Partitioning Large Scale Deep Belief Networks Using Dropout
Deep learning methods have shown great promise in many practical applications, ranging from speech recognition, visual object recognition, to text processing. However, most of the current deep learning methods suffer from scalability problems for large-scale applications, forcing researchers or users to focus on small-scale problems with fewer parameters. In this paper, we consider a well-known machine learning model, deep belief networks (DBNs) that have yielded impressive classification performance on a large number of benchmark machine learning tasks. To scale up DBN, we propose an approach that can use the computing clusters in a distributed environment to train large models, while the dense matrix computations within a single machine are sped up using graphics processors (GPU). When training a DBN, each machine randomly drops out a portion of neurons in each hidden layer, for each training case, making the remaining neurons only learn to detect features that are generally helpful for producing the correct answer. Within our approach, we have developed four methods to combine outcomes from each machine to form a unified model. Our preliminary experiment on the mnst handwritten digit database demonstrates that our approach outperforms the state of the art test error rate.
💡 Research Summary
The paper addresses the scalability bottleneck of Deep Belief Networks (DBNs), which are powerful but computationally intensive models. The authors propose a distributed training framework that leverages the dropout technique not only as a regularizer but also as a means to reduce the size of the network that each worker must train. In this scheme, each machine in a cluster randomly drops a fraction p of neurons in every hidden layer for each training case, thereby creating a smaller sub‑network. Because the number of parameters in a sub‑network scales roughly with (1‑p)², the memory footprint and arithmetic workload per worker are dramatically reduced, allowing the use of GPUs on each node without exceeding device memory limits.
To combine the independently trained sub‑networks into a single model, the authors introduce four strategies: (1) simple averaging of the final weight matrices from all workers, (2) majority voting over the predictions of each sub‑network on test instances, (3) synchronous parameter updates via a central parameter server where each worker fetches the latest weights, computes gradients, and pushes updated weights back, waiting for all others before proceeding, and (4) asynchronous lock‑free updates where workers read and write parameters without coordination, accepting possible race conditions for lower communication overhead. The synchronous method guarantees consistency at the cost of higher latency, while the asynchronous method introduces extra stochasticity but can achieve near‑linear speed‑up.
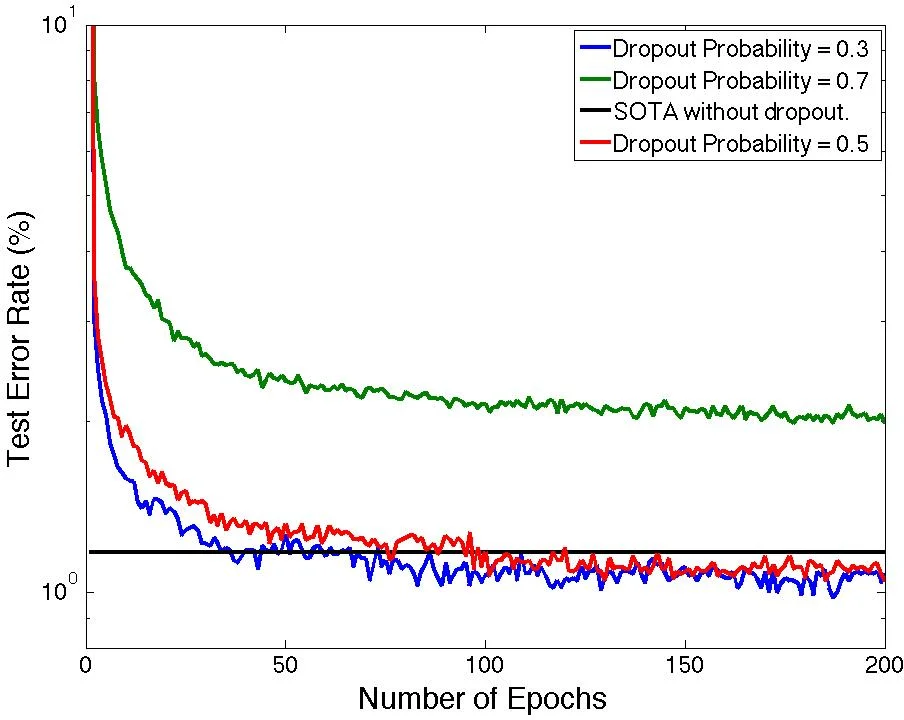
The implementation builds on Theano for GPU‑accelerated matrix operations and uses inter‑process communication (IPC) for data exchange among workers. The source code is released publicly. Experiments are conducted on the MNIST handwritten digit benchmark using a 784‑500‑500‑2000‑10 architecture. The network is first pretrained as a stack of Restricted Boltzmann Machines for 50 epochs, then fine‑tuned with dropout for 200 epochs. Dropout rates of 20 % on the input layer and 50 % on hidden layers are employed.
Results show that the dropout probability strongly influences generalization: moderate dropout (p≈0.5) yields the lowest test error, while higher dropout (>0.6) degrades performance, likely due to insufficient training epochs. Among the combination methods, weight averaging and synchronous updates achieve the best error rates of 0.98 % and 0.97 % respectively, surpassing the previously reported best DBN result of 1.18 % on MNIST. Majority voting and asynchronous updates perform slightly worse (1.04 % and 1.06 %).
The paper’s contributions are fourfold: (1) a novel dropout‑driven model parallelism that reduces per‑node parameter count, (2) an open‑source prototype that integrates GPU acceleration with cluster‑level parallelism, (3) four distinct model‑combination techniques that trade off consistency, communication cost, and accuracy, and (4) empirical validation demonstrating that the approach not only scales but also improves classification accuracy on a standard benchmark.
In discussion, the authors compare their method to existing frameworks such as DistBelief, highlighting that DistBelief partitions the full network without reducing its size, leading to high communication overhead, whereas their dropout‑based partitioning inherently lowers communication volume. They also note that while asynchronous updates are attractive for large‑scale systems, further theoretical analysis of convergence is needed. Future work is suggested on applying the framework to larger, more complex datasets (e.g., CIFAR‑10, ImageNet) and exploring peer‑to‑peer parameter synchronization to eliminate the central server bottleneck. Overall, the study demonstrates that integrating dropout with distributed training offers a practical path to scaling deep belief networks without sacrificing, and even improving, predictive performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment