Log-Normal Matrix Completion for Large Scale Link Prediction
The ubiquitous proliferation of online social networks has led to the widescale emergence of relational graphs expressing unique patterns in link formation and descriptive user node features. Matrix Factorization and Completion have become popular me…
Authors: Brian Mohtashemi, Thomas Ketseoglou
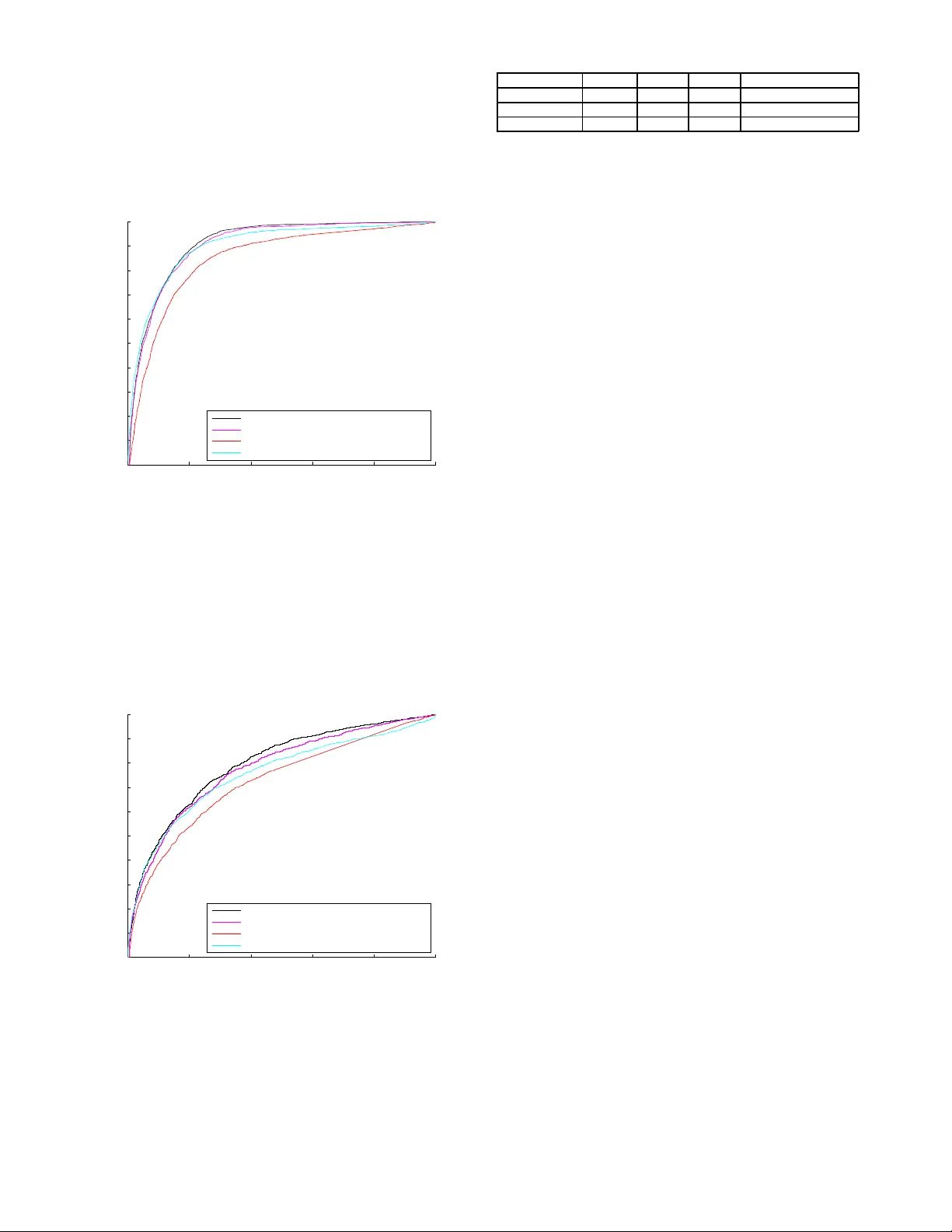
Log-Normal Matrix Completion for Lar ge Scale Link Prediction Brian Mohtashemi Thomas K etseoglou Abstract —The ubiqui tous proliferation of onlin e social net- works has led to th e widescale emer gence of relational graphs expressing uniqu e patterns in link formation and descriptive user n ode features. M atrix Factor ization and Completion ha ve become popular methods f or Link Prediction due to t he l ow rank nature of mutu al node friendshi p inf ormation, and th e a vailability of parallel computer ar chitectures f or rapid matrix processing . Current Link Pr ediction literature has d emonstrated vast perf ormance impro veme nt th rough the utilization o f spar- sity in addition to the low rank matrix assumpti on. Howev er , the majority of research has in troduced sparsity through the limited L 1 or Frobenius norms, instead of considerin g the more detailed distri butions which led to the graph formation and relationship e volution. In particular , social networks hav e been fo und to express either Pareto , or more recently discov ered, Log Normal distributions. Employing the con vexity-inducing Lovasz Extension, we demonstrate how i ncorporating specific degree distribution information can lead to large scale improv ements in Matrix Completion based Link prediction. W e introduce L og- Normal Matrix Completion (LNMC), and solve the complex opti- mization problem by employing Alternating Direc tion Method of Multipl iers. Using data from three popular social networks, our experiments yield up to 5% A UC i ncrease ov er top-perf orming non-structured sparsity based meth ods. I . I N T RO D U C T I O N As a result of wide spread r esearch on la rge scale r ela- tional data, the m atrix comp letion problem has emerged as a topic of interest in collabor ativ e filtering, link pr ediction [1]–[16], and machin e learnin g com munities. Relatio nships between pro ducts, p eople, and organiza tions, h av e b een f ound to gen erate low ran k spa rse matrices, with a broa d distribution of rank and sparsity patterns. More specifically , the node degrees in these networks exhibit well known Probability Mass Functions (PMFs), whose parameters can be de termined via Maximum Likelihoo d Estimation. In collabor ativ e filtering or link prediction applications, row an d co lumn degrees may be characterized by differing PMFs, which may be har nessed to provide improved estimation accu racy . Dire cted networks have unique in-degree and o ut-degree distributions, whereas undirected n etworks are symme tric and th us exhibit th e same row-wise and colu mn wise degree distributions. T hough or igi- nally though t to follow strict Po wer Law Distributions, modern social networks hav e been found to exhibit Log Normal degree patterns in lin k fo rmation [17]. In th is work, we pro pose Log No rmal Ma trix Comp letion (LNMC) as an alternative to typ ical L 1 or Frobenius norm constrained matrix comp letion for Link Pr ediction. The in- corpor ation of the degree d istribution prior generally lead s to a non -conve x op timization problem . Howe ver , by em ploying the Lovasz extension on th e resulting objective, we redu ce the problem to a conv ex minimization over the Lagra ngian, which is subsequen tly solved with Pro ximal De scent and Alter nating Direction Metho d of Multiplier s (ADMM). Th rough experi- mentation o n Goo gle Plus, Flickr , and Blog Catalog social networks, we dem onstrate the a dvantage of incorpo rating structured sparsity inf ormation in the re sulting optimization problem . I I . R E L A T E D W O R K Link predictio n has been thorou ghly research ed in the field of social n etwork analy sis as an essential element in forecast- ing future relationships, estimating unkn own a cquaintanc es, and d eriving shared attributes. In particular, [18] intr oduces the con cept of the Social Attribute Network , and uses it to predict the formation and dissolution of links. Their m ethod combines features from matrix factorization, Adamic Ad ar , and Random w alk with R estart using logistic regression to gi ve link probabilities. Ho wev er , the calculations of such inputs may be time-intensive, and shared attributes may b e unlikely , leading to no n-descrip ti ve feature vectors. Matrix Comp letion for Link Pred iction has previously b een in vestigated within the Positi ve U nlabeled (PU) Learnin g Framework, where the nu clear n orm regularizes a weighted value-specific objective function [19]. Although th e weighted objective im proves th e p rediction results, the subseq uent opti- mization is non- conv ex and thus subje ct to instability . Binary Matrix co mpletion employing p roximal gr adient d escent is studied in [20], howev er , sparsity is not con sidered, and L ink Prediction is not in cluded in the experiment section. Th e structural constrain ts that m ust be satisfied for provably exact completion are described in [ 21]. I n this technical report, the required car dinality of un iformly selected elemen ts is b ounded based o n th e r ank o f the matrix . Uniq ue ran k bou nds for matrix com pletion are considered in [22], where th e Schatten p-Norm is utilized on the singlu ar values of th e matrix . Matrix Completion for Power Law d istributed sam ples is stud ied in [2 3], where various m odels ar e comp ared, includin g the Random Graph, Ch ung Lu-V u, Pr eferential Attachment, an d Forest Fire mode ls. Howe ver , link pred iction is not con sidered and the resulting optimizatio n prob lem is non-co n vex. The co ncept of simu ltaneously spar se and low rank matr ices was introduced in [24], where Incremental Proximal Descent is employed to sequentially minimize the objective, and threshold the sing ular values and matrix entr ies. Due to th e seque ntiality of the o ptimization, the memo ry footpr int is reduced , ho wev er , the objective is non -conve x and may result in a loc al minimum solution. Also, the tested method s em ployed in simu lation are elementary , and more advanced techn iques are well known in the lin k predic tion commun ity . Simultaneous row and colum n- wise spar sity is discussed in [23], where a Lap lacian based norm is employed on r ows an d a Diric hlet semi-n orm is utilized on c olumns. A comp arison between n uclear and gr aph based norms is ad ditionally provided. In [25], Kim et. al present a m atrix factorization method which u tilizes group wise sparsity , to enable sp ecifically targeted regularization . Howe ver, th e datasets which we utilize d o not id entify gr oup membersh ip, and thus we will no t co nsider affiliation in o ur prediction models. Structured sparsity was th oroug hly investigated in [26], and applied to Graph ical Model Learning . However , the pap er focuses solely on the Pareto Distribution whic h character izes scale-free networks, and do es not cover the Log Normal Meth- ods wh ich are presented in this pap er . Also, Link Prediction is not c onsidered in th e experim ental section. Node specific de- gree prio rs are in troduced in [27], an d the L ovas z Ex tension is additionally e mployed to learn scale free ne tworks commo nly formed by Gaussian Models. Ho wever , the st ability of the edge rank up dating is not pr oven, and Log Nor mally distributed networks ar e no t con sidered. The Lovasz Extension a nd ba ckgrou nd theor y are presented in [28], whe re Bach p rovides an overview on sub modular function s and minimization. I I I . P R O P O S E D A P P ROA C H A. Link Pr ed iction In this pa per , w e co nsider social network gr aphs, since they h av e b een proven to follow Pareto, an d more recently discovered, Log Norm al, degree distributions. The Social Network Link Predictio n pr oblem in volves estimating the lin k status, X i,j , b etween no de i and n ode j , where X i,j is limited to binary outcomes. T og ether , the set of all nodes, V , and links, E , for m th e graph G = ( V , E ) , where E is only partially known. Unk nown link statuses may exist when either th e relation ship between i and j is non-pub lic, or the observation is considered u nreliable over several crawls o f the social ne twork. Combine d, the observations can be expressed in th e f orm o f a pa rtial adjacen cy matr ix, A Ω , wh ich con tains all known values in the set o f o bserved pairs, Ω . Unm easured states between two n odes are set to 0 in A Ω . This matrix can be stored in spar se f ormat for memory conservation, a nd operation complexity reductio n. B. Structured Sparsity based Matrix Completion for Link Pr ediction As dem onstrated in [19], [20], [ 24], Matrix Completio n in volves solving for unkn own entries in matrices by employing the low-rank assumption in addition to other side in formation regarding m atrix formation and ev olution. T ra ditionally , m atrix completion problems ar e expressed a s ˆ X = arg min X k A Ω − X Ω k 2 F + λ k X k ∗ , (1) where X Ω i,j = ( X i,j , if { i, j } ǫ Ω 0 , otherw ise , k · k F is th e Frobeniu s norm, and k · k ∗ is th e nuclear norm (Schatten p-nor m with p = 1 ). The n uclear n orm c an be defined as k X k ∗ = min { m,n } X i =1 σ i , (2) where σ i is the i th eigenv alu e, when arran ged in decreasing order, an d m and n are the row count and column c ount, respectively . In this p aper, m is assumed equal to n . ˆ X is the estimated complete matrix after con vergence is attained. Generally , these prob lems are solved using pro ximal gra dient descent, which e mploys singu lar v alue thr esholding on eac h iteration [ 29]. Howev er , th is pr oblem gen erally lacks incorpo - ration of prior sparsity in formation enc oded into the matr ix. Thus we au gment the problem as ˆ X = arg min X k A Ω − X Ω k 2 F + λ 1 k X k ∗ + G ( X ) , (3) where G is defined as f ollows: G ( X ) = λ 2 Γ i,α ( X ) + λ 3 Γ j,β ( X ) . (4) Here, Γ i,α ( X ) is a sparsity indu cing term, where i im plies that the sparsity is app lied on matrix rows, j implies sparsity is applied on matrix co lumns, α is the prio r in-degree distri- bution, and β is the out- degree distribution. For the rest o f this paper, we will consider the case of symmetric adjacency matrices, and thu s set λ 3 to 0 . C. Log-Normal Degr ee Prior As demo nstrated in [17], many so cial networks, includ ing Google+, tend to exhibit th e L og-Nor mal Degree Distribution p ( d ) = 1 dσ √ 2 π e − (ln d − µ ) 2 2 σ 2 . (5) Thus we de riv e Γ( X ) as the Maximum Likeliho od Estimate Γ( X ) = − ln Y i p ( d X i ) , (6) where d X i is the degree of the i th row of X , which simp lifies to the fo llowing: Γ( X ) = X i ln( d X i σ √ 2 π ) + (ln d X i − µ ) 2 2 σ 2 . (7) This is equivalent to a sum mation o f scaled Pareto Distribu- tions with sh ape p arameter 1 added to additiona l square term s. Thus the final optimizatio n prob lem becom es ˆ X = arg min X k A Ω − X Ω k 2 F + λ 1 k X k ∗ + λ 2 X i ln( d X i σ √ 2 π ) + (ln d X i − µ ) 2 2 σ 2 . (8) Due to the presence of the log term in the optimization, con vex methods cannot be d irectly ap plied to the minimiz ation, since the prob lem is n ot guaranteed to have an absolu te min imum. Optimization of this prob lem is a mu lti-part minimizatio n, which can be solved using the Alter nating Direction Method of M ultipliers ( ADMM). D. Optimization ADMM allows the optimiz ation problem to b e split in to less com plex sub-prob lems, which c an b e solved using conv ex minimization te chniques. I n order to d ecouple (8) into sm aller subprob lems, the additional variable, Y , is introdu ced as argmin X k A Ω − X Ω k 2 F + λ 1 k X k ∗ + Γ( Y ) s.t. X = Y . Expressing the pro blem in ADMM upd ate form, the seque ntial optimization becomes X k +1 = argmin X {k A Ω − X Ω k 2 F + λ 1 k X k ∗ (9) + µ 2 k X − Y k + V k k 2 F } Y k +1 = ar gmin Y λ 2 Γ( Y ) + µ 2 k X k +1 − Y + V k k 2 F (10) V k +1 = V k + X k +1 − Y k +1 . (11) In p ractice, step size values, µ , in th e r ange [ . 01 , . 1] have been found to w ork well. Con vergence is assum ed, and the sequence is terminated once k X k +1 − X k k 2 F < δ . The initial values, X 0 , Y 0 and V 0 are set to zeros m atrices. Altho ugh ADMM has slow convergence properties, a relatively accura te solution can be attained in a few iterations. Due to the conv exity o f the initial equation, proximal gradient d escent is employed for minim ization. The pro ximal gradie nt m ethod minimizes problem s of th e form minimize g ( X ) + h ( X ) , (12) using the g radient an d p roximal oper ator as X k,l +1 = prox ψ l h ( X k,l − ψ l ∇ g ( X k,l )) , (13) where ψ l +1 = φψ l , and φ is a multiplier utilized o n each gradient d escent ro und. T ypically a value o f . 5 is sufficient for φ , leadin g to rapid convergence in 10 rou nds, howe ver , a value < . 5 would re sult in slower , but more accurate m inimization. The optimal value fo r ψ 0 is determined throu gh experimen ta- tion. For Lo g-Norm al Matrix Completion, g ( X ) = k A Ω − X Ω k 2 F + µ 2 k X − Y k + V k k 2 F , an d h ( X ) = λ k X k ∗ . T he proxim al o perator of h ( X ) b ecomes a sequential thresho lding on the eig en values, σ , of the argument in (13) prox ψ h = Q diag (( σ i − ψ ) + ) i Q T , (14) where Q is the matrix of eig en vectors. The subprob lem reaches conv ergence when k X k,l +1 − X k,l k 2 F < κ . The n oise of the matrix is reduce d throug h sequ ential thresh olding, leaving only the strongest componen ts of the low rank matrix . This algorithm is advantageous due to rap id convergence pr op- erties and automatic rank selection . Known as the Iterativ e Soft Thr esholding Algor ithm (IST A), this me thod can be parallelized fo r g radient calcu lation an d reco mbined for the Eigenv alu e decomposition. Although the interim resu lt of each round of minimization is gen erally not sparse, matrix entries with values below a giv en thr eshhold can be forced to 0 to allow sparse matrix Eige n value Decom position (suc h as eigs in Matlab ) to be perfor med with minimal e rror . E. Lovasz Ex tension (10) is a n on-co n vex optim ization p roblem d ue to the log of th e set cardinality f unction. Howe ver, the p roblem can b e altered into a conv ex form using the Lovas z Extension o n the submodu lar set fun ction. As described in [28], the Lovasz Extension ta kes on the following f orm: f ( w ) = n X j =1 w z j [ F ( { z 1 , ..., z j } ) − F ( { z 1 , ..., z j − 1 } )] . (1 5) Here, z is a perm utation of j which ensures compon ents of w are ord ered in d ecreasing fashion, w z 1 ≥ w z 2 ≥ w z n , and F is a sub modular set function . T he Lovasz Extension is always conv ex when F is subm odular, th us allowing convex op ti- mization techniques to be used on the resulting transformed problem . In or der to transfo rm each individual row o f sam pled re - lationship in formatio n into a set, S , the suppo rt fu nction, S i = Sup p ( X i ) is utilized. As a result S i ǫ { 0 , 1 } n , wher e n is the n umber of co lumns present in the matr ix X. A sub modular set f unction must obey the relatio nship F ( A ∪ { p } ) − F ( A ) ≥ F ( B ∪ { p } ) − F ( B ) , (16) where A ⊆ B , and p is an additional set element. In this paper, F is a log-norm al transfor mation on the degree d . The degree, d i = P n i S i,j , is mo dular, and thus follows ( 16) with strict equality . Thu s f or F to be sub modular, the subsequ ent transform ation of th e degre e must be sub modular as well. After a pplying the Lovasz Extension to (7) , the result is Γ( X ) = m X i =1 n X j =1 [ ln 2 ( j + 1) − ln 2 ( j ) (17) + ( σ 2 − µ )( ln ( j + 1 ) − ln ( j )) σ 2 ] | X i,j | . Here, | X | is used in order to maintain the p ositivity required for the Lov asz Ex tension to remain con vex. Further details regarding the op timization o f th is problem can be ob tained in Append ix A. F . Considerations In order for (1 7) to be utilized, (7) m ust r emain a submod - ular fu nction of the degree. Thus, b oth th e first d eriv ative and the secon d deriv ativ e o f the fu nction mu st remain p ositi ve, creating th e following c onstraint: ln ( d + τ ) ≥ (1 + µ − σ 2 ) . (18) τ is in troduced to prevent th e left side of the ineq uality from approachin g −∞ . In practice, a small constant is also subtracted or added from the ob tained set function in ord er to 10 0 10 1 10 2 10 3 10 −10 10 −8 10 −6 10 −4 10 −2 10 0 Degree Probability Log−Normal Fit Empirical Data (a) Google+ 10 0 10 1 10 2 10 3 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 Degree Probability Log−Normal Fit Empirical Data (b) Fl ickr 10 0 10 1 10 2 10 3 10 −5 10 −4 10 −3 10 −2 10 −1 Degree Probability Log−Normal Fit Empirical Data (c) Bl og Cat. Fig. 1: Em pirical Node D egree Data and Fitted Lo g-Norma l Probability Distrib ution Functions assure that F ( ∅ ) = 0 . These small c oefficients are determ ined during th e Cro ss V alidatio n pha se, after obtain ing the optimal σ and µ values w hich satisfy the given con straints. I V . E X P E R I M E N T In or der to compar e th e perf ormance of the LNMC method with other popu lar Link Prediction me thods, an experiment was p erform ed u sing several data sets fr om existing literature: 1) Goo gle + - The Go ogle + dataset [18] contains 5 , 200 nodes and 24 , 690 links, ca ptured in A UG 2 011. The data contain s bo th G raph topolog y and node attribute informa tion; howe ver, the side- features are r emoved since our metho d r equires edg e status only . 2) Flickr - Flickr is a social network b ased o n imag e hosting, wh ere u sers for m comm unities and f riendships based on commo n interests. The Flickr dataset [30] c on- tains 80 , 513 nod es, 5 , 8 9 9 , 8 8 2 links, and 19 5 grou ps. Group affiliation was discar ded due to irr elev an ce to th e LNMC method. 3) Blog Catalog - Blog Catalog [30] is a b logging site where users can fo rm friendships, and acquire grou p membersh ip. The utilized dataset contains 10 , 312 node s, 333 , 983 lin ks, a nd 39 g roups. Again , for the context of this paper , the group inf ormation was removed. As seen in Fig. 1, all datasets f ollow a rou ghly Lo g-Norm al distribution, with varying amou nts o f degree sparsity , and variance. Due to the high num ber of lo w degree n odes in the Google+ dataset, a ll points appear co nstrained to th e left of the p lot axis; howe ver , as we will illustrate, the Log-N ormal Distribution is still superior to the Pareto D istribution for lin k prediction . During the training phase, 10 % o f th e data was removed in order to u se for fu ture predictions. For the p urposes of demo nstration, only 1 , 0 00 of the highest degree nodes ar e maintained for ad jacency matrix f ormation . V . R E S U LT S A. Baseline Methods a nd P erformance Metrics In ord er to un derstand the ad vantage of LNMC, the results are co mpared against the following method s: 1) Matrix Completio n with Pareto Spa rsity (MCPS) - MCPS [26] utilizes the same algorithm which we have outlined in the pap er with the exception of the prior . MCPS employs the Pareto Distribution f ( d ) = ( δ d ) χ . 2) Matrix Comp letion with L 1 Sparsity ( MCLS) - MCLS is used by Richard et al. [ 24], and rep resents on e of the first attempts at in corpo rating L 1 sparsity with the Lo w Rank assum ption. 3) Lo gistic Regression (MF + RwR + AA) - In their paper on Social Attribute Networks, Gong et al. [17] p rovide a meth od which com bines features fr om Matrix Factor- ization, Ran dom W alks with Restart, and Adamic Adar, which ef fectively solves the lin k prediction problem with high accuracy . In this pap er , the a ttributes ar e removed from the network for equal compariso n with our method. In or der to provide a fair b asis on which to judge the perfor mance, Are a Un der the Curve (A UC) is employe d for compariso n. By utilizing the A UC as the per forman ce metric, we av oid the need f or data balancing , a p rocess which f re- quently results in under sampling negative samples. Thus, all methods can b enefit fr om the additio nal training data. The results are obtained via 10 − fold Cross V alidation, using a rand om sampling metho d for h yper-parameter selection. Th e round s are averaged to pro duce the results shown in T able I. B. P erforma nce Comp arison As demonstrated in Fig. 2, LNMC o utperfo rms M CPS, MCLS, and LR, o n the Go ogle Plus dataset. Due to the h ighly Log-No rmal cha racteristic [17] of the data set, LNMC’ s fine - tuned degree specific prior captu res th e degree distribution behavior in combination with the low rank features of the data, leading to hig h A UC values. The high number of true po siti ves compare d to the false po siti ve rate leads to jagged graph distribution. In Fig 3, it is clear th at matr ix co mpletion with Pareto Sparsity p roduc es low A UC values due to the inaccurate distribution repr esentation. Similarly the LR m ethod fails to capture accurate low ran k info rmation b ecause th e low ran k matrix factorization is do ne p rior to the th e gradien t descent training for Log istic Regression. Due to the Pareto nature 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 False Positive Rate True Positive Rate Matrix Completion with Log Normal Sparsity Matrix Completion with Pareto Sparsity Matrix Completion with L1 Sparsity Logistic Regression (MF + RwR + AA) Fig. 2: Receiv er Operating Character istic for Google Plus Data of th e Flickr dataset, b oth the LNMC an d MCPS metho ds perfor m the same. As can be seen in (17), LNMC can adap t to Scale Fr ee Networks when the first term is small co mpared to the second term. Logistic Regression pe rforms po orly since the features are set, wh ereas Matrix Completio n me thods automatically select th e num ber of laten t para meters to utilize. 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 False Positive Rate True Positive Rate Matrix Completion with Log Normal Sparsity Matrix Completion with Pareto Sparsity Matrix Completion with L1 Sparsity Logistic Regression (MF + RwR + AA) Fig. 3: Receiver Operating Characteristic fo r Flickr Data As seen in Fig . 4, LNMC ou tperform s the Pareto Sparisty based matrix comple tion, d ue to the inclu sion of the squared log ter ms. Th e L 1 sparsity u sed in the MCLS method is in suf- ficiently descrip ti ve f or accur ate matrix estimation. Thu s Lo- gistic Re gression, which inco rporates more descripti ve featur es outperf orms the MCLS metho d. For p urposes of compa rison, 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 False Positive Rate True Positive Rate Matrix Completion with Log Normal Sparsity Matrix Completion with Pareto Sparsity Matrix Completion with L1 Sparsity Logistic Regression (MF + RwR + AA) Fig. 4: Receiver O perating Characteristic for Blog Catalog Data A UC values for each method and d ataset, are contained in T able I. As h ighlighted by the A UC T able, LNMC p rovides optimal results over all datasets. Data Set LNMC MCPS MCLS L R(MF+RwR+AA) Google+ .8541 .8439 .8113 .8434 Flickr .9052 .9052 .8504 .8972 Blog Catalog .7918 .7846 .7150 .7727 T ABLE I: A UC Performance Comp arison V I . C O N C L U S I O N As demo nstrated b oth theo retically , an d experimen tally , LNMC is able to su fficiently encapsulate the advantages of Pareto Sparsity in add ition to Log Nor mal Sparsity . Previously described by Gong et al. in [17], many modern social networks with un directed grap h topo logies exhibit Lo g Nor mal degree distributions. Thu s b y incorp orating the d egree-specific prior the op timization en courag es conver gence to a Log-No rmal degree distribution. Du e to the non -conv exity of so lving the joint low-rank an d structured sparsity ind ucing prior, the Lovasz Exten sion is introdu ced to solve the complex pro blem efficiently . Th rough analysis on three datasets, and using 3 top pe rformin g meth ods, we provid e r esults wh ich exceed the current o ptimum. These results r ev eal the fu ndamen tal v alue of prior de gree information in Link Prediction, and can provide insight into und erstanding the complex dyn amics which cause links to fo rm in a similar way across different networks. In future research we plan to investigate the incorpo ration of side inform ation into the objective. Node attributes introduce additional ch allenges, including missing features, and ad di- tional tr aining co mplexities. R E F E R E N C E S [1] H. R. Sa and R. B. Prudencio , “ Supe rvised Lea rning for Link Predict ion in Weighte d Netw orks , ” Center of Informatics, Federal Unive rsity of Pernamb uco, T ech. Rep. [2] Y . Sun, R. Barber , M. Gupta, C. C. Aggarwa l, and J. Han, “ Co-Author Relation ship P re dicti on in Heter oge neous Bibliogr aphic Networks , ” Uni- versi ty of Illinois at Urbana-Champai gn, T ech. Rep. [3] G.-J. Qi, C. C. Aggarwal , and T . Huang, “ Link Predict ion across Network s by Biased Cr oss-Network Sampling , ” Unive rsity of Illinois at Urbana-Ch ampaign, T ech. Rep. [4] P . Sarkar , D. Chakrabart i, and M. I. Jordan, “ Nonparame tric Link Pred iction in Dynami c Networks , ” Uni versity of California Berk eley , T ech. Rep. [5] Z. Lu, B. Sav as, W . T ang, and I. Dhillon, “ Supervised Link Predict ion Using Mul tiple Sour ces , ” in IEEE 10th Internat ional Confer ence on Dat a Mining , 2010, pp. 923–928. [6] J. Zhu, “ Max-Margi n Nonparametric Latent F eatur e Model s for Link Pred iction , ” in Pr oceedings of the 29th Internati onal Confer ence on Mach ine Learning , 2012. [7] K. T . Miller , T . L . Grif fiths, and M. I. Jordan, “ Nonparamet ric Latent F eature Models for Link Predic tion , ” in Proc eedings on Neural Informatio n Processi ng Systems , 2009. [8] L. Lu and T . Zhou, “ Link Predic tion in Comple x Networks: A Surve y , ” Uni ver sity of Fribourg, Chermin du Musee, Fribourg, Switzerla nd, T ech. Rep. [9] J. Lesko vec , D. Huttenl ocher , and J. Kleinber g, “ Predic ting Positive and Ne gativ e Links in Online Social Networks , ” in Internatio nal W orld W ide W eb Confer ence , 2010. [10] Y . Dong, J. T ang, S. W u, and J. Ti an, “ Link Pre dicti on and Rec- ommendati on acr oss Hete r og eneous Social Net works , ” in IEEE 12th Internati onal Confer ence on Data Mining , 2012. [11] P . S. Y u, J. Han, and C. Faloutsos, Link Mining: Models, Algorithms, and Applicati ons. Ne w Y ork, NY : Springer , 2010. [12] D. Li, Z. Xu, S. Li, and X. Sun, “ Link P re dicti on in Social Networks Based on Hypergr aph , ” in Internat ional W orld W ide W eb Confe r ence , 2013. [13] H.-H. Chen, L. Gou, X. Zhang, and C. L. Giles, “ Capturing Missing Edges in Soc ial Ne tworks Using Verte x Similarity , ” in K-CAP-11 , 2011. [14] E. Perez-Ce rv antes, J. M. Chalco, M. Oliv eira, and R. Cesar , “ Using Link Predi ction to Estimate the Colla borati ve Iinfluence of Researc hers , ” in IEEE 9th Internationa l Confer ence on eScience , 2013, pp. 293–300. [15] Z. Y in, M. Gupt a, T . W eninger , and J. Han, “ A Unified Framew ork for Link P re dicti on Using Random Walks , ” in Internati onal Confere nce on Advances in Social Networks Analysis and Mining , 2010, pp. 152–159. [16] P . Symeondis, E. T iakas, and Y . Manol opoulos, “ T ransiti ve Node Similarit y for Link Predic tion in Socia l Networks with P ositive and Ne gative Links , ” in RecSys2010 , 2010. [17] N. Z. Gong, W . Xu, and L. Huang, “Evol ution of Social-Att ribu te Networ ks: Measurement s, Modeling, and Implicatio ns using Google+, ” in IMC , 2012, pp. 1–14. [18] N. Z. Gong, A. T al walka r , and L. Mack e y , “Joint link predictio n and attrib ute inference using a s ocial -attri bute netw ork, ” AC M T ranaction s on Intellig ent Systems and T echnolo gy , vol. 5, pp. 1–14, 2014. [19] C.-J. Hsieh, N. Natarajan, and I. Dhillon, “PU Learning for Matrix Completi on, ” in Internat ional Confer ence on Machine Learning 32, 2015 , 2015, pp. 1–10. [20] M. A. Daven port, Y . Plan, E. va n den Ber g, and M. W ootters, “1-Bit Matrix Completion, ” Georgi a Institute of T echnology , T ech. Rep., 2014. [21] Y . Chen, S. Bhojana palli , S. S angha vi, and R. W ard, “Completing Any Low Rank Matrix Prov ably , ” Uni versi ty of Cali fornia Berke ley , T ech. Rep., 2014. [22] F . Nie, H. W ang, X. Cai, H. Huang, and C. Ding, “Robu st Matrix Completi on via Joint Schatten p-Norm and lp-Norm Minimiza tion, ” in IEEE International Confer ence on Data Mining , 2012, pp. 1–9. [23] R. Meka, P . Jain, and I. S. Dhillon, “Matrix Complet ion from Power - Law Distributed Samples, ” in Neural Information Proce ssing Systems , 2015, pp. 1–9. [24] E. Richard, P .-A. Sav alle, and N. V ayatis, “Estimation of Simultane ously Sparse and Low Rank Matrices, ” in P r oceed ings of the 29th Interna- tional Confer ence on Machine Learning , 2012, pp. 1–8. [25] J. Kim, R. Monte iro, and H. Park, “Group Sparsity in Nonnega ti ve Ma- trix Complet ion, ” in Pr oceedings of the SIAM Internat ional Confer ence on Data , 2012, pp. 1–12. [26] A. Defazi o and T . S. Caetano, “A Con vex Formulati on for Learning Scale-Fre e Netwo rks via Submodular Relaxation, ” in Advances in Neu- ral Information P r ocessing Systems 25 , 2015, pp. 1–9. [27] Q. T ang, S. Sun, C. Y ang, and J. Xu, “Learning Scal e Free Network by Node Speci fic Degree Prior , ” T oyot a T echnical Institute , T ech. Rep., 2015. [28] F . Bach, “Learning with Submodular Functions: A Con ve x Optimization Perspecti ve, ” Ecole Normale Superieure , T ech. Rep., 2013. [29] S. Gu, L. Zhang, W . Zuo, and X. Feng, “Weight ed Nucle ar Norm Minimiza tion with Applicat ion to Image Denoising, ” in Computer V ision and P attern R ecog nition , 2014. [30] L. T ang and H . Liu, “Scalable Learning of Collecti ve Beha vior based on Sparse Social Dimensions, ” in P r ocee dings of the 18th ACM Confer ence on Information and Knowledg e Managemen t , 2009, pp. 1–10. A P P E N D I X As seen in [26], th e optimization of (10) is performed by first im posing th e symmetry con straint o n Y as argmin Y λ 2 Γ( Y ) + µ 2 k X k +1 − Y + V k k 2 2 s.t. Y = Y T . This minimization lead s to the following algorithm: Data : X k +1 , V k , µ, Y init = ( X k +1 + V k ) Data : γ , U = 0 N , ω Result : Y initialization; while k Y − Y T k 2 < ω do for r = 0 → N − 1 do Y r, ∗ = LovaszOptimize ( Y init r, ∗ , U r, ∗ ) end U = U + γ ( Y − Y T ) end Y = 1 2 ( Y + Y T ) return Y Algorithm 1: Optimization with Sy mmetry Con straint Data : y init, u, M Data : d = y in it − u, p = 0 M Data : Set me mbership fun ction ζ Data : θ transfo rmation which translates sor ted po sition index to original index Result : y initialization; for l = 0 → M − 1 do q = θ ( l ) p q = | d q |− λ 2 µ ( ln 2 ( l + 1 ) − ln 2 ( l ) + ( σ 2 − µ )( ln ( l +1) − ln ( l )) σ 2 ) ζ ( q ) . value = p q r = l while r > 1 and ζ ( θ ( r )) . value ≥ ζ ( θ ( r − 1)) . value do Join th e sets contain ing θ ( r ) and θ ( r − 1) ζ ( θ ( r )) . value = 1 | ζ ( θ ( r )) P iǫζ ( θ ( r )) p i set: r to the first elem ent o f ζ ( θ ( r )) b y sor t ord ering end end for j = 1 to N do y j = ζ ( i ) . value if y j < 0 then y q = 0 end if d i < 0 then y q = − y q end end return y Algorithm 2: LovaszOptimize Problem
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment