Robust Satisfaction of Temporal Logic Specifications via Reinforcement Learning
We consider the problem of steering a system with unknown, stochastic dynamics to satisfy a rich, temporally layered task given as a signal temporal logic formula. We represent the system as a Markov decision process in which the states are built from a partition of the state space and the transition probabilities are unknown. We present provably convergent reinforcement learning algorithms to maximize the probability of satisfying a given formula and to maximize the average expected robustness, i.e., a measure of how strongly the formula is satisfied. We demonstrate via a pair of robot navigation simulation case studies that reinforcement learning with robustness maximization performs better than probability maximization in terms of both probability of satisfaction and expected robustness.
💡 Research Summary
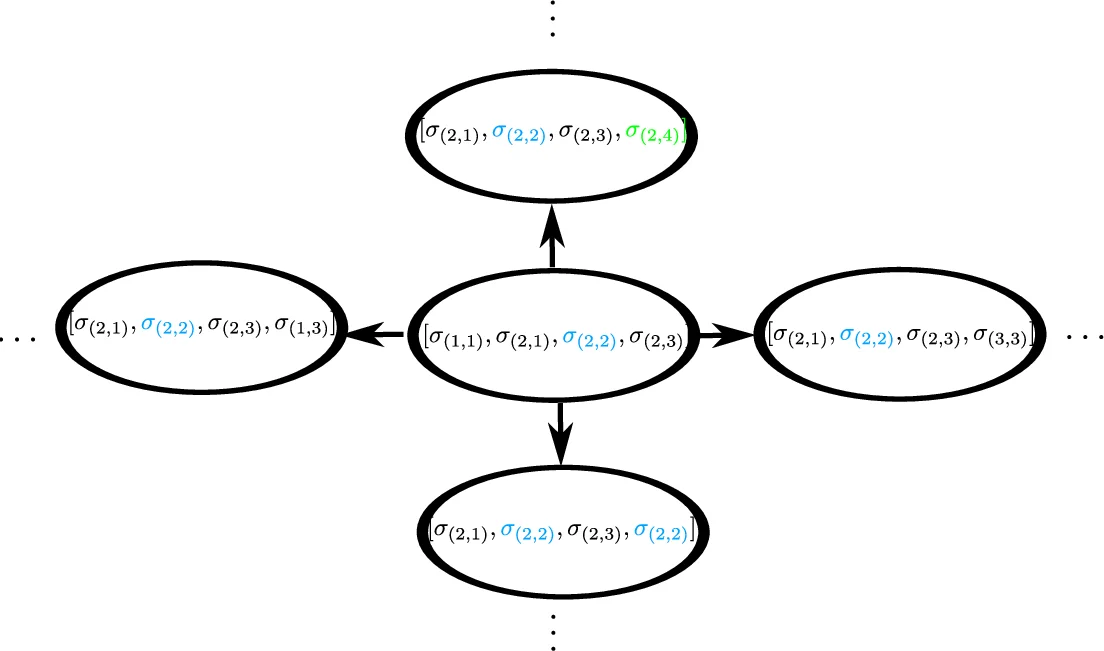
The paper addresses the challenge of controlling a system with unknown stochastic dynamics so that it satisfies a specification expressed in Signal Temporal Logic (STL). Unlike Linear Temporal Logic (LTL), STL includes time‑bounded operators and a quantitative robustness measure that indicates how strongly a trajectory satisfies a formula. To handle the history‑dependence inherent in STL, the authors introduce the τ‑MDP, a Markov Decision Process whose states encode the last τ regions visited by the system, where τ is the horizon length of the STL sub‑formula that determines satisfaction. By partitioning the continuous state space into a finite set of regions Σ and constructing a graph G that captures adjacency, each τ‑state is a sequence of τ symbols from Σ (with padding for shorter histories). Transition probabilities are defined so that a transition is possible only when the new τ‑state’s first τ‑1 symbols match the previous τ‑state’s last τ‑1 symbols and the final symbols correspond to neighboring regions in G. This construction yields a finite‑state MDP that faithfully captures the temporal requirements of STL without needing a deterministic Rabin automaton.
Two optimization problems are formulated. Problem 1 seeks a policy μ*_mp that maximizes the probability that a trajectory satisfies the STL formula φ, i.e., it maximizes Pr
Comments & Academic Discussion
Loading comments...
Leave a Comment