Partial Reinitialisation for Optimisers
Heuristic optimisers which search for an optimal configuration of variables relative to an objective function often get stuck in local optima where the algorithm is unable to find further improvement. The standard approach to circumvent this problem involves periodically restarting the algorithm from random initial configurations when no further improvement can be found. We propose a method of partial reinitialization, whereby, in an attempt to find a better solution, only sub-sets of variables are re-initialised rather than the whole configuration. Much of the information gained from previous runs is hence retained. This leads to significant improvements in the quality of the solution found in a given time for a variety of optimisation problems in machine learning.
💡 Research Summary
The paper addresses a well‑known limitation of heuristic optimizers: they often become trapped in local optima and require full restarts from random configurations to escape. While full restarts can eventually locate better solutions, each restart discards all knowledge accumulated in previous runs, leading to inefficient exploration. To overcome this, the authors propose Partial Reinitialisation, a hierarchical scheme that selectively re‑initialises only a subset of variables at each level of the search.
Algorithmic framework.
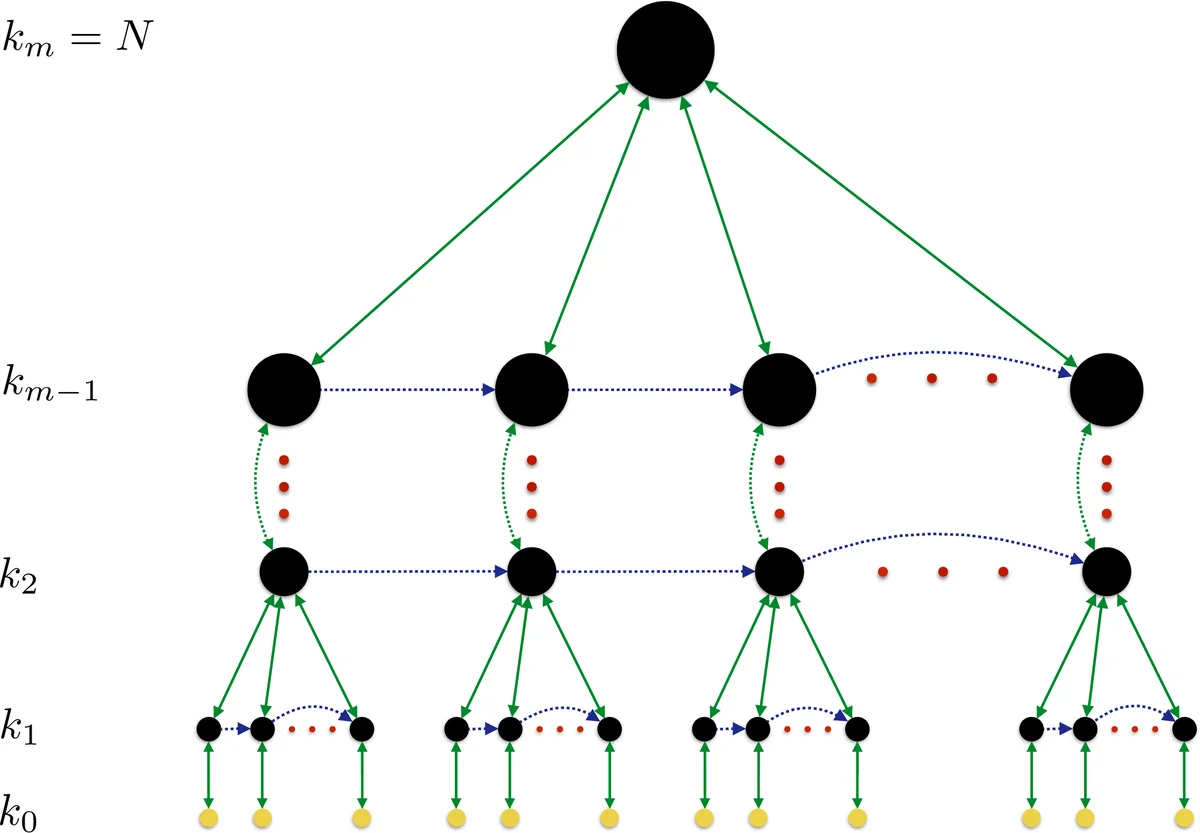
Let the problem have N variables. A hierarchy of m levels is defined with subset sizes k_m = N > k_{m‑1} > … > k_0. At level l the algorithm re‑initialises k_l variables (chosen either uniformly at random or via a problem‑specific heuristic) and then invokes the optimiser at the next lower level (l‑1). The lower‑level optimiser runs M_{l‑1} times on the partially perturbed configuration. After each batch of lower‑level calls, the algorithm compares the best cost found with the checkpoint x_0 (the best configuration seen so far at that level). If no improvement occurs, it reverts to x_0. This process repeats M_l times at each level. When the top level m has been processed, the algorithm has effectively performed a full restart (k_m = N), but the intermediate levels preserve useful structure from earlier runs.
Theoretical justification.
The authors introduce the notion of k‑optimality: a configuration is k‑optimal if re‑initialising any subset of size < k cannot escape the current local optimum. By gradually increasing k the algorithm systematically expands the “escape radius”. The number of re‑initialisations M_l required to assert k‑optimality with confidence 1‑δ is derived from the inequality M_l ≥ ln δ / ln(1‑P), where P is the probability that a random re‑initialisation of k variables yields an improvement. When the problem exhibits exploitable structure, P is relatively large and M_l grows only logarithmically; for unstructured search P may be tiny, leading to exponential effort—mirroring the inherent difficulty of the task.
Empirical evaluation.
Three representative machine‑learning tasks were used to compare partial re‑initialisation against conventional full restarts:
-
Hidden Markov Model (HMM) training – The Baum‑Welch algorithm was applied to learn a random 128‑bit binary sequence. Full restarts re‑initialised all transition and emission probabilities. In the partial scheme, 8 hidden states (8 variables) were re‑initialised ≈ 8000 times per global restart. The partial method achieved a much steeper increase in log‑likelihood versus wall‑clock time, reaching near‑perfect reconstruction far earlier than full restarts.
-
k‑means clustering – A synthetic dataset (A3) with 7 500 points generated from 50 Gaussian clusters was clustered using Euclidean distance. Full restarts used Forgy’s random centre initialisation. Partial re‑initialisation re‑initialised a single cluster centre at a time, performing about 100 such perturbations per global restart. While early‑stage cost reduction was slightly slower, the partial approach consistently reached lower within‑cluster sum‑of‑squares (WCSS) in less time once the cost threshold became modest, demonstrating superior convergence in the regime of high‑quality solutions.
-
k‑medoids (PAM) clustering – Similar to k‑means but with medoid constraints, the algorithm again showed that partial re‑initialisation could outperform full restarts, especially when the objective value was already low.
Across all benchmarks, the partial scheme preserved information from previous runs, required fewer full‑restart cycles, and delivered higher‑quality solutions for a given computational budget. The authors note that in the very early phases of optimisation, full random jumps can be advantageous because they explore the space more broadly; however, as the search homes in on promising regions, the finer‑grained perturbations of partial re‑initialisation become far more efficient.
Practical considerations and extensions.
The paper stresses that the method is straightforward to integrate into existing pipelines: one only needs to expose a routine that can re‑initialise a chosen subset of variables and a way to store checkpoints. The choice of subset selection heuristic is critical; random selection works reasonably well, but problem‑specific heuristics (e.g., selecting variables with strong mutual dependencies) can increase P and thus reduce required M_l. The authors also discuss continuous‑variable extensions, where partial re‑initialisation can be implemented by adding Gaussian noise (controlled by a mixing parameter α) rather than full replacement.
Conclusions.
Partial Reinitialisation offers a principled middle ground between exhaustive global restarts and deterministic local optimisation. By gradually enlarging the set of perturbed variables, it systematically expands the search radius while retaining valuable structural information, leading to faster convergence to high‑quality solutions. The approach is broadly applicable to any heuristic optimiser—simulated annealing, evolutionary algorithms, Bayesian optimisation, etc.—and opens avenues for automated tuning of hierarchy parameters and smarter subset‑selection strategies in future work.
Comments & Academic Discussion
Loading comments...
Leave a Comment