Weighted Spectral Cluster Ensemble
Clustering explores meaningful patterns in the non-labeled data sets. Cluster Ensemble Selection (CES) is a new approach, which can combine individual clustering results for increasing the performance of the final results. Although CES can achieve be…
Authors: Muhammad Yousefnezhad, Daoqiang Zhang
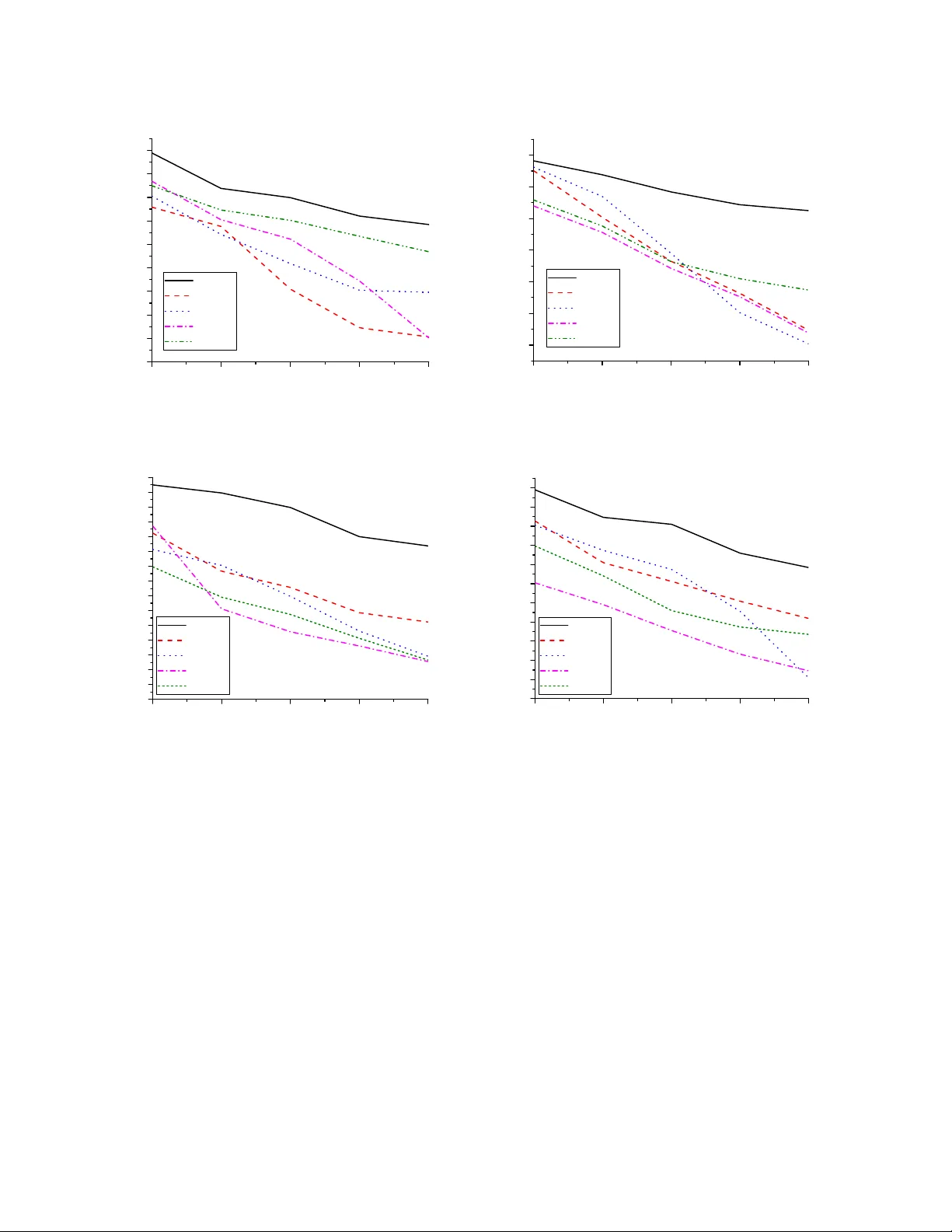
W eighted Spectral Cluster Ensemble Muhammad Y ousefnezhad Department of Computer Science and T echnolo gy Nanjing University of Aer onautics and Astr onautics Nanjing, China myousefnezhad@nuaa.edu.cn Daoqiang Zhang Department of Computer Science and T echnolo gy Nanjing University of Aer onautics and Astr onautics Nanjing, China dqzhang@nuaa.edu.cn Abstract —Clustering explores meaningful patter ns in the non-labeled data sets. Cluster Ensemble Selection (CES) is a new approach, which can combine individual clustering results for incr easing the performance of the final results. Although CES can achieve better final r esults in comparison with individual clustering algorithms and cluster ensemble methods, its perf ormance can be dramatically affected by its consensus diversity metric and thr esholding procedur e. There are two problems in CES: 1) most of the diversity metrics is based on heuristic Shannon’ s entropy and 2) estimating threshold values are really hard in practice. The main goal of this paper is proposing a rob ust approach for solving the above mentioned problems. Accordingly , this paper develops a novel framework for clustering problems, which is called W eighted Spectral Cluster Ensemble (WSCE), by exploiting some concepts from community detection arena and graph based clustering. Under this framework, a new version of spectral clustering, which is called T wo K ernels Spectral Clustering, is used for generating graphs based individual clustering results. Further , by using modularity , which is a famous metric in the community de- tection, on the transformed graph representation of individual clustering results, our approach provides an effective diversity estimation for indi vidual clustering results. Moreov er , this paper introduces a new approach for combining the evaluated individual clustering results without the procedure of thr esh- olding. Experimental study on varied data sets demonstrates that the prosed approach achieves superior performance to state-of-the-art methods. Keyw ords -cluster ensemble; spectral clustering; normalized modularity; weighted evidence accumulation clustering I . I N T R O D U C T I O N Clustering, the art of discov ering meaningful patterns in the non-labeled data sets, is one of the main tasks in machine learning. Generally , individual clustering algorithms provide different accuracies in a comple x data set because they generate the clustering results by optimizing a local or global function instead of natural relations between data points in each data set. [1], [2]. As a nov el solution, cluster ensemble which combines the different clustering results was proposed for achieving a better final result [1]. Cluster Ensemble Selection (CES) is a new solution which com- bines a selected group of best individual clustering results according to consensus metric(s) from ensemble committee in order to improve the accuracy of final results [3]. The ev aluation metric(s), thresholding and selection strategy , and aggregation method are the most important challenges in CES for selecting better partitions of ensemble committee and generating the final result. There are a wide range of ideas for solving mentioned challenges [3], [4], [5], [6], [7]. Although these methods can improv e performance and robustness of final results, using a wide range of threshold values and employing the entropy based metric are tw o main weak points of this method. Threshold v alues are different for each data set in the mentioned methods; and it is really hard to find optimum v alues in real-w orld applications. Moreov er, most of the real-world data sets do not have logarithm behavior . So, there is no prove that entropy based methods, which estimate the div ersity based on the logarithm, were the best choice to e valuate the di versity . This paper proposes a nov el methodology for solving clustering problems without mentioned weak points . As mentioned before, there are four stages in Cluster En- semble Selection (CES); i.e. generating individual clustering results, ev aluating, selecting and combining them as a final clustering result. Although CES can achie ve a better result in comparison with individual clustering algorithms and cluster ensemble methods, the accuracy of CES is fully sensitive to the process of thresholding for selecting indi vidual clustering results, and the consensus metric, which is used for diversity or quality estimation of the results. Unfortunately , it is so hard to find the optimum threshold values in practice; and most of the metrics, which were used for di versity or quality estimation, are heuristic; especially they are based on Shannons entropy . The main goal of this paper is solving mentioned problems. This paper proposes a new method for estimating the diversity of generated indi vidual clustering results by using a redefined version of modularity , which is based on expected value and it is introduced for the commu- nity detections applications. Further , this paper introduces a novel approach for combining the ev aluated individual clustering results without the process of thresholding. Our contribution in this paper can be summarized as follows: F irstly , this study proposes a greedy method based on feedback mechanism [8] which employs the idea of bisecting k-means for generating individual results. After that, this paper introduces the T wo Kernels Spectral Clus- tering (TKSC) for generating individual clustering results. This algorithm generates hybrid indi vidual clustering results, which contains Partitional results and Modular results. Same as simple clustering problems, our method generates Parti- tional results; and also it generates Modular results, which represented by a graph, as a ne w alternativ e for ev aluating and combining the individual results. Next, to satisfy the div ersity criterion, this study proposes Normalized Modu- larity , which is a redefined version of Modularity criterion in community detection [9], for e valuating diversity of individual results in the general clustering problems. Unlike most of the di versity metrics which are based on Shannon’ s entropy , this metric uses Expected V alue in probabilistic theory for ev aluating individual clustering results and av oids the undesired logarithm [9], [10]. Lastly , this paper proposed W eighted Evidence Accumulation Clustering (WEA C) to obtain the final clustering with a weighted combination of all individual results. While the weight of each individual result in WEAC can be estimated with different metrics, the normalized modularity was used in this paper . The rest of this paper is organized as follows: In Section 2, this study first briefly re vie ws some related works on cluster ensemble selection. Then, it introduces the proposed W eighted Spectral Clustering Ensemble (WSCE) framework in Section 3. Experimental results are reported in Section 4; and finally this paper presents conclusion and pointed out some future works in Section 5. I I . R E L A T E D W O R K S As an unsupervised method, Clustering discovers mean- ingful patterns in the non-labeled data sets. There is a wide range of studies, which try to increase the perfor- mance of clustering algorithms. For instance, Zhang et al. introduced a multi-manifold regularized nonnegati ve matrix factorization frame work (MMNMF) which can preserve the locally geometrical structure of the manifolds for multi-view clustering [11]. Anyway , indi vidual clustering algorithms provide dif ferent accuracies in a complex data set because they generate the clustering results by optimizing a local or global function instead of natural relations between data points in each data set [1], [2]. Generally , a cluster ensemble has two important steps: Firstly , generating indi vidual clustering results by using different algorithms and changing the number of their par - titions. Then, combining the primary results and generating the final ensemble. This step is performed by consensus functions (aggregating mechanism) [1], [12]. The idea that not all partitions are suitable for cooperating to generate the final clustering was proposed in CES [3]. Instead of combing all achieved individual results, CES can combine a selected group of best indi vidual results according to consensus metric(s) from the ensemble committee in order to improve the accuracy of final results [3], [5], [8], [4], [7]. Fern and Lin dev eloped a method to effecti vely select individual clustering results for ensemble and the final decision [3]. Azimi et al. prov ed that div ersity maximization is not an effecti ve approach in some real-world applications. They explored that the thresholding procedure must be done based on the complexity and quality of data sets [4]. Jia et al. proposed SIM for di versity measurement, which works based on the Normalized Mutual Information (NMI) [6]. Romano et al. proposed Standardized Mutual Information (SMI) for ev aluating clustering results [13]. Y ousefnezhad et al. introduced independency metric in- stead of quality metric for ev aluating the process of solving a problem in the CES [7]. Alizadeh et al. have concluded the disadvantages of NMI as a symmetric criterion. They used the APMM 1 and Maximum (MAX) metrics to measure div ersity and stability , respectiv ely , and suggested a new method for building a co-association matrix from a subset of base cluster results [5], [8]. Alizadeh et al. introduced W isdom of Crowds Cluster Ensemble (WOCCE), which is a novel method base on a theory in social science [8]. Although, this method can generate high performance and more stable results in comparison with other CES methods, using a wide range of thresholds and employing different types of clustering algorithms for generating individual results are two main problems in this method. Alizadeh et al. used A3, which is based on Shannon’ s entropy , for diversity ev aluation; and Basic Parameter Independency (BPI), which uses initialized v alues of individual clustering algorithms such as random seeds in the first iterative of k-means, for independency ev aluation. In addition, they introduced the feedback mechanism for generating the high-quality results [8]. As a graph based clustering methods, spectral clustering generates high-performance results when it is applied to dif- ferent applications; i.e. from image segmentation to commu- nity detection arena. Kuo et al. introduced a new method for automating the process of Laplacian creation in the medical applications; especially for fMRI segmentation where this method used standard Laplacians perform poorly [14]. Chen et al. proposed a clustering algorithm which is based graph clustering and optimizing an appropriate weighted objectiv e, where larger weights are giv en to observ ations (edge or no- edge between a pair of nodes) with lower uncertainty [15]. Gao et al. introduced a graph-based consensus maximization (BGCM) method for combining multiple supervised and unsupervised models. This method consolidated a classifi- cation solution by maximizing the consensus among both supervised predictions and unsupervised constraints [16]. I I I . T H E P R O P O S E D M E T H O D Giv en a set of high-dimensional data examples ˆ X = { ˆ x 1 , ˆ x 2 , . . . , ˆ x n } . The simple average of ˆ X can be denoted 1 Alizadeh-Parvin-Moshki-Minaei as follows: ¯ X = 1 n n X i =1 ˆ x i (1) where n is the number of instances in the ˆ X ; and ˆ x i denotes the i − th instance of the data points. At the beginning, this paper minimized the correlation between features. So, it denotes X as follows: X = ˆ X − ¯ X = { ( ˆ x 1 − ¯ x 1 ) , ( ˆ x 2 − ¯ x 2 ) , . . . , ( ˆ x n − ¯ x n ) } (2) where ˆ X is the data points, and ¯ X denotes simple average of ˆ X , which calculated by (1). It’ s clear that X is zero-mean. In other words, the excepted v alue of X is zero as follows: E { X } = 0 (3) Now , this paper maps Q : X ∈ R m × n → Y ∈ R m × n , where m , n denote the number of features and data points, respec- tiv ely . This mapping just minimizes the correlation between features. This problem can be reformulate as follows: Y = Q T X (4) If the correlation (cov ariance) of X is considered R = E { X X T } = 1 n P n i =1 x i x T i , then the correlation of Y will be defined as follows: E { Y Y T } = E { ( Q T X )( Q T X ) T } = E { Q T X X T Q } = Q T E { X X T } Q = Q T RQ (5) Based on above definition, the expected value of j − th feature of X denotes as follows: E { Y j Y T j } = q T Rq (6) where q denotes the j − th index of the Q . In other words, our correlation problem is changed to a v ariance probe. No w , maximizing the q based on the variance of X will be omitted the correlation between features. Since the scale of data after mapping must be same, we assume following equation: k q k = 1 (7) For maximizing the (6), which is denoted by Ψ( q ) , our problem will be reformulated as follows: max [Ψ( q ) = q T Rq ] ⇒ ∂ Ψ( q ) ∂ q = 0 ⇒ Ψ( q + δ q ) = Ψ( q ) ⇒ ( q + δ q ) T R ( q + δ q ) = q T Rq (8) where the symbol δ q is an abbreviation for ‘a small change in q’. W e consider ( δ q ) T δ q ≈ 0 , so the abov e definition denotes as follows: ( δ q ) T Rq = 0 (9) Based on (7) and (8), we can assume as follows: k δ q − q k = k q k = 1 ⇒ ( δ q ) T q = 0 (10) Now , this paper defines following equation by using (9) and (10): ( δ q ) T Rq − λ ( δ q ) T q = 0 ⇒ ( δ q ) T [ Rq − λq ] = 0 (11) where λ ∈ R is a constant. Since ( δ q ) T 6 = 0 , the follo wing equation must be satisfy for minimizing correlation between features: Rq = q λ (12) where R and λ denotes the eigenv ectors and eigen values, respectiv ely . For all features of X the above equation will be denoted as follows: RQ = Q Λ (13) which is called eigenstructure equation. In abov e equation, Λ is a diagonal matrix. Based on (7), we can define following equation: k q k 2 = 1 ⇒ Q T Q = I (14) where I is identity matrix. Following equation denotes based on (13) and (14): RQ = Q Λ ⇒ RQQ T = Q Λ Q T ⇒ R I = Q Λ Q T ⇒ R = Q T Λ Q ⇒ R = m X j =1 λ j q i q T j (15) where m denotes number of features in data X . Now , consider that R is a descending order based on Λ values. For an optional feature selection we can define the following equation instead of (15): R = d X j =1 λ j q i q T j (16) where d < m is the number of features, which must be selected for generating results. Algorithm 1 shows the mapping function, which can minimized correlation of data set based on abov e definitions. For generating individual clustering results, the proposed method partitions Y into C l clusters, where k denotes number of clusters in the individual results, and C l is l − th individual result in the reference set. This paper uses the range of l ∈ [ 2 , k + 2 ] for generating individual results, where k is the number of clusters in the final result. This is the same as bisect k-means algorithms but instead of applying the algorithm on generated results in each iterati ve, our proposed method stores this result on the ensemble committee; and then ev aluates and combines these results. In other words, the reference set denotes ζ ∈ R n × [2 ,k +1] = { C l } = { C 2 , . . . , C k +2 } . Algorithm 1 The Mapping Function Input: Data set ˆ X ∈ R m × n = { ˆ x 1 , ˆ x 2 , . . . , ˆ x n } , d as number of features: d = 0 is consider ed for deactivating the featur e selection Output: Mapped data set Y Method: 1. Calculating simple av erage ¯ X by using (1). 2. Calculating X by using (2). 3. Calculating R = E { X X T } = 1 n P n i =1 x i x T i . 4. Calculating Λ and Q as eigen values/vectors of R . 5. Sorting Q based on descending values of λ . 6. if d is not zero ( d 6 = 0 ) then selecting [1 , d ] features of Q , and sorting as Q d , else Q d = Q , d = m . end if 7. Return Y = Q T d X . Like other spectral methods, this paper calculates the non-symmetric distances (adjacency) matrix of Y , which is denoted by A [17], [18]. In the rest of this paper, our proposed method will be applied to the matrix A for each individual clustering results. Moreov er , this paper uses (17) as transform function for con verting distances matrix A to similarity matrix S . This transformation can optimize the memory usage [17], [18]. S i,j = ( exp −k y i − y j k 2 φ 2 if i 6 = j 0 if i = j (17) where y n denotes the n − th data point and k y i − y j k 2 will be calculated by Euclidean distance. The scaling parameter φ controls ho w rapidly affinity S i,j falls of f with the distance between the data points. This paper uses Ng et al. method for estimating this value automatically (count non-zero v alues in each columns of distance matrix A ) [17], [18]. This paper introduces T wo Kernels Spectral Clustering (TKSC) algorithm, which can generate all indi vidual results ( ζ ). Unlike normal clustering algorithms, which just generate a partition as the result, the TKSC algorithm generates two independent consequences, which are called Partitional re- sult and Modular result, for each of the individual clustering results by using two kernels ( C l = { P l , M } ). Partitional result ( P l ) is a partitioning of data points same as the result of other clustering methods; and Modular result ( M ) is a network of data points, which can be represented by a graph. This paper uses Modular result as a reference for e v aluating the div ersity of generated partition by using community de- tection methods [9], [10]. Furthermore, kernel in the TKSC refers to Laplacian equation in spectral methods because it transforms data points in new environment, especially linear en vironment for non-linear data sets. Partitional Kernel: This paper uses following equation for generating Partitional result: L P = I − D 1 / 2 S D 1 / 2 (18) where I is the identity matrix [17]; D is the diagonal matrix of S ( D = diag ( S ) ); and S will be calculated by (17). As shows in follo ws, the eigendecomposition is performed for calculating eigen vectors of L P : V = eig ens ( L P ) (19) where the matrix V is the eigenv ectors of Partitional Kernel. The coefficient W will be defined for normalizing the matrix V : W i = n X i =1 V i 1 × V i 2 ! 1 2 + (20) where V ij shows the i-th row and j-th column of the matrix V ; and is used for omitting the effect of zeros in the matrix W . This paper uses = 10 − 20 for generating the experimental results. Also, n denotes the number of instances in the data set ( W ∈ R n ). The normalized matrix of eigen vectors will be calculated as follows: U ij = V ij × W i (21) where U ij and V ij denote the i-th row and j-th column of these matrices; and W i is the i-th ro w of the matrix W which is used for normalization. The Partitional result of TKSC will be calculated by applying the simple k-means [8] on the matrix U as follows: P l = k means ( U, l ) (22) where K is the number of classes in individual results; and U will be calculated by (21). Modular Ker nel: This paper uses following equation for generating Modular result: L M = D − S (23) where D is the diagonal matrix of S ( D = diag ( S ) ); and S will be calculated by (17). This paper considers the normalized matrix of L M an adjacency matrix of graph representation of individual result as follows: M = 1 max ( L M ) L M (24) where L M is calculated by (23), and the function max finds the biggest value in the matrix L M . Further , all values in the matrix M , which is called Modular result, are between zero and one. Algorithm 2 shows the pseudo code of the TKSC method. T racing errors can control similarity and repetition of specific answers in clustering problems. There is a wide range of metrics, which are based on Shannon’ s entropy[8], [5], for ev aluating the diversity of individual results in the CES methods, such as MI [1], NMI [12], APMM [5], MAX [8], and SMI [13]. Shannon’ s entropy uses the logarithm of probability of individual results for Algorithm 2 T wo Kernels Spectral Clustering (TKSC) Input: Distance matrix A , Number of clusters l Output: Partitional result P l , Modular result M Method: 1. Generate similarity matrix S by using A on (17). 2. Generate diagonal matrix D by using S . 3. Generate L P by applying S and D on (18). 4. Generate L M by using S and D on (23). 5. Generate the matrix V as eigenv ectors of L p . 6. Generate U as normalized V by using (20) and (21). 7. Generate M by applying L M on (24). 8. P l = k means ( U, l ) 9. Return P l and M ev aluating the diversity but there is no mathematical prove that all real-world data sets ha ve logarithmic behavior . In community detection arena [9], [10], Modularity , which is based on Expected V alue, was proposed for solving this problem. Recently , many papers proved that modularity [9], [10] can estimate the div ersity on graph data sets better than entropy based methods. Unfortunately , modularity can measure the div ersity only for graph data [9]. This paper proposes TKSC, which can generate a graph based result, called Modular result, for an y types of data sets in real-world application. Since modularity was defined for community detection arena, this paper introduces a redefined version of modularity metric for general clustering problems, which is called Normalized Modularity ( N M ). It is used for ev aluating the div ersity of the individual results based on Modular result of the TKSC as follows: N M ( P l , M ) = 1 2 + 1 4 z X ij h Γ ij − σ i σ j 2 z i Θ ( c i , c j ) (25) where P l and M are calculated by (22) and (24), respec- tiv ely; z is sum of all cells in the matrix M ( z = P M M ij ); and c i and c j are the cluster’ s numbers of the i-th and j-th instances in the Partitional result P l . Also, σ i and σ j show the degree of i-th and j-th nodes in the graph of matrix M (How many rows contains non-zero value in the columns i or j ). In addition Γ ij and Θ ( c i , c j ) will be calculated as follows: Γ ij = 0 if M ij = 0 1 Otherwise (26) Θ ( c i , c j ) = 1 if c i = c j 0 Otherwise (27) This div ersity ev aluation is 0 ≤ N M ≤ 1 . In the rest of this section, we describe how N M will be used for ev aluating individual clustering results. Thresholding is used for selecting the ev aluated individual results in the CES. Then co-association matrix is generated by using consensus function on the selected results. Lastly , the final result is generated by applying linkage methods on the co-association Figure 1. In the traditional EAC, the α ( i,j ) represents the number of clusters shared by objects with indices (i, j); and β ( i,j ) is the number of partitions in which this pair of instances (i and j) is simultaneously presented. This method assumes the weights of all individual clustering results ( α ( i,j ) ) are the same. This paper proposes W eighted EA C for optimizing this method by using a weight for each individual clustering results instead of just counting their shared clusters. While the weight can hav e different definitions in the other applications, this paper uses average of Normalized Modularity (NM) of two algorithms as the weight in the WEA C ( ¯ α ( i,j ) = P α ( i,j ) ρ i,j ). matrix. These methods generate the Dendrogram and cut it based on the number of clusters in the result [12], [8]. In recent years, many papers hav e used EA C as a high- performance consensus function for combining individual results [12], [5], [8], [4], [3]. EA C uses the number of clusters shared by objects over the number of partitions in which each selected pair of objects is simultaneously presented for generating each cell of the co-association matrix. Figure 1 illustrates the effect of the EAC equation ( c ( i, j ) = α ( i,j ) β ( i,j ) ) on the shape of Dendrogram. Where α ( i,j ) represents the number of clusters shared by objects with indices (i, j); and β ( i,j ) is the number of partitions in which this pair of instances (i and j) is simultaneously presented. As a matter of fact; EA C considers that the weights of all algorithms results are the same. Instead of counting these indices, this paper uses follo wing equation, which is called W eighted EA C (WEA C), for generating the co-association matrix. c ( i, j ) = P α ( i,j ) ρ i,j β ( i, j ) (28) where α ( i, j ) and β ( i, j ) are same as the EA C equation; Also, ρ i,j is the weight of combining the instances. Although this weight can have dif ferent definitions in the other appli- cations, this paper uses a verage of Normalized Modularity of two algorithms as follows for combining individual results: ρ ij = 1 2 ( N M i + N M j ) (29) where N M i and N M j illustrates the Normalized Mod- ularity of the algorithms, which generate the results for indices i and j . In other words, as a new mechanism, this paper generates the effecti ve results when both algorithms hav e high NM values; and also the ef fects of individual results are near of zero when the both algorithms ha ve small values in the NM metric. As a result, this paper just omits the effect of low quality individual results by using mentioned mechanism instead of selecting them by thresholding procedures. Further , the final co-association matrix, which is a symmetric matrix, will be generated by (28) as follows: ξ = W E AC ( ζ ) = c (1 , 1) c (1 , 2) . . . c (1 , n ) c (2 , 1) c (2 , 2) . . . c (2 , n ) . . . . . . . . . . . . c ( i, 1) c ( i, 2) c ( i, j ) c ( i, n ) . . . . . . . . . . . . c ( n, 1) c ( n, 2) . . . c ( n, n ) (30) where n is the number of data points; and c ( i, j ) denotes the final aggregation for i − th and j − th instances. Algorithm 3 illustrates the pseudo code of the proposed method. In this algorithm, ˆ X is the data set; k is the number of clusters in the final result; P f is the final result partition. The distances are also measured by an Euclidean metric. The TKSC function b uilds the partitions and modules of indi vidual results; and NM function ev aluates these results by using (25). Then, the ev aluated results will be added to reference set. The WEA C function generates the co-association matrix, according to (28), by using the Normalized Modularity values and Partitional results. The A verage-Linkage function creates the final ensemble according to the a verage linkage method [5], [8]. Algorithm 3 The W eighted Spectral Cluster Ensemble Input: Data points ¯ X , Number of clusters k , Number of features d. Output: final result P f Method: 1. Generate Y by using ¯ X and d on Algorithm 1. 2. Generate matrix A by using Y based on [17]. 3. f or l = 2 to k + 2 do 4. P l , M = T K S C ( A, l ) by using Algorithm 2. 5. Q = N M ( P l , M ) based on (25) 6. Add [ P , Q ] to ζ as the reference set. 7. end for 8. Generate co-association matrix ξ = W E AC ( ζ ) 9. P f = Av erag e − Link age ( ξ ) I V . E X P E RI M E N T S The empirical studies will be presented in this section. The unsupervised methods are used to find meaningful patterns in non-labeled datasets such as web documents, etc. in real world application. Since the real dataset doesnt hav e class labels, there is no direct e v aluation method for estimating the performance in unsupervised methods. Like many pervious researches [12], [3], [5], [8], [7], this paper compares the performance of its proposed method with other individual clustering methods and cluster ensemble (selection) methods by using standard datasets and their real classes. Although this ev aluation cannot guarantee that the proposed method generate high performance for all datasets in comparison with other methods, it can be considered as an example for analyzing the probability of predicting good results in the WSCE. The results of the proposed method are compared with individual algorithms k-means [8] and Maximum Likelihood Estimator (MLE) [15], as well as APMM [5], WOCCE [8], SMI [13], and BGCM [16] which are state-of-the-art cluster ensemble (selection) methods. This paper reported the empirical results of k-means algorithm as one of the classical clustering methods. Furthermore, as a new alter- nativ e in the clustering methods, the empirical results of the proposed method are compared with the MLE, SMI, and BGCM methods. Also, this paper uses the unsupervised version of BGCM method (with the null set of supervision information). For representing the effect of Uniformity on the performance of the final results, it compares with two state-of-the-art metrics in di versity ev aluation (APMM and SMI). The last but not least, the experimental results of this paper are compared with the WOCCE as another method in the CES, which uses the independency estimation. All of these algorithms are implemented in the MA TLAB R2015a (8.5) by authors 2 in order to generate e xperimental results. All results are reported by a veraging the results of 10 independent runs of the algorithms which are used in the experiment. Also, the number of individual clustering results in the reference set of the ensemble is set as 20 for all of mentioned algorithms in all of experiments on a PC with certain specifications 3 . A. Data Sets This paper uses three different groups of data sets for generating experimental results; i.e. image based data sets, document based data sets and others. T able I illustrates the properties of these data sets. This paper uses the USPS digits data set, which is a collection of 16 × 16 gray-scale images of natural handwritten digits and is av ailable from [19]. Furthermore, this paper uses Alzheimer’ s Diseases Neuroimaging Initiativ e (ADNI) data set for 202 subjects as another image based real-world data set. This data set contains MRI and PET images from human Brian in two categories (which are sho wn by C1 and C2 in the T able I 2 The proposed method is av ailable http://sourceforge.net/projects/myousefnezhad/files/WSCE/ 3 Apple Mac Book Pro, CPU = Intel Core i7 (4*2.4 GHz), RAM = 8GB, OS = OS X 10.10 T able II T H E P ER F O R MA N C E O F C L U ST E R I NG A LG O R I TH M S . F U RT HE R , T H E O P TI O NA L FE ATU R E S E L EC T I O N I S N OT U S E D F O R T H E P RO P OS E D M E T HO D ( d = 0 ) . Data Sets Spectral MLE APMM WOCCE SMI BGCM WSCE 20 Ne wsgroups 14.31 ± 2.14 21.89 ± 1.02 28.03 ± 0.87 32.62 ± 0.52 29.14 ± 0.91 40.61 ± 0.83 52.06 ± 0.17 ADNI-MRI-C1 39.24 ± 0.21 39.84 ± 0.42 48.01 ± 0.56 48.82 ± 0.37 50.69 ± 0.69 45.54 ± 0.99 49.53 ± 0.19 ADNI-MRI-C2 32.72 ± 0.98 26.32 ± 0.67 39.93 ± 0.29 40.22 ± 0.44 38.32 ± 0.41 42.62 ± 1.04 41.14 ± 0.71 ADNI-PET -C1 43.71 ± 0.52 37.96 ± 0.87 48.37 ± 0.82 49.19 ± 0.26 49.45 ± 0.62 42.1 ± 0.78 52.05 ± 0.37 ADNI-PET -C2 37.27 ± 0.23 37.91 ± 0.83 38.53 ± 0.17 39.43 ± 0.79 41.76 ± 0.47 39.1 ± 1.2 43.11 ± 0.42 ADNI-FUL-C1 42.63 ± 0.63 42.62 ± 0.58 47.22 ± 0.93 48.82 ± 0.41 47.93 ± 0.83 48.56 ± 1.26 49.06 ± 0.36 ADNI-FUL-C2 39.51 ± 1.19 41.06 ± 0.17 50.09 ± 0.35 49.39 ± 0.63 49.16 ± 0.26 46.91 ± 0.42 50.11 ± 0.09 Arcene 58.31 ± 1.22 64.19 ± 0.498 66.28 ± 0.216 65.16 ± 0.32 67.14 ± 0.93 64.23 ± 0.28 73.34 ± 0.92 Bala. Scale 49.21 ± 0.87 52.76 ± 0.12 52.65 ± 0.63 54.88 ± 0.61 59.98 ± 0.812 59.62 ± 0.32 61.64 ± 0.12 Breast Can. 94.88 ± 1.14 82.65 ± 0.342 96.04 ± 0.88 96.92 ± 0.77 80.87 ± 0.652 99.12 ± 0.62 99.21 ± 0.43 Bupa 56.72 ± 1.18 53.98 ± 0.274 55.07 ± 0.28 57.02 ± 0.46 58.49 ± 0.21 53.17 ± 0.21 60.93 ± 0.09 CN AE-9 65.32 ± 0.43 77.72 ± 0.591 77.42 ± 0.792 79.2 ± 0.579 74.25 ± 0.614 80.12 ± 0.459 88.42 ± 0.02 Galaxy 31.24 ± 0.67 34.25 ± 0.872 33.72 ± 0.36 35.88 ± 0.81 35.21 ± 0.413 36.91 ± 0.17 39.89 ± 0.82 Glass 45.78 ± 0.87 50.32 ± 0.42 47.19 ± 0.21 51.82 ± 0.92 54.19 ± 0.144 53.66 ± 0.98 55.19 ± 0.51 Half Ring 80.61 ± 1.15 73.91 ± 0.762 80 ± 0.42 87.2 ± 0.14 71.19 ± 0.621 98.37 ± 0.59 99.92 ± 0.08 Ionosphere 69.71 ± 0.67 25.67 ± 0.53 70.94 ± 0.13 70.52 ± 0.132 70.87 ± 0.226 73.67 ± 0.341 76.25 ± 0.28 Iris 83.45 ± 0.82 89.02 ± 0.61 74.11 ± 0.25 92 ± 0.59 93.79 ± 0.21 97.29 ± 0.09 96.53 ± 0.32 Optdigit 54.19 ± 0.45 73.81 ± 0.69 77.1 ± 0.841 77.16 ± 0.21 80.21 ± 0.79 71.56 ± 0.692 82.82 ± 0.33 Pendigits 53.94 ± 0.25 59.36 ± 0.31 47.4 ± 0.699 58.68 ± 0.18 63.74 ± 0.37 63.13 ± 0.42 65.02 ± 0.91 Reuters-21578 48.78 ± 3.19 52.58 ± 1.92 65.23 ± 0.62 68.85 ± 0.32 62.92 ± 1.02 71.69 ± 0.51 78.34 ± 0.15 SA Hart 69.59 ± 0.08 61.69 ± 0.44 70.91 ± 0.42 68.7 ± 0.46 70.05 ± 0.51 73.92 ± 0.72 72.8 ± 0.82 Sonar 53.24 ± 0.62 54.93 ± 0.26 54.1 ± 0.91 54.39 ± 0.25 57.64 ± 0.47 52.06 ± 0.873 61.29 ± 0.11 Statlog 42.87 ± 0.62 52.35 ± 0.79 54.88 ± 0.528 55.77 ± 0.719 53.73 ± 0.52 55.76 ± 0.591 57.92 ± 0.26 USPS 62.67 ± 0.13 59.72 ± 0.62 63.91 ± 0.94 65.21 ± 0.69 68.73 ± 0.66 65.38 ± 1.02 70.37 ± 0.01 W ine 73.09 ± 1.38 83.81 ± 0.41 64.6 ± 0.231 71.34 ± 0.542 88.46 ± 0.71 87.34 ± 0.24 90.44 ± 0.02 Y east 32.96 ± 0.71 30.49 ± 0.63 31.06 ± 0.245 32.76 ± 0.268 35.19 ± 0.57 28.12 ± 0.462 36.92 ± 0.81 T able I T H E S T A N DA R D DAT A S E T S Data Set Instances Features Class 20 Ne wsgroups 26214 18864 20 ADNI-MRI-C1 202 93 3 ADNI-MRI-C2 202 93 4 ADNI-PET -C1 202 93 3 ADNI-PET -C2 202 93 4 ADNI-FUL-C1 202 186 3 ADNI-FUL-C2 202 186 4 Arcene 900 10000 2 Bala. Scale 625 4 3 Brea. Cancer 286 9 2 Bupa 345 6 2 CN AE-9 1080 857 9 Galaxy 323 4 7 Glass 214 10 6 Half Ring 400 2 2 Ionosphere 351 34 2 Iris 150 4 3 Optdigit 5620 62 10 Pendigits 10992 16 10 Reuters-21578 9108 5 10 SA Hart 462 9 2 Sonar 208 60 2 Statlog 6435 36 7 USPS 9298 256 10 W ine 178 13 2 Y east 1484 8 10 and II) for recognizing the Alzheimer diseases. In the first category , this data set partitions subjects to three groups of Health Control (HC), Mild Cognitive Impairment (MCI), and Alzheimer’ s Diseases (AD). In the second category , there are four groups because the MCI will be partitioned to high and low risk groups (HMCI/LMCI). This paper uses all possible forms of this data set by using only MRI features, only PET features and all of MRI and PET features (FUL) in each of two categorize. More information about ADNI-202 is av ailable in [20]. As a document based data set, the 20 Newsgroups is a collection of approximately 20,000 newsgroup documents, partitioned (nearly) evenly across 20 different ne wsgroups. Some of the newsgroups are very closely related to each other, while others are highly unrelated. It has become a popular data set for experiments in text applications of machine learning techniques, such as text classification and text clustering. Moreover , the Reuters- 21578 is one of the most widely used test collections for text classification research. This data set was collected and labeled by Carnegie Group, Inc. and Reuters, Ltd. W e use the 10 largest classes of this data set. The rest of standard data sets are from UCI [21]. The chosen data sets hav e div ersity in their numbers of clusters, features, and samples. Further , their features are normalized to a mean of 0 and variance of 1, i.e. N (0, 1). 5 10 15 20 25 25 30 35 40 45 50 55 60 65 70 Performance (%) Percentages of noise in features (%) WSCE BGCM SMI APMM WOCCE (a) Arcene 5 10 15 20 25 30 35 40 45 50 55 60 Perfromance (%) Parcentages of noise in features (%) WSCE BGCM SMI APMM WOCCE (b) CN AE-9 Figure 2. The effect of noisy data sets on the performance. 5 10 15 20 25 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 Performance (%) Percentages of missed-values in features (%) WSCE BGCM SMI APMM WOCCE (a) Arcene 5 10 15 20 25 38 40 42 44 46 48 50 52 54 56 58 60 Performance (%) Percentages of missed-values in features (%) WSCE BGCM SMI APMM WOCCE (b) CN AE-9 Figure 3. The effect of missed-values on the performance. B. P erformance analysis In this section the performance (accuracy metric [8]) of proposed method will be analyzed. In other words, the final clustering performance was ev aluated by re-labeling between obtained clusters and the ground truth labels and then counting the percentage of correctly classified samples [8]. The results of the proposed method are compared with individual algorithms Spectral clustering[17] and MLE [15], as well as APMM [5], WOCCE [8], SMI [13], and BGCM [16] which are state-of-the-art cluster ensemble (selection) methods. The main reason for comparing the proposed method with Spectral clustering is to show the effect of TKSC framework on the performance of the final results. Furthermore, as a new alternativ e in the graph based clustering methods, the empirical results of WSCE are compared with the MLE and BGCM methods. This paper uses the unsupervised version of BGCM method (with the null set of supervision information). For representing the effect of Normalized Modularity on the performance of the final results, it compares with three state-of-the- art metrics in di versity ev aluation (A3, APMM and SMI), which are based on Shannons entropy . This paper doesn’t use optional feature selection in this section ( d = 0 ). The experimental results are giv en in T able II. In this table, the best result which is achiev ed for each data set is highlighted in bold. As depicted in this table, although individual cluster - ing algorithms (Spectral and MLE) hav e shown acceptable performance in some data sets, they cannot recognize true patterns in all of them. As mentioned earlier in this paper , in order to solve the clustering problem, each individual algorithm considers a special perspective of a data set which is based on its objective function. The achiev ed results of individual clustering algorithms, which are depicted in T able II are good evidence for this claim. Furthermore, the results generated by APMM, SMI, and WOCCE show the effect of the aggregation method on improving accuracy in the final results. According to T able II, BGCM and the proposed algorithm (WSCE) hav e generated better results in comparison with other individual and ensemble algorithms. Even though the proposed method was outperformed by a number of algorithms in four data sets (Iris, SA Hart, and ADNI-MRI-C1/C2), the majority of the results demonstrate the superior accuracy of the proposed method in comparison with other algorithms. In addition, the difference between the performance of proposed method and the best result in those four data sets is lower that 2%. C. Noise and missed-values analysis The effect of noise and missed-values on the performance of clustering algorithms will be discussed in this section. The optional feature selection for the proposed method doesn’t use in this section (d = 0). In Figure 2, the ef fect of noise in the features of data sets will be analyzed on the performance of proposed method. This figure represents the performance of the WSCE, WOCCE, BGCM, SMI, and APMM on the noisy data sets. In this experiment, some features of Arcene and CN AE-9 data sets are randomly changed. This figure shows that proposed method generates more stable results because the Normalized Modularity provides a robust div ersity ev aluation for selecting most stable individual results. As mentioned before, Shannon’ s entropy uses the logarithm of probability of individual results for e v aluating the diversity but there is no mathematical prove that all real- world data sets have logarithmic behavior . This experiment is the best evidence for this claim. Figure 3 demonstrates the analysis for the ef fect of missed-values in the data sets on the performance of clustering algorithms. This figure illustrates the performance of the WSCE, WOCCE, BGCM, SMI, and APMM on the data sets with missed-values. In this experiment, some v alues of attributes of Arcene and CN AE-9 data sets are randomly missed (set null). As you can see in this Figure, the proposed method and BGCM generate more stable results. This is a ne w advantage of our proposed method in comparison other non-graph based methods. Since, our proposed method uses the TKSC algo- rithms for generating Partitional and Modular results, it can significantly handle the miss v alues. In other words, as a local error in the indi vidual results, a missed-value just can destroy an edge in our Modular result, which can be rec- ognized by comparing Modular result with Partitional result in the div ersity ev aluation by using the NM metric. That is another reason for exploiting the proposed framework in the clustering problems. D. P arameter analysis In this section the performance of the proposed method will be analyzed by using the optional features selection 100 90 80 7 0 60 50 30 35 40 45 50 55 60 65 70 75 80 85 90 95 Performance (%) Percentage of selected features (%) 20 NEWSGROUPS ARCENE ADNI-FUL-C2 USPS WINE Figure 4. The effect of optional features selection on the performance of proposed method. ( d parameter). This paper employs various data sets, i.e. two lo w dimension data sets (Wine, Glass), two high- dimension data sets (20 Newsgroups, Arcene), and tw o middle-dimension and also image based data sets (USPS, ADNI) for analyzing the performance of proposed method. Figure 4 illustrates the relationship between the performance of the proposed method based on the percentage of selected features in different data sets. The vertical axis refers to the performance while the horizontal axis refers to the percentage of selected feature in each data set. As you can see in this figure, the optional feature selection can significantly increase the performance of final results on high-dimensional data sets; and also it can dramatically decrease the performance on lo w-dimensional data sets. Further , it is not more ef fectiv e on the middle-dimension data sets. This paper offers that the optional features selection will be used only for high-dimensional data sets for handling features-sparsity . V . C O N C L US I O N There are two challenges in Cluster Ensemble Selection (CES); i.e. proposing a robust consensus metric(s) for diver - sity ev aluation and estimating optimum parameters in the thresholding procedure for selecting the ev aluated results. This paper introduces a novel solution for solving mentioned challenges. By employing some concepts from community detection arena and graph based clustering, this paper pro- poses a novel framew ork for clustering problems, which is called W eighted Spectral Cluster Ensemble (WSCE). Under this framework, a new version of spectral clustering, which is called T wo K ernels Spectral Clustering (TKSC), is used for generating graphs based individual clustering results; i.e. Partitional result and Modular result. Instead of entropy based methods in the traditional CES, this paper introduces Normalized Modularity (NM), which is a redefined version of modularity in the community detection arena for general clustering problems. The NM is used on the transformed graph representation of indi vidual clustering results for providing an effecti ve div ersity estimation. Moreover , this paper introduces a new solution for combining the ev aluated individual clustering results without the procedure of thresh- olding, which is called W eighted Evidence Accumulation Clustering (WEA C). While the weight of each individual result in WEAC can be estimated with different metrics, the NM was used in this paper . T o validate the effecti veness of the proposed approach, an extensiv e experimental study is performed by comparing with individual clustering methods as well as cluster ensemble (selection) methods on a large number of data sets. Results clearly show the superiority of our approach on both normal data sets and those with noise or missing values. In the future, we plan to develop a ne w version of normalized modularity for estimating the div ersity of Partitional results, directly . A C K N O W L E D G M E N T W e thank Dr . Sheng-Jun Huang for his helpful sug- gestions, and the anonymous revie wers for comments. This work was supported in part by the National Natural Science Foundation of China (61422204 and 61473149), Jiangsu Natural Science F oundation for Distinguished Y oung Scholar (BK20130034) and NU AA Fundamental Research Funds (NE2013105). R E F E R E N C E S [1] A. Strehl and J. Ghosh, “Cluster ensembles - a knowledge reuse framew ork for combining multiple partitions, ” Journal of Machine Learning Resear ch , vol. 3, pp. 583–617, 2002. [2] A. Fred and A. Lourenco, “Cluster ensemble methods: from single clusterings to combined solutions, ” Computer Intelli- gence , vol. 126, pp. 3–30, 2008. [3] X. Fern and W . Lin, “Cluster ensemble selection, ” in SIAM International Confer ence on Data Mining (SDM’08) , 24-26 April 2008, pp. 128–141. [4] J. Azimi and X. Fern, “ Adaptiv e cluster ensemble selection, ” in 21th International joint confer ence on artificial intelligence (IJCAI-09) , 11-17 July 2009, pp. 992–997. [5] H. Alizadeh, B. Minaei-Bidgoli, and H. Parvin, “Cluster ensemble selection based on a ne w cluster stability measure, ” Intelligence Data Analysis (IDA) , vol. 18, no. 3, pp. 389–40, 2014. [6] J. Jia, X. Xiao, and B. Liu, “Similarity-based spectral clus- tering ensemble selection, ” in 9th International Confer ence on Fuzzy Systems and Knowledge Discovery (FSKD) , 29-31 May 2012, pp. 1071–1074. [7] M. Y ousefnezhad, H. Alizadeh, and B. Minaei-Bidgoli, “New cluster ensemble selection method based on div ersity and independent metrics, ” in 5th Confer ence on Information and Knowledge T echnology (IKT’13) , 22-24 May 2013. [8] H. Alizadeh, M. Y ousefnezhad, and B. Minaei-Bidgoli, “W is- dom of cro wds cluster ensemble, ” Intelligent Data Analysis (ID A) , vol. 19, no. 3, 2015. [9] A. Clauset, M. Newman, and C. Moore, “Finding community structure in very lar ge networks, ” Physical Review E , vol. 70, no. 066111, 2004. [10] M. E. J. Newman, “Modularity and community structure in networks, ” Proceedings of the National Academy of Sciences of the United States of America , vol. 103, no. 23, pp. 8577– 8696, 2006. [11] X. Zhang, L. Zhao, L. Zong, and X. Liu, “Multi-view clustering via multi-manifold regularized nonnegativ e matrix factorization, ” in IEEE International Confer ence on Data Mining series (ICDM’14) , 15–17 December 2014. [12] A. Fred and A. K. Jain, “Combining multiple clusterings using evidence accumulation, ” IEEE T ransaction on P attern Analysis and Machine Intelligence , vol. 27, pp. 835–850, 2005. [13] S. Romano, J. Bailey , N. X. V inh, and K. V erspoor , “Stan- dardized mutual information for clustering comparisons: One step further in adjustment for chance, ” in 31st International Confer ence on Machine Learning (ICML14) , 21-26 June 2014, pp. 1143–1151. [14] C.-T . Kuo, P . W alker , O. Carmichael, and I. Davidson, “Spec- tral clustering for medical imaging, ” in IEEE International Confer ence on Data Mining series (ICDM’14) , 15–17 De- cember 2014. [15] Y . Chen, S. H. Lim, and H. Xu, “W eighted graph clustering with non-uniform uncertaintiese, ” in 31st International Con- fer ence on Machine Learning (ICML14) , 21-26 June 2014, pp. 1566–1574. [16] J. Gao, F . Liang, W . Fan, Y . Sun, and J. Han, “ A graph-based consensus maximization approach for combining multiple supervised and unsupervised models, ” IEEE T ransactions on Knowledge and Data Engineering , vol. 25, no. 1, pp. 15–2, 2013. [17] A. Ng, M. Jordan, and Y . W eiss, “On spectral clustering: Analysis and an algorithm, ” in Advances in Neural Informa- tion Pr ocessing Systems 14 (NIPS’01) , 2001, pp. 849–856. [18] D. Y an, L. Huang, and M. I. Jordan, “Fast approximate spectral clustering, ” in 15th A CM Confer ence on Knowledge Discovery and Data Mining (SIGKDD) , 2009. [19] S. Roweis. (1998) The world-famous courant institute of mathematical sciences, computer science department, ne w york university . [Online]. A v ailable: http://cs.nyu.edu/roweis/ data.html [20] C. Zu and D. Zhang, “Label-alignment-based multi-task fea- ture selection for multimodal classification of brain disease, ” in 4th NIPS W orkshop on Machine Learning and Interpr eta- tion in Neuroima ging (MLINI’14) , 13 December 2014. [21] C. B. D. J. Newman, S. Hettich, and C. Merz. (1998) Uci repository of machine learning databases. [Online]. A vailable: http://www .ics.uci.edu/mlearn/MLSummary .html
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment