Towards A Deeper Geometric, Analytic and Algorithmic Understanding of Margins
Given a matrix $A$, a linear feasibility problem (of which linear classification is a special case) aims to find a solution to a primal problem $w: A^Tw > \textbf{0}$ or a certificate for the dual problem which is a probability distribution $p: Ap = …
Authors: Aaditya Ramdas, Javier Pe~na
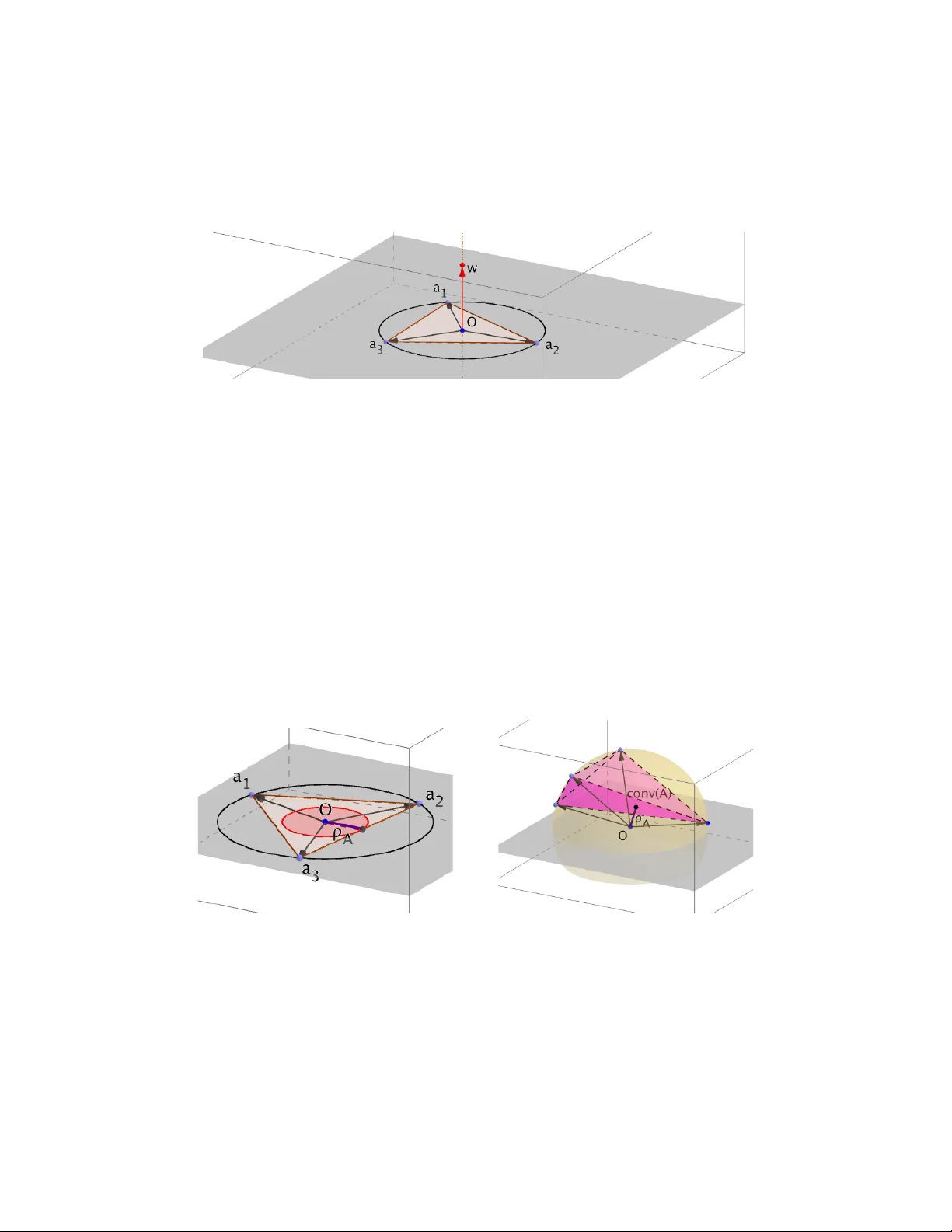
T o w ards A Deep er Geometric, Analytic and Algorithmic Understanding of Margins Aadit ya Ramdas Mac hine Learning Department Carnegie Mellon Univ ersity aramdas@cs.cmu.edu Ja vier P e ˜ na T epp er Sc ho ol of Business Carnegie Mellon Univ ersity jfp@andrew.cmu.edu June 25, 2018 Abstract Giv en a matrix A , a linear feasibilit y problem (of whic h linear classification is a spe- cial case) aims to find a solution to a primal problem w : A T w > 0 or a certificate for the dual problem which is a probabilit y distribution p : Ap = 0 . Inspired by the con- tin ued imp ortance of “large-margin classifiers” in machine learning, this pap er studies a condition measure of A called its mar gin that determines the difficulty of both the ab o ve problems. T o aid geometrical intuition, we first establish new c haracterizations of the margin in terms of relev ant balls, cones and hulls. Our second contribution is analytical, where w e presen t generalizations of Gordan’s theorem, and v ariants of Hoffman’s theorems, b oth using margins. W e end by pro ving some new results on a classical iterative scheme, the P erceptron, whose conv ergence rates famously dep ends on the margin. Our results are relev an t for a deep er understanding of margin-based learning and pro ving con vergence rates of iterativ e sc hemes, apart from providing a unifying persp ective on this v ast topic. 1 In tro duction Assume that w e ha v e a d × n matrix A represen ting n p oin ts a 1 , ..., a n in R d . In this pap er, w e will b e concerned with linear feasibility problems that ask if there exists a v ector w ∈ R d that makes p ositive dot-pro duct with every a i , i.e. ? ∃ w : A T w > 0 , (P) where b oldfaced 0 is a vector of zeros. The corresp onding algorithmic question is “if (P) is feasible, how quickly can we find a w that demonstrates (P)’s feasibility?”. Suc h problems ab ound in optimization as w ell as mac hine learning. F or example, consider binary line ar classific ation - given n p oin ts x i ∈ R d with lab els y i ∈ { +1 , − 1 } , a classifier w is said to separate the given p oin ts if w T x i has the same sign as y i or succinctly y i ( w T x i ) > 0 for all i . Representing a i = y i x i sho ws that this problem is a sp ecific instance of (P). 1 W e call (P) the primal problem, and (w e will later see wh y) we define the dual problem (D) as: ? ∃ p ≥ 0 : Ap = 0 , p 6 = 0 , (D) and the corresp onding algorithmic question is “if (D) is feasible, ho w quickly can we find a certificate p that demonstrates feasibility of (D)?”. Our aim is to deep en the geometric, algebraic and algorithmic understanding of the problems (P) and (D), tied together by a concept called mar gin . Geometrically , we pro vide in tuition ab out w ays to in terpret margin in the primal and dual settings relating to v arious balls, cones and h ulls. Analytically , w e prov e new margin-based versions of classical results in con vex analysis lik e Gordan’s and Hoffman’s theorems. Algorithmically , w e giv e new insights in to the classical P erceptron algorithm. W e b egin with a gen tle in tro duction to some of these concepts, b efore getting in to the details. Notation When w e write v ≥ w for vectors v , w , w e mean v i ≥ w i for all their indices i (similarly v ≤ w , v = w ). T o distinguish surfaces and interiors of balls more obviously to the eye in mathematical equations, w e choose to denote Euclidean balls in R d b y # := { w ∈ R d : k w k = 1 } , := { w ∈ R d : k w k ≤ 1 } and the probability simplex R n b y 4 := { p ∈ R n : p ≥ 0 , k p k 1 = 1 } . W e denote the linear subspace spanned b y A as lin( A ), and con v ex h ull of A by con v( A ). Lastly , define A := ∩ lin( A ) and r is the ball of radius r ( # A , r # are similarly defined). 1.1 Margin ρ The margin of the problem instance A is classically defined as ρ := sup w ∈ # inf p ∈4 w T Ap (1) = sup w ∈ # inf i w T a i . If there is a w such that A T w > 0 , then ρ > 0. If for all w , there is a p oint at an obtuse angle to it, then ρ < 0. A t the b oundary ρ can b e zero. The w ∈ # in the definition is imp ortan t – if it were w ∈ , then ρ would b e non-negativ e, since w = 0 w ould b e allow ed. This definition of margin was introduced by Goffin [13] who gav e several geometric inter- pretations. It has since b een extensively studied (for example, [20, 21] and [4]) as a notion of complexit y and conditioning of a problem instance. Broadly , the larger its magnitude, the b etter conditioned the pair of feasibility problems (P) and (D) are, and the easier it is to find a witnesses of their feasibilit y . Ev er since [25], the margin-based algorithms hav e b een extremely p opular with a gro wing literature in mac hine learning which it is not relev ant to presen tly summarize. In Sec. 2, we define an imp ortan t and “corrected” v ariant of the margin, whic h w e call affine-mar gin , that turns out to b e the actual quantit y determining con vergence rates of iterativ e algorithms. 2 Gordan’s Theorem This is a classical the or em of the alternative , see [3, 5]. It implies that exactly one of (P) and (D) is feasible. Sp ecifically , it states that exactly one of the follo wing statements is true. 1. There exists a w suc h that A T w > 0 . 2. There exists a p ∈ 4 suc h that Ap = 0 . This, and other separation theorems lik e F ark as’ Lemma (see ab ov e references), are widely applied in algorithm design and analysis. W e will later pro v e generalizations of Gordan’s theorem using affine-margins. Hoffman’s Theorem The classical v ersion of the theorem from [15] c haracterizes ho w close a p oint is to the solution set of the feasibility problem Ax ≤ b in terms of the amoun t of violation in the inequalities and a problem dep enden t constan t. In a n utshell, if S := { x | Ax ≤ b } 6 = ∅ then dist( x, S ) ≤ τ [ Ax − b ] + (2) where τ is the “Hoffman constan t” and it depends on A but is indep endent of b . This and similar theorems ha ve found extensive use in con vergence analysis of algorithms - examples include [12, 16, 23]. G ¨ uler, Hoffman, and Rothblum [14] generalize this b ound to an y norms on the left and righ t hand sides of the ab o ve inequalit y . W e will later prov e theorems of a similar fla vor for (P) and (D), where τ − 1 will almost magically turn out to b e the affine-margin. Suc h theorems are used for proving rates of conv ergence of algorithms, and ha ving the constan t explicitly in terms of a familiar quan tit y is useful. 1.2 Summary of Contributions • Geometric : In Sec.2, w e define the affine-mar gin , and argue wh y a subtle difference from Eq.(1) makes it the “right” quantit y to consider, esp ecially for problem (D). W e then establish geometrical characterizations of the affine-margin when (P) is feasible as well as when (D) is feasible and connect it to w ell-kno wn r adius the or ems . This is the pap er’s app etizer. • Analytic : Using the preceding geometrical insights, in Sec.3 w e prov e t w o generaliza- tions of Gordan’s Theorem to deal with alternatives inv olving the affine-margin when either (P) or (D) is strictly feasible. Building on this in tuition further, in Sec.4, w e pro ve sev eral interesting v arian ts of Hoffman’s Theorem, which explicitly in volv e the affine-margin when either (P) or (D) is strictly feasible. This is the pap er’s main course. • Algorithmic : In Sec.5, we pro v e new prop erties of the Normalized P erceptron, like its margin-maximizing and margin-appro ximating prop erty for (P) and dual conv ergence for (D). This is the pap er’s dessert. W e end with a historical discussion relating V on-Neumann’s and Gilb ert’s algorithms, and their adv an tage ov er the Perceptron. 3 2 F rom Margins to Affine -Margins An imp ortant but subtle p oint ab out margins is that the quantit y determining the difficult y of solving (P) and (D) is actually not the margin as defined classically in Eq.(1), but the affine-margin whic h is the margin when w is restricted to lin( A ), i.e. w = Aα for some co efficien t vector α ∈ R n . The affine-margin is defined as ρ A := sup w ∈ # A inf p ∈4 w T Ap = sup k α k G =1 inf p ∈4 α T Gp (3) where G = A T A is a k ey quantit y called the Gram matrix, and k α k G = √ α T Gα is easily seen to b e a self-dual semi-norm. In tuitively , when the problem (P) is infeasible but A is not full rank, i.e. lin( A ) is not R d , then ρ will never b e negative (it will alwa ys b e zero), b ecause one can alwa ys pic k w as a unit v ector p erp endicular to lin( A ), leading to a zero dot-pro duct with every a i . Since no matter how easily inseparable A is, the margin is alw ays zero if A is low rank, this definition do es not capture the difficulty of v erifying linear infeasibility . Similarly , when the problem (P) is feasible, it is easy to see that searching for w in directions p erp endicular to A is futile, and one can restrict attention to lin( A ), again making this the right quan tity in some sense. F or clarity , we will refer to ρ + A := max { 0 , ρ A } ; ρ − A := min { 0 , ρ A } (4) when the problem (P) is strictly feasible ( ρ A > 0) or strictly infeasible ( ρ A < 0) resp ectively . W e remark that when ρ > 0, w e hav e ρ + A = ρ A = ρ , so the distinction really matters when ρ A < 0, but it is still useful to mak e it explicit. One ma y think that if A is not full rank, p erforming PCA would get rid of the unnecessary dimensions. Ho wev er, w e often wish to only p erform elementary op erations on (p ossibly large matrices) A that are muc h simpler than eigenv ector computations. Instabilit y of ρ − A compared to ρ Unfortunately , the b ehaviour of ρ − A is quite finicky – unlik e ρ + A it is not stable to small p erturbations when con v( A ) is not full-dimensional. T o b e more sp ecific, if (P) is strictly feasible and w e p erturb all the vectors b y a small amoun t or add a vector that maintains feasibilit y , ρ + A can only change by a small amount. How ev er, if (P) is strictly in feasible and w e p erturb all the vectors by a small amoun t or add a vector that main tains infeasibilit y , ρ − A can change by a large amoun t. F or example, assume lin( A ) is not full-dimensional, and | ρ − A | is large. If we add a new v ector v to A to form A 0 = { A ∪ v } where v has a ev en a tiny comp onent v ⊥ orthogonal to lin( A ), then ρ − A 0 suddenly b ecomes zero. This is b ecause it is no w p ossible to choose a v ector w = v ⊥ / k v ⊥ k whic h is in lin( A 0 ), and mak es zero dot-product with A , and positive dot-pro duct with v . Similarly , instead of adding a vector, if we perturb a given set of v ectors so that lin( A ) increases dimension, the negativ e margin can suddenly jump from to zero. 4 Despite its instabilit y and lack of “con tinuit y”, it is indeed this negativ e affine margin that determines rate of con v ergence of algorithms for (D). In particular, the con vergence rate of the von Neumann–Gilb ert algorithm for (D) is determined by ρ − A m uch the same wa y as the con vergence rate of the p erceptron algorithm for (P) is determined b y ρ + A . W e discuss these issues in detail in Section 5 and Section 6.1. 2.1 Geometric In terpretations of ρ + A The p ositive margin has many known geometric in terpretations – it is the width of the feasibilit y cone, and also the largest ball cen tered on the unit sphere that can fit inside the dual cone ( w : A T w > 0 is the dual cone of cone( A )) – see, for example [4, 10]. Here, w e pro vide a few more interpretations. Remember that ρ + A = ρ when Eq.(P) is feasible. Prop osition 1. The distanc e of the origin to c onv ( A ) is ρ + A . ρ + A = inf p ∈4 k p k G = inf p ∈4 k Ap k (5) Pr o of. When ρ A ≤ 0, ρ + A = 0 and Eq.(5) holds b ecause (D) is feasible making the righ t hand side also zero. When ρ A > 0, ρ + A = sup w ∈ # inf p ∈4 w T Ap = sup w ∈ inf p ∈4 w T Ap = inf p ∈4 sup w ∈ w T Ap = inf p ∈4 k Ap k . (6) Note that the first t wo equalities holds when ρ A > 0, the next by the minimax theorem, and the last by self-dualit y of k . k . The quan tity ρ + A is also closely related to a particular instance of the Minimum Enclosing Ball (MEB) problem. While it is common knowledge that MEB is connected to margins (and supp ort v ector machines), it is possible to explicitly characterize this relationship, as w e hav e done b elow. Prop osition 2. Assume A = a 1 · · · a n ∈ R d × n and k a i k = 1 , i = 1 , . . . , d . Then the r adius of the minimum enclosing b al l of c onv( A ) is q 1 − ρ +2 A . Pr o of. It is a simple exercise to sho w that the following are the MEB problem, and its Lagrangian dual min c,r r 2 s.t. k c − a i k 2 ≤ r 2 (7) max p ∈4 1 − k Ap k 2 . The result then follo ws from Prop osition 1. As we show in Section 5, the (Normalized) P erceptron and related algorithms that w e in tro duce later yields a sequence of iterates that con verge to the cen ter of the MEB, and if the distance of the origin to con v( A ) is zero (b ecause ρ A < 0), then the sequence of iterates co verges to the origin, and the MEB just ends up b eing the unit ball. 5 2.2 Geometric In terpretations of | ρ − A | Prop osition 3. If ρ A ≤ 0 then | ρ − A | is the r adius of the lar gest Euclide an b al l c enter e d at the origin that c ompletely fits inside the r elative interior of the c onvex hul l of A . Mathematic al ly, | ρ − A | = sup n R k α k G ≤ R ⇒ Aα ∈ con v( A ) o . (8) Pr o of. W e split the pro of into tw o parts, one for each inequalit y . (1) F or inequalit y ≥ . Cho ose an y R suc h that Aα ∈ con v ( A ) for an y k α k G ≤ R . Given an arbitrary k α 0 k G = 1, put ˜ α := − Rα 0 . By our assumption on R , since k ˜ α k G = R , w e can infer that A ˜ α ∈ con v ( A ) implying there exists a ˜ p ∈ 4 suc h that A ˜ α = A ˜ p . Also α 0 T G ˜ p = α 0 T G ˜ α = − R k α 0 k 2 G = − R. Th us inf p ∈4 α 0 T Gp ≤ − R. Since this holds for an y k α 0 k G = 1, it follows that sup k α k G =1 inf p ∈4 α T Gp ≤ − R. In other words, | ρ − A | ≥ R. (2) F or inequalit y ≤ . It suffices to sho w k α k G ≤ | ρ − A | ⇒ Aα ∈ con v( A ). W e will pro ve the con trap ositiv e Aα / ∈ con v ( A ) ⇒ k α k G > | ρ − A | . Since conv( A ) is closed and con vex, if Aα / ∈ conv( A ), then there exists a hyperplane separating Aα and conv( A ) in lin( A ). That is, there exists ( β , b ) with k Aβ k = 1 in lin( A ) and a constan t b ∈ R such that β T A T Aα = β T Gα < b and β T A T Ap = β T Gp ≥ b for all p ∈ 4 . In particular, β T Gα < inf p ∈4 β T Gp ≤ sup k β k G =1 inf p ∈4 β T Gp = ρ − A . Since ρ − A ≤ 0, it follo ws that | ρ − A | < | β T Gα | ≤ k β k G k α k G = k α k G . One might b e tempted to deal with the usual margin and prov e that | ρ | = sup n R k w k ≤ R ⇒ w ∈ conv( A ) o (9) While the t wo definitions are equiv alen t for full-dimensional lin( A ), they differ when lin( A ) is not full-dimensional, whic h is esp ecially relev an t in the context of infinite dimensional repro ducing k ernel Hilb ert spaces, but could even o ccur when A is lo w rank. In this case, Eq.(9) will alwa ys b e zero since a full-dimensional ball cannot fit inside a finite-dimensional h ull. The right thing to do is to only consider balls ( k α k G ≤ R ) in the linear subspace spanned by columns of A (or the relative in terior of the con vex hull of A ) and not full- dimensional balls ( k w k ≤ R ). The reason it matters is that it is this altered | ρ − A | that determines rates for algorithms and the complexity of problem (D), and not the classical margin in Eq.(1) as one might ha ve exp ected. 6 “Radius Theorems” Recall that A 4 = { Ap : p ∈ 4} = con v( A ), A = ∩ lin( A ), and R A is just A of radius R. Since k α k G ≤ R ⇔ k Aα k ≤ R ⇔ Aα ∈ R A , an enligh tening restatement of Eq.(8) and Eq.(9) is | ρ − A | = sup n R R A ⊆ A 4 o , and | ρ | = sup n R R ⊆ A 4 o . It can b e read as “largest radius (affine) ball that fits inside the con vex h ull”. There is a nice parallel to the smallest (o v erall) and smallest p ositive singular v alues of a matrix. Using A = { Ax : x ∈ } for brevit y , σ + min ( A ) = sup n R R A ⊆ A o , and σ min ( A ) = sup n R R ⊆ A o (10) This highligh ts the role of the margin is a measure of conditioning of the linear feasibilit y systems (P) and (D). Indeed, there are a num b er of far-reac hing extensions of the classical “radius theorem” of [7]. The latter states that the Euclidean distance from a square non- singular matrix A ∈ R n × n to the set of singular matrices in R n × n is precisely σ min ( A ). In an analogous fashion, for the feasibilit y problems (P) and (D), the set Σ of il l-p ose d matrices A are those with ρ = 0. Cheung and Cuc k er [4] sho w that for a giv en a matrix A ∈ R m × n with normalized columns, the margin is the largest p erturbation of a row to get an ill-p osed instance or the “distance to ill-p osedness”, i.e. min ˜ A ∈ Σ max i =1 ,...,n k a i − ˜ a i k = | ρ | . (11) See [4, 21] for related discussions. 3 Gordan’s Theorem with Margins W e w ould lik e to mak e quan titativ e statemen ts ab out what happ ens when either of the alternativ es is satisfied e asily (with large p ositiv e or negativ e margin). Our preceding ge- ometrical intuition suggests a refinement of Gordan’s Theorem, namely Theorem 1 below, that accounts for margins. Related results ha ve b een previously derived and discussed by Li and T erlaky [17] as w ell as by T o dd and Y e [24]. In particular, it can b e shown that part 2 of Theorem 1 could b e obtained from [24, Lemma 2.1 and Lemma 2.2]. Similarly , parts 2 and 3 could b e reco v ered from [17, Theorem 5 and Theorem 6]. W e giv e a succinct and simple pro of of Theorem 1 b y relying on Prop osition 1 and Prop osition 3. Theorem 1 could also b e prov en, alb eit less succinctly , via separation argumen ts from conv ex analysis. Theorem 1. F or any pr oblem instanc e A and any c onstant γ ≥ 0 , 1. Either ∃ w ∈ # A s.t. A T w > 0 , or ∃ p ∈ 4 s.t. Ap = 0 . 2. Either ∃ w ∈ # A s.t. A T w > γ 1 , or ∃ p ∈ 4 s.t. k Ap k ≤ γ . 3. Either ∃ w ∈ # A s.t. A T w > − γ 1 , or ∀ v ∈ γ A ∃ p v ∈ 4 s.t. v = Ap v . 7 Pr o of. The first statement is the usual form of Gordan’s Theorem. It is also a particular case of the other tw o when γ = 0. Thus, we will prov e the other tw o: 2. If the first alternative do es not hold, then from the definition of ρ A it follows that ρ A ≤ γ . In particular, ρ + A ≤ γ . T o finish, observe that by Proposition 1 there exists p ∈ 4 such that k Ap k = ρ + A ≤ γ . (12) 3. Analogously to the previous case, if the first alternativ e do es not hold, then ρ A ≤ − γ . In particular, it captures | ρ − A | ≥ γ . (13) Observ e that b y Prop osition 3, ev ery p oint v ∈ γ A m ust be inside conv( A ), that is, v = Ap v for some distribution p v ∈ 4 . One can similarly argue that in eac h case if the first alternative is true, then the second m ust b e false. In the spirit of radius theorems introduced in the previous section, the statemen ts in Theorem 1 can b e equiv alently written in the follo wing succinct forms: 1’. Either { w ∈ # A : A T w > 0 } 6 = ∅ , or 0 ∈ A 4 2’. Either { w ∈ # A : A T w > γ 1 } 6 = ∅ , or γ A ∩ A 4 6 = ∅ 3’. Either { w ∈ # A : A T w > − γ 1 } 6 = ∅ , or γ A ⊆ A 4 As noted in the pro of of Theorem 1, the first statemen t is a special case of the other tw o when γ = 0. In case 2, w e hav e at least one witness p close to the origin, and in 3, we hav e an entire ball of witnesses close to the origin. 4 Hoffman’s Theorem with Margins Hoffman-st yle theorems are often useful to prov e the con vergence rate of iterativ e algorithms b y c haracterizing the distance of a curren t iterate from a target set. F or example, a Hoffman- lik e theorem was also pro ved by [16] (Lemma 2.3), where they use it to pro v e the linear con vergence rate of the alternating direction metho d of multipliers, and in [12] (Lemma 4), where they use it to prov e the linear con v ergence of a first order algorithm for calculating -appro ximate equilibria in zero sum games. It is w orth p ointing out that Hoffman, in whose honor the theorem is named and also an author of [14] whose proof strategy we follow in the alternate pro of of Theorem 3, himself app eared to ha v e o verlooked the in timate connection of the “Hoffman constan t” ( τ in Eq.(2)) to the p ositive and negative margin, as we present in our theorems b elo w. 8 4.1 Hoffman’s theorem for (D) when ρ − A 6 = 0 Theorem 2. Assume A ∈ R m × n is such that | ρ − A | > 0 . F or b ∈ R m define the “witness” set W = { x ≥ 0 | Ax = b } . If W 6 = ∅ then for al l x ≥ 0 , dist 1 ( x, W ) ≤ k Ax − b k | ρ − A | (14) wher e dist 1 ( x, W ) is the distanc e fr om x to W me asur e d by the ` 1 norm k · k 1 . Pr o of. Giv en x ≥ 0 with Ax 6 = b , consider a p oint v = | ρ − A | b − Ax k Ax − b k (15) Note that k v k = | ρ − A | and crucially v ∈ lin( A ) (since b ∈ lin( A ) since W 6 = ∅ ). Hence, b y Theorem 1, there exists a distribution p such that v = Ap . Define ¯ x = x + p k Ax − b k | ρ − A | (16) Then, by substitution for p and v one can see that A ¯ x = Ax + v k Ax − b k | ρ − A | = Ax + ( b − Ax ) = b (17) Hence ¯ x ∈ W , and dist 1 ( x, W ) ≤ k x − ¯ x k 1 = k Ax − b k | ρ − A | . The following v ariation (using witnesses only in 4 ) on the ab ov e theorem also holds. This result is closely related to [23, Lemma 2] and has essentially the same pro of. Prop osition 4. Assume A ∈ R m × n is such that | ρ − A | > 0 . Define the set of witnesses W = { p ∈ 4| Ap = 0 } . Then at any p ∈ 4 , dist 1 ( p, W ) ≤ 2 k Ap k k Ap k + | ρ − A | ≤ 2 k Ap k | ρ − A | = 2 k p k G | ρ − A | . (18) Pr o of. Assume Ap 6 = 0 as otherwise there is nothing to sho w. Consider v := − | ρ − A | k Ap k Ap. Since v ∈ lin( A ) and k v k = | ρ − A | , Prop osition 3 implies that v = Ap 0 for some p 0 ∈ 4 . Th us for λ := k Ap k k Ap k + | ρ − A | w e hav e ˜ p := λp 0 + (1 − λ ) p ∈ W and dist 1 ( p, W ) ≤ k p − ˜ p k 1 = λ k p − p 0 k 1 ≤ 2 λ = 2 k Ap k k Ap k + | ρ − A | = 2 k Ap k | ρ − A | = 2 k p k G | ρ − A | . 9 4.2 Hoffman’s theorem for (P) when ρ + A 6 = 0 Theorem 3. Define S = { y | A T y ≥ c } for some ve ctor c . Then, for al l w ∈ R d , dist( w , S ) ≤ k [ A T w − c ] − k ∞ ρ + A wher e dist( w , S ) is the k · k 2 -distanc e fr om w to S and ( x − ) i = min { x i , 0 } . Pr o of. Since ρ + A > 0, the definitions of margin (1) and affine margin (3) imply that there exists ¯ w ∈ # A with A T ¯ w ≥ ρ + A 1 . Supp ose, A T w 6≥ c . Then w e can add a multiple of ¯ w to w as follo ws. Let a = [ c − A T w ] + = − [ A T w − c ] − where ( x + ) i = max { x i , 0 } and ( x − ) i = min { x i , 0 } . Since a ≥ c − A T w and a ≥ 0, w e ha v e k a k ∞ 1 ≥ c − A T w and consequen tly A T w + k a k ∞ ρ + A ¯ w ≥ A T w + k a k ∞ 1 ≥ A T w + ( c − A T w ) = c. Hence, w + k a k ∞ ρ + A ¯ w ∈ S whose distance from w is precisely k a k ∞ ρ + A . The in terpretation of the preceding theorem is that the distance to feasibility for the problem (P) is gov erned by the magnitude of the largest mistake and the p ositiv e affine- margin of the problem instance A . W e also provide an alternativ e pro of of the theorem ab ov e, since proving the same fact from completely differen t angles can often yield insigh ts. W e follo w the tec hniques of [14], though we significan tly simplify it. This is p erhaps a more classical pro of st yle, and p ossibly more amenable to other b ounds not in v olving the margin, and hence it is instructive for those unfamiliar with pro ving these sorts of b ounds. A lternate Pr o of of The or em 3. F or an y given w , define a = − ( A T w − c ) − = ( − A T w + c ) + and hence note that a ≥ − ( A T w − c ). min A T u ≥ c k w − u k = min A T ( u − w ) ≥− A T w + c k w − u k = min A T z ≥− A T w + c k z k = sup k µ k≤ 1 min A T z ≥− A T w + c µ T z (19) = sup k µ k≤ 1 sup p ≥ 0 ,Ap = µ p T ( − A T w + c ) (20) = sup k p k G ≤ 1 ,p ≥ 0 p > ( − A T w + c ) (21) ≤ sup k p k G ≤ 1 ,p ≥ 0 p T a ≤ sup k p k G ≤ 1 ,p ≥ 0 k p k 1 k a k ∞ (22) = k a k ∞ ρ + A W e used the self-dualit y of k . k in Eq.(19), LP duality for Eq.(20), k Ap k = k p k G b y def- inition for Eq.(21), and Holder’s inequalit y in Eq.(22). The last equality follo ws b ecause 1 ρ + A = max k p k G =1 ,p ≥ 0 k p k 1 , since ρ + A = inf p ≥ 0 , k p k 1 =1 k p k G b y Prop osition 1. 10 5 The P erceptron Algorithm: New Insigh ts The Perceptron Algorithm was in tro duced and analysed b y [2, 18, 22] to solve the primal problem (P), with many v ariants in the mac hine learning literature. F or ease of notation throughout this section assume A = a 1 · · · a n ∈ R d × n and k a i k = 1 , i = 1 , . . . , d . The classical algorithm starts with w 0 := a i for any i , and in iteration t p erforms (c ho ose any mistak e) a i : w T t − 1 a i ≤ 0 . w t ← w t − 1 + a i . A v ariant called Normalized P erceptron whic h, as we p oin t out in Theorem 4 b elow, is a subgradien t metho d, only up dates on the w orst mistake, and tracks a normalized w that whic h is a conv ex com bination of a i ’s. (c ho ose the w orst mistake) a i = arg min a i { w T t − 1 a i } w t ← 1 − 1 t w t − 1 + 1 t a i . The b est known prop ert y of the unnormalized P erceptron or the Normalized P erceptron algorithm is that when (P) is strictly feasible with margin ρ + A , it finds suc h a solution w in 1 /ρ +2 A iterations, as pro ved b y [18, 2]. What is less ob vious is that the P erceptron is actually primal-dual in nature, as stated in the follo wing result of Li and T erlaky [17]. In the follo wing statemen t by an -c ertific ate for (D) we mean a vector α ∈ 4 such that k Aα k ≤ . Prop osition 5. If (D) is fe asible, the Per c eptr on algorithm (when normalize d) yields an -c ertific ate α t for (D) in 1 / 2 steps. Prop osition 5 and Prop osition 4 readily yield the following result. Corollary 1. Assume (D) is fe asible and | ρ − A | > 0 . Define the set of witnesses W = { α ∈ 4| Aα = 0 } . If w t = Aα t is the se quenc e of NP iter ates then dist 1 ( α t , W ) ≤ 2 | ρ − A | √ t W e pro ve tw o more non trivial facts ab out the Normalized P erceptron that we hav e not found in the published literature for the case when (P) is feasible. In this case not only do es the Normalized Perceptron pro duce a fe asible w in O (1 /ρ +2 A ) steps, but on contin uing to run the algorithm, w t will approach the optimal w that maximizes margin, i.e., ac hiev es margin ρ + A . This is actually not true with the classical P erceptron. The normalization in the follo wing theorem is needed b ecause k w t k 6 = 1. Theorem 4. Assume (P) is fe asible. If w t = Aα t , t = 0 , 1 , . . . is the se quenc e of NP iter ates with mar gin ρ t = inf p ∈4 w t k w t k T Ap , and the optimal p oint w ∗ := arg sup k w k =1 inf p ∈4 w T Ap achieves the optimal mar gin ρ = ρ + A = sup w ∈ # inf p ∈4 w T Ap , then ρ + A − ρ t ≤ w t k w t k − w ∗ ≤ 4 ρ + A √ t . 11 Pr o of. Let p t := arg min p ∈4 w T t Ap. Then ρ + A − ρ t = inf p ∈4 w T ∗ Ap − w t k w t k T Ap t ≤ w ∗ − w t k w t k T Ap t ≤ w t k w t k − w ∗ k Ap t k ≤ w t k w t k − w ∗ . The last step b ecause k a i k = 1 , i = 1 , . . . , n and p ∈ 4 . F or the second inequality , first observe that w t k w t k − w ∗ = 1 k w t k w t − ρ + A w ∗ + ( ρ + A − k w t k ) w ∗ ≤ 1 k w t k k w t − ρ + A w ∗ k + | ρ + A − k w t k| ≤ 1 ρ + A k w t − ρ + A w ∗ k + | ρ + A − k w t k| (23) where the first inequalit y follows by the triangle inequality , and b ecause k w ∗ k = 1. The second inequality holds b ecause ρ + A = inf p ∈4 k Ap k and α t ∈ 4 implies that k w t k = k Aα t k ≥ ρ + A . (24) The rest of the pro of hinges on the fact that NP can be interpreted as a subgradien t algorithm for the following problem: min w ∈ R m L ( w ) := min w ∈ R m 1 2 k w k 2 − min i { w T a i } . (25) W e repro duce a short argument from [19, 23] which sho ws that L ( w ) is minimized at ρ + A w ∗ . Let arg min α L ( w ) = tw 0 for some k w 0 k = 1 and some t ∈ R . Substituting this in to Eq.(25), we see that min w ∈ R m L ( w ) = min t> 0 { 1 2 t 2 − tρ + A } = − 1 2 ρ +2 A ac hieved at t = ρ + A and w 0 = w ∗ . Hence arg min w L ( w ) = ρ + A w ∗ . Note that the ( t + 1)-th iteration in the NP algorithm can b e written as w t +1 = w t − 1 t + 1 g t , for g t = w t − arg min a i { w T t a i } ∈ ∂ L ( w t ). Hence, the NP algorithm is a subgradien t metho d for (25). By construction, L ( w ) is a 1-strongly con vex function. Since it is minimized at ρ + A w ∗ , it follows that g T t ( w t − ρ + A w ∗ ) ≥ L ( w t ) − L ( ρ + A w ∗ ) + 1 2 k w t − ρ + A w ∗ k 2 ≥ k w t − ρ + A w ∗ k 2 . In addition, k g t k ≤ k w t k (1 + k a i k ) ≤ 2 k Aα t k ≤ 2 , so k w t +1 − ρ + A w ∗ k 2 = w t − 1 t + 1 g t − ρ + A w ∗ 2 = k w t − ρ + A w ∗ k 2 − 2 t + 1 g T t ( w t − ρ + A w ∗ ) + 1 ( t + 1) 2 k g t k 2 ≤ 1 − 2 t + 1 k w t − ρ + A w ∗ k 2 + 4 ( t + 1) 2 . 12 It thus follows b y induction on t that k w t − ρ + A w ∗ k ≤ 2 / √ t ⇒ k w t k − ρ + A ≤ 2 / √ t. (26) This yields the required b ound of 4 ρ + A √ t when plugged into Eq.(23). Let us revisit the primal-dual form ulation (7) of the minim um enclosing ball problem. The cen ter of the minimum enclosing ball is precisely c ∗ = ρ + A w ∗ . Consequently the follo wing result readily follows. Corollary 2. The se quenc e w t = Aα t , t = 0 , 1 , . . . of NP iter ates c onver ges to the c enter c ∗ = ρ + A w ∗ of the minimum enclosing b al l pr oblem (7) . The Normalized Perceptron algorithm also gives for free an estimate of ρ + A . Prop osition 6. The Normalize d Per c eptr on gives an -appr oximation to the value of the p ositive mar gin in 4 / 2 steps. Sp e cific al ly, k w 4 / 2 k − ≤ ρ + A ≤ k w 4 / 2 k Pr o of. The pro of follows from Eq.(26) and Eq.(24), whic h imply that w t satisfies ρ + A ≤ k w t k ≤ ρ + A + 2 / √ t whose rearrangement with t = 4 / 2 completes the pro of. It is worth noting that in sharp con trast to the estimate on ρ + A giv en b y Proposition 6, the question of finding elementary algorithms to estimate | ρ − A | remains op en. 6 Discussion 6.1 V on-Neumann or Gilb ert Algorithm for (D) V on-Neumann describ ed an iterative algorithm for solving dual (D) in a priv ate commu- nication with Dantzig in 1948, which was subsequently analyzed b y the latter, but only published in [6], and go es by the name of V on-Neumann’s algorithm in optimization cir- cles. Indep endently , Gilb ert [11] describ ed an essen tially identical algorithm that go es b y the name of Gilbert’s algorithm in the computational geometry literature. W e resp ect the indep enden t findings in differen t literatures, and refer to it as the V on-Neumann-Gilb ert (VNG) algorithm. It starts from a p oint in con v( A ), say w := a 1 and lo ops: (c ho ose furthest p oint) a i = arg max a i {k w t − 1 − a i k} (line search, λ ∈ [0 , 1]) w t ← arg min w λ k w λ k ; w λ = λw t − 1 + (1 − λ ) a i Dan tzig’s pap er sho wed that the V on-Neumann-Gilb ert (VNG) algorithm can pro duce an -approximate solution ( p such that k Ap k ≤ ) to (D) in 1 / 2 steps, establishing it as a 13 dual algorithm as conjectured by V on-Neumann. Though designed for (D), Ep elman and F reund [8] prov ed that when (P) is feasible, VNG also pro duces a feasible w in 1 /ρ +2 A steps and hence VNG is also primal-dual like the P erceptron (as prov ed in Prop osition 5). It readily follo ws that Theorem 4, Corollary 1, Corollary 2, and Prop osition 6 hold as well with the V on-Neumann-Gilb ert algorithm in place of the Normalized Perceptron algorithm. Nestero v w as the first to point out in a priv ate note to [9] that VNG is a F rank-W olfe algorithm for min p ∈4 k Ap k (27) Note that Eq.(25) is a relaxed v ersion of Eq.(3), and also that Eq.(27) and Eq.(3) are Lagrangian duals of eac h other as seen in Eq.(6). In this ligh t, it is not surprising that NP and VNG algorithms ha v e such similar prop erties. Moreo v er, Bac h [1] recen tly p oin ted out the strong connection via duality b etw een subgradient and F rank-W olfe metho ds. Ho wev er, VNG p ossesses one additional prop ert y . Restating a result of [8] – if | ρ − A | > 0, then VNG has linear conv ergence. W e include a simple geometrical pro of of this result. Prop osition 7. Assume (D) is fe asible, A = a 1 · · · a n ∈ R d × n with k a i k = 1 , i = 1 , . . . , d , and | ρ − A | > 0 . Then the iter ates w t = Aα t gener ate d by the VNG algorithm satisfy k w t +1 k ≤ k w t k q 1 − | ρ − A | 2 , t = 0 , 1 , . . . In p articular, the algorithm finds w t = Aα t , α t ∈ 4 with k w t k ≤ in at most O 1 | ρ − A | 2 log 1 steps. Pr o of. Figure 1 illustrates the idea of the pro of. Assume w t = Aα t ∈ lin( A ) 6 = 0 as otherwise there is nothing to show. By the definition of affine margin, there must exist a p oint a i suc h that cos α = w t k w t k · a i ≤ ρ − A or equiv alen tly | cos α | ≥ | ρ − A | . VNG sets w t +1 to b e the nearest p oin t to the origin on the line joining w t with a i . Consider ˜ w as the nearest point to the origin on a (dotted) line parallel to a i through w t . Note ( π / 2 − β ) + α = π (in ternal angles of parallel lines). Then, k w t +1 k ≤ k ˜ w k = k w t k cos β = k w t k sin α = k w t k √ 1 − cos 2 α ≤ k w t k p 1 − | ρ − A | 2 . Hence, VNG can conv erge linearly with strict infeasibility of (P), but NP cannot. Nev- ertheless, NP and VNG can b oth b e seen geometrically as trying to represent the center of circumscribing or inscribing balls (in (P) or (D)) of conv(A) as a con v ex com bination of input p oints. 6.2 Summary In this pap er, we adv ance and unify our understanding of margins through a slew of new results and connections to old ones. First, w e p oint out the correctness of using the affine margin, deriving its relation to the smallest ball enclosing conv(A), and the largest ball within conv(A). W e prov ed generalizations of Gordan’s theorem, whose statements w ere conjectured using the preceding geometrical intuition. Using these tools, we then deriv ed in teresting v arian ts of Hoffman’s theorems that explicitly use affine margins. W e ended by 14 pro ving that the Perceptron algorithm turns out to b e primal-dual, its iterates are margin- maximizers, and the norm of its iterates are margin-approximators. Righ t from his seminal in tro ductory paper in the 1950s, Hoffman-like theorems ha v e been used to pro ve conv ergence rates and stabilit y of algorithms. Our theorems and also their pro of strategies can be v ery useful in this regard, since suc h Hoffman-lik e theorems can b e v ery challenging to conjecture and prov e (see [16] for example). Similarly , Gordan’s theorem has b een used in a wide arra y of settings in optimization, giving a preceden t for the p ossible usefulness of our generalization. Lastly , large margin classification is no w such an in tegral mac hine learning topic, that it seems fundamen tal that we unify our understanding of the geometrical, analytical and algorithmic ideas b ehind margins. Ac kno wledgemen ts This research was partially supp orted by NSF grant CMMI-1534850. References [1] F rancis Bac h. Dualit y b etw een subgradien t and conditional gradient metho ds. arXiv pr eprint arXiv:1211.6302 , 2012. [2] HD Blo c k. The p erceptron: A mo del for brain functioning. i. R eviews of Mo dern Physics , 34(1):123, 1962. [3] Jonathan Borwein and Adrian Lewis. Convex analysis and nonline ar optimization: the ory and examples , volume 3. Springer, 2006. [4] Dennis Cheung and F elip e Cuck er. A new condition num b er for linear programming. Mathematic al pr o gr amming , 91(1):163–174, 2001. [5] V asek Ch v atal. Line ar pr o gr amming . Macmillan, 1983. [6] George Dantzig. An -precise feasible solution to a linear program with a conv exity constrain t in 1 / 2 iterations indep enden t of problem size. T echnical rep ort, Stanford Univ ersity , 1992. [7] Carl Ec k art and Gale Y oung. The approximation of one matrix b y another of lo wer rank. Psychometrika , 1(3):211–218, 1936. [8] Marina Ep elman and Rob ert M F reund. Condition n umber complexit y of an elementary algorithm for computing a reliable solution of a conic linear system. Mathematic al Pr o gr amming , 88(3):451–485, 2000. [9] Marina A Ep elman, Rob ert M F reund, et al. Condition numb er c omplexity of an ele- mentary algorithm for r esolving a c onic line ar system . Citeseer, 1997. [10] Rob ert M F reund and Jorge R V era. Some characterizations and prop erties of the dis- tance to ill-p osedness and the condition measure of a conic linear system. Mathematic al Pr o gr amming , 86(2):225–260, 1999. 15 [11] Elmer G Gilb ert. An iterativ e pro cedure for computing the minim um of a quadratic form on a con vex set. SIAM Journal on Contr ol , 4(1):61–80, 1966. [12] Andrew Gilpin, Javier Pe˜ na, and T uomas Sandholm. First-order algorithm with O (ln(1 / )) conv ergence for -equilibrium in t w o-p erson zero-sum games. Mathemati- c al pr o gr amming , 133(1-2):279–298, 2012. [13] JL Goffin. The relaxation metho d for solving systems of linear inequalities. Mathematics of Op er ations R ese ar ch , pages 388–414, 1980. [14] Osman G ¨ uler, Alan J Hoffman, and Uriel G Roth blum. Approximations to solutions to systems of linear inequalities. SIAM Journal on Matrix Analysis and Applic ations , 16(2):688–696, 1995. [15] Alan J Hoffman. On approximate solutions of systems of linear inequalities. Journal of R ese ar ch of the National Bur e au of Standar ds , 49(4):263–265, 1952. [16] Mingyi Hong and Zhi-Quan Luo. On the linear con vergence of the alternating direction metho d of multipliers. arXiv pr eprint arXiv:1208.3922 , 2012. [17] Dan Li and T am´ as T erlaky . The duality b etw een the p erceptron algorithm and the v on Neumann algorithm. Mo deling and Optimization: The ory and Applic ations , 62:113–136, 2013. [18] Alb ert BJ No vikoff. On conv ergence pro ofs for p erceptrons. T echnical rep ort, 1962. [19] Aadity a Ramdas and Ja vier Pe˜ na. Margins, k ernels and non-linear smo othed p ercep- trons. In Pr o c e e dings of the 31st International Confer enc e on Machine L e arning (ICML) , 2014. [20] James Renegar. Some p erturbation theory for linear programming. Mathematic al Pr o- gr amming , 65(1):73–91, 1994. [21] James Renegar. Incorp orating condition measures in to the complexity theory of linear programming. SIAM Journal on Optimization , 5(3):506–524, 1995. [22] F rank Rosenblatt. The p erceptron: a probabilistic mo del for information storage and organization in the brain. Psycholo gic al r eview , 65(6):386, 1958. [23] Negar Soheili and Javier Pe˜ na. A primal–dual smo oth p erceptron–von Neumann algo- rithm. In Discr ete Ge ometry and Optimization , pages 303–320. Springer, 2013. [24] M. T o dd and Y. Y e. Appro ximate Fark as lemmas and stopping rules for iterative infeasible-p oin t iterates for linear programming. Mathematic al Pr o gr amming , 81:1–21, 1998. [25] Vladimir N V apnik. Statistical learning theory . 1998. 16 A Figures Figure 1: Geometric illustration of a VNG iteration. Figure 2: Gordan’s Theorem: Either there is a w making an acute angle with all p oin ts, or the origin is in their conv ex hull. (note k a i k = 1) 17 Figure 3: When restricted to lin( A ), the margin is strictly negativ e. Otherwise, it w ould b e p ossible to choose w perp endicular to lin( A ), leading to a zero margin. Figure 4: Left: ρ − A is the radius of the largest ball cen tered at origin, inside the relativ e in terior of con v( A ). Righ t: ρ + A is the distance from origin to con v( A ). 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment