Wang
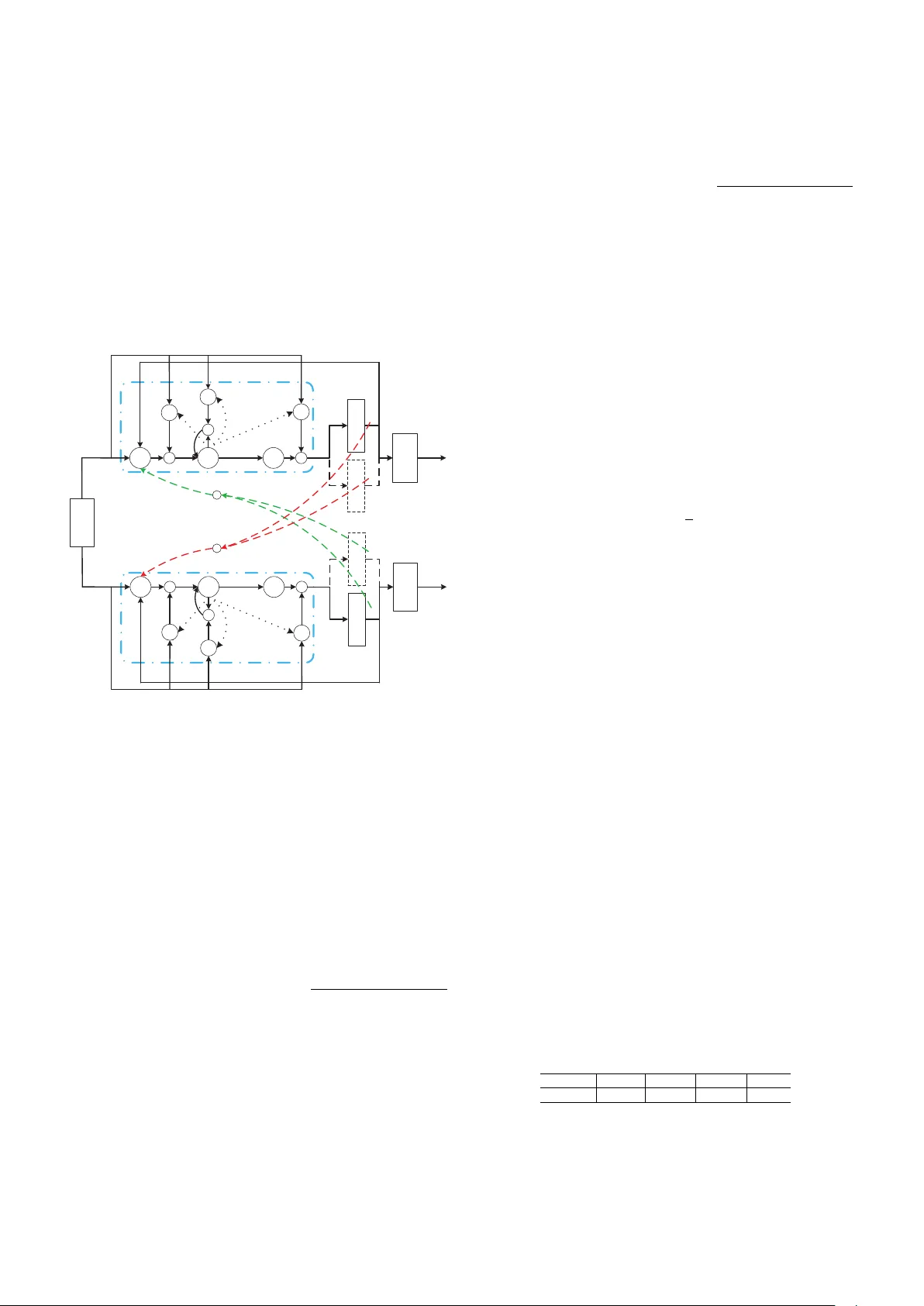
Multi-task Recurrent Model for Speech and Speaker Recognition Zhiyuan T ang † ‡ , Lantian Li † and Dong W ang † ∗ † Center for Speech and Language T echnologies, Division of T echnical Innov ation and Dev elopment, Tsinghua National Laboratory for Information Science and T echnology Center for Speech and Language T echnologies, Research Institute of Information T echnology , Tsinghua Univ ersity ‡ Chengdu Institute of Computer Applications, Chinese Academy of Sciences E-mail: { tangzy , lilt } @cslt.riit.tsinghua.edu.cn ∗ Corresponding author: wangdong99@mails.tsinghua.edu.cn Abstract —Although highly correlated, speech and speaker recognition hav e been regarded as two independent tasks and studied by two communities. This is certainly not the way that people behave: we decipher both speech content and speaker traits at the same time. This paper presents a unified model to perf orm speech and speaker recognition simultaneously and altogether . The model is based on a unified neural network where the output of one task is fed to the input of the other , leading to a multi-task recurr ent network. Experiments show that the joint model outperforms the task-specific models on both the two tasks. I . I N T RO D U C T I O N Speech recognition (ASR) and speaker recognition (SRE) are two important research areas in speech processing. T radi- tionally , these two tasks are treated independently and studied by two independent communities, although some researchers indeed work on both areas. Unfortunately , this is not the way that human processes speech signals: we always deci- pher speech content and other meta information together and simultaneously , including languages, speaker characteristics, emotions, etc. This ‘multi-task decoding’ is based on two foundations: (1) all these human capabilities share the same signal processing pipeline in our aural system, and (2) they are mutually beneficial as the success of one task promotes others’ in real life. Therefore, we believ e that multiple tasks in speech processing should be performed by a unified artificial intelligence system. This paper focuses on speech and speaker recognition, and demonstrates that these tw o tasks can be solved by a single unified model. In fact, the relev ance of speech and speaker recognition has been recognized by researchers for a long time. On one hand, these two tasks share many common techniques, from the MFCC feature extraction to the HMM modeling; and on the other hand, researchers in both areas hav e been used to learning from each other . For instance, the success of deep neural networks (DNNs) in speech recognition [1], [2] has motiv ated the neural model in speaker recognition [3], [4]. Additionally , researchers also know for a long time that employing the knowledge provided by one area often helps improv e the other . For instance, i-vectors produced by speaker recognition hav e been used to improv e speech recognition [5], and phone posteriors deriv ed from speech recognition hav e been utilized to improve speaker recognition [6], [7]. More- ov er , the combination of these two systems has already gained attention. For instance, speech and speaker joint inference was proposed in [8], and an LSTM-based multi-task model was proposed in [9]. Although highly interesting, all the above research can not be considered as multi-task learning, and the speech and speaker recognition systems are designed, trained and ex ecuted independently . The de velopment of deep learning techniques in speech processing provides new hope for multi-task learning. Since 2011, deep recurrent neural networks (RNNs) ha ve become the new state-of-the-art architectures in speech recognition [10], [11], and recently , the same architecture has g ained much success in speaker recognition, at least in text-dependent con- ditions [12]. In both the two tasks, deep learning deli vers two main advantages: first, the structural depth (multiple layers) extracts task-oriented features, and second, the temporal depth (recurrent connections) accumulates dynamic evidence. Due to the similarity in the model structure, a simple question rises that can we use a single model to perform the two tasks together? Indeed, this ‘multi-task learning’ has been known working well to boost correlated tasks [13]. For example, in multilin- gual speech recognition, it has been known that sharing low- lev el layers of DNNs can improve performance on each lan- guage [14]. And in another experiment, phone and grapheme recognition were treated as two correlated tasks [15]. The central idea of multi-task learning in the deep learning era is that correlated tasks can share the same feature extraction, and so the low-le vel layers of DNNs for these tasks can be shared. Ho wever , this feature-sharing architecture does not apply to speech and speaker recognition. This is because these two tasks are actually ‘negati vely correlated’: speech recognition requires features in volving as much as content information, with speaker v ariance remov ed; while speaker recognition requires features in volving as much as speaker information, with linguistic content remov ed. For these tasks, feature sharing is certainly not applicable. Unfortunately , man y tasks are negati vely correlated, e.g., language identification and speaker recognition, emotion recognition and speech recognition. Finding a multi-task learning approach that can ( ) F t ( ) P t ( ) S t ASR DNN / RNN SRE DNN / RNN ( 1 ) P t - ( 1 ) S t - Fig. 1. Multi-task recurrent learning for ASR and SRE. F ( t ) denotes primary features (e.g., Fbanks), P ( t ) denotes phone identities (e.g., phone posteriors, high-lev el representations for phones), S ( t ) denotes speaker identities (e.g., speaker posteriors, high-level representations for speakers). deal with negati vely-correlated tasks is therefore highly desir - able. This paper presents a nov el recurrent architecture that can be used to learn negativ ely-correlated tasks simultaneously . The basic idea is to use the output of one task as part of the input of others. It would be ideal if the output of one task can provide information for others immediately , but this is not feasible in implementation. Therefore the output of one task at the previous time step is used to provide information for others at the current time step. This leads to an inter-task recurrent structure that is similar to conv entional RNNs, though the recurrent connections link dif ferent tasks. W e employed this multi-task recurrent learning to speech and speaker recognition and observed promising results. The idea is illustrated in Fig. 1. W e note that a similar multi-task architecture was recently proposed in [9]. The difference is that they focus on speaker adaptation for ASR, while we demonstrated improv ement on both ASR and SRE tasks with the joint learning. The rest of the paper is organized as follows: Section II presents the model architecture, and Section III reports the ex- periments. The conclusions plus the future work are presented in Section IV. I I . M O D E L S A. Basic single-task model W e start from the single-task models for ASR and SRE. As mentioned, the state-of-the-art architecture for ASR is the re- current neural network, especially the long short-term memory (LSTM) [10]. This model also delivers good performance in SRE [12]. W e therefore choose LSTM to build the baseline single-task systems. Particularly , the modified LSTM structure proposed in [11] is used. The network structure is shown in Fig. 2. t r t x t m t o t i t f memor y blocks t c t p 1 t r - t y recurr e nt projec tion output input 1 t c - ´ ´ ´ g h Fig. 2. Basic recurrent LSTM model for ASR and SRE single-task baselines. The picture is reproduced from [11]. The associated computation is as follows: i t = σ ( W ix x t + W ir r t − 1 + W ic c t − 1 + b i ) f t = σ ( W f x x t + W f r r t − 1 + W f c c t − 1 + b f ) c t = f t c t − 1 + i t g ( W cx x t + W cr r t − 1 + b c ) o t = σ ( W ox x t + W or r t − 1 + W oc c t + b o ) m t = o t h ( c t ) r t = W rm m t p t = W pm m t y t = W y r r t + W y p p t + b y In the above equations, the W terms denote weight matrices and those associated with cells were set to be diagonal in our implementation. The b terms denote bias vectors. x t and y t are the input and output symbols respectively; i t , f t , o t represent respectiv ely the input, forget and output gates; c t is the cell and m t is the cell output. r t and p t are two output components deriv ed from m t , where r t is recurrent and fed to the next time step, while p t is not recurrent and contributes to the present output only . σ ( · ) is the logistic sigmoid function, and g ( · ) and h ( · ) are non-linear activ ation functions, often chosen to be hyperbolic. denotes the element-wise multiplication. B. Multi-task r ecurrent model The basic idea of the multi-task recurrent model, as sho wn in Fig. 1, is to use the output of one task at the current frame as an auxiliary information to supervise other tasks when processing the next frame. When this idea is materialized as a computational model, there are many alternati ves that need to be carefully inv estigated. In this study , we use the recurrent LSTM model shown in the previous section to build the ASR component and the SRE component, as shown in Fig. 3. These two components are identical in structure and accept the same input signal. The only dif ference is that they are trained with different targets, one for phone discrimination and the other for speaker discrimination. Most importantly , there are some inter-task recurrent links that combine the two components as a single network, as sho wn by the dash lines in Fig. 3. Besides the model structure, a bunch of design options need to be chosen. The first question is where the recurrent informa- tion should be extracted. For example, it can be extracted from the cell c t or cell output m t , or from the output component r t or p t , or even from the output y t . Another question is which computation block will receiv e the recurrent information. It can be simply the input v ariable x t , but can also be the input gate i t , the output gate o t , the forget gate f t or the non-linear function g ( · ) . Actually , augmenting the recurrent information to x t is equal to feed the information to i t , o t , f t and g ( · ) simultaneously . Note that a weight matrix is introduced as an extra free parameter for each recurrent information feedback. Moreov er , the component that the information is extracted from is not necessarily the same for different tasks, nor is the component that recei ves the information. Howe ver in this study , we simply consider the symmetric structure. a t r t x a t m a t o a t i a t f memor y blocks a t c a t p a t y s t r ´ s t m s t o s t i memor y blocks s t c s t p s t y 1 s t r - s t f 1 a t r - t x recurr ent projec tion phone s recurr ent projec tion spea kers g ´ ´ 1 a t c - ´ g ´ 1 s t c - ´ ´ + + 1 a t r - 1 a t p - 1 s t r - 1 s t p - input h h Fig. 3. Multi-task recurrent model for ASR and SRE, an example. W ith all the abov e alternativ es, the multi-task recurrent model is rather fle xible. The structure sho wn in Fig. 3 is just one simple example, where the recurrent information is e xtracted from both the recurrent projection r t and the nonrecurrent projection p t , and the information is applied to the non-linear function g ( · ) . W e use the superscript a and s to denote the ASR and SRE tasks respecti vely . The computation for ASR can be expressed as follows: i a t = σ ( W a ix x t + W a ir r a t − 1 + W a ic c a t − 1 + b a i ) f a t = σ ( W a f x x t + W a f r r a t − 1 + W a f c c a t − 1 + b a f ) g a t = g ( W a cx x a t + W a cr r a t − 1 + b a c + W as cr r s t − 1 + W as cp p s t − 1 ) c a t = f a t c a t − 1 + i a t g a t o a t = σ ( W a ox x a t + W a or r a t − 1 + W a oc c a t + b a o ) m a t = o a t h ( c a t ) r a t = W a rm m a t p a t = W a pm m a t y a t = W a y r r a t + W a y p p a t + b a y and the computation for SRE is as follows: i s t = σ ( W s ix x t + W s ir r s t − 1 + W s ic c s t − 1 + b s i ) f s t = σ ( W s f x x t + W s f r r s t − 1 + W s f c c s t − 1 + b s f ) g s t = g ( W s cx x s t + W s cr r s t − 1 + b s c + W sa cr r a t − 1 + W sa cp p a t − 1 ) c s t = f s t c s t − 1 + i s t g s t o s t = σ ( W s ox x s t + W s or r s t − 1 + W s oc c s t + b s o ) m s t = o s t h ( c s t ) r s t = W s rm m s t p s t = W s pm m s t y s t = W s y r r s t + W s y p p s t + b s y I I I . E X P E R I M E N T S The proposed method was tested with the WSJ database, which has been labelled with both w ord transcripts and speaker identities. W e first present the ASR and SRE baselines and then report the multi-task model. All the experiments were conducted with the Kaldi toolkit [16]. A. Data • Training set: This set inv olves 90% of the speech data randomly selected from train si284 (the other 10% used for speaker identification test whose results for almost all systems were perfect thus not presented). It consists of 282 speakers and 33 , 587 utterances, with 40 - 144 utterances per speaker . This set was used to train the two LSTM-based single-task systems, an i-vector SRE baseline, and the proposed multi-task system. • T est set: This set in volv es three datasets (de v93, ev al92 and ev al93). It consists of 27 speakers and 1 , 049 utter- ances. This dataset was used to ev aluate the performance of both ASR and SRE. For SRE, the ev aluation consists of 21 , 350 target trials and 528 , 326 non-target trials, constructed based on the test set. B. ASR baseline The ASR system was built largely following the Kaldi WSJ s5 nnet3 recipe, except that we used a single LSTM layer for simplicity . The dimension of the cell was 1 , 024 , and the dimensions of the recurrent and nonrecurrent projections were set to 256 . The target delay was 5 frames. The natural stochastic gradient descent (NSGD) algorithm was employed to train the model [17]. The input feature was the 40 - dimensional Fbanks, with a symmetric 2 -frame window to splice neighboring frames. The output layer consisted of 3 , 419 units, equal to the total number of pdfs in the con ventional GMM system that was trained to bootstrap the LSTM model. The baseline performance is reported in T able I. T ABLE I A S R B A SE L I NE R E S ULT S . dev92 ev al92 ev al93 T otal WER% 8.36 5.14 8.06 7.41 C. SRE baseline W e built two SRE baseline systems: one is an i-vector system and the other is an ‘r-vector’ system that is based on the recurrent LSTM model. For the i-vector system, the acoustic feature was 39 - dimensional MFCCs. The number of Gaussian components of the UBM was 1 , 024 , and the dimension of i-vectors was 200 . For the r-vector system, the architecture was similar to the one used by the LSTM-based ASR baseline, except that the dimension of the cell was 512 , and the dimensions of the recurrent and nonrecurrent projections were set to 128 . Additionally , there was no target delay . The input of the r- vector system w as the same as ASR system, and the output was corresponding to the 282 speakers in the training set. Similar to the work in [3], [4], the speaker vector (‘r-vector’) was deri ved from the output of the recurrent and nonrecurrent projections, by av eraging the output of all the frames. The dimension was 256 . The baseline performance is reported in T able II. It can be observed that the i-vector system generally outperforms the r- vector system. Particularly , the discriminativ e methods (LDA and PLD A) offer much more significant impro vement for the i- vector system than for the r-v ector system. This observation is consistent with the results reported in [4], and can be attributed to the fact that the r-v ector model has already been learned ‘discriminativ ely’ with the LSTM structure. For this reason, we only consider the simple cosine kernel when scoring r- vectors in the following experiments. T ABLE II S R E B A SE L I NE R E S ULT S . EER% System Cosine LDA PLDA i-vector (200) 2.89 1.03 0.57 r-v ector (256) 1.84 1.34 3.18 D. Multi-task joint training Due to the flexibility of the multi-task recurrent LSTM structure, it is not possible to ev aluate all the configurations. W e chose some typical ones and report the results in T able III. W e just sho w the ASR results on the combined dataset mentioned before. Note that the last configure, where the recurrent information is fed to all the gates and the non-linear activ ation g ( · ) , is equal to augmenting the information to the input variable x . From the results sho wn in T able III, we first observe that the multi-task recurrent model consistently improves performance on both ASR and SRE, no matter where the recurrent infor- mation is extracted and where it applies. Most interestingly , on the SRE task, the multi-task system can obtain equal or ev en better performance than the i-vector/PLD A system. This is the first time that the two negati vely-correlated tasks are learned jointly in a unified framew ork and boost each other . For the recurrent information, it looks like the recurrent pro- jection r t is suf ficient to provide valuable supervision for the T ABLE III J O IN T T RA I N I NG R E SU LT S . Feedback Feedback ASR SRE Info. Input WER% EER% r p i f o g 7.41 1.84 √ √ 7.05 0.62 √ √ √ 6.97 0.64 √ √ 7.12 0.66 √ √ √ 7.24 0.65 √ √ 7.26 0.65 √ √ √ 7.28 0.59 √ √ 7.11 0.62 √ √ √ 7.11 0.67 √ √ √ √ 7.06 0.66 √ √ √ √ √ 7.23 0.71 √ √ √ √ √ 7.05 0.55 √ √ √ √ √ √ 7.23 0.62 partner task. In volving more information from the nonrecurrent projection does not offer consistent benefit. This observation, howe ver , is only based on the present experiments. W ith more data, it is lik ely that more information leads to additional gains. For the recurrent information ‘receiv er’, i.e., the component that recei ves the recurrent information, it seems that for ASR the input gate and the activ ation function are equally effecti ve, while the output gate seems not so appropriate. For SRE, all results seem good. Again, these observations are just based on a relative small database; with more data, the performance with different configurations may become distinguishable. I V . C O N C L U S I O N S W e report a novel multi-task recurrent learning architecture that can jointly train multiple ne gati vely-correlated tasks. Primary results on the WSJ database demonstrated that the presented method can learn speech and speaker models simul- taneously and improve the performance on both tasks. Future work in volves analyzing more factors such as target delay , exploiting partially labelled data, and applying the approach to other negati vely-correlated tasks. A C K N O W L E D G M E N T This work was supported by the National Science Foun- dation of China (NSFC) Project No. 61371136, and the MESTDC PhD Foundation Project No. 20130002120011. R E F E R E N C E S [1] G. E. Dahl, D. Y u, L. Deng, and A. Acero, “Context-dependent pre- trained deep neural networks for large-v ocabulary speech recognition, ” Audio, Speech, and Language Processing, IEEE T ransactions on , vol. 20, no. 1, pp. 30–42, 2012. [2] G. Hinton, L. Deng, D. Y u, G. E. Dahl, A.-r . Mohamed, N. Jaitly , A. Senior, V . V anhoucke, P . Nguyen, T . N. Sainath et al. , “Deep neural networks for acoustic modeling in speech recognition: The shared vie ws of four research groups, ” Signal Processing Magazine, IEEE , v ol. 29, no. 6, pp. 82–97, 2012. [3] E. V ariani, X. Lei, E. McDermott, I. Lopez Moreno, and J. Gonzalez- Dominguez, “Deep neural networks for small footprint text-dependent speaker verification, ” in Pr oceedings of IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2014, pp. 4052–4056. [4] L. Li, Y . Lin, Z. Zhang, and D. W ang, “Improved deep speaker feature learning for text-dependent speaker recognition, ” in Pr oceedings of APSIP A Annual Summit and Confer ence . APSIP A, 2015. [5] A. W . Senior and I. Lopez-Moreno, “Improving dnn speaker inde- pendence with i-vector inputs. ” in Pr oceedings of IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2014, pp. 225–229. [6] Y . Lei, L. Ferrer, M. McLaren et al. , “ A nov el scheme for speaker recognition using a phonetically-aware deep neural network, ” in Pro- ceedings of IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2014, pp. 1695–1699. [7] P . Kenny , V . Gupta, T . Stafylakis, P . Ouellet, and J. Alam, “Deep neural networks for extracting Baum-W elch statistics for speaker recognition, ” in Pr oceedings of Odyssey , 2014, pp. 293–298. [8] M. F . BenZeghiba and H. Bourlard, “On the combination of speech and speaker recognition, ” in European Confer ence On Speech, Communica- tion and T echnology (EUROSPEECH) , no. EPFL-CONF-82941, 2003, pp. 1361–1364. [9] X. Li and X. W u, “Modeling speaker variability using long short- term memory networks for speech recognition, ” in Pr oceedings of the Annual Confer ence of International Speech Communication Association (INTERSPEECH) , 2015. [10] A. Graves and N. Jaitly , “T ow ards end-to-end speech recognition with recurrent neural networks, ” in Proceedings of the 31st International Confer ence on Machine Learning (ICML-14) , 2014, pp. 1764–1772. [11] H. Sak, A. Senior, and F . Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling, ” in Pr oceedings of the Annual Confer ence of International Speech Com- munication Association (INTERSPEECH) , 2014. [12] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer , “End-to-end text- dependent speaker verification, ” arXiv preprint , 2015. [13] D. W ang and T . F . Zheng, “T ransfer learning for speech and language processing, ” in Proceedings of APSIP A Annual Summit and Confer ence . APSIP A, 2015. [14] J.-T . Huang, J. Li, D. Y u, L. Deng, and Y . Gong, “Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers, ” in Pr oceedings of IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2013, pp. 7304–7308. [15] N. Chen, Y . Qian, and K. Y u, “Multi-task learning for text-dependent speaker verification, ” in Pr oceedings of the Annual Confer ence of Inter- national Speech Communication Association (INTERSPEECH) , 2015. [16] D. Povey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech r ecognition and understanding , no. EPFL-CONF-192584. IEEE Signal Processing Society , 2011. [17] D. Povey , X. Zhang, and S. Khudanpur , “Parallel training of deep neural networks with natural gradient and parameter a veraging, ” arXiv preprint arXiv:1410.7455 , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment