Learning parametric dictionaries for graph signals
In sparse signal representation, the choice of a dictionary often involves a tradeoff between two desirable properties -- the ability to adapt to specific signal data and a fast implementation of the dictionary. To sparsely represent signals residing…
Authors: Dorina Thanou, David I Shuman, Pascal Frossard
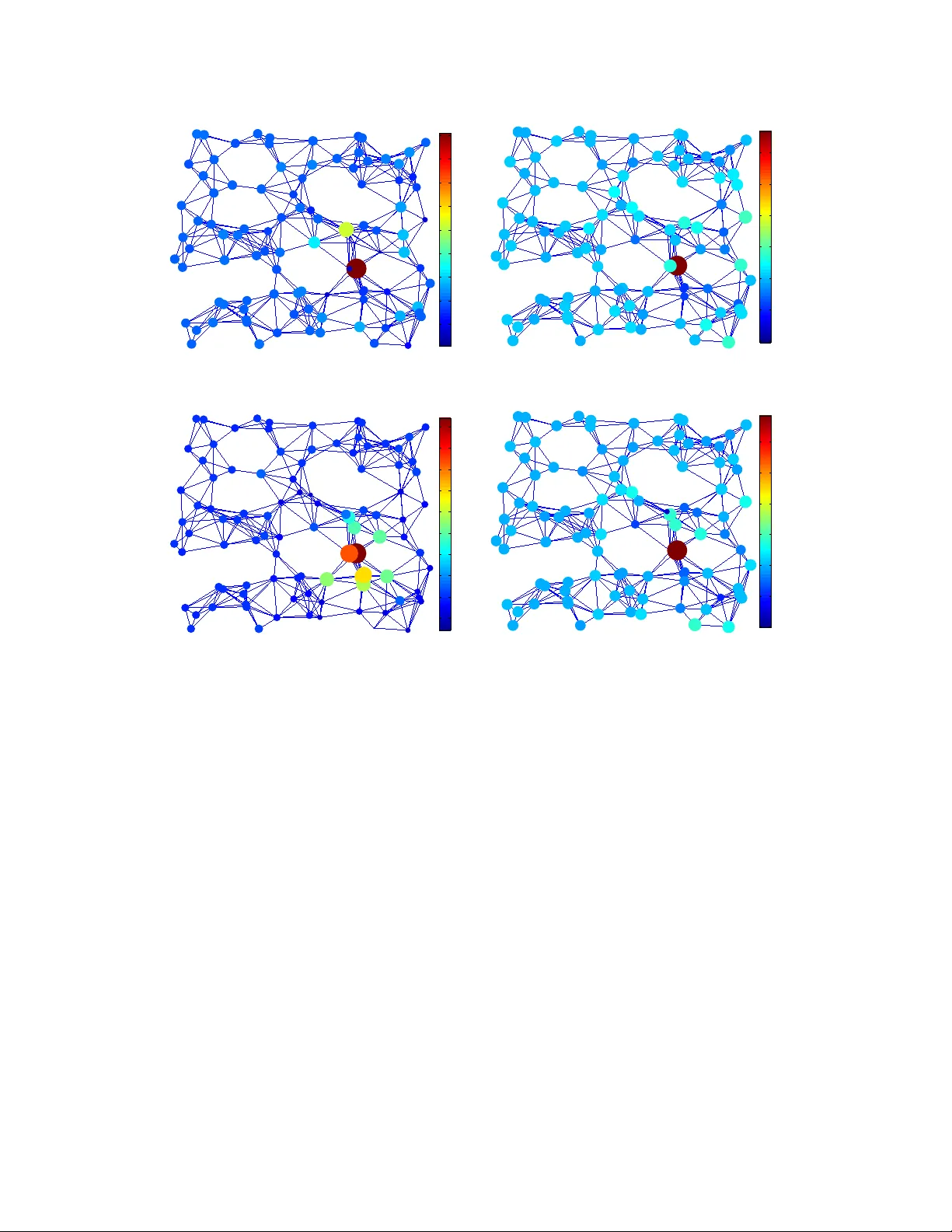
1 Learning P arametric Dictionaries for Signals on Graphs Dorina Thanou, David I Shuman, and P ascal Frossard Abstract In sparse signal representation, the choice of a dictionary often in v olves a tradeof f between two desirable properties – the ability to adapt to specific signal data and a f ast implementation of the dictionary . T o sparsely represent signals residing on weighted graphs, an additional design challenge is to incorporate the intrinsic geometric structure of the irregular data domain into the atoms of the dictionary . In this work, we propose a parametric dictionary learning algorithm to design data-adapted, structured dictionaries that sparsely represent graph signals. In particular , we model graph signals as combinations of ov erlapping local patterns. W e impose the constraint that each dictionary is a concatenation of subdictionaries, with each subdictionary being a polynomial of the graph Laplacian matrix, representing a single pattern translated to dif ferent areas of the graph. The learning algorithm adapts the patterns to a training set of graph signals. Experimental results on both synthetic and real datasets demonstrate that the dictionaries learned by the proposed algorithm are competiti ve with and often better than unstructured dictionaries learned by state-of-the-art numerical learning algorithms in terms of sparse approximation of graph signals. In contrast to the unstructured dictionaries, howe ver , the dictionaries learned by the proposed algorithm feature localized atoms and can be implemented in a computationally efficient manner in signal processing tasks such as compression, denoising, and classification. Index T erms Dictionary learning, graph signal processing, graph Laplacian, sparse approximation. D. Thanou, D. I Shuman and P . Frossard are with Ecole Polytechnique F ´ ed ´ erale de Lausanne (EPFL), Signal Processing Laboratory-L TS4, CH-1015, Lausanne, Switzerland (e-mail: { dorina.thanou, david.shuman, pascal.frossard } @epfl.ch). This work has been partialy funded by the Swiss National Science Foundation under Grant 200021 135493 . Part of the work reported here was presented at the IEEE Glob. Conf. Signal and Inform. Pr ocess., Austin, T exas, Dec. 2013. January 15, 2014 DRAFT 2 I . I N T RO D U C T I O N Graphs are flexible data representation tools, suitable for modeling the geometric structure of signals that live on topologically complicated domains. Examples of signals residing on such domains can be found in social, transportation, energy , and sensor networks [1]. In these applications, the vertices of the graph represent the discrete data domain, and the edge weights capture the pairwise relationships between the vertices. A graph signal is then defined as a function that assigns a real value to each verte x. Some simple examples of graph signals are the current temperature at each location in a sensor network and the traffic lev el measured at predefined points of the transportation network of a city . An illustrativ e example is gi ven in Fig. 1. W e are interested in finding meaningful graph signal representations that (i) capture the most important characteristics of the graph signals, and (ii) are sparse. That is, giv en a weighted graph and a class of signals on that graph, we want to construct an ov ercomplete dictionary of atoms that can sparsely represent graph signals from the giv en class as linear combinations of only a fe w atoms in the dictionary . An additional challenge when designing dictionaries for graph signals is that in order to identify and exploit structure in the data, we need to account for the intrinsic geometric structure of the underlying weighted graph. This is because signal characteristics such as smoothness depend on the topology of the graph on which the signal resides (see, e.g., [1, Example 1]). For signals on Euclidean domains as well as signals on irregular data domains such as graphs, the choice of the dictionary often in volv es a tradeoff between two desirable properties – the ability to adapt to specific signal data and a fast implementation of the dictionary [2]. In the dictionary learning or dictionary training approach to dictionary design, numerical algorithms such as K-SVD [3] and the Method of Optimal Directions (MOD) [4] (see [2, Section IV] and references therein) learn a dictionary from a set of realizations of the data (training signals). The learned dictionaries are highly adapted to the giv en class of signals and therefore usually exhibit good representation performance. Howe ver , the learned dictionaries are highly non-structured, and therefore costly to apply in various signal processing tasks. On the other hand, analytic dictionaries based on signal transforms such as the Fourier , Gabor , wa velet, curvelet and shearlet transforms are based on mathematical models of signal classes (see [5] and [2, Section III] for a detailed ov ervie w of transform-based representations in Euclidean settings). These structured dictionaries often feature fast implementations, but they are not adapted to specific realizations of the data. Therefore, their ability to efficiently represent the data depends on the accuracy of the mathematical model of the data. January 15, 2014 DRAFT 3 (a) Day 1 (b) Day 2 (c) Day 3 Fig. 1. Illustrative example: The three signals on the graph are the minutes of bottlenecks per day at different detector stations in Alameda County , California, on three different days. The detector stations are the nodes of the graph and the connectivity is defined based on the GPS coordinates of the stations. Note that all signals consist of a set of localized features positioned on different nodes of the graph. The gap between the transform-based representations and the numerically trained dictionaries can be bridged by imposing a structure on the dictionary atoms and learning the parameters of this structure. The structure generally rev eals various desirable properties of the dictionary such as translation in vari- ance [6], minimum coherence [7] or ef ficient implementation [8] (see [2, Section IV .E] for a complete list of references). Structured dictionaries generally represent a good trade-of f between approximation performance and efficienc y of the implementation. In this work, we build on our previous work [9] and capitalize on the benefits of both numerical and analytical approaches by learning a dictionary that incorporates the graph structure and can be implemented efficiently . W e model the graph signals as combinations of overlapping local patterns, describing localized ev ents or causes on the graph. For example, the e volution of traf fic on a highway might be similar to that on a different highway , at a dif ferent position in the transportation network. W e incorporate the underlying graph structure into the dictionary through the graph Laplacian operator, which encodes the connectivity . In order to ensure the atoms are localized in the graph v ertex domain, we impose the constraint that our dictionary is a concatenation of subdictionaries that are polynomials of the graph Laplacian [10]. W e then learn the coefficients of the polynomial kernels via numerical optimization. As such, our approach falls into the category of parametric dictionary learning [2, Section IV .E]. The learned dictionaries are adapted to the training data, efficient to store, and computationally ef ficient to apply . Experimental results demonstrate the ef fectiv eness of our scheme in the approximation of both synthetic signals and graph signals collected from real world applications. January 15, 2014 DRAFT 4 The structure of the paper is as follows. W e first highlight some related work on the representation of graph signals in Section II. In Section III, we recall basic definitions related to graphs that are necessary to understand our dictionary learning algorithm. The polynomial dictionary structure and the dictionary learning algorithms are described in Section IV. In Section V, we ev aluate the performance of our algorithm on the approximation of both synthetic and real world graph signals. Finally , the benefits of the polynomial structure are discussed in Section VI. I I . R E L A T E D W O R K The design of ov ercomplete dictionaries to sparsely represent signals has been extensi vely in vestigated in the past fe w years. W e restrict our focus here to the literature related to the problem of designing dictionaries for graph signals. Generic numerical approaches such as K-SVD [3] and MOD [4] can certainly be applied to graph signals, with signals viewed as vectors in R N . Howe ver , the learned dictionaries will neither feature a fast implementation, nor explicitly incorporate the underlying graph structure. Meanwhile, se veral transform-based dictionaries for graph signals ha ve recently been proposed (see [1] for an ov erview and complete list of references). For example, the graph Fourier transform has been sho wn to sparsely represent smooth graph signals [11]; wa velet transforms such as dif fusion wav elets [12], spectral graph wav elets [10], and critically sampled two-channel wav elet filter banks [13] target piece wise-smooth graph signals; and verte x-frequency frames [14]–[16] can be used to analyze signal content at specific verte x and frequency locations. These dictionaries feature pre-defined structures deri v ed from the graph and some of them can be efficiently implemented; howe ver , they generally are not adapted to the signals at hand. T wo exceptions are the diffusion wa velet packets of [17] and the wav elets on graphs via deep learning [18], which feature extra adaptivity . The recent work in [19] tries to bridge the gap between the graph-based transform methods and the purely numerical dictionary learning algorithms by proposing an algorithm to learn structured graph dictionaries. The learned dictionaries hav e a structure that is deri ved from the graph topology , while its parameters are learned from the data. This work is the closest to ours in a sense that both graph dictionaries consist of subdictionaries that are based on the graph Laplacian. Ho we ver , it does not necessarily lead to efficient implementations as the obtained dictionary is not necessarily a smooth matrix function (see, e.g., [20] for more on matrix functions) of the graph Laplacian matrix. Finally , we remark that the graph structure is taken into consideration in [21], not explicitly into the dictionary b ut rather in the sparse coding coefficients. The authors use the graph Laplacian operator as January 15, 2014 DRAFT 5 a regularizer in order to impose that the obtained sparse coding coefficients vary smoothly along the geodesics of the manifold that is captured by the graph. Ho wev er , the obtained dictionary does not ha ve any particular structure. None of the pre vious works are able to design dictionaries that provide sparse representations, particularly adapted to a gi ven class of graph signals, and ha ve efficient implementations. This is exactly the objecti ve of our work, where a structured graph signal dictionary is composed of multiple polynomial matrix functions of the graph Laplacian. I I I . P R E L I M I NA R I E S In this section, we briefly ov ervie w a few basic definitions for signals on graphs. A more complete description of the graph signal processing frame work can be found in [1]. W e consider a weighted and undirected graph G = ( V , E , W ) where V and E represent the verte x and edge sets of the graph, and W represents the matrix of edge weights, with W ij denoting the weight of an edge connecting v ertices i and j . W e assume that the graph is connected. The graph Laplacian operator is defined as L = D − W , where D is the diagonal degree matrix [22]. The normalized graph Laplacian is defined as L = D − 1 2 LD − 1 2 . Throughout the paper , we use the normalized graph Laplacian eigen vectors as the Fourier basis in order to av oid some numerical instabilities that arise when taking large po wers of the combinatorial graph Laplacian. Both operators are real symmetric matrices and they hav e a complete set of orthonormal eigen vectors with corresponding nonnegati ve eigen v alues. W e denote the eigen vectors of the normalized graph Laplacian by χ = [ χ 1 , χ 2 , ..., χ N ] , and the spectrum of eigen v alues by σ ( L ) := n 0 = λ 0 < λ 1 ≤ λ 2 ≤ ... ≤ λ N − 1 ≤ 2 o . A graph signal y in the vertex domain is a real-v alued function defined on the vertices of the graph G , such that y ( v ) is the v alue of the function at vertex v ∈ V . The spectral domain representation can also provide significant information about the characteristics of graph signals. In particular , the eigen v ectors of the Laplacian operators can be used to perform harmonic analysis of signals that liv e on the graph, and the corresponding eigen v alues carry a notion of frequency [1]. The normalized Laplacian eigen vectors are a Fourier basis, so that for any function y defined on the vertices of the graph, the graph Fourier transform ˆ y at frequency λ ` is defined as ˆ y ( λ ` ) = h y , χ ` i = N X n =1 y ( n ) χ ∗ ` ( n ) , while the in verse graph F ourier transform is y ( n ) = N − 1 X ` =0 ˆ y ( λ ` ) χ ` ( n ) , ∀ n ∈ V . January 15, 2014 DRAFT 6 Besides its use in harmonic analysis, the graph Fourier transform is also useful in defining the translation of a signal on the graph. The generalized translation operator can be defined as a generalized con volution with a Kronecker δ function centered at vertex n [14], [15]: T n g = √ N ( g ∗ δ n ) = √ N N − 1 X ` =0 ˆ g ( λ ` ) χ ∗ ` ( n ) χ ` . (1) The right-hand side of (1) allows us to interpret the generalized translation as an operator acting on the kernel ˆ g ( · ) , which is defined directly in the graph spectral domain, and the localization of T n g around the center vertex n is controlled by the smoothness of the kernel ˆ g ( · ) [10], [15]. One can thus design atoms T n g that are localized around n in the verte x domain by taking the kernel ˆ g ( · ) in (1) to be a smooth polynomial function of degree K : ˆ g ( λ ` ) = K X k =0 α k λ k ` , ` = 0 , ..., N − 1 . (2) Combining (1) and (2), we can translate a polynomial kernel to each vertex in the graph and generate a set of N localized atoms, which are the columns of T g = √ N ˆ g ( L ) = √ N χ ˆ g (Λ) χ T = √ N K X k =0 α k L k , (3) where Λ is the diagonal matrix of the eigenv alues. Note that the k th po wer of the Laplacian L is exactly k -hop localized on the graph topology [10]; i.e., for the atom centered on node n , if there is no K -hop path connecting nodes n and i , then ( T n g )( i ) = 0 . This definition of localization is based on the shortest path distance on the graph and ignores the weights of the edges. I V . P A R A M E T R I C D I C T I O N A RY L E A R N I N G O N G R A P H S Gi ven a set of training signals on a weighted graph, our objecti ve is to learn a structured dictionary that sparsely represents classes of graph signals. W e consider a general class of graph signals that are linear combinations of (overlapping) graph patterns positioned at dif ferent vertices on the graph. W e aim to learn a dictionary that is capable of capturing all possible translations of a set of patterns. W e use the definition (1) of generalized translation, and we learn a set of polynomial generating kernels (i.e., patterns) of the form (2) that capture the main characteristics of the signals in the spectral domain. Learning directly in the spectral domain enables us to detect spectral components that exist in our training signals, such as atoms that are supported on selected frequency components. In this section, we describe in detail the structure of our dictionary and the learning algorithm. January 15, 2014 DRAFT 7 A. Dictionary Structur e W e design a structured graph dictionary D = [ D 1 , D 2 , ..., D S ] that is a concatenation of a set of S subdictionaries of the form D s = b g s ( L ) = χ K X k =0 α sk Λ k ! χ T = K X k =0 α sk L k , (4) where b g s ( · ) is the generating kernel or pattern of the subdictionary D s . Note that the atom gi ven by column n of subdictionary D s is equal to 1 √ N T n g s ; i.e., the polynomial b g s ( · ) of order K translated to the verte x n . The polynomial structure of the kernel b g s ( · ) ensures that the resulting atom gi ven by column n of subdictionary D s has its support contained in a K -hop neighborhood of vertex n [10, Lemma 5.2]. The polynomial constraint guarantees the localization of the atoms in the verte x domain, but it does not provide any information about the spectral representation of the atoms. In order to control their frequency behavior , we impose two constraints on the spectral representation of the kernels { b g s ( · ) } s =1 , 2 ,...,S . First, we require that the kernels are nonneg ativ e and uniformly bounded by a giv en constant c . In other words, we impose that 0 ≤ b g s ( λ ) ≤ c for all λ ∈ [0 , λ max ] , or , equiv alently , 0 D s cI , ∀ s ∈ { 1 , 2 , ..., S } , (5) where I is the N × N identity matrix. Each subdictionary D s has to be a positi ve semi-definite matrix whose maximum eigen value is upper bounded by c . Second, since the classes of signals under consideration usually contain frequency components that are spread across the entire spectrum, the learned kernels { b g s ( · ) } s =1 , 2 ,...,S should also cover the full spectrum. W e thus impose the constraint c − 1 ≤ S X s =1 b g s ( λ ) ≤ c + 2 , ∀ λ ∈ [0 , λ max ] , (6) or equiv alently ( c − 1 ) I S X s =1 D s ( c + 2 ) I , (7) where 1 , 2 are small positiv e constants. Note that both (5) and (7) are quite generic and do not assume any particular prior on the spectral behavior of the atoms. If we ha ve additional prior information, we can incorporate that prior into our optimization problem by modifying these constraints. For example, if we kno w that our signals’ frequenc y content is restricted to certain parts of the spectrum, by choosing 1 close to c , we allow the flexibility for our learning algorithm to learn filters covering only these parts and not the entire spectrum. January 15, 2014 DRAFT 8 Finally , the spectral constraints increase the stability of the dictionary . From the constants c , 1 and 2 , we can deriv e frame bounds for D , as shown in the follo wing proposition. Proposition 1. Consider a dictionary D = [ D 1 , D 2 , ..., D S ] , wher e each D s is of the form of D s = P K k =0 α sk L k . If the kernels { b g s ( · ) } s =1 , 2 ,...,S satisfy the constraints 0 ≤ b g s ( λ ) ≤ c and c − 1 ≤ P S s =1 b g s ( λ ) ≤ c + 2 , for all λ ∈ [0 , λ max ] then the set of atoms { d s,n } s =1 , 2 ,...,S,n =1 , 2 ,...,N of D form a frame . F or e very signal y ∈ R N , ( c − 1 ) 2 S k y k 2 2 ≤ N X n =1 S X s =1 |h y , d s,n i| 2 ≤ ( c + 2 ) 2 k y k 2 2 . Pr oof: F r om [16, Lemma 1], whic h is a slight gener alization of [10, Theor em 5.6], we have N X n =1 S X s =1 |h y , d s,n i| 2 = N − 1 X ` =0 | ˆ y ( λ ` ) | 2 S X s =1 | b g s ( λ ` ) | 2 , ∀ λ ∈ σ ( L ) . (8) F r om the constr aints on the spectrum of kernels { b g s ( · ) } s =1 , 2 ,...,S we have S X s =1 | b g s ( λ ` ) | 2 ≤ S X s =1 b g s ( λ ` ) ! 2 ≤ ( c + 2 ) 2 , ∀ λ ∈ σ ( L ) (9) Mor eover , fr om the left side of (7) and the Cauc hy-Schwarz inequality , we have ( c − 1 ) 2 S ≤ P S s =1 b g s ( λ ` ) 2 S ≤ S X s =1 | b g s ( λ ` ) | 2 , ∀ λ ∈ σ ( L ) . (10) Combining (8), (9) and (10) yields the desir ed result. W e remark that if we alternati vely impose that P S s =1 | b g s ( λ ) | 2 is constant for all λ ∈ [0 , λ max ] , the resulting dictionary D would be a tight frame. Ho wever , such a constraint leads to a significantly more dif ficult optimization problem to learn the dictionary . The constraints (5) and (7) lead to an easier dictionary learning optimization problem, while still providing control on the spectral representation of the atoms and the stability of signal reconstruction with the learned dictionary . T o summarize, the dictionary D is a parametric dictionary that depends on the parameters { α sk } s =1 , 2 ,...,S ; k =1 , 2 ,...,K , and the constraints (5) and (7) can be vie wed as constraints on these parameters. B. Dictionary Learning Algorithm Gi ven a set of training signals Y = [ y 1 , y 2 , ..., y M ] ∈ R N × M , all living on the weighted graph G , our objectiv e is to learn a graph dictionary D ∈ R N × N S with the structure described in Section IV -A January 15, 2014 DRAFT 9 that can ef ficiently represent all of the signals in Y as linear combinations of only a few of its atoms. Since D has the form (4), this is equiv alent to learning the parameters { α sk } s =1 , 2 ,...,S ; k =1 , 2 ,...,K that characterize the set of generating kernels, { b g s ( · ) } s =1 , 2 ,...,S . W e denote these parameters in vector form as α = [ α 1 ; ... ; α S ] , where α s is a column vector with ( K + 1) entries. Therefore, the dictionary learning problem can be cast as the following optimization problem: argmin α ∈ R ( K +1) S , X ∈ R S N × M || Y − D X || 2 F + µ k α k 2 2 (11) subject to k x m k 0 ≤ T 0 , ∀ m ∈ { 1 , ..., M } , D s = K X k =0 α sk L k , ∀ s ∈ { 1 , 2 , ..., S } 0 D s c, ∀ s ∈ { 1 , 2 , ..., S } ( c − 1 ) I S X s =1 D s ( c + 2 ) I , where D = [ D 1 , D 2 , . . . , D S ] , x m corresponds to column m of the coef ficient matrix X , and T 0 is the sparsity lev el of the coef ficients of each signal. Note that in the objecti ve of the optimization problem (11), we penalize the norm of the polynomial coefficients α in order to (i) promote smoothness in the learned polynomial kernels, and (ii) improve the numerical stability of the learning algorithm. The optimization problem (11) is not con vex, b ut it can be approximately solved in a computationally ef ficient manner by alternating between the sparse coding and dictionary update steps. In the first step, we fix the parameters α (and accordingly fix the dictionary D via the structure (4)) and solve argmin X || Y − D X || 2 F subject to k x m k 0 ≤ T 0 ∀ m ∈ { 1 , ..., M } , using orthogonal matching pursuit (OMP) [23], [24], which has been shown to perform well in the dictionary learning literature. Before applying OMP , we normalize the atoms of the dictionary so that they all have a unit norm. This step is essential for the OMP algorithm in order to treat all of the atoms equally . After computing the coef ficients X , we renormalize the atoms of our dictionary to reco ver our initial polynomial structure [25, Chapter 3.1.4] and the sparse coding coefficients in such a way that the product D X remains constant. Note that other methods for solving the sparse coding step such as matching pursuit (MP) or iterative soft thresholding could be used as well. In the second step, we fix the coef ficients X and update the dictionary by finding the vector of January 15, 2014 DRAFT 10 parameters, α , that solves argmin α ∈ R ( K +1) S || Y − D X || 2 F + µ k α k 2 2 (12) subject to D s = K X k =0 α sk L k , ∀ s ∈ { 1 , 2 , ..., S } 0 D s cI , ∀ s ∈ { 1 , 2 , ..., S } ( c − 1 ) I S X s =1 D s ( c + 2 ) I . Problem (12) is con ve x and can be written as a quadratic program. The details are giv en in the Appendix A. Algorithm 1 contains a summary of the basic steps of our dictionary learning algorithm. Since the optimization problem (11) is solved by alternating between the two steps, the polynomial dictionary learning algorithm is not guaranteed to con ver ge to the optimal solution; howe ver , the algorithm con verged in all of experiments to a local optimum. Finally , the complexity of our algorithm is dominated by the pre-computation of the eigen values of the Laplacian matrix, which we use to enforce the spectral constraints on the kernels. In the dictionary update step, the quadratic program (line 10 of Algorithm 1) can be ef ficiently solved in polynomial time using optimization techniques such as interior point methods [26] or operator splitting methods (e.g., Alternating Direction Method of Multipliers [27]). The former methods lead to more accurate solutions, while the latter are better suited to solve large scale problems. For the numerical examples in this paper , we use interior point methods to solve the quadratic optimization problem. V . E X P E R I M E N T A L R E S U LT S In the follo wing experiments, we quantify the performance of the proposed dictionary learning method in the approximation of both synthetic and real data. First, we study the behavior of our algorithm in the synthetic scenario where the signals are linear combinations of a few localized atoms that are placed on dif ferent vertices of the graph. Then, we study the performance of our algorithm in the approximation of graph signals collected from real world applications. In all experiments, we compare the performance of our algorithm to the performance of (i) graph-based transform methods such as the spectral graph wa velet transform (SGWT) [10], (ii) purely numerical dictionary learning methods such as K-SVD [3] that treat the graph signals as vectors in R N and ignore the graph structure, and (iii) the graph-based dictionary learning algorithm presented in [19]. The kernel bounds in (11), if not otherwise specified, are January 15, 2014 DRAFT 11 Algorithm 1 Parametric Dictionary Learning on Graphs 1: Input: Signal set Y , initial dictionary D (0) , target signal sparsity T 0 , polynomial degree K , number of subdictionaries S , number of iterations iter 2: Output: Sparse signal representations X , polynomial coefficients α 3: Initialization: D = D (0) 4: f or i = 1 , 2 , ..., iter do: 5: Sparse A pproximation Step: 6: (a) Scale each atom in D to a unit norm 7: (b) Solve min X || Y − D X || 2 F subject to k x m k 0 ≤ T 0 ∀ m ∈ { 1 , ..., M } 8: (c) Rescale X and D to recov er the polynomial structure 9: Dictionary Update Step: 10: Compute the polynomial coef ficients α by solving the optimization problem (12), and update the dictionary according to (4) 11: end f or chosen as c = 1 and 1 = 2 = 0 . 01 , and the number of iterations in the learning algorithm is fixed to 25. W e use the sdpt3 solver [28] in the yalmip optimization toolbox [29] to solve the quadratic problem (12) in the learning algorithm. In order to directly compare the methods mentioned abov e, we always use orthogonal matching pursuit (OMP) for the sparse coding step in the testing phase, where we first normalize the dictionary atoms to a unit norm. W e could alternativ ely apply iterati ve soft thresholding to compute the sparse coding coefficients; ho we ver , that would require a careful tuning of the stepsize for each of the algorithms. Finally , the av erage approximation error is set to k Y test − D X test k 2 F / | Y test | , where | Y test | is the size of the testing set and X test are the sparse coding coefficients. A. Synthetic Signals W e first study the performance of our algorithm for the approximation of synthetic signals. W e generate a graph by randomly placing N = 100 vertices in the unit square. W e set the edge weights based on a thresholded Gaussian kernel function so that W ( i, j ) = e − [ dist ( i,j )] 2 2 θ 2 if the physical distance between vertices i and j is less than or equal to κ , and zero otherwise. W e fix θ = 0 . 9 and κ = 0 . 5 in our experiments, and ensure that the graph is connected. 1) P olynomial Generating Dictionary: In our first set of experiments, to construct a set of synthetic training signals consisting of localized patterns on the graph, we use a generating dictionary that is a January 15, 2014 DRAFT 12 concatenation of S = 4 subdictionaries. Each subdictionary is a fifth order ( K = 5 ) polynomial of the graph Laplacian according to (4) and captures one of the four constitutiv e components of our signal class. The generating kernels { b g s ( · ) } s =1 , 2 ,...,S of the dictionary are shown in Fig. 2(a). W e generate the graph signals by linearly combining T 0 ≤ 4 random atoms from the dictionary with random coefficients. W e then learn a dictionary from the training signals, and we expect this learned dictionary to be close to the kno wn generating dictionary . W e first study the influence of the size of the training set on the dictionary learning outcome. Collecting a large number of training signals can be infeasible in many applications. Moreo ver , training a dictionary with a large training set significantly increases the complexity of the learning phase, leading to impractical optimization problems. Using our polynomial dictionary learning algorithm with training sets of M = { 400 , 600 , 2000 } signals, we learn a dictionary of S = 4 subdictionaries. T o allo w some flexibility into our learning algorithm, we fix the degree of the learned polynomials to K = 20 . Comparing Fig. 2(a) to Figs. 2(b), 2(c), and 2(d), we observe that our algorithm is able to recover the shape of the kernels used for the generating dictionary , ev en with a very small number of training signals. Howe ver , the accuracy of the recov ery improves as we increase the size of the training set. T o quantify the improv ement, we define the mean SNR of the learned kernels as 1 S P S s =1 − 20 log( k b g s (Λ) − b g s 0 (Λ) k 2 ) , where b g s (Λ) is the true pattern of Fig. 2(a) for the subdictionary D s and b g s 0 (Λ) is the corresponding pattern learned with our polynomial dictionary algorithm. The SNR values that we obtain are { 4 . 9 , 5 . 3 , 14 . 9 } for M = { 400 , 600 , 2000 } , respecti vely . Next, we generate 2000 testing signals using the same method as for the the construction of the training signals. W e then study the ef fect of the size of the training set on the approximation of the testing signals with atoms from our learned dictionary . Fig. 3 illustrates the results for three different sizes of the training set and compares the approximation performance to that of other learning algorithms. Each point in the figure is the av erage of 20 random runs with different realizations of the training and testing sets. W e first observe that the approximation performance of the polynomial dictionary is always better than that of SGWT , which demonstrates the benefits of the learning process. The improvement is attributed to the fact that the SGWT kernels are designed a priori , while our algorithm learns the shape of the kernels from the data. W e also see that the performance of K-SVD depends on the size of the training set. Recall that K-SVD is blind to the graph structure, and is therefore unable to capture translations of similar patterns. In particular , we observe that when the size of the training set is relativ ely small, as in the case of M = { 500 , 600 } , the January 15, 2014 DRAFT 13 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (a) Kernels of the generating dictionary 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (b) Learned kernels with M = 400 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (c) Learned kernels with M = 600 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (d) Learned kernels with M = 2000 Fig. 2. Comparison of the kernels learned by the polynomial dictionary learning algorithm to the generating kernels { b g s ( · ) } s =1 , 2 ,...,S (shown in (a)) for M = 400 , M = 600 and M = 2000 training signals. approximation performance of K-SVD significantly deteriorates. It slightly impro ves when the number of training signals increases (i.e., M = 2000 ). Our polynomial dictionary ho wev er sho ws much more stable performance with respect to the size of the training set. W e note two reasons that may underly the better performance of our algorithm, as compared to K-SVD. First, K-SVD tends to learn atoms that sparsely approximate the signal on the whole graph, rather than to extract common features that appear in different neighborhoods. As a result, the atoms learned by K-SVD tend to hav e a global support on the graph, and K-SVD shows poor performance in the datasets containing many localized signals. An example of the atomic decomposition of a graph signal from the testing set with respect to the K-SVD and the January 15, 2014 DRAFT 14 0 5 10 15 20 25 0 0.05 0.1 0.15 0.2 0.25 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] K − SVD [3] SGWT [10] (a) M=400 0 5 10 15 20 25 0 0.05 0.1 0.15 0.2 0.25 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] K − SVD [3] SGWT [10] (b) M=600 0 5 10 15 20 25 0 0.05 0.1 0.15 0.2 0.25 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] K − SVD [3] SGWT [10] (c) M=2000 Fig. 3. Comparison of the learned polynomial dictionary to the SGWT [10], K-SVD [3] and the graph structured dictionary [19] in terms of approximation performance on test data generated from a polynomial generating dictionary , for different sizes of the training set. polynomial graph dictionary is illustrated in Fig. 4. Second, ev en when K-SVD does learn a localized pattern appearing in the training data, it only learns that pattern in that specific area of the graph, and does not assume that similar patterns may appear at other areas of the graph. Of course, as we increase the number of training signals, translated instances of the pattern are more to likely appear in other areas of the graph in the training data, and K-SVD is then more likely to learn atoms containing such patterns in dif ferent areas of the graph. On the other hand, our polynomial dictionary learning algorithm learns the patterns in the graph spectral domain, and then includes translated versions of the patterns to all locations in the graph in the learned dictionary , ev en if some specific instances of the translated patterns do not appear in the training data. The algorithm proposed in [19] represents some sort of intermediate solution between K-SVD and our algorithm. It learns a dictionary that consists of subdictionaries of the form χ b g s (Λ) χ T , where the specific v alues b g s ( λ 0 ) , b g s ( λ 1 ) , . . . , b g s ( λ N − 1 ) are learned, rather than learning a continuous kernel b g s ( · ) and e valuating it at the N discrete eigen values as we do. As a result, the obtained dictionary is adapted to the graph structure and it contains atoms that are translated versions of the same pattern on the graph. Ho wev er , the obtained atoms are not guaranteed to be well localized in the graph since the learned discrete v alues of b g s are not necessarily deriv ed from a smooth kernel. Moreover , the unstructured construction of the kernels in the method of [19] leads to more complex implementations, as discussed in Section VI. Finally , we study the resilience of our algorithm to potential noise in the training phase. W e generate M = 600 training signals as linear combinations of T 0 ≤ 4 atoms from the generating dictionary and January 15, 2014 DRAFT 15 (a) Graph signal (b) K-SVD (c) Polynomial dictionary Fig. 4. (a) An e xample of a graph signal from the testing set and its atomic decomposition with respect to (b) the dictionary learned by K-SVD and (c) the learned polynomial graph dictionary . Note that the K-SVD atoms hav e a more global support while the polynomial dictionary atoms are localized in specific neighborhoods of the graph. add some Gaussian noise with zero mean and variance σ = 0 . 015 , which corresponds to a noise lev el with S N R = 4 dB . These training signals are used to learn a polynomial dictionary with polynomials of degree K = 20 . The obtained k ernels are shown in Fig. 5(a). W e observe that, ev en though the training signals are quite noisy , we succeed in learning kernels that preserve the shape of our true noiseless kernels of Fig. 2(a). W e then test the performance of our algorithm on a set of 2000 testing signals generated as linear combinations of T 0 ≤ 4 atoms from the generating dictionary . The results for different sparsity le vels in the OMP approximation are sho wn in Fig. 5(b). W e observe that both K-SVD and the structured graph dictionary are more sensitive to noise than our polynomial dictionary . 2) Non-P olynomial Generating Dictionary: In the next set of experiments, we depart from the idealistic scenario and study the performance of our polynomial dictionary learning algorithm in the more general case when the signal components are not exactly polynomials of the Laplacian matrix. In order to generate training and testing signals, we di vide the spectrum of the graph into four frequency bands, defined by the eigen values of the graph: [ λ 0 : λ 24 ] , [( λ 25 : λ 39 ) ∪ ( λ 90 : λ 99 )] , [ λ 40 : λ 64 ] , and [ λ 65 : λ 89 ] . W e then construct a generating dictionary of J = 400 atoms, with each atom having a spectral representation that is concentrated exclusi vely in one of the four bands. In particular , atom j is of the form d j = b h j ( L ) δ n = χ b h j (Λ) χ T δ n . (13) Each atom is generated independently of the others as follo ws. W e randomly pick one of the four bands, randomly generate 25 coefficients uniformly distributed in the range [0 , 1] , and assign these random January 15, 2014 DRAFT 16 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Eige nv alue s of t he Laplac ian ( λ ) Gener a t in g ker n els ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (a) 0 5 10 15 20 25 0 0.05 0.1 0.15 0.2 0.25 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] K − SVD [3] SGWT [10] (b) Fig. 5. Dictionary learning performance when Gaussian noise is added to the training signals. (a) Kernels learned by the polynomial dictionary . (b) Approximation performance of the polynomial dictionary , SGWT [10], K-SVD [3] and the graph structured dictionary [19] on noiseless testing signals. coef ficients to be the diagonal entries of b h j (Λ) corresponding to the indices of the chosen spectral band. The rest of the values in b h j (Λ) are set to zero. The atom is then centered on a verte x n that is also chosen randomly . Note that the obtained atoms are not guaranteed to be well localized in the vertex domain since the discrete values of b h j (Λ) are chosen randomly and are not derived from a smooth kernel. Therefore, the atoms of the generating dictionary do not exactly match the signal model assumed by our dictionary design algorithm. Finally , we generate the training signals by linearly combining (with random coefficients) T 0 ≤ 4 random atoms from the generating dictionary . W e first verify the ability of our dictionary learning algorithm to recov er the spectral bands that are used in the synthetic generating dictionary . W e fix the number of training signals to M = 600 and run our dictionary learning algorithm for four dif ferent de gree values of the polynomial, i.e., K = { 5 , 10 , 20 , 25 } . The kernels { b g s ( · ) } s =1 , 2 , 3 , 4 obtained for the four subdictionaries are shown in Fig. 6. W e observe that for higher v alues of K , the learned kernels are more localized in the graph spectral domain. W e further notice that, for K = { 20 , 25 } , each kernel approximates one of the four bands defined in the generating dictionary , similarly to the beha vior of classical frequency filters. In Fig. 7, we illustrate the four learned atoms centered at the vertex n = 1 (one atom for each subdictionary), with K = 20 . W e can see that the support of the atoms adapts to the graph topology . The atoms can be either smoother around a particular verte x, as for example in Fig. 7(c), or more localized, as in Fig. 7(a). Comparing Figs. 6(c), and 7, we observe that the localization of the atoms in the graph domain depends on the spectral behavior of the kernels. Note that the smoothest atom on the January 15, 2014 DRAFT 17 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (a) K = 5 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (b) K = 10 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (c) K = 20 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) ! g 3 ( λ ) ! g 4 ( λ ) (d) K = 25 Fig. 6. K ernels { b g s ( · ) } s =1 , 2 , 3 , 4 learned by the polynomial dictionary algorithm for (a) K = 5 , (b) K = 10 , (c) K = 20 and (d) K = 25 . graph (Fig. 7(c)) corresponds to the subdictionary generated from the kernel that is concentrated on the lo w frequencies (i.e., b g 3 ( · ) ). This is because the graph Laplacian eigenv ectors associated with the lower frequencies are smoother with respect to the underlying graph topology , while those associated with the larger eigen values oscillate more rapidly [1]. Next, we test the approximation performance of our learned dictionary on a set of 2000 testing signals generated in e xactly the same w ay as the training signals. Fig. 8 sho ws that the approximation performance obtained with our algorithm improv es as we increase the polynomial degree. This is attrib uted to two January 15, 2014 DRAFT 18 − 0.05 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 (a) b g 1 ( L ) δ 1 − 0.1 − 0.05 0 0.05 0.1 0.15 0.2 (b) b g 2 ( L ) δ 1 − 0.02 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 (c) b g 3 ( L ) δ 1 − 0.1 − 0.05 0 0.05 0.1 0.15 0.2 (d) b g 4 ( L ) δ 1 Fig. 7. Learned atoms centered on vertex n = 1 , from each of the subdictionaries. The size and the color of each ball indicate the value of the atom in each v ertex of the graph. main reasons: (i) by increasing the polynomial degree, we allow more flexibility in the learning process; (ii) a small K implies that the atoms are localized in a small neighborhood and thus more atoms are needed to represent signals with support in dif ferent areas of the graph. In Fig. 9, we fix K = 20 , and compare the approximation performance of our learned dictionary to that of other dictionaries, with exactly the same setup as we used in Figure 3. W e again observe that K-SVD is the most sensitiv e to the size of the training data, for the same reasons explained earlier . Since the kernels used in the generating dictionary in this case do not match our polynomial model, the structured graph dictionary learning algorithm of [19] has more flexibility to learn the non-smooth generating kernels and therefore generally achieves better approximation. Nonetheless, the approximation performance of our learned dictionary is competitiv e, especially for smaller training sets, and the learned dictionary is January 15, 2014 DRAFT 19 0 5 10 15 20 25 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary K=5 Polynomial Dictionary K=10 Polynomial Dictionary K=20 Polynomial Dictionary K=25 Fig. 8. Comparison of the a verage approximation performance of our learned dictionary on test signals generated by the non-polynomial synthetic generating dictionary , for K = { 5 , 10 , 20 , 25 } . 0 5 10 15 20 25 0 0.05 0.1 0.15 0.2 0.25 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] Polynomial approximation of [19] K − SVD [3] SGWT [10] (a) M=400 0 5 10 15 20 25 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] Polynomial approximation of [19] K − SVD [3] SGWT [10] (b) M=600 0 5 10 15 20 25 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] Polynomial approximation of [19] K − SVD [3] SGWT [10] (c) M=2000 Fig. 9. Comparison of the learned polynomial dictionary to the SGWT [10], K-SVD [3] and the graph structured dictionary [19] and its polynomial approximation in terms of approximation performance on test data generated from a non-polynomial generating dictionary , for dif ferent sizes of the training set. more computationally ef ficient to implement. For a fairer comparison of approximation performance, we fit an order K = 20 polynomial function to the discrete v alues b g s learned with the algorithm of [19]. W e observe that our polynomial dictionary outperforms the polynomial approximation of the dictionary learned by [19] in terms of approximation performance. 3) Generating Dictionary F ocused on Specific F requency Bands: In the final set of experiments, we study the behavior of our algorithm in the case when we have the additional prior information that the training signals do not cover the entire spectrum, b ut are concentrated only in some bands that are not kno wn a priori . In order to generate the training signals, we choose only two particular frequency January 15, 2014 DRAFT 20 0 0.2 0.4 0.6 0.8 1 1.2 1.4 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Eige nv alue s of t he Laplac ian ( λ ) Gener a t ing ke rnels ! g ( λ ) ! g 1 ( λ ) ! g 2 ( λ ) Fig. 10. Kernels { b g s ( · ) } s =1 , 2 learned by the polynomial dictionary algorithm from a set of training signals that are supported in only two particular bands of the spectrum. The bands are defined by the eigen values of the graph [ λ 0 : λ 9 ] and [ λ 89 : λ 99 ] , which correspond to the values [0 : 0 . 275] and [1 . 174 : 1 . 256] respecti vely . bands, defined by the eigen v alues of the graph: [ λ 0 : λ 9 ] and [ λ 89 : λ 99 ] , which correspond to the v alues [0 : 0 . 275] and [1 . 174 : 1 . 256] , respectively . W e construct a generating dictionary of J = 400 atoms, with each atom concentrated in only one of the two bands and generated according to (13). The training signals ( M = 600 ) are then constructed by linearly combining T 0 ≤ 4 atoms from the generating dictionary . W e set K = 20 and 1 = c in order to allow our polynomial dictionary learning algorithm the flexibility to learn kernels that are supported only on specific frequency bands. The learned kernels are illustrated in Fig. 10. W e observe that the algorithm is able to detect the spectral components that e xist in the training signals since the learned kernels are concentrated only in the two parts of the spectrum to which the atoms of the generating dictionary belong. B. Appr oximation of Real Gr aph Signals After examining the behavior of the polynomial dictionary learning algorithm for synthetic signals, we illustrate the performance of our algorithm in the approximation of localized graph signals from real world datasets. In particular , we e xamine the following three datasets. • Flickr Dataset: W e consider the daily number of distinct Flickr users that took photos at different geographical locations around T rafalgar Square in London, between January 2010 and June 2012 [30]. Each vertex of the graph represents a geographical area of 10 × 10 meters. The graph is constructed by assigning an edge between two locations when the distance between them is shorter January 15, 2014 DRAFT 21 than 30 meters, and the edge weight is set to be in versely proportional to the distance. W e then remov e edges whose weight is below a threshold in order to obtain a sparse graph. The number of vertices of the graph is N = 245 . W e set S = 2 and K = 10 in our dictionary learning algorithm. W e hav e a total of 913 signals, and we use 700 of them for training and the rest for testing. • T raffic Dataset: W e consider the daily bottlenecks in Alameda County in California between January 2007 and May 2013. The data are part of the Caltrans Performance Measurement System (PeMS) dataset that provides traf fic information throughout all major metropolitan areas of California [31]. 1 In particular , the nodes of the graph consist of N = 439 detector stations where bottlenecks were identified over the period under consideration. The graph is designed by connecting stations when the distance between them is smaller than a threshold of θ = 0 . 08 which corresponds to approximately 13 kilometres. The distance is set to be the Euclidean distance of the GPS coordinates of the stations and the edge weights are set to be inv ersely proportional to the distance. A bottleneck could be any location where there is a persistent drop in speed, such as merges, large on-ramps, and incidents. The signal on the graph is the av erage length of the time in minutes that a bottleneck is active for each specific day . In our experiments, we fix the maximum degree of the polynomial to K = 10 and we learn a dictionary consisting of S = 2 subdictionaries. W e use the signals in the period between January 2007 and December 2010 for training and the rest for testing. For computational issues, we normalize all the signals with respect to the norm of the signal with maximum energy . • Brain Dataset: W e consider a set of fMRI signals acquired on fi ve dif ferent subjects [32], [33]. For each subject, the signals hav e been preprocessed into timecourses of N = 90 brain regions of contiguous voxels, which are determined from a fixed anatomical atlas, as described in [33]. The timecourses for each subject correspond to 1290 different graph signals that are measured while the subject is in dif ferent states, such as completely relaxing, in the absence of any stimulation or passi vely watching small movie excerpts. For the purpose of this paper , we treat the measurements at each time as an independent signal on the 90 vertices of the brain graph. The anatomical distances between regions of the brain are approximated by the Euclidean distance between the coordinates of the centroids of each region, the connectivity of the graph is determined by assigning an edge between two re gions when the anatomical distance between them is shorter than 40 millimetres, and the edge weight is set to be in versely proportional to the distance. W e then apply our polynomial dictionary learning algorithm in order to learn a dictionary of atoms representing brain activity 1 The data are publicly available at http://pems.dot.ca.go v. January 15, 2014 DRAFT 22 across the network at a fixed point in time. W e use the graph signals from the timecourses of two subjects as our training signals and we learn a dictionary of S = 2 subdictionaries and a maximum polynomial degree of K = 15 . W e use the graph signals from the remaining three timecourses to v alidate the performance of the learned dictionary . As in the pre vious dataset, we normalize all of the graph signals with respect to the norm of the signal with maximum ener gy . Fig. 11 shows the approximation performance of the learned polynomial dictionaries for the three dif ferent datasets. The behavior is similar in all three datasets, and also similar to results on the synthetic datasets in the pre vious section. In particular , the data-adapted dictionaries clearly outperform the SGWT dictionary in terms of approximation error on test signals, and the localized atoms of the learned polynomial dictionary effecti vely represent the real graph signals. In Fig. 12, we illustrate the six most used atoms after applying OMP for the sparse decomposition of the testing signals from the brain dataset in the learned K-SVD dictionary and our learned polynomial dictionary . Note that in Fig. 12(b), the polynomial dictionary consists of localized atoms with supports concentrated on the close neighborhoods of different vertices, which can lead to poor approximation performance at lo w sparsity lev els. Ho wev er, as the sparsity le vel increases, the localization property clearly becomes beneficial. As was the case in the synthetic datasets, the learned polynomial dictionary also has the ability to represent localized patterns that did not appear in the training data, unlike K-SVD. For example, an unexpected e vent in London could significantly increase the number of pictures taken in the vicinity of a location that was not necessarily popular in the past. Comparing our algorithm with the one of [19], we observe that the performance of the latter is sometimes better (see Fig. 11(b)) and sometimes worse (see Figs. 11(a), 11(c)). Apart from the differences between the tw o algorithms that we ha ve already discussed in the previous subsections, one drawback of [19] is the way the dictionary is updated. Specifically , the update of the dictionary is performed block by block, which leads to a local optimum in the dictionary update step. This can lead to worse performance when compared to our algorithm, where all subdictionaries are updated simultaneously . V I . C O M P U T A T I O N A L E FFI C I E N C Y O F T H E L E A R N E D P O L Y N O M I A L D I C T I O NA RY The structural properties of the proposed class of dictionaries lead to compact representations and computationally efficient implementations, which we elaborate on briefly in this section. First, the number of free parameters depends on the number S of subdictionaries and the de gree K of the polynomials. The total number of parameters is ( K + 1) S , and since K and S are small in practice, the dictionary is compact January 15, 2014 DRAFT 23 0 2 4 6 8 10 12 14 16 0 2 4 6 8 10 12 14 16 18 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] K − SVD [3] SGWT [10] (a) Flickr Dataset 0 5 10 15 20 25 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] K − SVD [3] SGWT [10] (b) Traf fic Dataset 0 5 10 15 20 25 30 35 40 45 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 Number of atoms used in the representation Avarage approximation error Polynomial Dictionary Structured Graph Dictionary [19] K − SVD [3] SGWT [10] (c) Brain Dataset Fig. 11. Comparison of the learned polynomial dictionaries to the SGWT , K-SVD, and graph structured dictionaries [19] in terms of approximation performance on testing data generated from the (a) Flickr, (b) traffic, and (c) brain datasets, respectiv ely . and easy to store. Second, contrary to the non-structured dictionaries learned by algorithms such as K-SVD and MOD, the dictionary forw ard and adjoint operators can be ef ficiently applied when the graph is sparse, as is usually the case in practice. Recall from (4) that D T y = P S s =1 P K k =0 α sk L k . The computational cost of the iterati ve sparse matrix-vector multiplication required to compute {L k y } k =1 , 2 ,...,K is O ( K |E | ) . Therefore, the total computational cost to compute D T y is O ( K |E | + N S K ) . W e further note that, by follo wing a procedure similar to the one in [10, Section 6.1], the term D D T y can also be computed in a fast way by e xploiting the fact that D D T y = P S s =1 b g s 2 ( L ) y . This leads to a polynomial of degree K 0 = 2 K that can be ef ficiently computed. Both operators D T y and D D T y are important components of most sparse coding techniques. Therefore, these efficient implementations are useful in numerous signal processing tasks, and comprise January 15, 2014 DRAFT 24 (a) K-SVD (b) Polynomial Dictionary Fig. 12. Examples of atoms learned from training data from the brain dataset with (a) K-SVD and (b) the polynomial dictionary . The six atoms are the ones that were most commonly included by OMP in the sparse decomposition of the testing signals. Notice that the atoms in (a) hav e a support that cov ers the entire graph while the atoms in (b) are localized around a verte x. one of the main adv antages of learning structured parametric dictionaries. For example, to find sparse representations of different signals with the learned dictionary , rather than using OMP , we can use iterati ve soft thresholding [34] to solve the lasso regularization problem [35]. The two main operations required in iterati ve soft thresholding, D T y and D T D x , can both be approximated by the Chebyshev approximation method of [10], as explained in more detail in [36, Section IV .C]. A third computational benefit is that in settings where the data is distributed and communication between nodes of the graph is costly (e.g., a sensor network), the polynomial structure of the learned dictionary enables quantities such as D T y , D x , D D T y , and D T D x to be efficiently computed in a distributed fashion using the techniques of [36]. As discussed in [36], this structure makes it possible to implement many signal processing algorithms in a distrib uted fashion. V I I . C O N C L U S I O N W e proposed a parameterized family of structured dictionaries – namely , unions of polynomial matrix functions of the graph Laplacian – to sparsely represent signals on a giv en weighted graph, and an algorithm to learn the parameters of a dictionary belonging to this family from a set of training signals on the graph. When translated to a specific vertex, the learned polynomial kernels in the graph spectral domain correspond to localized patterns on the graph. The fact that we translate each of these patterns to different areas of the graph led to sparse approximation performance that was clearly better than January 15, 2014 DRAFT 25 that of non-adapted graph wav elet dictionaries such as the SGWT and comparable to or better than that of dictionaries learned by state-of-the art numerical algorithms such as K-SVD. The approximation performance of our learned dictionaries was also more robust to the av ailable size of training data. At the same time, because our learned dictionaries are unions of polynomial matrix functions of the graph Laplacian, they can be efficiently stored and implemented in both centralized and distributed signal processing tasks. A C K N OW L E D G E M E N T S The authors would like to thank Prof. Dimitri V an De V ille for pro viding the brain data, Prof. Antonio Ortega, Prof. Pierre V anderghe ynst and Xiaowen Dong for their useful feedbacks about this work, and Giorgos Stathopoulos for helpful discussions about the optimization problem. A P P E N D I X A The optimization problem (12) is a quadratic program as it consists of a quadratic objecti ve function and a set of affine constraints. In particular , using (4), the objecti ve function can be written as || Y − D X || 2 F + µ k α k 2 2 = N X n =1 M X m =1 ( Y − D X ) 2 nm + µα T α = N X n =1 M X m =1 Y − S X s =1 K X k =0 α sk L k X s ! 2 nm + µα T α, (14) where X s ∈ R N × M denotes the rows of the matrix X corresponding to the atoms in the subdictionary D s . Let us define the column vector P s nm ∈ R ( K +1) as P s nm = [( L 0 ) ( n, :) X s (: ,m ) ; ( L 1 ) ( n, :) X s (: ,m ) ; ... ; ( L K ) ( n, :) X s (: ,m ) ] , where ( L k ) ( n, :) is the n th ro w of the k th po wer of the Laplacian matrix and X s (: ,m ) is the m th column of the matrix X s . W e then stack these column vectors into the column vector P nm ∈ R S ( K +1) , which is defined as P nm = [ P 1 nm ; P 2 nm ; ... ; P S nm ] . Using this definition of P nm , (14) can be written as || Y − D X || 2 F + µ k α k 2 2 = N X n =1 M X m =1 ( Y nm − P T nm α ) 2 + µα T α = N X n =1 M X m =1 Y 2 nm − 2 Y nm P T nm α + α T P nm P T nm α + µα T α = k Y k 2 F − 2 N X n =1 M X m =1 Y nm P T nm ! α + α T N X n =1 M X m =1 P nm P T nm + µI S ( K +1) ! α, January 15, 2014 DRAFT 26 where I S ( K +1) is the S ( K + 1) × S ( K + 1) identity matrix. The matrix P N n =1 P M m =1 P nm P T nm + µI is positi ve semidefinite, which implies that our objecti ve is quadratic. Finally , the optimization constraints can be expressed as af fine functions with 0 ≤ I S ⊗ B α ≤ c 1 and ( c − ) 1 ≤ 1 T ⊗ B α ≤ ( c + ) 1 , where the inequalities are component-wise inequalities, 1 is the vector of ones, I S is the S × S identity matrix, and B is the V andermonde matrix B = 1 λ 0 λ 2 0 . . . λ K 0 1 λ 1 λ 2 1 . . . λ K 1 . . . . . . . . . 1 λ N − 1 λ 2 N − 1 . . . λ K N − 1 . Thus, the optimization problem is quadratic and it can be solved ef ficiently . R E F E R E N C E S [1] D. I Shuman, S. K. Narang, P . Frossard, A. Ortega, and P . V ander gheynst, “The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains, ” IEEE Signal Pr ocess. Mag . , vol. 30, no. 3, pp. 83–98, May 2013. [2] R. Rubinstein, A. M. Bruckstein, and M. Elad, “Dictionaries for sparse representation modeling, ” Proc. of the IEEE , vol. 98, no. 6, pp. 1045 –1057, Apr . 2010. [3] M. Aharon, M. Elad, and A. Bruckstein, “K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation, ” IEEE T rans. Signal Process. , vol. 54, no. 11, pp. 4311–4322, 2006. [4] K. Engan, S. O. Aase, and J. H. Husoy , “ Method of optimal directions for frame design, ” in Pr oc. IEEE Int. Conf. Acc., Speech, and Signal Pr ocess. , W ashington, DC, USA, 1999, vol. 5, pp. 2443–2446. [5] S. Mallat, A W avelet T our of Signal Processing: The Sparse W ay , Academic Press, 3rd edition, 2008. [6] P . Jost, P . V ander gheynst, S. Lesage, and R. Gribon val, “Motif: An efficient algorithm for learning translation in variant dictionaries, ” in Pr oc. IEEE Int. Conf. Acc., Speech, and Signal Pr ocess. , T oulouse, France, 2006, vol. 5, pp. 857–860. [7] M. Y aghoobi, L. Daudet, and M. E. Davies, “Parametric dictionary design for sparse coding, ” IEEE T rans. Signal Pr ocess. , vol. 57, no. 12, pp. 4800–4810, Dec. 2009. [8] R. Rubinstein, M. Zibule vsky , and M. Elad, “Double sparsity: learning sparse dictionaries for sparse signal approximation, ” IEEE T rans. Signal Pr ocess. , vol. 58, no. 3, pp. 1553–1564, 2010. [9] D. Thanou, D. I Shuman, and P . Frossard, “Parametric dictionary learning for graph signals, ” in Pr oc. IEEE Glob . Conf. Signal and Inform. Pr ocess. , Austin, T exas, Dec. 2013. [10] D. Hammond, P . V andergheynst, and R. Gribon val, “W avelets on graphs via spectral graph theory , ” Appl. Comput. Harmon. Anal. , vol. 30, no. 2, pp. 129–150, March 2010. January 15, 2014 DRAFT 27 [11] X. Zhu and M. Rabbat, “ Approximating signals supported on graphs, ” in Pr oc. IEEE Int. Conf . Acc., Speech, and Signal Pr ocess. , K yoto, Japan, Mar . 2012, pp. 3921–3924. [12] R. R. Coifman and M. Maggioni, “Diffusion wav elets, ” Appl. Comput. Harmon. Anal. , vol. 21, pp. 53–94, March 2006. [13] S. K. Narang and A. Ortega, “Perfect reconstruction two-channel wav elet filter banks for graph structured data, ” IEEE T rans. Signal Process. , vol. 60, no. 6, pp. 2786–2799, June 2012. [14] D. I Shuman, B. Ricaud, and P . V anderghe ynst, “A windo wed graph Fourier transform, ” in Pr oc. IEEE Stat. Signal Pr ocess. Wkshp. , Michigan, Aug. 2012. [15] D. I Shuman, B. Ricaud, and P . V andergheynst, “V ertex-frequency analysis on graphs, ” submitted to Appl. Comput. Harmon. Anal. , July 2013. [16] D. I Shuman, Christoph W iesmeyr , Nicki Holighaus, and Pierre V anderghe ynst, “Spectrum-adapted tight graph wav elet and vertex-frequenc y frames, ” submitted to IEEE T rans. Signal Pr ocess. , Nov . 2013. [17] J. C. Bremer , R. R. Coifman, M. Maggioni, and A. D. Szlam, “Diffusion wav elet packets, ” Appl. Comput. Harmon. Anal. , vol. 21, no. 1, pp. 95–112, 2006. [18] R. M. Rustamov and L. Guibas, “W av elets on graphs via deep learning, ” in Advances in Neural Information Pr ocessing Systems (NIPS) , 2013. [19] X. Zhang, X. Dong, and P . Frossard, “Learning of structured graph dictionaries, ” in Proc. IEEE Int. Conf. Acc., Speech, and Signal Process. , Kyoto, Japan, Mar . 2012, pp. 3373 – 3376. [20] N. J. Higham, Functions of Matrices , Society for Industrial and Applied Mathematics, 2008. [21] M. Zheng, J. Bu, C. Chen, C. W ang, L. Zhang, G. Qiu, and D. Cai, “Graph regularized sparse coding for image representation, ” IEEE T rans. Image Pr ocess. , v ol. 20, no. 5, pp. 1327–1336, May 2011. [22] F . Chung, Spectral Graph Theory , American Mathematical Society , 1997. [23] J. A. Tropp, “Greed is good: Algorithmic results for sparse approximation, ” IEEE T rans. Inform. Theory , vol. 50, no. 10, pp. 2231–2242, 2004. [24] M. Bruckstein, D. Donoho, and M. Elad, “From sparse solutions of systems of equations to sparse modeling of signals and images, ” SIAM Rev . , v ol. 51, no. 1, pp. 34–81, Feb . 2009. [25] M. Elad, Sparse and Redundant Representations - F rom Theory to Applications in Signal and Image Pr ocessing , Springer, 2010. [26] S. Boyd and L. V andenberghe, Con vex Optimization , New Y ork: Cambridge Uni versity Press, 2004. [27] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed optimization and statistical learning via the alternating direction method of multipliers, ” F oundations and T r ends in Mac hine Learning , v ol. 3, no. 1, pp. 1–122, 2011. [28] K.C. T oh, M.J. T odd, and R.H. Tutuncu, “SDPT3 — a MA TLAB software package for semidefinite programming, ” in Optimization Methods and Softwar e , 1999, v ol. 11, pp. 545–581. [29] J. Lofber g, “Y ALMIP: A toolbox for modeling and optimization in MA TLAB, ” in Pr oc. CA CSD Conf . , T aipei, T aiwan, 2004. [30] X. Dong, A. Ortega, P . Frossard, and P . V andergheynst, “Inference of mobility patterns via spectral graph w avelets, ” in Pr oc. IEEE Int. Conf. Acc., Speech, and Signal Process. , V ancouver , Canada, May 2013. [31] T . Choe, A. Skabardonis, and P . P . V araiya, “Freeway performance measurement system (PeMS): an operational analysis tool, ” in Pr esented at Annual Meeting of T ransportation Resear ch Boar d , W ashington, DC, USA, Jan. 2002. [32] H. Eryilmaz, D. V an De V ille, S. Schwartz, and P . V uilleumier, “Impact of transient emotions on functional connectivity during subsequent resting state: A wa velet correlation approach, ” Neur oImage , vol. 54, no. 3, pp. 2481–2491, 2011. January 15, 2014 DRAFT 28 [33] J. Richiardi, H. Eryilmaz, S. Schwartz, P . V uilleumier, and D. V an De V ille, “Decoding brain states from fMRI connectivity graphs, ” Neur oImage , vol. 56, no. 2, pp. 616–626, 2011. [34] I. Daubechies, M. Defrise, and C. De Mol, “ An iterativ e thresholding algorithm for linear inv erse problems with a sparsity constraint, ” Commun. Pur e Appl. Math. , vol. 57, no. 11, pp. 1413–1457, Nov . 2004. [35] R. Tibshirani, “Regression shrinkage and selection via the lasso, ” J . R. Stat. Soc. Ser . B , vol. 58, pp. 267–288, 1994. [36] D. I Shuman, P . V andergheynst, and P . Frossard, “Chebyshev polynomial approximation for distributed signal processing, ” in Pr oc. Int. Conf . Distr . Comput. Sensor Sys. , Barcelona, Spain, June 2011. January 15, 2014 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment