Interactive Restless Multi-armed Bandit Game and Swarm Intelligence Effect
We obtain the conditions for the emergence of the swarm intelligence effect in an interactive game of restless multi-armed bandit (rMAB). A player competes with multiple agents. Each bandit has a payoff that changes with a probability $p_{c}$ per rou…
Authors: Shunsuke Yoshida, Masato Hisakado, Shintaro Mori
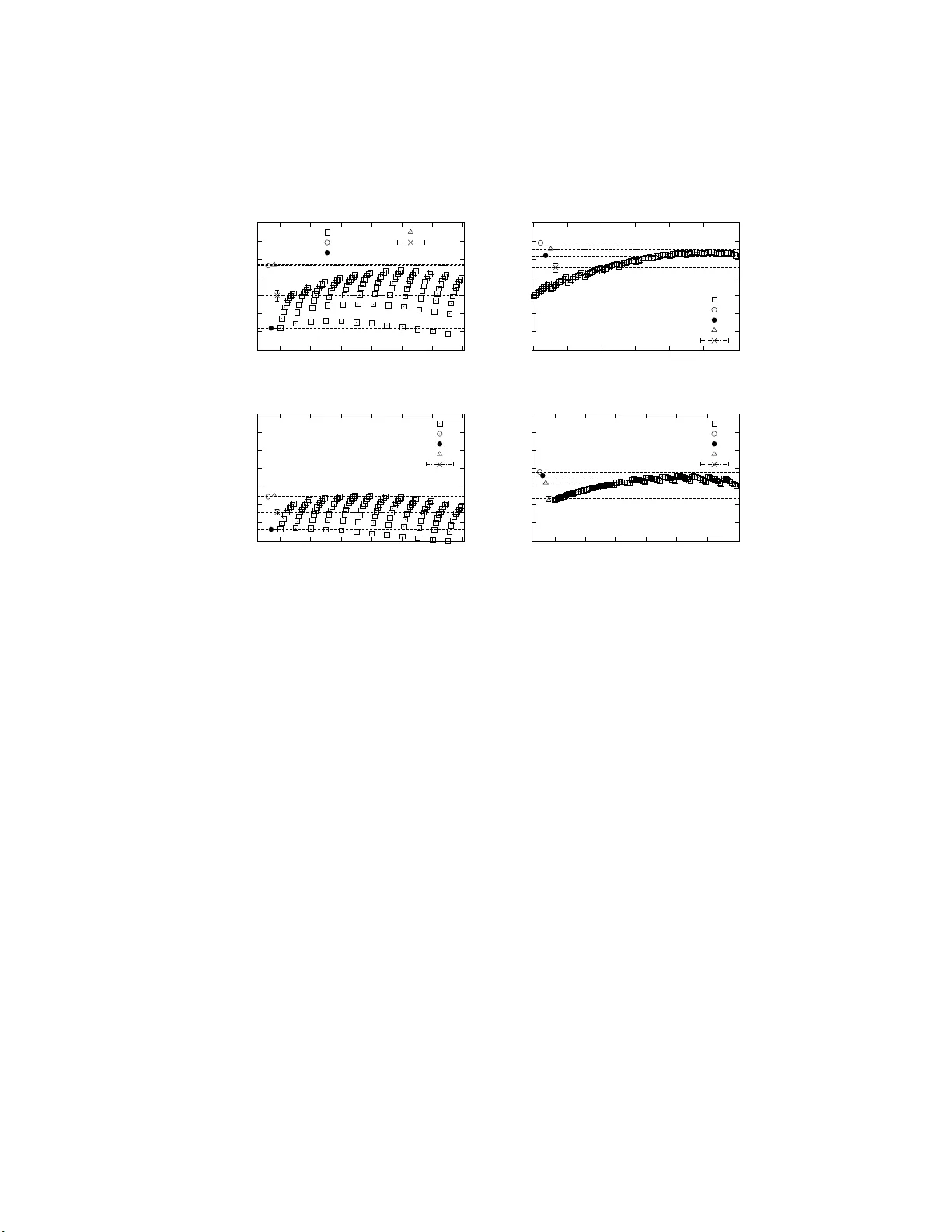
In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 1 In teractiv e Restless Multi-armed Bandit Game and Sw arm In tellige n ce Effect Sh unsuke Y oshida Kitasato University 1-15-1 Kitasato, Sagamih ar a, Kanagawa 252-0373 JAP AN Masato H isak ado Financial Servic es A gency 3-2-1 Kasumigaseki, Chi yo da-ku, T oky o 100-8967 JAP AN Shin taro Mori Kitasato University 1-15-1 Kitasato, Sagamih ar a, Kanagawa 252-0373 JAP AN shinta ro.mo ri@gmail.com Received 9 Sept emb er 2014 A bs tr act W e obtain the conditions for the e mer gence of the swarm int elligence effect in an interactive ga me of restless multi-armed bandit (rMAB). A pla yer comp etes with m ultiple agen ts. Ea ch bandit has a pay- off that changes with a probability p c per round. The agents a nd play er choose one of three options: (1 ) E x ploit (a g o o d bandit), (2) Innov ate (aso cial learning for a go o d bandit among n I randomly chosen ba ndits), and (3) Observe (so cial learning for a go o d bandit). Eac h ag en t has t wo parameters ( c, p obs ) to sp ecify the decision: (i) c , the thresho ld v a lue for Exploit, and (ii) p obs , the probability for Observe in lear ning. The pa- rameters ( c, p obs ) are unifor mly distributed. W e determine the optimal strategies for the pla yer us ing complete knowledge about the rMAB. W e show whether or no t so cial or aso cial learning is more optimal in the ( p c , n I ) space and define the sw arm in telligence effect. W e conduct a lab orator y ex p er imen t (67 sub jects) and observe the swarm int elligence effect only if ( p c , n I ) are chosen so that so cia l lear ning is far more o ptima l than aso cial le arning. 2 Shin taro M ori Keyw ords Multi-armed bandit, Swarm intelligence, Interactive game, Exp eriment, Optimal strateg y § 1 In tro duction The trade- off betw een the exploitation of go o d choices and the explo- ration of unknown but po ten tially more pr o fitable choices is a well-known pro b- lem 6, 10, 5) . A m ulti-armed bandit (MAB) provides the most t ypical environmen t for studying this tr ade-off. It is defined by sequential decision making a mong m ultiple choices that a re ass o ciated with a pay o ff. The MAB pr oblem involv es the maximization of the total reward fo r a giv en perio d or budget. In a v ariety of c ircumstances, exact or approximated o ptimal s tr ategies ha ve b een prop osed 2, 7, 11, 1, 13) . Recently , the MAB has a lso pr ovided a go o d environment for the trade- off betw een s o cial and aso cial lea rning 10) . Here, so cial learning is learning through observ ation o r interaction with o ther individuals, and aso cial learning is individual le a rning 8, 10, 6, 12) . The adv antage of so cial lea rning is its co st compared with aso cial lea rning. The disadv a n tage is its err or-pro ne nature, a s the infor mation o btained by so cial learning mig h t be o utdated o r inappropr iate. In order to clarify the optimal strategy in the environment with the tw o trade- offs, Rendell et a l. held a computer tour na ment using a restless multi-armed bandit (rMAB) 10) . Her e, restless means tha t the payoff o f eac h bandit changes ov er time. There ar e 1 0 0 bandits in an rMAB, and each ba ndit has a distinct pay o ff indep endently drawn fro m an exp onential distribution. The probability that a pay off changes p er r ound is p c . An agent ha s three options for each round: Inno v ate, Observe, and Exploit. Innov ate and Observe co rresp ond to aso cial and so cial lear ning, resp ectively . F or Innov ate, an a g ent o btains the pay o ff information of one randomly chosen bandit. F or Observ e, an ag en t obtains the pay off infor ma tion of n O randomly chosen ba ndits that were ex ploited by the agents during the previo us round. Compared to the information obtained by Innov ate, that obtained by Observe is older b y one round. F or Ex plo it, an agent c hoo ses a bandit that he has alre ady explored by Innov ate or O bs erve and obtains a pay off. In an rMAB environmen t, it is extremely difficult for ag en ts to optimize their choices 9, 10) . The outcome of the tour nament was that the winning strategies relied heavily on so cia l lear ning. This co nt radicted previous studies in which the o ptimal s trategy is a mixed one tha t relies on s o me combination of so cial and a s o cial learning. In the t ournament, the cost for Observe was not very In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 3 low, as a ppr oximately 5 0% o f the choices of Observe returns informa tio n that the ag ent s alr eady knew. The results o f the tournament imply the inadverten t filtering of information when an agent c ho oses Observe, as the agents c ho ose the bes t bandit during Ex ploit. In this pa p er , we discuss whether so cia l o r a s o cial learning is optimal in an rMAB, where a pla yer c ompe tes with many agen ts. W e a nswer t o the question why social learning is so adaptive in Rendell’s tournament. W e s upp os e that the cost of Innov ate b ecomes higher than that of Obs erve in the tour nament . In order to reduce the co st of Innov ate, we control the explor ation range n I for Innov ate, and a gents obtain the b est infor mation a bo ut the bandits among n I randomly chosen bandits. An rMAB is characterize d by tw o para meters, p c and n I . W e compare the av era ge pay offs of the optimal strategies when only Innov ate, only Observe, and b oth are av a ilable for learning using the complete knowledge of an rMAB and the information of the bandits exploited by ag ent s. W e determine the regio n in which each type of learning is optimal in the ( n I , p c ) pla ne and show that Observe is more adaptive than Innov a te for n I = 1 . W e define the swarm int elligence effect as the increase in the a verage pay off compa red with the payoffs of the optimal strategie s where only a s o cial lea rning is av ailable. W e hav e conducted a la bo ratory exp er imen t where 6 7 human sub jects comp eted with multiple agents in a n r MAB. If the pa rameters ar e chosen in the reg ion where so cia l lear ning is far more optimal than aso cia l learning, we obser ve the swarm int elligence effect. § 2 Restless m ulti-armed bandit in teractiv e game An int eractive rMAB ga me is a game in which a play er comp etes with 120 a gents using an rMAB. The play er aims to ma x imize the total pay off ov er 103 rounds and obtain a high ranking among a ll entrants. Below, we ter m the po pulation o f all agents and a play er as all entrants. The rMAB has N = 100 bandits, and we lab el them as n ∈ { 1 , 2 , · · · , N = 10 0 } . Ba ndit n has a distinct pa yoff s ( n ), and we term the ( n, s ( n )) pa ir as bandit informa tion. s ( n ) is a n integer drawn at random fro m an exp onential distributio n ( λ = 1; v alues were squared and rounded to give integers mo stly falling in the range of 0– 1 0 10) ). W e denote the pro bability function for s ( n ) as Pr( s ( n ) = s ) = P ( s ) (left figure in Figur e 1). W e write the exp ected v a lue of s ( n ) as E( S ( n )), and it is approximately 1.68. The pay off of each bandit changes indep endently b etw ee n 4 Shin taro M ori Fig. 1 Left: Plot of P ( s ). The exp ected v alue of s is E( s ) ≃ 1 . 68. R i gh t: Parameter assignmen t for agent i ∈ { 1 , 2 , · · · , 120 } . p obs ( i ) = 0 . 1 × ( i %10) ∈ { 0 . 0 , 0 . 1 , · · · , 0 . 9 } . c ( i ) = i/ 10 + 1 ∈ { 1 , 2 , · · · , 12 } . rounds with a pr obability p c , with new pay off drawn at rando m from the same distribution. Every entrant has his own rep ertoire a nd can store at most three pieces of bandit information. The ba ndit infor ma tion has a time sta mp when the ent rant obtains it. The time stamp is up dated when the entran t obtains new bandit information ab out the bandit. When an entran t obtains more tha n thr e e pieces of bandit information, the one with the oldest time stamp is er a sed fro m the repe r toire. There are three p os sible mo ves for the entran ts: Innov a te, O bserve, and Exploit. Inno v ate and Observe are learning pro cesses to obtain bandit information. E xploit is the exploitation pro cess that obtains some payoff. • Innov ate is individual learning , and an entrant obtains bandit informa- tion. n I bandits are chosen at ra ndom a mong N = 10 2 bandits, and the bandit information with the maximum payoff is pro vided to the entran t. If there are sev eral bandits with the s a me ma ximum pay off, o ne o f them is c hosen at rando m. • Observe is so cial learning, and an entran t obtains the bandit information exploited by an agent during the previous round. If there ar e many ag e nts who exploited a bandit, an age nt is r andomly chosen among them, a nd its ba ndit infor ma tion is provided to the entran t. If there a re no such In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 5 agents, no bandit information is pr ovided. The informa tion obtained by Observe is one r ound older than that obtained by Innov ate. • Exploit is the ex ploitation o f a ba ndit. An ent rant choo ses a bandit from his rep ertoir e and exploits the bandit. E ven if the bandit infor mation is ( n, s ( n )), as the infor mation c hanges with a probability p c per round, he do es not ne c essarily receive the pay off s ( n ). The rep ertoir e is up dated a fter a mov e. F or Innov ate, the ba ndit in- formation with the maximum pay off s I among n I randomly chosen ba ndits is provided to the entran t. W e denote the dis tr ibution function of s I as P I ( s ) = Pr( s I = s ). Intu itively , s I is chosen in the r egion of upper probability 1 /n I of P ( s ). W e denote the exp ectation v a lue of s I as E( s I ). If n I > 1, E( s I ) > E( s ) holds. F or exa mple, E( s I ) ≃ 9 . 63 for n I = 10. By co n trolling n I , we can change the cost o f Innov ate. 2.1 Agen t st r ategy W e explain the stra teg y of the agents. The mos t imp orta n t factor in the p erformance of the str ategies in Rendell’s tourna men t was the prop ortio n of O bserve in lear ning 10) . The hig h p erfor mance of Obs e rve originated from the inadverten t filtering of bandit information, as the agents ex ploited the best bandit in their rep ertoires . If the agents choos e at random, Observe do es not provide go o d bandit information. W e take these fa c ts into acc ount and introduce a simple strategy for the agents with tw o parameters c a nd p obs . • c : ev er y agent has a threshold v a lue c . If there is no bandit in one’s rep ertoire who se pay off is gr eater than c , the age nt will lear n by Innov ate or Observe. • p obs : a n a gent chooses Observe with a pr o bability p obs when he lea r ns. W e la b el 120 ag e n ts as i ∈ { 1 , 2 , · · · , I = 1 20 } . Agen t i has the par a m- eters ( c ( i ) , p obs ( i )). c ( i ) is given a s the quo tien t i / 10 plus one. p obs ( i ) is the remainder o f i %10 m ultiplied b y 0 .1. The assig nmen t o f ( c, p obs ) to agent i is represented in the right fig ure in Fig ure 1. 2.2 Game en vironmen t A play er participated in a ga me and comp eted with N agents. How e ver, the g ame did not adv a nce on a real-time basis . Age nts had already participa ted in the game for 1000 rounds. When a play er participated in the game, 1 03 sequential ro unds were randomly c ho sen from t he 1000 rounds, and he competed 6 Shin taro M ori Fig. 2 The interact ive rMA B game online interface. A human pla ye r i s presen ted with the present round t/ 100, his ranking among 121 entran ts (one play er and 120 agents), and his repertoir e. He mu st choose one among Inno v ate, Exploit a bandit, and Observe . In his reper toir e, only ( n, s ( n )) is sho wn. The bandit inf ormation fr om left to r i gh t indicates the new est to oldest information, resp ectiv ely . with agents for 103 ro unds. W e denote the r ound b y t ∈ {− 2 , − 1 , 0 , 1 , 2 , · · · , T = 100 } . The score s of the pla yer and a gents were set to zero. The a gents had already stored a t most thr e e pieces of bandit informa tion in their r ep ertoires. The player had three rounds to learn the r MAB. He could choose Innov ate or Observe for three rounds and s to red at most three pieces of bandit information in his re p er toire. After three rounds, the rMAB game started. As the agent s ha d already finished the game, they could not observe the information o f the pla yer. On the o ther ha nd, the pla yer co uld o bserve the information of the agents. The game e n vironment w as co nstructed a s a website. The informatio n of the agen ts fo r 1000 r o unds w as stored in a database of the w ebsite. The play er used a tablet (7 inch) and par ticipated in the g ame through a web browser. The play er ha d to lear n for three rounds and s tored at most three pieces of bandit information in his rep ertoire. Afterwards, the game s tarted. Figure 2 sho ws the int erface of the r MAB g ame. F or the present round t , the ranking and score are shown o n the screen. The player had to choo se an action among Innov ate, Exploit, a nd Obser ve. F or Exploit, the play er had to choo se which bandit he would exploit in his r ep e rtoire. Then, the pay off and new ranking were shown on the sc r een, and the game pro ceeded to the next round. In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 7 F or the par ameters ( n I , p c ) o f the rMAB, w e adopted the nex t four combinations. W e call the co m binations A, B, C, and D. A: ( n I , p c ) = (1 , 0 . 1 ). p c is small and the c hange in the pay off of a bandit is slow. As n I = 1 , E ( s I ) = E( s ), and it is difficult to find a bandit with high pa yoff with Inno v ate. B: ( n I , p c ) = (10 , 0 . 1). p c is small, as in A. As n I = 10, E ( s I ) ≃ 9 . 63 is large, and go o d bandit information can be obtained with Innov ate. C: ( n I , p c ) = (1 , 0 . 2). p c is lar ge, and the bandit informa tio n c hanges fre- quently . As n I = 1, it is difficult to o btain go o d bandit information with Innov ate. D: ( n I , p c ) = (10 , 0 . 2). p c is la rge, as in C. As n I = 10, go o d bandit infor - mation can b e obtained with Innov ate. 2.3 Exp erimen tal pro cedure The exp eriment repor ted here were conducted at t he Infor mation Science ro om at Kitasato Univ er s it y . The sub jects included students from the university , mainly from the Schoo l o f Science. The num b er of sub jects S was 67. Each sub ject participated in the game at most four times. The sub jects entered a ro om and sa t down o n a chair. After listening to a brief expla nation ab out the exp eriment and reward, they signed a consent do cument for participa tion in the experiment. Afterwards, they logged into the exp eriment w e bs ite using the IDs written o n the co nsent do cument. The ga me environmen t was chosen among the four cases A, B, C, and D, and they started their g ames. After 100 + 3 rounds, the game ended. The sub jects logg ed into the website a gain to participate in a new game. Within the a llotted time of approximately 4 0 min, most sub jects par ticipated in the game at least three times. Sub jects w ere paid up on b eing released from the exp eriment. There were s light differences in the exp erimental setup and rewards among the sub jects. F or the firs t 21 sub jects (July 201 4 ), there was no par- ticipation fee. The r eward w as completely determined b y the num b er of times that they entered the T op 20 among the 120 + 1 entrant s in ea ch g ame. Their rewards were a pr epaid card of 300 yen (approximately $2.50) for eac h placement within the T op 2 0. The sub ject co uld cho ose the game environment at the start of the game. They could choose each environment at most o nce, a nd the av er- age n um b er of sub jects in each environment is approximately 19. They did not know the parameter s of ea ch environment. F o r the last 46 s ub jects (December 8 Shin taro M ori 2014) there was a 1 0 50 yen (approximately $9) participation fee in addition to the p erfor mance-related reward. The reas on for the change in the reward is to recruit more sub jects. They were as ked to play the game at least three times during the allotted time. The ga me environmen t was randomly chosen by the exp erimental pr o gram. The av e r age n umber of sub jects in ea ch en vironment is approximately 37. A total of 67 sub jects pa rticipated in the exp er imen t, and we gathered data fro m approximately 56 sub jects for each game en vironment. § 3 Optimal strategy and sw arm int elligence ef- fect W e e stimate the ex p ected pa yoff of the optimal str ategies for the pla yer in the r MAB game. Here, o ptima l means to maximize the exp ected total pa yoff in a total of 100 + 3 rounds. F or the first three rounds ( t ∈ {− 2 , − 1 , 0 } ), the play er could choos e Innov ate or O bserve. After that, he could choos e all three options. The optimal c hoice for round t is defined as the choice that maximizes the expected payoff obtained during the remaining T − t rounds. W e assume that the pla yer ha s the complete k nowledge abo ut the r MAB game. More co ncretely , he knows p c , E( s ), and E( s I ) ab out the rMAB. F urther- more, he knows the bandit information exploited during the previous round. W e denote the average v alue of the payoff o f the exploited bandit at ro und t − 1 as O ( t ). If the play er ch o oses O bs erve for round t , the exp ected v alue of the pay o ff of the obtained bandit information is O ( t ). O ( t ) dep ends o n the a gents’ choices in the background. It is usua lly the most difficult quantit y to estimate for the play er in the g ame, as it dep ends on the s tr ategies o f the agents. With this informatio n, we estimated the ex pected v alue of the pay o ff p er round for the remaining r o unds for each choice. W e ass ume that there are M pieces o fba ndit information in the play er’s rep ertoire at ro und t . W e denote them as ( n m , s m , t m ) , m ∈ { 1 , · · · , M } . Here, t m is the round dur ing which the play er o btained the info r mation. When, the play er o btains info r mation from Innov ate or obtains up dated informatio n from Exploit a t t ′ , t m = t ′ . If the play er obtains information from O bserve at t ′ , t m = t ′ − 1, as Obser ve returns the bandit information fro m the previous round, t ′ − 1. W e denote the exp ected v a lue of the pay off per ro und for exploiting In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 9 bandit n m from t to T as E m ( t ). This quantit y is estimated as E m ( t ) = E( s ) + 1 T − t + 1 T X t ′ = t ( s m − E( s ))(1 − p c ) t ′ − t m = E( s ) + (1 − (1 − p c ) T − t +1 )( s m − E( s ))(1 − p c ) t − t m p c ( T − t + 1) (1) where (1 − p c ) t ′ − t m is the pro bability that the bandit informatio n do es not change from t m un til t ′ . During this p erio d, the pa yoff is s m . If the bandit information changes until t ′ , the probability for it is 1 − (1 − p c ) t ′ − t m , and the expected pay o ff of the bandit is given by E( s ). By summing these v alues and dividing by the nu mber of rounds T − t + 1, w e obtain the ab ov e expre s sion. W e denote the exp ected pay off per round for Innov a te a s I ( t ). F or Inno - v ate, a player do es not rec e ive any payoff. He only obtains bandit infor mation, and the exp ected v alue of the payoff of the o btained bandit information is E( s I ). W e e stimate the exp ected v alue of the payoff by Innov ate by a ssuming that the play er cont inues to exploit the new bandit with t he pay off E( s I ) from round t + 1 to T as I ( t ) = T − t T − t + 1 E( s )+ (1 − (1 − p c ) T − t )(E( s I ) − E( s ))(1 − p c ) p c ( T − t + 1) . (2) As the play er loses o ne r ound b ecause o f Innov ate, the pr e factor in front of E( s ) and the pow e r of (1 − p c ) a re reduced to ( T − t ) / ( T − t + 1) and ( T − t ) as compared with those in e q .(1). If n I = 1, E ( s I ) = E( s ), the s e cond term v anishes, a nd Innov ate is a lmost w orthless. F o r cases in which a ll of the pay offs of the bandit information in o ne’s r e per toire are zero or less than E( s ), it might b e optimal to choose Innov ate. Otherwise, instea d of losing o ne ro und and obtaining ba ndit information with a pa yoff E ( s ), it is optimal to choose Explo it with the ma x im um exp ected pay off. If p c is larg e, even if all the payoffs in one’s rep erto ire is zero , (1 − p c ) t − t m can b e negligibly small, a nd it is optimal to c ho ose E xploit. When n I > 1 and p c are not very large, Innov ate might b e optimal. Likewise, we estimate the expected pa yoff per round for Observe, which we denote as O ( t ). F or Obs e rve, a player obtains bandit information with a pay o ff O ( t ). The a g e of the information is one r ound older than the information obtained b y Innov ate. W e change E( s I ) to O ( t ) in eq.(2). Accounting for the age o f the ne w bandit information, we estimate O ( t ) a s 10 Shin taro M ori O ( t ) = T − t T − t + 1 E( s )+ (1 − (1 − p c ) T − t )( O ( t ) − E( s ))(1 − p c ) 2 p c ( T − t + 1) . (3) Comparing I ( t ) and O ( t ), which is more o ptimal depends on p c and E( s I ) − O ( t ). If p c is s ma ll and 1 − p c ≃ 1, the magnitude of the rela tionship b etw een E( s I ) and O ( t ) determines whic h is more optimal. The optimal stra tegy is to cho ose the action with maximum exp ected pay o ff during every ro und t ∈ {− 2 , − 1 , · · · , T = 100 } . F or example at t = T , the last round of the g ame, as I ( T ) = O ( T ) = 0 ho lds, it is optimal to choose Exploit for ba ndit m with the maximum E m ( T ). In the first three ro unds where the player can choose only Innov ate or Obser ve, if b oth p c and n I are s mall, E( s I ) < O ( t ) usually holds. Obse r ve is more optimal than Innov ate in this case. The situation is the same in la ter r ounds, and the o ptimal str ategy is a combination of Ex ploit and O bserve. Conversely , if b oth p c and n I are large, even if O ( t ) ≃ E( s I ), (1 − p c ) < 1 and I ( t ) > O ( t ) hold. W e estimate the exp ected pay off p er r o und for several “o ptimal” str ate- gies with a re s triction on the choice of learning. W e cons ider three strateg ies, and an Explo it-only strategy a s a control str a tegy . • I+O: The play er ca n choo se b oth Innov ate and Observe when learning. In the first three rounds, Innov ate is chosen. Then, the a ction with the highest expected pay off is chosen in the later rounds. • I: The pla yer can choose Innov ate for learning. The other conditions are the same a s I+O. • O: The play er can choo se Observe for learning. The other conditions are the same a s I+O. • EO: The play er can ch o ose Exploit with the maximum exp ected pay o ff after the fir st thr ee rounds. The exp ected payoffs per round for these strateg ie s a r e wr itten as I+O , I , O , and EO , r esp ectively . W e also denote the exp ected pa yoff p e r ro und for agent i as P(i) . They are estimated by a Mo nt e Carlo simulation. W e hav e per formed a simulation of a ga me in which 12 0 age nts a nd four play ers with ab ove strate- gies pa rticipate 1 0 4 times. As we hav e expla ined in the exp erimental pro cedure, the agents ca nnot obser ve the bandit information e x ploited by the play er. Only play er can obs e rve the bandit information of the agents. As there is no interac- tion b etw e en the play er s, we can estimate the expected pa y offs of the four pla yers simult aneously . In the exp eriment, the play er ca n choose Observe for the first three rounds. With the a b ove s trategies, the play er can choose Innov ate o nly In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 11 Fig. 3 Optimal learning in ( n I , p c ). The thick s olid l ine shows the boundary betw een the region I > O an d th e region O > I . The dotted line sho ws the b oundary beyo nd which EO ≃ I+O . for simplicit y . T he players and ag e n ts comp ete on equal terms. W e s ummarize the results in Figure 3. In ( n I , p c ) pla ne, w e show which strategy is mor e optimal, I or O . The thick s o lid line shows the bounda ry where I = O . In the lo wer-left regio n O > I holds. As n I and p c are small, the rela tio nship O ( t ) > E( s I ) holds, and Obse r ve b ecomes a o ptimal learning metho d. In the upper -right region, I > O holds. n I is large, and E( s I ) is gr eater than or comparable to O ( t ). As p c is large, the one round delay for ex ploiting the bandit information obtained b y Observe might b e crucial. The thin dotted line shows the b ounda r y b eyond which I+O is compa r able with EO . As p c is lar ge, the play er c an obtain co mparable pay o ffs b y only exploiting a go o d bandit in his r ep ertoire. There is neither an e xploitation–extr a po lation trade-o ff nor a so cial–as o cial le a rning tr ade-off ab ov e the dotted line. It is a noise- dominant region. One can understand why there is no so cial–a so cial lea rning trade-off in Rendell’s tournament 10) . In the tournament, they set n I = 1 and n O ≥ 1. Here, n O is the amount of bandit information obtained by Observe. If n I = 1, as we hav e ex plained previously , E ( s I ) = E ( s ) ho lds . If p c is small, O ( t ) is us ua lly greater than E( s ), as ag e nts exploit the g o o d bandit in their re p er toire. Then, an agent can obtain go o d bandit information by Observe, and O bs erve bec omes an optimal learning metho d. If p c is too lar ge, instea d o f tr ying to o btain go o d information with I nnov ate, it is o ptimal to wait sp ontaneous changes in the bandit info r mation in the r eper toire. Exploiting a g o o d bandit in one’s 12 Shin taro M ori rep ertoire (EO strategy ) is enough, and no other strateg y cannot exceed the per formance of E O. In the reg io n where O > I and I+O > EO , so cial learning is e ffective, and a sw arm intelligence can emerg e. W e define the swarm intelligence effect a s the increase in the p erformance compared to I . In the next section, we es timate the swarm intelligence effect for human sub jects. As for the c hoice of ( n I , p c ), we hav e studied fo ur cases A:(1,0.1), B:(10,0.1 ), C:(1,0.2), and D:(10,0 .2). W e show the p ositions for these choices in figure 3. F or cases A and C, O >> I , and one exp ect to observe the swarm in telligence effect in human sub jects. F or ca ses B and D, where O ≃ I and O < I , one do es not exp ect to observe it. W e make a comment abo ut the definition o f the s warm in telligence e ffect. F or the estimation of I , we assume that the play er knows p c , E( s ), and E( s I ) and can choose the b est option amo ng Exploit and Innov ate. The play er has to estimate this information from his actions in the real g ame. If the pla yer cannot choo se Obser ve, his per fo rmance canno t exceed I . The definition o f the swarm intelligence effect o nly provides a low er limit. T oy o k aw a 12) defined it as the surplus in p erfor ma nce compared to when the same play er can only choose Innov ate. Our definition has the adv antage that it can b e estimated easily without p er forming a n exp eriment. The same r easoning a pplies to I+O . In this case, the player kno ws everything that is related with his decisio n ma king. I+O provides an upper limit on the per formance of the play er in the game. § 4 Exp erimen tal results In this sec tion, we explain the exp erimental results. W e estimate the swarm in tellig ence effect for hum an sub jects. W e p erform a regre ssion analysis of the p erfor mance of each sub jects in each ex per iment al en vironment. 4.1 Sw arm intelligence effect W e c alculated the total payoff of eac h sub ject for 100+ 3 r ounds in each game environmen t. W e divided the total payoff by 100 and obtained the av er age pay o ff per r ound. F or ea ch g a me environment, we estimated the average v alue of the av erage pay offs p er r ound for approximately 56 sub jects a nd denote it as H . This repres e nts the av erage p erfor ma nce of human sub jects in each case. W e compare H with I+O , I , O , and P(i) for agent i . Figure 4 sho w the r esults for cases A, B, C, and D. W e ex plain the re sults o f each c ase. A: Case A is in the regio n where wher e O > I , and Observe is optimal for In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 13 2 4 6 8 10 12 14 16 0 20 40 60 80 100 120 Payoff/round i A: p c =0.1,n I =1 P(i) I+O=11.3 I=4.4 O=11.4 H=8.0 2 4 6 8 10 12 14 16 0 20 40 60 80 100 120 Payoff/round i B: p c =0.1,n I =10 P(i) I+O=13.8 I=12.4 O=13.1 H=11.1 2 4 6 8 10 12 14 16 0 20 40 60 80 100 120 Payoff/round i C: p c =0.2,n I =1 P(i) I+O=6.9 I=3.3 O=7.0 H=5.2 2 4 6 8 10 12 14 16 0 20 40 60 80 100 120 Payoff/round i D: p c =0.2,n I =10 P(i) I+O=9.6 I=9.2 O=8.4 H=6.7 Fig. 4 P l ots of P(i) ( ✷ ), I+O ( ◦ ), I ( • ), O ( △ ) and H ( × ). A:( p c , n I ) = (0 . 1 , 1), H (54)= 8 . 0 ± 0 . 6. B: ( p c , n I ) = (0 . 1 , 10), H (65)= 11 . 1 ± 0 . 5. C:( p c , n I ) = (0 . 2 , 1), H (54)= 5 . 2 ± 0 . 3. D:( p c , n I ) = (0 . 2 , 10), H (52)= 6 . 7 ± 0 . 3. The n umber in each parentheses is the num b er of sub jects i n eac h case. learning. As I+O ≃ O and O is m uc h greater than I , o ne ca n ex pec t the swarm in telligence effect. In fact, H , which is plotted with a chain line, is higher than I . F o r a fixed v alue of c , P(i) increa ses with p obs . F or the depe ndence of P(i) o n c for a fixed v a lue of p obs , there is a maxim um for some c . F or p obs = 0 . 0, P(i) is maximum at c ∼ 4. F or p obs = 0 . 9, P(i) is maximum at c ∼ 8 . 5. The a gent can o btain g o o d bandit informatio n by Observe, and they had better to adopt large c . B: Case B is in the r egion where O > I . How ever, it is near the b oundary for I = O , and the difference b et ween O and I is small. One cannot exp ect the swarm intelligence effect. In fact, H is below I . As I ≃ O , sub jects could not improve their perfor mance by O bserve. One see I+O > O , a nd the difference betw een I+O and O is sma ll. As n I = 10 is large, Innov ate is frequently more optimal than Obser ve. F or example, if an a gent finds that the pa y off of go o d bandit information changes to ze r o in round t 14 Shin taro M ori by Exploit, one can sus p ect that O bserve do es no t provide go o d ba ndit information. In particular, if the bandit is g o o d, a nd the payoff is hig h, one can assume that many agen ts also exploited the bandit. Then Obser ve should provide bandit information with zero payoff in round t + 1 with a high probability . P(i) is an increasing function o f p obs when c is small. When c is lar g e, P(i) does not dep end on c very muc h. When c is small, agents can easily obtain bandit informa tion whose pay off is gr eater than c . Then, the a g ent ex ploits the not so go o d bandit. On the other hand, if the agent obtains bandit informa tion by Observe, he can obtain go o d bandit information, as the bandit’s pay off exceeds the o ther agents’ c . O bserve is more optimal than Innov ate when c is sma ll. How ever, when c is large, the a gent can obtain g o o d bandit informatio n by Innov ate, as n I is lar ge. By Observe, the agent can obtain go o d bandit information, and there is not a big difference in the p e r formance of I and O . As a result, P(i) do es not depend very muc h on p obs when c is lar ge. C: Case C is in the region where O > I . I+O ≃ O , a nd O is m uch gre a ter than I , as with case A. One can observe the swarm in tellig ence effect bec ause H is grea ter than I . Because p c is lar ge, the exp ected pay offs and average pay o ff of the sub jects a re lo wer than those for cas e A. D: Case D is in the reg io n where I > O , and Innov ate is optimal for learning. As I+O > I , Observe is optimal in s ome cases. When c is large, P(i) is a decreasing function o f p obs . As bo th p c and n I are larg e, instead of obtaining go o d bandit information by O bserve, Innov ate succeeds in obtaining new and g o o d bandit information. When c is small, as in case B, the a gent can obtain be tter bandit information by Observ e than Inno v ate. One cannot o bserve the sw arm intelligence effect, as in ca se B. 4.2 Regression analysis of the p er formance of individual sub jects W e pe r form a statistical analysis of the v ariation in the payoffs o f the sub jects in the four cases. W e examined the factors that made strateg ies suc- cessful by using a linea r multiple reg ression analy sis. In Rendell’s tour nament, there were fiv e predictors in the b est-fit mo del for the p erformance of the strate- gies 10) . Among them, we considered three predictors: r learn , the prop or tion of mov es that involv e d learning of any k ind; r obs , the pr o po rtion o f learning mov es In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 15 that were Observe; and ∆ t learn , the average ro und betw een lea rning mov es. Other predictors were the v ariance in the num be r o f rounds to first use o f Ex- ploit and a qualitative predicto r of whether or not the agent progr a m e stimates p c . F or the latter, we supp ose that hum an sub jects estimated p c , or they could notice whether the freq uency of the change in bandit informa tio n is high or low. F or the former predictor , it is imp ossible to estimate it, as the s ub jects pa rtic- ipated in the ga me at most once for eac h case. W e do not include these tw o predictors in the r egressio n mo del. W e deno te the average payoff p er rounds for sub ject j a s pay of f ( j ). The multiple linear regress ion mo del is written as pay of f ( j ) = a 0 + a 1 · r learn ( j ) + a 2 · r obs ( j ) + a 3 · ∆ t learn ( j ). W e s elect the mo del with maxim um ˜ R 2 . The re s ults a re summar ized in T a ble 1. T able 1 Parameters of the li near multiple regression mo del predicting the av erage pay off per r ound in each game en vironment . F rom the second to fourth columns, the inte rcepts and regression coefficients for r lear n , r obs , and ∆ t lear n are shown . n.s. for p > 0 . 05,* f or p < 0 . 05,** for p < 1 0 − 2 ,*** for p < 10 − 3 and **** for p < 1 0 − 4 . Case Int ercept r learn r obs ∆ t learn ˜ R 2 A(53) 10.0 (****) -11.0(* * ) 3.3 ( p = 0 . 16) n.s. 0.2 53 B(65) 14.1 (****) -10.7 (*) n.s. n.s. 0.0 76 C(54) 8.37 (***) -8.2 (**) 3.0 (*) -0.49 ( p = 0 . 06) 0.1 86 D(52) 8.7 (****) -7.2 (**) 1.4 ( p = 0 . 23 ) n.s. 0.144 ALL(224) 12.0 (*** *) -13.8 (****) 1.3 ( p = 0 . 1 5) n.s. 0.24 6 r learn had a negative effect on the p erfo rmance o f the s ub jects, as in Rendell’s tour nament. This result suggests that it is sub optimal to inv est to o m uch time in lea rning, as one ca nnot obtain any pay offs for lear ning. F or r obs , the results are not c o nsistent with the results of Rendell’s tourna men t. There, the predictor ha d a strong pos itive effect, whic h reflected the fact that the best strategy w as to almost exclusiv ely cho ose O bs erve r ather tha n Innov ate. In our exp eriment, the pr e dictor seems to ha ve a pos itiv e effect fo r cases A, C, and D. F or cases A and C, it is consistent with the results in the previous section bec ause O > I , and O bserve is mor e o ptimal than Innov a te. In case D, a s H is m uch less than b oth I and O , obtaining goo d bandit infor mation fro m the agents by Observe might improve the p erfor mance. § 5 Conclusion 16 Shin taro M ori In this paper , we attempt to clar ify the o ptimal stra tegy in a tw o tra de- offs environmen t. Here, the tw o trade-offs are the trade-off of exploitation– exploratio n a nd tha t of so cial–a so cial learning. F o r this purpos e , we hav e devel- op ed an interactiv e rMAB ga me, where a play er c o mpetes with multiple agents. The player and a g ents choos e an action from three options: Exploit a ba ndit, Innov ate to obta in new ba ndit infor mation, and Obser ve the bandit informa tion exploited b y other agen ts. The rMAB has t wo para meters, p c and n I . p c is the probability for a change in the environment. n I is the scop e of ex plo ration for aso cial learning. The a gents ha ve t wo parameters for their decision making, p obs and c . p obs is the probability for Observe when the agents learn, a nd c is the threshold v a lue for Ex plo it. W e hav e e stimated the average pa y off of the optimal strategy with some restrictions o n learning and complete knowledge abo ut r MAB and the bandit information exploited during the previous r ound. W e consider thr e e types o f optimal str ategies, I+O , I , a nd O , where b oth Innov ate a nd O bserve, Inno v ate, and O bserve are av ailable. In the ( n I , p c ) plane, we hav e derived the strategy that is more optimal, either O or I . F urther more, we hav e defined the swarm int elligence effect a s the surplus of the p er fo rmance o f I . The e stimate o f the swarm int elligence effect provides o nly a low er b ound fo r it; how ev er, the es- timation is e a sy a nd ob jective. W e a lso p oint out that the swarm intelligence effect can b e observed in the region of the ( n I , p c ) plane wher e O is more optimal than I . W e hav e p erformed an exp eriment with 67 s ub jects and have gathered approximately 56 samples for the four cases o f ( n I , p c ). If ( n I , p c ) a re chosen in the regio n where O is far mor e optimal that I , we ha ve observed the swarm int elligence effect. If ( n I , p c ) are chosen nea r the b oundary of the tw o regions or in the region where I is more optimal tha n O , w e did not observe the swarm int elligence effect. W e have p erformed a regre ssion analysis of the p erfor mance of each sub ject in each case. Only the propor tion of lear ning is the effective factor in the four case s. In co n trast, the prop ortion of the use of Observe for learning is not significa n t. As the agent’s decision making algo rithm is to o simple, it is difficult to belie ve that the conditions for the emergence of the swarm intelligence in Figure 3 ar e gener al. In addition, the ana lysis of the h uman sub jects is to o supe r ficial, as we only s tudied the corr e lation betw een the p erforma nce and so me predictive factors. With these p oints in mind, we make three comments ab out future problems. In teractiv e Restless Multi-armed Bandit Game and Swarm In telligence Effect 17 The first one is a mor e elab or ate and a utonomous mo del of the de- cision ma king in an rMAB environment. The algorithm needs to es timate p c , E( s ) , E( s I ), and O ( t ) for round t on the basis of the data that the agent has o bta ined thro ugh his choices. Then, the agent can c hoo se the most optimal option during each round and maximize the exp ected total payoff o n the ba sis of these estimates. This is an ada ptiv e autono mous agent mo del. With this mo del, we ca n understand the decisio n making of h umans in the rMAB game more deeply . It is imp oss ible to unders tand h uman decision making c ompletely with exp erimental data. O n the bas is of the mo del, we can detect the deviatio n in h uman decisio n making and prop ose a decision ma k ing mo del for a human that can b e tested in other exper iment s. The second one is the colle ctive behavior o f the a bove adaptive au- tonomous ag ent s or humans. It is necessa ry to clar ify how the conditions for the emergence of the swarm intelligence effect w o uld change. In the case o f a popu- lation of a da ptive autonomous agents, they w ould estimate the optimal v alue of p obs for the environmen t ( n I , p c ) and collectively realize the optimal v a lue. The optimal strategy should be neither I nor O but a mixed strategy of Inno v ate and Observe. Then, the c o ndition for the emerg ence of the swarm intelligence effect is that the p erfor mance of I+O is equal to that of I . If the p erformance of the former is greater than that of the la tter for an y ( n I , p c ), the swarm intelligence effect can always emer ge, except fo r the noise- dominant region. After tha t, w e can study the conditions with human sub jects exp erimentally . A human sub ject participates in the r MAB game a s a player, as in this study , or ma n y human play er s participate in the game to comp ete with each o ther. The targ et is how and when humans collectiv ely solve the rMAB problem. The third one is the design of an environmen t in which swarm in telli- gence works. In this s tudy , we cho ose the rMAB interactiv e ga me and study the co nditions for the emer g ence of the s warm intelligence effect for a player. How ever, there are man y degre e s of freedom in the design of the game. F or example, when an agent observes, there ar e man y deg rees of freedom regarding how bandit informatio n is provided to the age n t. In the prese nt game environ- men t, the pr obability that a bandit exploited in the previo us round is chosen is prop or tional to the num b er of ag ents who hav e exploited it. Instead, we ca n consider an en vironment in which the bandit information of the most exploited bandit is provided, the ba ndit infor mation o f the agen ts who are near the agen t is provided, or the pla yer c an choo se a bandit b y sho w ing him the num b er of a gents 18 Shin taro M ori who have exploited the bandit. W e think these changes should affect the c hoice and p erforma nce of the player. It was shown experimentally that by pro viding sub jective information a bo ut a bandit, the p erfor mance o f the sub jects dimin- ished 12) . W e think that the interaction betw een the design of the environment and the decisio n making, p er formance, and swarm in tellig e nce effect s hould b e a very impo rtant problem in the industr ial usage of the swarm intelligence effect. A cknow le d gment W e thank the refer ees for their useful commen ts and criticisms. This work w as suppor ted b y a Grant-in-Aid fo r Challenging Explora tory Resear ch 256 10109 . R efer e nc es 1) Auer, P ., Cesa-Bianchi, N. and Fisher, P ., ”Finite-time analysis of the multi- armed bandit problem,” Mach. L e arn. 47 , p p. 235-256, 2002. 2) Berry , D. and F ristedt, B., eds., Bandit Pr oblems: Se quential Al lo c ation of Exp eriments , Springer, Berlin, 1985. 3) Galef, B. G., ”Strategies for so cial learning: T esting pred ictions from formal theory ,” A dv. Stud. Behav. 39 , pp. 117-151, 2009. 4) Giraldeau, L.-A.,V alone, T. J. and T empleton, J. J., ”Poten tial disadv antages of using so cially acquired information,” Philos. T r ans. R. So c. L ondon Ser. B, 357 , pp. 1559-1566, 2002. 5) Gueudr´ e, T.,Dobrinevski, A. and Bouc haud, J. P ., ”Explore or exploit? A generic mo del and an exactly solv able case,” Phys. R ev. Le tt., 112 , pp . 050602 - 050606, 2014. 6) Kameda, T. and Nak anishi, D., ”Does social/cultural learning increase human adaptabilit y? Roger’s question revisited,” Evol. Hum. Behav., 24 , pp. 242-260, 2003. 7) Lai, T. and R obbins, H., ”Asymp totically efficien t adaptative all ocation rules,” A dv. Appl. Math., 6 , p p. 4- 22, 1985. 8) Laland, K. N., ”Ba ndit problems: Sequ entia l allocation of exp eriments,” L e arn. Behav., 32 , pp. 4-14, 2004. 9) P apadimitriou, C. H. and Tsitsiklis, J. N., ”The complexity of optimal queueing netw ork con t rol,” Math. O p er. R es., 24 , pp. 293-30 5, 1999 . 10) Rendell, L. et al., ”Why copy others? I n sigh ts from the social learning strategies tournament,” Scienc e, 328 , p p. 208-213, 2010. 11) Sutton, R. S . and Barto, A. G., ed s., R einfor c ement L e arning: An Intr o duction , Cam bridge, MIT Press, 1998 . 12) T oy ok aw a, W., Kim. H and Kameda, T. ”H u man collective in telligence u nder dual exploration-exploitation dilemma,” PL oS ONE, 9 , p. e95789, 2014. 13) White, J. M., Bandit Algor ithms f or Website Optimi zation , O’Reilly Media, 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment