Semi-Stochastic Gradient Descent Methods
In this paper we study the problem of minimizing the average of a large number ($n$) of smooth convex loss functions. We propose a new method, S2GD (Semi-Stochastic Gradient Descent), which runs for one or several epochs in each of which a single ful…
Authors: Jakub Konev{c}ny, Peter Richtarik
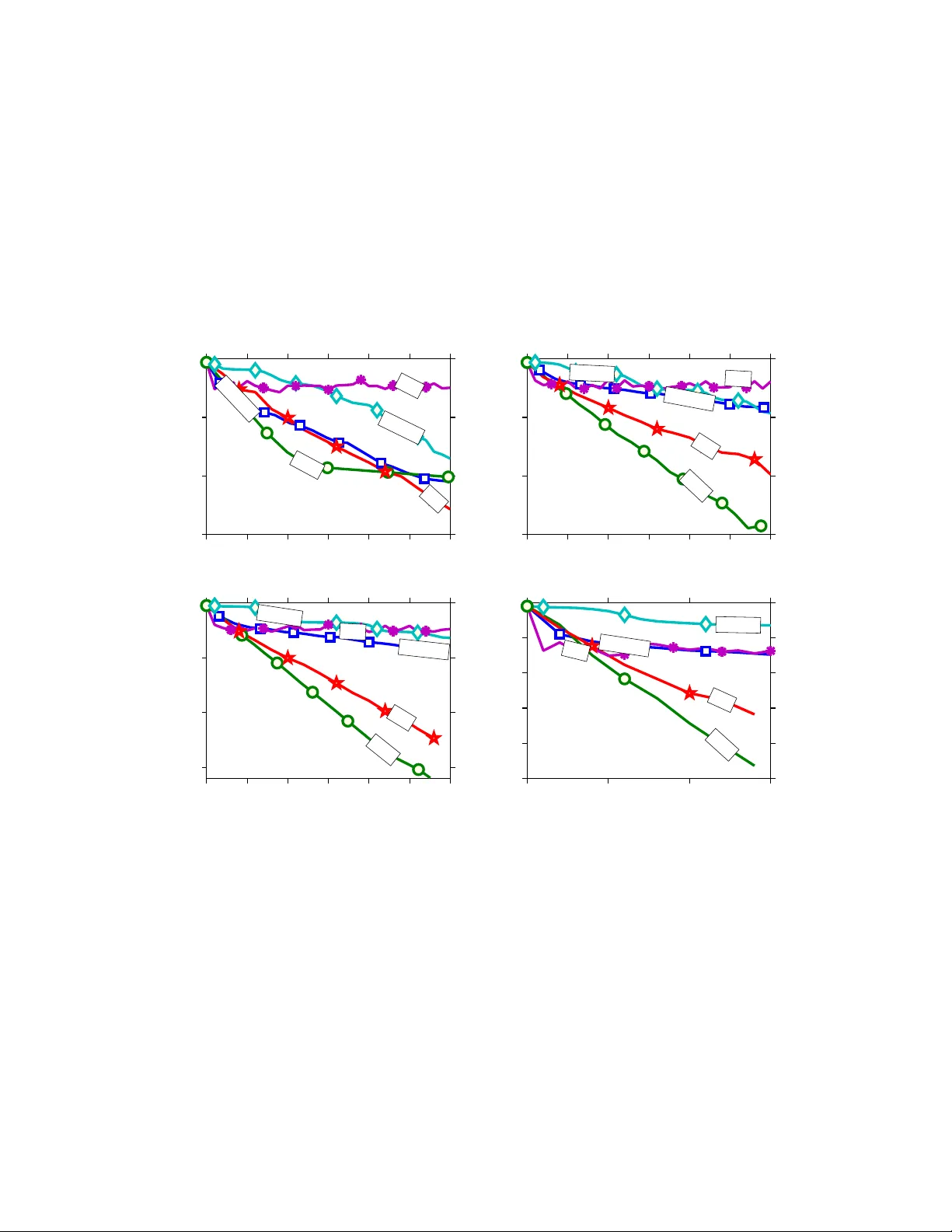
Semi-Sto c hastic Gradien t Descen t Metho ds Jakub Kone ˇ cn´ y ∗ P eter Rich t´ arik † Scho ol of Mathematics University of Edinbur gh Unite d Kingdom June 15, 2015 (first v ersion: Abstract In this pap er w e study the problem of minimizing the a verage of a large n um b er ( n ) of smo oth con vex loss functions. W e prop ose a new metho d, S2GD (Semi-Sto c hastic Gradient Descent), whic h runs for one or several ep ochs in each of whic h a single full gradient and a random num b er of sto c hastic gradients is computed, follo wing a geometric law. The total work needed for the metho d to output an ε -accurate solution in expectation, measured in the num b er of passes o ver data, or equiv alently , in units equiv alent to the computation of a single gradient of the empirical loss, is O (( n/κ ) log(1 /ε )), where κ is the condition num b er. This is ac hieved by running the metho d for O (log (1 /ε )) ep ochs, with a single gradient ev aluation and O ( κ ) sto c hastic gradien t ev aluations in eac h. The SVRG metho d of Johnson and Zhang [3] arises as a sp ecial case. If our method is limited to a single ep och only , it needs to ev aluate at most O (( κ/ε ) log(1 /ε )) sto c hastic gradien ts. In con trast, SVRG requires O ( κ/ε 2 ) stochastic gradients. T o illustrate our theoretical results, S2GD only needs the workload equiv alen t to ab out 2.1 full gradient ev aluations to find an 10 − 6 -accurate solution for a problem with n = 10 9 and κ = 10 3 . 1 In tro duction Man y problems in data science (e.g., machine learning, optimization and statistics) can b e cast as loss minimization problems of the form min x ∈ R d f ( x ) , (1) where f ( x ) def = 1 n n X i =1 f i ( x ) . (2) ∗ Sc ho ol of Mathematics, The Univ ersit y of Edinburgh, United Kingdom (e-mail: J.Konecn y@sms.ed.ac.uk) † Sc ho ol of Mathematics, The Universit y of Edin burgh, United Kingdom (e-mail: p eter.ric h tarik@ed.ac.uk) The work of b oth authors was supp orted by the Centre for Numerical Algorithms and Intelligen t Softw are (funded b y EPSRC grant EP/G036136/1 and the Scottish F unding Council). Both authors also thank the Simons Institute for the Theory of Computing, UC Berkeley , where this work was conceived and finalized. The work of P .R. was also supp orted b y the EPSRC grant EP/I017127/1 (Mathematics for V ast Digital Resources) and EPSRC grant EP/K02325X/1 (Accelerated Co ordinate Descent Metho ds for Big Data Problems). 1 Here d typically denotes the num ber of features / co ordinates, n the num ber of examples, and f i ( x ) is the loss incurred on example i . That is, w e are seeking to find a predictor x ∈ R d minimizing the a verage loss f ( x ). In big data applications, n is typically very large; in particular, n d . Note that this formulation includes more t ypical form ulation of L 2-regularized ob jectives — f ( x ) = 1 n P n i =1 ˜ f i ( x ) + λ 2 k x k 2 . W e hide the regularizer into the function f i ( x ) for the sake of simplicit y of resulting analysis. 1.1 Motiv ation Let us no w briefly review tw o basic approaches to solving problem (1). 1. Gr adient Desc ent. Given x k ∈ R d , the gradien t descent (GD) metho d sets x k +1 = x k − hf 0 ( x k ) , where h is a stepsize parameter and f 0 ( x k ) is the gradient of f at x k . W e will refer to f 0 ( x ) b y the name ful l gr adient . In order to compute f 0 ( x k ), we need to compute the gradients of n functions. Since n is big, it is prohibitive to do this at every iteration. 2. Sto chastic Gr adient Desc ent (SGD). Unlike gradient descent, sto c hastic gradient descen t [6, 17] instead pic ks a random i (uniformly) and up dates x k +1 = x k − hf 0 i ( x k ) . Note that this strategy drastically reduces the amount of work that needs to b e done in each iteration (b y the factor of n ). Since E ( f 0 i ( x k )) = f 0 ( x k ) , w e ha ve an un biased estimator of the full gradient. Hence, the gradien ts of the comp onen t functions f 1 , . . . , f n will b e referred to as sto chastic gr adients . A practical issue with SGD is that consecutiv e sto c hastic gradien ts may v ary a lot or even p oin t in opposite directions. This slows do wn the p erformance of SGD. On balance, how ev er, SGD is preferable to GD in applications where low accuracy solutions are sufficien t. In such cases usually only a small n umber of passes through the data (i.e., w ork equiv alent to a small num b er of full gradient ev aluations) are needed to find an acceptable x . F or this reason, SGD is extremely p opular in fields suc h as machine learning. In order to improv e up on GD, one needs to reduce the cost of computing a gradient. In order to impro ve up on SGD, one has to reduce the v ariance of the sto c hastic gradients. In this pap er we prop ose and analyze a Semi-Sto chastic Gr adient Desc ent (S2GD) metho d. Our metho d combines GD and SGD steps and reaps the b enefits of b oth algorithms: it inherits the stability and sp eed of GD and at the same time retains the w ork-efficiency of SGD. 1.2 Brief literature review Sev eral recen t papers, e.g., Rich t´ arik & T ak´ a ˇ c [8], Le Roux, Sc hmidt & Bach [11, 12], Shalev- Sh wartz & Zhang [13] and Johnson & Zhang [3] prop osed metho ds whic h achiev e such a v ariance- reduction effect, directly or indirectly . These metho ds enjoy linear conv ergence rates when applied to minimizing smo oth strongly conv ex loss functions. 2 The metho d in [8] is known as Random Co ordinate Descent for Comp osite functions (RCDC), and can b e either applied directly to (1)—in which case a single iteration requires O ( n ) w ork for a dense problem, and O ( d log (1 /ε )) iterations in total—or to a dual version of (1), which requires O ( d ) w ork p er iteration and O (( n + κ ) log (1 /ε )) iterations in total. Application of a co ordinate descen t metho d to a dual formulation of (1) is generally referred to as Sto c hastic Dual Co ordinate Ascen t (SDCA) [2]. The algorithm in [13] exhibits this duality , and the metho d in [14] extends the primal-dual framework to the parallel / mini-batc h setting. P arallel and distributed sto ch astic co ordinate descent metho ds were studied in [9, 1, 10]. Sto c hastic Average Gradien t (SAG) [11] is one of the first SGD-type metho ds, other than co ordinate descen t metho ds, which w ere shown to exhibit linear conv ergence. The metho d of Johnson and Zhang [3], called Sto c hastic V ariance Reduced Gradient (SVRG), arises as a special case in our setting for a sub optimal c hoice of a single parameter of our metho d. The Ep och Mixed Gradien t Descen t (EMGD) method [16] is similar in spirit to SVR G, but achiev es a quadratic dep endence on the condition n umber instead of a linear dependence, as is the case with SA G, SVR G and with our metho d. F or classical w ork on semi-stochastic gradien t descen t metho ds w e refer 1 the reader to the pap ers of Murti and F uc hs [4, 5]. 1.3 Outline W e start in Section 2 by describing tw o algorithms: S2GD, which w e analyze, and S2GD+, whic h we do not analyze, but whic h exhibits superior p erformance in practice. W e then mo v e to summarizing some of the main con tributions of this pap er in Section 3. Section 4 is dev oted to establishing exp ectation and high probability complexity results for S2GD in the case of a strongly con v ex loss. The results are generic in that the parameters of the method are set arbitrarily . Hence, in Section 5 we study the problem of choosing the parameters optimally , with the goal of minimizing the total workload (# of pro cessed examples) sufficient to produce a result of sufficient accuracy . In Section 6 we establish high probability complexity b ounds for S2GD applied to a non-strongly con vex loss function. Finally , in Section 7 we p erform very encouraging numerical exp erimen ts on real and artificial problem instances. A brief conclusion can b e found in Section 8. 2 Semi-Sto c hastic Gradien t Descen t In this section we describ e tw o nov el algorithms: S2GD and S2GD+. W e analyze the former only . The latter, ho wev er, has sup erior conv ergence prop erties in our exp erimen ts. W e assume throughout the pap er that the functions f i are con vex and L -smo oth. Assumption 1. The functions f 1 , . . . , f n have Lipschitz c ontinuous gr adients with c onstant L > 0 (in other wor ds, they ar e L -smo oth). That is, for al l x, z ∈ R d and al l i = 1 , 2 , . . . , n , f i ( z ) ≤ f i ( x ) + h f 0 i ( x ) , z − x i + L 2 k z − x k 2 . (This implies that the gr adient of f is Lipschitz with c onstant L , and henc e f satisfies the same ine quality.) 1 W e thank Zaid Harchaoui who p oin ted us to these pap ers a few days b efore we p osted our work to arXiv. 3 In one part of the pap er (Section 4) we also make the follo wing additional assumption: Assumption 2. The aver age loss f is µ -str ongly c onvex, µ > 0 . That is, for al l x, z ∈ R d , f ( z ) ≥ f ( x ) + h f 0 ( x ) , z − x i + µ 2 k z − x k 2 . (3) (Note that, ne c essarily, µ ≤ L .) 2.1 S2GD Algorithm 1 (S2GD) dep ends on three parameters: stepsize h , constant m limiting the num ber of sto c hastic gradients computed in a single ep o c h, and a ν ∈ [0 , µ ], where µ is the strong conv exit y constan t of f . In practice, ν would b e a known low er b ound on µ . Note that the algorithm w orks also without an y knowledge of the strong conv exit y parameter — the case of ν = 0. Algorithm 1 Semi-Sto c hastic Gradient Descent (S2GD) parameters: m = max # of sto c hastic steps p er ep och, h = stepsize, ν = low er b ound on µ for j = 0 , 1 , 2 , . . . do g j ← 1 n P n i =1 f 0 i ( x j ) y j, 0 ← x j Let t j ← t with probability (1 − ν h ) m − t /β for t = 1 , 2 , . . . , m for t = 0 to t j − 1 do Pic k i ∈ { 1 , 2 , . . . , n } , uniformly at random y j,t +1 ← y j,t − h ( g j + f 0 i ( y j,t ) − f 0 i ( x j )) end for x j +1 ← y j,t j end for The metho d has an outer loop, indexed by ep och coun ter j , and an inner lo op, indexed b y t . In each ep o c h j , the metho d first computes g j —the ful l gradient of f at x j . Subsequen tly , the metho d pro duces a random num b er t j ∈ [1 , m ] of steps, following a geometric law, where β def = m X t =1 (1 − ν h ) m − t , (4) with only two sto chastic gr adients computed in each step 2 . F or each t = 0 , . . . , t j − 1, the sto chastic gradien t f 0 i ( x j ) is subtracted from g j , and f 0 i ( y j,t − 1 ) is added to g j , whic h ensures that, one has E ( g j + f 0 i ( y j,t ) − f 0 i ( x j )) = f 0 ( y j,t ) , where the exp ectation is with resp ect to the random v ariable i . Hence, the algorithm is stochastic gradien t descen t – albeit executed in a nonstandard w a y (compared to the traditional implemen tation describ ed in the in tro duction). 2 It is p ossible to get aw ay with computinge only a single sto c hastic gradient p er inner iteration, namely f 0 i ( y j,t ), at the cost of having to store in memory f 0 i ( x j ) for i = 1 , 2 , . . . , n . This, how ever, will be impractical for big n . 4 Note that for all j , the exp ected n umber of iterations of the inner lo op, E ( t j ), is equal to ξ = ξ ( m, h ) def = m X t =1 t (1 − ν h ) m − t β . (5) Also note that ξ ∈ [ m +1 2 , m ), with the low er b ound attained for ν = 0, and the upp er bound for ν h → 1. 2.2 S2GD+ W e also implemen t Algorithm 2, which we call S2GD+. In our experiments, the performance of this metho d is sup erior to all metho ds we tested, including S2GD. How ev er, we do not analyze the complexit y of this metho d and leav e this as an op en problem. Algorithm 2 S2GD+ parameters: α ≥ 1 (e.g., α = 1) 1. Run SGD for a single pass ov er the data (i.e., n iterations); output x 2. Starting from x 0 = x , run a version of S2GD in which t j = αn for all j In brief, S2GD+ starts b y running SGD for 1 ep o c h (1 pass ov er the data) and then switches to a v arian t of S2GD in which the n um b er of the inner iterations, t j , is not random, but fixed to b e n or a small multiple of n . The motiv ation for this metho d is the following. It is common knowledge that SGD is able to progress muc h more in one pass ov er the data than GD (where this w ould corresp ond to a single gradien t step). How ev er, the very first step of S2GD is the computation of the full gradient of f . Hence, by starting with a single pass o ver data using SGD and then switc hing to S2GD, we obtain a sup erior metho d in practice. 3 3 Summary of Results In this section w e summarize some of the main results and contributions of this work. 1. Complexit y for strongly con vex f . If f is strongly conv ex, S2GD needs W = O (( n + κ ) log (1 /ε )) (6) w ork (measured as the total num b er of ev aluations of the sto chastic gradient, accounting for the full gradient ev aluations as well) to output an ε -appro ximate solution (in exp ectation or in high probabilit y), where κ = L/µ is the condition num b er. This is ac hieved by running S2GD with stepsize h = O (1 /L ), j = O (log(1 /ε )) ep o c hs (this is also equal to the num ber of full gradien t ev aluations) and m = O ( κ ) (this is also roughly equal to the n um b er of sto c hastic gradient ev aluations in a single ep o c h). The complexit y results are stated in detail in Sections 4 and 5 (see Theorems 4, 5 and 6; see also (27) and (26)). 3 Using a single pass of SGD as an initialization strategy was already considered in [11]. How ever, the authors claim that their implementation of v anilla SA G did not b enefit from it. S2GD does b enefit from suc h an initialization due to it starting, in theory , with a (heavy) full gradient computation. 5 2. Comparison with existing results. This complexit y result (6) matc hes the best-known results obtained for strongly conv ex losses in recent work such as [11], [3] and [16]. Our treatmen t is most closely related to [3], and contains their metho d (SVR G) as a sp ecial case. How ev er, our complexity results hav e b etter constan ts, whic h has a discernable effect in practice. In T able 1 w e compare our results in the strongly conv ex case with other existing results for differen t algorithms. Algorithm Complexit y/W ork Nestero v’s algorithm O ( √ κn log(1 /ε )) EMGD O ( n + κ 2 ) log(1 /ε ) SA G O ( n log(1 /ε )) SDCA O (( n + κ ) log(1 /ε )) SVR G O (( n + κ ) log (1 /ε )) S2GD O (( n + κ ) log(1 /ε )) T able 1: Comparison of p erformance of selected metho ds suitable for solving (1). The complex- it y/work is measured in the n umber of sto c hastic gradient ev aluations needed to find an ε -solution. W e should note that the rate of conv ergence of Nestero v’s algorithm [7] is a deterministic result. EMGD and S2GD results hold with high probability . The remaining results hold in exp ectation. Complexit y results for sto chastic co ordinate descent metho ds are also t ypically analyzed in the high probabilit y regime [8]. 3. Complexit y for conv ex f . If f is not strongly con vex, then we prop ose that S2GD be applied to a perturb ed version of the problem, with strong conv exit y constan t µ = O ( L/ε ). An ε -accurate solution of the original problem is reco vered with arbitrarily high probability (see Theorem 8 in Section 6). The total work in this case is W = O (( n + L/ε )) log (1 /ε )) , that is, ˜ O (1 / ), which is b etter than the standard rate of SGD. 4. Optimal parameters. W e deriv e form ulas for optimal parameters of the metho d which (appro ximately) minimize the total workload, measured in the n um b er of sto c hastic gradi- en ts computed (counting a single full gradient ev aluation as n ev aluations of the sto c hastic gradien t). In particular, we sho w that the metho d should be run for O (log(1 /ε )) ep ochs, with stepsize h = O (1 /L ) and m = O ( κ ). No such results were derived for SVRG in [3]. 5. One ep o c h. In the case when S2GD is run for 1 ep o c h only , effectively limiting the num b er of full gradient ev aluations to 1, w e show that S2GD with ν = µ needs O ( n + ( κ/ε ) log (1 /ε )) w ork only (see T able 2). This compares fa vorably with the optimal complexit y in the ν = 0 case (whic h reduces to SVRG), where the work needed is O ( n + κ/ε 2 ) . 6 F or tw o epo c hs one could just sa y that w e need √ ε decrease in iac h epo c h, thus ha ving complexit y of O ( n + ( κ/ √ ε ) log(1 / √ ε )). This is already b etter than general rate of SGD ( O (1 /ε )) . P arameters Metho d Complexit y ν = µ , j = O (log( 1 ε )) & m = O ( κ ) Optimal S2GD O (( n + κ ) log ( 1 ε )) m = 1 GD — ν = 0 SVR G [3] O (( n + κ ) log ( 1 ε )) ν = 0, j = 1, m = O ( κ ε 2 ) Optimal SVR G with 1 ep o c h O ( n + κ ε 2 ) ν = µ , j = 1, m = O ( κ ε log( 1 ε )) Optimal S2GD with 1 ep och O ( n + κ ε log( 1 ε )) T able 2: Summary of complexity results and sp ecial cases. Condition n umber: κ = L/µ if f is µ -strongly conv ex and κ = 2 L/ε if f is not strongly conv ex and ≤ L . 6. Sp ecial cases. GD and SVR G arise as sp ecial cases of S2GD, for m = 1 and ν = 0, resp ectiv ely . 4 7. Lo w memory requiremen ts. Note that SDCA and SAG, unlike SVRG and S2GD, need to store all gradients f 0 i (or dual v ariables) throughout the iterative pro cess. While this may not b e a problem for a mo dest sized optimization task, this requirement makes such metho ds less suitable for problems with v ery large n . 8. S2GD+. W e prop ose a “bo osted” v ersion of S2GD, called S2GD+, whic h w e do not analyze. In our experiments, how ev er, it performs v astly superior to all other methods w e tested, including GD, SGD, SA G and S2GD. S2GD alone is b etter than b oth GD and SGD if a highly accurate solution is required. The p erformance of S2GD and SAG is roughly comparable, ev en though in our exp erimen ts S2GD turned to hav e an edge. 4 Complexit y Analysis: Strongly Con v ex Loss F or the purp ose of the analysis, let F j,t def = σ ( x 1 , x 2 , . . . , x j ; y j, 1 , y j, 2 , . . . , y j,t ) (7) b e the σ -algebra generated by the relev ant history of S2GD. W e first isolate an auxiliary result. Lemma 3. Consider the S2GD algorithm. F or any fixe d ep o ch numb er j , the fol lowing identity holds: E ( f ( x j +1 )) = 1 β m X t =1 (1 − ν h ) m − t E ( f ( y j,t − 1 )) . (8) 4 While S2GD reduces to GD for m = 1, our analysis does not say an ything meaningful in the m = 1 case - it is to o coarse to cov er this case. This is also the reason b ehind the empty space in the “Complexity” b o x column for GD in T able 2. 7 Pr o of. By the tow er prop ert y of exp ectations and the definition of x j +1 in the algorithm, we obtain E ( f ( x j +1 )) = E ( E ( f ( x j +1 ) | F j,m )) = E m X t =1 (1 − ν h ) m − t β f ( y j,t − 1 ) ! = 1 β m X t =1 (1 − ν h ) m − t E ( f ( y j,t − 1 )) . W e now state and prov e the main result of this section. Theorem 4. L et Assumptions 1 and 2 b e satisfie d. Consider the S2GD algorithm applie d to solving pr oblem (1) . Cho ose 0 ≤ ν ≤ µ , 0 < h < 1 2 L , and let m b e sufficiently lar ge so that c def = (1 − ν h ) m β µh (1 − 2 Lh ) + 2( L − µ ) h 1 − 2 Lh < 1 . (9) Then we have the fol lowing c onver genc e in exp e ctation: E ( f ( x j ) − f ( x ∗ )) ≤ c j ( f ( x 0 ) − f ( x ∗ )) . (10) Before we pro ceed to proving the theorem, note that in the sp ecial cas e with ν = 0, we recov er the result of Johnson and Zhang [3] (with a minor improv emen t in the second term of c where L is replaced b y L − µ ), namely c = 1 µh (1 − 2 Lh ) m + 2( L − µ ) h 1 − 2 Lh . (11) If w e set ν = µ , then c can b e written in the form (see (4)) c = (1 − µh ) m (1 − (1 − µh ) m )(1 − 2 Lh ) + 2( L − µ ) h 1 − 2 Lh . (12) Clearly , the latter c is a ma jor improv ement on the former one. W e shall elaborate on this further later. Pr o of. It is w ell-known [7, Theorem 2.1.5] that since the functions f i are L -smooth, they necessarily satisfy the follo wing inequality: k f 0 i ( x ) − f 0 i ( x ∗ ) k 2 ≤ 2 L f i ( x ) − f i ( x ∗ ) − h f 0 i ( x ∗ ) , x − x ∗ i . By summing these inequalities for i = 1 , . . . , n , and using f 0 ( x ∗ ) = 0 , w e get 1 n n X i =1 k f 0 i ( x ) − f 0 i ( x ∗ ) k 2 ≤ 2 L f ( x ) − f ( x ∗ ) − h f 0 ( x ∗ ) , x − x ∗ i = 2 L ( f ( x ) − f ( x ∗ )) . (13) 8 Let G j,t def = g j + f 0 i ( y j,t − 1 ) − f 0 i ( x j ) be the direction of update at j th iteration in the outer loop and t th iteration in the inner lo op. T aking exp ectation with resp ect to i , conditioned on the σ -algebra F j,t − 1 (7), w e obtain 5 E k G j,t k 2 = E k f 0 i ( y j,t − 1 ) − f 0 i ( x ∗ ) − f 0 i ( x j ) + f 0 i ( x ∗ ) + g j k 2 ≤ 2 E k f 0 i ( y j,t − 1 ) − f 0 i ( x ∗ ) k 2 + 2 E k f 0 i ( x j ) − f 0 i ( x ∗ ) − f 0 ( x j ) k 2 = 2 E k f 0 i ( y j,t − 1 ) − f 0 i ( x ∗ ) k 2 +2 E k f 0 i ( x j ) − f 0 i ( x ∗ ) k 2 − 4 E f 0 ( x j ) , f 0 i ( x j ) − f 0 i ( x ∗ ) + 2 k f 0 ( x j ) k 2 (13) ≤ 4 L [ f ( y j,t − 1 ) − f ( x ∗ ) + f ( x j ) − f ( x ∗ )] − 2 k f 0 ( x j ) k 2 − 4 h f 0 ( x j ) , f 0 ( x ∗ ) i (3) ≤ 4 L [ f ( y j,t − 1 ) − f ( x ∗ )] + 4( L − µ ) [ f ( x j ) − f ( x ∗ )] . (14) Ab o v e we hav e used the b ound k x 0 + x 00 k 2 ≤ 2 k x 0 k 2 + 2 k x 00 k 2 and the fact that E ( G j,t | F j,t − 1 ) = f 0 ( y j,t − 1 ) . (15) W e no w study the exp ected distance to the optimal solution (a standard approac h in the analysis of gradien t metho ds): E ( k y j,t − x ∗ k 2 | F j,t − 1 ) = k y j,t − 1 − x ∗ k 2 − 2 h h E ( G j,t | F j,t − 1 ) , y j,t − 1 − x ∗ i + h 2 E ( k G j,t k 2 | F j,t − 1 ) (14)+(15) ≤ k y j,t − 1 − x ∗ k 2 − 2 h h f 0 ( y j,t − 1 ) , y j,t − 1 − x ∗ i +4 Lh 2 [ f ( y j,t − 1 ) − f ( x ∗ )] + 4( L − µ ) h 2 [ f ( x j ) − f ( x ∗ )] (3) ≤ k y j,t − 1 − x ∗ k 2 − 2 h [ f ( y j,t − 1 ) − f ( x ∗ )] − ν h k y j,t − 1 − x ∗ k 2 +4 Lh 2 [ f ( y j,t − 1 ) − f ( x ∗ )] + 4( L − µ ) h 2 [ f ( x j ) − f ( x ∗ )] = (1 − ν h ) k y j,t − 1 − x ∗ k 2 − 2 h (1 − 2 Lh )[ f ( y j,t − 1 ) − f ( x ∗ )] +4( L − µ ) h 2 [ f ( x j ) − f ( x ∗ )] . (16) By rearranging the terms in (16) and taking exp ectation ov er the σ -algebra F j,t − 1 , we get the follo wing inequality: E ( k y j,t − x ∗ k 2 ) + 2 h (1 − 2 Lh ) E ( f ( y j,t − 1 ) − f ( x ∗ )) ≤ (1 − ν h ) E ( k y j,t − 1 − x ∗ k 2 ) + 4( L − µ ) h 2 E ( f ( x j ) − f ( x ∗ )) . (17) Finally , we can analyze what happens after one iteration of the outer lo op of S2GD, i.e., betw een t wo computations of the full gradient. By summing up inequalities (17) for t = 1 , . . . , m , with inequalit y t multiplied by (1 − ν h ) m − t , w e get the left-hand side LH S = E ( k y j,m − x ∗ k 2 ) + 2 h (1 − 2 Lh ) m X t =1 (1 − ν h ) m − t E ( f ( y j,t − 1 ) − f ( x ∗ )) (8) = E ( k y j,m − x ∗ k 2 ) + 2 β h (1 − 2 Lh ) E ( f ( x j +1 ) − f ( x ∗ )) , 5 F or simplicit y , we supress the E ( · | F j,t − 1 ) notation here. 9 and the righ t-hand side RH S = (1 − ν h ) m E ( k x j − x ∗ k 2 ) + 4 β ( L − µ ) h 2 E ( f ( x j ) − f ( x ∗ )) (3) ≤ 2(1 − ν h ) m µ E ( f ( x j ) − f ( x ∗ )) + 4 β ( L − µ ) h 2 E ( f ( x j ) − f ( x ∗ )) = 2 (1 − ν h ) m µ + 2 β ( L − µ ) h 2 E ( f ( x j ) − f ( x ∗ )) . Since LH S ≤ R H S , w e finally conclude with E ( f ( x j +1 ) − f ( x ∗ )) ≤ c E ( f ( x j ) − f ( x ∗ )) − E ( k y j,m − x ∗ k 2 ) 2 β h (1 − 2 Lh ) ≤ c E ( f ( x j ) − f ( x ∗ )) . Since we ha ve established linear con v ergence of exp ected v alues, a high probability result can b e obtained in a straightforw ard wa y using Mark ov inequality . Theorem 5. Consider the setting of The or em 4. Then, for any 0 < ρ < 1 , 0 < ε < 1 and j ≥ log 1 ερ log 1 c , (18) we have P f ( x j ) − f ( x ∗ ) f ( x 0 ) − f ( x ∗ ) ≤ ε ≥ 1 − ρ. (19) Pr o of. This follows directly from Marko v inequality and Theorem 4: P ( f ( x j ) − f ( x ∗ ) > ε ( f ( x 0 ) − f ( x ∗ )) (10) ≤ E ( f ( x j ) − f ( x ∗ )) ε ( f ( x 0 ) − f ( x ∗ )) ≤ c j ε (18) ≤ ρ This result will b e also useful when treating the non-strongly conv ex case. 5 Optimal Choice of Parameters The goal of this section is to pro vide insigh t into the choice of parameters of S2GD; that is, the n umber of ep o c hs (equiv alen tly , full gradient ev aluations) j , the maximal num b er of steps in eac h ep och m , and the stepsize h . The remaining parameters ( L, µ, n ) are inherent in the problem and w e will hence treat them in this section as given. In particular, ideally w e wish to find parameters j , m and h solving the follo wing optimization problem: min j,m,h ˜ W ( j, m, h ) def = j ( n + 2 ξ ( m, h )) , (20) sub ject to E ( f ( x j ) − f ( x ∗ )) ≤ ε ( f ( x 0 ) − f ( x ∗ )) . (21) 10 Note that ˜ W ( j, m, h ) is the exp e cte d work , measured b y the n umber num b er of sto c hastic gradient ev aluations, p erformed by S2GD when running for j ep ochs. Indeed, the ev aluation of g j is equiv- alen t to n stochastic gradien t ev aluations, and each ep o c h further computes on av erage 2 ξ ( m, h ) sto c hastic gradients (see (5)). Since m +1 2 ≤ ξ ( m, h ) < m , w e can simplify and solv e the problem with ξ set to the conserv ative upp er estimate ξ = m . In view of (10), accuracy constrain t (21) is satisfied if c (whic h depends on h and m ) and j satisfy c j ≤ ε. (22) W e therefore instead consider the parameter fine-tuning problem min j,m,h W ( j, m, h ) def = j ( n + 2 m ) sub ject to c ≤ ε 1 /j . (23) In the follo wing w e (approximately) solve this problem in t wo steps. First, we fix j and find (nearly) optimal h = h ( j ) and m = m ( j ). The problem reduces to minimizing m sub ject to c ≤ ε 1 /j b y fine-tuning h . While in the ν = 0 case it is p ossible to obtain closed form solution, this is not p ossible for ν > µ . Ho wev er, it is still p ossible to obtain a go od form ula for h ( j ) leading to expression for go od m ( j ) which dep ends on ε in the correct wa y . W e then plug the formula for m ( j ) obtained this wa y bac k into (23), and study the quantit y W ( j, m ( j ) , h ( j )) = j ( n + 2 m ( j )) as a function of j , ov er whic h we optimize optimize at the end. Theorem 6 (Choice of parameters) . Fix the numb er of ep o chs j ≥ 1 , err or toler anc e 0 < ε < 1 , and let ∆ = ε 1 /j . If we run S2GD with the stepsize h = h ( j ) def = 1 4 ∆ ( L − µ ) + 2 L (24) and m ≥ m ( j ) def = ( 4( κ − 1) ∆ + 2 κ log 2 ∆ + 2 κ − 1 κ − 1 , if ν = µ, 8( κ − 1) ∆ 2 + 8 κ ∆ + 2 κ 2 κ − 1 , if ν = 0 , (25) then E ( f ( x j ) − f ( x ∗ )) ≤ ε ( f ( x 0 ) − f ( x ∗ )) . In p articular, if we cho ose j ∗ = d log(1 /ε ) e , then 1 ∆ ≤ exp(1) , and henc e m ( j ∗ ) = O ( κ ) , le ading to the worklo ad W ( j ∗ , m ( j ∗ ) , h ( j ∗ )) = d log 1 ε e ( n + O ( κ )) = O ( n + κ ) log 1 ε . (26) Pr o of. W e only need to show that c ≤ ∆, where c is given by (12) for ν = µ and by (11) for ν = 0. W e denote the t wo summands in expressions for c as c 1 and c 2 . W e c ho ose the h and m so that b oth c 1 and c 2 are smaller than ∆ / 2, resulting in c 1 + c 2 = c ≤ ∆. The stepsize h is c hosen so that c 2 def = 2( L − µ ) h 1 − 2 Lh = ∆ 2 , and hence it only remains to v erify that c 1 = c − c 2 ≤ ∆ 2 . In the ν = 0 case, m ( j ) is c hosen so that c − c 2 = ∆ 2 . In the ν = µ case, c − c 2 = ∆ 2 holds for m = log 2 ∆ + 2 κ − 1 κ − 1 / log 1 1 − H , where 11 H = 4( κ − 1) ∆ + 2 κ − 1 . W e only need to observ e that c decreases as m increases, and apply the inequalit y log 1 1 − H ≥ H . W e now comment on the ab o ve result: 1. W orkload. Notice that for the choice of parameters j ∗ , h = h ( j ∗ ), m = m ( j ∗ ) and any ν ∈ [0 , µ ], the metho d needs log(1 /ε ) computations of the full gradien t (note this is indep enden t of κ ), and O ( κ log (1 /ε )) computations of the stochastic gradient. This result, and sp ecial cases thereof, are summarized in T able 2. 2. Simpler formulas for m . If κ ≥ 2, we can instead of (25) use the follo wing (slightly w orse but) simpler expressions for m ( j ), obtained from (25) by using the bounds 1 ≤ κ − 1, κ − 1 ≤ κ and ∆ < 1 in appropriate places (e.g., 8 κ ∆ < 8 κ ∆ 2 , κ κ − 1 ≤ 2 < 2 ∆ 2 ): m ≥ ˜ m ( j ) def = ( 6 κ ∆ log 5 ∆ , if ν = µ, 20 κ ∆ 2 , if ν = 0 . (27) 3. Optimal stepsize in the ν = 0 case. Theorem 6 do es not claim to hav e solved problem (23); the problem in general do es not hav e a closed form solution. How ever, in the ν = 0 case a closed-form form ula can easily b e obtained: h ( j ) = 1 4 ∆ ( L − µ ) + 4 L , m ≥ m ( j ) def = 8( κ − 1) ∆ 2 + 8 κ ∆ . (28) Indeed, for fixed j , (23) is equiv alent to finding h that minimizes m sub ject to the constrain t c ≤ ∆. In view of (11), this is equiv alent to searc hing for h > 0 maximizing the quadratic h → h (∆ − 2(∆ L + L − µ ) h ), which leads to (28). Note that both the stepsize h ( j ) and the resulting m ( j ) are sligh tly larger in Theorem 6 than in (28). This is b ecause in the theorem the stepsize w as for simplicity chosen to satisfy c 2 = ∆ 2 , and hence is (slightly) suboptimal. Nevertheless, the dep endence of m ( j ) on ∆ is of the correct (optimal) order in both cases. That is, m ( j ) = O κ ∆ log( 1 ∆ ) for ν = µ and m ( j ) = O κ ∆ 2 for ν = 0. 4. Stepsize c hoice. In cases when one do es not hav e a go od estimate of the strong con vexit y constan t µ to determine the stepsize via (24), one may choose sub optimal stepsize that do es not depend on µ and deriv e similar results to those ab ov e. F or instance, one may choose h = ∆ 6 L . In T able 3 w e pro vide comparison of w ork needed for small v alues of j , and differen t v alues of κ and ε. Note, for instance, that for any problem with n = 10 9 and κ = 10 3 , S2GD outputs a highly accurate solution ( ε = 10 − 6 ) in the amount of work equiv alen t to 2 . 12 ev aluations of the full gradien t of f ! 12 ε = 10 − 3 , κ = 10 3 j W µ ( j ) W 0 ( j ) 1 1.06n 17 . 0 n 2 2 . 00 n 2.03n 3 3 . 00 n 3 . 00 n 4 4 . 00 n 4 . 00 n 5 5 . 00 n 5 . 00 n ε = 10 − 6 , κ = 10 3 j W µ ( j ) W 0 ( j ) 1 116 n 10 7 n 2 2.12n 34 . 0 n 3 3 . 01 n 3.48n 4 4 . 00 n 4 . 06 n 5 5 . 00 n 5 . 02 n ε = 10 − 9 , κ = 10 3 j W µ ( j ) W 0 ( j ) 2 7 . 58 n 10 4 n 3 3.18n 51 . 0 n 4 4 . 03 n 6 . 03 n 5 5 . 01 n 5.32n 6 6 . 00 n 6 . 09 n ε = 10 − 3 , κ = 10 6 j W µ ( j ) W 0 ( j ) 2 4 . 14 n 35 . 0 n 3 3.77n 8 . 29 n 4 4 . 50 n 6.39n 5 5 . 41 n 6 . 60 n 6 6 . 37 n 7 . 28 n ε = 10 − 6 , κ = 10 6 j W µ ( j ) W 0 ( j ) 4 8 . 29 n 70 . 0 n 5 7.30n 26 . 3 n 6 7 . 55 n 16 . 5 n 8 9 . 01 n 12.7n 10 10 . 8 n 13 . 2 n ε = 10 − 9 , κ = 10 6 j W µ ( j ) W 0 ( j ) 5 17 . 3 n 328 n 8 10.9n 32 . 5 n 10 11 . 9 n 21 . 4 n 13 14 . 3 n 19.1n 20 21 . 0 n 23 . 5 n ε = 10 − 3 , κ = 10 9 j W µ ( j ) W 0 ( j ) 6 378 n 1293 n 8 358n 1063 n 11 376 n 1002n 15 426 n 1058 n 20 501 n 1190 n ε = 10 − 6 , κ = 10 9 j W µ ( j ) W 0 ( j ) 13 737 n 2409 n 16 717n 2126 n 19 727 n 2025 n 22 752 n 2005n 30 852 n 2116 n ε = 10 − 9 , κ = 10 9 j W µ ( j ) W 0 ( j ) 15 1251 n 4834 n 24 1076n 3189 n 30 1102 n 3018 n 32 1119 n 3008n 40 1210 n 3078 n T able 3: Comparison of work sufficient to solv e a problem with n = 10 9 , and v arious v alues of κ and ε . The w ork w as computed using form ula (23), with m ( j ) as in (27). The notation W ν ( j ) indicates what parameter ν w as used. 6 Complexit y Analysis: Con v ex Loss If f is conv ex but not strongly con v ex, we define ˆ f i ( x ) def = f i ( x ) + µ 2 k x − x 0 k 2 , for small enough µ > 0 (w e shall see b elo w how the choice of µ affects the results), and consider the p erturbed problem min x ∈ R d ˆ f ( x ) , (29) where ˆ f ( x ) def = 1 n n X i =1 ˆ f i ( x ) = f ( x ) + µ 2 k x − x 0 k 2 . (30) Note that ˆ f is µ -strongly conv ex and ( L + µ )-smooth. In particular, the theory developed in the previous section applies. W e prop ose that S2GD b e instead applied to the p erturb ed problem, and sho w that an appro ximate solution of (29) is also an approximate solution of (1) (we will assume that this problem has a minimizer). 13 Let ˆ x ∗ b e the (necessarily unique) solution of the p erturb ed problem (29). The following result describ es an imp ortan t connection b et ween the original problem and the p erturbed problem. Lemma 7. If ˆ x ∈ R d satisfies ˆ f ( ˆ x ) ≤ ˆ f ( ˆ x ∗ ) + δ , wher e δ > 0 , then f ( ˆ x ) ≤ f ( x ∗ ) + µ 2 k x 0 − x ∗ k 2 + δ. Pr o of. The statement is almost iden tical to Lemma 9 in [8]; its pro of follo ws the same steps with only minor adjustmen ts. W e are now ready to establish a complexity result for non-strongly conv ex losses. Theorem 8. L et Assumption 1 b e satisfie d. Cho ose µ > 0 , 0 ≤ ν ≤ µ , stepsize 0 < h < 1 2( L + µ ) , and let m b e sufficiently lar ge so that ˆ c def = (1 − ν h ) m β µh (1 − 2( L + µ ) h ) + 2 Lh 1 − 2( L + µ ) h < 1 . (31) Pick x 0 ∈ R d and let ˆ x 0 = x 0 , ˆ x 1 , . . . , ˆ x j b e the se quenc e of iter ates pr o duc e d by S2GD as applie d to pr oblem (29) . Then, for any 0 < ρ < 1 , 0 < ε < 1 and j ≥ log (1 / ( ερ )) log(1 / ˆ c ) , (32) we have P f ( ˆ x j ) − f ( x ∗ ) ≤ ε ( f ( x 0 ) − f ( x ∗ )) + µ 2 k x 0 − x ∗ k 2 ≥ 1 − ρ. (33) In p articular, if we cho ose µ = < L and p ar ameters j ∗ , h ( j ∗ ) , m ( j ∗ ) as in The or em 6, the amount of work p erforme d by S2GD to guar ante e (33) is W ( j ∗ , h ( j ∗ ) , m ( j ∗ )) = O ( n + L ε ) log( 1 ε ) , which c onsists of O ( 1 ε ) ful l gr adient evaluations and O ( L log( 1 ε )) sto chastic gr adient evaluations. Pr o of. W e first note that ˆ f ( ˆ x 0 ) − ˆ f ( ˆ x ∗ ) (30) = f ( ˆ x 0 ) − ˆ f ( ˆ x ∗ ) ≤ f ( ˆ x 0 ) − f ( ˆ x ∗ ) ≤ f ( x 0 ) − f ( x ∗ ) , (34) where the first inequality follows from f ≤ ˆ f , and the second one from optimality of x ∗ . Hence, by first applying Lemma 7 with ˆ x = ˆ x j and δ = ε ( f ( x 0 ) − f ( x ∗ )), and then Theorem 5, with c ← ˆ c , f ← ˆ f , x 0 ← ˆ x 0 , x ∗ ← ˆ x ∗ , w e obtain P f ( ˆ x j ) − f ( x ∗ ) ≤ δ + µ 2 k x 0 − x ∗ k 2 (Lemma 7) ≥ P ˆ f ( ˆ x j ) − ˆ f ( ˆ x ∗ ) ≤ δ (34) ≥ P ˆ f ( ˆ x j ) − ˆ f ( ˆ x ∗ ) ˆ f ( ˆ x 0 ) − ˆ f ( ˆ x ∗ ) ≤ ε ! (19) ≥ 1 − ρ. The second statement follo ws directly from the second part of Theorem 6 and the fact that the condition n umber of the p erturb ed problem is κ = L + ≤ 2 L . 14 7 Numerical Exp erimen ts In this section w e conduct computational experiments to illustrate some aspects of the performance of our algorithm. In Section 7.1 w e consider the least squares problem with syn thetic data to compare the practical p erformance and the theoretical b ound on conv ergence in exp ectations. W e demonstrate that for both SVRG and S2GD, the practical rate is substan tially b etter than the theoretical one. In Section 7.2 we explain an efficient wa y to implemen t the S2GD algorithm for sparse datasets. In Section 7.3 we compare the S2GD algorithm on several real datasets with other algorithms suitable for this task. W e also pro vide efficient implementation of the algorithm for the case of logistic regression in the MLOSS rep ository 6 . 7.1 Comparison with theory Figure 1 presen ts a comparison of the theoretical rate and practical performance on a larger problem with artificial data, with a condition num b er w e can con trol (and choose it to be p o or). In particular, w e consider the L2-regularized least squares with f i ( x ) = 1 2 ( a T i x − b i ) 2 + λ 2 k x k 2 , for some a i ∈ R d , b i ∈ R and λ > 0 is the regularization parameter. 0 5 10 15 20 25 30 35 40 10 −15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum ν = µ ; theory ν = µ ; practice ν = 0; theory ν = 0; practice Figure 1: Least squares with n = 10 5 , κ = 10 4 . Comparison of theoretical result and practical p erformance for cases ν = µ (full red line) and ν = 0 (dashed blue line). W e consider an instance with n = 100 , 000, d = 1 , 000 and κ = 10 , 000 . W e run the algorithm with b oth parameters ν = λ (our b est estimate of µ ) and ν = 0. Recall that the latter choice leads to the SVRG metho d of Johnson and Zhang [3]. W e chose parameters m and h as a (numerical) solution of the w ork-minimization problem (20), obtaining m = 261 , 063 and h = 1 / 11 . 4 L for ν = λ 6 http://mloss.org/software/view/556/ 15 and m = 426 , 660 and h = 1 / 12 . 7 L for ν = 0. The practical p erformance is obtained after a single run of the S2GD algorithm. The figure demonstrates linear conv ergence of S2GD in practice, with the con v ergence rate b eing significantly b etter than the already strong theoretical result. Recall that the bound is on the exp ected function v alues. W e can observe a rather strong conv ergence to machine precision in w ork equiv alen t to ev aluating the full gradient only 40 times. Needless to say , neither SGD nor GD ha ve such sp eed. Our metho d is also an improv emen t ov er [3], b oth in theory and practice. 7.2 Implemen tation for sparse data In our sparse implemen tation of Algorithm 1, described in this section and formally stated as Algorithm 3, w e make the following structural assumption: Assumption 9. The loss functions arise as the c omp osition of a univariate smo oth loss function φ i , and an inner pr o duct with a data p oint/example a i ∈ R d : f i ( x ) = φ i ( a T i x ) , i = 1 , 2 , . . . , n. In this c ase, f 0 i ( x ) = φ 0 i ( a T i x ) a i . This is the structure in man y cases of interest, including linear or logistic regression. A natural question one might wan t to ask is whether S2GD can b e implemented efficiently for sparse data. Let us first tak e a brief detour and lo ok at SGD, whic h p erforms iterations of the t yp e: x j +1 ← x j − hφ 0 i ( a T i x ) a i . (35) Let ω i b e the n um b er of nonzero features in example a i , i.e., ω i def = k a i k 0 ≤ d . Assuming that the computation of the deriv ative of the univ ariate function φ i tak es O (1) amount of w ork, the computation of ∇ f i ( x ) will take O ( ω i ) w ork. Hence, the up date step (35) will cost O ( ω i ), to o, whic h means the metho d can naturally sp eed up its iterations on sparse data. The situation is not as simple with S2GD, which for loss functions of the t yp e describ ed in Assumption 9 p erforms inner iterations as follows: y j,t +1 ← y j,t − h g j + φ 0 i ( a T i y j,t ) a i − φ 0 i ( a T i x j ) a i . (36) Indeed, note that g j = f 0 ( x j ) is in general be fully dense even for sparse data { a i } . As a consequence, the update in (36) migh t b e as costly as d operations, irrespective of the sparsity level ω i of the activ e example a i . Ho wev er, we can use the following “lazy/dela y ed” up date trick. W e split the up date to the y vector into tw o parts: immediate, and delay ed. Assume index i = i t w as chosen at inner iteration t . W e immediately p erform the up date ˜ y j,t +1 ← y j,t − h φ 0 i t ( a T i t y j,t ) − φ 0 i t ( a T i t x j ) a i t , whic h costs O ( a i t ). Note that we hav e not computed the y j,t +1 . How ev er, we “know” that y j,t +1 = ˜ y j,t +1 − hg j , 16 Algorithm 3 Semi-Sto c hastic Gradient Descent (S2GD) for sparse data, using “lazy” up dates parameters: m = max # of sto c hastic steps p er ep och, h = stepsize, ν = low er b ound on µ for j = 0 , 1 , 2 , . . . do g j ← 1 n P n i =1 f 0 i ( x j ) y j, 0 ← x j χ ( s ) ← 0 for s = 1 , 2 , . . . , d Store when a co ordinate was up dated last time Let t j ← t with probability (1 − ν h ) m − t /β for t = 1 , 2 , . . . , m for t = 0 to t j − 1 do Pic k i ∈ { 1 , 2 , . . . , n } , uniformly at random for s ∈ nnz( a i ) do y ( s ) j,t ← y ( s ) j,t − ( t − χ ( s ) ) hg ( s ) j Up date what will b e needed χ ( s ) = t end for y j,t +1 ← y j,t − h ( φ 0 i ( y j,t ) − φ 0 i ( x j )) a i A sparse up date end for for s = 1 to d do Finish all the “lazy” up dates y ( s ) j,t j ← y ( s ) j,t j − ( t j − χ ( s ) ) hg ( s ) j end for x j +1 ← y j,t j end for without ha ving to actually compute the difference. At the next iteration, we are supp osed to p erform up date (36) for i = i t +1 : y j,t +2 ← y j,t +1 − hg j − h φ 0 i t +1 ( a T i t +1 y j,t +1 ) − φ 0 i t +1 ( a T i t +1 x j ) a i t +1 . (37) Ho wev er, notice that we can’t compute φ 0 i t +1 ( a T i t +1 y j,t +1 ) (38) as we nev er computed y j,t +1 . How ev er, here lies the trick: as a i t +1 is sparse, we only need to know those co ordinates s of y j,t +1 for which a ( s ) i t +1 is nonzero. So, just b efore we compute the (sparse part of ) of the up date (37), we p erform the up date y ( s ) j,t +1 ← ˜ y ( s ) j,t +1 − hg ( s ) j for co ordinates s for which a ( s ) i t +1 is nonzero. This wa y we kno w that the inner pro duct app earing in (38) is computed correctly (despite the fact that y j,t +1 p oten tially is not!). In turn, this means that w e can compute the sparse part of the up date in (37). W e now con tin ue as b efore, again only computing ˜ y j,t +3 . Ho wev er, this time w e ha ve to be more careful as it is no longer true that y j,t +2 = ˜ y j,t +2 − hg j . W e need to remember, for each co ordinate s , the last iteration coun ter t for which a ( s ) i t 6 = 0. This w ay we will know how man y times did w e “forget” to apply the dense up date − hg ( s ) j . W e do it in a just-in-time fashion, just b efore it is needed. 17 Algorithm 3 (sparse S2GD) performs these lazy updates as described ab o v e. It produces exactly the same result as Algorithm 1 (S2GD), but is muc h more efficient for sparse data as iteration pic k- ing example i only costs O ( ω i ). This is done with a memory o verhead of only O ( d ) (as represented b y vector χ ∈ R d ). 7.3 Comparison with other metho ds The S2GD algorithm can b e applied to several classes of problems. W e p erform exp erimen ts on an imp ortan t and in many applications used L2-regularized logistic regression for binary classification on sev eral datasets. The functions f i in this case are: f i ( x ) = log 1 + exp l i a T i x + λ 2 k x k 2 , where l i is the lab el of i th training exapmle a i . In our exp erimen ts we set the regularization parameter λ = O (1 /n ) so that the condition n um b er κ = O ( n ), whic h is ab out the most ill- conditioned problem use d in practice. W e added a (regularized) bias term to all datasets. All the datasets we used, listed in T able 4, are freely a v ailable 7 b enc hmark binary classification datasets. Dataset T raining examples ( n ) V ariables ( d ) L µ κ ijcnn 49 990 23 1.23 1/ n 61 696 r cv1 20 242 47 237 0.50 1/ n 10 122 r e al-sim 72 309 20 959 0.50 1/ n 36 155 url 2 396 130 3 231 962 128.70 100/ n 3 084 052 T able 4: Datasets used in the exp erimen ts. In the exp erimen t, w e compared the following algorithms: • SGD: Sto chastic Gradient Descen t. After v arious exp erimen ts, we decided to use a v arian t with constan t step-size that gav e the b est practical p erformance in hindsight. • L-BF GS: A publicly-av ailable limited-memory quasi-Newton metho d that is suitable for broader classes of problems. W e used a p opular implementation by Mark Schmidt. 8 • SA G: Sto c hastic Average Gradien t [12]. This is the most imp ortant metho d to compare to, as it also ac hiev es linear con v ergence using only stochastic gradien t ev aluations. Although the metho ds has b een analysed for stepsize h = 1 / 16 L , w e experimented with v arious stepsizes and c hose the one that gav e the b est p erformance for each problem individually . • S2GDcon: The S2GD algorithm with conserv ativ e stepsize choice, i.e., following the theory . W e set m = O ( κ ) and h = 1 / 10 L , which is appro ximately the v alue y ou would get from Equation (24) • S2GD: The S2GD algorithm, with stepsize that gav e the b est p erformance in hindsigh t. 7 Av ailable at http://www.csie.n tu.edu.tw/ ∼ cjlin/libsvm tools/datasets/. 8 h ttp://www.di.ens.fr/ ∼ mschmidt/Soft ware/minF unc.html 18 Note that SAG needs to store n gradients in memory in order to run. In case of relativ ely simple functions, one can store only n scalars, as the gradien t of f i is alwa ys a multiple of a i . If w e are comparing with SAG, w e are implicitly assuming that our memory limitations allo w us to do so. Although not included in Algorithm 1, we could also store these gradients we used to compute the full gradient, whic h w ould mean w e w ould only hav e to compute a single stochastic gradient p er inner iteration (instead of tw o). W e plot the results of these metho ds, as applied to v arious different, in the Figure 2 for first 15-30 passes through the data (i.e., amoun t of work work equiv alen t to 15-30 full gradien t ev aluations). 0 5 10 15 20 25 30 10 −15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum S2GDcon S2GD SAG L−BFGS SGD 0 5 10 15 20 25 30 10 −15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum S2GDcon S2GD SAG L−BFGS SGD 0 5 10 15 20 25 30 10 −15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum S2GDcon S2GD SAG L−BFGS SGD 0 5 10 15 10 −10 10 −8 10 −6 10 −4 10 −2 10 0 Passes through Data Objective minus Optimum S2GDcon S2GD SAG L−BFGS SGD Figure 2: Practical p erformance for logistic regression and the follo wing datasets: ijcnn, r cv (first ro w), r e alsim, url (second row) There are several remarks we would like to make. First, our exp erimen ts confirm the insigh t from [12] that for this types of problems, reduced-v ariance metho ds consistently exhibit substan tially b etter p erformance than the p opular L-BFGS algorithm. The p erformance gap b et ween S2GDcon and S2GD differs from dataset to dataset. A p ossible explanation for this can be found in an extension of SVR G to pro ximal setting [15], released after the first version of this pap er w as put onto arXiv (i.e., after December 2013) . Instead Assumption 1, where all loss functions are assumed to be asso ciated with the same constant L , the authors of 19 Time in seconds Algorithm ijcnn r cv1 r e al-sim url S2GDcon 0.42 0.89 1.74 78.13 S2GD 0.51 0.98 1.65 85.17 SA G 0.64 1.23 2.64 98.73 L-BF GS 0.37 1.08 1.78 830.65 T able 5: Time required to pro duce plots in Figure 2. [15] instead assume that each loss function f i has its own constant L i . Subsequen tly , they sample prop ortionally to these quantities as opp osed to the uniform sampling. In our case, L = max i L i . This imp ortance sampling has an impact on the conv ergence: one gets dep endence on the av erage of the quan tities L i and not in their maximum. The num b er of passes through data seems a reasonable wa y to compare p erformance, but some algorithms could need more time to do the same amoun t of passes through data than others. In this sense, S2GD should b e in fact faster than SAG due to the follo wing prop erty . While SAG up dates the test point after eac h ev aluation of a stochastic gradient, S2GD does not alw a ys mak e the update — during the ev aluation of the full gradient. This claim is supp orted b y computational evidence: SA G needed ab out 10-30% more time than S2GD to do the same amoun t of passes through data. Finally , in T able 5 w e pro vide the time it took the algorithm to produce these plots on a desktop computer with In tel Core i7 3610QM pro cessor, with 2 × 4GB DDR3 1600 MHz memory . The n umber for L-BF GS at the url dataset is not represen tativ e, as the algorithm needed extra memory , whic h slightly exceeded the memory limit of our computer. 7.4 Bo osted v ariants of S2GD and SA G In this section w e study the practical p erformance of b o osted metho ds, namely S2GD+ (Algo- rithm 2) and v ariant of SAG suggested by its authors [12, Section 4.2]. SA G+ is a simple mo dification of SAG, where one do es not divide the sum of the sto c hastic gradien ts b y n , but b y the n umber of training examples seen during the run of the algorithm, whic h has the effect of pro ducing larger steps at the b eginning. The authors claim that this metho d p erformed b etter in practice than a hybrid SG/SA G algorithm. W e hav e observed that, in practice, starting SAG from a p oin t close to the optimum, leads to an initial “aw a y jump“. Ev entually , the metho d exhibits linear con vergence. In contrast, S2GD con verges linearly from the start, regardless of the starting p osition. Figure 3 shows that S2GD+ consistently improv es ov er S2GD, while SA G+ do es not improv e alw ays: sometimes it p erforms essen tially the same as SAG. Although S2GD+ is ov erall a sup erior algorithm, one should note that this comes at the cost of ha ving to choose stepsize parameter for SGD initialization. If one chooses these parameters p oorly , then S2GD+ could p erform worse than S2GD. The other three algorithms can w ork well without any parameter tuning. 8 Conclusion W e hav e developed a new semi-sto chastic gradien t descent metho d (S2GD) and analyzed its com- plexit y for smo oth conv ex and strongly conv ex loss functions. Our metho ds need O (( κ/n ) log (1 /ε )) 20 0 5 10 15 20 25 30 10 −15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum S2GD SAG S2GD+ SAG+ 0 5 10 15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum S2GD SAG S2GD+ SAG+ 0 5 10 15 20 25 30 10 −15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum S2GD SAG S2GD+ SAG+ 0 5 10 15 20 25 30 10 −15 10 −10 10 −5 10 0 Passes through Data Objective minus Optimum S2GD SAG S2GD+ SAG+ Figure 3: Practical p erformance of b o osted metho ds on datasets ijcnn, r cv (first row), r e alsim, url (second ro w) w ork only , measured in units equiv alent to the ev aluation of the full gradient of the loss function, where κ = L/µ if the loss is L -smo oth and µ -strongly con v ex, and κ ≤ 2 L/ε if the loss is merely L -smo oth. Our results in the strongly conv ex case matc h or impro ve on a few very recent results, while at the same time generalizing and simplifying the analysis. Additionally , we prop osed S2GD+ —a metho d which equips S2GD with an SGD pre-pro cessing step—whic h in our exp eriments exhibits sup erior p erformance to all metho ds we tested. W e leav e the analysis of this metho d as an op en problem. References [1] Olivier F erco q and Peter Ric h t´ arik. Smo oth min imization of nonsmooth functions with parallel co ordinate descent metho ds. , 2013. 21 [2] C-J. Hsieh, K-W. Chang, C-J. Lin, S.S. Keerthi, , and S. Sundara jan. A dual coordinate descen t metho d for large-scale linear SVM. In ICML , 2008. [3] Rie Johnson and T ong Zhang. Accelerating sto c hastic gradient descent using predictive v ari- ance reduction. In NIPS , 2013. [4] Kurt Marti and E. F uchs. On solutions of sto c hastic programming problems by descen t pro- cedures with sto c hastic and deterministic directions. Metho ds of Op er ations R ese ar ch , 33:281– 293, 1979. [5] Kurt Marti and E. F uchs. Rates of conv ergence of semi-sto c hastic appro ximation pro cedures for solving sto c hastic optimization problems. Optimization , 17(2):243–265, 1986. [6] Ark adi Nemirovski, Anatoli Juditsky , Guanghui Lan, and Alexander Shapiro. Robust sto c has- tic approximation approac h to sto chastic programming. SIAM Journal on Optimization , 19(4):1574–1609, 2009. [7] Y urii Nesterov. Intr o ductory le ctur es on c onvex optimization: A b asic c ourse , volume 87. Springer, 2004. [8] P eter Ric h t´ arik and Martin T ak´ a ˇ c. Iteration complexit y of randomized block-coordinate de- scen t metho ds for minimizing a comp osite function. Mathematic al Pr o gr amming , pages 1–38, 2012. [9] P eter Rich t´ arik and Martin T ak´ aˇ c. Parallel co ordinate descen t metho ds for big data optimiza- tion. , 2012. [10] P eter Rich t´ arik and Martin T ak´ a ˇ c. Distributed co ordinate descent metho d for learning with big data. , 2013. [11] Nicolas Le Roux, Mark Schmidt, and F rancis Bac h. A sto c hastic gradien t metho d with an exp onen tial con vergence rate for finite training sets. , 2012. [12] Mark Sc hmidt, Nicolas Le Roux, and F rancis Bach. Minimizing finite sums with the sto c hastic a verage gradient. , 2013. [13] Shai Shalev-Shw artz and T ong Zhang. Sto chastic dual co ordinate ascent metho ds for regular- ized loss minimization. , 2012. [14] Martin T ak´ a ˇ c, Avleen Bijral, Peter Rich t´ arik, and Nati Srebro. Mini-batc h primal and dual metho ds for SVMs. In ICML , 2013. [15] Lin Xiao and T ong Zhang. A pro ximal sto chastic gradien t metho d with progressive v ariance reduction. , 2014. [16] Lijun Zhang, Mehrdad Mahda vi, and Rong Jin. Linear con v ergence with condition n umber indep enden t access of full gradien ts. NIPS , 2013. [17] T ong Zhang. Solving large scale linear prediction problems using sto c hastic gradient descent algorithms. In ICML , 2004. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment