Ethnicity sensitive author disambiguation using semi-supervised learning
Author name disambiguation in bibliographic databases is the problem of grouping together scientific publications written by the same person, accounting for potential homonyms and/or synonyms. Among solutions to this problem, digital libraries are in…
Authors: Gilles Louppe, Hussein Al-Natsheh, Mateusz Susik
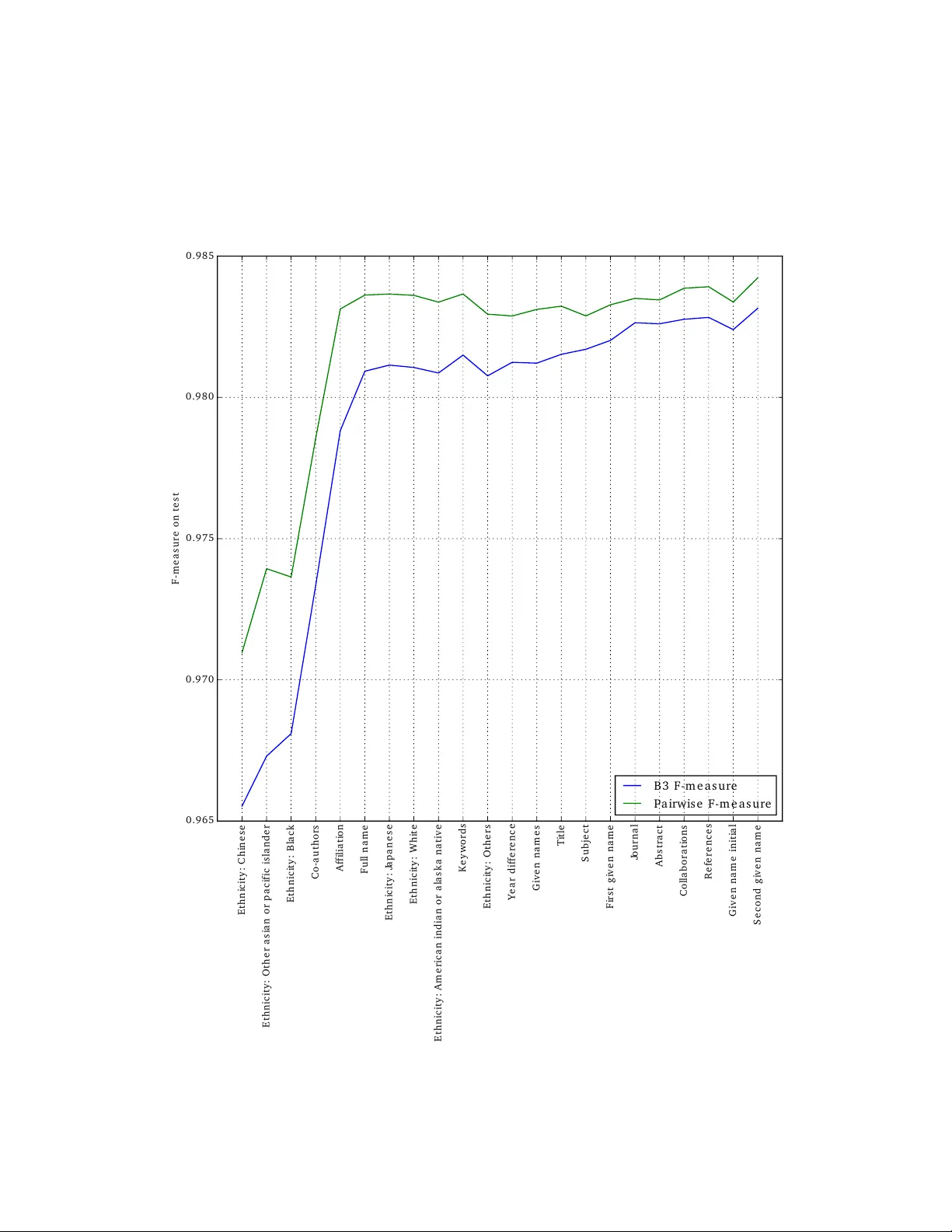
Ethnicit y sensitiv e author disam biguation using semi-sup ervised learning Gilles Loupp e CERN Switzerland Hussein Al-Natsheh CERN Switzerland Mateusz Susik CERN Switzerland Eamonn Maguire CERN Switzerland Abstract Author name disam biguation in bibliographic databases is the problem of grouping together scien tific publications written b y the same p erson, ac- coun ting for potential homonyms and/or synonyms. Among solutions to this problem, digital libraries are increasingly offering to ols for authors to man ually curate their publications and claim those that are theirs. In- directly , these to ols allow for the inexpensive collection of large annotated training data, which can be further leveraged to build a complemen tary au- tomated disam biguation system capable of inferring patterns for iden tifying publications written b y the same p erson. Building on more than 1 million publicly released cro wdsourced annotations, we propose an automated au- thor disambiguation solution exploiting this data (i) to learn an accurate classifier for iden tifying coreferring authors and (ii) to guide the clustering of scie n tific publications b y distinct authors in a semi-supervised w a y . T o the b est of our kno wledge, our analysis is the first to b e carried out on data of this size and co v erage. With resp ect to the state of the art, we v alidate the general pip eline used in most existing solutions, and improv e b y: (i) prop osing phonetic-based blocking strategies, thereb y increasing recall; and (ii) adding strong ethnicit y-sensitive features for learning a link age function, thereb y tailoring disambiguation to non-W estern author names whenev er necessary . 1 In tro duction In academic digital libraries, author name disam biguation is the problem of grouping to- gether publications written b y the same person. Author name disam biguation is often a difficult problem b ecause an author may use differen t sp ellings or name v ariants across their career (synonym y) and/or distinct authors ma y share the same name (p olysemy). Most notably , author disam biguation is often more troublesome for researchers from non-W estern cultures, where p ersonal names may be traditionally less diverse (leading to homon ym is- sues) or for whic h transliteration to Latin characters may not be unique (leading to synonym issues). With the fast growth of the scientific literature, author disambiguation has b ecome a pressing issue since the accuracy of information managed at the lev el of individuals directly affects: the relev ance search of results ( e.g. , when querying for all publications written b y a giv en author); the reliability of bibliometrics and author rankings ( e.g. , citation coun ts or other impact metrics, as studied in (Strotmann and Zhao, 2012)); and/or the relev ance of scien tific netw ork analysis (Newman, 2001). Efforts and solutions to author disambiguation ha ve b een proposed from v arious commu- nities (Liu et al., 2014). On the one hand, libraries hav e maintained authorship control through man ual curation, either in a centralized wa y by hiring professional collab orators or through dev eloping services that in vite authors to register their publications themselv es 1 ( e.g. , Go ogle Scholar or Inspire-HEP). Recent efforts to create p ersistent digital identifiers assigned to researc hers ( e.g. , ORCID or Researc herID), with the ob jective to embed these iden tifiers in the submission w orkflow of publishers or rep ositories ( e.g. , Elsevier, arXiv or Inspire-HEP), w ould univocally solve any disam biguation issue. With the large cost of cen tralized manual authorship con trol, or un til crowdsourced solutions are more widely adopted, the impact of these efforts are unfortunately limited by the efficiency , motiv ation and in tegrit y of their activ e contributors. Similarly , the success of p ersistent digital iden tifier efforts is conditioned to a large and ubiquitous adoption by b oth researc hers and publish- ers. F or these reasons, fully automated machine learning-based metho ds hav e been proposed during the past decade to provide immediate, less costly , and satisfactory solutions to author disam biguation. In this work, our goal is to explore and demonstrate how b oth approaches can co exist and b enefit from eac h other. In particular, we study ho w lab eled data obtained through man ual curation (either centralized or crowdsourced) can be exploited (i) to learn an accurate classifier for iden tifying coreferring authors, and (ii) to guide the clustering of scien tific publications b y distinct authors in a semi-sup ervised w ay . Our analysis of pa- rameters and features of this large dataset reveal that the general pip eline commonly used in existing solutions is an effective approac h for author disambiguation. Additionally , we prop ose alternativ e strategies for blo c king based on the phonetization of author names to increase recall. W e also propose ethnicity-sensitiv e features for learning a link age function, thereb y tailoring author disam biguation to non-W estern author names whenev er necessary . The remainder of this report is structured as follows. In Section 2, w e briefly review mac hine learning solutions for author disambiguation. The comp onents of our metho d are then defined in Section 3 and its implemen tation describ ed in Section 4. Experiments are carried out in Section 5, where we explore and v alidate features for the sup ervised learning of a link age function and compare strategies for the semi-sup ervised clustering of publications. Finally , conclusions and future w orks are discussed in Section 6. 2 Related work As review ed in (Smalheiser and T orvik, 2009; F erreira et al., 2012; Levin et al., 2012), author disam biguation algorithms are usually composed of tw o main components: (i) a link age function determining whether tw o publications ha ve b een written by the same author; and (ii) a clustering algorithm pro ducing clusters of publications assumed to be written by the same author. Approaches can b e classified along sev eral axes, dep ending on the t yp e and amoun t of data a v ailable, the w ay the link age function is learned or defined, or the clustering pro cedure used to group publications. Metho ds relying on sup ervised learning usually make use of a small set of hand-labeled pairs of publications identified as being either from the same or differen t authors to automatically learn a link age function betw een publications (Han et al., 2004; Huang et al., 2006; Culotta et al., 2007; T reeratpituk and Giles, 2009; T ran et al., 2014). T raining data is usually not easily av ailable, therefore unsupervised approaches propose the use of domain-sp ecific, man ually designed, link age functions tailored tow ards author disam biguation (Malin, 2005; McRae-Spencer and Shadb olt, 2006; Song et al., 2007; Soler, 2007; Kang et al., 2009; F an et al., 2011; Sc hulz et al., 2014). These approaches ha ve the adv antage of not requiring hand-labeled data, but generally do not p erform as w ell as sup ervised approac hes. T o reconcile b oth w orlds, semi-sup ervised metho ds make use of small, manually v erified, clusters of publications and/or high-precision domain-specific rules to build a training set of pairs of publications, from which a link age function is then built using supervised learning (F erreira et al., 2010; T orvik and Smalheiser, 2009; Levin et al., 2012). Semi-sup ervised approaches also allow for the tuning of the clustering algorithm when the latter is applied to a mixed set of lab eled and unlab eled publications, e.g. , by maximizing some clustering p erformance metric on the known clusters (Levin et al., 2012). Due to the lack of large and publicly av ailable datasets of curated clusters of publications, studies on author disam biguation are usually constrained to v alidating their results on man- ually built datasets of limited size and scop e (from a few hundred to a few thousand papers, 2 ... Signature for Doe, John Publications Signatures Title Lorem ipsum dolor sit amet, consectetur adipiscing elit Author Doe, John Affiliation University of Foo Co-authors Smith, John; Chen, Wang 2015 Y ear Figure 1: An example signature s for ”Do e, John”. A signatur e is defined as unique piece of information identifying an author on a publication, along with any other metadata that can b e derived from it, such as publication title, co-authors or date of publication. with sparse co verage of am biguous cases), making the true performance of these methods of- ten difficult to assess with high confidence. Additionally , despite dev oted efforts to construct them, these datasets are rarely public, making it ev en more difficult to compare methods using a common b enchmark. In this con text, we position the work in this pap er as a semi-sup ervised solution for author disam biguation, with the significant adv antage of having a v ery large collection of more than 1 million cro wdsourced annotations of publications whose true authors are iden tified. The exten t and co verage of this data allo ws us to revisit, v alidate and nuance previous findings regarding sup ervised learning of link age functions, and to b etter explore strategies for semi- sup ervised clustering. F urthermore, by releasing our data in the public domain, we hope to pro vide a benchmark on which further research on author disam biguation and related topics can b e built. 3 Semi-sup ervised author disambiguation F ormally , let us assume a set of publications P = { p 0 , ..., p N − 1 } along with the set of unique individuals A = { a 0 , ..., a M − 1 } having together authored all publications in P . Let us define a signature s ∈ p from a publication as a unique piece of information identifying one of the authors of p ( e.g. , the author name, his affiliation, along with any other metadata that can b e derived from p , as illustrated in Figure 1). Let us denote by S = { s | s ∈ p, p ∈ P } the set of all signatures that can b e extracted from all publications in P . In this framework, author disambiguation can be stated as the problem of finding a partition C = { c 0 , ..., c M − 1 } of S such that S = ∪ M − 1 i =0 c i , c i ∩ c j = φ for all i 6 = j , and where subsets c i , or clusters, each corresp onds to the set of all signatures b elonging to the same individual a i . Alternatively , the set A may remain (p ossibly partially) unknown, suc h that author disam biguation b oils do wn to finding a partition C where subsets c i eac h corresp ond to the set of all signatures from the same individual (without kno wing who). Finally , in the case of partially annotated databases as studied in this work, the set extends with the partial kno wledge C 0 = { c 0 0 , ..., c 0 M − 1 } of C , suc h that c 0 i ⊆ c i , where c 0 i ma y b e empt y . Or put otherwise, the set extends with the assumption that all signatures s ∈ c 0 i b elong to the same author. Inspired by sev eral previous w orks describ ed in Section 2, w e cast in this work author disam biguation into a semi-supervised clustering problem. Our algorithm is comp osed of three parts, as sketc hed in Figure 2: (i) a blo cking sc heme whose goal is to roughly pre- cluster signatures S into smaller groups in order to reduce computational complexity; (ii) the construction of a link age function d betw een signatures using supervised learning; and (iii) the semi-supervised clustering of all signatures within the same blo ck, using d as a pseudo distance metric. 3 Figure 2: Pipeline for author disambiguation: (a) signatures are blo cke d to reduce computa- tional complexity , (b) a link age function is built with sup ervised learning, (c) indep endently within each blo ck, signatures are grouped using hierarchical agglomerativ e clustering. 3.1 Blo c king As in previous works, the first part of our algorithm consists of dividing signatures S into disjoin t subsets S b 0 , ..., S b K − 1 , or blo cks (F ellegi and Sunter, 1969), follow ed by carrying out author disam biguation on eac h one of these blo cks indep enden tly . By doing so, the computational complexity of clustering (see Section 3.3) typically reduces from O ( |S | 2 ) to O ( P b |S b | 2 ), whic h is muc h more tractable as the n umber of signatures increases. Since disam biguation is performed indep endently per blo ck, a goo d blo cking strategy should b e designed suc h that signatures from the same author are all mapped to the same blo ck, otherwise their correct clustering w ould not b e p ossible in later stages of the workflo w. As a result, blo cking should b e a balance b etw een reduced complexity and maxim um recall. The simplest and most common strategy for blo cking, referred to hereon in as Surname and First Initial (SFI) , groups signatures together if they share the same surname(s) and the same first giv en name initial ( e.g. , SFI (”Do e, John”) == ”Doe, J”). Despite satisfactory p erformance, there are several cases where this simple strategy fails to cluster related pairs of signatures together, including: 1. There are different w ays of writing an author name, or signatures con tain a t yp o ( e.g. , ”Mueller, R.” and ”Muller, R.”, ”Tchaik ovsky , P .” and ”Cza jko wski, P .”). 2. An author has multiple surnames and some signatures place the first part of the surname within the given names ( e.g. , ”Martinez T orres, A.” and ”T orres, A. Mar- tinez”). 3. An author has multiple surnames and, on some signatures, only the first surname is present ( e.g. , ”Smith-Jones, A.” and ”Smith, A.”) 4. An author has m ultiple giv en names and they are not alw ays all recorded ( e.g. , ”Smith, Jack” and ”Smith, A. J.”) 5. An authors surname c hanged ( e.g. , due to marriage). T o account for these issues w e propose instead to blo ck signatures based on the phonetic represen tation of the normalized surname. Normalization in v olv es stripping accents ( e.g. , ”Jab lo ´ nski, L” → ”Jablonski, L”) and name affixes that inconsistently app ear in signatures ( e.g. , ”v an der W aals, J. D.” → ”W aals, J. D.”), while phonetization is based either on the Double Metaphone (Philips, 2000), the NYSI IS (T aft, 1970) or the Soundex (The National Arc hiv es, 2007) phonetic algorithms for mapping author names to their pronunciations. T ogether, these processing steps allow for grouping of most name v arian ts of the same p erson in the same blo ck with a small increase in the ov erall computational complexit y , thereb y solving case 1. 4 In the case of multiple surnames (cases 2 and 3), we propose to block signatures in tw o phases. In the first phase, all the signatures with a single surname are clustered together. Ev ery differen t surname tok en creates a new blo c k. In the second phase, the signatures with m ultiple surnames are compared with the blo c ks for the first and last surname. If the first surnames of an author w ere already used as the last given names on some of the signatures, the new signature is assigned to the block of the last surname (case 2). Otherwise, the signature is assigned to the block of the first surname (case 3). Finally , to prev ent the creation of to o large blo cks, signatures are further divided along their first giv en name initial. Cases 4 and 5 are not explicitly handled. 3.2 Link age function Sup ervise d classific ation. The second part of the algorithm is the automatic construction of a pair-wise link age function betw een signatures for use during the clustering step which groups all signatures from the same author. F ormally , the goal is to build a function d : S × S 7→ [0 , 1], such that d ( s 1 , s 2 ) approac hes 0 if both signatures s 1 and s 2 b elong to the same author, and 1 otherwise. This problem can b e cast as a standard sup ervised class ification task, where inputs are pairs of signatures and outputs are classes 0 (same authors), and 1 (distinct authors). In this w ork, we ev al- uate Random F orests (RF, Breiman (2001)), Gradien t Boosted Regression T rees (GBR T, F riedman (2001)), and Logistic Regression (F an et al., 2008) as classifiers. Input fe atur es. In most cases, supervised learning algorithms assume the input space X to b e n umeric ( e.g. , R p ), making them not directly applicable to structured input spaces suc h as S × S . F ollowing previous works, pairs of signatures ( s 1 , s 2 ) are first transformed to v ectors v ∈ R p b y building so-called similarit y profiles (T reeratpituk and Giles, 2009) on whic h supervised learning is carried out. In this w ork, we design and ev aluate fifteen standard input features based on the comparison of signature fields, as reported in the first half of T able 1. As an illustrative example, the F ul l name feature corresp onds to the similarit y b etw een the (full) author name fields of the t wo signatures, as measured using as com bination op erator the cosine similarity b etw een their resp ective ( n, m )- TF-IDF vector represen tations 1 . Similarly , the Y e ar differ enc e feature measures the absolute difference b et w een the publication date of the articles to which the tw o signatures resp ectively b elong. Author names from different cultures, origins or ethnic groups are likely to be disam biguated using different strategies ( e.g. , pairs of signatures with F rench author names v ersus pairs of signatures with Chinese author names) (T reeratpituk and Giles, 2012; Chin et al., 2014). T o supp ort our disam biguation algorithm, we added seven features to our feature set, with eac h ev aluating the degree of b elonging of b oth signatures to an ethnic group, as rep orted in the second half of T able 1. More specifically , using census data extracted from (Ruggles et al., 2008), w e build a supp ort v ector machine classifier (using a linear k ernel and one-v ersus-all classification scheme) for mapping the (1 , 5)-TF-IDF represen tation of an author name to one of the seven ethnic groups. Giv en a pair of signatures ( s 1 , s 2 ), the prop osed ethnicity features are eac h computed as the estimated probability of s 1 b elonging to the corresp onding ethnic group, multiplied by the estimated probability of s 2 b elonging to the same group. In doing so, the exp ectation is for the link age function to b ecome sensitive to the actual origin of the authors dep ending on the v alues of these features. Indirectly , let us also note that these features hold discriminativ e p o w er since if author names are predicted to b elong to differen t ethnic groups, then they are also likely to corresp ond to distinct p eople. Building a tr aining set. The distinctiv e aspect of our work is the knowledge of more than 1 million cro wdsourced annotations C 0 = { c 0 0 , ..., c 0 M − 1 } , indicating together that all signature s ∈ c 0 i are kno wn to corresp ond to the same individual a i . In particular, this data can b e used to generate p ositive pairs ( x = ( s 1 , s 2 ) , y = 0) for all s 1 , s 2 ∈ c 0 i , for all i . Similarly , negativ e pairs ( x = ( s 1 , s 2 ) , y = 1) can b e extracted for all s 1 ∈ c 0 i , s 2 ∈ c 0 j , for all i 6 = j . 1 ( n, m ) denotes that the TF-IDF v ectors are computed from c haracter n , n + 1, ..., m -grams. When not sp ecified, TF-IDF vectors are otherwise computed from words. 5 T able 1: Input features for learning a link age function F eature Com bination op erator F ull name Cosine similarity of (2 , 4)-TF-IDF Giv en names Cosine similarity of (2 , 4)-TF-IDF First given name Jaro-Winkler distance Second given name Jaro-Winkler distance Giv en name initial Equalit y Affiliation Cosine similarity of (2 , 4)-TF-IDF Co-authors Cosine similarity of TF-IDF Title Cosine similarity of (2 , 4)-TF-IDF Journal Cosine similarity of (2 , 4)-TF-IDF Abstract Cosine similarity of TF-IDF Keyw ords Cosine similarity of TF-IDF Collab orations Cosine similarity of TF-IDF References Cosine similarity of TF-IDF Sub ject Cosine similarity of TF-IDF Y ear difference Absolute difference White Pro duct of estimated probabilities Blac k Pro duct of estimated probabilities American Indian or Alask a Nativ e Pro duct of estimated probabilities Chinese Pro duct of estimated probabilities Japanese Pro duct of estimated probabilities Other Asian or Pacific Islander Pro duct of estimated probabilities Others Pro duct of estimated probabilities The most straightforw ard approac h for building a training set on which to learn a link age function is to sample an equal num b er of positive and negative pairs, as suggested ab ov e. By observing that the link age function d will even tually b e used only on pairs of signatures from the same blo c k S b , a further refinement for building a training set is to restrict positive and negative pairs ( s 1 , s 2 ) to only those for which s 1 and s 2 b elong to the same blo c k. In doing so, the trained classifier is forced to learn intra-block discriminative patterns rather than in ter-blo ck differences. F urthermore, as noted in (Lange and Naumann, 2011), most signature pairs are non-am biguous: if both signatures share the same author names, then they corresp ond to the same individual, otherwise they do not. Rather than sampling pairs uniformly at random, we prop ose to o v ersample difficult cases when building the training set ( i.e. , pairs of signatures with different author names corresp onding to same individual, and pairs of signatures with identical author names but corresp onding to distinct individuals) in order to improv e the ov erall accuracy of the link age function. 3.3 Semi-sup ervised clustering The last component of our author disam biguation pip eline is clustering, that is the process of grouping together, within a blo ck, all signatures from the same individual (and only those). As for many other works on author disambiguation, w e make use of hierarc hical clustering (W ard Jr, 1963) for building clusters of signatures in a b ottom-up fashion. The method in v olv es iteratively merging together the tw o most similar clusters until all clusters are merged together at the top of the hierarch y . Similarity b et ween clusters is ev aluated using either complete, single or av erage link age, using as a pseudo-distance metric the probability that s 1 and s 2 corresp ond to distinct authors, as calculated from the custom link age function d from Section 3.2. T o form flat clusters from the hierarch y , one must decide on a maximum distance threshold ab o v e whic h clusters are considered to corresp ond to distinct authors. Let us denote b y S 0 = { s | s ∈ c 0 , c 0 ∈ C 0 } the set of all signatures for which partial clusters are known. Let us also denote by b C the predicted clusters for all signatures in S , and b y b C 0 = { b c ∩ S 0 | b c ∈ b C } the predicted clusters restricted to signatures for which partial clusters are known. F rom these, w e ev aluate the following semi-sup ervised cut-off strategies, as illustrated in Figure 3: 6 Figure 3: Semi-supervised cut-off strategies to form flat clusters of signatures. • No cut: all signatures from the same blo ck are assumed to be from the same author. • Glob al cut: the threshold is chosen globally o ver all blocks, as the one maximizing some score f ( C 0 , b C 0 ). • Blo ck cut: the threshold is chosen lo cally at each block b , as the one maximizing some score f ( C 0 b , b C 0 b ). In case C 0 b is empt y , then all signatures from b are clustered together. 4 Implemen tation As part of this work, we dev elop ed a stand-alone application for author disambiguation, publicly av ailable online 2 for free reuse or study . Our implementation builds up on the Python scientific stack, making use of the Scikit-Learn library (Pedregosa et al., 2011) for the supervised learning of a link age function and of SciPy (Jones et al., 01 ) for clustering. All comp onen ts of the disambiguation pipeline hav e b een designed to follow the Scikit- Learn API (Buitinc k et al., 2013), making them easy to maintain, understand and reuse. Our implemen tation is made to b e efficien t, exploiting parallelization when av ailable, and ready for production environmen ts. It is also designed to be runnable in an incremen tal fashion, by enabling disambiguation only on sp ecified blocks if desired, instead of having to run the disambiguation pro cess on the whole signature set. 5 Exp erimen ts 5.1 Data The author disambiguation solution prop osed in this work, along with its enhancements, are ev aluated on data extracted from the INSPIRE p ortal (Gentil-Beccot et al., 2009), a digital library for scientific literature in high-energy physics. Ov erall, the p ortal holds more than 1 million publications P , forming in total a set S of more than 10 million signatures. Out of these, around 13% hav e b een claime d b y their original authors, mark ed as suc h b y professional curators or automatically assigned to their true authors thanks to persistent iden tifiers provided b y publishers or other sources. T ogether, they constitute a trusted set ( S 0 , C 0 ) of 15388 distinct individuals sharing 36340 unique author names spread within 1201763 signatures on 360066 publications. This data co vers sev eral decades in time and dozens of author nationalities w orldwide. F ollo wing the INSPIRE terms of use, the signatures S 0 and their corresp onding clusters C 0 are released online 3 under the CC0 license. T o the b est of our knowledge, data of this size and cov erage is the first to b e publicly released in the scop e of author disambiguation researc h. 2 https://github.com/glouppe/beard 3 https://github.com/glouppe/paper- author- disambiguation 7 5.2 Ev aluation proto col Exp erimen ts carried out to study the impact of the prop osed algorithmic comp onents and refinemen ts, as describ ed in Section 3, follo w a standard 3-fold cross-v alidation proto col, using ( S 0 , C 0 ) as ground-truth dataset. T o replicate the |S 0 | / |S | ≈ 13% ratio of claimed signatures with respect to the total set of signatures, as on the INSPIRE platform, cross- v alidation folds are constructed b y sampling 13% of claimed signatures to form a training set S 0 train ⊆ S 0 . The remaining signatures S 0 test = S 0 \ S 0 train are used for testing. Therefore, C 0 train = { c 0 ∩ S 0 train | c 0 ∈ C 0 } represen ts the partial known clusters on the training fold, while C 0 test are those used for testing. As commonly p erformed in author disambiguation research, we ev aluate the predicted clus- ters o ver testing data C 0 test , using b oth B3 and pairwise precision, recall and F-measure, as defined b elow: P B3 ( C , b C , S ) = 1 |S | X s ∈S | c ( s ) ∩ b c ( s ) | | b c ( s ) | (1) R B3 ( C , b C , S ) = 1 |S | X s ∈S | c ( s ) ∩ b c ( s ) | | c ( s ) | (2) F B3 ( C , b C , S ) = 2 P B3 ( C , b C , S ) R B3 ( C , b C , S ) P B3 ( C , b C , S ) + P B3 ( C , b C , S ) (3) P pairwise ( C , b C ) = | p ( C ) ∩ p ( b C ) | | p ( b C ) | (4) R pairwise ( C , b C ) = | p ( C ) ∩ p ( b C ) | | p ( C ) | (5) F pairwise ( C , b C ) = 2 P pairwise ( C , b C ) R pairwise ( C , b C ) P pairwise ( C , b C ) + R pairwise ( C , b C ) (6) and where c ( s ) (resp. b c ( s )) is the cluster c ∈ C such that s ∈ c (resp. the cluster b c ∈ b C suc h that s ∈ b c ), and where p ( C ) = ∪ c ∈C { ( s 1 , s 2 ) | s 1 , s 2 ∈ c, s 1 6 = s 2 } is the set of all pairs of signatures from the same clusters in C . Precision ev aluates whether signatures are group ed only with signatures from the same true clusters, while recall measures the exten t to which all signatures from the same true clusters are effectiv ely group ed together. The F-measure is the harmonic mean b etw een these tw o quantities. In the analysis below, we rely primarily on the B3 F-measure for discussing results, as the pairwise v ariant tends to fa v or large clusters (b ecause the num b er of pairs is quadratic with the cluster size), hence unfairly giving preference to authors with many publications. By con trast, the B3 F-measure w eigh ts clusters linearly with resp ect to their size. General conclusions drawn below remain ho w ev er consistent for pairwise F. 5.3 Results and discussion Baseline. Results presented in T able 2 are discussed with resp ect to a baseline solution using the following combination of components: • Blocking: same surname and the same first given name initial strategy (SFI); • Link age function: all 22 features defined in T able 1, gradien t b o osted regression trees as supervised learning algorithm and a training set of pairs built from ( S 0 train , C 0 train ), b y balancing easy and difficult cases. • Clustering: agglomerative clustering using av erage link age and block cuts found to maximize F B3 ( C 0 train , b C 0 train , S 0 train ). Blo cking. The go o d precision of the baseline (0 . 9901), but its low er recall (0 . 9760) suggest that the blo cking strategy might b e the limiting factor to further ov erall impro vemen ts. As sho wn in T able 3, the maxim um recall ( i.e. , if within a blo ck, all signatures w ere clustered 8 T able 2: Av erage precision, recall and f-measure scores on test folds. B3 P airwise Description P R F P R F Baseline 0.9901 0.9760 0.9830 0.9948 0.9738 0.9842 Blo c king = SFI 0.9901 0.9760 0.9830 0.9948 0.9738 0.9842 Blo c king = Double metaphone 0.9856 0.9827 0.9841 0.9927 0.9817 0.9871 Blo c king = NYSI IS 0.9875 0.9826 0.9850 0.9936 0.9814 0.9875 Blo c king = Soundex 0.9886 0.9745 0.9815 0.9935 0.9725 0.9828 No name normalization 0.9887 0.9697 0.9791 0.9931 0.9658 0.9793 Name normalization 0.9901 0.9760 0.9830 0.9948 0.9738 0.9842 Classifier = GBR T 0.9901 0.9760 0.9830 0.9948 0.9738 0.9842 Classifier = Random F orests 0.9909 0.9783 0.9846 0.9957 0.9752 0.9854 Classifier = Linear Regression 0.9749 0.9584 0.9666 0.9717 0.9569 0.9643 T raining pairs = Non-blo ck ed, uniform 0.9793 0.9630 0.9711 0.9756 0.9629 0.9692 T raining pairs = Blo ck ed, uniform 0.9854 0.9720 0.9786 0.9850 0.9707 0.9778 T raining pairs = Blo ck ed, balanced 0.9901 0.9760 0.9830 0.9948 0.9738 0.9842 Clustering = Average link age 0.9901 0.9760 0.9830 0.9948 0.9738 0.9842 Clustering = Single link age 0.9741 0.9603 0.9671 0.9543 0.9626 0.9584 Clustering = Complete link age 0.9862 0.9709 0.9785 0.9920 0.9688 0.9803 No cut 0.9024 0.9828 0.9409 0.8298 0.9776 0.8977 Global cut 0.9892 0.9737 0.9814 0.9940 0.9727 0.9832 Blo c k cut 0.9901 0.9760 0.9830 0.9948 0.9738 0.9842 Com bined b est settings 0.9888 0.9848 0.9868 0.9951 0.9831 0.9890 T able 3: Maximum recall R ∗ B3 and R ∗ pairwise of blocking strategies, and their num b er of blo c ks on S 0 . Blo c king R ∗ B3 R ∗ pairwise # blo cks SFI 0.9828 0.9776 12978 Double metaphone 0.9907 0.9863 9753 NYSI IS 0.9902 0.9861 10857 Soundex 0.9906 0.9863 9403 optimally) for SFI is 0 . 9828. At the price of fewer and therefore slightly larger blo cks (as rep orted in the righ t column of T able 3), the proposed phonetic-based blo cking strategies sho w b etter maximum recall (all around 0 . 9905), thereby pushing further the upp er bound on the maxim um p erformance of author disambiguation. Let us remind how ever that the rep orted maxim um recalls for the blo c king strategies using phonetization are also raised due to the b etter handling of multiple surnames, as described in Section 3.1. As T able 2 sho ws, switching to either Double metaphone or NYSI IS phonetic-based blocking allo ws to improv e the ov erall F-measure score, trading precision for recall. In particular, the NYSI IS-based phonetic blocking sho ws to be the most effectiv e when applied to the baseline (with an F-measure of 0 . 9850) while also b eing the most efficient computationally (with 10857 blo cks versus 12978 for the baseline). Finally , let us also note that T able 3 corrob orates the estimation of (T orvik and Smalheiser, 2009), stating that SFI blocking has a recall around 98% on real data. Name normalization. As discussed previously , the seemingly insignificant step of normalizing author names (stripping accents, removing affixes), as p erformed in the baseline, is shown to be imp ortant. Results from T able 2 clearly suggest that not normalizing significan tly reduces p erformance (yielding an F-measure of 0 . 9830 when normalizing, but decreasing to 0 . 9791 when raw author name strings are used instead). Linkage function. Let us first comment on the results regarding the supervised algorithm used to learn the link age function. As T able 2 indicates, b oth tree-based algorithms app ear to b e significan tly b etter fit than Linear Regression (0 . 9830 and 0 . 9846 for GBR T and Random 9 F orests versus 0 . 9666 for Linear Regression). This result is consisten t with (T reeratpituk and Giles, 2009) whic h ev aluated the use of Random F orests for author disambiguation, but con tradicts results of (Levin et al., 2012) for which Logistic Regression app eared to b e the b est classifier. Provided hyper-parameters are prop erly tuned, the sup eriority of tree-based metho ds is in our opinion not surprising. Indeed, given the fact that the optimal link age function is likely to be non-linear, non-parametric methods are exp ected to yield better results, as the exp eriments here confirm. Second, prop erly constructing a training set of positive and negativ e pairs of signatures from whic h to learn a link age function yields a significant improv ement. A random sampling of p ositiv e and negative pairs, without taking blo c king into account, significantly impacts the ov erall performance (0 . 9711). When pairs are dra wn only from blo cks, performance increases (0 . 9786), which confirms our in tuition that d should b e built only from pairs it will b e used to ev entually cluster. Finally , making the classification problem more difficult by o v ersampling complex cases prov es to b e relev an t, b y further improving the disambiguation results (0 . 9830). Using Recursive F eature Elimination Guy on et al. (2002), we next ev aluate the usefulness of all fifteen standard and seven additional ethnicity features for learning the link age function. The analysis consists in using the baseline algorithm first using all tw ent y t wo features, to determine the least discriminativ e from feature imp ortances (Loupp e et al., 2013), and then re-learn the bas eline using all but that one feature. That pro cess is rep eated recursiv ely un til even tually only one feature remains. Results are presented in Figure 4 for one of the three folds, starting from the far right with the baseline and Se c ond given name b eing the least imp ortant feature, and ending on the left with all features eliminated but Chinese . As the figure illustrates, the most imp ortan t features are ethnic-based features ( Chinese , Other Asian , Black ) along with Co-authors , Affiliation and F ul l name . Adding the remaining other features only brings marginal improv emen ts, with Journal , Abs tr act , Col lab or ations , R efer enc es , Given name initial and Se c ond given name b eing almost insignifican t. Ov erall, these results highlight the added v alue of the proposed ethnicity features. Their duality in modeling both the similarit y b etw een author names and their origins mak e them v ery strong predictors for author disambiguation. The results also corrob orate those from (Kang et al., 2009) or (F erreira et al., 2010), who found that the similarity b etw een co-authors w as a highly discriminative feature. If computational complexit y is a concern, this analysis also sho ws ho w decent p erformance can be achiev ed using only a very small set of features, as also observed in (T reeratpituk and Giles, 2009) or (Levin et al., 2012). Semi-sup ervise d clustering. The last part of our exp eriment concerns the study of agglom- erativ e clustering and the b est wa y to find a cut-off threshold to form clusters. Results from T able 2 first clearly indicate that av erage link age is significan tly b etter than b oth single and complete link age. Clustering together all signatures from the same block is the least effectiv e strategy (0 . 9409), but yields anyho w surprisingly decent accuracy , given the fact it requires almost no compu- tation ( i.e. , b oth learning a link age function and running agglomerative clustering can b e skipp ed – only the blo cking function is needed to group signatures). In particular, this result rev eals that author names are not am biguous in most cases 4 and that only a small fraction of them requires adv anced disam biguation procedures. On the other hand, b oth global and blo c k cut thresholding strategies give very goo d results, with a sligh t adv antage for block cuts (0 . 9814 v ersus 0 . 9830), as exp ected. In case S 0 b is empt y ( e.g. , b ecause it corresp onds to a y oung researcher at the b eginning of his career), this therefore suggests that either using a cut-off threshold learned globally from the known data or using SFI would in general give satisfactory results, only marginally w orse than if claimed signatures had been known. Combine d b est settings. When all best settings are com bined ( i.e. , Blocking = NYSIIS, Name normalization, Classifier = Random F orests, T raining pairs = blo c ked and balanced, Clustering = Average link age, Blo ck cuts), p erformance reaches 0 . 9862, i.e. , the b est of all 4 This holds for the data we extracted, but may in the future, with the rise of non-W estern researc hers, b e an underestimate of the ambiguous cases. 10 Figure 4: Recursiv e F eature Elimination analysis. E t h n ic it y : C h in e s e E t h n ic it y : O t h e r a s ia n o r p a c if ic is l a n d e r E t h n ic it y : B l a c k C o - a u t h o r s A f f il ia t io n F u l l n a m e E t h n ic it y : J a p a n e s e E t h n ic it y : W h it e E t h n ic it y : A m e r ic a n in d ia n o r a l a s k a n a t iv e K e y w o r d s E t h n ic it y : O t h e r s Y e a r d if f e r e n c e G iv e n n a m e s T it l e S u b j e c t F ir s t g iv e n n a m e J o u r n a l A b s t r a c t C o l l a b o r a t io n s R e f e r e n c e s G iv e n n a m e in it ia l S e c o n d g iv e n n a m e 0 . 9 6 5 0 . 9 7 0 0 . 9 7 5 0 . 9 8 0 0 . 9 8 5 F - m e a s u r e o n t e s t B 3 F - m e a s u r e P a ir w is e F - m e a s u r e 11 rep orted results. In particular, this combination exhibits both the high recall of phonetic blo c king based on the NYSIIS algorithm and the high precision of Random F orests. 6 Conclusions In this work, we hav e revisited and v alidated the general author disambiguation pip eline in- tro duced in previous independent researc h w ork. The generic approac h is comp osed of three comp onen ts, whose design and tuning are all critical to goo d p erformance: (i) a blo cking function for pre-clustering signatures and reducing computational complexity , (ii) a link- age function for identifying signatures with coreferring authors and (iii) the agglomerative clustering of signatures. Making use of a distinctively large dataset of more than 1 million cro wdsourced annotations, we exp erimentally study all three comp onents and prop ose fur- ther improv ements. With regards to blocking, w e suggest to use phonetization of author names to increase recall while main taining low computational complexit y . F or the link age function, w e in tro duce ethnicit y-sensitiv e features for the automatic tailoring of disam bigua- tion to non-W estern author names whenever necessary . Finally , we explore semi-sup ervised cut-off threshold strategies for agglomerativ e clustering. F or all three comp onen ts, experi- men ts show that our refinemen ts all yield significantly b etter author disam biguation accu- racy . Ov erall, these results all encourage further improv ements and research. F or blocking, one of the op en c hallenges is to manage signatures with inconsistent surnames or inconsistent first given names (cases 4 and 5, as described in Section 3.1) while main taining blo cks to a tractable size. As phonetic algorithms are not y et p erfect, another direction for further w ork is the design of b etter phonetization functions, tailored for author disam biguation. F or the link age function, the goo d results of the prop osed features pa ve the wa y for further researc h in ethnicity-sensitiv e author disambiguation. The automatic fitting of the pip eline to cultures and ethnic groups for whic h standard author disambiguation is known to b e less efficient ( e.g. , Chinese authors with man y homon yms) indeed constitutes a direction of researc h with great p otential b enefits for the concerned scien tific communities. As part of this study , w e also publicly release the annotated data extracted from the IN- SPIRE platform, on which our exp eriments are based. T o the b est of our kno wledge, data of this size and cov erage is the first to b e a v ailable in author disam biguation researc h. By releasing the data publicly , we hop e to provide the basis for further research on author disam biguation and related topics. References Breiman, L. (2001). Random forests. Machine le arning , 45(1):5–32. Buitinc k, L., Loupp e, G., Blondel, M., Pedregosa, F., Mueller, A., Grisel, O., Niculae, V., Prettenhofer, P ., Gramfort, A., Grobler, J., La yton, R., V anderPlas, J., Joly , A., Holt, B., and V aro quaux, G. (2013). API design for machine learning softw are: exp eriences from the scikit-learn pro ject. CoRR , abs/1309.0238. Chin, W.-S., Zh uang, Y., Juan, Y.-C., W u, F., T ung, H.-Y., Y u, T., W ang, J.-P ., Chang, C.-X., Y ang, C.-P ., Chang, W.-C., et al. (2014). Effective string pro cessing and matching for author disambiguation. The Journal of Machine L e arning R ese ar ch , 15(1):3037–3064. Culotta, A., Kanani, P ., Hall, R., Wic k, M., and McCallum, A. (2007). Author disam- biguation using error-driv en machine learning with a ranking loss function. In Sixth International Workshop on Information Inte gr ation on the Web (IIWeb-07), V anc ouver, Canada . F an, R.-E., Chang, K.-W., Hsieh, C.-J., W ang, X.-R., and Lin, C.-J. (2008). Liblinear: A library for large linear classification. The Journal of Machine L e arning R ese ar ch , 9:1871– 1874. F an, X., W ang, J., Pu, X., Zhou, L., and Lv, B. (2011). On graph-based name disambigua- tion. Journal of Data and Information Quality (JDIQ) , 2(2):10. 12 F ellegi, I. P . and Sunter, A. B. (1969). A theory for record link age. Journal of the Americ an Statistic al Asso ciation , 64:1183–1210. F erreira, A. A., Gon¸ calv es, M. A., and Laender, A. H. (2012). A brief survey of automatic metho ds for author name disam biguation. A cm Sigmo d R e c or d , 41(2):15–26. F erreira, A. A., V eloso, A., Gon¸ calv es, M. A., and Laender, A. H. (2010). Effectiv e self- training author name disambiguation in scholarly digital libraries. In Pr o c e e dings of the 10th annual joint c onfer enc e on Digital libr aries , pages 39–48. ACM. F riedman, J. H. (2001). Greedy function appro ximation: a gradient bo osting machine. A nnals of statistics , pages 1189–1232. Gen til-Beccot, A., Mele, S., Holtk amp, A., O’Connell, H. B., and Brooks, T. C. (2009). In- formation resources in high-energy ph ysics: Surv eying the present landscape and charting the future course. Journal of the A meric an So ciety for Information Scienc e and T e chnol- o gy , 60(1):150–160. Guy on, I., W eston, J., Barnhill, S., and V apnik, V. (2002). Gene selection for cancer classification using supp ort vector mac hines. Machine le arning , 46(1-3):389–422. Han, H., Giles, L., Zha, H., Li, C., and Tsioutsiouliklis, K. (2004). Two sup ervised learn- ing approac hes for name disambiguation in author citations. In Digital Libr aries, 2004. Pr o c e e dings of the 2004 Joint ACM/IEEE Confer enc e on , pages 296–305. IEEE. Huang, J., Ertekin, S., and Giles, C. L. (2006). Efficient name disambiguation for large-scale databases. In Know le dge Disc overy in Datab ases: PKDD 2006 , pages 536–544. Springer. Jones, E., Oliphant, T., P eterson, P ., et al. (2001–). SciPy: Open source scien tific to ols for Python. [Online; accessed 2015-08-10]. Kang, I.-S., Na, S.-H., Lee, S., Jung, H., Kim, P ., Sung, W.-K., and Lee, J.-H. (2009). On co-authorship for author disam biguation. Information Pr o c essing & Management , 45(1):84–97. Lange, D. and Naumann, F. (2011). F requency-a ware similarit y measures: wh y arnold sc h w arzenegger is alwa ys a duplicate. In Pr o c e e dings of the 20th ACM international c onfer enc e on Information and know le dge management , pages 243–248. ACM. Levin, M., Kraw czyk, S., Bethard, S., and Jurafsky , D. (2012). Citation-based b o otstrapping for large-scale author disambiguation. Journal of the A meric an So ciety for Information Scienc e and T e chnolo gy , 63(5):1030–1047. Liu, W., Islama j Do˘ gan, R., Kim, S., Comeau, D. C., Kim, W., Y eganov a, L., Lu, Z., and Wilbur, W. J. (2014). Author name disambiguation for pubmed. Journal of the Asso ciation for Information Scienc e and T e chnolo gy , 65(4):765–781. Loupp e, G., W ehenkel, L., Sutera, A., and Geurts, P . (2013). Understanding v ariable imp ortances in forests of randomized trees. In A dvanc es in Neur al Information Pr o c essing Systems , pages 431–439. Malin, B. (2005). Unsup ervised name disambiguation via social net work similarit y . In Workshop on link analysis, c ounterterr orism, and se curity , volume 1401, pages 93–102. McRae-Sp encer, D. M. and Shadbolt, N. R. (2006). Also by the same author: Aktiveauthor, a citation graph approac h to name disam biguation. In Pr o c e e dings of the 6th ACM/IEEE- CS joint c onfer enc e on Digital libr aries , pages 53–54. ACM. Newman, M. E. (2001). The structure of scien tific collab oration netw orks. Pr o c e e dings of the National A c ademy of Scienc es , 98(2):404–409. P edregosa, F., V aroquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P ., W eiss, R., Dub ourg, V., V anderplas, J., Passos, A., Cournapeau, D., Bruch er, M., Perrot, M., and Duchesna y , E. (2011). Scikit-learn: Mac hine learning in Python. Journal of Machine L e arning R ese ar ch , 12:2825–2830. Philips, L. (2000). The double metaphone search algorithm. C/C++ Users J. , 18(6):38–43. Ruggles, S., Sob ek, M., Fitc h, C. A., Hall, P . K., and Ronnander, C. (2008). Inte gr ate d public use micr o data series . Historical Census Pro jects, Department of History , Univ ersit y of Minnesota. 13 Sc h ulz, C., Mazloumian, A., P etersen, A. M., Penner, O., and Helbing, D. (2014). Exploiting citation netw orks for large-scale author name disambiguation. EPJ Data Scienc e , 3(1):1– 14. Smalheiser, N. R. and T orvik, V. I. (2009). Author name disambiguation. A nnual r eview of information scienc e and te chnolo gy , 43(1):1–43. Soler, J. (2007). Separating the articles of authors with the same name. Scientometrics , 72(2):281–290. Song, Y., Huang, J., Councill, I. G., Li, J., and Giles, C. L. (2007). Efficien t topic-based unsup ervised name disam biguation. In Pr o c e e dings of the 7th ACM/IEEE-CS joint c on- fer enc e on Digital libr aries , pages 342–351. ACM. Strotmann, A. and Zhao, D. (2012). Author name disambiguation: What difference do es it mak e in author-based citation analysis? Journal of the Americ an So ciety for Information Scienc e and T e chnolo gy , 63(9):1820–1833. T aft, R. L. (1970). Name searc h techniques. T echnical Rep ort Special Rep ort No. 1, New Y ork State Identification and In telligence System, Albany , NY. The National Archiv es (2007). The soundex indexing system. T orvik, V. I. and Smalheise r, N. R. (2009). Author name disam biguation in medline. A CM T r ansactions on Know le dge Disc overy fr om Data (TKDD) , 3(3):11. T ran, H. N., Huynh, T., and Do, T. (2014). Author name disam biguation b y using deep neural net work. In Intel ligent information and datab ase systems , pages 123–132. Springer. T reeratpituk, P . and Giles, C. L. (2009). Disam biguating authors in academic publications using random forests. In Pr o c e e dings of the 9th ACM/IEEE-CS joint c onfer enc e on Digital libr aries , pages 39–48. ACM. T reeratpituk, P . and Giles, C. L. (2012). Name-ethnicity classification and ethnicity-sensitiv e name matching. In AAAI . Citeseer. W ard Jr, J. H. (1963). Hierarc hical grouping to optimize an ob jective function. Journal of the Americ an statistic al asso ciation , 58(301):236–244. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment