Latent Variable Discovery Using Dependency Patterns
The causal discovery of Bayesian networks is an active and important research area, and it is based upon searching the space of causal models for those which can best explain a pattern of probabilistic dependencies shown in the data. However, some of…
Authors: Xuhui Zhang, Kevin B. Korb, Ann E. Nicholson
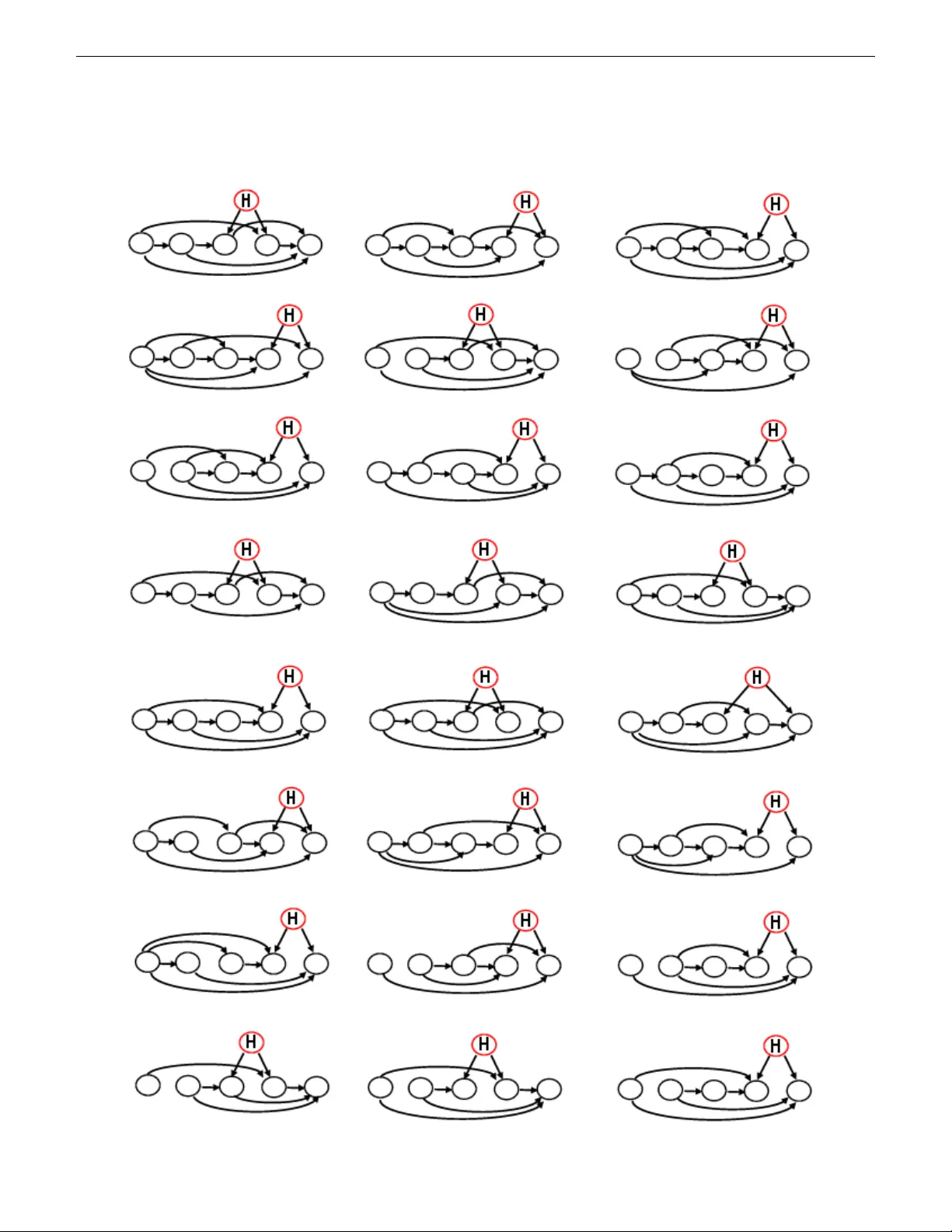
Latent V ariable Disco v ery Using Dependenc y P atterns Xuhui Zhang ∗ , K evin B. K orb † , Ann E. Nicholson ‡ , Ste ven Mascaro ‡ ∗ Clayton School of Information T echnology Monash Univ ersity Clayton, VIC 3800 A USTRALIA Bayesian Intelligence www.bayesian-intelligence.com Email: Xuhui.Zhang@monash.edu, kbkorb@gmail.com, Ann.Nicholson@monash.edu, sm@v oracity .com Abstract —The causal discovery of Bayesian networks is an active and important resear ch area, and it is based upon searching the space of causal models for those which can best explain a pattern of probabilistic dependencies shown in the data. Howev er , some of those dependencies are generated by causal structures involving variables which have not been measured, i.e., latent variables. Some such patterns of dependency “r eveal” themselves, in that no model based solely upon the observed variables can explain them as well as a model using a latent variable. That is what latent variable discovery is based upon. Here we did a search for finding them systematically , so that they may be applied in latent variable discovery in a more rigorous fashion. Index T erms —Bayesian netw orks, Latent v ariables, causal discovery , pr obabilistic dependencies I . I N T RO D U C T I O N What enables latent variable discov ery is the particular probabilistic dependencies between variables, will typically be representable only by a proper subset of the possible causal models ov er those variables, and therefore provide evidence in fa vour of those models and against all the remaining models, as can be seen in the Bayes factor . Some dependenc y structures between observed variables will provide e vidence fa voring latent variable models over fully observed models, 1 because they can explain the dependencies better than any fully observed model. W e call such structures “triggers” and did a systematically search for them. The result is a clutch of triggers, man y of which ha ve not been reported before to our knowledge. These triggers can be used as a data preprocessing analysis by the main discov ery algorithm. A. Latent V ariable Discovery Latent variable modeling has a long tradition in causal discov ery , beginning with Spearman’ s work [7] on intelligence testing. Factor analysis and related methods can be used to posit latent variables and measure their hypothetical ef fects. They do not provide clear means of deciding whether or not latent variables are present in the first place, howe ver , and in consequence there has been some controversy about that status 1 I.e., models all of whose variables are measured or observed. of exploratory versus confirmatory factor analysis. In this regard, causal disco very methods in AI ha ve the adv antage. One way in which discov ery algorithms may find evidence confirmatory of a latent variable model is in the greater simplicity of such a model relativ e to an y fully observed model that can represent the data adequately , as Friedman pointed out using the example in Figure 1 [1]. Figure 1: An illustration of how introducing a latent variable H can simplify a model [1]. Another advantage for latent variable models is that they can better encode the actual dependencies and independencies in the data. For example, Figure 2 demonstrates a latent variable model of four observed variables and one latent variable. If the data support the independencies W | = { Y , Z } and Z | = { W , X } , it is impossible to construct a network in the observed variables alone that reflects both of these independencies while also reflecting the dependencies implied by the d-connections in the latent v ariable model. It is this kind of structure which can allow us to infer the e xistence of latent v ariables, i.e., one which constitutes a trigger for latent variable discovery . Figure 2: One causal structure with four observed variables and one latent variable H . I I . S E A R C H I N G T R I G G E R S F O R L A T E N T V A R I A B L E S In this paper , latent variables are typically considered only in scenarios where they are common causes which having two or more children. As Friedman [1] points out, a latent variable as a leaf or as a root with only one child would marginalize out without affecting the distrib ution o ver the remaining v ari- ables. So too would a latent v ariable that mediates only one parent and one child. For simplicity , we also only search for triggers for isolated latent variables rather than multiple latent variables. W e start by enumerating all possible fully observed D AGs in a given number of variables (this step is already super exponential [6]!. Then it generates all possible d-separating evidence sets. For example, for the four variables W, X, Y and Z , there are eleven e vidence sets: 2 φ, { W } , { X } , { Y } , { Z } , { W X } , { W Y } , { W Z } , { X Y } , { X Z } , { Y Z } For each fully observed DA G it produces the corresponding dependencies for each e vidence set using the d-separation criterion (i.e., for the four variables W, X , Y and Z , the search produces elev en dependency matrices). Ne xt, it generates all possible single hidden-v ariable models whose latent v ariable is a common cause of two observed v ariables. It then generates all the dependencies between observed v ariables for each latent variable model, conditioned upon each evidence set. The set of dependencies of a latent variable model is a trigger if and only if these dependency sets cannot be matched by an y fully observed D AG in terms of d-separation. 3 W e ran our search for 3, 4 and 5 observed variables. Any structures with isolated nodes are not be included. As T able I shows, for three observed variables, we find no trigger, meaning the set of dependencies implied by all possible hidden models can also be found in one or more fully observed models. There are two triggers for four observed variables, the corresponding DA Gs are sho wn in T able II, together with the corresponding latent variable models. For fiv e observed variables, we find 57 triggers (see Appendix A). 2 Note that sets of three or more evidence variables leave nothing left over to separate. 3 In this search, labels (variable names) are ignored, of course, since all that matters are the dependency structures. Observed variables D A Gs Connected D AGs T riggers 3 6 4 0 4 31 24 2 5 302 268 57 T able I: Number of triggers found T able II: The D AGs of the two triggers found for four observed variables. All the dependency structures in the observed v ariables re- vealed as triggers will be better explained with latent variables than without. While it is not necessary to take triggers into account explicitly in latent variable discov ery , since random structural mutations combined with standard metrics may well find them, they can be used to advantage in the discovery process, by focusing it, making it more efficient and more likely to find the right structure. I I I . L E A R N I N G T R I G G E R S W I T H C AU S A L D I S C OV E RY A L G O R I T H M S The most popular causal discovery programs in general, come from the Carnegie Mellon group and are incorporated into TETRAD, namely FCI and PC [9]. Hence, they are the natural foil against which to compare anything we might produce. Our ultimate goal is to incorporate latent variable discov ery into a metric-based program. As that is a longer project, here we report experimental results using an ad hoc arrangement of running the trigger program as a filter to ordinary PC (T rigger-PC) and comparing that with the unaltered FCI and PC. Our experimental procedure, briefly , was: 1) Generate random netw orks of a given number of variables, with three categories of dependency: weak, medium and strong. 2) Generate artificial data sets using these networks. 3) Optimize the alpha level of the FCI and PC programs using the abov e. 4) Experimentally test and compare FCI and PC. The FCI and PC algorithms do not generally return a single D A G, but a hybrid graph [8]. An arc between two nodes may be undirected ’—’ or bi-directional ’ ↔ ’, which indicates the presence of a latent common cause. Additionally , the graph produced by FCI may contain ’o—o’ or ’o → ’. The circle represents an unknown relationship, which means it is not known whether or not an arro whead occurs at that end of the arc [8]. So, in order to measure how close the models learned by FCI and PC are to the true model, we developed a special v ersion of the edit distance between graphs (see the Appendix B). 2 A. Step one: generate networks with differ ent dependency str engths. Genetic algorithms (GAs) [5] are commonly applied as a search algorithm based on an artificial selection process that simulates biological e volution. Here we used a GA algorithm to find good representati ve, but random, graphs with the three lev els of desired dependency strengths between variables: strong, medium and weak. The idea is to test the learning algorithms across different de grees of difficulty in reco vering arcs (easy , medium and difficult, respectively). Mutual infor- mation [4] is used to assess the strengths of indi vidual arcs in networks. T o make the learning process more ef ficient, we set the arities for all nodes in a network to be the same, either two or three. W e randomly initialized all v ariables’ CPT parameters for each individual graph and used a whole population of 100 individuals. The GA was run 100 generations. W e ran the GA for each configuration (number of nodes and arities) three times, the first two to obtain networks with the strongest and weakest dependencies between parents and their children and the third time to obtain networks closest to the average of those two degrees of strength. B. Step two: generate artificial datasets. All networks with different arc strength lev els were used to generate artificial datasets with sample sizes of 100, 1000 and 10000. W e used Netica API [2] to generate random cases. The default sampling method is called “F orward Sampling” [3] which is what we used. Number of observed variables Structure type Number of structures T otal number of simulated datasets 4 Trigger 2 36 4 D A G 24 432 5 Trigger 57 1026 5 D A G 268 4824 T able III: Number of simulated datasets As T able III shows, there are a relatively large number of simulated datasets. This is due to the dif ferent state numbers, arc strength levels and data sizes. For example, there are 57 trigger structures for 5 observed v ariables, so there are 57 × 2 × 3 × 3 = 1026 simulated datasets. C. Step thr ee: optimize alpha to obtain the shortest edit distance fr om true models FCI and PC both rely on statistical significance tests to decide whether an arc e xists between tw o variables and on its orientation. They ha ve a default alpha lev el (of 0.05), b ut the authors have in the past criticized experimental work using the default and recommended instead optimizing the alpha le vel for the task at hand, so here we do that. The idea is to give the performance of FCI and PC the benefit of any possible doubt. Given the artificial data sets generated, we can use FCI and PC with different values of alpha to learn networks and compare the results to the models used to generate those data sets. W e then used our version of edit distance between the learned and generating models (see Appendix B) to find the optimal alpha lev els for both algorithms. W e first tried simulated annealing to search for an optimal alpha, but in the end simply generated sufficiently many random values from the uniform distribution ov er the range of [0.0, 0.5]. W e ev aluated alpha v alues for the datasets with 2 states and 3 states separately . As shown in the follo wing graphs, the av erage edit distances between the learned and true models approximate a parabola with a minimum around 0.1 to 0.2. The results belo w are specific to the exact datasets and networks we dev eloped for this experimental work. 1) FCI algorithm Results for FCI were broadly similar . In summary , the optimal alphas found for the abov e cases (in the same order) were: 0.12206, 0.19397, 0.20862 and 0.12627. • Number of observed variables: 4 Datasets: 2 state D A G structure simulated dataset Number of datasets: 24*9 = 216 Results: Minimum av erage edit distance: 14.85185 Maximum av erage edit distance: 15.82870 Mean av erage edit distance: 15.37168 Best Alpha: 0.12206 95% confidence lev el: 0.03242 95% confidence interval: (15.37168-0.03242, 15.37168+0.03242) • Number of observed variables: 4 Datasets: 3 state D A G structure simulated dataset Number of datasets: 24*9 = 216 3 Results: Minimum av erage edit distance: 11.42593 Maximum av erage edit distance: 13.43981 Mean av erage edit distance: 12.09355 Best Alpha: 0.19397 95% confidence lev el: 0.07259 95% confidence interval: (12.09355-0.07259, 12.09355+0.07259) • Number of observed variables: 5 Datasets: 2 state D A G structure simulated dataset Number of datasets: 268*9 = 2412 Results: Minimum av erage edit distance: 23.72844 Maximum av erage edit distance: 24.98466 Mean av erage edit distance: 24.08980 Best Alpha: 0.20862 95% confidence lev el: 0.03880 95% confidence interval: (24.08980-0.03880, 24.08980- 0.03880) • Number of observed variables: 5 Datasets: 3 state D A G structure simulated dataset Number of datasets: 268*9 = 2412 Results: Minimum av erage edit distance: 18.66501 Maximum av erage edit distance: 20.89221 Mean av erage edit distance: 19.32648 Best Alpha: 0.12627 95% confidence lev el: 0.08906 95% confidence interval: (19.32648-0.08906, 19.32648- 0.08906) 2) PC algorithm Results for PC were quite similar . In summary , the optimal alphas found for the above cases (in the same order) were: 0.12268, 0.20160, 0.20676 and 0.13636. D. Step four: compare the learned models with true model. Finally , we were ready to test FCI and PC on the artificial datasets of trigger (i.e., latent variable) and D A G structures. Artificial datasets generated by trigger structures were used to determine T rue Positiv e (TP) and False Ne gati ve (FN) results (i.e., finding the real latent and missing the real latent, respec- tiv ely), while the datasets of (fully observed) D AG structures were used for False Positiv e (FP) and True Negati ve (TN) results. Assume the latent variable in ev ery trigger structure is the parent o f node A and B, we used the following definitions: • TP: The learned model has a bi-directional arc between A and B. • FN: The learned model lacks a bi-directional arc between A and B. • TN: The learned model has no bi-directional arcs. • FP: The learned model has one or more bi-directional arcs. W e tested the FCI and PC algorithms on different datasets with their corresponding optimized alphas. W e do not report confidence intervals or significance tests between different algorithms under different conditions, since the cumulativ e results over 6,318 datasets suf fices to tell the comparativ e story . The following tables show the confusion matrix summing ov er all datasets (see Appendix C for more detailed results): 4 FCI PC Latent No Latent Latent No Latent Positiv e 235 981 226 819 Negati ve 827 4275 836 4437 W ith corresponding optimal alpha, the FCI’ s predictiv e accuracy was 0.71 (rounding off), its precision 0.19, its recall 0.22 and its false positiv e rate 0.19. The predictive accuracy for PC was 0.74, the precision was 0.22, its recall 0.21 and the false positi ve rate was 0.16. W e also did the same tests using the default alpha of 0.05. The results are sho wn as follo w (see Appendix C for more detailed results): FCI PC Latent No Latent Latent No Latent Positiv e 211 767 205 615 Negati ve 851 4489 857 4641 W ith alpha of 0.05, the FCI’ s predictiv e accuracy was 0.74, its precision 0.22, its recall 0.19 and its false positive rate 0.15. PC’ s predicti ve accuracy was 0.77, the precision w as 0.25, its recall 0.19 and the false positi ve rate was 0.12. As we can see from the results, the performance of FCI and PC are quite similar . Neither are finding the majority of latent v ariables actually there, but both are at least sho wing moderate false positiv e rates. Ar guably , false positives are a worse offence than false ne gati ves, since f alse negativ es leave the causal discovery process no worse off than an algorithm that ignores latents, whereas a false positive will positively mislead the causal discov ery process. I V . A P P LY I N G T R I G G E R S I N C A U S A L D I S C O V E RY A. An extension of PC algorithm (T rigger -PC) W e implemented triggers as a data filter into PC, yielding T rigger-PC, and see how well it would work. If Trigger - PC finds a trigger pattern in the data, then it returns that trigger structure, otherwise it returns whatev er structure the PC algorithm returns, while replacing any incorrect bi-directed arcs by undirected arcs. So the Trigger -PC algorithm (see Algorithm 1) giv es us a more specific latent model structure and, as we shall see, has fewer false positiv es. W e tested our T rigger-PC algorithm with the alpha opti- mized for the PC algorithm. The resultant confusion matrix was (see Appendix C for more details): trigger-PC Latent No Latent Positiv e 30 3 Negati ve 1032 5253 T rigger-PC’ s predictiv e accuracy was 0.84, its precision 0.91, its recall 0.03 and the false positiv e rate 0.0006. W e can see that Trigger -PC is finding far fewer latents than either PC or FCI, b ut when it asserts their existence we can hav e much greater confidence in the claim. As we indicated Algorithm 1 Trigger -PC Algorithm 1: Let D be the test dataset; 2: Let D l abels be the variable labels in D ; 3: Let T r igg er s be the triggers gi ven the number of v ariables in D ; 4: Perform conditional significant tests to get the dependency pattern P in D ; 5: Let matchT r ig ger = f alse ; 6: Let T be an empty DA G; 7: Let l abel assig nments be all possible label assignments of D l abel ; 8: for each trig g er in T r ig ger s do 9: Let t be the unlabeled D A G represented by trig g er ; 10: for each l abel assig nment in l abel assig nments do 11: Assign label assig nment to t , yield t l abeled ; 12: Generate dependency pattern of t l abeled , yield t patter n ; 13: if P matches t pattern then 14: matchT r igg er = tr ue ; 15: T = t label ed ; 16: break; 17: end if 18: end for 19: if matchT r igg er = tr ue then 20: break; 21: end if 22: end for 23: if matchT r ig ger = tr ue then 24: Output T ; 25: end if 26: if matchT r ig ger = f alse then 27: Run PC Algorithm with input dataset D ; 28: Let P C r esult be the result structure produced by PC Algorithm; 29: if there is any bi-directed arcs in P C r esult then 30: Replace all bi-directed arcs by undirected arcs, yield P C r esult ∗ ; 31: Output P C r esult ∗ ; 32: end if 33: end if abov e, av oiding false positives, while having at least some true positives, appears to be the more important goal in latent variable discovery . As before, we also tried the default 0.05 alpha in T rigger- PC, with the results (see mode details in Appendix C): trigger-PC Latent No Latent Positiv e 35 4 Negati ve 1027 5252 And, again, these results are only slightly dif ferent. With alpha of 0.05, the trigger -PC’ s predictive accuracy was 0.84, 5 its precision 0.90, its recall 0.03 and the false positiv e rate 0.0008. V . C O N C L U S I O N W e hav e presented the first systematic search algorithm to discov er and report latent variable triggers: conditional prob- ability structures that are better explained by latent variable models than by any DA G constructed from the observed vari- ables alone. For simplicity and efficienc y , we have limited this to looking for single latent variables at a time, although that restriction can be remov ed. W e ha ve also applied this latent discov ery algorithm directly in an existing causal discovery algorithm and compared the results to existing algorithms which discover latents using different methods. The results are certainly different and ar guably superior . Our next step will be to implement this approach within a metric-based causal discov ery program. R E F E R E N C E S [1] Friedman, N. (1997). Learning belief networks in the presence of miss- ing values and hidden variables (pp. 125-133). Int. Conf. on Machine Learning. [2] Netica API. https://www.norsys.com/netica_api.html [3] Netica API. https://www.norsys.com/netica-j/docs/ javadocs/norsys/netica/Net.html#FORWARD_SAMPLING [4] Pearl, J. (1988). Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann. [5] Russel, S. & Norvig, P . (2003). Artificial Intelligence: A Modern Ap- proach. EU A: Prentice Hall. [6] Robinson, R. W . (1977). Counting unlabeled acyclic digraphs. Comb . Math. V (pp. 28-43). Springer V erlag. [7] Spearman, C. (1904). General intelligence, objectively determined and measured. The Amer . Jrn. of Psychology , 15(2), 201–292. [8] Spirtes, P ., Glymour, C. N., & Scheines, R. (2000). Causation, Prediction, and Search. MIT press. [9] TETRAD V . http://www.phil.cmu.edu/projects/tetrad/ current.html 6 A P P E N D I X A 5 7 T R I G G E R S F O R L A T E N T V A R I A B L E M O D E L S F O U N D F O R FI V E O B S E RV E D V A R I A B L E S 7 8 A P P E N D I X B E D I T D I S TA N C E U S E D I N C AU S A L M O D E L R E S U LT S Edit distance between different type of arcs (between variable A and B) produced by PC algorithm and true arc type: T rue arc A B Learned arc A B Distance A → B T ail Arrow A—B T ail T ail 2 A → B T ail Arrow 0 A ← B Arrow T ail 4 A ↔ B Arrow Arrow 2 null null null 6 A ↔ B Arrow Arro w A—B T ail T ail 4 A → B T ail Arrow 2 A ← B Arrow T ail 2 A ↔ B Arrow Arrow 0 null null null 6 null null null A—B T ail T ail 6 A → B T ail Arrow 6 A ← B Arrow T ail 6 A ↔ B Arrow Arrow 6 null null null 0 Edit distance between different type of arcs (between variable A and B) produced by FCI algorithm and true arc type: 9 T rue arc A B Learned arc A B Distance A → B T ail Arrow A—B T ail T ail 2 A → B T ail Arrow 0 A ← B Arrow T ail 4 A o—B Circle T ail 3 A —o B T ail Circle 1 A o → B Circle Arrow 1 A ← o B Arrow Circle 3 A ↔ B Arrow Arrow 2 A o-o B Circle Circle 2 null null null 6 A ↔ B Arrow Arro w A—B T ail T ail 4 A → B T ail Arrow 2 A ← B Arrow T ail 2 A o—B Circle T ail 3 A —o B T ail Circle 3 A o → B Circle Arrow 1 A ← o B Arrow Circle 1 A ↔ B Arrow Arrow 0 A o-o B Circle Circle 2 null null null 6 null null null A—B T ail T ail 6 A → B T ail Arrow 6 A ← B Arrow T ail 6 A o—B Circle T ail 6 A —o B T ail Circle 6 A o → B Circle Arrow 6 A ← o B Arrow Circle 6 A ↔ B Arrow Arrow 6 A o-o B Circle Circle 6 null null null 0 A P P E N D I X C C O N F U S I O N M AT R I X 1) Results of FCI algorithm (with optimized alpha) • 4 observed variables with 2 state each simulated data Alpha: 0.12206 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 0 0 Negati ve 2 24 1 24 2 24 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 2 2 1 0 Negati ve 2 24 0 22 1 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 2 Negati ve 2 24 2 24 2 22 • 4 observed variables with 3 state each simulated data Alpha: 0.19397 10 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 2 1 Negati ve 2 24 1 24 0 23 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 4 1 1 2 0 Negati ve 2 20 1 23 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 1 0 2 0 4 Negati ve 2 23 2 22 2 20 • 5 observed variables with 2 state each simulated data Alpha: 0.20862 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 38 3 43 12 30 Negati ve 56 230 54 225 45 238 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 52 16 72 34 57 Negati ve 56 216 41 196 23 211 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 7 0 26 0 41 Negati ve 57 261 57 242 57 227 • 5 observed variables with 3 state each simulated data Alpha: 0.12627 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 6 82 26 59 51 16 Negati ve 51 186 31 209 6 252 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 104 19 98 46 15 Negati ve 56 164 38 170 11 253 11 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 6 1 80 8 138 Negati ve 57 262 56 168 49 130 2) Results of PC algorithm (with optimized alpha) • 4 observed variables with 2 state each simulated data Alpha: 0.12268 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 0 0 Negati ve 2 24 1 24 2 24 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 2 1 1 0 Negati ve 2 24 0 23 1 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 2 Negati ve 2 24 2 24 2 22 • 4 observed variables with 3 state each simulated data Alpha: 0.20160 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 2 1 Negati ve 2 24 1 24 0 23 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 2 1 1 2 0 Negati ve 2 22 1 23 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 2 0 4 Negati ve 2 24 2 22 2 20 • 5 observed variables with 2 state each simulated data 12 Alpha: 0.20676 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 38 4 29 11 16 Negati ve 56 230 53 239 46 252 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 49 15 52 30 40 Negati ve 56 219 42 216 27 228 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 7 0 23 0 41 Negati ve 57 261 57 245 57 227 • 5 observed variables with 3 state each simulated data Alpha: 0.13636 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 6 73 24 43 49 8 Negati ve 51 195 33 225 8 260 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 85 19 74 46 13 Negati ve 56 183 38 194 11 255 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 7 1 83 8 125 Negati ve 57 261 56 185 49 143 3) Results of trigger-PC algorithm (with optimized alpha) • 4 observed variables with 2 state each simulated data Alpha: 0.12268 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 Medium arc strength simulated data: 13 Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 1 0 Negati ve 2 24 1 24 1 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 • 4 observed variables with 3 state each simulated data Alpha: 0.20160 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 2 0 Negati ve 2 24 2 24 0 24 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 1 0 Negati ve 2 24 1 24 1 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 • 5 observed variables with 2 state each simulated data Alpha: 0.20676 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 57 268 57 268 57 268 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 2 0 0 Negati ve 57 268 57 266 57 268 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 57 268 57 268 57 268 14 • 5 observed variables with 3 state each simulated data Alpha: 0.13636 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 1 13 0 Negati ve 57 268 56 267 44 268 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 9 0 Negati ve 57 268 57 268 48 268 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 1 0 Negati ve 57 268 57 268 56 268 4) Results of FCI algorithm (with alpha of 0.05) • 4 observed variables with 2 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 0 0 Negati ve 2 24 1 24 2 24 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 1 2 1 2 0 Negati ve 2 23 0 23 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 • 4 observed variables with 3 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 1 0 Negati ve 2 24 1 24 1 24 Medium arc strength simulated data: 15 Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 1 2 0 Negati ve 2 24 1 23 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 6 Negati ve 2 24 2 24 2 18 • 5 observed variables with 2 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 2 32 3 47 10 24 Negati ve 55 236 54 221 47 244 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 29 8 63 33 49 Negati ve 56 239 49 205 24 219 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 2 0 7 Negati ve 57 268 57 266 57 261 • 5 observed variables with 3 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 2 64 25 63 48 13 Negati ve 55 204 32 205 9 255 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 65 17 116 48 15 Negati ve 56 203 40 152 9 253 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 2 0 29 3 138 Negati ve 57 266 57 239 54 130 5) Results of PC algorithm (with alpha of 0.05) • 4 observed variables with 2 state each simulated data 16 Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 0 0 Negati ve 2 24 1 24 2 24 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 1 2 1 2 0 Negati ve 2 23 0 23 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 • 4 observed variables with 3 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 1 0 Negati ve 2 24 1 24 1 24 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 1 2 0 Negati ve 2 24 1 23 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 6 Negati ve 2 24 2 24 2 18 • 5 observed variables with 2 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 25 4 35 10 12 Negati ve 56 243 53 233 47 256 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 1 18 7 47 32 33 Negati ve 56 250 50 221 25 235 Minimum arc strength simulated data: 17 Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 2 0 6 Negati ve 57 268 57 266 57 262 • 5 observed variables with 3 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 2 56 24 48 47 7 Negati ve 55 212 33 220 10 261 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 56 16 95 48 9 Negati ve 57 212 41 173 9 259 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 2 0 28 3 127 Negati ve 57 266 57 240 54 141 6) Results of trigger-PC algorithm (with alpha of 0.05) • 4 observed variables with 2 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 1 0 2 0 Negati ve 2 24 1 24 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 • 4 observed variables with 3 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 Medium arc strength simulated data: 18 Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 2 0 Negati ve 2 24 2 24 0 24 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 2 24 2 24 2 24 • 5 observed variables with 2 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 1 Negati ve 57 268 57 268 57 267 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 1 3 0 Negati ve 57 268 57 267 54 268 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 0 0 Negati ve 57 268 57 268 57 268 • 5 observed variables with 3 state each simulated data Maximum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 1 14 0 Negati ve 57 268 57 267 43 268 Medium arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 1 12 0 Negati ve 57 268 57 267 45 268 Minimum arc strength simulated data: Data case number 100 1000 10000 Latent No latent Latent No latent Latent No latent Positiv e 0 0 0 0 1 0 Negati ve 57 268 57 268 56 268 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment