Logical Concurrency Control from Sequential Proofs
We are interested in identifying and enforcing the isolation requirements of a concurrent program, i.e., concurrency control that ensures that the program meets its specification. The thesis of this paper is that this can be done systematically start…
Authors: Jyotirmoy Deshmukh (University of Texas at Austin), G. Ramalingam (Microsoft Research India), Venkatesh-Prasad Ranganath (Microsoft Research India)
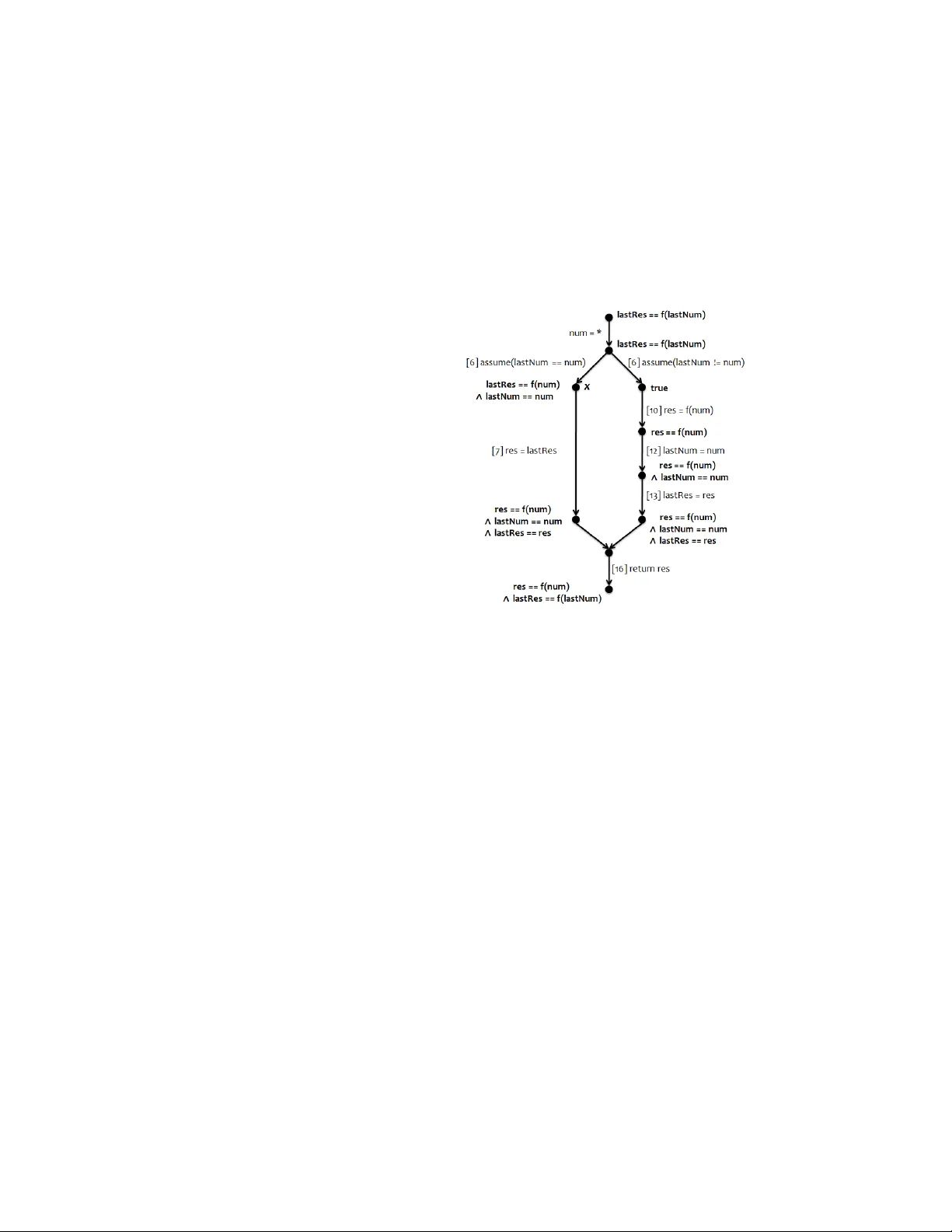
Logical Methods in Computer Science V ol. 7 (3:10) 2011, pp . 1–29 www .lmcs-online.org Submitted Jun.26, 2010 Published Sep . 2, 2011 LOGICAL CONCURRENCY CONTR OL FR OM SEQUENTIAL PROOFS JYOTIRMO Y DESHMUKH a , G. RAMALINGAM b , VENKA TESH-PRASAD RANGANA TH c , AND KAPIL V ASW ANI d a Univ ersity of T exas at Austin e-mail addr ess : jy otirmoy@cerc.utexas.edu b,c,d Microsoft Research, India e-mail addr ess : grama@microsoft.com, rvprasad@microsoft.com, k apilv@microsoft.com Abstract. W e are in terested in iden tifying and enforcing the isolation r e quir ements of a concurrent program, i.e., concurrency con trol that ensures that the program meets its sp ecification. The thesis of this pap er is that this can be done systematically starting from a sequential pro of, i.e., a pro of of correctness of the program in the absence of concurrent in terleavings. W e illustrate our thesis b y presenting a solution to the problem of making a sequential library thread-safe for concurrent clients. W e consider a sequential library annotated with assertions along with a pro of that these assertions hold in a sequen tial execution. W e show how we can use the pro of to deriv e concurrency control that ensures that any execution of the library metho ds, when inv ok ed by concurren t clients, satisfies the same assertions. W e also present an extension to guarantee that the library methods are linearizable or atomic. 1. Introduction A k ey c hallenge in concurren t programming is iden tifying and enforcing the isolation r e- quir ements of a program: determining what constitutes undesirable interference b etw een differen t threads and implementing concurrency con trol mechanisms that preven t this. In this pap er, we show how a solution to this problem can b e obtained systematically from a se quential pr o of : a proof that the program satisfies a sp ecification in the absence of concurren t interlea ving. Pr oblem Setting. W e illustrate our thesis b y considering the concrete problem of making a sequen tial library safe for concurren t clien ts. Informally , giv en a sequential library that w orks correctly when in v ok ed by any sequential client, w e sho w ho w to syn thesize concur- rency control co de for the library that ensures that it will w ork correctly when inv ok ed by an y concurrent clien t. 1998 ACM Subje ct Classific ation: D.1.3, D.2.4, F.3.1. Key wor ds and phr ases: concurrency control, program synthesis. a W ork done while at Microsoft Research India. LOGICAL METHODS l IN COMPUTER SCIENCE DOI:10.2168/LMCS-7 (3:10) 2011 c J . Deshmukh, G. Ramalingam, V .-P . Ranganath, and K. V aswani CC Creative Commons 2 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI P art I: Ensuring Assertions In Concurren t Executions. Consider the example in Figure 1(a). The library consists of one pro cedure Compute , which applies an exp ensiv e function f to an input v ariable num . As a p erformance optimization, the implementation cac hes the last input and result. If the curren t input matc hes the last input, the last computed result is returned. 1 : int lastNum = 0; 2 : int lastRes = f (0); 3 : /* @returns f (num) */ 4 : Compute(num) { 5 : /* acquire (l); */ 6 : if(lastNum==num) { 7 : res = lastRes; 8 : } else { 9 : /* release (l); */ 10 : res = f (num); 11 : /* acquire (l); */ 12 : lastNum = num; 13 : lastRes = res; 14 : } 15 : /* release (l); */ 16 : return res; 17 : } (a) (b) Figure 1: (a) Procedure Compute (excluding Lines 5,9,11,15) applies a (side-effect free) function f to a parameter num and caches the result for later in v ocations. Lines 5,9,11,15 contain a lo ck-based concurrency con trol generated by our tec h- nique. (b) The con trol-flo w graph of Compute , its edges lab eled by statements of Compute and no des lab eled by pro of assertions. This pro cedure w orks correctly when used b y a sequential clien t, but not in the presence of concurrent pro cedure inv o cations. E.g., consider an inv o cation of Compute(5) follo w ed b y concurrent inv o cations of Compute(5) and Compute(7) . Assume that the second in v o- cation of Compute(5) ev aluates the condition in Line 6, and pro ceeds to Line 7. Assume a con text switch o ccurs at this p oint, and the inv ocation of Compute(7) executes completely , o v erwriting lastRes in Line 13. No w, when the inv o cation of Compute(5) resumes, it will erroneously return the (changed) v alue of lastRes . In this pap er, we present a technique that can detect the p otential for such interfer- ence and syn thesize concurrency con trol to prev en t the same. The (lo ck-based) solution syn thesized by our technique for the ab ov e example is shown (as commen ts) in Lines 5, 9, 11, and 15 in Figure 1(a). With this concurrency con trol, the example w orks correctly ev en for concurrent pro cedure inv o cations while p ermitting threads to p erform the exp ensive function f concurrently . The F ormal Pr oblem. F ormally , w e assume that the correctness criterion for the library is sp ecified as a set of assertions and that the library satisfies these assertions in any execution LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 3 of any sequential clien t. Our go al is to ensur e that any exe cution of the libr ary with any c oncurr ent client also satisfies the given assertions. F or our running example in Figure 1(a), Line 3 sp ecifies the desired functionalit y for pro cedure Compute : Compute returns the v alue f ( num ). L o gic al Concurr ency Contr ol F r om Pr o ofs. A key challenge in coming up with concurrency con trol is determining what interlea vings b etw een threads are safe. A conserv ativ e solution ma y reduce concurrency b y prev en ting correct in terlea vings. An aggressive solution may enable more concurrency but introduce bugs. The fundamental thesis we explore is the following: a pro of that a co de fragmen t satisfies certain assertions in a sequential execution precisely iden tifies the prop erties relied on b y the co de at differen t points in execution; hence, such a sequential pro of clearly identifies what concurrent interference can b e p ermitted; thus, a correct concurrency con trol can b e systematically (and even automatically) derived from such a pro of. W e now provide an informal o v erview of our approac h b y illustrating it for our running example. Figure 1(b) presents a pro of of correctness for our running example (in a sequential setting). The program is presented as a control-flo w graph, with its edges representing program statements. (The statemen t “ num = * ” at the en try edge indicates that the initial v alue of parameter num is unkno wn.) A pro of consists of an inv arian t µ ( u ) attached to ev ery v ertex u in the con trol-flo w graph (as illustrated in the figure) suc h that: (a) for ev ery edge u → v lab elled with a statement s , execution of s in a state satisfying µ ( u ) is guaran teed to pro duce a state satisfying µ ( v ), (b) The inv ariant µ ( entr y ) attached to the en try v ertex is satisfied by the initial state and is implied by the inv ariant µ ( exit ) attac hed to the exit vertex, and (c) for every edge u → v annotated with an assertion ϕ , w e hav e µ ( u ) ⇒ ϕ . Condition (b) ensures that the pro of is v alid o v er an y se quenc e of executions of the pro cedure. The inv ariant µ ( u ) at vertex u indicates the prop erty required (b y the pro of ) to hold at u to ensure that a sequen tial execution satisfies all assertions of the library . W e can rein terpret this in a concurrent setting as follo ws: when a thread t 1 is at p oin t u , it can tolerate c hanges to the state by another thread t 2 as long as the inv ariant µ ( u ) contin ues to hold from t 1 ’s p ersp ectiv e; ho w ever, if another thread t 2 w ere to change the state such that t 1 ’s inv arian t µ ( u ) is broken, then the contin ued execution by t 1 ma y fail to satisfy the desired assertions. Consider the pro of in Figure 1(b). The v ertex labeled x in the figure corresp onds to the p oin t b efore the execution of Line 7. The inv ariant attac hed to x indicates that the pro of of correctness depends on the condition l astRes == f ( num ) being true at x . The execution of Line 10 b y another thread will not in v alidate this condition. But, the execution of Line 13 b y another thread can p otentially in v alidate this condition. Th us, we infer that, when one thread is at p oint x , an execution of Line 13 b y another thread should b e av oided. W e preven t the execution of a statement s by one thread when another thread is at a program p oint u (if s might inv alidate a predicate p that is required at u ) as follo ws. W e introduce a lo ck p corresp onding to p , and ensure that every thread holds p at u and ensure that every thread holds p when executing s . Our algorithm does this as follo ws. F rom the in v ariant µ ( u ) at vertex u , we compute a set of predicates pm ( u ). (F or no w, think of µ ( u ) as the conjunction of predicates in pm ( u ).) pm ( u ) represen ts the set of predicates required at u . F or any edge u → v , any predicate p that is in pm ( v ) \ pm ( u ) is required at v but not at u . Hence, we acquire the lo ck for p along 4 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI this edge. Dually , for any predicate that is required at u but not at v , w e release the lo ck along the edge. As a sp ecial case, w e acquire (release) the lo cks for all predicates in pm ( u ) at pro cedure entry (exit) when u is the pro cedure en try (exit) v ertex. Finally , if the execution of the statement on edge u → v can inv alidate a predicate p that is required at some vertex, w e acquire and release the corresp onding lock b efore and after the statement (unless it is already a required predicate at u or v ). Note that our approach conserv atively assumes that an y tw o statements in the library ma y be sim ultaneously executed b y different threads. If an analysis can iden tify that certain statemen ts cannot b e simultaneously executed (by differen t threads), this information can b e exploited to improv e the solution, but this is b ey ond the scop e of this pap er. Our algorithm ensures that the lo c king sc heme do es not lead to deadlo cks by merging lo c ks when necessary , as described later. Finally , w e optimize the synthesized solution using a few simple tec hniques. E.g., in our example whenever the lo ck corresponding to lastRes == res is held, the lock for lastNum == num is also held. Hence, the first lock is redundan t and can b e eliminated. Figure 1 shows the resulting library with the concurrency con trol we synthesize. This implemen tation satisfies its sp ecification even in a concurrrent setting. The syn thesized solution permits a high degree to concurrency since it allows multiple threads to compute f concurren tly . A more conserv ative but correct lo cking sc heme would hold the lo c k during the entire procedure execution. A distinguishing asp ect of our algorithm is that it requires only local reasoning and not reasoning ab out interlea ved executions, as is common with man y analyses of concurren t programs. Note that the syn thesized solution dep ends on the pro of used. Different pro ofs can p otentially yield different concurrency control solutions (all correct, but with p otentially differen t p erformance). W e note that our approach has a close connection to the Owic ki-Gries [18] approac h to computing pro ofs for concurren t programs. The Owicki-Gries approac h shows ho w the pro ofs for tw o statements can b e comp osed into a proof for the concurren t comp osition of the statemen ts if the two statements do not interfer e with e ach other . Our approach detects p otential interference b etw een statemen ts and inserts concurrency-control so that the in terference does not o ccur (p ermitting a safe concurrent comp osition of the statements). Implementation. W e hav e implemen ted our algorithm, using an existing softw are mo del c hec k er to generate the sequential pro ofs. W e used the to ol to successfully syn thesize con- currency control for sev eral small examples. The synthesized solutions are equiv alent to those an exp ert programmer w ould use. P art I I: Ensuring Linearizability . The abov e approach can b e used to ensure that con- curren t executions guarantee desired safet y prop erties, preserv e data-structure inv ariants, and meet sp ecifications (e.g., given as a precondition/p ostcondition pair). Library imple- men tors ma y , ho w ev er, wish to pro vide the stronger guaran tee of linearizabilit y with resp ect to the sequen tial sp ecification: any c oncurr ent exe cution of a pr o c e dur e is guar ante e d to satisfy its sp e cific ation and app e ars to take effe ct instantane ously at some p oint during its exe cution . In the second half of the paper, we show how the techniques sketc hed ab ov e can b e extended to guarantee linearizabilit y . LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 5 Con tributions. W e presen t a tec hnique for syn thesizing concurrency con trol for a library (e.g., dev eloped for use b y a single-threaded clien t) to mak e it safe for use b y concurren t clien ts. Ho w ev er, we believe that the k ey idea we presen t – a tec hnique for identifying and realizing isolation requiremen ts from a sequential pro of – can b e used in other con texts as w ell (e.g., in the con text of a whole program consisting of multiple threads, eac h with its o wn assertions and sequen tial pro ofs). Sometimes a library designer ma y choose to delegate the resp onsibilit y for concurrency con trol to the clien ts of the library and not make the library thread-safe 1 . Alternatively , library implemen ters could c ho ose to make the execution of a library method app ear atomic b y wrapping it in a transaction and executing it in an STM (assuming this is feasible). These are v alid options but orthogonal to the p oint of this pap er. T ypically , a program is a softw are stac k, with eac h level serving as a library . Passing the buck, with regards to concurrency con trol, has to stop somewhere. Somewhere in the stack, the developer needs to decide what degree of isolation is required by the program; otherwise, w e w ould end up with a program consisting of m ultiple threads where we require ev ery thread’s execution to app ear atomic, which could b e rather sev ere and restrict concurrency needlessly . The ideas in this pap er provide a systematic metho d for determining the isolation requiremen ts. While we illustrate the idea in a simplified setting, it should ideally b e used at the appropriate level of the softw are stac k. In practice, full sp ecifications are rarely av ailable. W e b elieve that our technique can b e used even with light weigh t sp ecifications or in the absence of sp ecifications. Consider our example in Fig. 1. A sym b olic analysis of this library , with a harness representing a sequen tial client making an arbitrary sequence of calls to the library , can, in principle, infer that the returned v alue equals f(num) . As the returned v alue is the only observ able v alue, this is the strongest functional sp ecification a user can write. Our to ol can b e used with suc h an inferred sp ecification as w ell. L o gic al interfer enc e. Existing concurrency control mec hanisms (b oth p essimistic as well as optimistic) rely on a data-access based notion of in terference: concurren t accesses to the same data, where at least one access is a write, is conserv atively treated as interfence. A con tribution of this pap er is that it in tro duces a more logical/seman tic notion of in terference that can be used to ac hiev e more p ermissiv e, yet safe, concurrency control. Specifically , concurrency control based on this approach p ermits interlea vings that existing schemes based on stricter notion of in terference will disallow. Hand-crafted concurren t co de often p ermits “b enign in terference” for p erformance reasons, suggesting that programmers do rely on such a logical notion of interference. 2. The Problem In this section, we introduce required terminology and formally define the problem. Rather than restrict ourselves to a sp ecific syntax for programs and assertions, w e will treat them abstractly , assuming only that they can b e given a semantics as indicated b elow, whic h is fairly standard. 1 This may b e a v alid design option in some cases. How ever, in examples suc h as our running example, this could b e a bad idea. 6 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI 2.1. The Sequen tial Setting. Se quential Libr aries. A library L is a pair ( P , V G ), where P is a set of procedures (defined below), and V G is a set of v ariables, termed glob al v ariables, accessible to all and only procedures in P . A pro cedure P ∈ P is a pair ( G P , V P ), where G P is a control-flo w graph with eac h edge lab eled by a primitiv e statement, and V P is a set of v ariables, referred to as lo c al v ariables, restricted to the scop e of P . (Note that V P includes the formal parameters of P as well.) T o simplify the sem an tics, w e will assume that the set V P is the same for all pro cedures and denote it V L . Ev ery control-flo w graph has a unique en try vertex N P (with no predecessors) and a unique exit v ertex X P (with no successors). Primitiv e statements are either skip state- men ts, assignment statemen ts, assume statemen ts, return statemen ts, or assert state- men ts. An assume statemen t is used to implement conditional con trol flo w as usual. Given con trol-flo w graph no des u and v , w e denote an edge from u to v , lab eled with a primitiv e statemen t S , by u S − → v . T o reason about all p ossible sequences of inv o cations of the library’s pro cedures, we define the c ontr ol gr aph of a library to b e the union of the control-flo w graphs of all the pro cedures, augmented by a new vertex w , as w ell as an edge from every pro cedure exit v ertex to w and an edge from w to every pro cedure entry v ertex. W e refer to w as the quiesc ent vertex. Note that a one-to-one corresp ondence exists b etw een a path in the con trol graph of the library , starting from w , and the execution of a sequence of pro cedure calls. The edge w → N P from the quiescent vertex to the entry vertex of a pro cedure P mo dels an arbitrary call to pro cedure P . W e refer to these as c al l e dges . Se quential States. A pro cedure-lo cal state σ ` ∈ Σ s ` is a pair ( p c , σ d ) where p c , the program coun ter, is a vertex in the control graph and σ d is a map from the lo cal v ariables V L to their v alues. (W e use “ s ” as a sup erscript or subscript to indicate elements of the semantics of sequen tial execution.) A global state σ g ∈ Σ s g is a map from global v ariables V G to their v alues. A library state σ is a pair ( σ ` , σ g ) ∈ Σ s ` × Σ s g . W e define Σ s to b e Σ s ` × Σ s g . W e sa y that a state is a quiesc ent state if its p c v alue is w and that it is an entry state if its p c v alue equals the entry v ertex of some pro cedure. Se quential Exe cutions. W e assume a standard semantics for primitive statements that can b e captured as a transition relation s ⊆ Σ s × Σ s as follo ws. Ev ery control-flo w edge e induces a transition relation e s , w here σ e s σ 0 iff σ 0 is one of the p ossible outcomes of the execution of (the statemen t lab eling) the edge e in state σ . The edge w → N P from the quiescen t v ertex to the entry vertex of a procedure P models an arbitrary call to procedure P . Hence, in defining the transition relation, such edges are treated as statements that assign a non-deterministically c hosen v alue to ev ery formal parameter of P and the default initial v alue to ev ery lo cal v ariable of P . Similarly , the edge X P → w is treated as a skip statemen t. W e say σ s σ 0 if there exists some edge e such that σ e s σ 0 . A se quential exe cution is a sequence of states σ 0 σ 1 · · · σ k where σ 0 is the initial state of the library and we hav e σ i s σ i +1 for 0 ≤ i < k . A sequen tial execution represen ts the execution of a sequence of calls to the library’s procedures (where the last call’s exe- cution may b e incomplete). Giv en a sequential execution σ 0 σ 1 · · · σ k , w e say that σ i is the c orr esp onding entry state of σ j if σ i is an en try state and no state σ h is an en try state for i < h ≤ j . Se quential Assertions. W e use assert statemen ts to sp ecify desired correctness prop erties of the library . Assert statements ha ve no effect on the execution seman tics and are equiv alent LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 7 to skip statements in the seman tics. Assertions are used only to define the notion of wel l- b ehave d executions as follows. An assert statement is of the form assert θ where, θ is a 1-state assertion ϕ or a 2-state assertion Φ. A 1-state assertion, which we also refer to as a predicate, mak es an assertion ab out a single library state. Rather than define a specific syn tax for assertions, w e assume that the semantics of assertions are defined b y a relation σ | = s ϕ denoting that a state σ satisfies the assertion ϕ . 1-state assertions can b e used to sp ecify the in v arian ts exp ected at certain program p oin ts. In general, specifications for pro cedures tak e the form of tw o-state assertions, which relate the input state to output state. W e use 2-state assertions for this purp ose. The seman tics of a 2-state assertion Φ is assumed to b e defined b y a relation ( σ in , σ out ) | = s Φ (meaning that state σ out satisfies assertion Φ with resp ect to state σ in ). In our examples, w e use sp ecial input v ariables v in to refer to the v alue of the v ariable v in the first state. E.g., the sp ecification “ x == x in + 1” asserts that the v alue of x in the second state is one more than its v alue in the first state. Definition 2.1. A sequential execution is said to satisfy the library’s assertions if for an y transition σ i e s σ i +1 in the execution, where e is lab elled by the statemen t “ assert θ ”, w e hav e (a) σ i | = s θ if θ is a 1-state assertion, and (b) ( σ in , σ i ) | = s θ where σ in is the corresp onding en try state of σ i , otherwise. A sequen tial library satisfies its sp ecifications if ev ery execution of the library satisfies its sp ecifications. 2.2. The Concurren t Setting. Concurr ent Libr aries. A concurren t library L is a triple ( P , V G , Lk ), where P is a set of concurrent pro cedures, V G is a set of global v ariables, and Lk is a set of global lo cks. A concurrent procedure is like a sequential pro cedure, with the extension that a primitiv e statemen t is either a sequential primitiv e statement or a locking statemen t of the form acquire ( ) or release ( ) where is a lo ck. Concurr ent States. A concurren t library p ermits concurren t inv o cations of procedures. W e asso ciate each pro cedure inv o cation with a thread (represen ting the clien t thread that in v ok ed the pro cedure). Let T denote an infinite set of thread-ids, whic h are used as unique iden tifiers for threads. In a concurrent execution, every thread has a priv ate cop y of lo cal v ariables, but all threads share a single copy of the global v ariables. Hence, the lo cal-state in a concurrent execution is represen ted by a map from T to Σ s ` . (A thread whose lo cal-state’s p c v alue is the quiescen t p oint represents an idle thread, i.e., a thread not pro cessing any pro cedure inv o cation.) Let Σ c ` = T → Σ s ` denote the set of all lo cal states. A t any p oin t during execution, a lo c k lk is either free or held by one thread. W e represen t the state of lo c ks by a partial function from Lk to T indicating which thread, if an y , holds an y given lo ck. (A lock that is not held b y any thread will not b e in the domain of the partial function.) Let Σ c lk = Lk → T represent the set of all lo c k-states. Let Σ c g = Σ s g × Σ c lk denote the set of all global states. Let Σ c = Σ c ` × Σ c g denote the set of all states. Giv en a concurren t state σ = ( σ ` , ( σ g , σ lk )) and thread t , w e define σ [ t ] to b e the sequential state ( σ ` ( t ) , σ g ). Concurr ent Exe cutions. The concurren t seman tics is induced by the sequen tial semantics as follo ws. Let e b e an y control-flo w edge lab elled with a sequential primitiv e statement, and t be any thread. W e say that ( σ ` , ( σ g , σ lk )) ( t,e ) c ( σ 0 ` , ( σ 0 g , σ lk )) iff ( σ t , σ g ) e s ( σ 0 t , σ 0 g ) where 8 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI σ t = σ ` ( t ) and σ 0 ` = σ ` [ t 7→ σ 0 t ]. The transitions corresp onding to lo ck acquire/release are defined in the obvious wa y . W e say that σ c σ 0 iff there exists some ( t, e ) such that σ ( t,e ) c σ 0 . A c oncurr ent exe cution is a sequence σ 0 σ 1 · · · σ k , where σ 0 is the initial state of the library and σ i ` i c σ i +1 for 0 ≤ i < k , where the lab el i = ( t i , e i ) iden tifies the executing thread and executed edge. W e say that 0 · · · k − 1 is the sche dule of this execution. A sequence 0 · · · m is a fe asible sche dule if it is the schedule of some concurren t execution. Consider a concurrent execution σ 0 σ 1 · · · σ k . W e say that a state σ i is a t -entry-state if it is generated from a quiescen t state by thread t executing a call edge. W e say that σ i is the c orr esp onding t-entry state of σ j if σ i is a t -en try-state and no state σ h is a t -en try-state for i < h ≤ j . W e note that our semantics uses sequential consistency . Extending our results to sup- p ort weak er memory mo dels is future work. Interpr eting Assertions In Concurr ent Exe cutions. In a concurrent setting, assertions are ev aluated in the con text of the thread that executes the corresp onding assert statemen t. W e sa y that state σ satisfies a 1-state assertion ϕ in the context of thread t i (denoted b y ( σ, t i ) | = c ϕ ) iff σ [ t i ] | = s ϕ . F or an y 2-state assertion Φ, we say that a giv en pair of states ( σ in , σ out ) satisfies Φ in the context of thread t (denoted by (( σ in , σ out ) , t ) | = c Φ) iff ( σ in [ t ] , σ out [ t ]) | = s Φ. Definition 2.2. A concurren t execution π is said to satisfy an assertion “ assert θ ” la- b elling an edge e if for any transition σ i ( t,e ) c σ i +1 in the execution, we hav e (a) ( σ i , t ) | = c θ , if θ is a 1-state assertion, and (b) (( σ in , σ i ) , t ) | = c θ where σ in is the corresp onding t -en try state of σ i , otherwise. The execution is said to satisfy the library’s sp ecification if it satisfies all assertions in the library . A concurrent library satisfies its sp ecification if ev ery execution of the library satisfies its sp ecification. F r ame Conditions. Consider a library with tw o global v ariables x and y and a pro cedure IncX that increments x by 1. A p ossible sp ecification for IncX is ( x == x in + 1) && ( y == y in ). The condition y == y in is IncX ’s frame condition, whic h sa ys that it will not mo dify y . Ex- plicitly stating such frame conditions is unnecessarily restrictive, as a concurren t up date to y b y another procedure, when IncX is executing, would be considered a violation of IncX ’s sp ecification. F rame conditions can b e handled b etter by treating a sp ecification as a pair ( S, Φ) where S is the set of all global v ariables referenced b y the pro cedure, and Φ is a sp ec- ification that do es not refer to any global v ariables outside S . F or our ab ov e example, the sp ecification will b e ( { x } , x == x in + 1)). In the sequel, ho wev er, we will restrict ourselv es to the simpler setting and ignore this issue. 2.3. Goals. Our goal is: Given a sequential library L with assertions satisfied in ev ery sequen tial execution, construct ˆ L , by augmen ting L with concurrency con trol, suc h that ev ery concurren t execution of ˆ L satisfies all assertions. In Section 6, we extend this goal to construct ˆ L such that every concurren t execution of ˆ L is linearizable. LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 9 3. Preser ving Single-St a te Asser tions In this section we describ e our algorithm for synthesizing concurrency control, but restrict our attention to single-state assertions. 3.1. Algorithm Ov erview. A se quential pr o of is a mapping µ from vertices of the con trol graph to predicates such that (a) for ev ery edge e = u t − → v , { µ ( u ) } t { µ ( v ) } is a v alid Hoare triple σ 1 | = s µ ( u ) and σ 1 e s σ 2 implies σ 2 | = s µ ( v )), and (b) for every edge u assert ϕ − − − − − − → v , w e hav e µ ( u ) ⇒ ϕ . Note that condition (a) requires { µ ( u ) } t { µ ( v ) } to b e partially correct. The execution of statement t in a state satisfying µ ( u ) do es not ha v e to succeed. This is required primarily for the case when t represents an assume statement. If w e w ant to ensure that the execution of a statement t do es not cause any run time error, we can simply replace t by “ assert p ; t ” where p is the condition required to ensure that t do es not cause any run time error.) Note that the inv arian t µ ( u ) attached to a vertex u by a pro of indicates tw o things: (i) any sequen tial execution reaching p oint u will pro duce a state satisfying µ ( u ), and (ii) an y sequen tial execution from p oint u , starting from a state satisfying µ ( u ) will satisfy the in v arian ts labelling other program points (and satisfy all assertions encoun tered during the execution). A procedure that satisfies its assertions in a sequential execution may fail to do so in a concurren t execution due to interference by other threads. E.g., consider a thread t 1 that reac hes a program p oint u in a state that satisfies µ ( u ). A t this p oint, another thread t 2 ma y execute some statement that changes the state to one where µ ( u ) no longer holds. Now, w e no longer hav e a guarantee that a con tin ued execution b y t 1 will successfully satisfy its assertions. The preceding paragraph, ho w ever, hin ts at the in terference we must av oid to ensure correctness: when a thread t 1 is at p oin t u , w e should ensure that no other thread t 2 c hanges the state to one where t 1 ’s in v arian t µ ( u ) fails to hold. Any change to the state b y another thread t 2 can b e tolerated by t 1 as long as the invariant µ ( u ) c ontinues to hold . W e can ac hiev e this by asso ciating a lo ck with the inv ariant µ ( u ), ensuring that t 1 holds this lo c k when it is at program p oin t u , and ensuring that an y thread t 2 acquires this lock before executing a statemen t that ma y break this inv ariant. An inv ariant µ ( u ), in general, may b e a b o olean formula o v er simpler predicates. W e could p otentially get differen t lo c king solutions by associating differen t lo cks with different sub-form ulae of the in v arian t. W e elab orate on this idea b elo w. A pr e dic ate mapping is a mapping pm from the v e rtices of the con trol graph to a set of predicates. A predicate mapping pm is said to b e a b asis for a pro of µ if ev ery µ ( u ) can b e expressed as a b oolean formula (inv olving conjunctions, disjunctions, and negation) o v er pm ( u ). A basis pm for pro of µ is p ositive if every µ ( u ) can b e expressed as a b o olean form ula inv olving only conjunctions and disjunctions ov er pm ( u ). Giv en a pro of µ , we sa y that an edge u s − → v se quential ly p ositively pr eserves a predicate ϕ if { µ ( u ) ∧ ϕ } s { ϕ } is a v alid Hoare triple. Otherwise, w e say that the edge may se quential ly falsify the predicate ϕ . Note that the ab ov e definition is in terms of the Hoare logic for our sequen tial language. Ho w ev er, we wan t to formalize the notion of a thread t 2 ’s execution of an edge falsifying a predicate ϕ in a thread t 1 ’s scope. Given a predicate ϕ , let ˆ ϕ denote the predicate obtained by replacing every lo cal v ariable x with a new unique v ariable ˆ x . W e sa y that an edge u s − → v may falsify ϕ iff the edge may sequentially falsify ˆ ϕ . (Note 10 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI that this reasoning requires w orking with formulas with free v ariables, such as ˆ x . This is straigh tforw ard as these can b e handled just like extra program v ariables.) E.g., consider Line 13 in Fig. 1. Consider predicate l astRes == f ( num ). By renaming lo cal v ariable num to av oid naming conflicts, we obtain predicate lastRes == f( ˆ num) . W e sa y that Line 13 may falsify this predicate because the triple { r es == f ( num ) ∧ l astN um == num ∧ l astRes == f ( ˆ num ) } lastRes = res { l astRes == f ( ˆ num ) } is not a v alid Hoare triple. Let pm b e a p ositive basis for a pro of µ and R = ∪ u pm ( u ). F or an y program p oin t u , if a predicate ϕ is in pm ( u ), we sa y that ϕ is r elevant at program p oint u . In a concurrent execution, w e say that a predicate ϕ is relev ant to a thread t in a giv en state if t is at a program p oint u in the given state and ϕ ∈ pm ( u ). Our lo cking scheme asso ciates a lo c k with every predicate ϕ in R . The inv ariant it establishes is that a thread, in any state, will hold the locks corresp onding to precisely the predicates that are relev an t to it. W e will simplify the initial description of our algorithm by assuming that distinct predicates are asso ciated with distinct lo cks and later relax this requirement. Consider an y con trol-flo w edge e = u s − → v . Consider any predicate ϕ in pm ( v ) \ pm ( u ). W e say that predicate ϕ b e c omes r elevant 2 at edge e . In the m otiv ating example, the predicate lastNum == num b ecomes relev ant at Line 12 W e ensure the desired inv ariant b y acquiring the lo c ks corresp onding to every predicate that b ecomes relev an t at edge e prior to statement s in the e dge . (Acquiring the lo ck after s may b e to o late, as some other thread could in terv ene b etw een s and the acquire and falsify predicate ϕ .) No w consider an y predicate ϕ in pm ( u ) \ pm ( v ). W e sa y that ϕ b e c omes irr elevant at edge e . E.g., predicate lastRes == f(lastNum) b ecomes irrelev ant once the false branc h at Line 8 is taken. F or every p that b ecomes irrelev ant at edge e , we release the lo c k corresp onding to p after statement s . The ab o ve steps ensure that in a concurren t execution a thread will hold a lo ck on all predicates relev ant to it. The second comp onen t of the concurrency con trol mechanism is to ensure that an y thread acquires a lock on a predicate before it falsifies that predicate. Consider an edge e = u s − → v in the control-flo w graph. Consider any predicate ϕ ∈ R that ma y b e falsified b y edge e . W e add an acquire of the lo c k corrresp onding to this predicate b efore s (unless ϕ ∈ pm ( u )), and add a release of the same lo ck after s (unless ϕ ∈ pm ( v )). Managing lo cks at pr o c e dur e entry/exit. W e will need to acquire/release lo c ks at procedure en try and exit differen tly from the sc heme ab o ve. Our algorithm w orks with the control graph defined in Section 2. Recall that w e use a quiescent vertex w in the control graph. The in v arian t µ ( w ) attac hed to this quiescen t v ertex describ es in v arian ts main tained b y the library (in b etw een pro cedure calls). An y return edge u return − − − − → v must b e augmen ted to release all lo c ks corresp onding to predicates in pm ( u ) b efore returning. Dually , an y pro cedure entry edge w → u m ust be augmented to acquire all lo cks corresp onding to predicates in pm ( u ). Ho w ev er, this is not enough. Let w → u b e a pro cedure p ’s entry edge. The inv ariant µ ( u ) is part of the library in v ariant that pro cedure p dep ends up on. It is imp ortant to ensure that when a thread executes the entry edge of p (and acquires lo c ks corresp onding to the 2 F requently it will b e the case that the execution of statement s makes predicate ϕ true. This is true if ev ery in v ariant µ ( v ) is a conjunction of the basis predicates in pm ( u ). Since w e allow disjunctions as w ell, this is not, how ev er, alwa ys true. LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 11 basis of µ ( u )) the inv ariant µ ( u ) holds. W e achiev e this b y ensuring that an y pro cedure that inv alidates the inv ariant µ ( u ) holds the locks on the corresp onding basis predicates un til it reestablishes µ ( u ). W e now describ e ho w this can b e done in a simplified setting where the in v arian t µ ( u ) can b e expressed as the conjunction of the predicates in the basis pm ( u ) for ev ery pro cedure entry v ertex u . (Disjunction can b e handled at the cost of extra notational complexity .) W e will refer to the predicates that o ccur in the basis pm ( u ) of some pro cedure en try vertex u as libr ary invariant pr e dic ates . W e use an obligation mapping om ( v ) that maps each vertex v to a set of library in v ari- an t predicates to trac k the in v ariant predicates that ma y b e inv alid at v and need to b e reestablished b efore the procedure exit. W e say a function om is a v alid obligation mapping if it satisfies the follo wing constrain ts for any edge e = u → v : (a) if e ma y falsify a library in v arian t ϕ , then ϕ must b e in om ( v ), and (b) if ϕ ∈ om ( u ), then ϕ must b e in om ( v ) unless e establishes ϕ . Here, we say that an edge u s − → v establishes a predicate ϕ if { µ ( u ) } s { ϕ } is a v alid Hoare triple. Define m ( u ) to b e pm ( u ) ∪ om ( u ). Now, the sc heme describ ed earlier can b e used, except that w e use m in place of pm . L o cking along assume e dges. Recall that we mo del conditional branching, based on a con- dition p , using t w o edges lab elled “ assume p ” and “ assume ! p ”. An y lo ck to b e acquired along an assume edge will need to b e acquired b efore the condition is ev aluated. If the lo c k is required along b oth assume edges, this is sufficien t. If the lo ck is not required along all assume edges out of a vertex, then we will hav e to release the lock along the edges where it is not required. De ad lo ck Pr evention. The lo c king sc heme synthesized ab ov e may p otentially lead to a deadlo c k. W e no w show how to mo dify the lo cking sc heme to av oid this p ossibility . F or an y edge e , let mbf ( e ) b e (a conserv ative appro ximation of ) the set of all predicates that ma y b e falsified by the execution of edge e . W e first define a binary relation on the predicates used (i.e., the set R ) as follo ws: w e sa y that p r iff there exists a con trol-flo w edge u s − → v such that p ∈ m ( u ) ∧ r ∈ ( m ( v ) ∪ mbf ( u s − → v )) \ m ( u ). Note that p r holds iff it is p ossible for some thread to try to acquire a lo ck on r while it holds a lo c k on p . Let ∗ denote the transitive closure of . W e define an equiv alence relation on R as follows: p r iff p ∗ r ∧ r ∗ p . Note that an y p ossible deadlo ck m ust in v olv e an equiv alence class of this relation. W e map all predicates in an equiv alence class to the same lo ck to av oid deadlo cks. In addition to the ab o v e, we establish a total ordering on all the lo cks, and ensure that all lo ck acquisitions w e add to a single edge are done in an order consisten t with the established ordering. (Note that the ordering on the lo cks do es not hav e to b e total; a partial ordering is fine, as long as any t w o lo cks acquired along a single edge are ordered.) Impr oving The Solution. Our scheme can sometimes in troduce r e dundant lo c king. E.g., assume that in the generated solution a lock 1 is alw ays held whenev er a lo ck 2 is acquired. Then, the lo ck 2 is redundant and can b e eliminated. Similarly , if w e hav e a predicate ϕ that is nev er falsified by an y statement in the library , then w e do not need to acquire a lo ck for this predicate. W e can eliminate such redundant locks as a final optimization pass o v er the generated solution. Using R e ader-Writer L o cks. Note that a lo ck may b e acquired on a predicate ϕ for one of t w o reasons in the ab o ve scheme: either to “preserve” ϕ or to “break” ϕ . These are similar to read-lo c ks and write-lo c ks. Note that it is safe for m ultiple threads to simultaneously 12 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI hold a lo c k on the same predicate ϕ if they wan t to “preserve” it, but a thread that w an ts to “break” ϕ needs an exclusiv e lo ck. Th us, reader-writer lo cks can b e used to improv e concurrency , but space constraints prev ent a discussion of this extension. How ev er, since it is unsafe for a thread that holds a read-lo ck on a predicate ϕ to try to acquire a write-lock ϕ , using this optimization also requires an extension to the basic deadlo c k av oidance sc heme. Sp ecifically , it is unsafe for a thread that holds a read-lo ck on a predicate ϕ to try to acquire a write-lo ck ϕ , as this can lead to a deadlo ck. Hence, an y acquisition of a lo c k on a predicate ϕ (to preserv e it) should b e made an exclusive (write) lo ck if along some execution path it may b e necessary to promote this lo c k to a write lo c k b efore the lo ck is released. Gener ating Pr o ofs. The sequential pro of required by our sc heme can b e generated using v erification to ols such as SLAM [2], BLAST [11, 12] or Y ogi [10]. Predicate abstraction [2] is a program analysis technique that constructs a conserv ativ e, finite state abstraction of a program with a large (p ossibly infinite) state space using a set of predicates ov er program v ariables. T o ols such as SLAM and BLAST use predicate abstraction to chec k if a giv en program P satisfies a sp ecification φ . The to ols start with a simple initial abstraction and iterativ ely refine the abstraction until the abstraction is rich enough to prov e the absence of a concrete path from the program’s initial state to an error state (or a real error is iden tified). F or programs for which verification succeeds, the final abstraction produced, as w ell as the result of abstract interpretation using this abstraction, serv e as a go od starting p oint for constructing the desired pro of. The final abstraction consists of a predicate map pm whic h maps each program p oint to a set of predicates and as w ell as a mapping from eac h program statement to a set of abstract predicate transformers which together define an abstract transition system. F urthermore, abstract in terpretation utilizing this abstraction effectiv ely computes a formula µ ( u ) o v er the set of predicates pm ( u ) at every program p oint u that conserv ativ ely describ es all states that can arise at program p oint u . The map µ constitutes a pro of of sequen tial correctness, as required by our algorithm, and the predicate map pm is a v alid basis for the proof. The map pm can b e extended in to a p ositive basis for the pro of easily enough. Since a minimal pro of can lead to b etter concurrency control, approaches that pro duce a “parsimonious pro of ” (e.g., see [12]) are preferable. A parsimonious pro of is one that a v oids the use of unnecessary predicates at an y program p oin t. 3.2. Complete Sc hema. W e no w present a complete outline of our schema for synthesizing concurrency control. (1) Construct a sequential pro of µ that the library satisfies the giv en assertions in any sequen tial execution. (2) Construct p ositive basis pm and an obligation mapping om for the pro of µ . (3) Compute a map mbf from the edges of the con trol graph to R , the range of pm , suc h that mbf ( e ) (conserv atively) includes all predicates in R that ma y be falsified by the execution of e . (4) Compute the equiv alence relation on R . (5) Generate a predicate lo ck allo cation map lm : R → L such that for any ϕ 1 ϕ 2 , we ha v e lm ( ϕ 1 ) = lm ( ϕ 2 ). LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 13 (6) Compute the following quan tities for ev ery edge e = u s − → v , where w e use lm ( X ) as shorthand for { lm ( p ) | p ∈ X } and m ( u ) = pm ( u ) ∪ om ( u ): BasisL o cksA c q ( e ) = lm ( m ( v )) \ lm ( m ( u )) BasisL o cksR el ( e ) = lm ( m ( u )) \ lm ( m ( v )) Br e akL o cks ( e ) = lm ( mbf ( e )) \ lm ( m ( u )) \ lm ( m ( v )) (7) W e obtain the concurrency-safe library b L by transforming every edge u s − → v in the library L as follows: (a) ∀ p ∈ BasisL o cksA c q ( u s − → v ), add an acquire ( lm ( p )) b efore s ; (b) ∀ p ∈ BasisL o cksR el ( u s − → v ), add a release ( lm ( p )) after s ; (c) ∀ p ∈ Br e akL o cks ( u s − → v ), add an acquire ( lm ( p )) b efore s and a release ( lm ( p )) after s . All lo ck acquisitions along a giv en edge are added in an order consistent with a total order established on all lo cks. 3.3. Correctness. W e now presen t a formal statement of the correctness claims for our algorithm. Let L b e a given library with a set of embedded assertions satisfied by all sequen tial executions of L . Let b L b e the library obtained b y augmenting L with concurrency con trol using the algorithm presented in Section 3.2. Let µ , pm , and om b e the pro of, the p ositiv e basis, and the obligation map used to generate b L . Consider an y concurren t execution of the giv en library L . W e sa y that a thread t is safe in a state σ if ( σ, t ) | = c µ ( u ) where t ’s program-counter in state σ is u . W e sa y that thread t is active in state σ if its program-counter is something other than the quiescent vertex. W e say that state σ is safe if every activ e thread t in σ is safe. Recall that a concurrent execution is of the form: σ 0 ` 0 − → σ 1 ` 1 − → · · · σ n , where each lab el i is an ordered pair ( t, e ) indicating that the transition is generated by the execution of edge e by thread t . W e say that a concurrent execution is safe if every state in the execution is safe. It trivially follo ws that a safe execution satisfies all assertions of L . Note that every concurrent execution π of b L corresponds to an execution π 0 of L if w e ignore the transitions corresp onding to lo ck acquire/release instructions. W e sa y that an execution π of b L is safe if the corresp onding execution π 0 of L is safe. The goal of the syn thesized concurrency control is to ensure that only safe executions of b L are p ermitted. W e say that a transition σ ( t,e ) − − → σ 0 preserv es the basis of an activ e thread t 0 6 = t whose program-coun ter in state σ is u if for ev ery predicate ϕ ∈ pm ( u ) the following holds: if ( σ, t 0 ) | = c ϕ , then ( σ 0 , t 0 ) | = c ϕ . W e sa y that a transition σ ( t,e ) − − → σ 0 ensures the basis of thread t if either e = x → y is not the pro cedure entry edge or for every activ e thread t 0 6 = t whose program-coun ter in state σ is u and for every predicate ϕ ∈ pm ( u ) none of the predicates in pm ( y ) are in om ( u ). W e sa y that a transition σ ( t,e ) − − → σ 0 is b asis-pr eserving if it preserves the basis of ev ery activ e thread t 0 6 = t and ensures the basis of thread t . A concurrent execution is said to b e b asis-pr eserving if all transitions in the execution are basis-preserving. Lemma 3.1. (a) Any b asis-pr eserving c oncurr ent exe cution of L is safe. (b) Any c oncurr ent exe cution of b L c orr esp onds to a b asis-pr eserving exe cution of L . 14 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI Pr o of. (a) W e prov e that every state in a basis-preserving execution of L is safe b y induction on the length of the execution. Consider a thread t in state σ with program-counter v alue u . Assume that t is safe in σ . Th us, ( σ, t ) | = c µ ( u ). Note that µ ( u ) can b e expressed in terms of the predicates in pm ( u ) using conjunction and disjunction. Let SP denote the set of all predicates ϕ in pm ( u ) suc h that ( σ, t ) | = c ϕ . Let σ 0 b e any state suc h that ( σ 0 , t ) | = c ϕ for every ϕ ∈ SP . Then, it follo ws that t is safe in σ 0 . Thus, it follows that after any basis-preserving transition e v ery thread that was safe b efore the transition con tin ues to b e safe after the transition. W e no w just need to v erify that whenever an inactiv e thread b ecomes active (represent- ing a new pro cedure in vocation), it starts off b eing safe. W e can establish this by inductively sho wing that every library in v arian t must be satisfied in a given state or must be in om ( u ) for some active thread t at vertex u . (b) Consider a concurren t execution of b L . W e need to sho w that ev ery transition in this execution, ignoring lo ck acquires/releases, is basis-preserving. This follows directly from our lo c king scheme. Consider a transition σ ( t,e ) − − → σ 0 . Let t 0 6 = t b e an active thread whose program-coun ter in state σ is u . F or ev ery predicate ϕ ∈ pm ( u ) ∪ om ( u ), our scheme ensures that t 0 holds the lo ck corresp onding to ϕ . As a result, b oth the conditions for preserving basies are satisfied. Theorem 3.2. (a) A ny c oncurr ent exe cution of b L satisfies every assertion of L . (b) The libr ary b L is de ad lo ck-fr e e. Pr o of. (a) This follo ws immediately from Lemma 3.1. (b) This follows from our scheme for merging lo c ks and can b e pro ved b y con tradiction. Assume that a concurrent execution of b L pro duces a deadlo ck. Then, w e must ha v e a set of threads t 1 to t k and a set of lo cks 1 to k suc h that each t i holds lo c k i and is waiting to acquire lo ck i ⊕ 1 , where i ⊕ 1 denotes ( i mo d k ) + 1. In particular, t i m ust hold lo ck i b ecause it w an ts a lo ck on some predicate p i , and must b e trying to acquire lo ck i ⊕ 1 b ecause of some predicate q i ⊕ 1 . Th us, we must hav e q i p i and p i q i ⊕ 1 for ev ery i . This implies that all of p i and q i m ust be in the same equiv alence class of and, hence, 1 through k m ust b e the same, which is a contradiction (since we m ust ha v e k > 1 to hav e a deadlo ck). As men tioned earlier, our synthesis tec hnique has a close connection to Owicki-Gries [18] approac h to verifying concurrent programs. An alternativ e approach to proving Theo- rem 3.2(a) w ould b e to construct a suitable Owic ki-Gries st yle pro of for the library . W e b eliev e that this is doable. 4. Handling 2-St a te Asser tions The algorithm presen ted in the previous section can b e extended to handle 2-state assertions via a simple program transformation that allows us to treat 2-state assertions (in the original program) as single-state assertions (in the transformed program). W e augment the set of lo cal v ariables with a new v ariable ˜ v for ev ery (lo cal or shared) v ariable v in the original program and add a primitive statement LP at the en try of every pro cedure, whose execution essen tially copies the v alue of ev ery original v ariable v to the corresp onding new v ariable ˜ v . Let σ 0 denote the pro jection of a transformed program state σ 0 to a state of the original program obtained b y forgetting the v alues of the new v ariables. Giv en a 2-state assertion Φ, LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 15 Library Description compute.c See Figure 1 r educe.c See Figure 3 incr ement.c See Figure 4 av er ag e.c Tw o pro cedures that compute the running sum and av erage of a sequence of num b ers dev ice cache.c One pro cedure that reads data from a device and caches the data for subsequen t reads [7]. The specification requires quantified pred- icates. ser v er stor e.c A library derived from a Jav a implemen tation of Simple Authen- tication and Security Lay er (SASL). The library stores security con text ob jects for sessions on the serv er side. T able 1: Benchmarks used in our ev aluation. let ˜ Φ denote the single-state assertion obtained b y replacing ev ery v in b y ˜ v . As formalized b y the claim b elow, the satisfaction of a 2-state assertion Φ b y executions in the origi- nal program corresp onds to satisfaction of the single-state assertion ˜ Φ in the transformed program. Lemma 4.1. (1) A sche dule ξ is fe asible in the tr ansforme d pr o gr am iff it is fe asible in the original pr o gr am. (2) L et σ 0 and σ b e the states pr o duc e d by a p articular sche dule with the tr ansforme d and original pr o gr ams, r esp e ctively. Then, σ = σ 0 . (3) L et π 0 and π b e the exe cutions pr o duc e d by a p articular sche dule with the tr ansforme d and original pr o gr am, r esp e ctively. Then, π satisfies a single-state assertion ϕ iff π 0 satisfies it. F urthermor e, π satisfies a 2-state assertion Φ iff π 0 satisfies the c orr esp onding one- state assertion ˜ Φ . Syn thesizing concurrency control. W e no w apply the tec hnique discussed in Section 3 to the transformed program to synthesize concurrency con trol that preserves the assertions transformed as discussed ab o ve. It follows from the ab ov e Lemma that this concurrency con trol, used with the original program, preserv es both single-state and t w o-state assertions. 5. Implement a tion W e ha v e built a protot yp e implementation of our algorithm. Our implementation tak es a sequen tial library and its assertions as input. It uses a pre-pro cessing phase to com bine the library with a harness that sim ulates the execution of any p ossible sequence of library calls to get a complete C program. (This program corresp onds to the control graph describ ed in Section 2.) It then uses a verification to ol to generate a pro of of correctness for the assertions in this program. W e use the predicate-abstraction based softw are verification to ol Y ogi describ ed in [3] to generate the required pro ofs. W e mo dified the verifier to emit the pro of from the final abstraction, which asso ciates every program p oint with a b o olean form ula ov er predicates. It then uses the algorithm presen ted in this pap er to synthesize concurrency con trol for the library . It utilizes the theorem pro ver Z3 [5] to iden tify the statemen ts in the program whose execution may falsify relev ant predicates. 16 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI W e used a set of b enchmark programs to ev aluate our approach (T able 1). W e also applied our technique manually to t w o real w orld libraries, a device cache library [7], and a C implemen tation of the Simple Authentication and Security Lay er (SASL). The pro ofs for the device cache library and the SASL library require quantified predicates, which were b ey ond the scop e of the verifier w e used. In all these programs, the concurrency con trol sc heme w e syn thesized was identical to what an experienced programmer would generate. The concurrency control we synthesized required one lo ck for all libraries, with the exception of the SASL library , where our solution uses tw o lo c ks. Our solutions p ermit more concurrency as compared to a naive solution that uses one global lo ck or an atomic section around the b o dy of each pro cedure. F or example, in case of the server store library , our sc heme generates smaller critical sections and identifies a larger num b er of critical sections that acquire differen t lo cks as compared to the default implementation. F or these examples, the running time of our approach is dominated by the time required to generate the pro of; the time required for the synthesis algorithm was negligible. The source co de for all our examples and their concurren t v ersions are av ailable online at [1]. Note that our ev aluation studies only small programs. W e leav e a more detailed ev aluation of our approach as future work. 6. Concurrency Control For Linearizability 6.1. The Problem. In the previous section, w e sho wed how to derive concurrency con trol to ensure that eac h pro cedure satisfies its sequential sp ecification ev en in a concurren t execution. How ever, this ma y still b e to o p ermissive, allowing in terlea v ed executions that pro duce counter-in tuitiv e results and preven ting compositional reasoning in clients of the library . E.g., consider the procedure Increment sho wn in Fig. 2, which incremen ts a shared v ariable x b y 1 . The figure sho ws the concurrency con trol derived using our approach to ensure sp ecification correctness. Now consider a multi-threaded client that initializes x to 0 and in v ok es Increment concurrently in t w o threads. It w ould b e natural to exp ect that the v alue of x would b e 2 at the end of any execution of this client. How ever, this implemen tation permits an interlea ving in whic h the v alue of x at the end of the execution is 1 : the problem is that b oth in vocations of Increment individually meet their sp ecifications, but the cumulativ e effect is unexp ected 3 . This is one of the difficulties with using pre/p ost-condition sp ecifications to reason ab out concurrent executions. One solution to this problem is to apply concurrency control syn thesis to the co de (li- brary) that calls Increment . The syn thesis can then detect the p otential for in terference b et w een the t w o calls to Increment and preven t them from happ ening concurrently . An- other p ossible solution, which we explore in this section, is for the library to guarantee a stronger correctness criteria called line arizability [13]. Linearizabilit y gives the illusion that in any concurrent execution, (the sequen tial sp ecification of ) every pro cedure of the library app ears to execute instantane ously at some p oint b etw een its call and return. This illusion allo ws clients to reas on ab out the b ehavior of concurren t library comp ositionally using its 3 W e conjecture that such concerns do not arise when the sp ecification do es not refer to global v ariables. F or instance, the specification for our example in Fig. 1 do es not refer to global v ariables, even though the implemen tation uses global v ariables. LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 17 1 i n t x = 0 ; 2 // @ ensur es x == x in + 1 ∧ r etur ns x 3 I n c r e m e n t ( ) { 4 i n t t m p ; 5 a c q u i r e ( l ( x == x in ) ) ; t m p = x ; r e l e a s e ( l ( x == x in ) ) ; 6 t m p = t m p + 1 ; 7 a c q u i r e ( l ( x == x in ) ) ; x = t m p ; r e l e a s e ( l ( x == x in ) ) ; 8 r e t u r n t m p ; 9 } Figure 2: A non-linearizable implemen tation of the pro cedure Increment sequen tial sp ecifications. In this section, w e sho w how our approach presented earlier for syn thesizing a lo gic al c oncurr ency c ontr ol can b e adapted to derive concurrency con trol mec hanisms that guarantee linearizabilit y . 6.1.1. Line arizability. W e no w extend the earlier notation to define linearizabilit y . Lineariz- abilit y is a prop erty of the library’s externally observ ed b ehavior. A library’s interaction with its clien ts can b e describ ed in terms of a history , whic h is a sequence of even ts, where eac h ev en t is an invo c ation even t or a r esp onse even t. An in v o cation ev en t is a tuple con- sisting of the pro cedure in v ok ed, the input parameter v alues for the in v o cation, as well as a unique iden tifier. A resp onse ev ent consists of the identifier of a preceding in v o cation ev ent, as w ell as a return v alue. F urthermore, an inv ocation ev en t can hav e at most one matc hing resp onse even t. A complete history has a matching resp onse even t for every in vocation ev en t. Note that an execution, as defined in Section 2, captures the internal execution steps p erformed during a pro cedure execution. A history is an abstraction of an execution that captures only pro cedure in v o cation and return steps. A sequen tial history is an alternating sequence inv 1 , r 1 , · · · , inv n , r n of in vocation ev en ts and corresponding resp onse ev ents. W e abuse our earlier notation and use σ + inv i to denote an entry state corresp onding to a pro cedure in v o cation consisting of a v aluation σ for the library’s global v ariables and a v aluation inv i for the in vok ed procedure’s formal parameters. W e similarly use σ + r i to denote a pro cedure exit state with return v alue r i . Let σ 0 denote the v alue of the globals in the library’s initial state. Let Φ i denote the sp ecification of the pro cedure in v ok ed by inv i . A sequen tial history is le gal if there exist v aluations σ i , 1 ≤ i ≤ n , for the library’s globals such that ( σ i − 1 + inv i , σ i + r i ) | = s Φ i for 1 ≤ i ≤ n . A complete interlea ved history H is line arizable if there exists some legal sequential history S such that (a) H and S ha v e the same set of inv o cation and resp onse even ts and (b) for every return even t r that precedes an in v ocation even t inv in H , r and inv app ear in that order in S as well. An incomplete history H is said to b e linearizable if the complete history H 0 obtained by app ending some resp onse even ts and omitting some in v o cation even ts without a matching resp onse even t is linearizable. Finally , a library L is said to b e linearizable if ev ery history pro duced by L is lineariz- able. The concept of a line arization p oint is often used in explanations and proofs of correct- ness of linearizable algorithms. Informally , a linearization p oint is a p oin t (or control-flo w edge) inside the pro cedure suc h that the pro cedure app ears to execute atomically when it executes that p oin t. Our even tual goal is to parameterize our synthesis algorithm with a 18 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI linearization p oint sp ecification (a description of the p oin t or p oin ts we wish to serv e as the linearization p oint). In this pap er, how ever, we treat the pro cedure entry edge as the linearization p oint and will refer to it as the linearization p oint. 6.1.2. Implementation As A Sp e cific ation and L o gic al Serializability. The techniques we presen t in this section actually guarantee linearizabilit y with resp ect to the given sequen tial implemen tation (i.e., treating the sequential implemen tation as a sequential sp ecification). In particular, this approach guaran tees that the concurrent execution will return the same v alues as some sequen tial execution. (The word atomicity is sometimes used to describ e this b eha vior.) Suc h an approac h has b oth adv antages as w ell as disadv antages. The adv an tage is that the tec hnique is more broadly applicable, in practice, as it do es not require a user- pro vided sp ecification. The disadv antage is that, in theory , the sequential implementation ma y b e more restrictiv e than the intended sp ecification. Hence, preserving the sequential implemen tation b ehavior ma y unnecessarily restrict concurrency . The prop erties of atomicity and linearizabilit y relate to the externally observed b ehavior of the library (i.e., the b ehavior as seen b y clients of the library). The implementation tec hnique we use also guaran tee s certain properties about the internal (execution) b eha vior of the library , which w e explain now. Recall that an execution, as defined in Section 2, captures the in ternal execution steps p erformed during a pro cedure execution while a history is an abstraction of an execution that captures only pro cedure inv ocation and return steps. Recall that ev ery transition σ ( t,e ) s σ 0 is labelled by a pair ( t, e ), indicating that the tran- sition w as created by the execution of edge e b y thread t . W e refer to a pair of the form ( t, e ) as a step . A schedule ζ is a sequence of steps 1 , · · · , k . W e say that a sc hedule 1 , · · · , k is fe asible if there exists an execution σ 0 ` 1 c σ 1 · · · ` k c σ k , where σ 0 is the initial program state. Given an execution π = σ 0 ` 1 c σ 1 · · · ` k c σ k , the sub-schedule of t in π is the sequence s 1 , · · · , s n of steps executed by t in π . A pro cedure in v o cation t 1 is said to precede another pro cedure in v o cation t 2 in an execution if t 1 completes b efore t 2 b egins. Tw o complete executions are said to b e observ ationally-equiv alent if they consist of the same set of pro cedure inv o cations and for each pro cedure inv o cation the return v alues are the same in b oth executions. An execution π 1 is said to b e a p ermutation of another execution π 2 if for ev ery thread (pro cedure inv o cation) t the sub-schedule of t in π 1 and π 2 are the same. An execution π 1 is said to b e top ologically consisten t with another execution π 2 if for ev ery pair of pro cedure in v o cations t 1 and t 2 , if t 1 precedes t 2 in π 1 then t 1 precedes t 2 in π 2 as well. Our goal is to syn thesize a concurrency con trol mec hanism that p ermits only executions that are observ ationally-equiv alent, top ologically consisten t, permutations of sequen tial ex- ecutions. W e note that this concept is similar to v arious notions of serializability [25] (com- monly used in database transactions). The new v arian t we exploit may b e though t of as lo gic al serializability: corresp onding p oints in the compared executions satisfy equiv alence with resp ect to certain predicates of interest, as determined by the basis. 6.1.3. T erminolo gy. In this section, w e will use a mo dified notion of basis introduced in Section 3. LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 19 The k ey idea w e explore in this pap er is that of precisely characterizing what is r elevant to a thread at a particular p oin t and using this information to deriv e a concurrency control solution. In the previous sections, we captured the rele v an t information as an inv ariant or set of predicates (the basis). In this section, w e will find it necessary to mark certain v alues (e.g., the v alue of a v ariable at a particular program p oint) as relev an t as well. In order to seamlessly reason ab out such relev ant v alues (e.g., of t yp e in teger) along with relev ant predicates, we utilize symb olic predicates to enco de the relev ance of v alues. In the sequel, note that w e consider t wo predicates to be equal only if they are syn tac- tically equal. A symbolic predicate is one that utilizes auxiliary (logical) v ariables. As an example, giv en program v ariable x and a logical v ariable w , w e will make use of predicates suc h as “ x = w ”. Suc h sym bolic predicates can b e manipulated just lik e normal predicates (e.g., in computing weak est-precondition). Conceptually , such a symbolic predicate can b e in terpreted as a short-hand notation for the (p ossibly infinite) family of predicates obtained b y replacing the logical v ariable w by every p ossible v alue it can tak e. Th us, if x and w are of type T , then th e ab ov e symbolic predicate represen ts the set of predicates { x = c | c ∈ T } . Note that this set of predicates captures the v alue of x : i.e., w e know the v alue of ev ery predicate in this set iff we kno w the v alue of x . This trick lets us use the sym b olic predicate “ x = w ” to indicate that the v alue of x is relev ant to a thread (and, hence, should not b e mo dified by another thread). Giv en any predicate ϕ , let ϕ ∗ denote the set of predicates it represen ts (obtained b y instan tiating the logical v ariables in ϕ as explained ab ov e). (Th us, for a non-symbolic predicate ϕ , ϕ ∗ = { ϕ } .) W e say that ϕ 1 and ϕ 2 are equiv alent if ϕ ∗ 1 = ϕ ∗ 2 . E.g., if w ranges ov er all in tegers, then “ x = w ” and “ x = w + 1” are equiv alen t predicates. Predicate equiv alence can b e used to simplify a set of predicates or a basis. Giv en a set of predicates S , let S ∗ represen t the set of predicates ∪{ ϕ ∗ | ϕ ∈ S } . If S ∗ 1 = S ∗ 2 , then it is safe, in the sequel, to replace the set S 1 b y the set S 2 in a basis. This ma y b e critical in creating finite represen tations of certain basis. W e sa y that a predicate ϕ is cov ered by a set of predicates S if ϕ can b e expressed as a b o olean form ula ov er the predicates in S using conjunctions and disjunctions. Recall that a pr e dic ate mapping is a mapping pm from the v ertices of the con trol graph to a set of predicates. W e say that a predicate mapping pm is wp-close d if for ev ery edge e = u s − → v and for ev ery ϕ ∈ pm ( v ), (a) If e is not the en try edge of a pro cedure, then the w eak est-precondition of ϕ with resp ect to s , wp ( s , ϕ ) is cov ered b y pm ( u ), and (b) If e is the edge w → N P from the quiescen t vertex to the en try vertex of P , then ϕ 0 is cov ered b y pm ( w ), where ϕ 0 is obtained b y replacing the o ccurrence of an y pro cedure parameter x i b y a new logical v ariable x 0 i . Finally , w e say that a predicate mapping is close d if it is wp-closed and if for every vertex u and every predicate ϕ in pm ( u ), the negation of ϕ is also in pm ( u ). The later condition helps us reuse the algorithm description from Section 3 in spite of some differences in the con text. Without loss of generality , we assume that each pro cedure P j returns the v alue of a sp ecial lo cal v ariable r et j . 6.2. The Syn thesis Algorithm. W e now sho w ho w our approac h can b e extended to guaran tee linearizabilit y or atomicity . W e use a few tric ky cases to motiv ate the adaptations w e use of our previous algorithm. 20 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI W e start b y characterizing non-linearizable in terlea vings p ermitted by our earlier ap- proac h. W e classify the interlea vings based on the nature of linearizability violations they cause. F or each class of interlea vings, w e describ e an extension to our approac h to generate additional concurrency control to prohibit these in terlea vings. Finally , we pro ve correctness of our approach by sho wing that all in terlea vings w e p ermit are linearizable. 6.2.1. Delaye d F alsific ation. The first issue we address, as w ell as the solution w e adopt, are not surprising from a conv entional p ersp ective. (This extension is, in fact, the analogue of t wo-phase lo c king: i.e., the trick of acquiring all lo c ks b efore releasing any lo c ks to av oid in terference.) Informally , the problem with the Increment example can be c haracterized as “dirt y reads” and “lost up dates”: the second pro cedure inv o cation executes its linearization p oin t later than the first procedure in v o cation but reads the original v alue of x , instead of the v alue pro duced by the the first inv o cation. Dually , the up date done by the first pro cedure in v ocation is lost, when the second pro cedure in v o cation up dates x . F rom a logical p ersp ective, the second inv o cation relies on the in v ariant x == x in early on, and the first inv o cation breaks this inv arian t later on when it assigns to x (at a p oin t when the second inv o cation no longer relies on the inv ariant). This preven ts us from reordering the execution to construct an equiv alent sequen tial execution (while preserving the pro of ). T o ac hiev e linearizability , w e need to a v oid suc h “delay ed falsification”. The extension w e no w describe prev ents suc h interference b y ensuring that instructions that may falsify predicates and o ccur after the linearization p oint app ear to execute atomi- cally at the linearization p oint. W e ac hiev e this by modifying the strategy to acquire lo cks as follows. • W e generalize the earlier notion of may-falsify . W e sa y that a path may-falsify a predicate ϕ if some edge in the path may-falsify ϕ . W e sa y that a predicate ϕ may-b e-falsifie d-after v ertex u if there exists some path from u to the exit vertex of the procedure that do es not contain an y linearization p oint and may-falsify ϕ . • Let mf b e a predicate map such that for any v ertex u , mf ( u ) includes any predicate that ma y-b e-falsified-after u . • W e generalize the original scheme for acquiring lo c ks. W e augment ev ery edge e = u S − → v as follows: (1) ∀ ∈ lm ( mf ( v )) \ lm ( mf ( u )), add an “ acquire ( )” b efore S (2) ∀ ∈ lm ( mf ( u )) \ lm ( mf ( v )), add an “ release ( )” after S This extension suffices to pro duce a linearizable implemen tation of the example in Fig. 2. 6.2.2. R eturn V alue Interfer enc e. W e no w fo cus on in terference that can affect the actual value r eturne d by a pr o c e dur e invo c ation , leading to non-linearizable executions. Consider procedures IncX and IncY in Fig. 3, which increment v ariables x and y re- sp ectiv ely . Both pro cedures return the v alues of x and y . How ever, the p ostconditions of IncX (and IncY ) do not sp e cify anything ab out the final value of y (and x resp ectiv ely). Let us assume that the linearization p oin ts of the pro cedures are their entry p oints. Initially , w e hav e x = y = 0. Consider the following in terlea ving of a concurren t execution of the tw o pro cedures. The t wo pro cedures execute the incremen ts in some order, pro ducing the state with x = y = 1. Then, b oth pro cedures return (1 , 1). This execution is non-linearizable b ecause in an y legal sequential execution, the pro cedure executing second is obliged to re- turn a v alue that differs from the v alue returned b y the pro cedure executing first. The LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 21 int x, y; IncX() { acquire( l x == x in ); x = x + 1; ( r et 11 , r et 12 )=(x,y); release( l x == x in ); } IncY() { acquire( l y == y in ); y = y + 1; ( r et 21 , r et 22 )=(x,y); release( l y == y in ); } (a) int x, y; @ ensures x = x in + 1 @ retur ns ( x, y ) IncX() { [ r et 0 11 ==x+1 ∧ r et 0 12 ==y] LP : x = x in [x==x in ∧ ret 0 11 ==x+1 ∧ r et 0 12 =y] x = x + 1; [x==x in +1 ∧ r et 0 11 ==x ∧ r et 0 12 = y] ( r et 11 , r et 12 )=(x,y); [x==x in +1 ∧ r et 11 == r et 0 11 ∧ ret 12 == r et 0 12 ] } (b) int x, y; IncX() { acquire( l merged ); x = x+1; ( r et 11 , r et 12 )=(x,y); release( l merged ); } IncY() { acquire( l merged ); y = y+1; ( r et 21 , r et 22 )=(x,y); release( l merged ); } (c) Figure 3: An example illustrating return v alue interference. Both pro cedures return (x,y) . r et ij refers to the j th return v ariable of the i th pro ce- dure. Figure 3(a) is a non-linearizable implementation synthesized using the approach describ ed in Section 3. Figure 3(b) sho ws the extended proof of correctness of the procedure IncX and Figure 3(c) sho ws the linearizable implemen tation. left column in Figure 3 sho ws the concurrency con trol derived using our approach with previously describ ed extensions. This is insufficient to preven t the ab o ve interlea ving. This in terference is allo w ed b ecause the sp ecification for IncX allo ws it to change the v alue of y arbitrarily; hence, a concurrent mo dification to y by any other pro cedure is not seen as a hindrance to IncX . T o prohibit suc h interferences within our framework, w e need to determine whether the execution of a statemen t s can p otentially affect the return-v alue of another pro cedure in v o cation. W e do this b y computing a predicate φ ( r et 0 ) at ev ery program p oint u that captures the relation b etw een the program state at p oin t u and the v alue returned by the pro cedure inv o cation ev en tually (denoted by r et 0 ). W e then chec k if the execution of a statemen t s will break predicate φ ( r et 0 ), treating r et 0 as a free v ariable, to determine if the statemen t could affect the return v alue of some other pro cedure inv o cation. F ormally , we assume that each pro cedure returns the v alue of a sp ecial v ariable r et . (Th us, “ return exp ” is shorthand for “ r et = exp ”.) W e in tro duce a sp ecial auxiliary v ariable r et 0 . W e sa y that a predicate map pm c overs r eturn statements if for every edge u → v lab elled by a return statement “ return exp ” the set pm ( u ) cov ers the predicate r et 0 == r et . (See the earlier discussion in Section 6.1.3 ab out such symbolic predicates and ho w they enco de the requiremen t that the v alue of r et at a return statement is relev ant and m ust b e preserv ed.) By applying our concurrency-control synthesis algorithm to a closed basis that co v ers return statements, w e can ensure that no return-v alue interference occurs. The middle column in Figure 3 sho ws the augmen ted sequen tial pro of of correctness of IncX . The concurrency control deriv ed using our approach starting with this pro of is sho wn in the third column of Fig. 3. The lo ck l mer ged denotes a lo ck obtained by merging lo c ks corresp onding to multiple predicates sim ultaneously acquired/released. It is easy to see that this implemen tation is linearizable. Also note that if the shared v ariables y and x w ere 22 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI 1 i n t x , y ; 2 // @ ensur es y = y in + 1 3 I n c Y ( ) { 4 [ tr ue ] LP : y in = y 5 [ y == y in ] y = y + 1 ; 6 [ y == y in + 1] 7 } 1 // @ ensur es x < y 2 R e d u c e X ( ) { 3 [ tr ue ] LP 4 [ tr ue ] i f ( x ≥ y ) { 5 [ tr ue ] x = y - 1 ; 6 } 7 [ x < y ] 8 } Figure 4: An example illustrating in terference in control flo w. Each line is annotated (in square braces) with a predicate the holds at that program p oin t. not returned b y pro cedures IncX and IncY resp ectively , w e will deriv e a locking scheme in whic h accesses to x and y are protected by different lo cks, allo wing these pro cedures to execute concurrently . 6.2.3. Contr ol Flow Interfer enc e. An interesting asp ect of our scheme is that it p ermits in terference that alters the control flow of a pro cedure in v o cation if it do es not cause the in v o cation to violate its specification. Consider pro cedures ReduceX and IncY shown in Fig. 4. The sp ecification of ReduceX is that it will pro duce a final state where x < y , while the sp ecification of IncY is that it will incremen t the v alue of y by 1. ReduceX meets its sp ecification by setting x to b e y − 1, but do es so only if x ≥ y . No w consider a client that inv okes ReduceX and IncY concurren tly from a state where x = y = 0. Assume that the ReduceX inv o cation enters the pro cedure. Then, the in v ocation of IncY executes completely . The ReduceX inv o cation con tin ues, and do es nothing since x < y at this p oin t. Figure 4 shows a sequen tial pro of and the concurrency control derived by the scheme so far, assuming that the linearization p oin ts are at the pro cedure en try . A k ey p oint to note is that ReduceX ’s pro of needs only the single predicate x < y . The statement y = y + 1 in IncY do es not falsify the predicate x < y ; hence, IncY do es not acquire the lo ck for this predicate. This locking scheme p ermits IncY to execute concurrently with ReduceX and affect its control flow. While our approach guarantees that this con trol flo w in terference will not cause assertion violations, proving linearizabilit y in the presence of suc h control flo w interference, in the general case, is challenging (and an op en problem). W e no w describ e how our technique can b e extended to preven t control flow interference, whic h suffices to guaran tee linearizability . W e ensure that interference b y one thread do es not affect the execution path another thread tak es. W e sa y that a basis pm c overs the br anch c onditions of the program if for ev ery branch edge u s − → v , the set pm ( u ) co v ers the assume condition in s . If w e synthesize concurrency control using a close d basis pm that co vers the branch conditions, w e can ensure that no control-flo w in terference happ ens. In the current example, this requires predicate x ≥ y to b e added to the basis for ReduceX . As a result, ReduceX will acquire lo ck l x ≥ y at entry , while IncY will acquire the same lo c k at its linearization point and release the lo c k after the statement y = y + 1. It is easy to see that this implemen tation is linearizable. LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 23 6.2.4. The Complete Schema. In summary , our schema for syn thesizing concurrency control that guarantees linearizabilit y is as follo ws. First, we determine a closed basis for the program that co vers all r eturn statemen ts and branc h conditions in the program. (Such a basis is the analogue of the proof and basis used in Section 3. An algorithm for generating such a basis is b eyond the scope of this paper. Suc h a basis can b e computed by iteratively computing weak est-preconditions, but, in the general case, subsumption and equiv alence among predicates will need to b e utilized to simplify basis sets to ensure termination.) W e then apply the extended concurrency control syn thesis algorithm describ ed in Section 6.2.1. 6.3. Correctness. The extensions describ ed abov e to the algorithm of Sections 3 and 4 for syn thesizing concurrency con trol are sufficien t to guarantee linearizability , as w e sho w in this section. Let σ b e a program state. W e define TBP( σ , t ) to b e the set { ϕ ∈ ( pm ( u )) ∗ | ( σ, t ) | = c ϕ } where t ’s program-coun ter in state σ is u . (See Section 6.1.3 for the definition of S ∗ for any set of predicates S .) Lemma 6.1. L et pm b e a wp-close d pr e dic ate map. Consider tr ansitions σ 1 ( t,e ) c σ 2 and σ 3 ( t,e ) c σ 4 . If TBP( σ 1 , t ) ⊇ TBP( σ 3 , t ) , then TBP( σ 2 , t ) ⊇ TBP( σ 4 , t ) . Pr o of. Let e b e the edge u S − → v . Note that for ev ery predicate ϕ ∈ pm ( v ), the w eak est- precondition of ϕ with respect to the statement S can b e expressed in terms of the predicates in pm ( u ) using conjunction and disjunction (by definition of a wp-closed predicate map). The result follows. Consider any concurrent execution π 1 pro duced by a schedule ξ . W e assume, without loss of generality , that ev ery pro cedure inv o cation is executed b y a distinct thread. Let t 1 , . . . , t k denote the set of threads which complete execution in the given schedule, ordered so that t i executes its linearization p oin t b efore t i +1 . W e sho w that ξ is linearizable b y sho wing that ξ is equiv alent to a sequen tial execution of the specifications of the threads t 1 , . . . , t k executed in that order. Let ξ i denote a pr oje ction of schedule ξ consisting only of execution steps by thread t i . Let ζ denote the schedule ξ 1 · · · ξ k . Lemma 6.2. ζ k is a fe asible sche dule. F urthermor e, for any c orr esp onding exe cution steps σ j ( t,e ) c σ j +1 and σ 0 k ( t,e ) c σ 0 k +1 of the two exe cutions, we have TBP( σ j , t ) ⊇ TBP( σ 0 k , t ) . Pr o of. Pro of by induction ov er the execution steps of ζ . The claim is trivially true for the first step of ζ , since the initial state in the same in b oth executions. No w, consider an y pair of “candidate” successiv e execution steps σ 0 k − 1 ( t,e 0 ) c σ 0 k ( t,e ) c σ 0 k +1 of ζ . That is, we assume, from our inductive hypothesis, that the first execution step ab o ve is feasible, but we need to establish that the second step is a feasible execution step. Let σ m − 1 ( t,e 0 ) c σ m and σ j ( t,e ) c σ j +1 b e the tw o corresp onding execution steps in the original execution. Our inductive h yp othesis guarantees that TBP( σ m , t ) ⊇ TBP( σ 0 k , t ). But any concur- ren t execution is guaranteed to b e interference-free. Hence, it follows that TBP( σ j , t ) ⊇ TBP( σ m , t ). Hence, it follows that TBP( σ j , t ) ⊇ TBP( σ 0 k , t ). 24 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI No w, if e is a conditional branc h statement lab elled with the statement “assume ϕ ”, then w e m ust ha v e ( σ j , t ) | = c ϕ . It follo ws that ( σ 0 k , t ) | = c ϕ . (This follo ws b ecause we use a basis that cov ers all branc h conditions.) Thus, the second candidate execution step of ζ is indeed a feasible execution step. It then follows from Lemma 6.1 that TBP( σ j +1 , t ) ⊇ TBP( σ 0 k +1 , t ). No w, consider any pair of successive execution steps σ 0 k − 1 ( t h − 1 ,e 0 ) c σ 0 k ( t h ,e ) c σ 0 k +1 of ζ . Thus, w e consider the first step executed by thread t h after thread t h − 1 executes its last step. Note that TBP( σ 0 k , t h − 1 ) = TBP( σ 0 k , t h ) (since none of the basis predicates at the quiescen t vertex in volv e thread-lo cal v ariables). Let σ p ( t h − 1 ,e ) c σ p +1 denote the corresp onding, last, execution step p erformed b y t h − 1 in the interlea ved execution. Let σ j ( t h ,e ) c σ j +1 denote the corresp onding, first, execution step p erformed b y t h in the in terleav ed execution. By the inductiv e h yp othesis, TBP( σ p , t h − 1 ) ⊇ TBP( σ 0 k , t h − 1 ). Note that in the interlea ved execution p ma y b e less than or greater than j : t h − 1 ma y or ma y not hav e completed execution b y the time t h p erforms its first execution step. Y et, w e can establish that TBP( σ j , t h ) ⊇ TBP( σ 0 k , t h − 1 ). This is b ecause no thread can execute a step that will chan ge the v alue of any predicate in TBP( σ p , t h − 1 ) b et ween the last step of t h − 1 and the first step of t h (no matter how these t w o steps are ordered during execution). Lemma 6.3. F or t ∈ { t 1 , · · · , t k } , the value r eturne d by pr o c e dur e invo c ation t in π 1 is the same as the value r eturne d by t in the se quential exe cution π 2 c orr esp onding to sche dule ζ . Pr o of. Let σ j ( t,e ) c σ j +1 and σ 0 k ( t,e ) c σ 0 k +1 denote the execution of the return statements b y t in π 1 and π 2 resp ectiv ely . it follows from Lemma 6.2 that TBP( σ j , t ) ⊇ TBP( σ 0 k , t ). Suppose that t returns a v alue c in the sequen tial execution π 2 . Note that w e use a basis that c o v ers all return statemen ts. Hence, the predicate c == r et must b e in TBP( σ 0 k , t ). It follows that c == r et m ust b e in TBP( σ j , t ) as well. Hence, t returns c in π 1 as well. Theorem 6.4. Given a libr ary L that is total ly c orr e ct with r esp e ct to a given se quential sp e cific ation, the libr ary b L gener ate d by our algorithm is line arizable with r esp e ct to the given sp e cific ation. Pr o of. F ollows immediately from Lemma 6.3. The ab o v e theorem requires total c orr e ctness of the library in the sequential setting. E.g. , consider a pro cedure P with a sp ecification ensures x==0 . An implementation that sets x to be 1, and then enters an infinite lo op is p artial ly correct with resp ect to this sp ec- ification (but not totally correct). In a concurrent setting, this can lead to non-linearizable b eha vior, since another concurrent thread can observ e that x has v alue 1, which is not a legally observ able v alue after pro cedure P completes execution. 6.4. Discussion. In this section, we hav e presented a logical approac h to synthesizing concurrency control to ensure linearizability/atomicit y . In particular, we use predicates to describ e what is r elevant to ensure correctness (or desired properties). Predicates enable us to describ e relev ance in a more fine-grained fashion, creating opp ortunities for more concurrency . LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 25 W e b elieve that this approach is promising and that there is significan t scop e for im- pro ving our solution and sev eral in teresting researc h directions w orth pursuing. Indeed, some basic optimizations to the scheme presen ted ma y b e critical to getting reasonable so- lutions. One example is an optimization relating to frame conditions, hin ted at in Section 2. As an example, assume that x > 0 is an inv ariant that holds true in b etw een pro cedure in v o cations in a sequential execution. (Thus, this is a library inv ariant.) A pro cedure that neither reads or writes x will, nevertheless, hav e the inv arian t x > 0 at ev ery program point (to indicate that it nev er breaks this inv ariant). Our solution, as sk etc hed, will require the pro cedure to acquire a lo ck on this predicate and hold it during the en tire pro cedure. Ho w ev er, this is not really necessary , and can b e optimized aw ay . In general, the in v arian t or the basis at an y program p oint may b e seen as consisting of t w o parts, the fr ame and the fo otprint . The fo otprin t relates to predicates that are relev ant and/or may b e mo dified b y the pro cedure, while the frame simply indicates predicates that are irrelev ant and left un touc hed b y the pro cedure. W e need to consider only the fo otprin t in synthesizing the concurrency con trol solution. W e leav e fleshing out the details of such optimizations as future work. W e conjecture that the extensions presen ted in this section to a v oid con trol-flo w in ter- ference is not necessary to ensure linearizability . Indeed, note that if we can ensure that an y concurrent execution is observ ationally equiv alent and top ologically equiv alen t to some sequen tial execution, this is sufficien t. Our current technique ensures that the concurren t execution is also a p erm utation of the sequen tial execution: i.e., every pro cedure inv o cation follo ws the same execution path in both the concurrent and sequential execution. How ever, our current pro of of correctness relies on this prop ert y . Relaxing this requiremen t is an in teresting op en problem. W e b elieve that our tec hnique can b e adapted in a straigh t-forw ard fashion to w ork with linearization p oints other than the pro cedure entry (as long as the linearization p oin t satisfies certain constrain ts). Different linearization points can potentially produce different concurrency control solutions. W e also b eliev e that with v arious of these improv ements, w e can synthesize the so- lution presented in Fig. 1 as a linearizable and atomic implementation, starting with no sp ecification whatso ever. 7. Rela ted W ork Syn thesizing Concurrency Con trol : V ec hev et al. [24] presen t an approac h for synthe- sizing concurrency control for a concurren t program, given a sp ecification in the form of assertions in the program. This approach, Abstraction Guided Synthesis, generalizes the standard counterexample-guided abstraction refinement (CEGAR) approach to verification as follows. The algorithm attempts to prov e that the concurren t program satisfies the de- sired assertions. If this fails, an interlea ved execution that violates an assertion is iden tified. This counterexample is used to either refine the abstraction (as in CEGAR) or to restrict the program by adding some atomicity constrain ts. An atomicity constrain t indicates that a con text-switc h should not o ccur at a given program p oin t (thus requiring the statemen ts immediately preceding and follo wing the program p oin t to b e in an atomic-blo ck) or is a disjunction of such constrain ts. Having th us refined either the abstraction or the program, the algorithm rep eats this pro cess. 26 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI Our work has the same high-lev el goal and philosophy as V ec hev et al.: derive a con- currency cont rol solution automatically from a sp ecification of the desired correctness prop- erties. Ho wev er, there are a num b er of differences b et w een the tw o approaches. Before we discuss these differences, it is worth noting that the concrete problem addressed b y these t w o pap ers are somewhat differen t: while our work fo cuses on making a sequential library safe for concurren t clien ts, V echev et al. fo cus on adding concurrency con trol to a giv en concurren t program to make it safe. Thus, neither technique can b e directly applied to the other problem, but we can still observe the follo wing p oin ts ab out the essence of these tw o approac hes. Both approaches are similar in exploiting verification techniques for synthesizing con- currency con trol. Ho w ev er, our approach decouples the verification step from the synthesis step, while V ec hev et al. present an integrated approach that com bines b oth. Our verifi- cation step requires only sequential reasoning, while the V echev et al. algorithm in v olv es reasoning ab out concurren t (interlea v ed) executions. Sp ecifically , we exploit the fact that a sequential pro of indicates what prop erties are critical at different program p oints (for a giv en thread), whic h allo ws us to determine whether the execution of a particular statemen t (b y another thread) constitutes (p otentially) undesirable interference. W e present a lo cking-based solution to concurrency control, while V echev et al. present the solution in terms of atomic regions. Note that if our algorithm is parameterized to use a single lo c k (i.e., to map ev ery predicate to the same lo ck), then the generated solution is effectiv ely one based on atomic regions. Raza et al. [19] present an approach for automatically parallelizing a program that mak es use of a separation logic pro of. This approac h exploits the separation logic based pro of to identify whether candidate statemen ts for parallelization access disjoint sets of lo cations. Like most classical approaches to automatic parallelization, this approach to o relies on a data-based notion of interference, while our approac h identifies a logical notion of interference. Sev eral papers [9, 4, 8, 16, 14, 21] address the problem of inferring lo ck-based synchro- nization for atomic sections to guarantee atomicity . These existing lo c k inference schemes iden tify p oten tial conflicts b et w een atomic sections at the gran ularit y of data items and acquire lo c ks to prev en t these conflicts, either all at once or using a tw o-phase lo cking ap- proac h. Our approac h is no vel in using a logical notion of in terference (based on predicates), whic h can p ermit more concurrency . [20] describ es a sk etc hing tec hnique to add missing synchronization by iteratively ex- ploring the space of candidate programs for a giv en thread sc hedule, and pruning the searc h space based on coun terexample candidates. [15] uses mo del-c hecking to repair errors in a concurren t program b y pruning erroneous paths from the control-flo w graph of the in ter- lea v ed program execution. [23] is a precursor to [24], discussed ab ov e, that considers the tradeoff b etw een increasing parallelism in a program and the cost of synchronization. This pap er allows users to sp ecify limitations on what may b e used as the guard of conditional critical regions (the synchronization mechanism used in the pap er), thus con trolling the costs of sync hronization. [6] allo ws users to sp ecify sync hronization patterns for critical sections, whic h are used to infer appropriate synchronization for each of the user-iden tified region. V ec hev et al. [22] address the problem of automatically deriving linearizable ob- jects with fine-grained concurrency , using hardware primitives to ac hiev e atomicit y . The approac h is semi-automated, and requires the developer to pro vide algorithm schema and insigh tful manual transformations. Our approach differs from all of these techniques in LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 27 exploiting a pro of of correctness (for a sequential computation) to synthesize concurrency con trol that guarantees thread-safet y . V erifying Concurrent Programs : Our prop osed st yle of reasoning is closely related to the axiomatic approach for pro ving concurrent programs of Owicki & Gries [18]. While they fo cus on proving a concurren t program correct, we fo cus on synthesizing concurrency con trol. They observ e that if t w o statemen ts do not interfer e , the Hoare triple for their parallel comp osition can be obtained from the sequential Hoare triples. Our approach iden tifies statemen ts that may interfer e and violate the sequential Hoare triples, and then syn thesizes concurrency control to ensure that sequen tial assertions are preserv ed b y parallel comp osition. Prior work on verifying concurren t programs [17] has also sho wn that attac hing in- v arian ts to resources (such as lo cks and semaphores) can enable mo dular reasoning ab out concurren t programs. Our pap er turns this around: w e use sequential pro ofs (which are mo dular pro ofs, but v alid only for sequential executions) to iden tify critical in v arian ts and create lo c ks corresp onding to such inv ariants and augmen t the program with concurrency con trol that enables us to lift the sequential pro of into a v alid pro of for the concurrent program. 8. Limit a tions, Extensions, and Future W ork In this pap er, w e hav e explored the idea that pro ofs of correctness for sequen tial compu- tations can yield concurrency control solutions for use when the same computations are executed concurren tly . W e hav e adopted simple solutions in a num ber of dimensions in order to fo cus on this cen tral idea. A num b er of in teresting ideas and problems app ear w orth pursuing in this regard, as explained b elo w. Pr o c e dur es. The simple programming language presented in Section 2 do es not include pro cedures. The presence of pro cedure calls within the library giv es rise to a different set of challenges. V erification to ols often compute pro cedure summaries to derive the o v erall pro of of correctness. Our approach could use summaries as pro xies for pro cedure calls and deriv es concurrency con trol sc hemes where lo cks are acquired and released only in the top- lev el pro cedures. A more aggressive approac h could analyze the pro ofs b ottom up and infer nested concurrency control sc hemes where lo cks are acquired and released in pro cedures that subsume the lifetimes of the corresp onding predicates. R elaxe d Memory Mo dels. The programming language semantics we use and our pro ofs assume sequen tial consistency . W e b eliev e it should b e p ossible to extend the notion of logical interference to relaxed memory models. Under a relaxed mo del, reads may return more v alues compared to sequential consistent executions. Therefore, w e may hav e to consider these additional b ehaviors while determining if a statement can interfere with (the pro of of ) a concurrent thread. W e leav e this extension for future work. Optimistic Concurr ency Contr ol. Optimistic concurrency control is an alternative to p es- simistic concurrency con trol (such as lock-based techniques). While w e presen t a lock-based p essimistic concurrency control mec hanism, it would be in teresting to explore the p ossibil- it y of optimistic concurrency con trol mec hanisms that exploit a similar weak er notion of in terference. 28 J. DESHMUKH, G. RAMALINGAM, V.-P . RANGANA TH, AND K. V ASW ANI Cho osing Go o d Solutions. This pap er presents a space of v alid lo c king solutions that guar- an tee the desired properties. Sp ecifically , the lo c king solution generated is dependent on sev eral factors: the sequential pro of used, the basis used for the pro of, the mapping from basis predicates to lo c ks, the linearization point used, etc. Given a metric on solutions, generating a go o d solution according to the given metric is a direction for future work. E.g., one possibility is to ev aluate the p erformance of candidate solutions (suggested b y our framew ork) using a suitable test suite to c ho ose the b est one. Integrating the concurrency con trol syn thesis approach with the pro of generation approac h, as done b y [24], can also lead to b etter solutions, if the pro ofs themselves can b e refined or altered to make the concurrency control more efficient. Fine-Gr aine d L o cking. Fine-grained lo cking refers to lo cking disciplines that use an un- b ounded n um b er of lo c ks and associate each lock with a small num b er of shared ob jects (t ypically one). Programs that use fine-grained lo cking often scale b etter b ecause of re- duced con ten tion for lo cks. In its current form, the approac h presen ted in this pap er do es not derive fine-grained locking sc hemes. The lo cking sc hemes w e synthesize associate lo c ks with predicates and the n um b er of such predicates is statically b ounded. Generalizing our approac h to infer fine-grained lo cking from sequen tial pro ofs of correctness remains an op en and challenging problem. Lightweight Sp e cific ations. Our technique relies on user-provided sp ecifications for the li- brary . Recently , there has b een in terest in light weigh t annotations that capture commonly used correctness conditions in concurrent programs (such as atomicity , determinism, and linearizabilit y). As we discuss in Section 1, we b eliev e that there is p otential for profitably applying our technique starting with such light weigh t sp ecifications (or even no sp ecifica- tions). Class invariants. In our approach, a thread holds a lo ck on a predicate from the p oint the predicate is established to the point after which the predicate is no longer used. While this approac h ensures correctness, it may often b e to o p essimistic. F or example, it is often the case that a library is asso ciated with class/ob ject inv ariants that characterize the stable state of the library’s ob jects. Pro cedures in the library may temp orarily break and then re-establish the inv ariants at v arious p oin ts during their inv o cation. If class inv ariants are kno wn, it ma y be p ossible to deriv e more efficient concurrency con trol mechanisms that release locks on the class inv ariants at p oints where the inv arian ts are established and re-acquire these lo cks when the inv ariants are used. Suc h a scheme works only when all pro cedures “co-op erate” and ensure that the lo cks asso ciated with the inv ariants are released only when the inv ariant is established. References [1] WYPIWYG examples. h ttp://research.microsoft.com/en-us/pro jects/wypiwyg/ wypi- wyg examples.zip, June 2009. [2] T. Ball and S. K. Ra jamani. Beb op: A symbolic model c heck er for Bo olean programs. In SPIN 00: SPIN Workshop , pages 113–130. 2000. [3] Nels E. Beckman, Adity a V. Nori, Sriram K. Ra jamani, Robert J. Simmons, SaiDeep T etali, and Adit ya V. Thakur. Pro ofs from tests. IEEE T r ans. Softwar e Eng. , 36(4):495–508, 2010. [4] Sigmund Cherem, T rishul Chilimbi, and Sumit Gulwani. Inferring lo cks for atomic sections. In Pr o c. of PLDI , 2008. LOGICAL CONCURRENCY CONTROL FR OM SEQUENTIAL PR OOFS 29 [5] Leonardo Mendon¸ ca de Moura and Nikola j Bjørner. Z3: An efficient smt solver. In T ACAS , pages 337–340, 2008. [6] Xianghua Deng, Matthew B. Dwyer, John Hatcliff, and Masaaki Mizuno. In v ariant-based sp ecification, syn thesis, and verification of synchronization in concurrent programs. In Pr o c. of ICSE , pages 442–452, 2002. [7] Tyfun Elmas, Serdar T asiran, and Shaz Qadeer. A calculus of atomic sections. In Pr o c. of POPL , 2009. [8] Michael Emmi, Jeff Fisc her, Ranjit Jhala, and Rupak Ma jumdar. Lo ck allo cation. In Pr o c. of POPL , 2007. [9] Cormac Flanagan and Stephen N. F reund. Automatic synchronization correction. In Pr o c. of SCOOL , 2005. [10] Bhargav S. Gula v ani, Thomas A. Henzinger, Y amini Kannan, Adit ya V. Nori, and Sriram K. Ra jamani. Synergy: A new algorithm for prop erty chec king. In Pr o c. of FSE , Nov ember 2006. [11] T. A. Henzinger, R. Jhala, R. Ma jumdar, and G. Sutre. Lazy abstraction. In Pr oc. of POPL , pages 58–70, 2002. [12] Thomas A. Henzinger, Ranjit Jhala, Rupak Ma jumdar, and Kenneth L. McMillan. Abstractions from pro ofs. In Pr o c. of POPL , pages 232–244, 2004. [13] Maurice P . Herlih y and Jeannette M. Wing. Linearizability: a correctness condition for concurrent ob jects. Pr o c. of A CM TOPLAS , 12(3):463–492, 1990. [14] Michael Hic ks, Jeffrey S. F oster, and Polyvios Pratik akis. Lock inference for atomic sections. In First Workshop on L anguages, Compilers, and Har dwar e Supp ort for T r ansactional Computing , 2006. [15] Muhammad Umar Janjua and Alan Mycroft. Automatic correcting transformations for safety prop erty violations. In Pr o c. of Thr e ad V erific ation , pages 111–116, 2006. [16] Bill McCloskey , F eng Zhou, David Ga y , and Eric A. Brewer. Autolo ck er: Synchronization inference for atomic sections. In Pr o c. of POPL , 2006. [17] Peter W. O’Hearn. Resources, concurrency , and lo cal reasoning. The or. Comput. Sci. , 375(1-3):271–307, 2007. [18] Susan Owic ki and David Gries. V erifying prop erties of parallel programs : An axiomatic approac h. In Pr o c. of CA CM , 1976. [19] Mohammad Raza, Cristiano Calcagno, and Philippa Gardner. Automatic parallelization with separation logic. In ESOP , pages 348–362, 2009. [20] Armando Solar-Lezama, Christopher Grant Jones, and Rastislav Bo dik. Sketc hing concurrent data structures. In Pr o c. of PLDI , pages 136–148, 2008. [21] Mandana V aziri, F rank Tip, and Julian Dolby . Asso ciating synchronization constraints with data in an ob ject-orien ted language. In Pr o c. of POPL , pages 334–345, 2006. [22] Martin V echev and Eran Y ahav. Deriving linearizable fine-grained concurrent ob jects. In In Pr o c. of PLDI , pages 125–135, 2008. [23] Martin V ec hev, Eran Y ahav, and Greta Y orsh. Inferring synchronization under limited observ abilit y . In Pr o c. of T ACAS , 2009. [24] Martin T. V echev, Eran Y ahav, and Greta Y orsh. Abstraction-guided syn thesis of sync hronization. In POPL , pages 327–338, 2010. [25] Gerhard W eikum and Gottfried V ossen. T r ansactional Information Systems: The ory, Algorithms, and the Pr actic e of Concurr ency Contr ol . Morgan Kaufmann, 2001. This work is licensed under the Creative Commons Attribution-NoDerivs License. T o view a copy of this license, visit http://creativecommons.org/licenses/by-nd/2.0/ or send a letter to Creative Commons, 171 Second St, Suite 300, San Fr ancisco , CA 94105, USA, or Eisenacher Strasse 2, 10777 Berlin, Germany
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment