Quantifying the impact of weak, strong, and super ties in scientific careers
Scientists are frequently faced with the important decision to start or terminate a creative partnership. This process can be influenced by strategic motivations, as early career researchers are pursuers, whereas senior researchers are typically attr…
Authors: Alex, er Michael Petersen
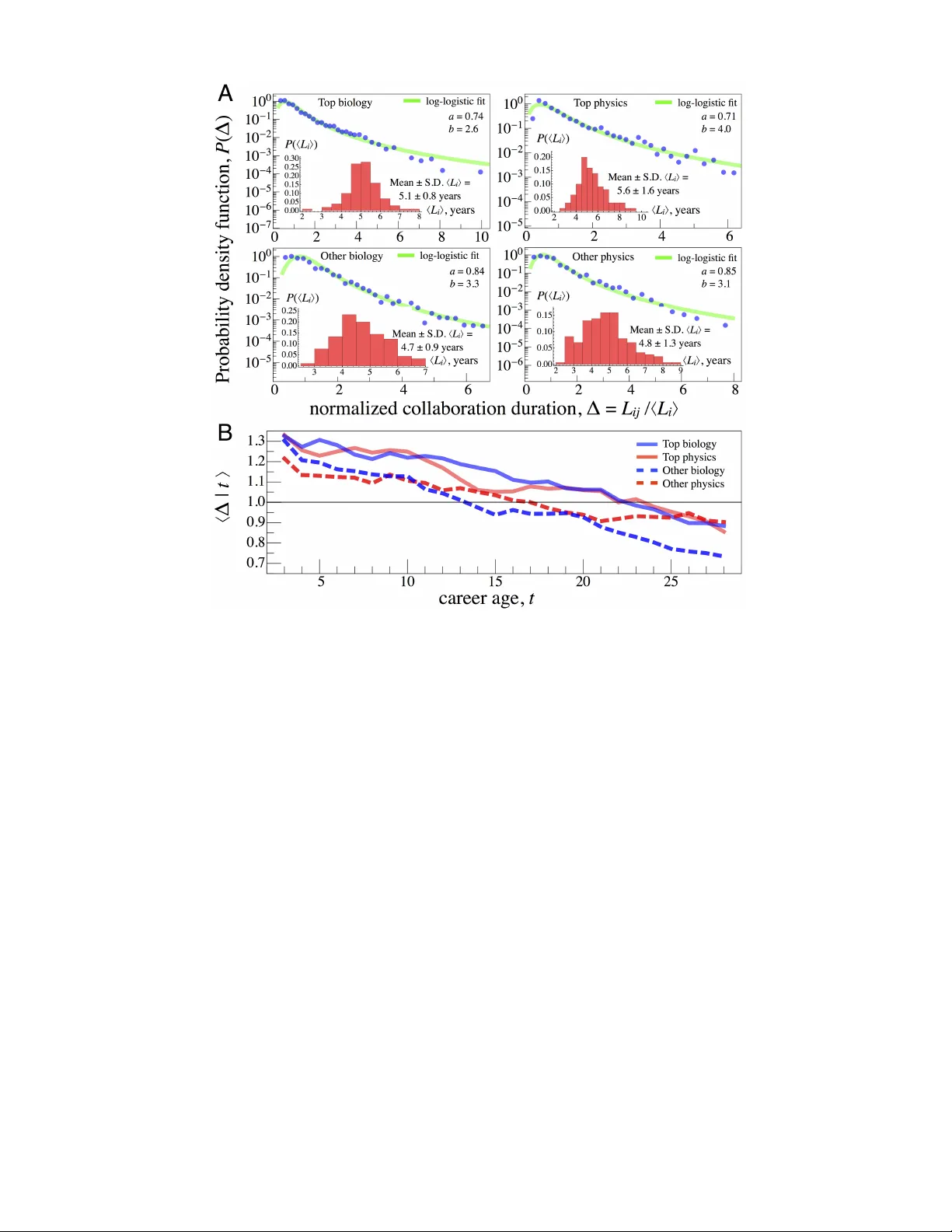
Quantifying the impact of weak, strong, and super ties in scientific car eers Alexander M. Petersen 1 1 Laboratory for the Analysis of Complex Economic Systems, IMT Lucca Institute for Advanced Studies, Lucca 55100, Italy Scientists are frequently faced with the important decision to start or terminate a creati ve partnership. This process can be influenced by strategic moti vations, as early career researchers are pursuers, whereas senior researchers are typically attractors, of new collaborativ e opportunities. F ocusing on the longitudinal aspects of scientific collaboration, we analyzed 473 collaboration profiles using an ego-centric perspectiv e which accounts for researcher -specific characteristics and provides insight into a range of topics, from career achievement and sustainability to team dynamics and efficienc y . From more than 166,000 collaboration records, we quantify the frequency distributions of collaboration duration and tie-strength, showing that collaboration netw orks are dominated by weak ties characterized by high turnover rates. W e use analytic extreme-v alue thresholds to identify a new class of indispensable ‘super ties’, the strongest of which commonly e xhibit > 50 % publication ov erlap with the central scientist. The prev alence of super ties suggests that they arise from career strategies based upon cost, risk, and reward sharing and complementary skill matching. W e then use a combination of descriptiv e and panel regression methods to compare the subset of publications coauthored with a super tie to the subset without one, controlling for pertinent features such as career age, prestige, team size, and prior group experience. W e find that super ties contribute to abov e-average productivity and a 17% citation increase per publication, thus identifying these partnerships – the analog of life partners – as a major factor in science career dev elopment. A scientist will encounter many potential collabora- tors throughout the career . As such, the choice to start or terminate a collaboration can be an impor- tant strategic consideration with long-term implica- tions. While pre vious studies have focused primarily on aggr egate cross-sectional collaboration patter ns, here we analyze the collaboration network from a re- searcher’ s local perspective along his/her career . Our longitudinal approach re veals that scientific collabo- ration is characterized by a high turnover rate juxta- posed with surprisingly frequent ‘life partners’. W e show that these extremely strong collaborations have a significant positiv e impact on pr oductivity and ci- tations – the apostle effect – repr esenting the advan- tage of ‘super’ social ties characterized by trust, con- viction, and commitment. For the Supporting Informa- tion see the published version: A. M. Petersen (2015) Pr oc. Nat. Acad. Sci. USA 112, E4671–E4680. DOI:10.1073/pnas.1501444112 Science operates at multiple scales, ranging from the global and institutional scale down to the le vel of groups and in- dividuals [ 1 ]. Integrating this system are multi-scale social networks that are ripe with structural, social, economic, and behavioral complexity [ 2 ]. A subset of this multiplex is the scientific collaboration network, which forms the structural foundation for social capital in vestment, knowledge diffusion, reputation signaling, and important mentoring relations [ 3 – 8 ]. Here we focus on collaborativ e endeav ors that result in sci- entific publication, a process which draws on various aspects of social ties, e.g. colocation, disciplinary identity , competi- tion, mentoring, and knowledge flow [ 9 ]. The dichotomy be- tween strong and weak ties is a longstanding point of research [ 10 ]. Howe ver , in ‘science of science’ research, most stud- ies hav e analyzed macroscopic collaboration networks aggre- gated across time, discipline, and individuals [ 11 – 21 ]. Hence, despite these significant efforts, we know little about how properties of the local social network affect scientists’ strate- gic career decisions. For example, how might creativ e op- portunities in the local collaboration network impact a re- searcher’ s decision to explore ne w avenues versus exploit- ing old partnerships, and what may be the career tradeoffs in the short versus the long-term, especially considering that academia is driv en by dynamic knowledge frontiers [ 22 , 23 ]. Against this background, we de velop a quantitati ve ap- proach for improving our understanding of the role of weak and strong ties, meanwhile uncovering a third classification – the ‘super tie’ – which we find to occur rather frequently . W e analyzed longitudinal career data for researchers from cell bi- ology and physics, together comprising a set of 473 researcher profiles spanning more than 15,000 career years, 94,000 pub- lications, and 166,000 collaborators. In order to account for prestige ef fects, we define 2 groups within each discipline set, facilitating a comparison of top-cited scientists with scientists that are more representativ e of the entire researcher population (henceforth referred to as “other”). From the N i publication records spanning the first T i career years of each central sci- entists i , we constructed longitudinal representations of each scientist’ s coauthorship history . W e adopt an ego-centric perspectiv e in order to track re- search careers from their inception along their longitudinal growth trajectory . By using a local perspective we control for the heterogeneity in collaboration patterns that e xists both be- tween and within disciplines. W e also control for other career - specific collaboration and productivity dif ferences that would otherwise be av eraged out by aggregate cross-sectional meth- ods. Thus, by simultaneously lev eraging multiple features of the data – resolved over the dimensions of time, indi viduals, productivity , and citation impact – our analysis contributes to the literature on science careers as well as team activities char - acterized by dynamic entry and exit of human, social, and cre- 2 ativ e capital. Given that collaborations in business, industry , and academia are increasingly operationalized via team struc- tures, our findings provide rele vant quantitativ e insights into the mechanisms of team formation [ 15 ], efficiency [ 24 ], and performance [ 25 , 26 ]. The organization of our study is structured as follows. The longitudinal nature of a career requires that we start by quan- tifying the tie-strength between two collaborators from two different perspectiv es: duration and strength. First we analyze the collaboration duration, L ij , defined as the time period be- tween the first and last publication between two researchers i and j . Our results indicate that the “invisible college” de- fined by collaborati ve research activities (i.e. excluding infor - mal communication channels and arm’ s length associations) is surprisingly dominated by high-frequenc y interactions lasting only a few years. W e then focus our analysis on the collab- orativ e ‘tie strength’, K ij , defined as the cumulative number of publications coauthored by i and j during the L ij years of activity . From the entire set of collaborators, we then identify a sub- set of ‘super tie’ coauthors – those j with K ij values that are statistically unlikely according to an author-specific extreme- value criteria. Because almost all of the researchers we ana- lyzed hav e more than one super tie, and roughly half of the publications we analyzed include at least one super-tie coau- thor , we were able to quantify the added value of super ties – for both for productivity and citation impact – in two ways, (i) using descriptiv e measures and (ii) implementing a fixed- effects regression model. Controlling for author-specific fea- tures, we find that super ties are associated with increased publication rates and increased citation rates. W e term this finding the ‘apostle effect’, signifying the dividends generated by extreme social ties based upon mu- tual trust, conviction, and commitment. This term borro ws from biblical conte xt, where an apostle represents a distin- guished partner selected according to his/her notew orthy at- tributes from among a large pool of candidates. What we do not connote is any particular power relation (hierarchy) be- tween i and the super tie coauthors, which is be yond the scope of this study . Also, because the perspecti ve is centered around i , our super-tie definition is not symmetric, i.e. if j is a super tie of i , i is not necessarily a super tie of j . Because super ties have significant long-term impact on productivity and citations, our results are important from a career dev elopment perspectiv e, reflecting the strategic ben- efits of cost, risk, and rew ard-sharing via long-term partner- ship. The implications of research partnerships will become increasingly relev ant as more careers become inextricably em- bedded in team science environments, wherein it can be dif- ficult to identify contributions, signal achie vement, and dis- tribute credit. The credit distrib ution problem has receiv ed recent attention from the perspectives of institutional policy [ 8 ], team ethics [ 7 ], and practical implementation [ 27 – 29 ]. Results Defining the ego collaboration network. Our frame work as- sumes the perspective of the central scientist i in the ego net- work formed by all of his/her collaborators (index ed by j ). W e use longitudinal publication data from Thompson Reuters W eb of Kno wledge (TR WOK), comprising 193 biology and 280 physics careers. Each career profile is constructed by ag- gregating the collaboration metadata o ver the first t = 1 . . . T i years of his/her career . W e downloaded the TR WOK data in calendar year Y i , which is the citation count census year . Each disciplinary set includes a subset of 100 highly-cited scien- tists (hereafter referred to as “top”), selected using a rank- ing of the top-cited researchers in the high-impact journals Physical Review Letters and Cell . The rest of the researcher profiles (“other”) are aggregated across physics and cell biol- ogy , with subsets that are specifically activ e in the domains of graphene, neuroscience, molecular biology , and genomics. The “other” dataset only includes i with at least as many publi- cations as the smallest N i among the top-cited researchers: as such, N i ≥ 52 for biology and N i ≥ 46 for physics. This fa- cilitates a reasonable comparison between “top” and “other”, possibly identifying differences attributable to innate success factors. See the Supporting Information T ext ( SI T e xt ) for fur - ther details on the data selection. This longitudinal approach le verages author-specific fac- tors, rev ealing how career paths are affected by idiosyncratic ev ents. T o motiv ate this point, Fig. 1 illustrates the career trajectory of A. Geim, co-winner of the 2010 Nobel Prize in Physics. This schematic highlights three fundamental dimen- sions of collaboration ties – duration, strength, and impact: (a) each horizontal line indicates the collaboration of length L ij ≡ t f ij − t 0 ij + 1 between i and coauthor j , beginning with their first joint publication in year t 0 ij and ending with their last observed joint publication in year t f ij ; (b) the circle color indicates the total number of joint pub- lications, K ij , representing our quantitative measure of ‘tie strength’; (c) the circle size indicates the net citations C ij = P p c j,p in Y i , summed o ver all publications p that include i and j . Figs. S1 and S2 in the SI T ext further illustrate the variability in collaboration strengths, both between and within career profiles. It is also worth mentioning that since multiple j may contribute to the same p , it is possible for coauthor measures to covary . Howe ver , for the remainder of the analysis we focus on the dyadic relations between only i and j , leaving the triadic and higher-order ‘team’ structures as an av enue for future work. F or example, it would be interesting to kno w the likelihood of triadic closure between any two super ties of i , signaling coordinated cooperation; or contrariwise, low triadic closure rates may indicate hierarchical organization around i . 3 FIG. 1: V isualizing the embedding of academic careers in dy- namic social netw orks. A career schematic sho wing A. Geim’ s col- laborations, ordered by entry year . Notable career events include the first publication in 2000 with K. S. No voselov (co-winner of the 2010 Nobel Prize in Physics) and their first graphene publication in 2004. An interesting network reorganization accompanies Geim’ s institu- tional move from Radboud Univ ersity Nijmegen (NL) to U. Manch- ester (UK) in 2001. Moreover , the rapid accumulation of coauthors following the 2004 graphene disco very signals the new opportunities that accompany reputation gro wth. Quantifying the collaboration lifetime distribution. W e use L ij to measure the duration of the producti ve interaction be- tween i and j . W e find that a remarkable 60 to 80 percent of the collaborations hav e L ij = 1 year (see SI T ext Fig. S4). Considering the overwhelming dominance of the L ij = 1 ev ents, in this subsection we concentrate our analysis on the subset of repeat collaborations ( L ij > 1 ) which produced tw o or more publications. Furthermore, due to censoring bias, L ij values estimated for j who are activ e around the final career year of the data ( T i ) may be biased towards small v alues. T o account for this bias, in this subsection we also exclude those collaborations that were activ e within the final L c i -year period, defining L c i as an initial average L ij value calculated across all j for each i . Then, we calculate a second representativ e mean value, h L i i , which is calculated excluding the j with L ij = 1 and the j acti ve in the final L c i -year period. Figure 2(A) shows the probability distrib ution P ( h L i i ) , with mean values rang- ing from 4 to 6 years, consistent with the typical duration of an early career position (e.g. PhD or postdoctoral fellow , as- sistant professor). Establishing statistical regularities across research profiles requires the use of a normalized duration measure, ∆ ij ≡ L ij / h L i i , which controls for author-specific collaboration patterns by measuring time in units of h L i i . The empirical distributions are right-ske wed, with approximately 63% of the data with L ij < h L i i (corresponding to ∆ ij < 1 ). Never - theless, approximately 1% of collaborations last longer than 4 h L i i ≈ 15 to 20 years. Moreo ver , Fig. 2(A) sho ws that the log-logistic probability density function (pdf) P (∆) = ( b/a )(∆ /a ) b − 1 (1 + (∆ /a ) b ) 2 , (1) provides a good fit to the empirical data over the entire range of ∆ ij . The log-logistic (Fisk) pdf is a well-known surviv al analysis distribution with property Median (∆) = a . By con- struction, the mean v alue h ∆ i ≡ 1 , which reduces our param- eter space to just b as a = sin( π /b ) / ( π/b ) . For each dataset we calculate b ≥ 2 . 6 , estimating the parameter using ordinary least-squares. Associated with each P (∆) is a hazard function representing the likelihood that a collaboration terminates for a gi ven ∆ ij . Since b > 1 , the hazard function is unimodal, with a maximum value occurring at ∆ c = a ( b − 1) 1 /b with bounds ∆ c > a for b > 2 and ∆ c > 1 for b > 2 . 83 ... ; using the best-fit a and b values we estimate ∆ c ≈ 0.94 (top biol- ogy), 1.11 (other biology), 0.77 (top ph ysics), and 1.08 (other physics). Thus, ∆ c represents a tipping point in the sustain- ability of a collaboration, because the lik elihood that a collab- oration terminates peaks at ∆ c and then decreases monoton- ically for ∆ ij > ∆ c . This observation lends further signifi- cance to the author-specific time scale h L i i . The log-logistic pdf is also characterized by asymptotic po wer-la w behavior P (∆) ∼ ∆ − ( b +1) for large ∆ ij . In order to determine ho w the ∆ ij values are distributed across the career , we calculated the mean duration h ∆ | t i using a 5-year (sliding windo w) moving a verage centered around career age t . If the ∆ ij values were distributed independent of t , then h ∆ | t i ≈ 1 . Instead, Figure 2(B) shows a negati ve trend for each dataset. Interestingly , the h ∆ | t i values are consistently larger for the top scientists, indicating that the relatively short L ij are more concentrated at larger t . This pattern of increasing access to short-term collaboration opportunities points to an additional positiv e feedback mechanism contrib uting to cumulati ve advantage [ 30 , 31 ]. 4 FIG. 2: Log-logistic distribution of collaboration duration. (A) The probability distribution P (∆) is right-skewed and well-fit by the log-logistic pdf defined in Eq. [1]. (Insets) The probability distribution P ( h L i i ) show that the characteristic collaboration length in physics and biology is typically between 2 and 6 years. (B) The decrease in the typical collaboration timescale, h ∆ | t i , reflects how careers transition from being pursuers of collaboration opportunities to attractors of collaboration opportunities. Quantifying the collaboration life cycle. The P (∆) distri- bution points to the v ariability of time scales in the scientific collaboration network – while a small number of collabora- tions last a lifetime, the remainder decay quite quickly in a collaboration en vironment characterized by a remarkably high churn rate. Since it is possible that a relatively long L ij corre- sponds to just the minimum 2 publications, it is also important to analyze the collaboration rate. T o this end, we quantify the patterns of growth and decay in tie strength using the more than 166,000 dyadic ( ij ) collaboration records: K ij ( t ) is the cumulativ e number of coauthored publications between i and j up to year t , and ∆ K ij ( t ) = K ij ( t ) − K ij ( t − 1) is the annual publication rate. In order to define a collaboration trajectory that is better suited for av eraging, we normalize each individual ∆ K ij ( τ ) by its peak value, ∆ K 0 ij ( τ ) ≡ ∆ K ij ( τ ) / Max[∆ K ij ( τ )] . (2) Here τ ≡ τ ij = t − t 0 ij + 1 is the number of years since the initiation of a giv en collaboration. This normalization proce- dure is useful for comparing and av eraging time series’ that are characterized by just a single peak. Expecting that the collaboration trajectories depend on the tie strength, we grouped the indi vidual ∆ K 0 ij ( τ ) according to the normalized coauthor strength, x ij ≡ K ij / h K i i . The nor- malization factor h K i i = S − 1 i P S i j =1 K ij is calculated across the S i distinct collaborators (the collaboration radius of i ), and represents an intrinsic collaboration scale which grows in proportion to both an author’ s typical collaboration size and his/her publication rate. W e then aggregated the N { x } trajec- tories in each { x } group and calculated the av erage trajectory h ∆ K 0 ij ( τ | x ) i ≡ N − 1 { x } X { x } ∆ K 0 ij ( τ | x ) . (3) Indeed, Fig. 3 shows that the collaboration ‘life cycle’ ∆ K ij ( τ | x ) depends strongly on the relativ e tie strength x ij ≡ K ij / h K i i . The trajectories with x ij > 12 . 0 decay o ver a relativ ely long timescale, maintaining a v alue approximately 0 . 2 Max[∆ K ij ( τ )] even 20 years after initiation, reminis- cent of a ‘research life partner’. The trajectories with x ij ∈ [0 . 9 , 1 . 4] represent common collaborations that decay expo- nentially ov er the characteristic time-scale h L i i . A mathe- 5 FIG. 3: Gro wth and decay of collaboration ties. (A,B) A verage collaboration intensity , normalized to peak value, measured τ ij years after the initiation of the collaboration tie. (Insets) On log-linear axes the decay appears as linear , corresponding to an exponential form. (C,D) For each { x } group we show the av erage and standard deviation (error bar) of τ 1 / 2 ; we use logarithmically spaced { x } groups that correspond by color to the same { x } as in panels (A,B). The ζ value quantifies the scaling of h τ 1 / 2 i as a function of the normalized coauthor strength x ij ≡ K ij / h K i i . The sub linear ( ζ < 1 ) values indicate that collaborations are distributed over a timescale that grows slower than proportional to x ; con versely , this means that longer collaborations are relati vely more producti ve, being characterized by increasing mar ginal returns ( 1 /ζ > 1 ). SI Appendix Fig. S3 shows the analogous plot for the other physics and biology datasets; all 4 datasets exhibit similar features. matical side note, useful as a modeling benchmark, is the lin- ear decay when plotted on log-linear axes, suggesting a func- tional form that is e xponential for large τ , h ∆ K 0 ij ( τ | x ) i ∼ exp[ − τ /τ ] . W e further emphasize the ramifications of the life-c ycle variation by quantifying the relation between x ij and the collaboration’ s half-life τ 1 / 2 , defined as the number of years to reach half of the total collaborati ve output according to the relation K ij ( t = τ 1 / 2 ) = K ij / 2 . W e observe a scaling relation h τ 1 / 2 i ∼ x ζ with ζ v alues ranging from 0.4 to 0.5. Sublinear values ( ζ < 1 ) indicate that a collaboration with twice the strength is likely to have a corresponding τ 1 / 2 that is less-than doubled. This feature captures the burstiness of collaborati ve acti vities, which likely arises from the heterogenous o verlapping of multiple timescales, e.g. the variable contract lengths in science ranging from single-year contracts to lifetime tenure, the overlapping of multiple age cohorts, and the projects and grants themselves which are typically characterized by relati vely short terms. Nev ertheless, dx/dτ 1 / 2 ∼ τ (1 − ζ ) /ζ 1 / 2 is increasing function for ζ < 1 , indicating an increasing marginal returns with increasing τ 1 / 2 , further signaling the productivity benefits of long-term collaborations characterized by formalized roles, mutual trust, experience, and group learning that together facilitate ef ficient interactions. Quantifying the tie-strength distribution. Here we focus on the cross-sectional distribution of tie strengths within the ego network. W e use the final tie strength value K ij to distinguish the strong ties ( K ij ≥ h K i i ) from the weak ties ( K ij < h K i i ). Figure 4(A) shows the cumulative distribution P ( ≤ h K i i ) of the mean tie strength h K i i , which can vary o ver a wide range depending on a researcher’ s inv olvement in large team science activities. W e also quantify the concentration of tie strength using the Gini index G i calculated from each researcher’ s K ij values; the distribution P ( ≤ G i ) is sho wn in Fig. 4(B). T o- gether , these two measures capture the variability in collab- oration strengths across and within discipline, with physics exhibiting lar ger h K i i and G i values. Another important author-specific variable is the publica- tion ov erlap between each researcher and his/her top col- laborator . This measure is defined as the fraction of a re- searcher’ s N i publications including his/her top collaborator , f K,i = M ax j [ K ij ] / N i . W e observe surprisingly large varia- tion in f K,i , with mean and standard deviation in the range of 0 . 16 ± 0 . 14 for the top scientists and 0 . 36 ± 0 . 23 for the other scientists. Across all profiles, the min and max f K,i values are 0 . 03 and 0 . 99 , respecti vely , representing nearly the maximum possible variation in observed publication overlap. An exam- ple of this limiting scenario is shown in Fig. S2, highlight- ing the “dynamic duo” of J. L. Goldstein and M. S. Brown, winners of the 1985 Nobel Prize in Physiology or Medicine; 6 FIG. 4: Characteristic measures of collaboration tie strength. (A) Cumulativ e distribution of the mean collaboration strength, h K i i . The K olmogorov-Smirnov (K-S) test indicates that the P ( h K i i ) are similar for biology ( p = 0 . 031 ) and significantly dif- ferent for physics ( p = 0 . 004 ). V ertical lines indicate median value. (B) Cumulative distribution of G i . The pairwise K-S test indicates that the P ( G i ) are similar for biology ( p = 0 . 14 ) but not for physics ( p = 0 . 02 ). V ertical lines indicate the mean value, with physics indicating significantly higher G i than for biology . (C,D) For each dataset, the cumulative distrib ution of normalized collaboration strength x ij shows excellent agreement with the exponential distri- bution E ( x ) = exp[ − x ] (gray line) ov er the bulk of the distrib ution, with the deviations in the tail regime representing less than 0.1% of the data. Goldstein and Brown published more than 450 publications each, with roughly 100 × f K,i ≈ 95% coauthored together . Remarkably , we find that ov erlaps lar ger than 50% are not un- common, observing 100 P ( f K ≥ 0 . 5) ≈ 9% (biology) and 100 P ( f K ≥ 0 . 5) ≈ 20% (physics) of i having more than half of their publications with their strongest collaborator . Howe ver , within a researcher profile, it is likely that more than just the top collaborator was central to his/her career . Indeed, key to our in vestigation is the identification of the extremely strong collaborators – super ties – that are distin- guished within the subset of strong ties. Hence, using the empirical information contained within each researcher’ s tie- strength distribution, P ( K ij ) , we develop an objectiv e super- tie criteria that is author-specific. First, in order to gain a bet- ter understanding of the statistical distribution of K ij , we ag- gregated the tie-strength data across all research profiles, us- ing the normalized collaboration strength x ij . Figures 4(C,D) show the cumulative distribution P ( ≥ x ) for each discipline. Each P ( ≥ x ) is in good agreement with the exponential dis- tribution exp[ − x ] (with mean value h x i = 1 by construction), with the e xception in the tail, P ( ≥ x ) . 10 − 3 , which is home to extreme collaborator outliers. Thus, by a second means in addition to the result for L ij , we find that roughly 2/3 of the ties we analyzed are weak (i.e. the fraction of observations with x ij < 1 is gi ven by 1 − 1 /e ≈ 0 . 63 ). Based upon this empirical evidence, we use the discrete exponential distribution as our baseline model, P ( K ij ) ∝ exp( − κ i K ij ) . W e then use extreme statistics ar guments to precisely define the author-specific super-tie threshold K c i . The extreme statistic criteria posits that out of the S i em- pirical observations there should be just a single observation with K ij > K c i . The threshold K c i is operationalized by in- tegrating the tail of P ( K ij ) according to the equation 1 /S i = P ∞ K ij >K c i P ( K ij ) = exp( − κ i K c i ) , with the analytic relation h K i i = P ∞ K ij =1 K ij P ( K ij ) = e κ i / ( e κ i − 1) ≈ 1 + 1 /κ i for small κ i . In the relati vely large S i limit, K c i is given by the simple relation K c i = ( h K i i − 1) ln S i . (4) The advantage of this approach is that K c i is nonparametric, depending only on the observ ables h K i i and S i . Thus, the super-tie threshold is proportional to h K i i − 1 (the − 1 arises because the minimum K ij value is 1), with a logarithmically factor ln S i reflecting the sample size dependence. This ex- treme v alue criteria is generic, and can be deriv ed for any data following a baseline distrib ution; for a succinct explanation of this analytic method see page 17 of ref. [ 32 ]. In what follo ws, we label each coauthor j with K ij > K c i a super tie, with indicator variable R j ≡ 1 . The rest of the ties with K ij ≤ K c i hav e an indicator variable R j ≡ 0 . This method has limitations, specifically in the case that the collaboration profile does not follow an exponential P ( K ij ) . For example, consider the extreme case where every K ij = 1 , meaning that K c i = 0 (independent of S i ), resulting in all coauthors being super ties ( R j = 1 for all j ). This scenario is rare and unlik ely to occur for researchers with relativ ely large N i and S i , as in our researcher sample. Quantifying the prev alence and impact of super ties. How common are super ties? For each profile we denote the num- ber of coauthors that are super ties by S R,i (with complement S ! R,i = S i − S R,i ). SI T ext Fig. S4 sho ws that the distribution of S R,i is rather broad, with mean and standard deviation S R,i values: 18 ± 13 (top bio.), 16 ± 13 (other bio.), 7 . 3 ± 4 . 8 (top phys.), 6 . 8 ± 5 . 1 (other phys.). The super-tie coauthor frac- tion, f R,i = S R,i /S i , measures the super-tie frequency on a per-collaborator basis, with mean v alue h f R i ≈ 0 . 04 (i.e. typ- ically 1 super tie for ev ery 25 coauthors). Furthermore, Fig. 5(A) sho ws that the distribution P ( ≤ f R ) is common across the four datasets. W e tested the universality of the probabil- ity distribution P ( f R ) between the top and other researcher datasets using the Kolmogoro v-Smirnov (K-S) statistic, which tests the null h ypothesis that the data come from the same un- derlying pdf. The smallest pairwise K-S test p -value between any two P ( f R ) is p = 0 . 21 , indicating that we fail to reject the null hypothesis that the distributions are equal, highlight- ing that the four datasets are remarkably well-matched with respect to the distribution of f R,i . On a per paper basis, Fig. 5(B) sho ws that the fraction of a researcher’ s portfolio coauthored with at least one super tie, f N ,i , can vary over the entire range of possibilities, with mean and standard deviation 0 . 50 ± 0 . 18 (top bio.), 0 . 74 ± 0 . 13 (other bio.), 0 . 42 ± 0 . 19 (top phys.), 0 . 58 ± 0 . 23 (other phys.). Furthermore, we found that 41% of the top scientists have f N ,i ≥ 0 . 5 . Interestingly , the distributions of f K,i and f N ,i indicate that top scientists have lower le vels of super -tie de- 7 FIG. 5: The fr equency of super ties. V ertical lines indicate the dis- tribution mean. (A) Cumulativ e distribution of the fraction f R,i of the S i coauthors that are super ties. All pairwise comparisons of the distributions hav e K-S p -value greater than 0.21 indicating a com- mon underlying distribution P ( f R ) . (B) Cumulative distribution of the fraction f N ,i of publications that include at least one super-tie coauthor . The top scientist distributions show mean values that are significantly smaller than their counterparts. (C) Cumulativ e distri- bution of the fraction f K,i of publications coauthored with his/her top collaborator . The mean and standard deviation for biology (top) is 0 . 15 ± 0 . 16 , for biology (other) is 0 . 31 ± 0 . 16 , for physics (top) is 0 . 17 ± 0 . 13 , and for physics (other) is 0 . 38 ± 0 . 26 . (D) The mean rate of super-ties per new collaboration, h λ R ( t ) i , av eraged over all the profiles in each dataset using observations aggregated over con- secutiv e 3-year periods. pendency than their counterparts. W e also analyzed the arriv al rate of super-ties. For each pro- file we tracked the number of super ties initiated in year t , and normalized this number by the total number of ne w collabora- tions initiated in the same year . This ratio, λ R,i ( t ) , estimates the likelihood that a new collaboration eventually becomes a super tie as a function of career age t . For example, using the set of collaborations initiated in each scientist’ s first year , we estimate the likelihood that a first-year collaborator (mentor) becomes a super tie at λ R ( t = 1) = 8% (top bio.), 16% (other bio.), 14% (top phys.), and 15% (other phys.). Figure 5(D) shows the mean arriv al rate, h λ R ( t ) i , calculated by av erag- ing over all profiles in each dataset. The super tie arri val rate declines across the career, reaching a 5% likelihood per new collaborator at t = 20 and 2.5% likelihood by t = 30 . The decay is not as fast for the top-cited scientists, possibly re- flecting their preferential access to outstanding collaborators. Howe ver , the estimate for large t is biased tow ard smaller val- ues because collaborations initiated late in the career may not hav e had sufficient time to gro w . In the next two subsections, we in vestigate the role of super ties at the micro lev el by analyzing producti vity at the annual time resolution and the citation impact of individual publications. In the SI T e xt we provide additional evidence for the advantage of super ties by de veloping descriptive methods that measures the net producti vity and citations of the super ties relativ e to all other ties. The Apostle effect I: Quantifying the impact of super ties on annual productivity . W e analyzed each research profile ov er the career years t i ∈ [6 , M in (29 , T i )] , separating the data into non-ov erlapping ∆ t -year periods, and neglecting the first 5 years to allow the L ij ( t ) and K ij ( t ) sufficient time to grow . W e then modeled the dependent v ariable, n i,t / h n i i , which is the productivity aggregated over ∆ t -year periods, normalized by the baseline a verage calculated ov er the period of analysis. Recent analysis of assistant and tenured profes- sors has shown that the annual publication rate is gov erned by slow but substantial growth across the career , with fluctuations that are largely related to collaboration size [ 24 ]. T o better understand the factors contributing to producti v- ity growth, we include controls for career age t along with four additional variables measuring the composition of col- laborators from each ∆ t -year period. First, we calculated the av erage number of authors per publication, a i,t , a proxy for labor input, coordination costs, and the research technology lev el. Second, we calculated the mean duration, L i,t , by a ver- aging the L ij ( t − ∆ t ) values (from the pre vious period) across only the j who are active in t – i.e. those coauthors with ∆ K ij ( t ) > 0 . In this way , we account for the possibility that j was not activ e in the pre vious period ( t − ∆ t ) , in which case L ij ( t − ∆ t ) is e ven smaller than L ij ( t ) − ∆ t . Thus, L i,t mea- sures the prior experience between i and his/her collaborators. Third, for the same set of coauthors as for L i,t , we calculated the Gini index of the collaboration strength, G K i,t , using the tie strength v alues up to the previous period, K ij ( t − ∆ t ) . Thus, G K i,t provides a standardized measure of the dispersion in coauthor activity , with values ranging from 0 (all coauthors published equally in the past with i ) to 1 (extreme inequality in prior publication with i ). Thus, while L i,t measures the lifetime of the group’ s prior collaborations, G K i,t measures the concentration of their prior experience. And finally , for each period t , we calculated the contribution of super tie collabora- tors normalized by the contribution of all other collaborators, ρ i,t ≡ P j | R =1 ∆ K ij ( t ) P j | R =0 ∆ K ij ( t ) , (5) accounting for the possibility that the relative contribution of super ties may affect productivity . While the total coauthor contribution P j ∆ K ij ( t ) is highly correlated with n i,t , the correlation coefficient between ρ i,t and n i,t is only 0.07. W e only include researchers in this analysis if there are ≥ 4 data points for which the denominator of Eq. [5] is nonzero. W e implemented a fixed ef fects regression of the model n i,t h n i i = β i, 0 + β a ln a i,t + β L L i,t + β G G K i,t + β ρ ρ i,t + β t t i,t + i,t , (6) which accounts for author-specific time-in variant features ( β i, 0 ), using rob ust standard errors to account for autocorrela- tion within each i . Because the predictors are calculated from the same ego profile, co variance is e xpected; for example, the highest correlation coefficient between any two independent variables is 0 . 32 between ln a i,t and G K i,t , because the variance 8 in K ij increases proportional to the sample size (i.e. a i,t ) . T a- ble 1 shows the results of our model estimates for ∆ t = 1 year and T able S1 sho ws the results for ∆ t = 3 years. W e also ran the regression for all the datasets together,“ All”, and provide standardized coefficients that better f acilitate a comparison of the coefficient magnitudes. W e observed a positiv e coefficient β ρ = 0 . 11 ± 0 . 01 ( p ≤ 0 . 003 for all datasets), meaning that larger contributions by super ties is associated with abov e-average productivity . By way of example, consider a scenario where the super ties contribute a third of the total coauthor input, corresponding to ρ i,t = 0 . 5 , the av erage ρ i,t value we observed. Consider a second scenario with ρ i,t = 1 , corresponding to equal input by the super ties and their counterparts ( ρ i,t ≥ 1 for 14% of the observ ations). If all other parameters contribute a baseline productivity v alue 1, then the additional contribution from β ρ corresponds to a 100 × 0 . 5 β ρ / (1 + 0 . 5 β ρ ) = 5 . 2 % producti v- ity increase. This v alue is consistent with the 5% productivity spillov er observed in a study of star scientists [ 33 ]. W e also found that periods corresponding to higher lev els of prior e xperience are associated with below-a verage produc- tivity ( β L < 0 , p ≤ 0 . 008 for all datasets except for top bi- ology). Despite the costs associated with tie-formation, this result demonstrates that productivity can benefit from collab- orator turnover . Nev ertheless, above-a verage producti vity is associated with higher inequality in the concentration of prior experience ( β G > 0 , p < 0 . 001 le vel for all datasets). T o- gether , these results point to the benefits of strategically pair- ing new collaborators with incumbent ones in order to pro- mote the atypical combination of kno wledge backgrounds and to achie ve higher scientific impact [ 34 ]. In T able 1 we also re- port standardized coefficients that facilitate a comparison of the relativ e strengths of the model v ariables, re vealing that β G is twice as strong as β ρ and β L . Interestingly , β ρ and β L hav e opposite signs, yet are balanced in magnitude, suggesting a compensation strategy for group managers. The age coefficient β t is also positiv e ( p < 0 . 001 level for all datasets), consistent with patterns of steady producti vity growth observed for successful research careers [ 5 , 24 , 31 ]. Possible explanatory variables to consider in extended anal- yses are the standard de viation in K ij , a contact frequency ( K ij /L ij ) measure of tie strength intensity per Granovetter’ s original operationalization [ 10 ], and absolute calendar year y , variables which we omit here to k eep the model streamlined. The A postle effect II: Quantifying the impact of super ties on the long-term citation of individual publications. Deter- mining the impact of super ties on a publication’ s long-term citation tally is difficult to measure, because clearly older pub- lications have had more time to accrue citations than newer ones – a type of censoring bias – and so a direct comparison of ra w citations counts for publications from different years is technically flawed. T o address this measurement problem, we map each publication’ s citation count c i,p,Y ( y ) in census year Y i to a normalized z -score, z i,p,y ≡ ln c i,p,Y ( y ) − h ln c m Y ( y ) i σ [ln c m Y ( y )] . (7) This citation measure is well-suited for the comparison of publications from dif ferent y because z i,p,y is measured rel- ativ e to the mean h ln c m Y ( y ) i number of citations by publica- tions from the same year y , in units of the standard deviation, σ [ln c m Y ( y )] [ 31 ]. Thus, we take advantage of the fact that the distribution of citations obeys a uni versal log-normal distribu- tion for p from the same y and discipline [ 35 ]. In this way , z is defined such that the distribution P ( z ) is sufficiently time in- variant. T o confirm this property , we aggregated z i,p,y within successiv e 8-year periods, and calculated the conditional dis- tributions P ( z | y ) , which are stable and approximately nor- mally distributed over the entire sample period ( SI T ext Fig. S5). T o define the detrending indices h ... i and σ [ ... ] we use the baseline journal set m comprising all research articles col- lected from the journals Natur e , Proceedings of the National Academy of Science , and Science . W e use this aggregati on of three multidisciplinary journals only to control for the time dependent feature of citation counts. W e chose these jour- nals as our baseline because they hav e relativ ely large impact factors (high citation rates), and so the temporal information contained in h ... i and σ [ ... ] is less noisy than other m with lower citation rates. Furthermore, since most publications reach their peak citation rate within 5-10 years after publi- cation [ 5 ], we only analyze z i,p,y with y ≤ 2003 . In this way , the z i,p,y values we analyze are less sensiti ve to fluctuations early in the citation lifecycle, in addition to recent paradigm shifts in science such as the internet, which af fects the search, the retrie val, and the citation of prior literature, and the rise of open-access publishing. In our regression model we use 5 explanatory variables which are author ( i ) and publication ( p ) specific. The first is the number of coauthors, a i,p , which controls for the tendency for publications with more coauthors to receiv e more citations [ 4 ]. This variable is also a gross level of technology and co- ordination costs, since larger teams typically reflect endeav- ors with higher technical challenge distributed across a wider range of skill sets. W e use ln a i,p since the range of values is rather broad, appearing to be approximately log-normally dis- tributed in the right tail [ 7 ]. The second explanatory variable is the dummy v ariable R i,p which takes the value 1 if p in- cludes a super tie and the value 0 otherwise. Remarkably , the percentage of publications including a super tie is rather close to parity for three of the four datasets: 54% (top biology), 45% (top physics), 74% (other biology) and 54% (other physics). The third age variable t i,p is the career age of i at the time of publication. The fourth variable N i ( t p ) is the total number of publications up to year t i,p which is a non-citation-based mea- sure of the central author’ s reputation, visibility , and experi- ence within the scientific community . The final explanatory variable is the collaboration radius, S i ( t p ) , which is the cu- mulativ e number of distinct coauthors up to t i,p , representing the central author’ s access to collaborati ve resources, as well as an estimate of the number of researchers in the local com- munity who, having published with i , may preferentially cite i . Hence, by including N i ( t p ) and S i ( t p ) , we control for two dimensions of cumulati ve adv antage that could potentially af- fect a publication’ s citation tally . 9 T ABLE I: Parameter estimates for the producti vity model in Eq. (6) using ∆ t = 1 year long periods, and the citation model in Eq. (8) using only the publications with y p ≤ 2003 . Each fixed effects model was calculated using robust standard errors, implemented by the Huber/White/sandwich method. V alues significant at the p ≤ 0 . 04 le vel are indicated in boldf ace. “Std. coeff. ” represents the estimates of the standardized (beta) coefficients.“ All” corresponds to the combination of all datasets. Apostle effect I: producti vity model ( n i,t ) Dataset A ln a t L t G K t ρ t t N obs. Adj. R 2 All 466 0 . 002 ± 0 . 029 − 0 . 054 ± 0 . 008 1 . 788 ± 0 . 134 0 . 110 ± 0 . 013 0 . 029 ± 0 . 002 8483 0.19 (Std. coeff.) 0 . 002 ± 0 . 033 − 0 . 140 ± 0 . 021 0 . 320 ± 0 . 024 0 . 140 ± 0 . 016 0 . 049 ± 0 . 004 p -value 0 . 943 0 . 000 0 . 000 0 . 000 0 . 000 Biology (top) 99 − 0 . 123 ± 0 . 056 − 0 . 011 ± 0 . 018 2 . 816 ± 0 . 270 0 . 111 ± 0 . 026 0 . 031 ± 0 . 003 2202 0.24 p -value 0 . 031 0 . 519 0 . 000 0 . 000 0 . 000 Biology (other) 95 − 0 . 061 ± 0 . 056 − 0 . 067 ± 0 . 025 1 . 654 ± 0 . 287 0 . 071 ± 0 . 023 0 . 053 ± 0 . 006 1467 0.29 p -value 0 . 275 0 . 008 0 . 000 0 . 003 0 . 000 Physics (top) 100 − 0 . 146 ± 0 . 057 − 0 . 047 ± 0 . 015 2 . 053 ± 0 . 287 0 . 153 ± 0 . 025 0 . 022 ± 0 . 004 2056 0.15 p -value 0 . 012 0 . 002 0 . 000 0 . 000 0 . 000 Physics (other) 172 0 . 089 ± 0 . 050 − 0 . 065 ± 0 . 013 1 . 495 ± 0 . 213 0 . 101 ± 0 . 021 0 . 026 ± 0 . 005 2758 0.15 p -value 0 . 079 0 . 000 0 . 000 0 . 000 0 . 000 Apostle effect II: citation model ( z i,p ) Dataset A ln a p R p t p ln N i ( t p ) ln S i ( t p ) N obs. Adj. R 2 All 377 0 . 263 ± 0 . 024 0 . 202 ± 0 . 023 − 0 . 061 ± 0 . 004 0 . 062 ± 0 . 066 0 . 065 ± 0 . 072 68589 0.27 (Std. coeff.) 0 . 135 ± 0 . 012 0 . 129 ± 0 . 015 − 0 . 039 ± 0 . 003 0 . 044 ± 0 . 046 0 . 050 ± 0 . 055 p -value 0 . 000 0 . 000 0 . 000 0 . 347 0 . 367 Biology (top) 100 0 . 263 ± 0 . 039 0 . 213 ± 0 . 033 − 0 . 029 ± 0 . 007 − 0 . 138 ± 0 . 102 0 . 062 ± 0 . 112 22135 0.12 p -value 0 . 000 0 . 000 0 . 000 0 . 177 0 . 578 Biology (other) 55 0 . 579 ± 0 . 053 0 . 152 ± 0 . 066 − 0 . 031 ± 0 . 015 − 0 . 179 ± 0 . 095 0 . 211 ± 0 . 094 4801 0.20 p -value 0 . 000 0 . 026 0 . 040 0 . 065 0 . 029 Physics (top) 100 0 . 139 ± 0 . 043 0 . 230 ± 0 . 044 − 0 . 070 ± 0 . 007 0 . 277 ± 0 . 118 − 0 . 119 ± 0 . 135 22673 0.19 p -value 0 . 002 0 . 000 0 . 000 0 . 021 0 . 380 Physics (other) 122 0 . 272 ± 0 . 042 0 . 235 ± 0 . 049 − 0 . 060 ± 0 . 008 0 . 082 ± 0 . 095 0 . 017 ± 0 . 104 18980 0.19 p -value 0 . 000 0 . 000 0 . 000 0 . 389 0 . 870 W e then implement a fixed-ef fects regression to estimate the parameters of the citation impact model, z i,p = β i, 0 + β a ln a i,p + β R R i,p + β t t i,p + β N ln N i ( t p ) + β S ln S i ( t p ) + i,p , (8) using the Huber/White/sandwich method to calculate robust standard error estimates that account for heteroskedasticity and within-panel serial correlation in the idiosyncratic error term i,p . W e excluded publications with y p > 2003 , and in order that the ‘top’ and ‘other’ datasets are well-balanced, we also excluded the ‘other’ researchers with less than 43 (bio) and 33 (phys.) publications (observations) as of 2003. T able 1 lists the (standardized) parameter estimates. W e estimated β R = 0 . 20 ± 0 . 02 ( p ≤ 0 . 026 level in each regression), indicating a significant relativ e citation increase when a publication is coauthored with at least one super tie. The standardized β a and β R coefficients are roughly equal, meaning that increasing a p from 1 (a solo author publica- tion) to e ≈ 3 coauthors produces roughly the same effect as a change in R p from 0 to 1. Thus, while larger team size correlates with more citations [ 4 ], the relativ e strength of β R stresses the importance of ‘who’ in addition to ‘how man y’. Interestingly , the career age parameter β t = − 0 . 061 ± 0 . 004 is negati ve (significant at the p ≤ 0 . 04 le vel in each regression), meaning that researchers’ normalized citation im- pact decreases across the career , possibly due to finite career and kno wledge life-cycles. This finding is consistent with a large-scale analysis of researcher histories within high-impact journals, which also shows a ne gati ve trend in the citation im- pact across the career [ 31 ]. Neither the reputation ( β N ) nor collaboration radius ( β S ) parameters were consistently statis- 10 tically significant in explaining z i,p,y , likely because they are highly correlated with t p for established researchers. Modi- fications to consider in followup analysis are controls for the impact factor of the journal publishing p , the absolute year y in order to account for shifts in citation patterns in the post- internet era, and removing self-citations from super ties. Un- fortunately , this last task requires a substantial increase in data cov erage, far beyond the relativ ely small amount needed to construct individual e go-network collaboration profiles. W e develop three additional descriptiv e methods in the SI T ext to compare the subset of publications with at least one super-tie to the complementary subset of publications with- out one. These in vestigations provide further e vidence for the apostle effect. First, we defined an aggregate career measure, the producti vity premium p N ,i (see SI T ext Eq. [S1]), which measures the average K ij value among the super ties relativ e to all the other collaborators. Second, we defined a similar ca- reer measure, the citation premium p C,i (see SI T e xt Eq. [S5]), which quantifies the av erage citation impact attributable to su- per ties relativ e to all the other collaborators. Independent of dataset, we observed rather substantial pre- mium values. For example, the productivity premium has an av erage value h p N i ≈ 8 , meaning that on a per-collaborator basis, productivity with super ties is roughly 8 times higher than the remaining collaborators. Similarly , the citation pre- mium p C,i is also significantly right-ske wed, with average value h p C i ≈ 14 , meaning that net citation impact per super tie is 14 times larger than the net citation impact from all other collaborators. W e emphasize that p C,i appropriately accounts for team size by using an equal partitioning of citation credit across the a p coauthors, remedying the multiplicity problem concerning citation credit. And third, we calculated an additional estimation of the publication-lev el citation adv antage due to super ties. For both biology and physics, we found that the publications with super ties receiv e roughly 17% more citations than their counterparts. In basic terms, this means that the av erage pub- lication with a super tie has 21 more citations in biology and 8 more citations in physics than the av erage publication without a super tie. This is not a tail effect, because the citation boost factor α R = 1 . 17 applies a multiplicative shift to the entire citation distribution, P ( ˜ c | R p = 1) ≈ P ( α R ˜ c | R p = 0) , thereby impacting publications abov e and below the a verage. Discussion The characteristic collaboration size in science has been steadily increasing over the last century [ 4 , 7 , 21 ] with con- sequences at ev ery level of science, from education and aca- demic careers to univ ersities and funding bodies [ 8 ]. Un- derstanding how this team-oriented paradigm shift affects the sustainability of careers, the efficienc y of the science system, and society’ s capacity to ov ercome grand challenges, will be of great importance to a broad range of scientific actors, from scientists to science policy makers. Collaborativ e activities are also fundamental to the career growth process, especially in disciplines where research ac- tivities require a division of labor . This is especially true in biology and physics research, where computational, theoret- ical, and experimental methods provide complementary ap- proaches to a wide array of problems. As a result, a con- temporary research group leader is likely to find the assem- bly of team – one which is composed of individuals with di- verse yet complementary skill sets – a daunting task, espe- cially when under constraints to optimize financial resources, valuable facilities, and other material resources. Online social network platforms, such as VIVO (http://www .viv oweb .org/) and Pr ofiles RNS (http://profiles.catalyst.harvard.edu/), which serve as match-making recommendation systems, have been dev eloped to facilitate the challenges of team assembly . Our analysis indicates that 2/3 of the collaborations ana- lyzed here are “weak”. Nevertheless, the remaining strong ties represent social capital in vestments that can indeed have important long-term implications, for example on information spreading [ 17 ], career paths [ 36 ], and access to key strategic resources [ 37 ]. In the pri vate sector strong ties facilitate ac- cess to ne w growth opportunities, playing an important role in sustaining the competitiv eness of firms and employees [ 38 ]. These considerations further identify why it is important for researchers to understand the opportunities that exist within their local network. Understanding the redundancies in the local network [ 39 ] and the interaction capacity of team mem- bers [ 25 ] can help a group leader optimize group intelligence [ 26 ] and monitor team efficiency [ 24 ], thereby constituting a source of strategic competiti ve adv antage. In summary , we developed methods to better understand the div ersity of collaboration strengths. W e focused on the ca- reer as the unit of analysis, operationalized by using an ‘ego’ perspectiv e so that collaborations, publications, and impact scores fit together into a temporal framew ork ideal for cross- sectional and longitudinal modeling. Analyzing more than 166,000 collaborations, we found that a remarkable 60%-80% of the collaborations last only L ij = 1 year . W ithin the subset of repeat collaborations ( L ij ≥ 2 years), we find that roughly 2/3 of these collaborations last less than a scientist’ s av erage duration h L i i ≈ 5 years, yet 1% last more than 4 h L i i ≈ 20 years. This wide range in duration and the disparate frequen- cies of long and short L ij , together point to the dichotomy of burstiness and persistence in scientific collaboration. Closer inspection of individual career paths signals how idiosyncratic ev ents, such as changing institutions or publishing a seminal study or book, can ha ve significant downstream impact on the arriv al rate of new collaboration opportunities and tie forma- tion (see Figs. 1 and S1). Also, the frequency of relativ ely large publication ov erlap measures ( f K,i and f N ,i ) indicates that career partners occur rather frequently in science. In the first part of the study we provide descriptiv e insights into basic questions such as how long are typical collabora- tions, how often does a scientist pair up with his/her main collaborator , and what is the characteristic half-life of a col- laboration. W e also found that as the career progresses, re- searchers become attractors rather than pursuers of new col- laborations. This attractive potential can contribute to cumula- 11 tiv e advantage [ 30 , 31 ], as it provides select researchers access to a large source of collaborators, which can boost productiv- ity and increase the potential for a big discov ery . W e operationalized tie strength using an ego-centric per- spectiv e of the collaboration network. Because the number of publications K ij between the central scientist i and a given coauthor j was found to be exponentially distributed, the mean value h K i i is a natural author-specific threshold that distinguishes the strong ( K ij ≤ h K i i ) from the weak ties ( K ij < h K i i ). W ithin the subset of strong ties we iden- tified ‘super tie’ outliers using an analytic extreme-statistics threshold K c i defined in Eq. [4]. Also, because the number of publications produced by a collaboration is highly correlated with its duration, a super tie also represents persistence that is in excess of the stochastic churn rate that is characteristic of the scientific system. On a per-collaborator basis, the fraction of coauthors within a research profile that are super ties ( f R,i ) was remarkably common across datasets, indicating that super ties occur at an av erage rate of 1 in 25 collaborators. There are v arious candidate explanations for why such ex- tremely strong collaborations exist. Prosocial motiv ators may play a strong role, i.e. for some researchers doing science in close community may be more rew arding than going alone. Also, the search and formation of a compatible partnership requires time and other social capital in vestment, i.e. net- working. Hence, for two researchers who hav e found a col- laboration that leverages their complementarity , the potential benefits of improving on their match are likely outweighed by the long-term returns associated with their stable partner- ship. Complementarity , and the greater skill-set the part- nership brings, can also provide a competitiv e advantage by way of research agility , whereby a larger collective resource base can facilitate rapid adjustments to new and changing knowledge fronts, thereby balancing the risks associated with changing research direction. After all, a first-mov er advantage can make a significant difference in a winner-tak es-all credit & rew ard system [ 2 ]. Scientists may also strategically pair up in order to share costs, re wards, and risk across the career . In this light, an additional incentiv e to form super ties may be explained, in part, by the benefits of re ward-sharing in the current scientific credit system, wherein publication and citation credit arising from a single publication are multiplied across the a p coau- thors in ev eryday practice. Considered in this way , the career risk associated with productivity lulls can be reduced if a close partnership is formed. For example, we observed a few ‘twin profiles’ characterized by a publication overlap fraction f K,i between the researcher and his/her top collaborator that was nearly 100%. Moreov er , we found that 9% of the biologists and 20% of the physicists shared 50% or more of their pa- pers with their top collaborator . This highlights a particularly difficult challenge for science, which is to de velop a credit system which appropriately divides the net credit, but at the same does not reduce the incentives for scientists to collabo- rate [ 8 , 27 – 29 ]. Thus, it will be important to consider these relativ ely high levels of publication and citation overlap in the dev elopment of quantitativ e career ev aluation measures, oth- erwise there is no penalty to discourage coauthor free-riding [ 7 ]. W e concluded the analysis by implementing two fixed- effects regression models to determine the sign and strength of the ‘apostle effect’ represented by β ρ (productivity) and β R (citations). T ogether , these two coefficients address the funda- mental question: is there a measurable adv antage associated with heavily in vesting in a select group of research partners? In the first model we measured the impact of super ties on a researcher’ s annual publication rate, controlling for career age, av erage team size, the prior experience of i with his/her coauthors, and the relative contribution of super ties within year t as measured by ρ i,t in Eq. [5]. W e found larger ρ i,t to be associated with abov e-average productivity ( β ρ > 0 ), in- dicating that super ties play a crucial role in sustaining career growth. W e also found increased lev els of prior experience to be associated with decreased productivity ( β L < 0 ), suggest- ing that maintaining redundant ties conflicts with the potential benefits from mixing new collaborators into the en vironment. Nev ertheless, higher inequality in the concentration of prior experience was found to hav e a positi ve ef fect on productivity ( β G > 0 ). In the second regression model we analyzed the impact of super ties on the citation impact of individual publications, using the detrended citation measure z i,p,y defined in Eq. [7]. This citation measure is normalized within publication year cohorts, thus allowing for a comparison of citation counts for research articles published in different years. W e found that publications coauthored with super ties, corresponding to 52% of the papers we analyzed, have a significant increase in their long-term citations ( β R > 0 ). In the SI T ext we provide additional evidence for the apostle effect, showing that publications with super ties recei ve 17% more citations. This added v alue may arise from the extra visibility the publications recei ves, since the super-tie collaborator may also contribute a substantial reputation and future productivity that promote the visibility of the publication. This type of network-mediated reputation spillover is corroborated by a recent study finding a significant citation boost attributable to a researcher’ s centrality within the collaboration network [ 40 ]. Policy r ecommendations. In all, these results provide quantitativ e insights into the benefits associated with strong collaborativ e partnerships and the value of skill-set com- plementarity , social trust, and long-term commitment. This data-oriented analysis also contributes to the literature on the science of science policy [ 41 ], providing insight and guidance in an increasingly metrics-based ev aluation system on ho w to account for individual achie vement in team settings. One particularly rele vant scenario is fello wship, tenure, and career award ev aluations, where it is a common practice to consider “independence from one’ s thesis advisor” as a selection criteria. W e show that in order to assess a researcher’ s independence, e valuation committees should also take into consideration the level of publication overlap between a researcher and his/her strongest collaborator(s). e.g. f K,i and f N ,i . Y et at the same time, the beneficial role of super ties – as we hav e quantitativ ely demonstrated – should also be acknowledged and supported. For example, funding 12 programs might consider career awards that are specifically multipolar [ 8 ], which would also benefit the research partners in academia who are actually life partners, and who may face the daunting “two-body problem” of coordinating two research careers. Furthermore, understanding the basic levels of publication overlap in science is also important for the ex post facto revie w of funding outcomes as a means to ev aluate the ef ficiency of science. In lar ge-team settings, measuring the efficienc y of a laboratory or project is difficult without a better understanding of how to measure overlapping labor inputs (i.e., collaborator contributions) relative to the project outputs (e.g., publications, patents, etc.). Finally , our study informs early career researcherswho are likely to face important decisions concerning the (possibly strategic) selection of collaborative opportunitieson the positive impact that the right research partner can hav e on their careers long-term sustainability and growth. In all, our results provide quantitative insights into the benefits associated with strong collaborative partnerships, pointing to the added value deriv ed from skill-set complementarity , social trust, and long-term commitment. Acknowledgments The author is grateful for helpful discus- sions with O. Doria, M. Imbruno, B. T uncay , and R. Metulini and constructive criticism and keen insights from two anony- mous referees. The author also acknowledges support from the Italian Ministry of Education for the National Research Project (PNR) “Crisis Lab” (http://www .crisislab.it/) and for feedback from participants of the European Union COST Ac- tion TD1210 (KnowEscape) workshop on “Quantifying sci- entific impact: networks, measures, insights?” [1] B ¨ orner K, et al. (2010) A multi-lev el systems perspectiv e for the science of team science. Science T ranslational Medicine 2:49cm24. [2] Stephan P (2012) How Economics Shapes Science (Harvard Univ ersity Press, Cambridge MA, USA). [3] Nahapiet J, Ghoshal S (1998) Social capital, intellectual capital, and the organizational advantage. Acad. of Management Rev . 23:242–266. [4] W uchty S, Jones BF , Uzzi B (2007) The increasing dominance of teams in production of knowledge. Science 316:1036–1039. [5] Petersen AM, et al. (2014) Reputation and impact in aca- demic careers. Pr oceedings of the National Academy of Sci- ences 111:15316–15321. [6] Malmgren RD, Ottino JM, Amaral LAN (2010) The role of mentorship in protege performance. Nature 463:622–626. [7] Petersen AM, Pavlidis I, Semendeferi I (2014) A quantitative perspectiv e on ethics in large team science. Sci. & Eng. Ethics. 20:923–945. [8] Pa vlidis I, Petersen AM, Semendeferi I (2014) T ogether we stand. Nature Physics 10:700–702. [9] Borgatti SP , Mehra A, Brass DJ, Labianca G (2009) Network analysis in the social sciences. Science 323:892–895. [10] Granov etter MS (1973) The strength of weak ties. Amer . J. Sociology 78:1360–1380. [11] Newman MEJ (2001) The structure of scientific collaboration networks. Pr oceedings of the National Academy of Sciences 98:404–409. [12] Newman MEJ (2001) Scientific collaboration networks. I. network construction and fundamental results. Phys. Rev . E 64:016131. [13] Barabasi AL, et al. (2002) Evolution of the social network of scientific collaborations. Physica A: Statistical Mechanics and its Applications 311:590 – 614. [14] Newman MEJ (2004) Coauthorship networks and patterns of scientific collaboration. Pr oceedings of the National Academy of Sciences 101:5200–5205. [15] Guimera R, Uzzi B, Spiro J, Amaral LAN (2005) T eam assem- bly mechanisms determine collaboration network structure and team performance. Science 308:697–702. [16] Palla G, Barabasi AL, V iscek T (2007) Quantifying social group ev olution. Natur e 446:664–667. [17] Pan RK, Saram ¨ aki J (2012) The strength of strong ties in scien- tific collaboration networks. EPL 97:18007. [18] Martin T , Ball B, Karrer B, Ne wman MEJ (2013) Coauthor- ship and citation patterns in the physical review . Phys. Rev . E 88:012814. [19] Ke Q, Ahn YY (2014) T ie strength distribution in scientific collaboration networks. Phys. Rev . E 90:032804. [20] B ¨ orner K, Maru JT , Goldstone RL (2004) The simultaneous ev olution of author and paper networks. Pr oceedings of the National Academy of Sciences 101:5266–5273. [21] Milojevic S (2014) Principles of scientific research team for- mation and ev olution. Pr oceedings of the National Academy of Sciences 111:3984–3989. [22] March JG (1991) Exploration and exploitation in organizational learning. Organizational Science 2:71–87. [23] Lazer D, Friedman A (2007) The network structure of explo- ration and exploitation. Adm. Sci. Quarterly 52:667–694. [24] Petersen AM, Riccaboni M, Stanley HE, Pammolli F (2012) Persistence and uncertainty in the academic career . Pr oc. Natl. Acad. Sci. USA 109:5213 – 5218. [25] Pentland A (2012) The new science of building great teams. Harvar d Business Review 90:60–69. [26] W oolley A W , et al. (2010) Evidence for a collectiv e intelligence factor in the performance of human groups. Science 330:686– 688. [27] Stallings J, et al. (2013) Determining scientific impact using a collaboration index. Proceedings of the National Academy of Sciences 110:9680–9685. [28] Allen L, Brand A, Scott J, Altman M, Hlava M (2014) Credit where credit is due. Nature 508:312–313. [29] Shen HW , Barabasi AL (2014) Collecti ve credit allocation in science. Pr oceedings of the National Academy of Sciences 111:12325–12330. [30] Petersen AM, Jung WS, Y ang JS, Stanley HE (2011) Quan- titativ e and empirical demonstration of the Matthew effect in a study of career longevity . Proceedings of the National Academy of Sciences 108:18–23. [31] Petersen AM, Penner O (2014) Inequality and cumulativ e ad- vantage in science careers: a case study of high-impact journals. EPJ Data Science 3:24. [32] Krapivsk y P , Redner S, Ben-Naim E (2010) A kinetic view of statistical physics (Cambridge Univ ersity Press, Cambridge, UK). 13 [33] Azoulay P , Zivin JSG, W ang J (2010) Superstar extinction. Q. J. of Econ. 125:549–589. [34] Uzzi B, Mukherjee S, Stringer M, Jones B (2013) Atypical combinations and scientific impact. Science 342:468–472. [35] Radicchi F , Fortunato S, Castellano C (2008) Univ ersality of citation distributions: T oward an objecti ve measure of scientific impact. Proc. Natl. Acad. Sci. USA 105:17268–17272. [36] Clauset A, Arbesman S, Larremore DB (2015) Systematic in- equality and hierarchy in faculty hiring networks. Science Ad- vances 1. [37] Duch J, et al. (2012) The possible role of resource requirements and academic career-choice risk on gender differences in pub- lication rate and impact. PLoS One 125:e51332. [38] Uzzi B (1999) Embeddedness in the making of financial cap- ital: Ho w social relations and networks benefit firms seeking financing. Amer . Soc. Rev . 64:481–505. [39] Burt RS (1992) Structural Holes (Harv ard University Press, Cambridge MA, USA). [40] Sarigl E, Pfitzner R, Scholtes I, Garas A, Schweitzer F (2014) Predicting scientific success based on coauthorship networks. EPJ Data Science 3:9. [41] Fealing KH, eds. (2011) The science of science policy: A hand- book. (Stanford Business Books, Stanford CA, USA).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment