Parameters of the Menzerath-Altmann law: Statistical mechanical interpretation as applied to a linguistic organization
The distribution behavior dictated by the Menzerath-Altmann (MA) law is frequently encountered in linguistic and natural organizations at various structural levels. The mathematical form of this empirical law comprises three fitting parameters whose …
Authors: Sertac Eroglu
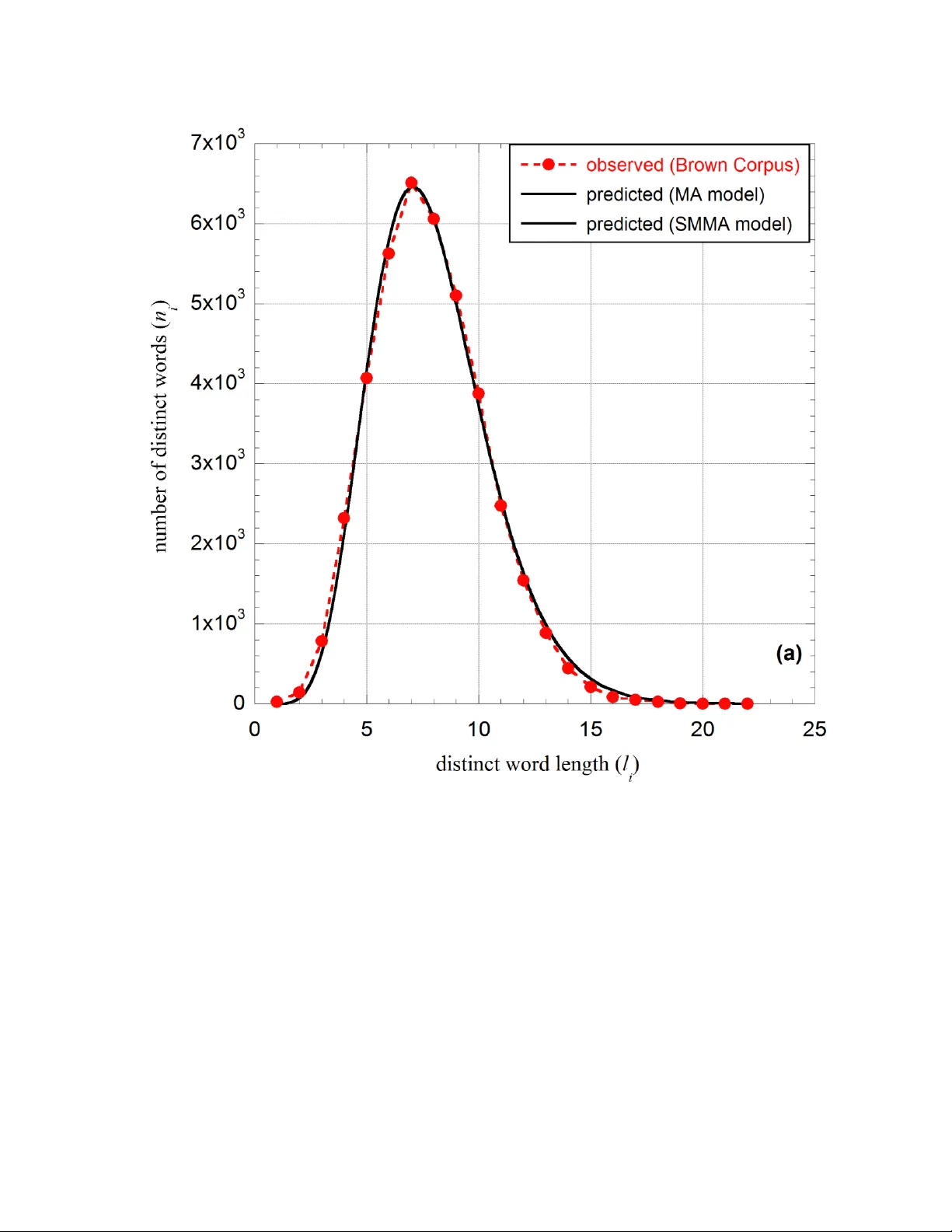
Parameters of the Menzerath-Altm ann l aw : Statistical m echanical interpr etat ion as applied to a lingui stic organization Sertac Eroglu Department of Physics, Eskisehir Osmangazi University, Meselik, 26480 Eskisehir, Turkey e-mail: seroglu@ogu.edu.tr (Dated: July 24, 2013) Submitted to: Physica A ABSTRACT The distribution behavior dictated b y the Menzerath-Altmann (MA) law is frequently encountered in linguistic and natural organizations at various structural levels. The mathematical form of this empirical law comprises three fitting parameters whose values tend to be elusive, especiall y in inter-organizational studies. To allow inte rpretation of these parameters and better understand such distribution behavior, we present a statistical mechanical approach based on an an alogy between the classical particles of a s tatistical mechanical organization and the number of distinct words in a textual organization. W ith this derivation, we ach ieve a transformed ( generalized) form of the MA model, termed the statistical mechanical Menzerath-Altmann (SMMA) model. This novel transformed model consists of four parameters, one of which is a structure-dependen t input parameter, and three o f which ar e free-fitting parameters. Using distinct word data sets from two text corpora, w e verified that the SMMA model describes the same distribution as the MA model. We propose that the additional structure-depe ndent parameter of the SMMA model converts the three fitti ng parameters into structure-independent parameter s. Moreov er, the parameters of the SMMA model are a ssociated with a corresponding physical interpretation that can lead t o characterization of an organization’s thermod ynamic properties. We also propose that man y organizations presenting MA law behavior, whether li nguistic or not, can be examined b y th e SMMA distribution model through the properl y defined structur al degeneracy parameter and the energy associated states. Keywords: Menzerath-Altmann law; power law with exponential cutoff; parameters of Menzerath- Altmann law; distinct word distribution; language 2 1. Introduction The Menzerath-Altmann ( MA ) law is one of the well-known stochastic laws in quantitative linguistics and has been considerably put into pr actice. Th e law p rincipally states that ‘ the longer the construct the shorter i ts constit uents ’ 1 . This general statement has been employed to measure regularities in the structural organization of many natural languages at various orga nizational levels, including phonemic, morphemic, s yntactic, and textual 2-5 . Furthermore, the extent of this distribution behavior is not limi ted to linguistic organizations, in fact, the MA law has also been shown to describe some quantifiable regularity in a variet y of semiotic and biologic organizations as well 6-12 . The familiar m athematical definition of the MA law which describes the dependence of a construct’s size (or length) y on its constituent’ s size (or length) x is given by 13 . b c x y x A x e (1 ) Here A , b and c are the model parameters. Eq. ( 1), power-law with exponential cutoff, should be viewed as a continuous distribution function of the structural or ganization under investigation, and the empirical parameter s are uniquely determine d for the best fit. Linguistic or not man y organizational construct s mostl y comprise discrete constituent sizes, i x , while it cannot be said the same for construct siz e (in some cases a mean size), y , which is not priory discrete but not trul y continuous . Using the MA law for the detection of regularities at the word length l evel has primarily been the attention of the correlation studi es between the length of the words oc curring in a text and the length frequenc y of each word’s constituents 14,16 . On the other hand, our recent stud y 17 3 reports that the length distribution of vocabulary 1 or distinct words (DWs) in a larg e text obeys the MA law distribution behavior. T his distribution be havior c an be translated as ‘the number of relatively short length DWs in a text increases when the tex t length increases’. The stud y specifically reveals that the MA law, a special case of gamma distribution function, is quite accurate in describing the DW length distribution, in letter count, in a large tex t. Hence, the MA law is more descriptive model than the familiar Heap’s law 18 ; i.e., ‘th e number of DWs increases with increasing text length’. Although the MA law is a well-recognized distribution model in the study of linguistics and naturally occurring phen omena that present language-like organizational behavior, yet, there is no convincing statis tical support for the law’s widespread validit y and the su bstantiated interpretation of its parameters. There have been n umerous attempts to elucidate the model parameters from a linguistics point of view b y using comparative parameter an alysis 19-20 ; however, the interpretation of the pa rameters is still controversial. This fa ct hampers research on two lev els ; firstly, the ability to reach decisive conclusions during comparative studies, i.e. between different organizational levels or between different source of organizations (e.g., l anguages), and secondly, the ability to reach a comprehensive understanding of organizational dyna mics. In turn, these drawbacks prevent realization of the full potential of the MA law. In an effort to estimate some thermodynamic pr operties of a li nguistic organization, several studies have proposed to im plement statistical mechanics tools to uncover th e fundamental regularities in linguistic organizations. Some of these studies 21, 23 simply mad e use of the universality of Maxwell - Boltzmann’s ex ponential term, B e xp k T E . Some other studi es 24, 25 , 1 Henceforth, w e will refer to vocab ulary of a text as distinct words ( DWs) for convenience. In general, DWs of a text can be considered as the set o f dissimilar co nstituents of a construct at the le vel of organization under i nvestigatio n. 4 on the other hand, have approached the p roblem from information content perspective by utilizing Shannon entrop y, lo g jj j H p p . All of t hese studies provide viable information for a given organization; however, due to varying structural properties it becomes intricate to relate the obtained thermodynamic properties of dissimilar structura l organizations. In this study, our objective is to present a theoretical framework fo r the derivation of the empirical MA dist ribution model from a statistical mec hanical perspective. The derived model wa s referred to as the statisti cal mechanical MA (SMM A) law. The stud y revealed that the constituent distribution of a ling uistic orga nization which is prese ntin g the MA law behavior can alternatively be described b y the SMMA law. We showed th e MA and SMMA laws are actually the same distribution functions having different sets of parameters. The derivation of the SMMA law wa s based on the analogy b etween the non-interacting classical particles of a statis tical mechanical organization and the DWs of a textual orga nization. Since the SMMA law was derived using th e description of the structural organization at the microscopic (constituent) level to obtain the organizational properties at the macroscopic (construct) level, t he p rocedure establishes a firm foundation for interpreting the derived model par ameters in terms of ph ysical concepts. We fina ll y proposed that if the structural organization under investigation (which could be from various disciplines) presents the MA law behavior, this same procedure can be implemented to characterize constituent diversity dynamics of that structural organization in terms of thermodynamic concepts. Th e paper is organized as follows: S ection 2 describes the derivation process of the MA law using statis tical mechanical concepts and tools. For the sake of co nsistency in notation, Section 2 includes a b rief statistic al mechanical description of the accessible states of a classic al particle system, and it is followed by the analogous tr eatment of the accessible states of DW s in a te xt . The assessment of the SM MA law, ph ysical interpretation of its paramete rs and a demonstrating study 5 are p resented in Section 3. Section 4 provides the concluding re marks of this stud y and the extent of the obtained results. 2. Physical analogy and the model derivation 2.1. Accessible microstates of a classical particle organization We start the derivation of the S MMA model by introducing a brief review of the familiar physical s ystem of classi cal, or Max well-Boltzmann, particles. Suppose that the total energy of the system is E, and the system contains the total of N non-interacting pa rticles, e.g., atoms, molecules or e lementary p articles. Further more, the particle s are disting uishable and they are distributed over a set of quantized energy levels 12 , , , k such that the energy of a particle at the i th energy state is i . Each energy state has an asso ciated degenerac y 12 , , , k g g g with a corresponding numbe r of occupation s 12 , , , k n n n . There are no restrictions as to the number of particles in any given state. The two r equirements th at are imposed on the number of occupations di stributed over the energy states are as follows: a) The total number of particles, N , is fixed: 12 . i i k N n n n n (2 ) b) The total energy, E , of the system is constant: 1 1 2 2 . ii i kk E n n n n (3 ) The average energy of this classical particle organization is 6 , i i i i Ep (4 ) where ii p is the probability of a particle bein g in the energ y state i . The probabilit y distribution of the particles is ex plored using combinato rial statistical mechanics analysis. The mul tinomial coefficient W that is the total number of ways i n which N distin guishable particles displa y ing a particular set of distribution i n is defined by 12 !! ! ! ! ! k i i i NN Wn n n n n (5 ) The disorder number is defined as the number of microstates available to a macrostate, or number of a ccessible mi crostates. If the energy states are not de generate, the disorder number is equal to W . However, i n general, the energy states contain associated degenericies, degenerate states are the states with the same energy, and then the disorder number is given by Ω ! ! i i n n i ii ii i g n W g N n (6 ) This is the general equation for the accessible microstates of a classical particle s ystem. In the fo llowing section w e aim to define the analogous accessible microstates definiti on for the DW s in a text. 2.2. Accessible microstates of a DW organization A tex t exhibits several levels of structural, s yntactic and semantic organization. We have to emphasize that the p resented procedure is applicable to many lin guistic or nonlinguistic 7 organization al levels which present th e MA law behavior. However, due to the concerns such as straightforward presentation of the derivation and assessment of the theor etical result with readil y available data; in this stud y , the tex tual organization level of interest is the simple structural letter- string organization of DW s in a text. Consider that we examine a large text, or corpus, t o increase the number an d variety of samples for statistical completeness, and s uppose the corpus contains a total number of N T words, N of which are distinct, i.e. distinguishable. Ac cording to the linguistic rules an d the desired information content to be transmitted, a particular text ’s words interact with each other in the word-string organization. If we consider the tex t at the level of DW organization, howeve r, there is no expli ci t association or regularity of DW s occurrence. This condition suggests that the DW s of a text present non-interacting behavior. Therefore, in our suggested ph ysical analogy, a corpus consisti ng of N number of DW s can be treated as a classical particle s ystem of N particles, in which each DW corresponds to a non-interacting and distinguishable particle of the system. The next step in treating a corpus as a classical particl e s y stem is to define the DW organization ’s energy states by equating word length with word energy; i.e. , the length of each word on the basis of letter count equals the word ’s ene rgy (o r effor t). Empirical observ ations have shown that human behavior, including articulatio n, tends to obey the prin ciple of least effort, for a straightforward reason: The longer the word the longer the time it takes to read, write and perceive that word. The p rinciple of least effort was ori ginally proposed by Zipf 26 , and recentl y a more direct connection be tween ene rgy and information theory has be en explored 27 . Accordingl y, the energy-preserving preference of lan guage users s upports our wo rd length and word energy analogy as a quite realistic assumption during written or verbal communication. Thus, we will use the 8 terminologies ‘word l ength, in letter count,’ and ‘word energy ’ interchan geably, for the rest of the paper. As a result, the DW energies are distributed over a set of quantized energ y levels given by quantized length states 12 , , , k l l l in letter count such that th e energ y of a DW at the i th energy state is simpl y the word’s letter count l i . Each DW energy stat e has an associated de generacy 12 , , , k g g g with a corresponding number of occupation s 12 , , , k n n n . There are no restrictions as to the number of DW s in any given state. As in the classica l particle organization, the two requirements that are imposed on the number of occ upations distributed over the DW leng th states are as follows: a) The total number of DW s, , is fixed: 12 , i i k N n n n n (7 ) where n i is the number of DWs, distinguishable words, in the i th state; i.e., the number of DW s having the same length l i in letter count. b) Note that we only consider the wor d length distribution of DW s in a text, s o the fre quency and the occurrence positions of the words a re insignificant. Similar to the total energy in the classical particles system, Eq. (3), the total word length count of DW s L is finite: 1 1 2 2 . k k i i i L l n l n l n l n (8 ) The average length of this DW organization is 9 , i i i i L l p l (9 ) where ii p l is the probabilit y of a DW ’s being in th e length state l i . The res t of the accessible states derivation of the DW organization is the same as in the cl assical particle organization, Eq. (6). The key at this stage of the derivation procedure is to define the degeneracies associated with the length states of DW s. Since the accessible number of DWs a t a particular length state is called the de generacy of that state, the degenerac y of the i th word length state is theoreticall y equal to i l . Here is the number of letters in the alphabet of the language in which the text is written. In general terms, ca n be defined as ‘ structural degeneracy param eter ’. is principally equal to the total number of distinct uni ts , i.e. letters, from which the DW s can be formed. For instance, in English the degenerac y of the three-letter-long DW state, l 3 , is 26 3 =17576; i.e., there are 17576 possible manif estations of a thre e-letter-long DW. In practice, however, the occupanc y o f the accessible degenerate states for a given wor d length state is primaril y governed b y two counteracting effects: (i ) the linguistic rules and restrictions prohibit the genera tion of some of the accessible degenerate states, DW s. For instance, as lon g as the y are n ot abbreviations, English vocabulary does not consist of some of the words in l 3 length state such as ‘ aps ’ , ‘ eps ’ , ‘ iop ’, an d many more. This effect has a relatively more si gnificant impact on shorter length DWs than longer length DW s; in turn, the DW leng th is forced to have higher word len gth v alues for the generation of new DWs, and ( ii ) the principle of least effort effect, on the other hand, forces the words to have shorter lengths fo r feasible articulation, as discussed earlier. At equilibrium, these two counteracting effects define an optimum word length value of which the oc cupancy tendency of the degenerate states will be relatively hig her around that particular word length value. 10 The primar y proposition of statistical mechanics is that all the states of a physica l s ystem are equally li kely a ccessible. This assumption holds for isolated s ystems; howe ver, in many non- isolated s ystems, a certain state’s occurrenc e can be more probable t han that of others. The aforementioned two cou nteracting effects cause t he DW length o rganization in a text to behave as a non-isolated ph y sical s ystem; i.e., length states present favorability. Therefore, to account for the length favorabilit y of DW states, we implement an ansatz such th at a p articular outc ome’s probability p i , which is associated with the occurrence of i th outcome, is weighted b y means of positive-valued power α of the discrete variable l i . This wei ghted probabilit y requires a weighted number of degeneracy at the i th state, which can be defined as . i ii l g l (10) If the degeneracy of the i th state is not biase d by the mechanism of the aforementioned two counteracting effects, i.e ., α is equal to 0, the number of degeneracy of the i th state in Eq. (10 ) reduces to its equally accessible states form, i l , as e xpected. Finally, the num ber of ways in which N distinguishable words of a text can take place is obtained by substituting Eq. (10) into Eq. (6) Ω ! ! i i l n i i i i nN n l (11) 2.3. Derivation of the DW distribution model The most probable distribution is determined by the realization of the set of occupations i n that max imizes accessible microstates, . Note t hat is defined on a subset of th e real valued 11 numbers and satisfies the condition of ΩΩ xy for all xy ; i.e., is a monotonically increasing f unction. Hence, maximizing is the same as maximizing ln Ω . This func tional behavior allows us to easil y approximate the factorial terms in Eq. (11). Next, assume each i n is sufficiently large, which impli es that N is very l arge, ideall y in the limit as N ; in this case Stirling’s approx imation, l n l n ! i i i i n n n n provides a quite a ccurate estimate for the f actorial terms in Eq. (11) and we obtain ln Ω l n ln ln . i n i i i i i N N N g n n n (12) ln Ω is maximized for n i value, which sa t isfies the following condition: dl n Ω ln ln 0 . i l i i i i n l dn (13) Since d n i ’s are related to each other b y the constraints g iven in Eq s. (7 ) and (8), the solution to this extreme value p roblem is achieved b y scrutinizing th e constraints associated with the Lagrange multipliers and ; i.e., the well-known Lag range multi pliers’ method, 0, i i dn (14) and 0. ii i l dn (15) In Eq. (15), the minus sign is arbitrary; however, for positive valued l i the sum appropriately converges. By substituting Eq . (14) and Eq. (15 ) in to Eq. (13), we get 12 ln l n 0 . i l i i i i i nl l dn (16) Now we assume all d n i ’s are independe nt of eac h other by suitabl y chosen and values that fulfill the conditions required for the constraints , Eq. (7) and Eq. (8). The condition for Eq. (16) is satisfied when the term inside the square bracket identically vanishes for each i th state such that ln l n i ii l i l nl (17) which leads to the most probable length distribution of the DW s as follows . i i i i i ll n e l l e (18) Using the constraint in Eq. (7), Eq. (18) can be alterna ti vely rewritten as , i i i l i i l l n l Z e N (19) where Z is the partition function, and it is defined by . i i ll i i le Z (20) The correspondence b etween the models and the physical implications of th e pa rameters for the DW length distribution in a large text are presented in the following section. 13 3. Results and Discussion 3.1. Parameters of the models Equation (18) is the four-parameter SMMA model that was derived to characterize the DW organization in a lar ge tex t. One of the parameters, structural de generacy parameter , in the SMMA model is not a free parameter, it is a fixed or structu re -specific parameter. The remainin g three free parameters are to be determined experimentally. In Eq. (18), l et ln c b eA (21) then, the SMMA model reduces to the discrete form of the MA model, see Eq. (1), . i cl b i i i n l A l e (22) This sugge sts that both the SMMA model, Eq. (18), and its reduced form of the MA model, Eq. (22), theoretically describe the very same distribution function with two different sets of parameters which are related to e ach other given by Eq. (21 ). As a result, both mo dels ar e identical in their functional behavior, i.e., . i i i cl b i i i i ll n l A l e e l e (23) In this study, the particular organization that we are examining is the length distribution, in letter count, of DWs (constituents) in a large text (construct). Ou r recent stud y 17 demonstrated the validity of the MA model in de scribing the DW distribution for two corpora written in differe nt languages, the Brown Corpus (English) and the M ETU Corpus (Turkish). Since the related question 14 is whether the derived SMMA model experimentally predi cts the same DW distribu ti on as the MA model does, we utilized the same data set in Ref. 17 for consistency, as seen Table 1. The discrete data were fitted to the MA model and to the SMMA model with the best fitting parameter sets g iv en in Table 2. S ince there are 26 letters in the English alphabet and 29 letters in the Turkish alphabe t, the structural degenerac y parameter in the SMMA m odel was taken to be = 26 for the Brown C orpus and =29 for the METU Corpus. The non-linear regression analysis was performed b y usin g Levenberg-Marquardt algorithm 28 , also known as the damped least-square fitting method. The algorithm initi ally starts with the user defined parameter guesses, and iteratively generates slight v ariations in the pa rameter values. At e ach it eration, the sum of the squared error between th e observed data and the predicted fit , chi-square value, is calculated and the best fit is found by minimizing the chi-square value. One mi ght improve the goodness of the fit by utilizing different r egression anal ysis method; in this study, however, our priority was to present the c orrespondence be tween the MA and SMMA models by appl ying the same regression analysis method to both models. Table 1 is placed about here Table 2 is placed about here 15 Table 1 shows the predicted DW distribution values for both corpora using both distribution models with the parameter sets given in Table 2. The results indicated that the DW distribution values for both models are the same with ne gligible differences in some stat es’ predictions. Another evidence supporting our cl aim that both distribution models experimentally perform in the same manner is the identical values of R , linear correlation coefficient, and R 2 , coefficient of determination, for both models as seen in Table 2. To graphically illustrate the correspondence between the models, the observed data and the predicted distribution cur ves by the MA model, Eq. (22), and t he SMMA model, Eq. (18), are shown in Fig. 1(a ) and Fi g. 1(b) fo r the Brown Corpus and for the METU Corpus, respectively. Notice that both predicted DW distribution curves exactly overlap for both corpora. In conclusion, these experimental indications confirm ed that the SMMA and the MA laws are the same distribution models, and the SMMA model is the transformed (g eneralized) form of the MA model. As theoretically propos ed in Eq. (21), the experimental values of the paramete rs b and α are essentially equal to each other and independent from the model utilized, see Table 2, which suggests that b , or α , is j ust responsible for predi cting the h eight of the di stribution maxima . This behavior can be confirmed by simulating the var ying α values. While α parameter is invariant under the model transformation, b , and eA ; th e values of p arameter c of the MA m odel and its corresponding parameter in the S MMA m odel were observed to be different (Table 2) . Moreover, the values of para mete rs c and c an b e confirmed to be related to each other as dictated Figure 1 is placed about here 16 by the structural degenerac y parameter given b y Eq. (21). This result revealed that the structure dependent information of the organization is implicitly embedded into the MA model, but explicitly included in the S MMA model. In oth er words, the i l term in the SMMA model inputs organization characteristic information to the distribution function and, in turn, converts the other model parameter , c , into the structu re-independent model parameter, . Thus, the obtained parameter valu es ar e in dependent from the structural differences for the organizations under investigation. This is an exceedingly useful characteristic propert y of the SMMA model, especially in the comparative studies of different organizations, as demonstrated in the following sections. 3.2. Physical interpretation of the SMMA model parameters Since the SMMA model, Eq. (18), was derived by using statistical mechanical concepts and tools, the model parameters have the following noticeable ph ysical interpretations : The exponential term, ex p i l , is analogous to the Max well-Boltzmann exponential term, B ex p k T i , in a classical particle distribution . Hence, the parameter is equivalent to which is equal to the reciprocal of the fundamental ph y sical energ y unit B kT ; i.e., B 1 k T . Here B k is Boltzmann ’s constant, T is absolute temperature, and B kT is the energy asso ciated with ea ch microscopic degree of freedom. For a giv en classical particle s ystem, the average kinetic energy associated with a particle’s degree of freedom (e.g., the translational motion) is given by B kT . Therefore, the mean translational kinetic energy per particle is proport ional to the temperature, and the multiplication of this averag e energ y by t he total number of particles is simpl y equal to the thermal energ y of th e system. When absolute temperature drops to its lowest theoretical value, absolute zero, the particles ’ r andom mo tion due to their kinetic e nergy terminat es. I n the case of DW distribution, the 17 condition of absolute ze ro temperature or translates that there is no common source of disturbance to a gitate the text’s DW s simultaneousl y , i.e., each expected DW len gth state is completely occupied. Another ph ysically intuitive parameter in Eq. (18) is the parameter in the first exponential term, e . This parameter is related to the chemical potential o f a grand canonical ensemble of classical particles. In the case of DW dist ribution, a sim ple analysis suggests that and since h as the dimension of energy, as a result the relation between the parameter and the chemical potential energy is . A well-known statement of statistical mechanics is th a t pressure controls any change in volume and, likewise, chemical potential controls an y change in the number of particles. The chemical potential corresponds to the (infinitesimal) change in entrop y associated with adding a particle to the s ystem (while holding total energy and volume fixed), , UV T S N . Entropy is another informative thermodynamic property of statisti cal mechanics systems, and it is defined as the me asure of the numbe r of ways in which a s ystem may be arranged; i.e., the measure of disorder. The Boltzmann entropy in st atistical mechanics for a system in equilibrium is equal to B S= k ln . ii i pp (24) Therefore, the entropy of the DW distribution in a text can be obtained as B S= k 1 . ln 1 ln i l ii i i nl N Nn N (25) 18 In thermod ynamics, the Helmholtz free energy, the thermodynamic potential, is a measure of useful energy o r a maximum amount of extractable work from a thermod y namic s ystem, and it is simply defined by B F = k T l n . Z (26) So by substituting Eq. (20) in Eq. (26), the free energy of the DW organization in a text is equal to B 1 F = k T l n n. l i i i i l l l l i i i i l e l e (27) As we shall see in the following section, these results were put into practice and provided quantitative conclusions for comparative DW organization anal ysis in terms of thermodynamic concepts. 3.3. Some thermodynamic properties of DW organization in selected corpora In this section, we dem onstrate that the SMMA model allows us to obtain and compare the thermodynamic propertie s of the DW organizations of the previously introduced two corpora. Due to their large sizes, both corpora examined in thi s stud y are quite inclusive in terms of the languages’ vocabular y (DW ) content; for this reason, one can unp retentiously d educe that the thermodynamic propertie s of the corpora can be ex tended to the thermody n amic properties of the languages in DW organiz ation as anticipated in the following investi gations. Furthermore, for the sake of simplicity, we set Boltzmann’s constant B k equal to 1 for the subsequent computational calculations. 19 As discussed earlier 1 T ; then, the temperature of the corpora, in arbitrar y unit s, was obtained as 0.226 4 and 0.227 4 for the Brown C orpus and the METU C orpus, respectively. The temperature values indicated that Turkish langua ge is sli ghtly ‘ hotter ’ than English lan guage in DW organization. In statisti cal mechanics terminology, this means that the average energy pe r DW is somewhat higher in Turkish than in English, which reveals that the DW s are more energetic, or more energy consuming, as used in Turkish. T his is an expected result, since the peak of the distribution curve is positioned at longer wo rd length state ( two letters higher) for Turkish, see Figs. (1a) and (1b). Similarly, the pa rameter was shown to be analogous to the chemical potential energy given by 1 T , as discussed in the previous section. Hence, the chemical potential energy, in arbitrar y units, was calculated as 0.2101 and -0.0653 for the Brown Corpus and the METU C orpus, respectively. These numerical results suggest ed that the entropy of Turkish langua ge has a tendency to increase with the addition of new DWs, while the entropy of English lan guage has a tendenc y to decrease with the addition of new DWs. Since the chemical potential energy c oncept is notoriousl y somewhat elusive, the full interpretation of the above numerical values in their organizations wo uld require further elaboration. From Eq. (25), t he numerical values of entropies, in arbitrary unit s, are calculated as 6 1. 8 10 and 6 9. 5 10 for the Brown Corpus and the METU Corpus, respectivel y. This result uncovered that the increase in disorder is about five times higher in Turkish language’s DW organization compared to that of English language. Finally, the free energies of the corpora’s DW organizations were obtained by subst ituting the SMMA model parameter values, seen in Table 2 , into Eq. (27). The numerical values of the free 20 energies, in arbitrary units , are calculated as -2.1 911 and -2.8095 for the Brown Corpus and the ME TU Corpus, respectively. These ar e the amount of energies have to be committed b y languag e users of two lang ua ges in the DW usag e during their communication. According to this result, we quantified that the energy consumption due to the DW usage is about 22% less in English compared to Turkish, which suggests that English is more effective langua ge than Tu rkish at the level of DW organization. This drawn conclusion is in line with the comparison of the average DW length values, 7.8 for the Brown Corpus and 9.4 for the METU Corpus. From the above straightforward demonstrations, we inferred that the SMMA model transformation methodol ogy is a powerful tool t o draw comparative conclusions on organiz ations presenting MA law behavior by means of enumerating their thermodynamic properties. 4. Conclusion In this study, we propo sed a generalization me thodology of the MA model , termed as the SMMA model. The deriva tion of the four parameter SMMA model was based on the statis tical mechanics tre atment of DW s in a text. The significance of the model is that it consists of a n additional structure-dependent parameter input that converts the remaining three parameters into structure-independent free parameters. W e have to emphasize that the additional parameter in the SMMA law is not a fr ee parameter during the fitting process. It is uniquely dictated by the fo rmational nature of the structural organization under investigation , and it s value is described prior to fitting process. Thus, it is not rea sonable to ex pect that the four-parameter S MMA law provides better fit compared to the three-parameter MA law as in dica ted by the Akaike information c riterion 29 . In fact, we deliberately showed that the MA law a nd the SMMA law are the identical distribution models with different sets of parameters. 21 Moreover, the parameters of the SMMA model are associated with a corresponding ph ysica l interpretation that ca n lead to character iz ation of an organization’s thermodyna mi c properties. The derivation procedure m ay su ggest that th e re ason for the MA l aw behav ior’s inevitable presence in many natural and artificial organizations mi ght be the discrete and en ergy-preserving nature of such constructs’ constituent configuration . The DW distributi on is, of course, onl y one linguistic trait of tex ts. However, we emphasiz e that the methodolog y u sed here can b e applied to the comparative quantification of regularity between other linguistic organization al levels, lan guages and even natur al phenomena that p resent the MA law behavior . The recipe for carrying ou t such investigation is sim ply to describe; (i ) the structural degeneracy par ameter for the level of organization under investigation, which is not necessarily the same for each level of organization , and (ii) the energy(effort)-associated states, naturally constituent length or size, in the SMMA model. Moreover, n atural lan guages serv e as a r eadily a vailable model for the investigation of man y complex s y stems, and linguistic-based theories and algorithms are commonly employed to study such complex systems. Therefore, quantitative linguistic studies not onl y contribute to the sc ienc e of language, but also simplify the characterization and understanding of the self-organization and evolution processes of many complex systems. I n conclusion, constituent diversit y dynamics is of broad scientific interest to a range of d iscipline s from information technologies to bioinformatics, and we anticipate that the utilization of the presented methodolog y b y th ose researching complex syst em s could result in some intriguing outcomes. 22 Acknowledgments We are grateful to A. Algin for helpful discussions and we appreciate the careful proo freading of the manuscript by H. Kreuzer. This work was partially suppo rted b y Eskisehir Osmangazi University’s Scientific Research Projec t C ommission (Grant No. 2008 -19019). References 1 P. Menzerath, Die Architektonik des deutschen Wortschatzes, Dümmler, Bonn , 1954. 2 L. Hrebicek, The Menzerath-Altmann law on the semantic level, Glottometrika 11 (1989) 47-56. 3 R. Teupenhayn, G. Altmann, Clause length and Menzerath's law, Glott ometrika 6 (1984) 127-138. 4 L. Hrebicek, Text L ev els : Language Const ructs, Constituents and the Menzera th -Altmann Law, Wissenschaftlicher Verlag, Trier, 1995. 5 G. Wimmer, R. Kö hler, R. Grotjahn, G. Altmann, Towards a theor y of word length distribution, J. Quant. Linguist. 1 (1994) 98-106. 6 S. Eroglu, Language-like behavior of protein length d istribution in proteomes , J . Theor. Biol. (submitted). 7 M.G. Boroda, G. Altmann, Menzerath's law in musical texts, Musi kometrica 3 (19 91) 1-13. 8 R. Ferrer-i-Cancho, N. Forns, A. Hernández - Fe rnández, G. Bel-enguix, J. Baixeries, The challenges of statistical patterns of language: The case of Menzerath's law in genomes, Complexity 18 (2013 ) 11 – 17. 9 W. L i, Menz erath's law at the gene-exon level in the human genome, Complexit y 17 (2012) 49 – 53. 10 A. Hernández - Fernández , J. Baixeries, N. Forn s , R. Ferrer-i-Cancho, S ize of the whole versus number of parts in genomes, Entropy 13 (2011) 1465-1480. 11 R. V. Solé, Genome siz e, self-organization and DNA's dark matter, Complexit y 16 (2010) 20-23. 12 R. Ferrer-i-Cancho, N. Forns, The self-organiz ation of genomes, Complexit y 15 (2009) 34- 36. 13 G. Altmann, Prolegomena to Menzerath’s law , Glottometrika 2 (1980) 1- 10 . 14 A. Krott, Some remarks on the relation between word length and morpheme length, J . Quant. Linguist. 3 (1996) 29-37. 23 15 G. Antic, E. Stadlober, P . Gry z bek, E. Kelih, Word Length and Frequency Distributions in Different Tex t Ge nres, in : M. Spiliopoulou, R. Kruse, C. Borgelt, A. Niirnberger, W. Gaul (Eds. ), From D ata and Information Analysis to Knowledge Engineering , Springer-Verlag , Berlin, 2006, pp. 310-317. 16 I. -I. Popescu et al., Word Frequency Studies, Mouton de Gruyter, Berlin – New York, 2009. 17 S. Eroglu, Menzerath-Altmann law for distinct word distribution analysis in a large text, Physica A 392 (2013) 2775-2780. 18 H. S. Heaps, Information Retrieval: Computational and Theoretical Aspects , Academic Press, Orlando, 1978. 19 A. Kulacka, J. Macutek, A discrete formula for the Menzerath-Altmann L aw, J. Quant. Linguist. 14 (2007) 23-32. 20 I.M. Cramer, The parameters of the Menzerath-Altmann law, J. Quant. Linguist. 12 (2005) 41-52. 21 K. Kosmidis, A. Kalampokis, P. Argyrakis, Statistical mechanical approach of human language, Physica A 366 (2006) 495-502. 22 S. Miyazima, K. Yamamoto, Measuring the temperature of texts, Fractals 16 (2008) 25-32. 23 A. R ovenchak, S. Buk , Application of a quantu m ensemble model to li nguistic anal y sis , Physica A 390 (2011) 1326-1331. 24 R. Ferrer-i-Cancho, Decoding least effort and scaling in signal fr equency distributions, Physica A 345 (2005) 275-284. 25 V.K. Balasubrahmanyan, S. Naranan, Quantitative linguistics and complex s y stem studi es, J. Quant. Linguist. 3 (1996) 177-228. 26 G. K. Z ip f, Human B ehaviour and the P rinciple of L east Effort: An I ntrod uction to Human Ecology, Addison-Wesley , Cambridge, 1949. 27 R. Ferrer-i- Cancho, A. Hernández - Fernández, D. Lusseau, G. Agoramoorthy, M.J. Hsu, S. Semple, Compression as a universal principle of animal behavior, arXiv:1303.617. 28 W.H. Press, B.P. Flannery, S.A.Teukolsky, W.T. Vetterlin g, Numerical Recipes in C : The Art of Scientific Computing, Cambridge University Press, New York, 1988. 29 H. Akaike, A new lo ok at the statistical model identification, IEEE Trans. Autom. Control 19 (1974) 716 – 723. 24 TABLES Table 1. Observed and predicted DW length distributions for the corpora. DW length a Number of DWs / Brown Cor. (English) Number of D Ws / METU Cor . (Turkish) Predicted Predicted Observed b MA model b SMMA m odel Observed b MA model b SMMA m odel 1 26 1 1 2 0 0 2 142 73 73 341 47 47 3 783 639 640 1,592 622 623 4 2,318 2,123 2,124 3,814 2,900 2,903 5 4,072 4,154 4,154 9,023 7,601 7,605 6 5,627 5,814 5,813 13,050 13,835 13,834 7 6,508 6,459 6,457 19,034 19,576 19,570 8 6,059 6,059 6,056 22,362 23,040 23,028 9 5,099 4,994 4,992 23,488 23,556 23,542 10 3,877 3,718 3,716 22,286 21,554 21,541 11 2,475 2,549 2,548 18,473 18,028 18,018 12 1,544 1,632 1,632 14,869 14,001 13,994 13 885 987 987 10,192 10,217 10,214 14 444 569 569 6,609 7,071 7,070 15 209 314 314 3,744 4,675 4,675 16 85 167 167 2,117 2,970 2,971 17 48 86 86 1,174 1,822 1,823 18 23 43 43 607 1,084 1,085 19 7 21 21 345 627 628 20 1 10 10 151 354 354 21 2 5 5 71 195 196 22 1 2 2 29 106 106 23 NA NA NA 7 56 56 24 NA NA NA 6 29 29 25 NA NA NA 3 15 15 a Observed DW length co unt truncation was 22 letters for the B rown Corpus and and 25 letters for the ME TU Corpus. b Adopted from Reference 17 . 25 Table 2. The fitting analysis results of the MA and the SMMA models for the corpora. Fitting param et er values a and correla t ion coeffic i ents Model Corpus A ( ) b (α) c ( ) R R 2 MA model b Brown (Engl ish) 2.5236 0.47 05 8.2039 0.18 64 1.1595 0.02 55 0.9991 0.9982 METU (Turki sh) 0.7454 0.28 58 8.9357 0.32 00 1.0303 0.03 59 0.9973 0.9945 SMMA m odel c Brown (Engl ish) 0.9281 0.18 73 8.2014 0.18 86 4.4173 0.0262 0.9991 0.9982 METU (Turki sh) -0.2871 0.38 64 8.9299 0.32 48 4.3970 0.03 71 0.9973 0.9945 a Each value is displayed with the associated standard error. b The free model para meters are A , b and c. c The free model parameters ar e , α and ( =26 fo r the Brown Corpus and =29 for the MET U Corpus). 26 FIGURES Figure 1. The prediction of the DW distribution f or the Brown and the METU C orpora. Observed number of DW versus DW length data (dashed li ne) are fitted with distribution prediction curves (s olid lines) proposed by the MA model and the SMAA model for (a) the Brown Corpus (English) and ( b) the METU Corpus (T urkish). Note th at b oth prediction curves, ob tained b y the MA model and the derived SMMA model, exactly overlap for both distributions. 27 Fig. 1a 28 Fig. 1b
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment