Deep Successor Reinforcement Learning
Learning robust value functions given raw observations and rewards is now possible with model-free and model-based deep reinforcement learning algorithms. There is a third alternative, called Successor Representations (SR), which decomposes the value…
Authors: Tejas D. Kulkarni, Ardavan Saeedi, Simanta Gautam
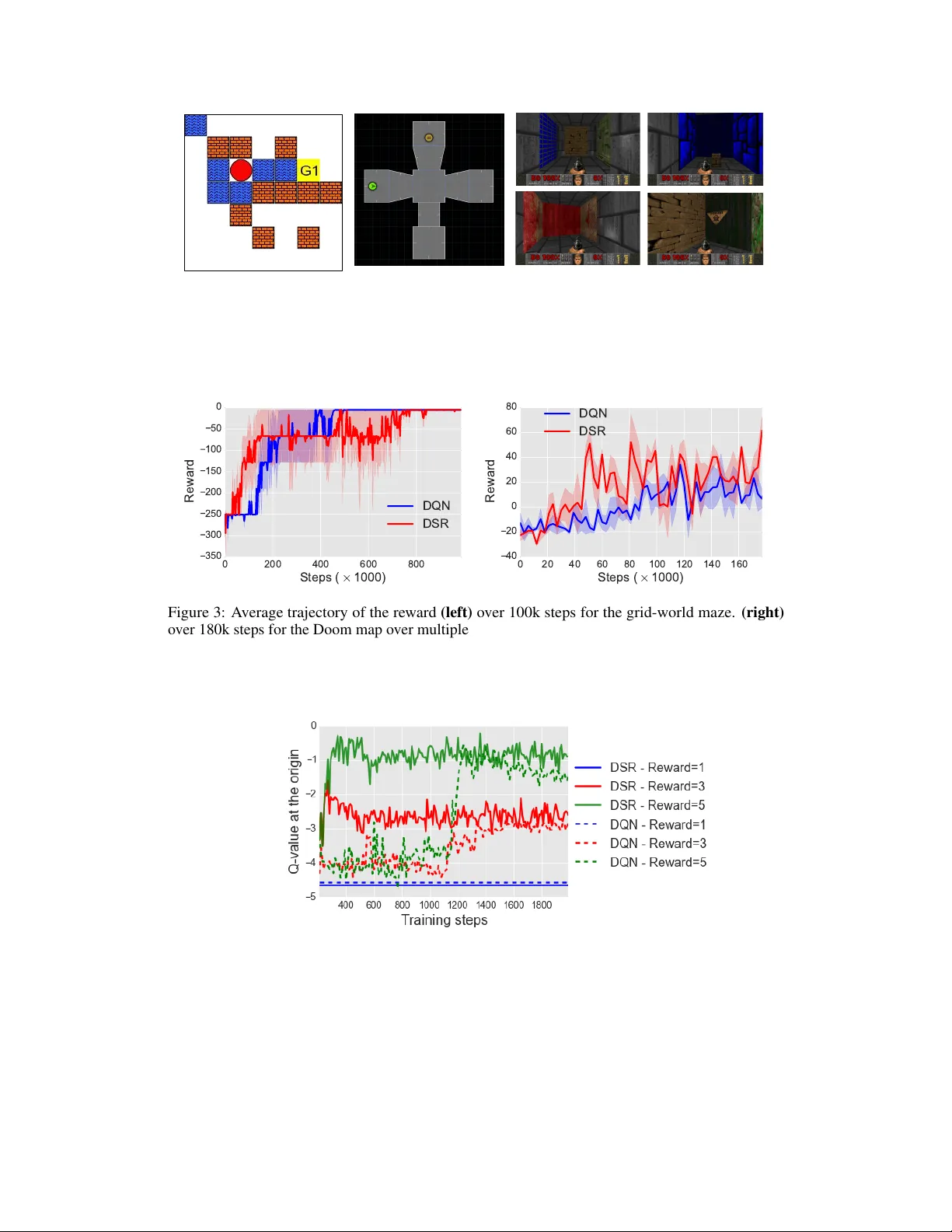
Deep Successor Reinf or cement Learning T ejas D. K ulkarni ∗ BCS, MIT tejask@mit.edu Ardav an Saeedi ∗ CSAIL, MIT ardavans@mit.edu Simanta Gautam CSAIL, MIT simanta@mit.edu Samuel J. Gershman Department of Psychology Harvard Uni versity gershman@fas.harvard.edu Abstract Learning robust v alue functions gi ven raw observ ations and re wards is now possible with model-free and model-based deep reinforcement learning algorithms. There is a third alternativ e, called Successor Representations (SR), which decomposes the value function into tw o components – a reward predictor and a successor map. The successor map represents the expected future state occupancy from any giv en state and the re ward predictor maps states to scalar re wards. The value function of a state can be computed as the inner product between the successor map and the re ward weights. In this paper , we present DSR, which generalizes SR within an end-to-end deep reinforcement learning framew ork. DSR has sev eral appealing properties including: increased sensitivity to distal reward changes due to factorization of rew ard and world dynamics, and the ability to e xtract bottleneck states (subgoals) giv en successor maps trained under a random policy . W e show the ef ficacy of our approach on two di verse en vironments gi ven ra w pixel observ ations – simple grid-world domains (MazeBase) and the Doom game engine. 2 1 Introduction Many learning problems in volve inferring properties of temporally extended sequences giv en an objectiv e function. For instance, in reinforcement learning (RL), the task is to find a policy that maximizes expected future discounted rew ards (value). RL algorithms fall into two main classes: (1) model-free algorithms that learn cached value functions directly from sample trajectories, and (2) model-based algorithms that estimate transition and reward functions, from which v alues can be computed using tree-search or dynamic programming. Howe ver , there is a third class, based on the successor repr esentation (SR), that factors the value function into a predictiv e representation and a rew ard function. Specifically , the v alue function at a state can be expressed as the dot product between the vector of e xpected discounted future state occupancies and the immediate re ward in each of those successor states. Representing the value function using the SR has se veral appealing properties. It combines computa- tional ef ficiency comparable to model-free algorithms with some of the flexibility of model-based algorithms. In particular, the SR can adapt quickly to changes in distal reward, unlike model-free algorithms. In this paper , we also highlight a feature of the SR that has been less well-in v estigated: the ability to extract bottleneck states (candidate subgoals) from the successor representation under a random policy [ 35 ]. These subgoals can then be used within a hierarchical RL framew ork. In this paper we de velop a powerful functi on approximation algorithm and architecture for the SR using a deep neural network, which we call Deep Successor Reinfor cement Learning (DSR). This enables learning the SR and rew ard function from raw sensory observ ations with end-to-end training. ∗ Authors contributed equally and listed alphabetically . 2 Code and other resources – https://github.com/Ardavans/DSR 32 8x8 s t 64 4x4 64 3x3 512 s t f ✓ 512 256 512 512 256 512 . . . m s t ,a =1 m s t ,a = n u ↵ 512 4x4 256 4x4 128 4x4 64 4x4 channels 4x4 g ˜ ✓ ˆ s t w R ( s t ) Figure 1: Model Architectur e: DSR consists of: (1) feature branch f θ (CNN) which takes in raw images and computes the features φ s t , (2) successor branch u α which computes the SR m s t ,a for each possible action a ∈ A , (3) a deep con volutional decoder which produces the input reconstruction ˆ s t and (4) a linear regressor to predict instantaneous rew ards at s t . The Q-value function can be estimated by taking the inner-product of the SR with re ward weights: Q π ( s, a ) ≈ m sa · w . . The DSR consists of two sub-components: (1) a reward feature learning component, constructed as a deep neural netw ork, predicts intrinsic and extrinsic rewards to learn useful features from ra w observ ations; and (2) an SR component, constructed as a separate deep neural network, that estimates the expected future “feature occupancy” conditioned on the current state and averaged over all actions. The value function can then be estimated as the dot product between these two factored representations. W e train DSR by sampling experience trajectories (state, next-state, action and rew ard) from an experience replay memory and apply stochastic gradient descent to optimize model parameters. T o avoid instability in the learning algorithm, we interleav e training of the successor and rew ard components. W e show the efficac y of our approach on tw o different domains: (1) learning to solve goals in grid-world domains using the MazeBase game engine and (2) learning to navigate a 3D maze to gather a resource using the Doom game engine. W e sho w the empirical con ver gence results on se veral policy learning problems as well as sensiti vity of the value estimator gi ven distal re ward changes. W e also demonstrate the possibility of extracting plausible subgoals for hierarchical RL by performing normalized-cuts on the SR [32]. 2 Related work The SR has been used in neuroscience as a model for describing different cogniti ve phenomena. [ 7 ] showed that the temporal context model [ 11 ], a model of episodic memory , is in fact estimating the SR using the temporal difference algorithm. [ 3 ] introduced a model based on SR for preplay and rapid path planning in the CA3 region of the hippocampus. They interpret the SR as an an attractor network in a lo w–dimensional space and show that if the network is stimulated with a goal location it can generate a path to the goal. [ 35 ] suggested a model for tying the problems of na vigation and rew ard maximization in the brain. They claimed that the brain’ s spatial representations are designed to support the re ward maximization problem (RL); they sho wed the beha vior of the place cells and grid cells can be explained by finding the optimal spatial representation that can support RL. Based on their model the y proposed a way for identifying reasonable subgoals from the spectral features of the SR. Other work (see for instance, [ 2 , 4 ]) hav e also discussed utilizing the SR for subgoal and option discov ery . 2 There are also models similar to the SR that have been been applied to other RL-related domains. [ 31 ] introduced a model for e valuating the positions in the game of Go; the model is reminiscent of SR as it predicts the f ate of ev ery position of the board instead of the o verall game score. Another rew ard-independent model, univ ersal option model (UOM), proposed in [ 39 ], uses state occupancy function to build a general model of options. They pro ved that UOM of an option, giv en a rew ard function, can construct a traditional option model. There has also been a lot of work on option discov ery in the tabular setting [ 14 , 18 – 20 , 34 ]. In more recent work, Machado et al. [ 17 ] presented an option discovery algorithm where the agent is encouraged to explore re gions that were previously out of reach. Ho wever , option discovery where non-linear state approximations are required is still an open problem. Our model is also related to the literature on v alue function approximation using deep neural networks. The deep-Q learning model [ 22 ] and its v ariants (e.g., [ 21 , 24 , 29 , 33 ]) ha ve been successful in learning Q-value functions from high-dimensional comple x input states. 3 Model 3.1 Background Consider an MDP with a set of states S , set of actions A , re ward function R : S → R , discount factor γ ∈ [0 , 1] , and a transition distrib ution T : S × A → [0 , 1] . Gi ven a polic y π : S × A → [0 , 1] , the Q-value function for selecting action a in state s is defined as the expected future discounted return: Q π ( s, a ) = E " ∞ X t =0 γ t R ( s t ) | s 0 = s, a 0 = a # , (1) where, s t is the state visited at time t and the expectation is with respect to the polic y and transition distribution. The agent’ s goal is to find the optimal policy Q ∗ which follows the Bellman equation : Q ∗ ( s, a ) = R ( s t ) + γ max a 0 E [ Q ( s t +1 , a 0 )] . (2) 3.2 The successor repr esentation The SR can be used for calculating the Q-value function as follows. Given a state s , action a and future states s 0 , SR is defined as the expected discounted future state occupanc y: M ( s, s 0 , a ) = E " ∞ X t =0 γ t 1 [ s t = s 0 ] | s 0 = s, a 0 = a # , where 1 [ . ] = 1 when its argument is true and zero otherwise. This implicitly captures the state visitation count. Similar to the Bellman equation for the Q-value function (Eq. 2), we can express the SR in a recursiv e form: M ( s, s 0 , a ) = 1 [ s t = s 0 ] + γ E [ M ( s t +1 , s 0 , a t +1 )] . (3) Giv en the SR, the Q-v alue for selecting action a in state s can be expressed as the inner product of the immediate rew ard and the SR [5]: Q π ( s, a ) = X s 0 ∈S M ( s, s 0 , a ) R ( s 0 ) (4) 3.3 Deep successor repr esentation For lar ge state spaces, representing and learning the SR can become intractable; hence, we appeal to non-linear function approximation. W e represent each state s by a D -dimensional feature vector φ s which is the output of a deep neural network f θ : S → R D parameterized by θ . For a feature v ector φ s , we define a feature-based SR as the e xpected future occupancy of the features and denote it by m sa . W e approximate m sa by another deep neural network u α parameterized by α : m sa ≈ u α ( φ s , a ) . W e also approximate the immediate reward for state s as a linear function of the feature vector φ S : R ( s ) ≈ φ s · w , where w ∈ R D is a weight vector . Since rew ard values 3 can be sparse, we can also train an intrinsic rew ard predictor R i ( s ) = g ˜ θ ( φ s ) . A good intrinsic rew ard channel should give dense feedback signal and provide features that preserve latent factors of variations in the data (e.g. deep generativ e models that do reconstruction). Putting these two pieces together , the Q-value function can be approximated as (see 4 for closed form): Q π ( s, a ) ≈ m sa · w . (5) The SR for the optimal policy in the non-linear function approximation case can then be obtained from the following Bellman equation: m sa = φ s + γ E m s t +1 a 0 (6) where a 0 = argmax a m s t +1 a · w . 3.4 Learning The parameters ( θ , α, w , ˜ θ ) can be learned online through stochastic gradient descent. The loss function for α is giv en by: L m t ( α, θ ) = E [( φ ( s t ) + γ u α prev ( φ s t +1 , a 0 ) − u α ( φ s t , a )) 2 ] , where a 0 = argmax a u α ( φ s t +1 , a ) · w and the parameter α prev denotes a pre viously cached parameter value, set periodically to α . This is essential for stable Q-learning with function approximations (see [22]). For learning w , the weights for the rew ard approximation function, we use the following squared loss function: L r t ( w , θ ) = ( R ( s t ) − φ s t · w ) 2 (7) Parameter θ is used for obtaining the φ ( s ) , the shared feature representation for both rew ard prediction and SR approximation. An ideal φ ( s ) should be: 1) a good predictor for the immediate re ward for that state and 2) a good discriminator for the states. The first condition can be handled by minimizing loss function L r t ; howe ver , we also need a loss function to help in the second condition. T o this end, we use a deep conv olutional auto-encoder to reconstruct images under an L2 loss function. This dense feedback signal can be interpreted as an intrinsic rew ard function. The loss function can be stated as: L a t ( ˜ θ , θ ) = ( g ˜ θ ( φ s t ) − s t ) 2 . (8) The composite loss function is the sum of the three loss functions giv en abov e: L t ( θ , α, w , ˜ θ ) = L m t ( α, θ ) + L r t ( w , θ ) + L a t ( ˜ θ , θ ) (9) For optimizing Eq. 9, with respect to the parameters ( θ , α, w , ˜ θ ) , we iterati vely update α and ( θ , w , ˜ θ ) . That is, we learn a feature representation by minimizing L r t ( w ) + L a t ( ˜ θ ) ; then giv en ( θ ∗ , w ∗ , ˜ θ ∗ ) , we find the optimal α ∗ . This iteration is important to ensure that the successor branch does not back-propagate gradients to affect θ . W e use experience replay memory D of size 1 e 6 to store transitions, and apply stochastic gradient descent with a learning rate of 2 . 5 e − 4 , momentum of 0 . 95 , a discount factor of 0 . 99 and the exploration parameter annealed from 1 to 0.1 as training progresses. Algorithm 1 highlights the learning algorithm in greater detail. 4 A utomatic Subgoal Extraction Learning policies giv en sparse or delayed rewards is a significant challenge for current reinforcement learning algorithms. This is mainly due to inef ficient exploration schemes such as − greedy . Existing methods like Boltzmann exploration and Thomson sampling [ 26 , 36 ] offer significant impro vements ov er -greedy , b ut are limited due to the underlying models functioning at the lev el of basic actions. Hierarchical reinforcement learning algorithms [ 1 ] such as the options frame work [ 38 , 39 ] provide a flexible framework to create temporal abstractions, which will enable e xploration at different time-scales. The agent will learn options to reach the subgoals which can be used for intrinsic motiv ation. In the context of hierarchical RL, [ 8 ] discuss a frame work for subgoal extraction using the structural aspects of a learned polic y model. Inspired by previous work in subgoal discovery from 4 Algorithm 1 Learning algorithm for DSR 1: Initialize experience replay memory D , parameters { θ , α, w , ˜ θ } and exploration probability = 1 . 2: for i = 1 : # episodes do 3: Initialize game and get start state description s 4: while not terminal do 5: φ s = f θ ( s ) 6: W ith probability , sample a random action a , otherwise choose argmax a u α ( φ s , a ) · w 7: Execute a and obtain next state s 0 and rew ard R ( s 0 ) from en vironment 8: Store transition ( s, a, R ( s 0 ) , s 0 ) in D 9: Randomly sample mini-batches from D 10: Perform gradient descent on the loss L r ( w , θ ) + L a ( ˜ θ , θ ) with respect to w , θ and ˜ θ . 11: Fix ( θ , ˜ θ , w ) and perform gradient descent on L m ( α, θ ) with respect to α . 12: s ← s 0 13: end while 14: Anneal exploration v ariable 15: end for state trajectories [ 34 ] and the tab ular SR [ 35 ], we use the learned SR to generate plausible subgoal candidates. Giv en a random policy π r ( = 1 ), we train the DSR until conv ergence and collect the SR for a large number of states T = { m s 1 ,a 1 , m s 2 ,a 2 , ..., m s n ,a n } . Follo wing [ 32 , 34 ], we generate an affinity matrix W giv en T , by applying a radial basis function (with Euclidean distance metric) for each pairwise entry ( m s i ,a i , m s j ,a j ) in T (to generate w ij ). Let D be a diagonal matrix with D ( i, i ) = P j w ij . Then as per [ 32 ], the second largest eigen v alue of the matrix D − 1 ( D − W ) gi ves an approximation of the minimum normalized cut value of the partition of T . The states that lie on the end-points of the cut are plausible subgoal candidates, as they pro vide a path between a community of state groups. Gi ven randomly sampled T from π r , we can collect statistics of ho w many times a particular state lies along the cut. W e pick the top- k states as the subgoals. Our experiments indicate that it is possible to extract useful subgoals from the DSR. 5 Experiments In this section, we demonstrate the properties of our approach on MazeBase [ 37 ], a grid-world en vironment, and the Doom game engine [ 13 ]. In both en vironments, observations are presented as raw pix els to the agent. In the first experiment we show that our approach is comparable to DQN in two goal-reaching tasks. Next, we in vestigate the ef fect of modifying the distal reward on the initial Q-value. Finally , using normalized-cuts, we identify subgoals gi ven the successor representations in the two en vironments. 5.1 Goal-directed Behavior Solving a maze in MazeBase W e learn the optimal policy in the maze shown in Figure 2 using the DSR and compare its performance to the DQN [ 22 ]. The cost of living or moving ov er water blocks is -0.5 and the reward v alue is 1. For this experiment, we set the discount rate to 0.99 and the learning rate to 2 . 5 · 10 − 4 . W e anneal the from 1 to 0.1 ov er 20k steps; furthermore, for training the rew ard branch, we anneal the number of samples that we use, from 4000 to 1 by a factor of 0.5 after each training episode. For all experiments, we prioritize the rew ard training by keeping a database of non-zero rew ards and sampling randomly from the replay buf fer with a 0.8 probability and 0.2 from the database. Figure 3 sho ws the average trajectory (o ver 5 runs) of the re wards obtained ov er 100k episodes. As the plot suggests, DSR performs on par with DQN. Finding a goal in a 3D en vironment W e created a map with 4 rooms using the V iZDoom plat- form [ 13 ]. The map is sho wn in Figure 2. W e share the same network architecture as in the case of MazeBase. The agent is spa wned inside a room, and can explore an y of the other three rooms. The agent gets a per -step penalty of -0.01 and a positiv e rew ard of 1.0 after collecting an item from one 5 Figure 2: En vironments : (left) MazeBase [ 37 ] map where the agent starts at an arbitrary location and needs to get to the goal state. The agent gets a penalty of -0.5 per-step, -1 to step on the water -block (blue) and +1 for reaching the goal state. The model observes raw pixel images during learning. (center) A Doom map using the V izDoom engine [ 13 ] where the agent starts in a room and has to get to another room to collect ammo (per -step penalty = -0.01, re ward for reaching goal = +1). (right) Sample screen-shots of the agent exploring the 3D maze. 0 200 400 600 800 S t e p s ( × 1 0 0 0 ) 350 300 250 200 150 100 50 0 Reward DQN DSR 0 20 40 60 80 100 120 140 160 S t e p s ( × 1 0 0 0 ) 40 20 0 20 40 60 80 Reward DQN DSR Figure 3: A verage trajectory of the rew ard (left) ov er 100k steps for the grid-world maze. (right) ov er 180k steps for the Doom map over multiple runs. of the room (highlighted in r ed in Figure2). As sho wn in Figure3, the agent is able to successfully navigate the en vironment to obtain the re ward, and is competiti ve with DQN. Figure 4: Changing the value of the distal r eward: W e train the model to learn the optimal policy on the maze shown in Figure 2. After conv ergence, we change the value of the distal rew ard and update the Q-value for the optimal action at the origin (bottom-left corner of the maze). In order for the value function to con v erge again, the model only needs to update the linear weights w giv en the new e xternal rew ards. 5.2 V alue function sensitivity to distal r eward changes The decomposition of v alue function into SR and immediate reward prediction allo ws DSR to rapidly adapt to changes in the re ward function. In order to probe this, we performed experiments to measure 6 the adaptability of the value function to distal re ward changes. Giv en the grid-world map in Figure2, we can train the agent to solve the goal specified in the map as highlighted in section 5.1. W ithout changing the goal location, we can change the reward scalar v alue upon reaching the goal from 1.0 to 3.0. Our h ypothesis is that due to the SR-based v alue decomposition, our v alue estimate will con ver ge to this change by just updating the rew ard weights w (SR remains same). As shown in Figure 4, we confirm that the DSR is able to quickly adapt to the new v alue function by just updating w . 5.3 Extracting subgoals from the DSR Follo wing section 4, we can also extract subgoals from the SR. W e collect T by running a ran- dom policy on both MazeBase and V izDoom. During learning, we only update SR ( u α ) and the reconstruction branch ( g ˜ θ ), as the immediate rew ard at any state is zero (due to random policy). As sho wn in Figures 5 and 6, our subgoal extraction scheme is able to capture useful subgoals and clusters the environment into reasonable segments. Such a scheme can be ran periodically within a hierarchical reinforcement learning frame work to aid e xploration. One inherent limitation of this approach is that due to the random policy , the subgoal candidates are often quite noisy . Future work should address this limitation and provide statistically rob ust ways to extract plausible candidates. Additionally , the subgoal extraction algorithm should be non-parametric to handle flexible number of subgoals. (a) (b) Figure 5: Subgoal extraction on grid-world: Giv en a random policy , we train DSR until conv er- gence and collect a large number of sample transitions and their corresponding successor representa- tions as described in section 4. W e apply a normalized cut-based algorithm on the SRs to obtain a partition of the en vironment as well as the bottleneck states (which correspond to goals) (a) Subgoals are states which separate different partitions of the environments under the normalized-cut algorithm. Our approach is able to find reasonable subgoal candidates. (b) Partitions of the en vironment reflect latent structure in the en vironment. 6 Conclusion W e presented the DSR, a novel deep reinforcement learning frame work to learn goal-directed beha vior giv en raw sensory observ ations. The DSR estimates the v alue function by taking the inner product between the SR and immediate reward predictions. This factorization of the v alue function gives rise to se veral appealing properties ov er existing deep reinforcement learning methods—namely increased sensitivity of the value function to distal re ward changes and the possibility of e xtracting subgoals from the SR under a random policy . For future work, we plan to combine the DSR with hierarchical reinforcement learning. Learning goal- directed behavior with sparse rew ards is a fundamental challenge for existing reinforcement learning algorithms. The DSR can enable ef ficient exploration by periodically e xtracting subgoals, learning policies to satisfy these intrinsic goals (skills), and subsequently learning hierarchical policy over these subgoals in an options frame work [ 15 , 28 , 39 ]. One of the major issues with the DSR is learning discriminativ e features. In order to scale up our approach to more expressiv e en vironments, it will be crucial to combine various deep generati ve and self-supervised models [ 6 , 9 , 10 , 12 , 16 , 25 , 27 , 40 ] 7 Figure 6: Subgoal extraction on the Doom map The subgoals are e xtracted using the normalized cut-based algorithm on the SR. The SR samples are collected based on a random polic y . The subgoals mostly correspond to the rooms’ entrances in the common area between the rooms. Due to random policy , we sometimes observe high v ariance in the subgoal quality . Future work should address robust statistical techniques to obtain subgoals, as well as non-parametric approaches to obtaining flexible number of subgoals. with our approach. In addition to subgoals, using DSR for extracting other intrinsic motiv ation measures such as improvements to the predictive world model [ 30 ] or mutual information [ 23 ] is worth pursuing. References [1] Andrew G Barto and Sridhar Mahade van. Recent advances in hierarchical reinforcement learning. Discrete Event Dynamic Systems , 13(4):341–379, 2003. [2] Matthew Botvinick and Ari W einstein. Model-based hierarchical reinforcement learning and human action control. Philosophical T ransactions of the Royal Society of London B: Biological Sciences , 369(1655):20130480, 2014. [3] Dane S Corneil and W ulfram Gerstner . Attractor network dynamics enable preplay and rapid path planning in maze–like en vironments. In Advances in Neural Information Pr ocessing Systems , pages 1675–1683, 2015. [4] Nathaniel D Daw and Peter Dayan. The algorithmic anatomy of model-based ev aluation. Philosophical T ransactions of the Royal Society of London B: Biolo gical Sciences , 369(1655):20130478, 2014. [5] Peter Dayan. Improving generalization for temporal difference learning: The successor representation. Neural Computation , 5(4):613–624, 1993. [6] SM Eslami, Nicolas Heess, Theophane W eber , Y uv al T assa, Koray Ka vukcuoglu, and Geoffrey E Hinton. Attend, infer , repeat: Fast scene understanding with generativ e models. arXiv preprint , 2016. [7] Samuel J Gershman, Christopher D Moore, Michael T T odd, Kenneth A Norman, and Per B Sederber g. The successor representation and temporal context. Neural Computation , 24(6):1553–1568, 2012. [8] Sandeep Goel and Manfred Huber . Subgoal disco very for hierarchical reinforcement learning using learned policies. In FLAIRS conference , pages 346–350, 2003. [9] Klaus Greff , Rupesh Kumar Sriv astav a, and Jürgen Schmidhuber . Binding via reconstruction clustering. arXiv pr eprint arXiv:1511.06418 , 2015. [10] Karol Gregor , Ivo Danihelka, Alex Graves, and Daan Wierstra. Draw: A recurrent neural network for image generation. arXiv preprint , 2015. [11] Marc W Howard and Michael J Kahana. A distributed representation of temporal context. J ournal of Mathematical Psychology , 46(3):269–299, 2002. [12] Jonathan Huang and Ke vin Murphy . Ef ficient inference in occlusion-aware generati ve models of images. arXiv pr eprint arXiv:1511.06362 , 2015. 8 [13] Michał Kempka, Marek W ydmuch, Grzegorz Runc, Jakub T oczek, and W ojciech Ja ´ sko wski. V izdoom: A doom-based ai research platform for visual reinforcement learning. arXiv preprint , 2016. [14] George K onidaris and Andre S Barreto. Skill discovery in continuous reinforcement learning domains using skill chaining. In Advances in Neural Information Pr ocessing Systems , pages 1015–1023, 2009. [15] T ejas D Kulkarni, Karthik R Narasimhan, Ardavan Saeedi, and Joshua B T enenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. arXiv preprint arXiv:1604.06057 , 2016. [16] T ejas D K ulkarni, William F Whitne y , Pushmeet K ohli, and Josh T enenbaum. Deep con volutional in verse graphics network. In Advances in Neural Information Pr ocessing Systems , pages 2530–2538, 2015. [17] Marlos C Machado and Michael Bowling. Learning purposeful behaviour in the absence of re wards. arXiv pr eprint arXiv:1605.07700 , 2016. [18] Shie Mannor , Ishai Menache, Amit Hoze, and Uri Klein. Dynamic abstraction in reinforcement learning via clustering. In Pr oceedings of the twenty-first international confer ence on Machine learning , page 71. A CM, 2004. [19] Amy McGov ern and Andrew G Barto. Automatic discovery of subgoals in reinforcement learning using div erse density . Computer Science Department F aculty Publication Series , page 8, 2001. [20] Ishai Menache, Shie Mannor, and Nahum Shimkin. Q-cut—dynamic discov ery of sub-goals in reinforce- ment learning. In Machine Learning: ECML 2002 , pages 295–306. Springer , 2002. [21] V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Grav es, T imothy P Lillicrap, Tim Harley , David Silver , and K oray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. arXiv pr eprint arXiv:1602.01783 , 2016. [22] V olodymyr Mnih, K oray Kavukcuoglu, David Silver , Andrei A Rusu, Joel V eness, Marc G Bellemare, Alex Gra ves, Martin Riedmiller , Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature , 518(7540):529–533, 2015. [23] Shakir Mohamed and Danilo Jimenez Rezende. V ariational information maximisation for intrinsically motiv ated reinforcement learning. In Advances in Neur al Information Pr ocessing Systems , pages 2116– 2124, 2015. [24] Arun Nair , Prav een Srinivasan, Sam Blackwell, Cagdas Alcicek, Rory Fearon, Alessandro De Maria, V edavyas P anneershelvam, Mustafa Sule yman, Charles Beattie, Stig Petersen, et al. Massively parallel methods for deep reinforcement learning. arXiv preprint , 2015. [25] Mehdi Noroozi and Paolo Fa varo. Unsupervised learning of visual representations by solving jigsaw puzzles. arXiv preprint , 2016. [26] Ian Osband, Charles Blundell, Ale xander Pritzel, and Benjamin V an Roy . Deep exploration via bootstrapped dqn. arXiv preprint , 2016. [27] Danilo Jimenez Rezende, Shakir Mohamed, Iv o Danihelka, Karol Gregor , and Daan W ierstra. One-shot generalization in deep generativ e models. arXiv preprint , 2016. [28] T om Schaul, Daniel Horgan, Karol Gregor , and David Silv er . Universal v alue function approximators. In Pr oceedings of the 32nd International Confer ence on Mac hine Learning (ICML-15) , pages 1312–1320, 2015. [29] T om Schaul, John Quan, Ioannis Antonoglou, and David Silver . Prioritized experience replay . arXiv pr eprint arXiv:1511.05952 , 2015. [30] Jürgen Schmidhuber . Formal theory of creati vity , fun, and intrinsic motiv ation (1990–2010). Autonomous Mental Development, IEEE T r ansactions on , 2(3):230–247, 2010. [31] Nicol N Schraudolph, Peter Dayan, and T errence J Sejnowski. T emporal difference learning of position ev aluation in the game of go. Advances in Neural Information Pr ocessing Systems , pages 817–817, 1994. [32] Jianbo Shi and Jitendra Malik. Normalized cuts and image segmentation. P attern Analysis and Machine Intelligence, IEEE T ransactions on , 22(8):888–905, 2000. 9 [33] David Silv er , Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, Geor ge V an Den Driessche, Julian Schrittwieser , Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Natur e , 529(7587):484–489, 2016. [34] Özgür ¸ Sim ¸ sek, Alicia P W olfe, and Andrew G Barto. Identifying useful subgoals in reinforcement learning by local graph partitioning. In Proceedings of the 22nd international conference on Machine learning , pages 816–823. A CM, 2005. [35] Kimberly L Stachenfeld, Matthew Botvinick, and Samuel J Gershman. Design principles of the hip- pocampal cognitiv e map. In Advances in neural information pr ocessing systems , pages 2528–2536, 2014. [36] Bradly C Stadie, Ser gey Levine, and Pieter Abbeel. Incentivizing exploration in reinforcement learning with deep predictiv e models. arXiv preprint , 2015. [37] Sainbayar Sukhbaatar , Arthur Szlam, Gabriel Synnaeve, Soumith Chintala, and Rob Fergus. Mazebase: A sandbox for learning from games. arXiv pr eprint arXiv:1511.07401 , 2015. [38] Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence , 112(1):181–211, 1999. [39] Csaba Szepesvari, Richard S Sutton, Joseph Modayil, Shalabh Bhatnag ar, et al. Universal option models. In Advances in Neural Information Pr ocessing Systems , pages 990–998, 2014. [40] W illiam F Whitney , Michael Chang, T ejas Kulkarni, and Joshua B T enenbaum. Understanding visual concepts with continuation learning. arXiv preprint , 2016. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment