Generalized Measures for the Evaluation of Community Detection Methods
Community detection can be considered as a variant of cluster analysis applied to complex networks. For this reason, all existing studies have been using tools derived from this field when evaluating community detection algorithms. However, those are…
Authors: *제공된 정보에 저자 명단이 포함되어 있지 않습니다.*
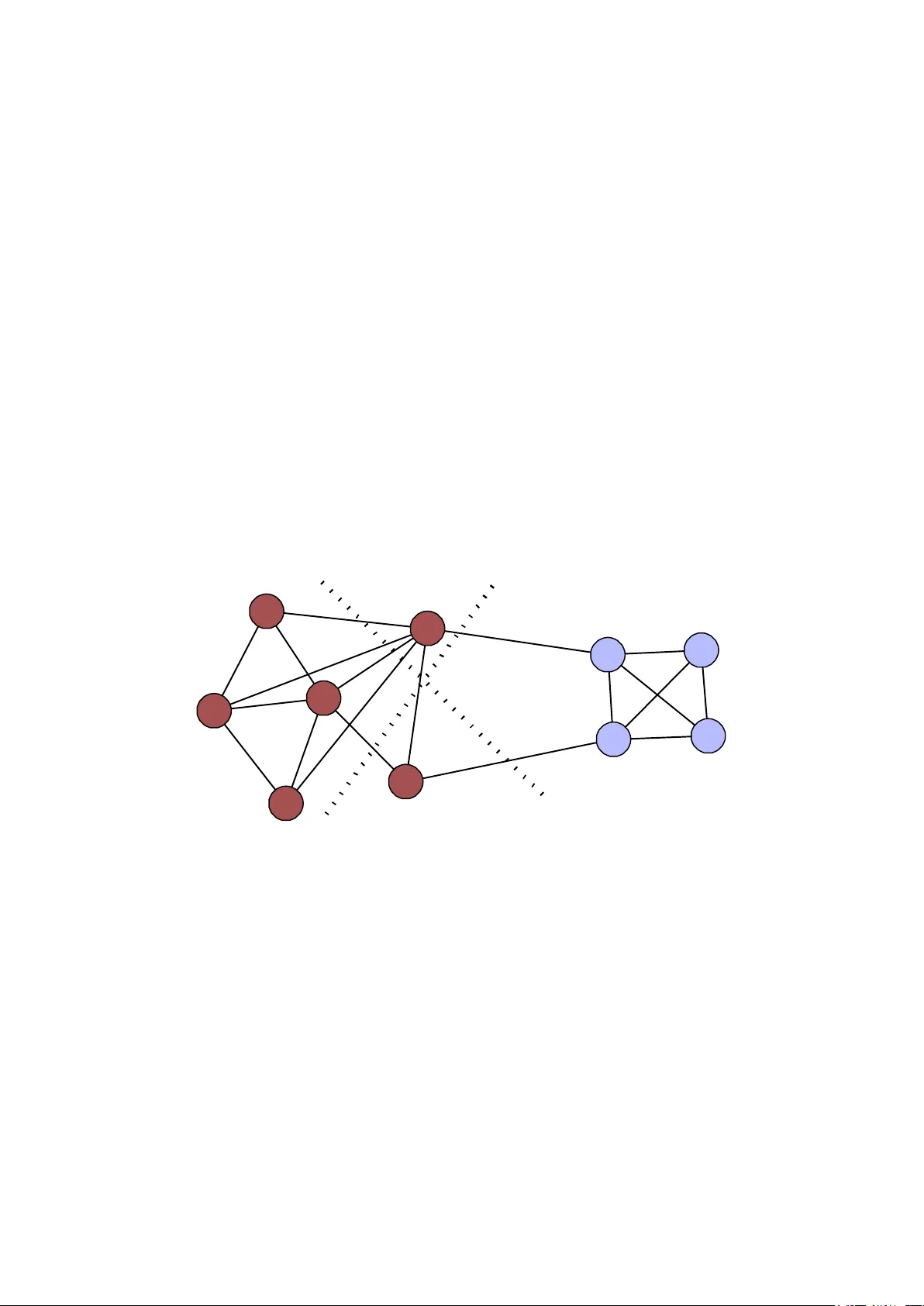
Generalized Mea sures for the E valuation of Com munity Detection Method s Vincent Labatut Galatasaray University, Computer Science Department , I stanbul, Turkey v l a b at ut @ g s u. ed u . tr 20/3/2013 Abstract. Community detection can be considered as a variant of cluster analysis applied to complex netwo rks. For this reason, all existing studies have been usin g tools derived from th is field when evaluating co mmunity detection algorithms. Ho wever, those are not completely relevant in the con text of network analysis, because they ignore an essenti al part of the available information: the netw o rk structure. Therefore, they can lead to incorrect interpretations. In this a rticle, we review these measures, and illustrate this limitation. We propose a modification to so lve this problem, and apply it to the three m o st w idespread m e asures: purity , Rand index and normalized mutual information (NMI) . We th en perform an experimental evaluation o n arti ficially generated networks with realistic communit y structure. We assess the relevance of the modified measures b y co mparison with their trad itional counterparts, and also relatively to the topological properties of the comm u nity structures . On these data, the modified NMI turns out to provide the most relevant results. Keywords: Complex Networks, Community Detection, Evaluation Measure , Cluster Analysis, Purity, Adjusted Rand Index, Norm alized Mutual Information. 1 Introduction Community detection is a par t of the complex net works anal ysis field. It consists in characterizing the str ucture of suc h a network at the mesoscopic level, i.e. when considering neither the node (microscopic le vel) nor the wh ole network (macroscopic level), but rather an intermediar y structure, called co mmunity. More co ncretely, o ne wants to brea k the network d own to a set o f lo osely interc onnected subgraphs, each one corresponding to a community. The prob lem is difficult to formalize, in the sense this task can be defined i n m any dif ferent ways. Ho wever, most authors agree on an intuitive descriptio n, which is to obtain co mmunities whose nodes ar e more densel y interconnected, co mpared to the rest of the network [1 ]. A document presenti ng a new co mmunit y detection method generally ha s the following structure. First, the authors describe their al gorithm in detai ls. Second, the y select some test data, which can be rea l-world and/or artificiall y generated networks, Edit 13/05/2016: the R source code for the measures described in this article is now publicly available online on GitHub: https://github.com/CompNet/TopoMeasures 2 Vincent Labatut and app ly both their algorithm a nd other existing too ls to these d ata. Third, th ey process so me measure to quantify the p erformances of t he considered co mmunity detection tools. T he resulting values are then used to compar e these algorithms . T he newly p resented method generall y happ ens to overco me t he existing ones o n one or several aspects (precisio n, speed, robustness, etc.). This pro cedure raises several important methodological issues. When the tes t is performed on real- world data, acco rding to which criteria should the networks be selected? T hose networks display h eterogeneous top ological properties [2 ], some o f which can introduce bias when comparing community detection methods. For example, a network with a low transitivity (a. k.a. cluster ing coef ficient) will penalize clique-percolation methods lo oking f or trian gles. Moreo ver, in most case the ac tual community str ucture o f real -world networks is not known with certai nty: how r eliable are the p erformance results obtain ed on s uch data? If the test is perfor med on so me artificial data, then the select ion of an appropriate generative model i s a cause for concern. The results o f the evaluation are suppo sed to be gener al enough to hold when the algorith ms are ap plied to some r eal-world data. B ut for this to be true, the generative model must pr oduce realistic networks, which is difficult to guara ntee [3] . Despite t he impor tance of these issues, in this artic le we put them apar t to foc us on another i mportant methodological point: t he too l used to measure the p erformance of the algorithms. In the literature, it always takes the form of a metric associating a numerical score to the co mmunity structure e stimated by an algorith m for a given network. It is processed b y comparing this estimated structure to the actual one, which is supposed ly kno wn for the c onsidered network (either because it was identified, for a real-world network, or b y construction for an arti ficial one) . In the case of mutually exclusive communities, which interests us in this article, each co mmunity structure can b e co nsidered as a partition of the node set. Therefor e, the standard ap proach to compare t wo co mmunity structures co nsists in quantifying the similarity between the two co rresponding partitions. For this purpose, the most popular measures in the context of co mmunity detection are the P urity [4 ], the Adj usted Rand Index [5 ] and the Normalized Mutual I nformation [6 ]. However, as shown in a recent study [7] , th i s approach h as some limitations. Indeed, it is po ssible for t wo distinct co mmunity structure s to be very close in terms of partition, t herefore o btaini ng roughl y the sa me sco re, and at the sa me ti me to ha ve sensibly different to pological pro perties (embeddedness, av erage distance, etc. ). This, of co urse, is not desira ble, si nce these pr operties s hould be co nsidered to discriminate the co mmunity str uctures. One can trace b ack this proble m to the cluster ana lysis origin o f the measures. T hey co mpletely i gnore what makes the specificit y of community detectio n: the structure of t he net work. In o ther words, the per formance assessment is realized while i gnoring a part of the a vailable relevant infor mation ( the topological information). In t his article, we prop ose to modif y certai n e xisting measures in or der to take the topological information into account. Our goal is to design a tool allowing a m or e relevant discri mination of the community str uctures. In t he next section, we review the main measures used in the co mmunity detect ion literature to e valuate t he performances of t his type of algorithms. In section 3, we describe in d etails their Generalized Measures for the Evaluation of Comm unity Detection Methods 3 limitation when ap plied to the comparison of communit y structures. W e then prop ose our modifications i n section 4, and evaluate them in section 5. We conclude with a discussion of our work and its possible extensions. 2 Traditional Approach Cluster an alysis , or unsupervised classification, is a part of t he data mining field. It consists i n p artitioning a se t of objects, in o rder to identify ho mogeneous groups . Each o bject is described individually through a ve ctor of attributes , and the proced ure is conducted b y comparing objects thanks to these attrib utes . Co mmunity detectio n is obviously a very similar task, with o ne d ifference t hough. When co nsidering complex networks, t he objec ts of inter est are nodes , a nd the infor mation used to per form the partition is the network str ucture . In ot her words, instea d of considering so me individual information (attr ibutes) like for cluster analysis , we take advantage of a relational one (links) . Ho wever, the result is the sa me i n both ca ses: a p artition o f the set o f ob jects, which is called commu nity structure in the context of co mplex network analysis. It is therefore not surp rising to see authors developi ng co mmunity detection tools use cluster analysis methods to assess th e per formance o f their method. For some o f them, the bo rrowing is explic it [8], whereas others develop ed their own to ols, which happen to be similar to alread y ex isting ones [9 , 10 ] . In cl uster anal ysis, this assessment is perfor med thanks to a measure allowin g to ob tain a score repr esenting the classifier performance. When a reference partition is available, this score represents the similarity b etween this actual p artition and the o ne estimated by t he considered classifier; a nd one refers to t his measure as an extern al evalua tion criterion [4 ]. A number o f such measures e xist, and in the domain o f classi fication, the deb ate regarding which one is the mos t appr opriate has been star ted a long time ago, and is s till going o n [ 11 ]: this shows how important this methodological p oint i s. Indeed, w hat is the interest in evaluating a tool if the eval uation method is not valid? A lot of the measures u sed in cluster anal ysis have been ap plied to communit y detection. Ho wever, t hree of them stand o ut i n ter ms of popularit y: P urity [4] , Adjusted Rand Index [5 ] and Normalized Mutual Infor mation [6 ]. Incidentally, each of them repr esents one of t he three m ain f amilies o f measures d esigned as e xternal evaluation criteria. I n the first , each object is con sidered individually, whereas in the second the assessment is performed on pairs of objects. The third family relie s o n an information theor y approac h. For these two reaso ns, i n this section we focus on these three measures. In the rest o f this article, we w il l note and t wo partitions of the same set , where and are the parts ( and ) . To d enote the cardinalities, we use for the total number o f eleme nts in the partitioned set, and for the intersection of t wo par ts. We also note and the par t sizes . When need ed, elements will b e represented by the variables and . 4 Vincent Labatut 2.1 Purity The P ur ity measure [4 ] is histo rically the first one used in t he co ntext of co mmunity detection, since i t was used by Gir van and Newman in thei r seminal article [9], under the na me fraction o f co rrectly classified vertices . More generall y, the Purity app ears in the literat ure under so many different names that it woul d be difficult to list t hem exhaustively. The p ur it y of a part relatively to the other partition is expressed in the following way: (1) In other words, we first id entify the part of whose intersection with is the largest , and t hen calc ulate t he proportion of e lements in th is inter section a mounts to . The larger the intersect ion and t he larger the pur ity, i.e. the lar ger the correspondence between the two con sidered parts. The total purity of partition relatively to par tition is ob tained b y s umming the p urity of each , weighted b y it s prevalence in the consider ed set: (2) The upp er bound is , it co rresponds to a per fect match bet ween the par titions. T he lower bound is and indicates the op posite. It is important to notice t he p ur it y is not a sy mmetric measure : processi ng t he p urity o f relativel y to amounts to considering the parts o f majority in each par t of . Therefore, in general, there is no reason to suppose and are equal. From the community detection point of view, we can therefore use two d istinct measures, dep ending on whether w e calcu late the p urity of the estimated co mmunities relatively to the actua l ones, or the opposite. In cluster analysis, t he first version i s generally used, and called sim p ly Purity , whereas the second version is t he I nverse Purity [ 12 ]. In this document, we will use these ter ms to distinguish both versio ns. It is difficult to determine which one o f the m was ac tually used in existing community detectio n works. I ndeed, in their ar ticle, Girva n and Ne wman give a ver y succinct descriptio n of the measure they pro cess [9 ]. A su bsequent article seems to indicate it was the inverse purit y [ 13 ] (note 19), which Ne wman direc tly con firmed to us. Many later works conducted b y other authors used measures bearing the same name a nd/or directly referrin g to this article. However, due to the initial imprecision, it is very likel y t hey used the purity i n p lace of t he i nverse purit y. For example, i n [8] (p.4), Danon et al . m a ke a c omment on Girvan and Ne wman’s measure , explain ing how it can be biased b y the n umber a nd sizes of co mmunities. However, their remar k is actually val id only for the purity , and not for the inverse version they ar e supposed to discuss. This bias is an importa nt lim itation o f both measures, and was also identified b y the cluster analysis co mmunity. P urity tends to favor algorithms identi fying nu merous small co mmunities . In t he most extre me case, if t he algorithm id entifies Generalized Measures for the Evaluation of Comm unity Detection Methods 5 communities containing a single node each, one gets a maximal p urity, since each estimated co mmunity is per fectly pure . On the contrary, th e inverse p urity favors algorithms detecti ng few lar ge co mmunities. This t ime, the most extreme ca se occur s when the algorithm puts all the nodes in the same co mmunity . T here again, one gets a maximal purity, because each actual community is per fectly pure: all the nod es it contains b elong to the sa me (unique) estimated community. T o so lve this p roblem, Newman intro duced an ad ditional constraint [ 13 ]: w he n an estim ated community is majority i n several act ual com munities, all the concerned nodes ar e co nsidered as misclassified. The solution ge nerally ad opted in cl uster analysis rat her co nsists in processing the F-Measure , which is the harmonic mean of both versions of the purity [ 12 ]: (3) The obtained measure is symmetric, and t his co mbination i s supposed to solve the previously mentioned bias. This ap proach penalize s in a similar way t he u nder - and over-estimation of the nu mber of communities. For this re ason, we w ill later work with this adjustment, and not the one pr oposed by Newman. 2.2 Adjusted Rand In dex The Rand Index [ 14 ] is b ased on a different approach. Instead of direc tly considering how p arts o verlap, like the p urity and other related measures, it focuses on pair wise agreement. For each possible p air of elements in t he consider ed set, the Rand Index evaluates how similarly the two partitions treat them. One ca n d istinguish 4 different cases . Let ( resp. ) be the number of pairs in whic h nod es belong to the same part (resp. to different parts ) in both partitions . Let (resp. ) b e the number of p airs in which nodes belo ng to t he same part in the first (resp. seco nd ) partition, whereas they belong to different parts i n the second ( resp. first) one . Formall y, ca n be obtained by counting the number of pair s belonging to part intersec tions : (4) On the contrary, and co rrespond to pairs whose elements are loca ted in different part intersections. For , this amounts to counting the nu mber of pairs belonging to part which were not alread y counted i n ; and is defi ned symmetrically: (5) (6) 6 Vincent Labatut Finally, can be o btained by subtracting , and to the total number of pairs. After simplification, we get: (7) Values and rep resent p airs for which b oth partitions a gree, in the se nse t hey both consider the nodes should be put toget her, or shou ld be separ at ed . On the contrary , and correspo nd to the t w o po ssible disagreeme nts: i n one par tition the nodes are put together, whereas they belo ng to distinct parts in the other. The index is obtained by processing the pr oportion of pairs o n which both partitio ns agree: (8) Like for the p urity, t he upper bound is , wh ich corresponds to a perfect match between the par titions, and the lower bo und is , which indicates the opp osite. But unlike the purity, the Rand Index is sym me tric : its value d oes not change if one switch es the partitions. In the domain of community detectio n, the chance-corr ected versio n o f this measure, called Adjusted Rand I ndex ( ARI) [5 ], seems to be preferred. It is known to be less sensiti ve to the number of parts [ 15 ]. The chance correction is based on the general formula defined for any measure [ 16 ]: (9) Where is the cha nce-correc ted measure, is the maximal value can reach, and is the value expected for some null model. Hubert & Arabie chose a model in which the partitions ar e generated rando mly with the co nstraint of having fixed number o f parts ( and ) and part sizes ( and ). Under this assumption, t he expected value for the number of pairs in a p art intersection is [5]: ( 10 ) Equation ( 10 ) can be used to process the expected value s o f and , which in turn allows processing . By replaci ng in equation (9) and a fter some simplificatio ns, we get the final adj usted Rand index [5 ]: ( 11 ) Like the Rand index, this measure is s ymmetric. Its upper bound is , meaning both p artitions are exactl y similar. Because it is chance -corrected , a value equal or below r epresents t he fact the si milarity b etween and is equal or less than what is expected from t wo random partitions. Generalized Measures for the Evaluation of Comm unity Detection Methods 7 2.3 Normalized M utual Infor m a tion In clu ster anal ysis, the use o f the Norma lized Mutual Information ( NMI) is much more rece nt t han for the prev ious measures [6 ] . I t was introduced in the communit y detection do main b y Danon et al . [8] , and since then i t has bee n used in ma ny works . In t his measures, b oth par titions and are co nsidered as dis crete rando m variables, whose definition domains ar e and , respectively. T heir joint probability distribution is obtained by co nsidering the freq uencies measured on the available data: ( 12 ) The value represents the prob ability, for a rando mly dra wn elemen t, to belong simultaneously to parts and . T he marginal di stributions are obtained b y summing over the jo int frequencies: ( 13 ) ( 14 ) The value (resp. ) represents the probab ility , for a rando mly drawn ele ment, to belong to part (resp. ). Fro m t here, one ca n pro cess the mutual in formation of these variables, which measures the p robabilistic d epen de n ce between them [ 17 ]: ( 15 ) The mutual in formation corresponds to the quantity o f infor mation shared by the variables. Unlike the purit y, b ut like t he Rand I ndex, it is symmetric. Its lower bound is , representing the independ ence of the variab les (they shar e no information). The upper b ound correspo nds to a co mplete r edundancy, however this value i s not fixed. Several normalizations exist to solve this p roblem . T he app roach used in [ 18 ], and later by Danon et al . and the rest of the community detectio n field, consists in dividing the mutual information by the ar ithmetic mean of the entropies: , where and . The final expression of t his measure is t herefore: ( 16 ) This normalization retains the lo wer bound and symmetr y of the measure, and its upper bound b ecomes . 8 Vincent Labatut 3 Limitations of the Existing Measures By definition, all the m ea sures coming from cluster analysis, including the t hree presented in the p revious section, consider a co mmunity structure onl y a s a p artition of the nod e set . In the context of co mmunity detectio n, this can be viewed as a limitation, b ecause all classification erro rs do not necessarily have the same importance. Let us co nsider the example presented in Fig. 1 , which displa ys a network containing two communities, each one repr esented b y a d ifferent colo r. T his community structure is not ed , and the red ( i.e. left) and blue (i.e . r ight) communities ar e noted and , respectivel y. We p ropose two different estimatio ns and of this reference com munity struct ure. For bo th of them, the left and right communities are numbered and , respectively. Each one o f the se esti mated community str uctures i ncludes a classification erro r: one node from t he left community i s incorr ectly placed in the right one . For , this misclassificatio n concerns node , whereas for it is node . Fig. 1. Example illustrating the limitation of purely partition -based measures. Colo rs correspond to the actual communities, whereas lines labeled and represent two different (incorrect) estimations of this comm unit y structure. Let us app ly the me asures p resented in the previous sectio n, in ord er to compare to . We ob tain the score for both the p urity and inverse purity. Conseq uently, the F-Measure, which is their mean, reaches t he same value. For the adjusted Rand index, we get , and for the NMI. Now, if we process t he same mea sures for the other partition , we get e xactly the sa me values. Indeed , from a p artition perspective, nothing allows to distin guish nodes from node , so misclassifying the former o r the latter leads to the sa me e valuation. In other word s, t hose measures consid er the errors present in and to b e exactly similar. 7 8 9 10 1 2 3 4 5 6 A B Generalized Measures for the Evaluation of Comm unity Detection Methods 9 Yet, intuitive ly, those errors do not seem equivale nt at all. Indeed, node is much more integrated in its actual c ommunity t han node . Its misclassification in partition is therefore a more serious error than that o f node in p artition . I n consequence, the score associated to should be higher. To check more obj ectively t his i ntuition, we can con sider the modularity [ 19 ] o f these partitions. This meas ure quantifies the quality of a community structure in a blind way, i.e. w it hout the us e of a reference. In cluster an alysis ter ms, it w o uld b e called an internal ev aluation criterion (cf . the introduction of section 2 ). For this matter, it compares t he prop ortion of links loca ted inside the co mmunities with t he expectation o f the same value for a rando m model generating similar networks (sa me size and degree distributio n). T he modularity ha s been used as a n obj ective functio n by numerous co mmunity detection al gorithms [1 ]. In our ca se, the reference reaches a modularity of , whereas and obtain the sco res and , respectively. More than their m agnitude, what is relevant here is t he relative differences betwee n those v alues: clearly leads to a lower score than , w hic h confirms our intuition. This observation, per formed on our very simple e xample, is co rroborated on more realistic network s by the re cent study b y Orman et al . [7] . Its authors co mpare community struct ures by co nsidering trad itional measures (such as those presented in the previo us sectio n), but also the d istribution o f several measures allo wing to characterize them topological ly (community size, transitivity, d ensity, etc.) . One of their conclusio ns i s that t wo community struc tures can at the sa me time rea ch very similar scores, and be topolo gically very differen t. There are two i mportant consequences to this result . First, an estimated co mmunity structure can reach a high score, without necessaril y being topo logically similar to the actual co mmunity structure . Second, two es timated partitions can reach appro ximately the same score without having a utomatically the sa me topo logical properties. B ecause of these limitations, we can state tradi tional measures are not perfectl y ad apted neither to the evaluation of a co mmunity detec tion algorithm i n absolute terms, nor to the comparison of several such algorithms. 4 Propos ed Modifications Of course, t he proble m highlighted in t he previous sec tion co mes from the fact t he traditional m eas ures consider a co mmunity struct ure is si mply a partition, and therefore ignore a part o f the available i nformation: the network topolo gy . In o rder to make a more reliable evaluation, Or man et al . pr opose to jointly use traditional measures and various top ological proper ties [7] . However, the y also ackno wledge this makes the evaluation p rocess more co mplicated , due to the multiplicity of values to take into account. The solutio n we p ropose here, on the contrar y, co nsists i n retaini ng a single value , by modifying traditional measures so that they take the network topolog y into account. T his approach allows benefiting from the conci sion o f a u nique score to measure and co mpare community detection algorithms. 10 Vincent Labatut In this section, eac h o ne of the firs t t hree s ubsections presents the propo sed modifications for one of the three measures describ ed in section 2. All o f those modifications are based o n the definition o f an in di vidual weight, reflecti ng the relative i mportance of ea ch node. W e chose to discuss it separately, in the la st subsection, because the nature o f this weight constitutes a separ ate point, independent from the general form of the modified measures . 4.1 Modified Purity Compared to the measures of the two ot her fa mi lies, the purity has the advantage that it can be expressed in order to make app ear the individ ual contribution of ea ch node to the to tal sco re . For this p urpose, w e fir st d efine the notio n of purity of a node for a partition relativel y to another partition : (17) Where and ; and is the Kronecker delta , i.e. if , and otherwise . T he function is there fore binary: if the p art o f contai ning is majority in t hat of also containing , and otherwise . A s an exa mple, consider in the case of F ig. 1 . I n , node belongs to th e red (left) part , so the second argu ment of the is . In , it belo ngs to t he right par t , whose intersection is larger with than with , so the first argu ment of t he is . Conseq uently, . On the contrar y, if we focus on node instead, we obtain . The purit y of a par t relativel y to a partition can then be calculated b y averaging the purity of its nod es: ( 18 ) The ab ove expressio n is e quivalent to t hat o f equatio n (1), thus it allo ws derivin g the total purit y of p artition r elatively to , as in equatio n (2 ). By developin g th e resulting expression, we get: ( 19 ) One can notice the purity o f each nod e is weighted by a val ue . In o rder to take into account the top ological information, we pro pose to rep lace this unifor m wei ght by a value , wh ich ca n be different for an y node . Its ro le is to penalize more strongly misclassifications co ncerning to pologically important nodes . We then get the modified purity , defined as follo ws: ( 20 ) Where , i.e. the sum of all weights. T his normalization allo ws keeping th e measure b etween et . Finall y, by applying to the sa me principle we de scribed Generalized Measures for the Evaluation of Comm unity Detection Methods 11 in equat ion ( 3) (i.e. taking th e har monic mean of t he p urity and inverse purity) , we obtain a modified F-Measure, which takes the network topology into accou nt, and that we note . 4.2 Modified ARI Because the Rand index is bas ed on p airwise comparisons, it is not possible to i solate the individual effect of each n ode, like w e did for the purity. Ho wever, we can proceed similarly for pairs of nodes. I n t he origina l measure, each pair contributes similarly to the total score. Instead, we propose to distinguish them in terms of topological i mportance. The most direct appro ach co nsists in associati ng a sp ecific weight to each pair o f nodes. For instance, one could co nsider t he geo desic distanc e between the nodes. T he consequence w o uld be to pen alize m o re disagree ments o n p airs of distant n o des. However, there is no reason to think misclassificat ions o n dista nt nodes are more important than on close o nes (or the op posit e). Using nodal weight s li ke for the purity see ms to b e a more app ropriate solution. Since we handle pairs of nodes here, we propo se to use the pro duct of the t wo corresponding nodal weights : . Of course, a ny ot her co mbination could b e used, b ut our goal was to clearl y advantage couples of importa nt nodes. Then for a ny subset of , we define the follo wing quantity: ( 21 ) The b inomial coefficie nts used in the for mulas of the o riginal a nd adj usted Rand indices aim at counting the number o f pairs pr esent in variou s subsets o f the partitions. This amounts to processing in the specific case where all are equal to . In o rder to obtain the modified versions o f these measure s, we simply replace al l binomial coefficient s by our generalized coef ficient , in their respec tive formulas . Therefore, fro m equation ( 11 ) we get the modified version of the ARI, noted : ( 22 ) 4.3 Modified NM I In t he trad itional definitio n o f t he NMI, o ne i mplicitly consider s all nodes have the same probability to be randomly dra wn. This beco mes exp licit if we re write the expression of given in equation ( 12 ) in the following way: ( 23 ) We propose to replace this uni form val ue b y the nod e -specific weight alread y introduced for the p revious measures. As before, it must be nor malized using , in 12 Vincent Labatut order to sum to . W e can consequently define a mod ified jo int probability distribution : ( 24 ) By rep lacing by in equations ( 13 ) and ( 14 ), we obtain and , respectively. We t hen use th ese modified prob ability distributions in the definit ion given i n equation ( 16 ) , in order to get the modified nor malized mutual i nfor mation, noted : ( 25 ) 4.4 Nodal Weights All the modified meas ures we pro posed in this section depend on the d efinition o f an individual weight representing t he relative importance of each n o de in t he considered network. T he question is t herefore now to determine ho w to character ize and qua ntify t his importa nce. Our general idea i s that a misclassificatio n concerni ng a node strongly i ntegrated in to its co mmunity should co unt more tha n for a node located on the community fringe. For this purpo se, we can consider the node degree . This way, we give more weight to co mmunity hubs such as nod e fro m Fig. 1 , and less weight to per ipheral nodes such as node . I n order to get a normalized value, we divide by the maximal degree ob served in the network, leading to the normalized degree : ( 26 ) Where denotes the de gree of node . T his value ranges from (no connec tion at all) to (most connected nod e in the whole net work). However, this app roach can b e criticized o n two po ints. First, it is possible for a high degree node to have its connections distributed over numerous co mmunities, therefore preventing any strong integratio n into an y particular co mmunity. Si nce t he community member ship of th is node see ms rather u ncertain, giving it a large weight appears inappr opriate. Seco nd, using onl y the de gree leads to do wnplaying th e importance of nodes w hose connections are few, b ut entirel y located inside their community. The emb eddedness mea sure [2] allo ws solving both pro blems: ( 27 ) Where is the internal degree of node , i.e. the number o f co nnections it has in its o wn co mmunity. T hus, the embeddedness is the proportion of neighbors located in t he sa me community tha n t he node of interest. It ranges fro m ( no neighbor in the same community) to (all neighbors in t he same community). Generalized Measures for the Evaluation of Comm unity Detection Methods 13 In order to combine the n ormalized degree an d embeddedness, we propo se to multiply t hem. T his way, the more a node po ssesse s both proper ties and the more it is important for us. T he weight i s therefore , which after si mplification leads to the following expr ession: ( 28 ) Note we treated the question of the nodal weight i ndependently fro m the measure modifications f or two reason s. First, this point is co mmon to all three modifications we propo sed, in the se nse eac h of them needs this weight. Second, the sp ecific weight described above is only a p roposal: it ca n be adapted depending o n t he user’s needs. For instance, if t he links o f the considered network are weig hted, one can consider the strength of the nod es instead of their degree. By using a uniform for every node, we obtain the traditional version of the considered measure. T hus, the m odi fications we propo se can be co nsidered as generalization of the traditional measures. Table 1. Values obtained for the community structures displayed in Fig. 1. Measure Traditional Modified Partition and F-Measure (Purity) Adjusted Rand Index Normalized Mutual Information Let us no w co nside r again t he example from Fig. 1 , and p rocess the modified measures for both estimated par titions. T able 1 recapitulates the p revious and newl y calculated values. For all three measures, the scores obtained for partition are lo w er than those o f par tition , w hich is the behavior w e were e xpecting, as e xplained in section 3. 5 Experimental Evaluation The results o btained on the ex ample from Fi g. 1 are obviousl y not s ufficient to assess the relevance of t he modifie d measures. W e therefore app lied them o n a larger dataset . In this section, we first present the experi mental setup we used . T hen, we describe ho w t he p roposed modification affected the individ ual per formance sco res. Finally, we study its e ffect on algorithm ranking . 5.1 Setup We d ecided to use the same data, and to apply the same communit y algorithms t han in [7] for our experi mental validation, for several r easons. First, t h is study by Or man et al . contains observations regarding the to pological properties of both real and 14 Vincent Labatut estimated community structures. The y u sed them to illustrate how co mmunity structures obtaining s imilar traditio nal scores can in f act b e sensibly different, topologically. Thanks to t hem, we will be able to verify if our modified measures behave as expected, i.e. are sensitive t o these differenc es. Moreo ver, they used artificially generated networks, which means the real co mmunity structure s are kno wn with certainty. Fina lly, the gener ative model they selected reach es the highest po ssible level of realism , at lea st according to c urrent knowledge on r eal-world s ystems. This point is important, in ord er to be able to generalize o ur results. The dataset is constituted of net works of nodes each , whose mai n topological prop erties are consist ent with real -world networks st udied in the literature: degree distributio n, transitivity (cl ustering coef ficient) , co mmunity sizes, embeddedness, etc. Eight di fferent co mmunity detection algorithms are applied to these net works, in order to estimate t he co mmunity struct ures. The y are rec ent a nd representative enoug h of the main methods designed to per form community detectio n: Copra [ 20 ], FastGree dy [ 13 ], InfoMap [ 21 ], InfoMod [ 22 ], Louvain [ 23 ] , Mar kovCluster [ 24 ], Oslom [ 25 ] and WalkTr ap [ 26 ] . Since those topics are not the main p oint of this article, we refer the reader to [ 7] for an y further details regardin g the generati ve process and community detec tion algorit hms. W e also insist on t he fact our goal with this work is not to id entify the best algorithm (which, as mentioned i n the introd uction, nece ssitates tackling a number of methodo logical pro blems), but rather to check the relevance of the evaluation tool we p ropo se (i.e. the modified measures). In their w ork, Orman et al . u se a representative set of traditional measures to compare the p artitions e stimated b y the co nsidered algorithms: the fraction o f correctly c l assified nodes (i.e. Newman’s purity, as explained in section 2), the Rand index and its ad justed version, and t he NMI. Fo r t he ad justed Rand index and NMU, we can directl y use their r esults and co mpare them with t hose obtained for the corresponding m odified versio ns d escribed in section 4. However, it is not po ssible to do so for the p urity, since we need to compare our modified m easure to th e F - Measure in o rder to make a relevant e valuation. T herefore, we had to compute the F - Measure ourselves . 5.2 Effect on the Sco res Fig. 2 displa ys the r esults o btained for all the considered measures. T he values for the traditional versions are o n th e left side of the p lot, whereas those for the modified ones are on the right. For ea ch measure, the algorithms a re ordered by decreasing value o f the trad itional vers ion. In or der to ease visual com parison, the sa me ord er is kept for the modified version. This allo ws highlighting disagreements between both versions. Globally, the performance s increase for all mea sures when co mparing the traditional and modified versi ons. We used Student’s test ( ) to assess the significance of this e volution. Inf o Mod is th e only algorith m to u ndergo a d ecrease with all three m ea sures, and m o reover those are significant . WalkTrap increases or decreases dep ending on the measure, but never si gnificant ly. Generalized Measures for the Evaluation of Comm unity Detection Methods 15 The algorith m with the larges t improvement is b y far Louv ain : highest for the F - Measure ( ) and ARI ( ), second highest for the NMI ( ) . T he typical improvement is rather un d er for the other algorithms. At a less er extent, FastGreedy also experience s a significant performance improvement for all three measures. Oslo m and Markov Cluster see t heir performance significantly increa se, but only for the F-Mea sure and ARI. For the NMI, we observe a decrease and an increase, respectively, but thos e are not significa nt. Fig. 2. Com parison of the results obtained with the traditional (left) and m o dified (rig ht) versions of the measures. InfoMap undergoes a sli ght improvement with the F -Measure, whereas for the ARI and NMI it d ecreases slightly, but not signi ficantly. This might be due to the fact its performance is already so hi gh with the traditio nal ver sions that t here is not m uch room for increase. Finally, the measures do not agree for Copra, which und ergoes a clear in crease with the F-Measure ( ) , a small decrease ( ) with the NMI and a non - significant change with the ARI. By constructio n of the modified measures, an increase in the score of a giv en algorithm ca n be interpreted as the fact i ts per formance re lie s mainly on nodes with high weights, i.e . o f larger top ological importance. Therefo re, according to the t hree considered mea sures, this is the case of most of the algor ithms, except Copr a and InfoMod (the latter o f which t hey all agree upon). Interestingly, these are also ranked last by all measures, be it the traditional of modified version s . This m ea ns that, amongst the co nsidered algorithms, those obtaining th e lowest performance from a Traditional F-Mes ure Modified F-Measure Copra F as t G re e dy InfoMod Oslom Louvain MarkovCluster WalkTrap In fo Ma p 1.0 0.8 0.6 0.4 0.2 0.0 0.0 0.2 0.4 0.6 0.8 1.0 Copra InfoMod FastGreedy Oslom WalkTrap Louvain MarkovCluster In fo Ma p Traditional ARI Modified ARI 1.0 0.8 0.6 0.4 0.2 0.0 0.0 0.2 0.4 0.6 0.8 1.0 Copra F as t G r ee d y InfoMod Oslom Louvain WalkTrap MarkovCluster In fo Ma p Traditional NMI Modified NMI 1.0 0.8 0.6 0.4 0.2 0.0 0.0 0.2 0.4 0.6 0.8 1.0 16 Vincent Labatut purely partition -based perspective are also those w ho d o not seem to b e good on topologically important nodes. 5.3 Effect on the Ra nkings Table 2, Tab le 3 and Table 4 display t he al gorithms ran ked by p erfor mance acco rding to both versions of t he AR I, F-Measure and NM I, r espectively. T o o rder the m, we performed an ANOVA and applied Tukey ’s test with a signi ficance level of . Algorithms whose scores are not con sidered significantly different we r e p lac ed on the sa me ro w . In o ur a nalysis, we focus o n the correspond ences and d iscrepancies identified b y Or man et a l . bet ween the trad itional measures and the to pological proper ties. We discuss if the modified versions of the measures allo w consistently taking this aspect of the p erformance into account. Table 2. Algorithm rankings obtained with both traditional and modified versions of the ARI. Algorithms experiencing a change in their relative position are represented in bold. Traditional Adjusted Rand Index Modified Adjusted Rand Index Rank Algorithm Rank Algorithm 1 InfoMap, MarkovCluster 1 Louvain , InfoMap, Mar kovCluster 3 Louvain, WalkTrap 4 WalkTrap , Oslom 5 Oslom, FastGreed y, InfoMod 6 FastGreedy 8 Copra 7 InfoMo d - - 8 Copra It is worth noticing the trad itional versions o f the F -Measure and N MI give exac tl y the sa me r ankings. For this r eason, w e will discuss them jo intly. But first, we start with the A RI. A ccording to i ts traditional vers ion, there is no significant difference between In foMap a nd Mar kovCluster. Ho wever, t he top ology -based observations show the for mer is much closer to the reference str ucture. For this reason, we would expect the m odified version to make a distinction b etween them. Ho wever, this is not the case: no significa nt difference is detected. The traditional versio n d oes n ot make any significant distinction between Louvain and WalkT rap. But topo logically speak ing, WalkTrap is supposed to be the closest to the reference just after InfoMap, so we would exp ect this d ifference to appear in the ranking based on the modified version. Neverthe less, we o bserve the o pposite: Louvain is inconsistently raise d to the level of InfoMap and MarkovCluster. Oslom, FastGreedy and InfoMod are considered to have equivalent per formance by t he traditional version. Fr om a topolo gical point of view, Os lom and Fa stGreedy are ver y close to Lo uvain, this one being slightl y b etter. As mentioned before, Louvain has indeed a better rank accord ing to the modi fied version. Ho wever, our measure also introd uces a distinction between Fast Greedy and Oslom. Concern ing InfoMod, it is suppo sed to be much topologicall y different from the reference than Oslom and FastGreed y. This is consistently reflected with the modified measure. Generalized Measures for the Evaluation of Comm unity Detection Methods 17 Table 3. Algorithm rankings obtained with both traditional and mod ified versions of th e F - Measure. Algorithms experiencing a change in their relative position are represented in bold. Traditional F-M easure Modified F-Measure Rank Algorithm Rank Algorit hm 1 InfoMap 1 InfoMap 2 MarkovCluster, WalkTrap 2 Louvain , MarkovCluster 4 Louvain, Oslom 4 WalkTrap , Oslo m 6 InfoMod, FastGreed y 6 FastGreedy 8 Copra 7 InfoMo d , Copra We now turn to the F-Measure and NMI. For both of their traditional versions, In foMap i s ranked first, a nd alone. T his is a lso the ca se with the modified versions, which is consistent with t he topolo gy. According to th e traditional versions, WalkT rap and MarkovClu ster perfor m equivalently. Both modified measures m anage to make a dist inction between them, but the y disa gree. For the F -Measure, MarkovCl uster i s b etter, which is inco nsistent with our topological kno wledge, wherea s on t he co ntrary t he NMI consistently puts WalkTrap at a higher rank. Louvain and Oslo m ob tain the same rank wi th the tradit ional versio ns. Fro m a topological po int of view, we know the y are indeed very close, the for mer being slightly clo ser to the r eference. The modified F -Measure makes the corr ect distinction between them, b ut tends to o verestimate their ran king, putting Louvai n at the level of MarkovCluster and Oslom at that of WalkTrap . The modified NMI keeps on considering the algorit hms are not significantly differen t, which seems more r elevant. The traditional versions consider InfoMod and Fast Greedy have s i milar performance. For bo th modified versions, InfoMod is ranked lo wer, which is consistent with t he topology -based o bservations. T he NMI additionall y raises FastGreedy to the level o f Louvain and Oslo m, which is consistent. Table 4. Algorithm rankings o btained with both trad itional and modified v ersions of the NMI . Algorithms experiencing a change in their relative position are represented in bold. Traditional NM I Modified NMI Rank Algorithm Rank Algorithm 1 InfoMap 1 InfoMap 2 MarkovCluster, W alkTrap 2 WalkTrap 4 Louvain, Oslo m 3 MarkovCluster 6 InfoMod, FastGreed y 4 Louvain, Oslom, F astGreedy 8 Copra 7 InfoMod 8 Copra Amongst t he three measures we modified, the NMI appear s to be the one leading to the result s the most co nsistent with the obser vations previously made i n [ 7] . Indeed, it seems to roughly preserve the ord er estab lished by the traditio nal ver sion, while distinguishing between otherwise not significantl y different r esults , in a way 18 Vincent Labatut compatible with our knowledge of the community structures topology . Ho wever, there is still roo m for i mprovement, since it is not able to separ ate Louvain, Oslom and FastGreedy. T he t wo other measures are less sati sfying, and display some anomalies. For instance, we cannot find a n e xplanation for the ver y stron g increase observed for Louvain, con sidering the topolog y of the communities it identified is relatively different fro m the reference. 6 Conclusion In this article, we focused on the mea sures used to assess co mmunity detection algorithms. All those mentioned in the literature are si milar to those used in data mining, more precisel y in cluster a nalysis. Our first contr ibution is to have s hown none o f the m i s fully app ropriate for this tas k, b ecause they co mpletely i gnore network topolog y. This decr eases their rele vance, and can lea d the user to incorr ectly interpret the obtained scores. O ur seco nd contrib ution is to ha ve defined variants of the three most widespread measures (F -Measure, Adjusted Rand index, Nor malized mutual information) , in order to so lve this problem. For this matter, we modified t hem by introducing nodal weights: a d iffere nt value can be associated to each nod e, allowing to penalize classification errors in an individual way. Adapting those modified measures to co mmunity detectio n is t hen strai ghtforward: we need the weight to r epresent the topological i mportance o f t he node. We p ropose to use a combination of the d egree and community embeddedness of the node. Our third contribution is the experi mental evaluation of the proposed m od ifications. We used data ob tained by applying a selection of co mmunity detec tion algorithms to a set of artificially ge nerated networ ks with rea listic topo logical pro perties. W e compared the obtained rankin gs with those of the traditio nal versions o f the measures, and as sessed their co nsistency with o bservations from a p reviously co nducted study regarding the topological properties of the estimated co mmunity structures [7 ]. On these data, the results o btained with t he F-Measure a nd ARI prese nt some incon sistencies. On th e contrary, the modified vers ion of the NMI is generally able to appropriately co mbine both aspects, i.e. a ssess ho w good the correspo ndence with the refere nce is in ter ms of both community member ship and topological p roperties. One o f the li mitations of this work concerns t he size of the dataset u sed to evaluate our measures. T o draw more definitive conclusio ns, it i s n ecessary to test them on a larger corpus. Defining the weig hts used to introduce the topolo gical aspect in the measures co nstitutes another sensiti ve point . Indeed, ea ch weig ht is suppo sed to represent the i mportance of the associated node in the net work, and this notion is difficult to d efine ob jectively . In this ar ticle, we penalized algor ithms unable to treat correctly the nod es suppose dly easy to q ualify : th ose l ocated at the cor e of the communities. But it would be po ssible to use the oppo site ap proach, if we suppose all algorithms are ab le to correctl y cla ssify these nodes: one sh ould then g i ve more importance to those loca ted o n t he b order of t he co mmunities. We would t hen probably obtain rather different res ults. Generalized Measures for the Evaluation of Comm unity Detection Methods 19 Besides those points, o ur work can be extended in several wa ys. First, our modified measures can be used, as is, for d ifferent purposes. The y were designed to compare an estimated and a reference partitio ns, but they could al so be app lied to two es timated partitions. One would the n take the topolo gical aspect into acco unt when performing the compariso n. T he modified measures could also be used in the context of class ic cluster anal ysis, i.e. on no n -relational data, when o ne wants to distinguis h the classified ob jects in ter ms of importance. Seco nd, i n this ar ticle we focused on plain networks, but the w e ight s (and therefore th e measures) co uld be ad apted to various types o f networks such as directed or weighted ones. T hird, the principle of o ur mo di fi cation could be applied to any other measure co ming fro m cluster anal ysis. We only treated the most w id espre ad in t he co mmunity detectio n field, b ut many o ther exist: precision, recall, J accard index, etc . Acknowledg ments. This article is a translated a nd extended version of a previo us work presented at the MARAMI 2012 conference [ 27 ]. References 1. Fortunato, S.: Community Detection in Graphs. Phys Re p 486, 75 -174 (2010) 2. Lancichinetti, A., Kivelä, M., Saramäki, J., F ortunato, S.: Characterizing the Community Structure of Complex Networks. PLoS ONE 5, e11976 (2010) 3. Orman, G.K., Labatut, V.: The Effect of Network Realis m on Community Detection Algorithms. ASONAM (2010) 301-305 4. Manning, C.D., Raghavan, P ., Schütze, H.: Introduction to In formation Retrieval. Cambridge University Press (2008) 5. Hubert, L., Arabie, P.: Comparing Partitions. Journal of Classification 2, 193 -218 (1985) 6. Strehl, A., Ghosh, J.: Clu ster Ensembles: A Knowledge Reuse Fr amework for Co mbining Multiple Partitions. Journal of Machine Learning Research 3, 583−617 (2002) 7. Orman, G .K., Labatut, V., Cherifi, H.: Comparative Evaluation o f Communit y Detection Algorithms: A Topological Approach. Journal of Statistical Mechanics 8, P08001 (2012) 8. Danon, L., Díaz-Guilera, A., Duch, J., Arenas, A.: Co mparing Community S tructure Identification. J Stat Mech P09008 (2005) 9. Girvan, M ., Newman, M .E.J.: Community Stru cture in Social and Biological Networks. PNAS 99, 7821-7826 (2002) 10. Zhang, P., Li, M.H., Wu, J.S., Di, Z.R., Fan, Y.: The Analysis a nd Dissimilarity Comparison of Community Structure. Physica A 367, 577 -585 (2006) 11. Liu, C.R., Frazier, P ., Kumar, L.: Comparative Assessment of the Measures o f Thematic Classification Accuracy . Remote Sens En viron 107, 606-616 (2007) 12. Artiles, J., Gonzalo, J., Se kine, S.: The Semeval-2007 Weps Evaluation: Establishing a Benchmark for the Web People Search Ta sk. Workshop on Semantic Evaluation (2007) 13. Newman, M .E.J.: Fast Alg orithm for Detecting Co mmunity Structure in Networks. Phys Rev E 69, 066133 (2004) 14. Rand, W.M.: Ob jective Crit eria for the Evaluation o f Clu stering Methods. J Am Stat Assoc 66, 846-850 (1971) 20 Vincent Labatut 15. Vinh, N.X., Epps, J., Bailey, J.: In formation Theoretic Measures for Clusterin gs Comparison: Is a Correction for Chance Necessary ? In: Intern ational Conference on Machine Learning, 1073-1081, Montreal, CA (2009) 16. Goodman, L. A., Krusk al, W .H.: Measures of Association f or Cross Classif ic ation. J Am Stat Assoc 49, 732-764 (1954) 17. Cover, T.M., Thomas, J.A.: Elements of Information Theory . John Wiley and Sons (2006) 18. Fred, A.L.N., Jain, A.K.: Ro bust Data Clu stering. Computer V ision and P attern Recognition 2, 128-133 (2003) 19. Newman, M.E.J., Girvan, M.: Finding and Evaluating Community Structure in Network s. Phys Rev E 69, 026113 (2004) 20. Gregory, S. : Finding Overlapping Comm u nities in Netw o rks b y Label Propagation. New Journal of Physics 12, 103018 (2010) 21. Rosvall, M., Bergstrom, C.T.: Maps of Random Walks on Co mplex Networks Reveal Community Structure. PNAS 105, 1118 (2008) 22. Rosvall, M., Bergstrom, C.T.: An Information -Theoretic Framework for Resolving Community Structure in Co mple x Networks. P roceedings of the National Academy of Sciences of the United States of America 104, 7327-7331 (2007) 2 3. Blondel, V .D., Guillaume, J. -L., Lambiotte, R., Lefebvre, E.: Fast Unfolding of Communities in Large Networks. J Stat Mech P10008 (2008) 24. van Dongen, S.: Graph Clustering Via a Discrete Uncoupling P rocess. SIAM J Matrix Anal Appl 30, 121-141 (2008) 25. Lancichinetti, A., Radicchi, F., Ramasco, J., Fo rtunato, S.: Finding Statistically Significant Communities in Networks. PLoS ONE 6, e18961 26. Pons, P., Latapy, M.: Computing Co mmunities in Large Net works Using R andom Walks. Lecture Notes in Computer Science 3733, 284-293 (2005) 27. Labatut, V.: Une Nouvelle Mesure Pour L’évaluation Des Métho des De Détection De Communautés. 3ème Co nférence sur les modèles et l'analyse de réseaux : appro ches mathématiques et informatiques (2012) 12 Generalized Measures for the Evaluation of Comm unity Detection Methods 21 Appendix This section contai ns material which was cut in the sub mitted version o f this article . This mainly concerns the trad itional and modi fied versions of the Rand i ndex. Traditional and M odified ( Non-Adjusted) Rand Indice s Both the traditional and modi fied (non-adjusted) Rand indi ces were not presented in the experi mental part, because they re sult in a lack of discriminatio n bet ween the algorithms (as alrea dy o bserved in [ 7]). For this reason, they were cut from sections 2 and 4. For matters of co mpleteness, here is the traditio nal version [5]: ( 29 ) And here is t he modified version, derived by replacing in ( 29 ) as explained in section 4.2: ( 30 ) The values o btained for the example o f section 3 (as prese nted in Table 1 for the other measures) are r especti vely: for the trad itional version, for the modified versio n ap plied to partition and for the modified version applied to partition . Fig. 3. Com parison of the results obtained with the traditional (left) and m o dified (right) versions of the (non-adjusted) Rand index. The above figure represents the experi mental results obtained for the traditiona l and modified versions o f t he (non-adjusted) Rand index, with the data p resented in section 5. On the co nsidered data, the measure d oes not seem to have a strong discriminant power. T his is confirmed b y Stude nt’s test, as d isplayed in Table 5: more than half the algorith ms perfor mances are not significantl y different. The modified version of t he measure distinguishes more groups, but we nevertheless decided not to includ e the (non-adj usted) Rand index in our study, and to focus only on its adjusted versio n instead. Copra F as t G r ee d y Oslom InfoMod WalkTrap Louvain MarkovCluster In fo Ma p Traditional Rand Index Modified Rand Index 1.0 0.8 0.6 0.4 0.2 0.0 0.0 0.2 0.4 0.6 0.8 1.0 22 Vincent Labatut Table 5. Algorithm rankings obtained with bo th tradit ional and mo dified versions o f the (non- adjusted) Ra nd index . Algorithms experiencing a c hange in their relative po sition are represented in bold. Traditional Rand Index Modified Rand Index Rank Algorithm Rank Algorithm 1 InfoMap , MarkovCluster , Louvain, WalkTrap , InfoMod 1 InfoMap , MarkovClust er , Louvain 6 Oslom, FastGreed y 4 WalkTrap , Osl om , InfoMod 8 Copra 7 FastGreedy 8 Copra Comparison of Experimental Results The belo w table displays the rankings ob tained with the four origin al and m o dified measures. It is a s ynthesis of the tables presented in s ection 5, plus the r esults obtained for the ( non-adjusted) Rand index. Table 6. Algorithm ranking obtained with the considered and proposed measures: F -Measure, Rand Index, Adjusted Rand Index, and Normalized Mutual Information. Algorithm Traditional Versions Modified Versions FM RI ARI NMI FM RI ARI NMI Copra 8 8 8 8 7 8 8 8 FastGreedy 6 6 5 6 6 7 6 4 InfoMap 1 1 1 1 1 1 1 1 InfoMod 6 1 5 6 7 4 7 7 Louvain 4 1 3 4 2 1 1 4 MarkovCluster 2 1 1 2 2 1 1 3 Oslom 4 6 5 4 4 4 4 4 WalkTr ap 2 1 3 2 4 4 4 2
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment