Multiresolution Recurrent Neural Networks: An Application to Dialogue Response Generation
We introduce the multiresolution recurrent neural network, which extends the sequence-to-sequence framework to model natural language generation as two parallel discrete stochastic processes: a sequence of high-level coarse tokens, and a sequence of …
Authors: Iulian Vlad Serban, Tim Klinger, Gerald Tesauro
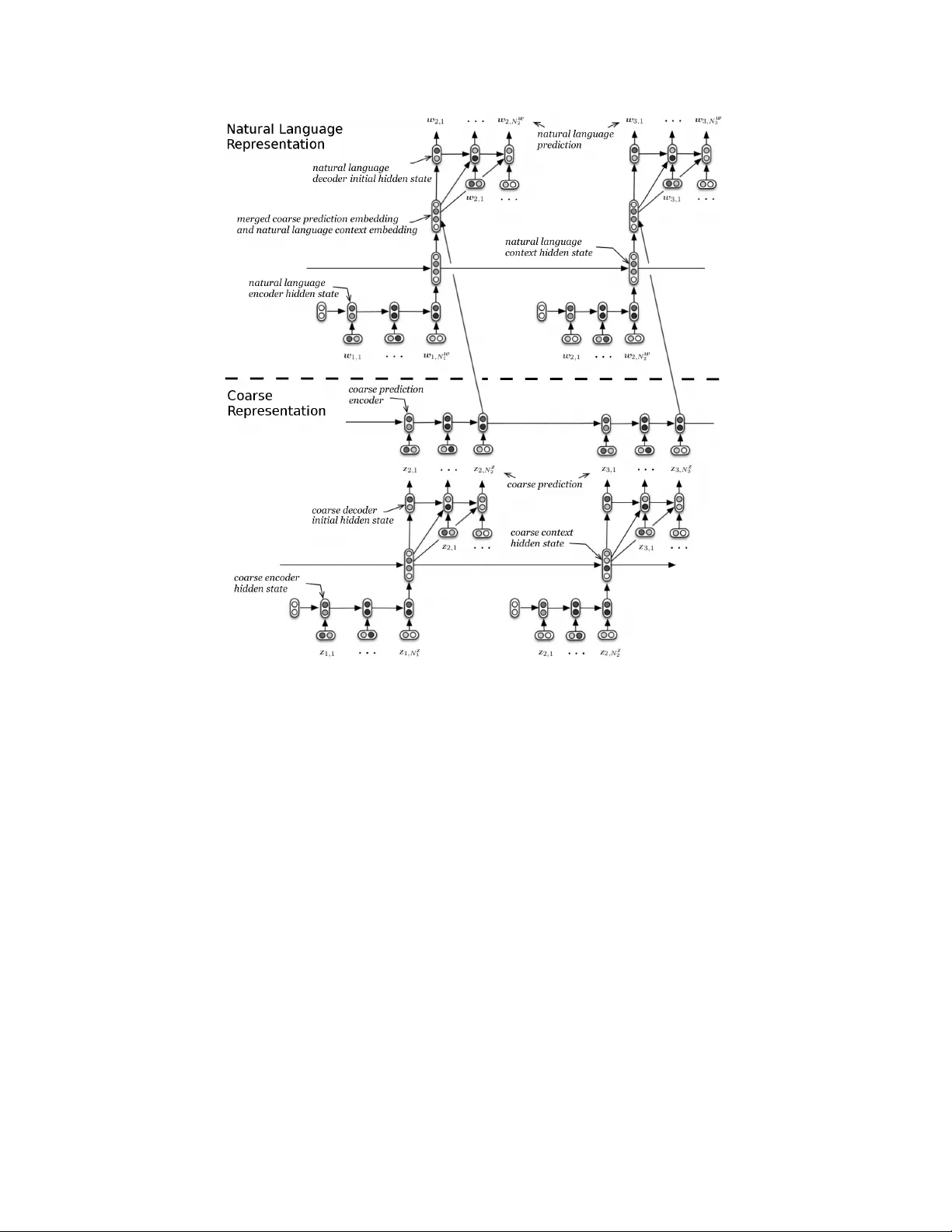
Multir esolution Recurr ent Neural Networks: An A pplication to Dialogue Response Generation Iulian Vlad Serban ∗ ◦ Univ ersity of Montreal 2920 chemin de la T our , Montréal, QC, Canada Tim Klinger IBM Research T . J. W atson Research Center , Y orktown Heights, NY , USA Gerald T esauro IBM Research T . J. W atson Research Center , Y orktown Heights, NY , USA Kartik T alamadupula IBM Research T . J. W atson Research Center , Y orktown Heights, NY , USA Bowen Zhou IBM Research T . J. W atson Research Center , Y orktown Heights, NY , USA Y oshua Bengio † ◦ Univ ersity of Montreal 2920 chemin de la T our , Montréal, QC, Canada Aaron Cour ville ◦ Univ ersity of Montreal 2920 chemin de la T our , Montréal, QC, Canada Abstract W e introduce the multiresolution recurrent neural network, which extends the sequence-to-sequence framew ork to model natural language generation as two parallel discrete stochastic processes: a sequence of high-le v el coarse tokens, and a sequence of natural language tok ens. There are man y ways to estimate or learn the high-lev el coarse tokens, but we argue that a simple extraction procedure is sufficient to capture a wealth of high-lev el discourse semantics. Such procedure allows training the multiresolution recurrent neural network by maximizing the exact joint log-likelihood ov er both sequences. In contrast to the standard log- likelihood objecti ve w .r .t. natural language tokens (w ord perplexity), optimizing the joint log-likelihood biases the model towards modeling high-le vel abstractions. W e apply the proposed model to the task of dialogue response generation in two challenging domains: the Ubuntu technical support domain, and T witter con versations. On Ub untu, the model outperforms competing approaches by a substantial margin, achie ving state-of-the-art results according to both automatic ev aluation metrics and a human ev aluation study . On T witter , the model appears to generate more rele vant and on-topic responses according to automatic e v aluation metrics. Finally , our experiments demonstrate that the proposed model is more adept at ov ercoming the sparsity of natural language and is better able to capture long-term structure. * This work was carried out while the first author w as at IBM Research. ◦ Email: {iulian.vlad.serban,yoshua.bengio,aaron.courville}@umontreal.ca Email: {tklinger ,gtesauro,krtalamad,zhou}@us.ibm.com † CIF AR Senior Fellow 1 Introduction Recurrent neural networks (RNNs) hav e been gaining popularity in the machine learning community due to their impressiv e performance on tasks such as machine translation [ 32 , 5 ] and speech recogni- tion [ 10 ]. These results ha ve spurred a cascade of nov el neural network architectures [ 15 ], including attention [1, 6], memory [35, 9, 15] and pointer-based mechanisms [19]. The majority of the pre vious work has focused on de v eloping ne w neural netw ork architectures within the deterministic sequence-to-sequence frame work. In other words, it has focused on changing the parametrization of the deterministic function mapping input sequences to output sequences, trained by maximizing the log-likelihood of the observed output sequence. Instead, we pursue a complimentary research direction aimed at generalizing the sequence-to-sequence framew ork to multiple input and output sequences, where each sequence exhibits its o wn stochastic process. W e propose a ne w class of RNN models, called multiresolution recurrent neural networks (MrRNNs), which model multiple parallel sequences by factorizing the joint probability over the sequences. In particular, we impose a hierarchical structure on the sequences, such that information from high-le v el (abstract) sequences flows to low-le vel sequences (e.g. natural language sequences). This architecture exhibits a new objectiv e function for training: the joint log-likelihood over all observed parallel sequences (as opposed to the log-likelihood over a single sequence), which biases the model tow ards modeling high-lev el abstractions. At test time, the model generates first the high-level sequence and afterwards the natural language sequence. This hierarchical generation process enables it to model complex output sequences with long-term dependencies. Researchers hav e recently observ ed critical problems applying end-to-end neural netw ork architec- tures for dialogue response generation [ 28 , 16 ]. The neural networks hav e been unable to generate meaningful responses taking dialogue context into account, which indicates that the models have failed to learn useful high-le vel abstractions of the dialogue. Moti v ated by these shortcomings, we apply the proposed model to the task of dialogue response generation in tw o challenging domains: the goal-oriented Ubuntu technical support domain and non-goal-oriented T witter con versations. In both domains, the model outperforms competing approaches. In particular , for Ub untu, the model outperforms competing approaches by a substantial margin according to both a human evaluation study and automatic ev aluation metrics achie ving a ne w state-of-the-art result. 2 Model Architecture 2.1 Recurrent Neural Network Language Model W e start by introducing the well-established recurrent neural network language model (RNNLM) [ 20 , 3 ]. RNNLM v ariants ha ve been applied to di v erse sequential tasks, including dialogue modeling [ 28 ], speech synthesis [ 7 ], handwriting generation [ 8 ] and music composition [ 4 ]. Let w 1 , . . . , w N be a sequence of discrete v ariables, called tokens (e.g. words), such that w n ∈ V for vocab ulary V . The RNNLM is a probabilistic generati ve model, with parameters θ , which decomposes the probability ov er tokens: P θ ( w 1 , . . . , w N ) = N Y n =1 P θ ( w n | w 1 , . . . , w n − 1 ) . (1) where the parametrized approximation of the output distribution uses a softmax RNN: P θ ( w n +1 = v | w 1 , . . . , w n ) = exp( g ( h n , v )) P v 0 ∈ V exp( g ( h n , v 0 )) , (2) h n = f ( h n − 1 , w n ) , g ( h n , v ) = O T v h n , (3) where f is the hidden state update function, which we will assume is either the LSTM gating unit [ 11 ] or GR U gating unit [ 5 ] throughout the rest of the paper . For the LSTM gating unit, we consider the hidden state h m to be the LSTM cell and cell input hidden states concatenated. The matrix I ∈ R d h ×| V | is the input word embedding matrix, where column j contains the embedding for word index j and d h ∈ N is the word embedding dimensionality . Similarly , the matrix O ∈ R d h ×| V | is the output word embedding matrix. According to the model, the probability of observing a token w at position n + 1 increases if the context v ector h n has a high dot-product with the word embedding 2 corresponding to token w . Most commonly the model parameters are learned by maximizing the log-likelihood (equi valent to minimizing the cross-entropy) on the training set using gradient descent. 2.2 Hierarchical Recurrent Encoder-Decoder Our work here builds upon that of Sordoni et al. [ 31 ], who proposed the hierarchical recurrent encoder-decoder model (HRED). Their model e xploits the hierarchical structure in web queries in order to model a user search session as two hierarchical sequences: a sequence of queries and a sequence of words in each query . Serban et al. [ 28 ] continue in the same direction by proposing to exploit the temporal structure inherent in natural language dialogue. Their model decomposes a dialogue into a hierarchical sequence: a sequence of utterances, each of which is a sequence of words. More specifically , the model consists of three RNN modules: an encoder RNN, a context RNN and a decoder RNN. A sequence of tokens (e.g. words in an utterance) are encoded into a real-valued vector by the encoder RNN. This in turn is gi ven as input to the conte xt RNN, which updates its internal hidden state to reflect all the information up to that point in time. It then produces a real-valued output vector , which the decoder RNN conditions on to generate the next sequence of tokens (next utterance). Due to space limitations, we refer the reader to [ 31 , 28 ] for additional information on the model architecture. The HRED model for modeling structured discrete sequences is appealing for three reasons. First, it naturally captures the hierarchical structure we want to model in the data. Second, the context RNN acts like a memory module which can remember things at longer time scales. Third, the structure makes the objecti ve function more stable w .r .t. the model parameters, and helps propagate the training signal for first-order optimization methods [31]. 2.3 Multiresolution RNN (MrRNN) W e consider the problem of generatively modeling multiple parallel sequences. Each sequence is hierarchical with the top le v el corresponding to utterances and the bottom level to tok ens. Formally , let w 1 , . . . , w N be the first sequence of length N where w n = ( w n, 1 , . . . , w n,K n ) is the n ’th constituent sequence consisting of K n discrete tokens from vocab ulary V w . Similarly , let z 1 , . . . , z N be the second sequence, also of length N , where z n = ( z n, 1 , . . . , z n,L n ) is the n ’th constituent sequence consisting of L n discrete tokens from vocab ulary V z . In our experiments, each sequence w n will consist of the words in a dialogue utterance, and each sequence z n will contain the coarse tokens w .r .t. the same utterance (e.g. the nouns in the utterance). Our aim is to build a probabilistic generative model ov er all tokens in the constituent sequences w 1 , . . . , w N and z 1 , . . . , z N . Let θ be the parameters of the generati ve model. W e assume that w n is independent of z n 0 conditioned on z 1 , . . . , z n for n 0 > n , and factor the probability ov er sequences: P θ ( w 1 , . . . , w N , z 1 , . . . , z N ) = N Y n =1 P θ ( z n | z 1 , . . . , z n − 1 ) N Y n =1 P θ ( w n | w 1 , . . . , w n − 1 , z 1 , . . . , z n ) = N Y n =1 P θ ( z n | z 1 , . . . , z n − 1 ) P θ ( w n | w 1 , . . . , w n − 1 , z 1 , . . . , z n ) , (4) where we define the conditional probabilities ov er the tokens in each constituent sequence: P θ ( z n | z 1 , . . . , z n − 1 ) = L n Y m =1 P θ ( z n,m | z n, 1 , . . . , z n,m − 1 , z 1 , . . . , z n − 1 ) P θ ( w n | w 1 , . . . , w n − 1 , z 1 , . . . , z n ) = K n Y m =1 P θ ( w n,m | w n, 1 , . . . , w n,m − 1 , w 1 , . . . , w n − 1 , z 1 , . . . , z n ) W e refer to the distribution ov er z 1 , . . . , z N as the coarse sub-model, and to the distribution ov er w 1 , . . . , w N as the natural language sub-model. For the coarse sub-model, we parametrize the conditional distrib ution P θ ( z n | z 1 , . . . , z n − 1 ) as the HRED model described in subsection 2.2, applied to the sequences z 1 , . . . , z N . For the natural language sub-model, we parametrize P θ ( w n | w 1 , . . . , w n − 1 , z 1 , . . . , z n ) as the HRED model applied to the sequences w 1 , . . . , w N , but with one dif ference. The coarse prediction encoder GR U-gated RNN encodes all the pre viously generated tokens z 1 , . . . , z n into a real-v alued vector , which is concatenated with the context RNN 3 Figure 1: Computational graph for the multiresolution recurrent neural network (MrRNN). The lo wer part models the stochastic process over coarse tok ens, and the upper part models the stochastic process ov er natural language tokens. The rounded boxes represent (deterministic) real-v alued v ectors, and the variables z and w represent the coarse tokens and natural language tokens respecti vely . and gi ven as input to the natural language decoder RNN. The coarse pr ediction encoder RNN is important because it encodes the high-level information, which is transmitted to the natural language sub-model. Unlike the encoder for the coarse-lev el sub-model, this encoding will be used to generate natural language and therefore the RNN uses dif ferent w ord embedding parameters. At generation time, the coarse sub-model generates a coarse sequence (e.g. a sequence of nouns), which corresponds to a high-le vel decision about what the natural language sequence should contain (e.g. nouns to include in the natural language sequence). Conditioned on the coarse sequence, through the coarse pr ediction encoder RNN, the natural language sub-model then generates a natural language sequence (e.g. dialogue utterance). The model is illustrated in Figure 1. W e will assume that both z 1 , . . . , z N and w 1 , . . . , w N are observed and optimize the parameters w .r .t. the joint log-likelihood ov er both sequences. At test time, to generate a response for sequence n we exploit the probabilistic f actorization to approximate the maximum a posteriori (MAP) estimate: arg max w n , z n P θ ( w n , z n | w 1 , . . . , w n − 1 , z 1 , . . . , z n − 1 ) ≈ arg max w n P θ ( w n | w 1 , . . . , w n − 1 , z 1 , . . . , z n − 1 , z n ) arg max z n P θ ( z n | z 1 , . . . , z n − 1 ) , (5) where we further approximate the MAP for each constituent sequence using beam search. 4 3 T asks W e consider the task of natural language response generation for dialogue. Dialogue systems have been dev eloped for applications ranging from technical support to language learning and entertainment [ 36 , 30 ]. Dialogue systems can be categorized into two different types: goal-driven dialogue systems and non-goal-dri ven dialogue systems [ 27 ]. T o demonstrate the versatility of the MrRNN, we apply it to both goal-driv en and non-goal-driv en dialogue tasks. W e focus on the task of conditional response generation. Gi ven a dialogue conte xt consisting of one or more utterances, the model must generate the next response in the dialogue. Ubuntu Dialogue Corpus The goal-dri ven dialogue task we consider is technical support for the Ubuntu operating system, where we use the Ubuntu Dialogue Corpus [ 18 ]. The corpus consists of about 0 . 5 million natural language dialogues e xtracted from the #Ub untu Internet Relayed Chat (IRC) channel. Users entering the chat channel usually hav e a specific technical problem. The users first describe their problem and afterwards other users try to help them resolve it. The technical problems range from software-related issues (e.g. installing or upgrading existing software) and hardware-related issues (e.g. fixing broken dri vers or partitioning hard dri ves) to informational needs (e.g. finding software with specific functionality). Additional details are given in appendix 8. T witter Dialogue Corpus The ne xt task we consider is the non-goal-driven task of generating responses to T witter conv ersations. W e use a T witter dialogue corpus extracted in the first half of 2011 using a procedure similar to Ritter et al. [ 24 ]. Unlike the Ubuntu domain, T witter conv ersations are often more noisy and do not necessarily center around a single topic. W e perform a minimal preprocessing on the dataset to remov e irregular punctuation marks and afterw ards tokenize it. The dataset is split into training, validation and test sets containing respecti vely 749 , 060 , 93 , 633 and 10 , 000 dialogues. 1 4 Coarse Sequence Representations W e experiment with two procedures for e xtracting the coarse sequence representations: Noun Representation This procedure aims to e xploit the basic high-le vel structure of natural lan- guage discourse.It is based on the hypothesis that dialogues are topic-dri ven and that these topics may be characterized by nouns. In addition to a tokenizer , used by both the HRED and RNNLM model, it requires a part-of-speech (POS) tagger to identify the nouns in the dialogue. The procedure uses a set of 84 and 795 predefined stop words for Ubuntu and T witter respectiv ely . It maps a natural language utterance to its coarse representation by extracting all the nouns using the POS tagger and then remo ving all stop words and repeated words (keeping only the first occurrence of a word). Dialogue utterances without nouns are assigned the "no_nouns" token. The procedure also extracts the tense of each utterance and adds it to the beginning of the coarse representation. Activity-Entity Representation This procedure is specific to the Ubuntu technical support task, for which it aims to exploit domain kno wledge related to technical problem solving. It is motiv ated by the observ ation that most dialogues are centered around activities and entities . For e xample, it is v ery common for users to state a specific problem they w ant to resolve, e.g. how do I install pr o gram X? or My driver X doesn’ t work, how do I fix it? In response to such questions, other users often respond with specific instructions, e.g. Go to website X to download software Y or T ry to execute command X . In such cases, it is clear that the principal information resides in the technical entities and in the v erbs (e.g. install , fix , download ), and therefore that it will be advantageous to e xplicitly model this structure. Motiv ated by this observ ation, the procedure uses a set of 192 activities (v erbs), created by manual inspection, and a set of 3115 technical entities and 230 frequent terminal commands, extracted automatically from a vailable package managers and from the web . The procedure uses the POS tagger to e xtract the verbs from the each natural language utterance. It maps 1 Due to T witter’ s terms of service we are not allo wed to redistribute T witter content. Therefore, only the tweet IDs can be made public. These are av ailable at: www.iulianserban.com/Files/TwitterDialogueCorpus. zip . 5 the natural language to its coarse representation by keeping only verbs from the activity set, as well as entities from the technical entity set (irrespective of their POS tags). If no activity is found in an utterance, the representation is assigned the "none_activity" token. The procedure also appends a binary v ariable to the end of the coarse representation indicating if a terminal command was detected in the utterance. Finally , the procedure extracts the tense of each utterance and adds it to the beginning of the coarse representation. Both extraction procedures are applied at the utterance le vel, therefore there exists a one-to-one alignment between coarse sequences and natural language sequences (utterances). There also exists a one-to-many alignment between the coarse sequence tokens and the corresponding natural language tokens, with the exception of a fe w special tok ens. Further details are gi ven in appendix 9. 2 5 Experiments The models are implemented in Theano [ 33 ]. W e optimize all models based on the training set joint log-likelihood ov er coarse sequences and natural language sequences using the first-order stochastic gradient optimization method Adam [ 13 ]. W e train all models using early stopping with patience on the joint-log-likelihood [ 2 ]. W e choose our hyperparameters based on the joint log-likelihood of the validation set. W e define the 20 K most frequent words as the vocab ulary and the word embedding dimensionality to size 300 for all models, with the exception of the RNNLM and HRED on T witter , where we use embedding dimensionality of size 400 . W e apply gradient clipping to stop the parameters from exploding [ 23 ]. At test time, we use a beam search of size 5 for generating the model responses. Further details are gi ven in appendix 10 5.1 Baseline Models W e compare our models to several baselines used pre viously in the literature. The first is the standard RNNLM with LSTM gating function [ 20 ] (LSTM), which at test time is similar to the Seq2Seq LSTM model [ 32 ]. The second baseline is the HRED model with LSTM gating function for the decoder RNN and GRU gating function for the encoder RNN and context RNN, proposed for dialogue response generation by Serban et al.[ 28 ] [ 31 ]. Source code for both baseline models will be made publicly av ailable upon acceptance for publication. For both Ubuntu and T witter, we specify the RNNLM model to hav e 2000 hidden units with the LSTM gating function. For Ubuntu, we specify the HRED model to have 500 , 1000 and 500 hidden units respectiv ely for the encoder RNN, context RNN and decoder RNN. For T witter, we specify the HRED model to have 2000 , 1000 and 1000 hidden units respecti vely for the encoder RNN, context RNN and decoder RNN. The third baseline is the latent v ariable latent v ariable hierarchical recurrent encoder -decoder (VHRED) proposed by Serban et al. [29]. W e use the exact same VHRED models as Serban et al. [29]. For Ubuntu, we introduce a fourth baseline, called HRED + Activity-Entity F eatures , which has access to the past activity-entity pairs. This model is similar to to the natural language sub-model of the MrRNN model, with the difference that the natural language decoder RNN is conditioned on a real-valued vector , produced by a GRU RNN encoding only the past coarse-lev el activity-entity sub-sequences. This baseline helps dif ferentiate between a model which observes t he coarse-lev el sequences only as as additional features and a model which explicitly models the stochastic process of the coarse-lev el sequences. W e specify the model to have 500 , 1000 , 2000 hidden units respectiv ely for the encoder RNN, context RNN and decoder RNN. W e specify the GRU RNN encoding the past coarse-lev el acti vity-entity sub-sequences to hav e 500 hidden units. 5.2 Multiresolution RNN The coarse sub-model is parametrized as the Bidirectional-HRED model [ 28 ] with 1000 , 1000 and 2000 hidden units respectiv ely for the coarse-lev el encoder , context and decoder RNNs. The natural language sub-model is parametrized as a conditional HRED model with 500 , 1000 and 2000 hidden units respecti vely for the natural language encoder , conte xt and decoder RNNs. The coarse pr ediction encoder RNN GRU RNN is parametrized with 500 hidden units. 2 The pre-processed Ub untu Dialogue Corpus used, as well as the noun representations and acti vity-entity representations, are av ailable at www.iulianserban.com/Files/UbuntuDialogueCorpus.zip . 6 T able 1: Ubuntu ev aluation using precision (P), recall (R), F1 and accuracy metrics w .r .t. activity , entity , tense and command (Cmd) on ground truth utterances, and human fluency and rele v ancy scores giv en on a scale 0-4 ( ∗ indicates scores significantly different from baseline models at 90% confidence) Activity Entity T ense Cmd Human Eval. Model P R F1 P R F1 Acc. Acc. Fluency Relevancy LSTM 1 . 7 1 . 03 1 . 18 1 . 18 0 . 81 0 . 87 14 . 57 94 . 79 - - HRED 5 . 93 4 . 05 4 . 34 2 . 81 2 . 16 2 . 22 22 . 2 92 . 58 2.98 1.01 VHRED 6 . 43 4 . 31 4 . 63 3 . 28 2 . 41 2 . 53 20 . 2 92 . 02 - - HRED + Act.-Ent. 7 . 15 5 . 5 5 . 46 3 . 03 2 . 43 2 . 44 28 . 02 86 . 69 2.96 0.75 MrRNN Noun 5 . 81 3 . 56 4 . 04 8 . 68 5 . 55 6 . 31 24 . 03 90 . 66 3 . 48 ∗ 1 . 32 ∗ MrRNN Act.-Ent. 16 . 84 9 . 72 11 . 43 4 . 91 3 . 36 3 . 72 29 . 01 95 . 04 3 . 42 ∗ 1 . 04 5.3 Ubuntu Evaluation Methods It has long been kno wn that accurate ev aluation of dialogue system responses is difficult [ 26 ]. Liu et al. [ 17 ] hav e recently sho wn that all automatic ev aluation metrics adapted for such ev aluation, including word overlap-based metrics such as BLEU and METEOR, hav e either very lo w or no correlation with human judgment of the system performance. W e therefore carry out an in-lab human study to e v aluate the Ub untu models. W e recruit 5 human e valuators, and sho w them each 30 − 40 dialogue contexts with the ground truth response and 4 candidate responses (HRED, HRED + Activity-Entity Features and MrRNNs). For each conte xt example, we ask them to compare the candidate responses to the ground truth response and dialogue context, and rate them for fluency and relev anc y on a scale 0 − 4 . Our setup is very similar to the e valuation setup used by K oehn and Monz [14], and comparable to Liu et al [17]. Further details are gi ven in appendix 11. W e further propose a new set of metrics for ev aluating model responses on Ubuntu, which compare the activities and entities in the model generated response with those of the ground truth response. That is, the ground truth and model responses are mapped to their respectiv e acti vity-entity representations, using the automatic procedure discussed in section 4, and then the o verlap between their acti vities and entities are measured according to precision, recall and F1-score. Based on a careful manual inspection of the extracted activities and entities, we believe that these metrics are particularly suited for the goal-oriented Ubuntu Dialogue Corpus. The acti vities and entities reflect the principal instructions giv en in the responses, which are ke y to resolving the technical problems. Therefore, a model able to generate responses with actions and entities similar to the ground truth human responses – which often do lead to solving the users problem – is more likely to yield a successful dialogue system. The reader is encouraged to v erify the details and completeness of the acti vity-entity representations in appendix 9. Scripts to generate the noun and activity-entity representations, and to ev aluate the dialogue responses w .r .t. activity-entity pairs are av ailable online. 3 Results The results on Ubuntu are giv en in table 1. The MrRNNs clearly perform substantially better than the baseline models both w .r .t. human e v aluation and automatic e v aluation metrics. The MrRNN with noun representations achie ves 2 x − 3 x higher scores w .r .t. entities compared to other models, and the human ev aluators also rate its fluenc y and rele vanc y substantially higher than other models. The MrRNN with acti vity representations achiev es 2 x − 3 x higher scores w .r .t. acti vities compared to other models and nearly 2 x higher scores w .r .t. entities compared to all baselines. Human ev aluators also rate its fluency substantially higher than the baseline models. Ho we ver ,its relev ancy is rated only slightly higher compared to the HRED model, which we belie ve is caused by human 3 https://github.com/julianser/Ubuntu- Multiresolution- Tools/tree/master/ ActEntRepresentation . 7 e valuators being more lik ely to noticing software entities than actions in the dialogue responses (ev en though actions are critical to solving the actual technical problem). Overall, the results demonstrate that the MrRNNs hav e learned to model high-le vel goal-oriented sequential structure on Ub untu. T able 2: Ub untu model examples. The arrows indicate change of turn. Context Response Hey guys what do you in general use for irc something ubuntu xchat or xchat- gnome ? → without -gnome. that is just cut down → you mean drop xchat- gnome and go with xchat ? MrRNN Act. -Ent.: im using xchat right now MrRNN Noun: what is xchat-gnome ? VHRED: correct HRED: yes when setting up rules with iptables command only writes changes this file " etciptables. rules "? i ask this so i can backup before messing anything → sudo iptables-save something . dat to backup your rules restore with sudo iptables-restore < something . dat MrRNN Act. -Ent.: I don’t see any reason why you need iptables to do that MrRNN Noun: are you using ubuntu ? VHRED: thx HRED: thanks Hello I tried to install ubuntu studio but I get W : Failed to fetch 404 Not Found when apt-get update → the ppa you added is not online MrRNN Act. -Ent.: try a different mirror MrRNN Noun: something VHRED: but I dont know ho w to add it HRED: how do I do that ? hi community .. is there any difference between " /.bashrc " " /.bashrc. local " → yes, they’ re different files :-) the default /.bashrc sources /.bashrc. local → sorry I could undersatnd... If I write on terminal " gedit /.bashrc " it opens a file but ho w I open " /.bashrc. local " → " gedit /.bashrc. local "... → but it just open blank file nothing inside it MrRNN Act. -Ent.: open up gedit /.bashrc, there is a file called " something " MrRNN Noun: the file is empty .. VHRED: it’ s in /.bashrc or /.bashrc HRED: what are you trying to do ? Model responses are shown in T able 2. In general, the MrRNN responses are more coherent and topic-oriented compared to the other model responses, which usually produce very generic responses [ 28 ]. In particular, the MrRNN with activity-entity representation appears to giv e more goal-oriented instructions compared to the MrRNN with noun representation (see examples 2-4 in T able 2). Additional e xamples are shown in appendix 12. 5.4 T witter Evaluation Methods For T witter , similar to the Ub untu metrics, we use the precision, recall and F1 metrics between the model responses and ground truth responses w .r .t. the noun representation. The reason we propose to use these metrics is similar to the reason given for the Ubuntu metrics related to entities: a good model response is one which includes the same nouns as the ground truth response. W e also compute the tense accuracy , as we did for Ubuntu. Furthermore, we use the three embedding-based textual similarity metrics proposed by Liu et al. [ 17 ]: Embedding A vera ge (A verage), Embedding Extr ema (Extrema) and Embedding Gr eedy (Greedy). All three metrics are based on computing the textual similarity between the ground truth response and the model response using word embeddings. All three metrics measure topic similarity: if a model-generated response is on the same topic as the ground truth response (e.g. contain paraphrases of the same words), the metrics will yield a high score. This is a highly desirable property for dialogue systems on an open platform such as T witter, ho we ver it is also substantially dif ferent from measuring the o verall dialogue system performance, or the appropriateness of a single response, which would require human ev aluation. Results The results on T witter are giv en in T able 3. The responses of the MrRNN with noun representation are better than all other models on precision, recall and F1 w .r .t nouns. MrRNN is also better than all other models w .r .t. tense accuracy , and it is on par with VHRED on the embedding- based metrics. In accordance with our pre vious results, this indicates that the model has learned to generate more on-topic responses and, thus, that e xplicitly modeling the stochastic process o ver nouns helps learn the high-le vel structure. This is confirmed by qualitati ve inspection of the generated responses, which are clearly more topic-oriented. See T able 10 in appendix. 6 Related W ork Closely related to our work is the model proposed by Ji et al.[ 12 ], which jointly models natural language text and high-level discourse phenomena. Ho we ver , it only models a discrete class per sentence at the high lev el, which must be manually annotated by humans. On the other hand, MrRNN models a sequence of automatically e xtracted high-le vel tok ens. Recurrent neural netw ork models 8 T able 3: T witter ev aluation using precision (P), recall (R), F1 and accuracy metrics w .r .t. noun representation, tense accuracy and embedding-based e v aluation metrics on ground truth utterances. Noun T ense Embedding Metrics Model P R F1 Acc. A verage Gr eedy Extrema LSTM 0 . 71 0 . 71 0 . 65 27 . 06 51 . 24 38 . 9 36 . 58 HRED 0 . 31 0 . 31 0 . 29 26 . 47 50 . 1 37 . 83 35 . 55 VHRED 0 . 5 0 . 51 0 . 46 26 . 66 53 . 26 39 . 64 37 . 98 MrRNN Noun 4 . 82 5 . 22 4 . 63 34 . 48 49 . 77 40 . 44 37 . 45 with stochastic latent v ariables, such as the V ariational Recurrent Neural Networks by Chung et al. [ 7 ], are also closely related to our work. These models face the more difficult task of learning the high-le vel representations, while simultaneously learning to model the generati ve process ov er high-lev el sequences and low-le vel sequences, which is a more difficult optimization problem. In addition to this, such models assume the high-le vel latent v ariables to be continuous, usually Gaussian, distributions. Recent dialogue-specific neural network architectures, such as the model proposed by W en et al. [ 34 ], are also relev ant to our work. Different from the MrRNN, they require domain-specific hand-crafted high-lev el (dialogue state) representations with human-labelled examples, and they usually consist of sev eral sub-components each trained with a dif ferent objecti ve function. 7 Discussion W e hav e proposed the multiresolution recurrent neural network (MrRNN) for generativ ely modeling sequential data at multiple le vels of abstraction. It is trained by optimizing the joint log-likelihood ov er the sequences at each le vel. W e apply MrRNN to dialog response generation on two dif ferent tasks, Ub untu technical support and T witter con v ersations, and ev aluate it in a human ev aluation study and via automatic evaluation metrics. On Ubuntu, MrRNN demonstrates dramatic improv ements compared to competing models. On T witter , MrRNN appears to generate more relev ant and on-topic responses. Even though abstract information is implicitly present in natural language dialogues, by explicitly representing information at different lev els of abstraction and jointly optimizing the generation process across abstraction lev els, MrRNN is able to generate more fluent, rele vant and goal-oriented responses. The results suggest that the fine-grained abstraction (low-le vel) pro vides the architecture with increased fluency for predicting natural utterances, while the coarse-grained (high-lev el) abstraction gives it the semantic structure necessary to generate more coherent and relev ant utterances. The results also imply that it is not simply a matter of adding additional features for prediction – MrRNN outperforms a competitive baseline augmented with the coarse-grained abstraction sequences as features – rather , it is the combination of representation and generation at multiple levels that yields the improvements. Finally , we observe that the architecture provides a general framew ork for modeling discrete sequences, as long as a coarse abstraction is a vailable. W e therefore conjecture that the architecture may successfully be applied to broader natural language generation tasks, such as generating prose and persuasi v e argumentation, and other tasks in v olving discrete sequences, such as music composition. W e leave this to future w ork. Acknowledgments The authors thank Ryan Lowe, Michael Nose worthy , Caglar Gulcehre, Sungjin Ahn, Harm de Vries, Song Feng and On Y i Ching for participating and helping with the human study . The authors thank Orhan Firat and Caglar Gulcehre for constructiv e feedback, and thank Ryan Lowe, Nissan Po w and Joelle Pineau for making the Ubuntu Dialogue Corpus a v ailable to the public. 9 References [1] Bahdanau, D., Cho, K., and Bengio, Y . (2015). Neural machine translation by jointly learning to align and translate. In ICLR . [2] Bengio, Y . (2012). Practical recommendations for gradient-based training of deep architectures. In Neural Networks: T ric ks of the T rade , pages 437–478. Springer . [3] Bengio, Y ., Ducharme, R., V incent, P ., and Janvin, C. (2003). A neural probabilistic language model. The Journal of Mac hine Learning Resear ch , 3 , 1137–1155. [4] Boulanger-Le wando wski, N., Bengio, Y ., and V incent, P . (2012). Modeling temporal dependencies in high-dimensional sequences: Application to polyphonic music generation and transcription. In ICML . [5] Cho, K. et al. (2014). Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Pr oc. of EMNLP , pages 1724–1734. [6] Chorowski, J. K., Bahdanau, D., Serdyuk, D., Cho, K., and Bengio, Y . (2015). Attention-based models for speech recognition. In NIPS , pages 577–585. [7] Chung, J., Kastner , K., Dinh, L., Goel, K., Courville, A., and Bengio, Y . (2015). A recurrent latent variable model for sequential data. In NIPS , pages 2962–2970. [8] Grav es, A. (2013). Generating sequences with recurrent neural networks. . [9] Grav es, A., W ayne, G., and Danihelka, I. (2014). Neural turing machines. . [10] Hinton, G. et al. (2012). Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal Processing Ma gazine, IEEE , 29 (6), 82–97. [11] Hochreiter , S. and Schmidhuber , J. (1997). Long short-term memory . Neural computation , 9 (8). [12] Ji, Y ., Haffari, G., and Eisenstein, J. (2016). A latent variable recurrent neural network for discourse relation language models. In NAA CL-HL T . [13] Kingma, D. and Ba, J. (2015). Adam: A method for stochastic optimization. In Pr oc. of ICLR . [14] K oehn, P . and Monz, C. (2006). Manual and automatic evaluation of machine translation between european languages. In W orkshop on Statistical Machine T ranslation, ACL , pages 102–121. [15] Kumar , A., Irsoy , O., Su, J., Bradbury , J., English, R., Pierce, B., Ondruska, P ., Gulrajani, I., and Socher , R. (2016). Ask me anything: Dynamic memory networks for natural language processing. ICML . [16] Li, J., Galley , M., Brockett, C., Gao, J., and Dolan, B. (2016). A diversity-promoting objecti ve function for neural con versation models. In NAA CL . [17] Liu, C.-W ., Lowe, R., Serban, I. V ., Nosew orthy , M., Charlin, L., and Pineau, J. (2016). Ho w NOT to ev aluate your dialogue system: An empirical study of unsupervised ev aluation metrics for dialogue response generation. . [18] Lowe, R., Po w , N., Serban, I., and Pineau, J. (2015). The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-T urn Dialogue Systems. In Pr oc. of SIGDIAL-2015 . [19] Luong, M. T ., Sutske ver , I., Le, Q. V ., V inyals, O., and Zaremba, W . (2015). Addressing the rare word problem in neural machine translation. In A CL . [20] Mikolov , T . et al. (2010). Recurrent neural network based language model. In 11th Pr oceedings of INTERSPEECH , pages 1045–1048. [21] Mikolov , T . et al. (2013). Distributed representations of words and phrases and their compositionality . In Advances in Neural Information Pr ocessing Systems , pages 3111–3119. [22] Owoputi, O. et al. (2013). Improv ed part-of-speech tagging for online con versational text with word clusters. In Pr oc. of A CL . [23] Pascanu, R., Mik olov , T ., and Bengio, Y . (2012). On the dif ficulty of training recurrent neural networks. Pr oceedings of the 30th International Confer ence on Machine Learning , 28 . [24] Ritter , A., Cherry , C., and Dolan, W . B. (2011a). Data-driv en response generation in social media. In EMNLP . [25] Ritter , A., Clark, S., Mausam, and Etzioni, O. (2011b). Named entity recognition in tweets: An experimental study . In Proc. of EMNLP , pages 1524–1534. [26] Schatzmann, J., Georgila, K., and Y oung, S. (2005). Quantitativ e ev aluation of user simulation techniques for spoken dialogue systems. In 6th SIGdial W orkshop on DISCOURSE and DIALOGUE . [27] Serban, I. V ., Lowe, R., Charlin, L., and Pineau, J. (2015). A survey of av ailable corpora for building data-driv en dialogue systems. CoRR , abs/1512.05742 . [28] Serban, I. V ., Sordoni, A., Bengio, Y ., Courville, A. C., and Pineau, J. (2016a). Building end-to-end dialogue systems using generativ e hierarchical neural network models. In AAAI , pages 3776–3784. [29] Serban, I. V ., Sordoni, A., Lowe, R., Charlin, L., Pineau, J., Courville, A., and Bengio, Y . (2016b). A hierarchical latent variable encoder-decoder model for generating dialogues. arXiv pr eprint arXiv:1605.06069 . 10 [30] Shawar , B. A. and Atwell, E. (2007). Chatbots: are they really useful? In LD V F orum , volume 22. [31] Sordoni, A., Bengio, Y ., V ahabi, H., Lioma, C., Simonsen, J. G., and Nie, J.-Y . (2015). A hierarchical recurrent encoder-decoder for generati ve conte xt-aw are query suggestion. In Pr oc. of CIKM-2015 . [32] Sutske ver , I., V inyals, O., and Le, Q. V . (2014). Sequence to sequence learning with neural networks. In NIPS , pages 3104–3112. [33] Theano De velopment T eam (2016). Theano: A Python frame work for fast computation of mathematical expressions. arXiv e-prints , abs/1605.02688 . [34] W en, T .-H., Gasic, M., Mrksic, N., Rojas-Barahona, L. M., Su, P .-H., Ultes, S., V andyke, D., and Y oung, S. (2016). A network-based end-to-end trainable task-oriented dialogue system. . [35] W eston, J., Chopra, S., and Bordes, A. (2015). Memory networks. ICLR . [36] Y oung, S., Gasic, M., Thomson, B., and W illiams, J. D. (2013). POMDP-based statistical spok en dialog systems: A revie w . Pr oceedings of the IEEE , 101 (5), 1160–1179. 11 A ppendix 8 T ask Details Ubuntu W e use the Ubuntu Dialogue Corpus v2.0 extracted Jamuary , 2016: http://cs.mcgill.ca/ ~jpineau/datasets/ubuntu- corpus- 1.0/ . T witter W e preprocess the dataset using the Moses tokenizer extracted June, 2015: https://github.com/ moses- smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl . 4 9 Coarse Sequence Representations Nouns The noun-based procedure for extracting coarse tok ens aims to exploit high-le vel structure of natural language discourse. More specifically , it b uilds on the hypothesis that dialogues in general are topic-driv en and that these topics may be characterized by the nouns inside the dialogues. At any point in time, the dialogue is centered around one or sev eral topics. As the dialogue progresses, the underlying topic ev olves as well. In addition to the tokenizer required by the previous extraction procedure, this procedure also requires a part-of-speech (POS) tagger to identify the nouns in the dialogue suitable for the language domain. For e xtracting the noun-based coarse tokens, we define a set of 795 stop words for T witter and 84 stop words for Ubuntu containing mainly English pronouns, punctuation marks and prepositions (excluding special placeholder tokens). W e then e xtract the coarse tokens by applying the follo wing procedure to each dialogue: 1. W e apply the POS tagger v ersion 0 . 3 . 2 dev eloped by Ow oputi and colleagues [ 22 ] to extract POS. 5 For T witter , we use the parser trained on the T witter corpus dev eloped by Ritter et al. [ 25 ]. For Ub untu, we use the parser trained on the NPS Chat Corpus developed by Forsyth and Martell which was extracted from IRC chat channels similar to the Ubuntu Dialogue Corpus. 6 7 2. Giv en the POS tags, we remove all words which are not tagged as nouns and all words containing non-alphabet characters. 8 . W e keep all urls and paths. 3. W e remove all stop w ords and all repeated tokens, while maintaining the order of the tokens. 4. W e add the "no_nouns" token to all utterances, which do not contain any nouns. This ensures that no coarse sequences are empty . It also forces the coarse sub-model to explicitly generate at least one token, e ven when there are no actual nouns to generate. 5. For each utterance, we use the POS t ags to detect three types of time tenses: past, present and future tenses. W e append a token indicating which of the 2 3 tenses are present at the beginning of each utterance. 9 If no tenses are detected, we append the token "no_tenses". As before, there exists a one-to-many alignment between the e xtracted coarse sequence tokens and the natural language tokens, since this procedure also maintains the ordering of all special placeholder tokens, with the exception of the "no_nouns" token. W e cut-off the vocab ulary at 10000 coarse tokens for both the T witter and Ubuntu datasets excluding the special placeholder tokens. On av erage a T witter dialogue in the training set contains 25 coarse tokens, while a Ubuntu dialogue in the training set contains 36 coarse tokens. 4 Due to T witter’ s T erms and Conditions we are unfortunately not allowed to publish the preprocessed dataset. 5 www.cs.cmu.edu/~ark/TweetNLP/ 6 As input to the POS tagger, we replace all unknown tokens with the word "something" and remov e all special placeholder tokens (since the POS tagger was trained on a corpus without these words). W e further reduce any consecuti ve sequence of spaces to a single space. For Ub untu, we also replace all commands and entities with the word "something". For T witter , we also replace all numbers with the word "some", all urls with the word "some where" and all heart emoticons with the word "lov e". 7 Forsyth, E. N. and Martell, C. H. (2007). Lexical and discourse analysis of online chat dialog. In Semantic Computing, 2007. ICSC 2007. International Conference on, pages 19–26. IEEE. 8 W e define nouns as all words with tags containing the prefix "NN" according to the PTB-style tagset. 9 Note that an utterance may contain sev eral sentences. It therefore often happens that an utterance contains sev eral time tenses. 12 T able 4: Unigram and bigram models bits per word on noun representations. Model Ubuntu T witter Unigram 10.16 12.38 Bigram 7.26 7.76 Model statistics for the unigram and bigram language models are presented in T able 4 for the noun representations on the Ubuntu and T witter training sets. 10 The table shows a substantial difference in bits per words between the unigram and bigram models, which suggests that the nouns are significantly correlated with each other . Activity-Entity Pairs The activity-entity-based procedure for e xtracting coarse tokens attempts to exploit domain specific kno wledge for the Ubuntu Dialogue Corpus, in particular in relation to providing technical assistance with problem solving. Our manual inspection of the corpus shows that man y dialogues are centered around activities . For e xample, it is very common for users to state a specific problem they w ant to resolve, e.g. how do I install pr ogr am X? or My driver X doesn’ t work, how do I fix it? . In response to such queries, other users often respond with specific instructions, e.g. Go to website X to download software Y or T ry to execute command X . In addition to the technical entities, the principle message con v eyed by each utterance resides in the verbs, e.g. install , work , fix , go , to , download , execute . Therefore, it seems clear that a dialogue system must hav e a strong understanding of both the acti vities and technical entities if it is to ef fecti vely assist users with technical problem solving. It seems likely that this would require a dialogue system able to relate technical entities to each other , e.g. to understand that fir efox depends on the GCC library , and conform to the temporal structure of activities, e.g. understanding that the install activity is often follo wed by download activity . W e therefore construct two word lists: one for activities and one for technical entities. W e construct the activity list based on manual inspection yielding a list of 192 verbs. For each activity , we further develop a list of synonyms and conjugations of the tenses of all words. W e also use W ord2V ec word embeddings [ 21 ], trained on the Ubuntu Dialogue Corpous training set, to identify commonly misspelled variants of each activity . The result is a dictionary , which maps a verb to its corresponding acti vity (if such e xists). For constructing the technical entity list, we scrape publicly av ailable resources, including Ub untu and Linux-related websites as well as the Debian package manager APT . Similar to the activities, we also use the W ord2V ec word embeddings to identify misspelled and paraphrased entities. This results in another dictionary , which maps one or two words to the corresponding technical entity . In total there are 3115 technical entities. In addition to this we also compile a list of 230 frequent commands. Examples of the extracted activities, entities and commands can be found in the appendix. Afterwards, we extract the coarse tok ens by applying the following procedure to each dialogue: 1. W e apply the technical entity dictionary to extract all technical entities. 2. W e apply the POS tagger version 0 . 3 . 2 dev eloped by Owoputi and colleagues, trained on the NPS Chat Corpus dev eloped by Forsyth and Martell as before. As input to the POS tagger, we map all technical entities to the token "something". This transformation should improv e the POS tagging accuracy , since The corpus the parser was trained on does not contain technical words. 3. Giv en the POS tags, we extract all verbs which correspond to activities. 11 . If there are no verbs in an entire utterance and the POS tagger identified the first word as a noun, we will assume that the first word is in fact a verb . W e do this, because the parser does not work well for tagging technical instructions in imperativ e form, e.g. upgrade fir efox . If no activities are detected, we append the token "none_activity" to the coarse sequence. W e also keep all urls and paths. 4. W e remove all repeated acti vities and technical entities, while maintaining the order of the tokens. 5. If a command is found inside an utterance, we append the "cmd" token at the end of the utterance. Otherwise, we append the "no_cmd" token to the end of the utterance. This enables the coarse sub-model to predict whether or not an utterance contains ex ecutable commands. 6. As for the noun-based coarse representation, we also append the time tense to the beginning of the sequence. As before, there exists a one-to-many alignment between the e xtracted coarse sequence tokens and the natural language tokens, with the exception of the "none_acti vity" and "no_cmd" tokens. 10 The models were trained using maximum log-likelihood on the noun representations excluding all special tokens. 11 W e define verbs as all words with tags containing the prefix "VB" according to the PTB-style tagset. 13 T able 5: T witter Coarse Sequence Examples Natural Language T weets Noun Representation <first_speaker> at pinkberry with my pink princess enjoying a precious moment - they are adorable, alma still speaks about emma bif sis . hugs present_tenses pinkberry princess moment present_tenses alma emma bif sis hugs <first_speaker> when you are spray painting, where are you doing it ? outside ? in your apartment ? where ? mostly spray painting outside but some little stuff in the bathroom . present_tenses spray painting apartment present_tenses spray stuff bathroom T able 6: Ub untu Coarse Sequence Examples Natural Language Dialogues Activity-Entity Coarse Dialogues if you can get a hold of the logs, there ’ s stuff from **unknown** about his inability to install amd64 I’ll check fabbione ’ s log, thanks sounds like he had the same problem I did ew , why ? ... upgrade lsb-base and acpid i’m up to date what error do you get ? i don’t find error :/ where do i search from ? acpid works, but i must launch it manually in a root sterm ... future_tenses get_activity install_activity amd64_entity no_cmd no_tenses check_acti vity no_cmd past_present_tenses none_activity no_cmd no_tenses none_activity no_cmd ... no_tenses upgrade_activity lsb_entity acpid_entity no_cmd no_tenses none_activity no_cmd present_tenses get_activity no_cmd present_tenses discover_acti vity no_cmd present_future_tenses work_acti vity acpid_entity root_entity no_cmd ... Since the number of unique tok ens are smaller than 10000 , we do not need to cut-of f the v ocabulary . On av erage a Ubuntu dialogue in the training set contains 43 coarse tokens. Our manual inspection of the extracted coarse sequences, show that the technical entities are identified with very high accuracy and that the acti vities capture the main intended action in the majority of utterances. Due to the high quality of the extracted activities and entities, we are confident that they may be used for e valuation purposes as well. Scripts to generate the noun and activity-entity representations, and to ev aluate the dialogue responses w .r .t. acti vity-entity pairs are available online at: https://github.com/julianser/ Ubuntu- Multiresolution- Tools/tree/master/ActEntRepresentation . 14 Stop W ords for Noun-based Coarse T okens Ubuntu stop words for noun-based coarse representation: all another any anybody anyone an ything both each each other either e verybody everyone ev erything fe w he her hers herself him himself his I it its itself man y me mine more most much myself neither no one nobody none nothing one one another other others ours ourselves sev eral she some somebody someone something that their theirs them themselves these they this those us we what whatever which whichev er who whoever whom whome ver whose you your yours yourself yourselv es . , ? ’ - – ! 15 T witter stop words for noun-based coarse repr esentation: 12 all another any anybody anyone an ything both each each other either e verybody everyone ev erything fe w he her hers herself him himself his I it its itself man y me mine more most much myself neither no one nobody none nothing one one another other others ours ourselves sev eral she some somebody someone something that their theirs them themselves these they this those us we what whatever which whichev er who whoev er whom whomever whose you your yours yourself yourselves . , ? ’ - – !able about above abst accordance according accordingly across act actually added adj adopted affected affecting af fects after afterwards again against ah all almost alone along already also although al ways am among amongst an and announce another an y anybody anyho w anymore anyone anything anyway anyways anywhere apparently approximately are aren arent arise around as aside ask asking at auth av ailable away awfully b back bc be became because become becomes becoming been before beforehand begin beginning beginnings begins behind being believe belo w beside besides between beyond biol bit both brief briefly but by c ca came can cannot can’t cant cause causes certain certainly co com come comes contain containing contains cos could couldnt d date day did didn didn’t different do does doesn doesn’t doing don done don’t dont down do wnwards due during e each ed edu effect eg eight eighty either else elsewhere end ending enough especially et et-al etc even ever every everybody everyone everything everywhere ex except f far few ff fifth first five fix followed following follows for former formerly forth found four from further furthermore g game gave get gets getting give given gives giving go goes going gone gonna good got gotten great h had happens hardly has hasn hasn’t have haven haven’t having he hed hence her here hereafter hereby herein heres hereupon hers herself hes he y hi hid him himself his hither home ho w howbeit ho we ver hundred i id ie if i’ ll im immediate immediately importance important in inc indeed index information instead into inv ention inward is isn isn’ t it itd it’ll its itself i’ v e j just k keep keeps kept ke ys kg km kno w kno wn kno ws l ll lar gely last lately later latter latterly least less lest let lets like liked likely line little ll ’ll lol look looking looks lot ltd m made mate mainly mak e makes many may maybe me mean means meantime meanwhile merely mg might million miss ml more moreover most mostly mr mrs much mug must my myself n na name namely nay nd near nearly necessarily necessary need needs neither never nevertheless new next nine ninety no nobody non none nonetheless noone nor normally nos not noted nothing now nowhere o obtain obtained obviously of off often oh ok okay old omitted omg on once one ones only onto or ord other others otherwise ought our ours ourselves out outside o ver o verall o wing own p page pages part particular particularly past people per perhaps placed please plus poorly possible possibly potentially pp predominantly present previously primarily probably promptly proud provides put q que quickly quite qv r ran rather rd re readily really recent recently ref refs regarding regardless regards related relativ ely research respecti vely resulted resulting results right rt run s said same saw say saying says sec section see seeing seem seemed seeming seems seen self selves sent seven several shall she shed she’ll shes should shouldn shouldn’t show showed shown showns shows significant significantly similar similarly since six slightly so some somebody someho w someone somethan something sometime sometimes somewhat somewhere soon sorry specifically specified specify specifying state states still stop strongly sub substantially successfully such sufficiently suggest sup sure t take taken taking tbh tell tends th than thank thanks thanx that that’ll thats that’ve the their theirs them themselves then thence there thereafter thereby thered therefore therein there’ll thereof therere theres thereto thereupon there’ ve these they theyd they’ll theyre they’ ve thing things think this those thou though thoughh thousand throug through throughout thru thus til time tip to together too took toward towards tried tries truly try trying ts tweet twice two u un under unfortunately unless unlike unlik ely until unto up upon ups ur us use used useful usefully usefulness uses using usually v v alue v arious v e ’ v e very via viz vol vols vs w wanna want wants was wasn wasn’t way we wed welcome well we’ll went were weren weren’t we’v e what whatever what’ll whats when whence whenev er where whereafter whereas whereby wherein wheres whereupon wherev er whether which while whim whither who whod whoever whole who’ll whom whomever whos whose why widely will willing wish with within without won won’t words world would w ouldn wouldn’t www x y yeah yes yet you youd you’ll your youre yours yourself yourselv es you’ ve z zero Activities and Entities for Ubuntu Dialogue Corpus Ubuntu activities: accept, activate, add, ask, appoint, attach, backup, boot, check, choose, clean, click, comment, compare, compile, compress, change, affirm, connect, continue, administrate, copies, break, create, cut, debug, decipher , decompress, define, describe, debind, deattach, deactiv ate, download, adapt, eject, email, conceal, consider, execute, close, expand, expect, export, discover , correct, fold, freeze, get, deliv er, go, grab, hash, import, include, install, interrupt, load, block, log, log-in, log-out, demote, b uild, clock, bind, more, mount, move, navigate, open, arrange, partition, paste, patch, plan, plug, post, practice, produce, pull, purge, push, put, queries, quote, look, reattach, reboot, receive, reject, release, remake, delete, name, replace, request, reset, resize, restart, retry , return, rev ert, reroute, scroll, send, set, display , shutdown, size, sleep, sort, split, come-up, store, signup, get-ahold-of, say, test, transfer, try , uncomment, de-expand, uninstall, unmount, unplug, unset, sign-out, update, upgrade, upload, use, delay , enter, support, prevent, loose, point, contain, access, share, buy , sell, help, work, mute, restrict, play , call, thank, burn, advice, force, repeat, stream, respond, browse, scan, restore, design, refresh, bundle, implement, programming, compute, touch, overheat, cause, affect, swap, format, rescue, zoomed, detect, dump, simulate, checkout, unblock, document, troubleshoot, con v ert, allocate, minimize, maximize, redirect, maintain, print, spam, throw , sync, contact, destroy 12 Part of these were extracted from https://github.com/defacto133/twitter- wordcloud- bot/ blob/master/assets/stopwords- en.txt . 16 Ubuntu entities (excerpt): ubuntu_7.04, dmraid, vnc4server , tasksel, ae gis, mirage, system-config-audit, uif2iso, aumix, unrar , dell, hibernate, ucoded, finger , zone- minder , ucfg, macaddress, ia32-libs, synergy , aircrack-ng, pulseaudio, gnome, kid3, bittorrent, systemsettings, cups, finger, xchm, pan, uwidget, vnc-java, linux-source, ucommand.com, epiphany , avanade, onboard, uextended, substance, pmount, lilypond, proftpd, unii, jockey-common, aha, units, xrdp, mp3check, cruft, uemulator , ulivecd, amsn, ub untu_5.10, acpidump, uadd-on, gpac, ifenslave, pidgin, soundcon verter , kdelibs-bin, esmtp, vim, travel, smartdimmer, uactionscript, scrotwm, fbdesk, tulip, beep, nikto, wine, linux-image, azureus, vim, makefile, uuid, whiptail, alex, junior-arcade, libssl-dev , update-inetd, uextended, uaiglx, sudo, dump, lockout, overlay- scrollbar , xubuntu, mdk, mdm, mdf2iso, linux-libc-dev , sms, lm-sensors, dsl, lxde, dsh, smc, sdf, install-info, xsensors, gutenprint, sensors, ubuntu_13.04, atd, ata, fatrat, fglrx, equinix, atp, atx, libjpeg-dbg, umingw , update-inetd, firefox, devede, cd-r, tango, mixxx, uemulator , compiz, libpulse-de v , synaptic, ecryptfs, crawl, ugtk+, tree, perl, tree, ubuntu-docs, libsane, gnomeradio, ufilemaker , dyndns, libfreetype6, daemon, xsensors, vncviewer , vga, indicator-applet, nvidia-173, rsync, members, qemu, mount, rsync, macbook, gsfonts, synaptic, finger, john, cam, lpr, lpr, xsensors, lpr , lpr, screen, inotify , signatures, units, ushareware, ufraw , bonnie, nec, fstab, nano, bless, bibletime, irssi, ujump, foremost, nzbget, ssid, onboard, synaptic, branding, hostname, radio, hotwire, xebia, netcfg, xchat, irq, lazarus, pilot, ucopyleft, java-common, vm, ifplugd, ncmpcpp, irc, uclass, gnome, sram, binfmt-support, vuze, jav a-common, sauer- braten, adapter , login Ubuntu commands: alias, apt-get, aptitude, aspell, awk, basename, bc, bg, break, builtin, bzip2, cal, case, cat, cd, cfdisk, chgrp, chmod, chown, chroot, chkconfig, cksum, cmp, comm, command, continue, cp, cron, crontab, csplit, curl, cut, date, dc, dd, ddrescue, declare, df, diff, diff3, dig, dir , dircolors, dirname, dirs, dmesg, du, echo, egrep, eject, enable, env , ev al, ex ec, exit, expect, expand, export, e xpr, false, fdformat, fdisk, fg, fgrep, file, find, fmt, fold, for , fsck, ftp, function, fuser, gawk, getopts, grep, groupadd, groupdel, groupmod, groups, gzip, hash, head, history, hostname, htop, iconv , id, if, ifconfig, ifdown, ifup, import, install, ip, jobs, join, kill, killall, less, let, link, ln, local, locate, logname, logout, look, lpc, lpr , lprm, ls, lsof, man, mkdir , mkfifo, mknod, more, most, mount, mtools, mtr , mv, mmv , nc, nl, nohup, notify-send, nslookup, open, op, passwd, paste, ping, pkill, popd, pr , printf, ps, pushd, pv , pwd, quota, quotacheck, quotactl, ram, rar , rcp, read, readonly , rename, return, re v , rm, rmdir , rsync, screen, scp, sdif f, sed, select, seq, set, shift, shopt, shutdo wn, sleep, slocate, sort, source, split, ssh, stat, strace, su, sudo, sum, suspend, sync, tail, tar, tee, test, time, timeout, times, touch, top, tput, traceroute, tr, true, tsort, tty , type, ulimit, umask, unalias, uname, unexpand, uniq, units, unrar, unset, unshar , until, useradd, userdel, usermod, users, uuencode, uudecode, vi, vmstat, wait, watch, wc, whereis, which, while, who, whoami, write, xargs, xdg-open, xz, yes, zip, admin, purge 17 10 Model Details T raining All models were trained with a learning rate of 0 . 0002 or 0 . 0001 , batches of size either 40 or size 80 and gradients are clipped at 1 . 0 . W e truncate the backpropagation to batches with 80 tokens W e validate on the entire validation set ev ery 5000 training batches. W e choose almost identical hyperparameters for the Ub untu and T witter models, since the models appear to perform similarly w .r .t. different hyperparameters and since the statistics of the two datasets are comparable. W e use the 20 K most frequent words on T witter and Ubuntu as the natural language v ocabulary for all the models, and assign all w ords outside the v ocabulary to a special unkno wn token symbol. For MrRNN, we use a coarse token v ocabulary consisting of the 10 K most frequent tokens in the coarse token sequences. Generation W e compute the cost of each beam search (candidate response) as the log-likelihood of the tokens in the beam divided by the number of tokens it contains. The LSMT model performs better when the beam search is not allowed to generate the unkno wn token symbol, ho we ver e ven then it still performs worse than the HRED model across all metrics except for the command accurac y . Baselines Based on preliminary experiments, we found that a slightly different parametrization of the HRED baseline model worked better on T witter . The encoder RNN has a bidirectional GR U RNN encoder , with 1000 hidden units for the forward and backward RNNs each, and a context RNN and a decoder RNN with 1000 hidden units each. Furthermore, the decoder RNN computes a 1000 dimensional real-v alued vector for each hidden time step, which is multiplied with the output conte xt RNN. The output is feed through a one-layer feed-forw ard neural network with hyperbolic tangent acti v ation function, which the decoder RNN then conditions on. 11 Human Evaluation All human evaluators either study or work in an English speaking en vironment, and hav e indicated that they hav e some experience using a Linux operating system. T o ensure a high quality of the ground truth responses, human ev aluators were only asked to ev aluate responses, where the ground truth contained at least one technical entity . Before starting ev aluators, were sho wn one short annotated example with a brief explanation of ho w to giv e annotations. In particular, the e v aluators were instructed to use the following reference in Figure 2. Figure 2: Fluenc y and relev anc y reference table presented to human ev aluators. The 5 ev aluators ga ve 1069 ratings in total. T able 7 shows the scores by category . T able 7: Ub untu human fluency and rele v ancy scores by rating cate gory Fluency Relevancy ` ` ` ` ` ` ` ` ` ` Model Rating Level 0 1 2 3 4 0 1 2 3 4 HRED 3 11 21 50 49 68 22 19 19 4 HRED + Act.-Ent. 3 17 19 37 57 69 39 18 6 2 MrRNN Noun 1 2 8 52 71 51 45 24 10 4 MrRNN Act.-Ent 0 2 6 52 74 27 53 39 14 1 18 12 Model Examples Model response examples are given in this section. All the model responses can be do wnloaded at www.iulianserban.com/Files/TwitterDialogueCorpus.zip and www.iulianserban.com/Files/ UbuntuDialogueCorpus.zip . T able 8: Ub untu model examples. The → token indicates a change of turn. Context Response seriously ... 50% cpu from xorg running just two apps(terminal and system monitor ) i’ ve been seeing this ever since i upgraded to 12.10 an yone else seeing this → I would do such kind of tests with ’ top ’ or ’ something Enjoy the difference... → that is top saying 50% cpu from xorg → Ok. In that case I would try a window manager without composite for a try . 50% is too much. MrRNN Act. -Ent.: Are you using XGL ? MrRNN Noun: What window manager are you using ? HRED + Act.-Ent.: I don’t know how to help you with that, sorry . HRED: i have no idea how to do that, i just want to know how to do it LSTM: something ? my linux seems to be stuck at rev 18... other systems in the house are as high as rev 34... any suggestions ? → what ’ s rev ? → the linux info says kernel linux says 3.5. something generic MrRNN Act. -Ent.: how do i compile the kernel ? MrRNN Noun: the linux kernel is 2.6. something HRED + Act.-Ent.: how do i find out what v ersion of ubuntu i have ? HRED: that ’ s not what you want to do LSTM: ? what do you mean ? i need some SERIOUS help with fullscreen video playback. i al- ready asked in #lubuntu, b ut i might have a better chance here : most video files either let the player hang or audio/video goes badly out of sync right away . i know that it does work with the same files and it even did so like two hours ago, but after some browsing and man page reading, the problem comes up again. i have NO idea where to look anymore nor what I did to ’ reproduce ’ the → even with vlc MrRNN Act. -Ent.: works fine in vlc MrRNN Noun: do you use vlc ? HRED + Act.-Ent.: what video card do you have ? HRED: yeah, i know , but i don’t know how to do that, but i don’t kno w how to do that LSTM: ? what do you mean ? I’m in the process of building a new desktop and I was wondering if there w as an y way to, using KVM, start or restart a Windo ws ses- sion when my girlfriend logs in. I have plenty of memory and my i5 3570 supports all the necessary virtualisation technologies. → you can install VirtualBox, and I’m sure there ’ s a command line method to run VB with a specified installed VM operating system, and you can make that command a startup command ending with " & " MrRNN Act. -Ent.: have you installed virtualbox ? MrRNN Noun: are you trying to install ubuntu ? HRED + Act.-Ent.: I don’t know how to do that, sorry . I don’t kno w how to do that. HRED: thanks, I’ll giv e it a shot. LSTM: thanks, I’ll try that. hello all, how can i setup two default gateways graphically in net- work manager ? → you can’t have 2 default gateway on one de- vice...? → well.. i can → hows that gonna work ? MrRNN Act. -Ent.: what are you looking for ? MrRNN Noun: do you have a def ault gateway ? HRED + Act.-Ent.: what are you trying to do ? HRED: i want to set up a static ip, but i dont know how to set it up LSTM: ? They are mounted via fstab → sure they are mounted ? → I’v e been using them all day :[ p :P * MrRNN Act. -Ent.: I see MrRNN Noun: something :/ something ls -ld something HRED + Act.-Ent.: I can mount it, but when I try to mount it, it says " mount : special device /dev/sda1 does not exist HRED: what do you mean by mount ? LSTM: ? what are you talking about ? 19 T able 9: Ub untu model examples. The → token indicates a change of turn. Context Response can you have gnome and KDE installed and use one or the other ? cough erin brainwav es MrRNN Act.-Ent.: what are you looking for ? MrRNN Noun: gconf-editor HRED + Act.-Ent.: what do you want me to do ? HRED: yeah, i just did a fresh install of ubuntu, and it w orked fine. LSTM: ? Ugh so my mount points need to be in /media rather than /mnt to make them appear in the nautilus side-pane : → you could symlink /mnt to /media afaik MrRNN Act. -Ent.: thank you :) MrRNN Noun: you need to mount it in /mnt or /media HRED + Act.-Ent.: if you don’t know what you are trying to do, then you should be able to mount it manually , but I don’t know ho w HRED: I don’t kno w how to do that, I just want to be able to mount them in /media LSTM: what ? How can i install ub untu raring ? → ask in #ub untu+1 → they are afk all of them → so ? doesn’t mean its ontoppic here MrRNN Act. -Ent.: can you just tell me how ? MrRNN Noun: join #ubuntu-of ftopic HRED + Act.-Ent.: what are you trying to do ? HRED: i know , but i dont know how to install it LSTM: ? How shall I reboot BIOS 100 time through script → i’m really curious why anyone would ever want to do that... → For BIOS stress testing MrRNN Act. -Ent.: do you know how to check bios ? MrRNN Noun: How do I disable the bios ? HRED + Act.-Ent.: I don’t want to reboot, I just want to be able to boot from a USB stick, but I don’t want to have to do it ev ery time I want to do it HRED: that ’s not what you want to do, but you might want to ask in ##hardware LSTM: ? what is the current version of wine in ubuntu ? i can see wine 1.5. Howe ver , when I try to install it via synaptic it wants to remove VLC ? → did you install vlc as a windows version ? → windows version on Ubuntu ? MrRNN Act. -Ent.: what version of ff do you have installed ? MrRNN Noun: what version of ubuntu are you using ? HRED + Act.-Ent.: how do i install the latest version of wine ? i have the latest version, b ut i dont know ho w to install it HRED: yes LSTM: yes Hey guys, I’m trying to install libreoffice from the repositories, but it ’ s throwing a wobbly . Can anyone help ? Looks like de- pendency problems, but when I attempt to resolve them it throws a wobbly at me. → try ’ apt-get install -f ’ yeah, it looks like you don’t have java install Y ou need to try to run ’ apt-get install -f ’, just that string try ’ apt-get purge libreoffice ’ it looks like you had it installed previously → update : just realized I re- moved it earlier because it wasn’t working. let me re-install. when I run ’ apt-get purge libreof fice ’ it just complains of unmet depen- dencies/ → but you were able to reinstall fine ? → no, it throws the errors seen in the pastebin at me → jwrigley , check to see if /var/lib/libreof fice/share/prereg e xists → doesn’t appear to exist when i cd to it in terminal → use apt-get via the command line tab completion helps a lot run ’ apt-get purge libreoffice ’ → oh, yeah i see now . sorry . now it is telling me to fix dependencies with apt-get install -f → awesome, so are you all set now ? → well libreoffice is still not working, so no. MrRNN Act. -Ent.: I see. MrRNN Noun: how do I get rid of libreof fice ? HRED + Act.-Ent.: it says " E : Could not get lock /var/lib/dpkg/lock - open ( 11 Resource temporarily unavail- able ) E : Unable to locate package something " HRED: I don’t know what that is, but I don’t know how to fix it LSTM: is installed Can an yone help get wireless working ? → whats the trouble ? → It doesnt show an y wireless networks MrRNN Act. -Ent.: It ’ s not working. MrRNN Noun: How do I get to the network manager ? HRED + Act.-Ent.: what is the name of your wireless card ? HRED: are you using ndiswrapper ? LSTM: what do you mean ? Who can answer : " How can i get mac address of the server i just connected via pppoe ?" → try tcpdump ? tcpdump -e MrRNN Act. -Ent.: what are you looking for ? MrRNN Noun: what is your mac address ? HRED + Act.-Ent.: what are you trying to do ? HRED: thanks, i’ll try that LSTM: command not found 20 T able 10: T witter model examples. The → token indicates a change of turn. Context Response kids are so well informed! MrRNN: i love the kids!!! VHRED: wow , you’re so cute! HRED: i’m so happy for you!!! LSTM: that’ s the spirit!!! russell cro we. amazing actor and good person. perfect. i am sure. MrRNN: johnny depp is the best!!! VHRED: something!!! HRED: i’m glad you enjoyed it! LSTM: he is a great actor . thank you for being so welcoming. who kne w do wntown little rock was so beauti- ful? loved it! MrRNN: i love that song!!! VHRED: happy birthday to you! HRED: i love you!!! LSTM: i’m glad you liked it! i’ ve got a core i5 macbook air right here if any- one has any questions. or you can ask in the comments thread here → how well does it run photoshop illustrator? → pretty much just as well as the current macbook pros do. MrRNN: do you have a macbook pro???!!! VHRED: ok, so what do you want to do? HRED: i’m sure you’ll find it soon. i’m sure it’ll be worth it. LSTM: thanks for the heads up. i’ll check it out. maybe bigger than jb. haha jk. → i’m fan of her . she’ s so awesome. → hahahahahahahaha p just amazed. → thinking of dudz? MrRNN: yes. i love justin bieber!!! VHRED: i love her . HRED: no, i don ’t think so. LSTM: i think she’ s just a little bit of a something. countdown reminds me of hold on wilsonphillips MrRNN: it’ s a spring break!!! - - - - - - - - - - - - - - - - - VHRED: i’m so excited for you!!! HRED: something!!! LSTM: something!!! here is a sadbuttrue fact - bad news trav els f ast while good news seems to just linger. people don ’t like spreading good ne ws MrRNN: i agree with the news!!! VHRED: thank you for the support! HRED: what’ s the news? LSTM: i agree, but i don ’t think it’ s a bad thing to do. i don ’t think it’s a bad thing to do. have you dmed justin bieber yet for me? → yeah. MrRNN: do you have bieber fe ver? VHRED: dm me your email and i’ll send it to you HRED: thank you LSTM: thank you hanging out in the library for the past cou- ple hours makes me feel like i’ll do great on this test! → wow , what a nerd lol jk haha p what!? you changed your bio → do you like my bio now? i feel bad for changing it but i like change. p MrRNN: yeah, it’ s in the library!!! VHRED: what do you mean? HRED: haha i’m glad i’m not the only one! LSTM: yeah i like it but i don ’ t know what to do with it lol christian bale must be prepping for a gordon’ s fish sticks commercial. oscar MrRNN: i’m not a christian bale. i don ’ t kno w what he’ s talking about. but i don ’t kno w what he’ s talking about. lol. something!!! VHRED: did you see the new harry potter movie? HRED: i don ’t think it’ s a good movie, b ut it’ s a good movie. LSTM: i’m going to have to watch that. some railscamp nz action. → how goes it? MrRNN: it’ s great to see you in nz!!! VHRED: not too bad, just a little tired. how are you? HRED: it’ s been a while since i’ ve been here. HRED: it’ s going to be a long day . second netball game for the week. let’s do it! isupportwomeninsport MrRNN: what’ s netball???!!! VHRED: i’m going to have to go to the gym tomorro w . HRED: i’m going to be in the ’ s. LSTM: what’ s the score? 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment