The influence of relatives on the efficiency and error rate of familial searching
We investigate the consequences of adopting the criteria used by the state of California, as described by Myers et al. (2011), for conducting familial searches. We carried out a simulation study of randomly generated profiles of related and unrelated…
Authors: Rori V. Rohlfs, Erin Murphy, Yun S. Song
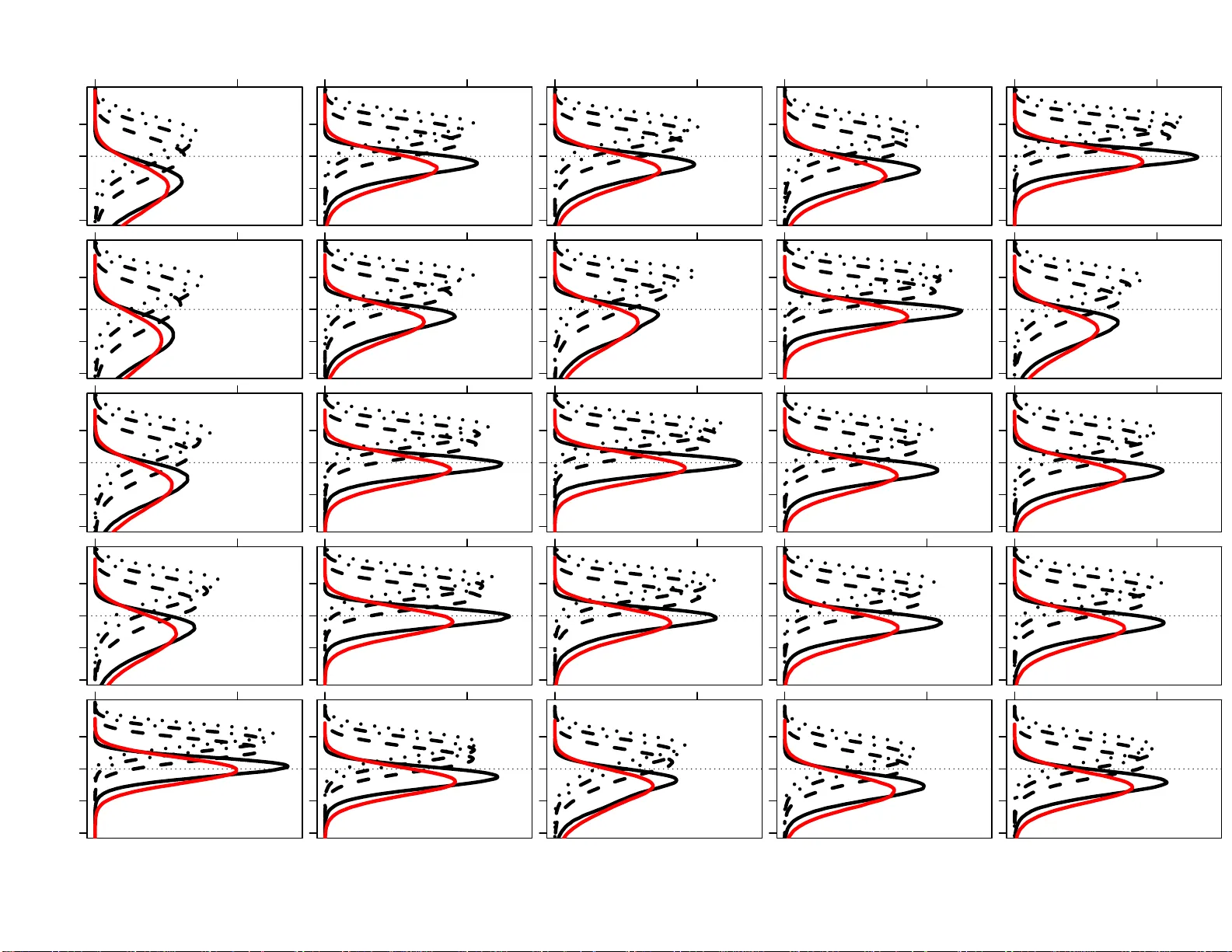
The influence of r el atives on the effici ency and erro r ra te of famil ial searching Rori V. Rohlfs a, ∗ , Erin Murph y b , Y un S. Song c,d , Mon tgo mery Slatkin a a Dep artment of Inte gr ative Biolo gy, Univer si ty of California, Berkeley, CA 94720, USA b Scho ol of L aw, New Y ork University, New Y ork, NY 10012, USA c Computer Sci enc e Di vision, University of Cali fornia, Berkeley, CA 94720, USA d Dep artment of Statistics, University of Calif ornia, Berkeley, CA 94720, USA Abstract W e in v estigate the consequences of adopting th e criteria used by the s tate of California, as d escrib ed b y My ers et al. (2011 ), for conducting familial searc hes. W e carried out a s im ulation s tu dy of randomly generate d p rofiles of related and unrelated individ uals with 13-locus CODIS genot yp es and YFiler R Y-c hromosome h aplot yp es, on wh ich the Myers p rotocol for relativ e id entificatio n w as carried out. F or Y-c h romosome sharin g first degree relativ es, the My ers proto col has a high probabilit y (80 ∼ 99%) of identifying their r elatio n ship. F or unrelated individuals, there is a lo w probabilit y that an un related p erson in the d atabase w ill b e identified as a first-degree relativ e. F or more distant Y-haplot yp e sharing relativ es (half-siblings, first cousins, half-first cousins or second cousins) th er e is a substant ial p robabilit y that the more d istan t relativ e w ill b e incorrectly iden tified as a first-degree relativ e. F or example, there is a 3 ∼ 18% p r obabilit y that a fir st cousin will b e iden tified as a full sibling, with the p robabilit y dep ending on the p opu lation bac kground. Although the California familial searc h p olicy is lik ely to iden tify a first degree relativ e if his pr ofile is in the database, and it p oses little risk of falsely identifying an unr elated individ ual in a database as a fi rst-degree relativ e, there is a sub stan tial risk of falsely iden tifying a more distan t Y-haplot yp e sharing relativ e in the database as a first-degree relativ e, with the consequence th at their imm ediate family may b ecome the target for further inv estigation. Th is risk f alls disprop ortionately on those ethnic groups that are currently o verrepresen ted in state and federal databases. Keywor ds: familial searc hing, kinship searc hing, p opulation genetics, distant relativ es, like lih o o d ratio, Y-c hromosome In tro duction DNA d atabases hav e unq u estionably assumed a vital r ole in the American crimin al justice system. Genetic evidence has serv ed to b olster the evidence in existing cases and to identify susp ects through “cold hit” database m atches [1]. T ypically , in vestiga tive queries in DNA d atabases ha ve b een limited to searc hes in tended to fi nd the source of the crime-scene sample. Ho wev er, increasing atten tion has b een give n to the question of whether law enforcement should also b e able to search for partial matc h es, th at is, DNA searc hes inte n ded to find th e source b y ident if y in g a relativ e in the database [1 , 2]. Suc h searches are commonly called “kinship” or “familial” searches. ∗ Corresponding author, rroh lfs@berkeley .edu, +1 (510) 643-0060 Email addr esses: rrohlfs@berkeley .edu (Rori V . Rohlfs), eem9@nyu.edu (Erin Murphy), yss@eecs.b erkeley.edu (Y un S. Song), slatkin@berkel ey.edu (Montgo mery Slatkin) Pr eprint submitte d to arXiv Aug ust 16, 2013 The concept of f amilial searc hin g is not particularly n ew. In fact, familial searc hes fu eled some of th e earliest illustrations of the in ve stigativ e p o wer of DNA typing [3]. In 2002, inv estigato r s in the Un ited Kingdom iden tified a serial rapist in part th rough a database searc h that led th em to the p erp etrator via the DNA profile of his son [4]. In an other widely cited case, UK in ve stigators reco v er ed DNA from a bric k thrown off an o verpass that landed on a tr uc k, leading to the driver’s fatal heart attac k, and foun d the source through a database s earc h that lo cated a relativ e [5]. More recen tly , California authorities used a familial searc h to iden tify the putativ e son of a serial killer nic knamed the “Grim Sleep er,” and arrested the susp ect after a sting op eration in w hic h p olice collect ed a discarded pizza crust [5]. F amilial searc h es by no means domin ate the use patterns of DNA databases, in part b ecause they are difficult to conduct, require access to a sizeable database, are sub ject to v arious clear or unclear legal restrictions, and raise ethical concerns [6]. Because f amilial searc hes are by design inexact, th e most effectiv e metho d s t ypically emplo y several steps b eyo nd a s imple database searc h. T o fin d a lead, one commonly used approac h, wh ic h ma y enta il additional rounds of testing, relies on examining the Y haplot yp e of all significan t partial matc h es. Ev en if a partial m atc h is identified, la w enforcement still must in vestig ate the relativ es of that p erson to determine if an y are lik ely to b e th e crime scene sample sou r ce. Nev ertheless, familial searc hes are presen tly conducted by a n umber of jur isdictions and con tin u e to garn er interest. The UK is the most pr ominen t and longstanding advocate of the tec hnique: from 2004 to 2011, 179 cases w ere submitted f or searc h [7]. As of 2009, New Zealand had condu cted 12 familial searc hes in serious cases [8]. The Netherlands recen tly passed legislation authorizing familial searc h es [9, 10]. J apan, Australia and C anada h a v e r ob u st DNA collectio n programs, b ut only Canada h as explicitly rejected familial searc hes on what app ear to b e p riv acy ground s [11]. With regard to Eur op e, it is w orth noting that adoption ma y b e slo wed b y the Decem b er 2008 judgment by the Europ ean Court of Human Righ ts that declared the reten tion of DNA p rofiles and samp les from u ncon victed p ersons a violation of Article 8 of the Con ven tion for th e Protection of Hu man Right s and F undamental F reedoms. That opinion, (S. & Marp er v. United Kingd om), in vok ed the pro vision of the Conv en tion that safeguards its mem b ers’ “priv ate life” [12]. Although the influence of the ruling b eyond its imm ediate holding is un clear, the Marp er decision do es represent the fi rst sub stan tial curtailmen t of DNA expansion programs by a legal en tit y . Moreo ver, Marp er ma y b e used by p riv acy adv o cates and opp onents to widespr ead DNA t yp ing to b olster their legal claims to circumscrib e suc h p rograms. In th e United States, the push to expand DNA testing has in tensifi ed . Originally , United States national database administrators prohibited the disclosure of iden tifying information for partial matc hes made across state lines [5]. As a result, although man y states either legally authorized or informally p ermitted partial m atch (“mo derate strin gency”) rep orting and/or familial searc hes [13], inv estigators could not obtain inf orm ational leads on p rofiles generated out of state. In 2006, ho wev er, th e FBI mo d ified its p olicy and no w p ermits inte r state sharing [14]. As of Ma y 2012, a bill was p ending b efore Con gress that w ould allo w the FBI to conduct familial searc hes in federal and state inv estigati ons [15]. Because th e ru les go ve r ning familial searc h metho ds in the United States consist of a patch w ork of state law, s tate and lo cal r egulation, and ev en internal lab oratory p olicies [5, 6], it is im p ossible to relate a precise legal picture. In J une of 2013, th e U.S. Su preme Court in Maryland v. King [16] upheld DNA collection fr om arrestees for s er ious offenses. Although the Court noted that Maryland forbids f amilial searches, th at observ ation did not seem cen tral to its h olding, and no lo wer courts ha ve ruled on the iss u e. Assessmen t is furth er complicate d by the slim line th at differen tiates uninte n tional and in tentio n al partial matc h searc h es, b ecause some jur isdictions allo w the former but not the latter. Nev ertheless, some clarit y is p ossible. 2 A t the state lev el, b oth Maryland and W ashington, D.C. h av e laws expressly forbidd ing familial searc hing [17 , 18], although the language of b oth statutes could b e inte rpreted to p ermit r ep orting of uninte n tional partial matches. As a matter of either written or unwritten p olicy , r ou gh ly nine states expressly forbid b oth partial matc hing and familial searc h ing: Alask a, Nev ada, Utah, New Mexico, Michiga n , V erm on t, Massac husetts, and Georgia [19]. A t least an other seven states prohibit familial searc hes, b ut allo w rep orting of inadverte n t p artial matches [19]. Fifteen states allo w b oth forms of p artial matc hing, although all of them rely up on formal or informal p olicies rather than express statutory auth orizatio n [19]. The states most activ ely pursu ing familial matc hes are California, Colorado, Virginia, and T exas; Pe nnsylv ania, Minnesota, and T enn essee are considering legislat ion. In April 2008, Califor- nia b ecame the first state to form ally endorse and adopt exp licit rules for conducting inten tional familial searc hes [20]. The bur geoning in terest in familial searc hing has reignited a n ational conv ers ation ab out the propriet y of the metho d that fo cu ses on legal and ethical issues [21, 22]. The ma jor concerns are t wo- f old: fi rst, is familial searc hin g actually efficacious, and second, do es it adequately resp ect priv acy and equalit y in terests? With regard to efficacy , the c hallenges of familial searc hing are reflected in its rep orted success rates, alb eit based on limited data. Th e UK rep orts the greatest effectiv eness with a 11 ∼ 27% success rate) [23]. California has conducted 29 searches, with 2 r ep orted successes ( ∼ 7% su ccess rate) [24 ]. With regard to the ethical iss ues, familial searc h es raise p riv acy , equalit y , and d emocr atic ac- coun tabilit y concerns [5, 25, 2, 1, 6 , 26]. In the United S tates, the most common critique is that the metho d is likely to h a v e a discriminatory effect b ecause DNA d atabases conta in the profiles of cer- tain racial minorities in disp rop ortion to their presence in the p opulation. T o d ate there ha ve b een only a handful of efforts to quantify the imp act of familial searc h es, and all ha ve b een u ndertak en without referen ce to a sp ecific searc h p olicy [1, 2, 3]. Only one s tudy , by a multidisciplinary team of researc hers, attempted to calculate th e general d iscriminatory impact and concluded that roughly “four times as m u c h of the African-American p op u lation as the U.S. Caucasian p opulation would b e ‘un der surveilla n ce’ as a resu lt of family forensic DNA” [2]. It is this estimation that s c holars, p olicymak ers and the p opular press hav e latc hed up on as a means of quantifying the racial imp act of familial searc h ing [21, 27, 28, 29], and while helpful, it is nonetheless an approximati on reac hed b efore any sp ecific p olicy was in p lace to b e examined. Answ ering the efficacy and ethical concerns raised by familial searc h metho ds in part requires addressing complex statistica l questions. The articulation of the fi r st formal familial searc h p olicy b y California [30], an American state with the w orld’s fourth largest DNA database (nearly 2 million profiles) and a large and diverse general p opulation [31], affords an opp ortun it y to gain v aluable insigh t into the question of whether and under what circum s tances f amilial searc hing should b e allo w ed. T he racial and ethnic d iv ersit y of the California database roughly mirr ors the racial and ethnic div er s it y of the United States n ational database [32, 33]. Moreo v er, as a b ellw ether of criminal justice p olicy , California has already wielded influence b oth nationally and in ternationally as other jur isdictions con template v arious app roac hes. Metho ds Here we imp lemen t the My ers et al. familial iden tification pro cedure used f or familial searc hing in California [30] to estimate p o w er and false p ositiv e rate in addition to estimating the rates of misiden tification of distant relativ es as first-degree relativ es. As d etailed more b elo w, in the Myers et al. metho d, b oth p aren t-offspring and sib ling relationships are considered by first calculating 3 eac h lik eliho o d ratio usin g autosomal data b etw een the u nkno w n sample and eac h en try in the state database. Of these, the database samp les with the highest lik eliho o d ratios are considered in a sec- ondary lik eliho o d ratio analysis using Y-c hromosome haplot yp es. Th e cum u lativ e lik eliho o d ratios are calculate d u nder three p op u lation genetic assump tions and if they pass particular thresholds, the individual is considered a susp ect. This metho d is d etailed in our descriptions b elo w. Al lele fr e quency data Autoso mal data In this study , w e u se allele frequency estimates to in vestig ate id en tification p ro cedures that are con tingen t on racially defined p opulation samp le allel e frequen cy calculatio n s. F or th e autosomal STR allele frequencies, we rely up on estimates from a published su rv ey of fiv e p opu lation samples consisting of 182-2 13 individuals eac h and classified according to so cially-iden tified race [33]. The groups are describ ed in the study as ‘Vietnamese,’ ‘African American,’ ‘Caucasian,’ ‘Hispanic,’ and ‘Na v a jo.’ Any lab eling s cheme introdu ces questions and classifies groups in different wa ys not indep end ent of the so cial constru ction of these group s. In this study we use the lab els Vietnamese American, Af r ican American, Eu rop ean American, Latino Am er ican, and Nativ e American. The consent and p opulation groupin g pro cedures us ed to obtain these data are not clear. Since these data were collected, th e customary ethical standards regarding informed consent pro cesses ha ve c hanged considerably , driven by sev eral cases of severe m isuse of samples pr o vided by Indige- nous comm u nities [34, 35, 36 , 37, 38, 39, 40, 41, 42]. W e u s e these data b ecause of their public a v ailabilit y and utilit y to in vestig ate error rates and efficacy in familial searc h ing. W e lo ok f orw ard to working with data collected using transparent informed consen t metho dology . The California state database consists of some entries with the 13 core CODIS lo ci and some with 15 lo ci [30]. T o maintain manageable complexit y , in this study w e only consider the core 13 lo ci. Similar analyses can b e p erformed w ith 15 lo cus profiles. Y-chr omosom e data F or the Y-haplot yp es, w e consider d ata released by ABI consisting of YFiler R haplot yp es geno- t yp ed in ind ividuals group ed according to so cial lab els ‘Vietnamese,’ ‘Afr ican American,’ ‘Cau- casian,’ ‘Hispanic,’ and ‘Nativ e American’, with sample sizes of 103, 1918, 4102, 1594, and 105 individuals, resp ectiv ely (Applied Biosystems R , F oster Cit y , CA) [43]. Again, w e r efer to these groups as Vietnamese American, Afr ican American, Europ ean American, Latino American, and Nativ e American. Individu als were genot yp ed and categorized in to p opu lation lab eling sc h emes differentl y for the autosomal and Y-chromosome marke rs. I n this study , w e u s e samples with the same lab els in b oth the autosomal and Y c h romosome data to get our com b ined p opulation sample allele frequencies for the Vietnamese American, African American, Europ ean American, and L atino American groups. Accordingly , the group w e call Nativ e American is created from ‘Na v a jo’ autosomal mark er allele frequencies and ‘Nativ e American’ Y-c hromosome allele frequencies. This inconsistency brin gs to question the relev ance of these results for highly sp ecified p opulations. Ho wev er, this degree of inconsistency in p opu lation lab eling is not remark able when consid ering the wid e v ariation t yp ical to categoriz ing p opulation groups (so cial identit y-b ased lab els like ‘Hispanic’, ‘Afr ican American,’ or ‘Caucasian’). Th e results of th e analysis of these data sh ould b e confi rmed and augmen ted by similar analyses of more transparent data. 4 Simulation sc heme Simulating r elatives T o inv estigate the p o w er and false p ositiv e rate of relativ e identificatio n pro cedures, pairs of related ind ividuals w ere sim u lated. Sp ecifically , 100,00 0 pairs of paren t-offspr ings, siblings, half- siblings, cousins, half-cousins (individu als sh aring a single grandparent), and s econd cousin s (in- dividuals s haring a set of great-grand paren ts) w ere sim ulated u sing allele frequ ency distribu tions for eac h of the five p opu lations describ ed ab o ve . The r elativ e p airs were s imulated to share a Y- haplot yp e by descent , an d we refer to this sort of r elationship as Y-sharing. The autosomal mark ers for all of the individ u al pairs w er e simulated with a p opulation backg r ound relatedness parameter θ = . 01, in accordance with the lo wer recommended corr ection in identificati on lik eliho o d ratio estimations [44]. Simulating unr elate d individuals Since unrelated individuals v ery r arely sh are enough alleles to resem b le genetic relativ es, more sim u lations are needed to accurately estimate the rates of p ositive r elativ e id entificatio n b et wee n unrelated ind ividuals. T o this end, 200,00 0,000 pairs of unrelated ind ividuals w ere simulat ed based on allele f requencies from eac h p air of p opu lation samples. Because of the immense p olymorphism of Y -c hromosome haplot yp es, accurate estimates of bac k- ground Y-c h romosome relatedness ( ˆ θ Y ) require greater sample sizes. T o simulate Y-haplot yp es of unrelated individu als with realistic lev els of bac kground relatedness, haplot yp es were indep endent ly dra w n f rom the data. This wa y , rates of coincidenta lly shared Y-haplot yp es corresp on d with those observ ed in the a v ailable data. Note that sim u lated rates of coinciden tally shared Y-c hromosome haplot yp es are greatly influenced by the av ailable data, which for some p opu lation samples is based on small num b ers of individuals. R elative identific ation pr o c e dur e P arent-o ffs pring and s ibling identificat ion proto cols w ere follo we d with the metho d implement ed in California wh ic h incorp orates autosomal and Y-c h romosome haplot yp e data [30]. Th ese calcu- lations were p erformed on p airs of individuals simulated with different genetic r elatio n ships, using the allele fr equencies from eac h p opulation samp le. Autoso mal likeliho o d r atio Using au tosomal data, the s tandard likel iho o d ratio (LR) comparing th e pr ob ab ilities of the observ ed genot yp es ( G ) assu ming a particular genetic relationship (paren t-offsprin g or sibling) and assuming the individuals are un related is defined as [1, 45] d LR A = P ( G | k 0 , k 1 , k 2 ) P ( G | k 0 = 1 , k 1 = 0 , k 2 = 0) , (1) where k 0 , k 1 , and k 2 are p arameters d escribing th e pr obabilities that individu als with the sp ecified relationship share 0, 1, or 2 alleles iden tical b y descen t (IBD) [46]. As sp ecified by My ers et al. , this LR is estimated under three conditions using allele fr equency d istributions from African American, Europ ean American, and Latino American p opulation samp les with no θ -correction for p opulation substru cture, as p racticed in California [30]. 5 Y-haplotyp e likeliho o d r atio Ignoring m utation, the probability that t wo Y-sharing relativ es h a v e the same haplot yp e of p opulation frequency p is p . On the other hand, the pr obabilit y that t wo u nrelated male individuals eac h ha ve that same h aplot yp e is p 2 . So, the Y-haplotype lik eliho o d ratio LR Y is 1 /p . In the My ers et al. pr o cedure [30 ], LR Y w as estimated as the inv erse of th e upp er 95% confid ence limit of the h aplot yp e frequ ency , obtained us ing the data p o oled across p opulations excluding the sampled haplot yp e [47, 30]. S p ecifically , after exclusion, if the Y-haplot yp e is observ ed w ith sample frequency ˆ p in the database, d LR Y = " ˆ p + 1 . 96 r ˆ p (1 − ˆ p ) n # − 1 , (2) whereas if th e Y-haplot yp e is not observed in the database, d LR Y = 1 − 0 . 05 1 /n − 1 , (3) where n d enotes the total n u mb er of Y-haplot yp es in th e d atabase. Combine d r esult The combined test statistic d efined by My ers et al. [30] is the pro d uct of the autosomal m ark er and Y-haplot yp e LR estimates, divided b y the database size ( N ): X = d LR A · d LR Y N . (4) X is calculate d for eac h of the th ree p opulation samples describ ed ab ov e. In this study w e consider a database of s ize N = 1 , 824 , 085, the size of the California state database as of Jan u ary 2012 [48]. An inv estigativ e p ositiv e identi fication (called simply a p ositiv e identificat ion here) is called when X is greater than 0.1 un der all th r ee assumed p opulation s amples, and greater than 1.0 for at least one p opu lation sample [30]. Results F alse p ositive r ates of r elative identific ation Unrelated individuals were simulate d b ased on allele f requency data from fiv e p opulation sam- ples to inv estigate f alse p ositiv e rates of parent -offspring and sibling iden tification. Autosomal and Y-c hromosome LRs w ere estimated using (1 )-(3), and the com b ined test statistic X defined in (4) was calculated for u nrelated pairs of individu als simulated from all pairs of p opulation sam- ples. Using the pro cedure describ ed by My ers et al. [30], false p ositive rates were estimated for paren t-offspr ing (T able 1) an d sib ling (T able 2) id en tifications. Ev en though false p ositiv e r ates are lo w , on the order of 1 × 10 − 5 to 1 × 10 − 9 , across p opulation sample pairs, there is some v ariation (T ables 1 and 2). In particular, the false p ositiv e rates f or unrelated pairs of individu als simulate d with Vietnamese American and with Nativ e American allele frequencies are r elativ ely high and lo w, resp ectiv ely (T ables 1 and 2). In sibling identificati on, th e Vietnamese American sample sho ws a comparativ ely high false p ositiv e rate of 1 . 1 × 10 − 5 , w hile no false p ositiv es are observe d in the Nativ e American sample (T able 2). This can b e exp lained b y the particular Y-haplot yp e p atterns considered for these p opu lation samples. F alse p ositiv e iden tifications were observ ed only wh en un r elated individuals coinciden tally share a Y-hap lotype. In the a v ailable Vietnamese American p opulation sample of Y-haplot yp es ( n = 103), several pairs 6 of ind ivid uals share Y-haplot yp es, while in the Nativ e American p opulation sample ( n = 105), no individuals sh are Y-haplotypes. In the other p opulation samples, Y-haplot yp es are shared at frequencies inte r mediate to those in the Vietnamese American and Nativ e American p opulation samples. Giv en the small sizes for these p opulation samples, it is not clear if v arying rates of coinciden tal Y-haplot yp e sharing are due to p opu lation genetic d ifferences, or sto c h asticit y of small samples. T o examine the v alidit y of th e total lac k of observed false p ositiv e relativ e identificat ions for unrelated individu als simulated fr om th e Nativ e Am er ican p opulation sample, we consid er th e p os- sibilit y of observ in g complete Y-haplot yp e div ersity (as observ ed) by chance. Using sim ulations, 100,00 0 subsamples of 105 (the Nativ e American sample size) Y-haplot yp es w ere randomly c ho- sen from th e larger African American, Eu rop ean American, and Latino American samples. Of the s ubsamples, 0.67, 0.57, 0.37 of the African American, Europ ean American, and Latino Amer- ican samples, resp ectiv ely , consisted of all u nique h aplot yp es, as observ ed in th e Nativ e American sample. This indicates the plausibility that a small samp le from a group with the in termediate degree of Y-haplot y p e diversit y observed in these larger p opu lation samples could all ha ve unique Y-haplot yp es b y c hance. Larger Y-haplot yp e samples are requ ired to confidentl y estimate false p ositiv e rates b etw een u nrelated individuals across p opulation samples. F alse p ositives in the datab ase c ontext Our results agree with previous work, sh owing that with the pr escrib ed metho dology , false p ositiv e rates of parent -offspr ing and sibling iden tification are lo w, on the order of 1 × 10 − 5 to 1 × 10 − 9 (T ables 1 and 2) [30]. But ev en w ith these lo w f alse p ositiv e rates, differences were observ ed b et ween p op u lation samples, raising the question of h ow these d ifferen ces in false p ositiv e rates interact with distortions in DNA database r epresen tation. T o in ve stigate this question, California census and pr ison p opulation p r op ortions of Asian, African American, Europ ean American, Latino American, and Nativ e American individu als we re normalized to fit the assump tion that all individuals are d escrib ed by exactly one of these cate- gories (T able S1 in File S1) [49, 50]. In combining census and p opulation genetic d ata, groups lab eled as ‘Vietnamese’ and ‘Asian’ were equated to eac h other. Clearly , these simplifications limit the ap p licabilit y of the p opulation sample-sp ecificit y of this analysis, ho wev er it pr o vides a first approac h. Using eac h of th e census and prison d emographics, the pr op ortion of false p ositiv e parent- offspring and siblin g identificati ons that inv olv e at least one memb er of eac h p opulation group were estimated (T ables S2 and S3 in File S1). As exp ected, in the demographic conte xt of a p rison system in which African Americans are drastically ov er-represen ted (T able S1 in File S1, exact binomial test p < 2 . 2 × 10 − 16 ), the rates of false id en tification of individ u als in this groups is m uch higher, roughly t wo orders of magnitude h igher (T ables S 2 and S3 in File S1). Nevertheless, the o ve r all rate of false identificat ion of unr elated individuals remains lo w. Spurious identific ation of distant r elatives The simulat ions of u nrelated individuals sho wed lo w false p ositiv e rates of parent -offspring and sib ling identificati on. H o we v er, d istan t Y-sharing relativ es may b e more often mistak en for paren t-offspr ings or siblings. T o in ve stigate this, ind ividuals with v arious Y-sharing relationships (paren t-offsprin g, siblings, half-siblings, cousin s , half-cousins, and second cousins) from p opulation sample bac kground s w er e simulat ed and used in th e s ame relativ e identi fication p ro cedure. Note that when considering Y-sh aring relativ es, the d LR Y calculatio n is greatly infl uenced b y the database size, as opp osed to the Y-haplot yp e reference frequ ency . 7 The observed distributions of the test statistic X for second-degree and d istan t relativ es is shifted left of those for first-degree r elativ es, but still has significant mass greater than 1 (Fig- ure 1). So as relatedness decreases, the X more effectiv ely distinguish es first-degree from distan t Y-sharing relativ es. Concordant with a previous stud y [51], d istinguishabilit y is also higher with appropriately-sp ecified allele frequencies in p opulation samples with higher p olymorph ism at th e mark ers considered. By considerin g these distr ib utions, it is clear that r egardless of the exact decision pro cedure, distant Y-sharing relativ es sho w elev ated X v alues. P ositiv e rates v ary across tr u e relationships, p opulation samp les, and tests of parent -offspring v ersu s sibling relationships (Figure 2, T ables 3 and 4 ). The p o we r of the p arent-offspring test v aries from 0.94 to 0.99 and the sibling test v aries from 0.68 to 0.85 for v arious p op u lation samples. Of course, a d ifferen t threshold pro cedure could raise the p o wer of these tests, but w ill simulta neously raise the false p ositiv e rates. Regardless of th e particular thr eshold pro cedure, the relativ e trends observ ed across tru e relationships, p op u lation samples, and tests of parent- offspring v ersus sibling relationships will h old for LR-based metho ds. When implemen ting the f u ll My ers et al. pro cedure to call p utativ e relativ es, Y-sharing relativ es are fr equen tly mistak enly iden tified as parent -offspr ings or siblings (T able 4). Second degree Y- sharing relativ es lik e half-siblings are called as siblings in 5 ∼ 24% of simulations (T able 4). The frequency of relativ e identificat ion decreases w ith the degree of relatedness (or equiv alently , those with higher kinship co efficien ts), but ev en Y-sharing h alf-cousins are called as siblings in 1 ∼ 10% of sim ulations, dep ending on the p opulation sample (T able 4). P ositiv e id en tification b et we en distan t Y-sh aring relativ es o ccurs more often when considerin g sibling relationships rather than parent- offspring b ecause of th e less strin gent allele sharing require- men ts. F or examp le, Y-sharing half-siblings are called as siblin gs in 5 ∼ 24% of sim u lations and called as parent-offspring in 4 ∼ 10% of simulations (T ables 3 and 4). S haring at least one allele at eac h lo cus, as required for p aren t-offspring relationships, is less likel y by c hance than sharing on a ve r age one allele at eac h lo cus, as exp ected for sibling relationships. Higher r ates of p ositiv e identi fication are observed for ind ivid uals simula ted w ith Nativ e Amer- ican or Vietnamese American allele frequencies (Figure 2, T ab les 3 and 4). Th is is like ly due to allele frequency m iss p ecification inherent in the metho d , wh ic h calculates the test statistic X under African American, Eu rop ean American, and Latino American allele frequencies only , and due to v arying p opu lation sample gene dive rsit y , as found in a stud y of au tosomal lo ci [51]. F or relativ es sim ulated from African American, Eu r op ean American, or Latino American p opulation samples, the metho d correctly sp ecifies th eir allele frequencies, so they show comparative ly low er iden tification r ates (Figures 2 and 1, T ables 3 and 4). T o sho w that these differences in identifica tion rates across p opulation samples are not d riv en b y differing sample sizes, the same rates were estimated with a reduced Y-haplot yp e reference of 103 haplot yp es p er p opu lation sample. Again, w e see the same trends across p opulation samples, confirming that they are n ot caused b y v arying reference Y-haplot yp e sample sizes (T ables S4 and S5 in File S1). No te that the absolute false identifica tion r ates differ in the full and subsample analysis b ecause the estimated Y-haplot yp e frequency a fu nction of the p o oled samp le size. Discussion W e ha ve in vestig ated by compu ter sim u lation th e consequences of using a familial searc h p olicy similar to that describ ed by My ers et al. [30], whic h is the p olicy currently used by the state of California for condu cting familial searc hes. Our simulatio ns assumed that allele frequ encies at the 13 CODIS lo ci and the Y haplot yp es for fiv e ethnic groups are as giv en in Budo wle et al. and the ABI reference database [33, 43]. W e reac h th ree main conclusions. F ir st, if the profile of a 8 first-degree relativ e of a r andomly generated profile is in the d atabase searched, there is a relativ ely high probabilit y of iden tifying the relativ e as s u c h. T h u s w e agree with My ers et al. [30], Bieb er et al. [1], and Curran and Buc kleton [3] that familial searc hing can b e an effectiv e wa y to iden tify first-degree Y-sharin g r elativ es of an individu al w ho left a crime scene sample. Ho w ever, note that the simulati on study of Bieb er et al. [1] s u ggests higher ident ifi cation efficiency th an observed in an empirical stud y b y Curr an and Bucklet on [3], p ossibly due to p opulation stru cture in the emp irical dataset [51 ]. Slo oten and Meester [52] ha ve also shown that there m ay b e h igh v ariabilit y in p o wer to id entify relativ es when considering p rofiles of v arying rareness in sp ecific databases. Second, we f ound that the p robabilit y of identifying an unr elated Y-c hromosome-carrying indi- vidual as a first-degree relativ e is quite low, agreeing with the results of Mye rs et al. [30]. Ho wev er, our abilit y to obtain precise estimates of this probability for d ifferen t ethn ic groups is limited by the r elativ ely sm all samples sizes av ailable to estimate Y haplotype frequencies, esp ecially for the Vietnamese Am er ican and Nativ e American samples. F or p opulation samp les other than those, the probabilities are so lo w that we could reasonably exp ect at most one unrelated in dividual w ould b e incorrectly identified as a first-degree relativ e even in a database as large as California’s, wh ich is approac hing 2 million pr ofi les. T he h igh f alse p ositiv e rate in the Vietnamese American p opu lation sample is sub ject to samplin g err or w ith the relativ ely lo w n umb er of Y-haplot y p es for this group (103 h aplot yp es), so w e hesitate to pu t great confidence b ehind th at particular rate. Our third conclusion is that there is a pr eviously unr ecognized r isk from conducting familial searc hes created by the p ossibilit y that a more distan t relativ e whose profile is in a database will b e incorr ectly identified as a first-degree r elativ e of the p erson who left th e crime-scene sample. With the data considered here (13 autosomal loci and 17-locus Y-haplotypes), ev en with other decision pro cedures, d istin gu ish abilit y of firs t-degree and distant genetic relativ es may b e limited (Figure 1). This is esp ecially tr ou b ling when con templating the p ossibility that familial searc hes ma y b e conducted in th e national database, whic h contai n s o ver ten million profiles. Widen ing the geographic scop e of a s earch is lik ely to result in more of the source’s d istan t r elativ es ha ving a presence in the database. T o b e clear, our concerns arise only with resp ect to in adv ertent erron eous identificat ion of distan t relativ es as first-degree leads. F amilial searc hes are ineffectiv e if secondary relativ es are in tentio n ally sought. Ind eed, the Myers proto col targets first-degree relationships only b ecause activ ely seeking more r emote connections ordin arily returns to o many leads to in ve stigate. Y et familial searc h es also cann ot b e configur ed to assure that only first-degree r elativ es of the crime scene s ample source are identified as leads. As our and other researc h h as shown, the tailored approac h of the Myers et al. proto col has the adv an tage of return ing few spur ious leads – if a lead is generated, it is almost certainly a relativ e of the crime s cene sample source. Ou r findin gs, ho wev er, suggest th at th e closeness of the lead to the sour ce is an op en question. Significan tly , our researc h do es not revea l the p ercen tage of cases in which a lead returned will b e a distant r elativ e, as opp osed to a first d egree relativ e. Such an estimation requires a differen t set of simula tions including complex d emographic estimates. In our sim u lations, w e set the coancestry co efficien t θ = . 01, w h ic h aligns w ith the less conser- v ative parameter v alue suggested for direct id en tification [44]. The curr en tly imp lemented familial searc hing metho dology in California assum es θ = 0 . 0. This discrepancy cont r ibutes to elev ated rates of p ositiv e identificat ions observed b etw een b oth unrelated individuals and distan t Y-sharin g relativ es. In add ition, ou r simula tion parameter v alue θ = . 01 may b e an underestimate for some p opulation samples [44]. F or th ese cases, we ha ve underestimated the amoun t of coinciden tal re- latedness, and thus, estimated p ow er and false p ositive r ate. T h is is particularly relev ant for some p opulation s amples with higher θ including s ome Nativ e American group s. In our analysis, we estimate the Y-haplotype frequency u pp er 95% confidence limit asymptoti- 9 cally , rather th an exactly , as ind icated in the Mye r s et al. metho d. This estimate ma y b e sufficient, but has greater err or than the exact confidence limit. F or very lo w Y-haplot yp e frequencies, the asymptotic estimate may b e lo we r than the tru e confidence limit, w hic h w ould lead to infl ated (an ti- conserv ativ e) LR Y . A study of the affect of different confidence limit estimates on fi n al outcomes w ould inform metho d c h oice. In this study , we hav e considered only complete genot yp es with no err ors or allelic drop out. It is not clear h o w allelic drop out wo u ld affect familial searc hing results, but this must b e explored b efore consid ering exten tion to lo w-template s amp les. The p robabilities we estimated with our sim u lations are n ecessarily approximate . Autosomal allele and Y-haplot yp e frequencies for v arious p opu lation samples are p o orly kno w n b ecause pub licly a v ailable databases are of limited size and are unav ailable f or many p opu lation groups. Neverthele ss, the grou p s for w hic h we hav e d ata in clude Afr ican Americans, who hav e relativ ely high genetic div ersity at the considered lo ci, and Nativ e Americans, wh o hav e r elativ ely lo w d iv ersit y , whic h suggests th at our results are applicable to other p opulations for which data are u na v ailable. A difference b et ween our analysis and the imp lemen ted My ers et al. metho d is the one or tw o- stage design. In the Mye rs et al. metho d, first an analysis is p erformed usin g only autosomal data and the top 168 matc hes are genot yp ed f or Y-haplot yp e and the cum u lativ e statistic X is computed only for these samples [30]. In our analysis w e simp ly compu ted the cum u lativ e X f or all samp les considered. An additional study of p ositiv e identificatio n of d istan t relativ es using the t wo-sta ge metho d in the con text of a realistic database w ould pr o vide more r ealistic rate estimates, h ow ev er this sort of analysis is hindered by lac k of access to forensic databases [53]. Su ch a study is u nlik ely to sho w substantial ly different results than those presented h ere since the pairs of in dividuals w e p ositiv ely identify as first d egree relativ es are lik ely to app ear r elated and rank ab o ve the 168 p erson threshold. W e also note that in this analysis we only consider the familial searc h ing metho d of Myers et al. . T o our k n o wledge, at the writing of this manuscript, the My ers et al. metho d is the only explicit proto col a v ailable and the curr ent standard in the field [54, 55 ]. Although the absolute rates of iden tification w ill change according to th e metho d used, when considering LR-based approac hes, whic h ha ve b een sho wn to b e more effectiv e than allele-sharing metho ds [56], the trends we observ ed across p opulation samp les and close and distan t r elativ es will hold. Implic ations of spurious identific ation of distant r elatives Our fin dings confi r m that familial s earches carried out according to the Myers p rotocol do a go o d job of lo cating a relativ e if one is in the database. T hey also affirm that a searc h is unlik ely to retur n a f alse lead – in other w ord s, a matc h that app eared to b e r elated to th e crime scene source, bu t in fact was n ot. Ho w ever, w e hav e sh o wn th at if there is a m ore distant relativ e in the database, that p erson ma y h a v e u p to a 42% c hance of b eing r etur ned as a lead and erroneously lab eled as a first degree relativ e of the crime scene source (T able 4). The p ossibility that the lead is a more remote relativ e of th e source might not b e a concern if in vestig ators could easily ascertain wh at kind of lead they had b een giv en. But the Myers proto col can do n o more than alert inv estigators that the sour ce ma y b e a relativ e of the ind ividual in the database; it d o es not tell in vestig ators whic h relativ e or the closeness or kind of r elatio n . I n an y case, once a searc h returns a lead, law enf orcemen t must und ertak e further inv estigation to lo cate the actual s ou r ce. It is th e scop e and impact of th e follo w-up inv estigati on that, in light of our results, m ay b e troubling. Before our r esearc h iden tified the p ossibilit y that a familial searc h might ident ify distant relativ es and err oneously lab el them as fi rst degree relativ es of the source, it ma y b e that la w enforcemen t simply assumed that all leads were to a fi r st d egree relativ e, b ecause that is what the searc h is 10 structured to fi nd. Accordingly , if fu rther inv estigation did not iden tify a sour ce from among the lead’s first d egree relativ es, then officers lik ely assu med that the problem w as the lead, rather than the d epth of their inv estigation. In ligh t of our results, ho wev er, la w enforcemen t may no w recognize that a lead that fails to reve al a source among first degree relativ es m a y still b e a go o d lead, it is only that the inv estigati on m ust extend to more remote b ranc hes of the f amily tree. T o illustrate, supp ose that la w enforcement conducts a familial search to find a burglar. F ol- lo wing the Mye r s pr otocol, the search returns a lead to the p rofile of K, a kno wn offender in the database. Con ven tional wisdom holds that the burglar is lik ely a br other or the father of K, and so la w enforcement officers initiate their inv estigation accordingly . T hey ascertain the id entify of K’s father and any brothers , and c h ec k their ages and criminal records. T hey determine wh ether the father or brothers w ere in the area of the b urglary at the time it o ccurr ed, used cell phones or credit cards around that area, or otherwise engaged in susp icious b eha v ior. Ultimate ly , they migh t surreptitiously attempt to obtain DNA samples for testing from members of K’s immediate family – say by p osing as restauran t p ersonnel or collecting up a half-eaten lu nc h. In some num b er of cases, one of those immediate family mem b ers will matc h , and the bu rglar will b e f ou n d. But if no matc h is made, then inv estigato r s a ware of our researc h may conclude three things: that the f amilial searc h wa s almost certainly effectiv e, that the probabilit y that the lead was a bad lead is low, and that leads that d o not initially p an out are like ly to ha ve faltered only b ecause the source is a m ore distant relativ e than in v estigators presu med. In other w ord s, th e source is not a brother or father, but instead is a cousin, second cousin, uncle, half-sibling, or ev en half-cousin. A t that p oint the officers ha ve t wo choic es. Th ey ma y limit themselv es to the f ollo w -up they ha ve already condu cted with the fi rst degree relativ es and simply stop their inv estigation or, more lik ely , they ma y s im p ly widen the s cop e of their inv estigation, and start pursu ing all second-degree relativ es of the lead. Our r esearc h thus suggests t wo unant icipated like ly outcomes of familial searc h p olicies. Firs t, in vestig ations ma y wr on gly target th e immediate families of kno wn offenders, b ecause officers mis- tak enly b eliev e that their lead is a fir s t-degree relativ e. Second, inv estigatio n s ma y ultimately pr ob e far more d eeply than initially imagined, b ecause once officers are convinced th at th e source cannot b e found among fir s t d egree relativ es, they will widen their net of in ve stigation to includ e more distan t relations. Both of these consequences exacerbate the numerous ethical problems presen ted b y familial searc h ing. First, familial searc hes will affect a greater num b er of p ersons. There is n o wa y for inv estigato r s to know f rom the start that a lead is a d istan t, rather th an immediate, relativ e of the source. Th u s suspicion m a y n o longer b e restricted to a father and small n u m b er of sib lin gs – one of whom is lik ely to b e the crim e scene samp le source – but instead will fall up on inn o cen t immediate family mem b ers and a muc h larger num b er of second-degree relativ es. Th e greater the num b er of p ersons in volv ed, and the less likely that one of them is in fact the p erp etrator, the more su c h inv estigatio ns ma y b egin to feel lik e a fishing exp edition rather than a r easonable s earc h. T his is particularly true giv en that any inv estigated family mem b er is, by d esign, a mem b er of the family whose DNA is not already in the database as a r esu lt of wrongdoing. Second, follo w-u p inv estigatio n s ma y pro ve m ore in tru siv e and yet less effectiv e. Iden tification of more d istan t r elativ es requir es more complicated in vesti gation th an d o es determining a lead’s immediate family mem b ers. F or ins tance, the known offender will lik ely hav e pro v id ed information ab out immediate relativ es in the course of the criminal case that is readily av ailable, suc h as in a bail rep ort, corrections dossier, or probation fi le. But suc h sour ces are muc h less lik ely to conta in information ab out secondary relativ es, and th u s simply comp osing the list of p oten tial su sp ects could requir e more aggressiv e inv estigation. Moreo ver, the difficulty in accurately mapping more distan t familial relations might lo we r the already lo w su ccess rate of familial searches. Although 11 a lead ma y in fact b e a relativ e, it ma y simply b e to o difficult to lo cate th e actual s ou r ce if that p erson is a half-cousin or other distan t relation. Third, widenin g the p o ol intensifies th e threat that familial searc hing p oses to ou r u nderstand- ings of families as constru ctions of so cial, not biological , realities. A p erson ma y hav e hundreds of “cousins” b ut only a handfu l of biologica l cousin s. Inv estigato r s ma y either ignore the difference and unn ecessarily in vestig ate th ose non-biological relatio ns, or else engage in p oten tially intrusiv e questioning or activit y (such as DNA sampling) to differentia te b et we en proffered and actual rela- tions. Probing secondary b iological relationships m igh t also dredge up painful family exp eriences of d eath, unkn own b iological ties, or pr evious partners. And , to the exten t th at some advocates of familial searc h ing hav e justified the practice on grounds akin to “crime run s in families,” such argumen ts m ay b e less d efensible wh en more remote connections are in volv ed. Finally , to the exten t that our findings suggest that familial searc hes ma y in fact necessitate in vestig ating a greater n um b er of p eople with a greater degree of intrusiv eness, that consequence is particularly troublin g in that it will b e sp ecially visited on certain racial groups. It has b een w ell do cument ed that familial searc hing is apt to disprop ortionately affect African American families, due to the greater representa tion of those groups in DNA databases and the h igh rate of in tra- racial pro creation. Limiting inv estigations to the imm ed iate family mem b ers of known offenders at least minimizes the in tru sion on inno cen t r elativ es within those racial grou p s. But if more distan t relations are in cluded, the w eb of p oten tial “genetic susp ects” b ecomes still br oader, and ma y effectiv ely encompass entire comm unities. It tak es only one mem b er of a large and v aried family tree to rend er eve r y father, brother, half-brother, cousin, half-cousin, uncle, nephew and so on vu lnerable to scru tin y and surreptitious samplin g by la w enf orcemen t officers. Of course, it is alwa ys p ossible to limit, for p r actica l or ethical reasons, the range of p ermissible follo w-up in vesti gation to first degree r elativ es in familial searc h cases as a matter of p olicy . Such an approac h migh t b e sensible f r om a practical p ersp ectiv e in light of the difficulty in iden tifying and inv estigati ng more remote relativ es, and the heighte n ed ethical concerns. It would also ensu re that an y sp urious leads – of wh ic h, gran ted, there are exp ected to b e few – would n ot first generate highly in v asiv e and costly inv estigations. Whatev er the case, our r esearc h suggests that as states and lo calities deb ate the virtues of familial searching and craft p olicies to go vern law enforcemen t, it wo u ld b e w ise to consid er terms delimiting th e scop e of p oten tial follo w -up inv estigatio n with regard to degree of relatedness. Ac kno w ledgmen ts W e are immensely grateful to the individ uals w hose DNA samples were used in this study , without wh ic h none of this work would b e p ossible. W e thank Kirk Lohmueller for his v aluable discussions on th ese topics. Supp orting Information Legends File S1, T ables S1-5 12 References [1] F. Bieb er, C. Brenn er, D. Lazer, Finding criminals through DNA of their relativ es, Science 312 (2006 ) 1315– 1316. [2] H. Greely , D. Riordan, N. Garrison, J. Mounta in , F amily ties: The u se of DNA offender databases to catc h offenders’ kin , J ournal of La w, Medicine, and Ethics 34 (2006) 248–2 62. [3] J. Curran, J. Buc kleton, Effectiv eness of familial searc hes, Science and Justice 48 (2008) 164– 167. [4] R. Williams, P . Johnson, Inclusiv eness, effectiv eness and intrusiv eness: Issues in the dev eloping uses of dn a profiling in su pp ort of crimin al inv estigations, The J ournal of La w , Medicine, and Ethics 33 (2005) 545–55 8. [5] E. Murphy , Relativ e d oubt: Familial searc hes of DNA databases, Mic higan Law Review 109 (2011 ) 291–349. [6] C. Gersha w, A. S c hw eighardt, L . Rourke, M. W allace, F orensic utilizatio n of familial searc hes in DNA databases, F orensic Science International: Genetics 5 (2011) 16–20. [7] K. O ’Connor, E. Butts, C. Hill, J. Butler, P . V allone, Ev aluating the effect of additional forens ic lo ci on lik eliho o d ratio v alues for complex kinship analysis, in : 21st In ternational Symp osium on Human Identi fication, F amilial Searc h W orksh op , 2010, citing Ch ris Maguire, formerly of the F orensic Science Service. [8] S. Rushton, F amilial searching and predictive DNA testing f or forensic purp oses: A review of laws and practi c e s july 2010. URL htt p://dnapr oject.co.z a/new_dna/wp- content/uploads/2011/03/Report- Familial- S earching- a n d - [9] Netherlands Ministry of Securit y and Justice, Senate agrees to DNA relationship test, 22 No v 2011. URL htt p://www.g overnment. nl/documents- and- p ublications/press- releases/2011/11/23/senate- a g r e [10] Netherlands Ministry of S ecurit y and J ustice, Ove rview of acts th at will ente r int o effect on 1 april 2012, 3 Ap ril 2012. URL htt p://www.g overnment. nl/documents- and- p ublications/press- releases/2012/04/02/overview - [11] Statemen ts of Lisa C ampb ell & Constable Derek Egan, b efore S tand ing Committee on Public Safet y and Na t i o n a l (Discussing inabilit y to make familial matc hes, p ressure to do so, and p riv acy-related con- cerns against) Canadian in ve stigators did solve one case b y ev aluating t w o samples offered v oluntarily and determining that a relativ e w as the like ly p erp etrator. Th ere h a v e b een some recen t efforts to authorize familial s earches in Canad a. URL htt p://www2. parl.gc.ca /HousePublications/Publication.aspx?DocId=3702024&Language=E&Mod [12] S. & Marp er v. United Kin gdom, Eur. Ct. H.R. 1581 (2008). URL ht tp://www.b ailii.org/ eu/cases/ECHR/2008/1581.html [13] N. Ram, F ortuit y and forensic familial identificatio n , S tanford La w Review 63 (2011) 751. [14] In terim plan for release of information in the even t of a ‘p artial match’ at n dis (July 20, 2006). [15] H.R. 3361, Utilizing DNA Technolog y to S olv e Cold Cases Act of 2011. 13 [16] S.Ct., 2013 WL 2371466, No. 12-207 (June 3, 2013) . [17] Md. Co de Ann., P ub. S afet y s 2-506 (d ) (West 2010). [18] D.C. Co de s 22-41 51 (2010). [19] Council for Resp ons ib le Genetics, State rules on partial/familial searc h ing, although the map do es not s ho w New Y ork in the inadverte n t matc h category , the state h as recen tly authorized only that form of rep orting. URL ht tp://www.c ouncilforr esponsiblegenetics.org/dnadata/usa/usa2.html [20] California Departmen t of Justice, Division of La w Enforcement, In formation bulletin no. 2008- BFS-01, DNA partial matc h (crime scene DNA profile to offender) Policy (2008). [21] J. Rosen, Genetic surveil lance for all, Slate. [22] E. Nak ashima, S. Hsu, U.S . to expand collection of crime su sp ects’ DNA: Policy adds p eople arrested b ut not con victed, W ashington Post. [23] J. Butler, Adv anced T opics in F orensic DNA Typing: Metho dology , Academic P r ess, 2012. [24] K. Konzak, F amilial searc hing: A practical & effectiv e approac h : Californias exp erience, in: 22nd International S ymp osium on Human Iden tification, F amilial Searc h W orkshop, 2011. [25] T. Hic ks , F. T aroni, J. Curran, J . Buckle ton, V. C astella, O. Ribaux, Use of DNA pr ofiles for in vesti gation using a sim ulated national DNA database: Part I I. Statistical and ethical considerations on familial searc hin g, F orensic S cience International: Genetics 4 (2010 ) 316– 322. [26] N. Garrison, R. Rohlfs, S. F u llerton, F orensic familial searc hing: S cien tific and so cial im p lica- tions, Nature Reviews Genetics 14, in press. [27] T. Reid, M. Baird, J. Reid, S. L ee, R. Lee, Use of siblin g pairs to determine the familial searc hing efficiency of forensic databases, F orensic Science I nternational: Genetics 2 (200 8) 340–3 42. [28] D. Grimm, The d emographics of genetic sur v eillance: Familial DNA testing and the Hispan ic comm un ity , Columbia La w Review 107 (2007) 1164–1 194. [29] 60 Min u tes, A n ot so p erfect m atc h (Marc h 2007). URL ht tp://www.c bsnews.com /stories/2007/03/23/60minutes/main2600721.shtml [30] S. My ers, M. Timke n , M. Piucci, G. Sims, M. Greenw ald, J. W eigand, K. Konzak, M. Buoncris- tiani, Searc h in g for firs t-degree familial relationships in California’s offend er DNA database: V alidation of a likeli ho o d ratio-based approac h, F orensic Science International: Genetics 5 (2011 ) 493–500. [31] E. Stein b erger, G. Sims, Finding criminals through the DNA of their relativ es – Familial searc hing of the California offender DNA database, Prosecutor’s Brief 31 28. [32] H. W est, W. Sab ol, Prisoners in 2007, T ec h . Rep . 3, Bureau of Justice S tatistics (2008). [33] B. Budowle, T. R. Moretti, Examp les of STR p opulation databases for CODIS and casewo r k, 9th International Sym p osium on Human Identi fication 1 (1998) 64–73. 14 [34] R. Dalton, T r ib e b lasts ‘exploitation’ of blo o d samples, Nature 420 (2002) 111. [35] D. Wiw char, Nuu-c h ah-n ulth blo o d returns to w est coast, Ha-Shilth-Sa. [36] M. Mello, L. W olf, T he Ha v asupai I n dian trib e case – lessons for researc h in volvi ng stored biologic samp les, Th e New England J ournal of Medicine 363 (2010 ) 204–207 . [37] Asociaci´ on ANDES, Genographic pro ject hun ts the last of the Incas, ANDES C omm un iqu´ e. [38] L. Arb our, D. Co ok, DNA on loan: Issues to consider wh en carrying out genetic researc h wtih Ab original families and communities, Communit y Genetics 9 (2006) 153–160 . [39] S. Goering, S. Holland, K. F ry er-Ed w ards , T ransforming genetic researc h p ractices with marginalized communities: A case for resp onsive ju stice, Hastings Center Rep ort 38 (2008) 43–53 . [40] J. And erson, Commen tary on implications of the Genographic Pro ject, In ternational Journ al of Cu ltural Prop erty 16 (2009) 213–217. [41] J. Ka ye , C. Heeney , N. Ha wkin s, J. d e V ries, P . Bo ddington, Data sharing in genomics – re-shaping s cien tific pr actice , Nature Reviews Genetics 10 (2009) 331–3 35. [42] R. McIness, 2010 presiden tial add ress: Culture: The silent language geneticists must learn – genetic researc h with In digenous p opulations, American Journ al of Hu man Genetics 88 (2011) 254–2 61. [43] Applied Biosystems, YFiler haplot yp e database. URL ht tp://www6. appliedbio systems.com/yfilerdatabase/ [44] Nati onal Researc h Cou n cil: Committee on DNA forens ic science, The ev aluation of forensic DNA evidence, National Academy Press, 1996. [45] J. Buc kleton, C . T riggs, F orensic DNA Evidence Int erpretation, CRC Press, 2005, C h. Relat- edness. [46] B. W eir, A. Anderson, A. Help er, Genetic relatedness analysis: mo dern data and n ew c hal- lenges, Nature Reviews Genetics 7 (2006) 771–7 80. [47] Scien tific W orking Group on DNA Analysis Metho ds (SWGD AM), Y-c hr omosome short tan- dem rep eat (Y-STR) inte r pretation guid elines, F orens ic Science Comm u nications 11 (2009) 1–5. [48] FBI, CODIS-NDIS statistics (Jan u ary January 2012). URL ht tp://www.f bi.gov/abo ut- us/lab/codis/ndis- s tatistics [49] California Departmen t of Corr ections and Rehabilitation, T otal institution p opu lation, offend- ers by ethnicit y and gend er, Prison Censu s Data. [50] United States Censu s Bureau, S tate and coun t y Quic kFacts. URL ht tp://quick facts.cens us.gov/qfd/states/06000.html [51] R. R oh lf s , S. F ullerton, B. W eir, F amilial identificat ion: Population structure and relationship distinguishabilit y , PLoS Genetics 8 (2012) e1002469. 15 [52] K. Slo oten, R. Meester, F orensic iden tification: Database lik eliho o d ratios and familial DNA searc hing, arXiv 1201 (2012) 4261v3 . [53] D. Krane, V. Bahn, D. Balding, B. Barlo w, H. Cash, B. Desp ortes, P . D’Eustac h io, K. Devlin, T. Do om, I. Dror, S. F ord, C. F unk, J. Gilder, G. Hampikian, K. In man, A. J amieson, P . Kent, R. Kopp l, I. K orn field, S. K rimsky , J. Mno okin, L. Mueller, E. Murphy , D. Pa oletti, D. Pet r o v, M. Ra ymer, D. Risinger, A. Roth, N. Rudin, W. Shields, J. Siegel, M. Slatkin, Y. Song, T. Sp eed, C. S p iegelman, P . Su lliv an, A. Swienton, T. T arp ey , W. Thompson, E. Un gv arsky , S. Z ab ell, Time for DNA d isclosure, S cience 326 (2009) 1631–1632 . [54] K. O’Connor, Introdu ction to f amilial searching (2011). URL ww w.cstl.nis t.gov/strb ase/pub_pres/OConnor_Promega2011.pdf [55] Global Priv acy and Inform ation Qu alit y W orking Group (QPIQWG) , An introd uction to familial DNA searc hing for state, lo cal, and tribal ju stice agencies (2011). URL ht tp://www.i t.ojp.gov/ docdownloader.aspx?ddid=1698 [56] D. Balding, M. Kra wcza k, J. Buc kleton, J. Curran, Decisio n -making in familial database searc hing: KI alone or n ot alone?, F orens ic Science International: Genetics 7 (2012) 52–54 . 16 Figure Legends Figure 1: Di stributions of the test statistic X , de fined in (4) , for sibling te s t for indiv iduals who are siblings (solid red), parent- off springs (solid black), half-sibs (dashe d bl ac k ), cousins (dashdot blac k ), and second cousins (dotted black). The p opulation sample indiv iduals are sam pled from is along the top and the assumed p op sample i s along the side. Figure 2: Positive ide n ti fication rates across different true relationships of indi viduals si mu lated from different sample p opulations Vietnamese American (red circles), African American (orange trian- gles), Europ ean A merican (purple pluses), Latino American (blue exe s), and Native American (green diamonds); le ft plot is for sibli ng test, right for parent test 17 T ables T able 1: F alse p ositive parent- off spring identification rates b etw een pai rs of unrelated i ndividuals si m - ulated from all pairs of p opulation sam pl es. Vietnamese African Europ ean Latino N ativ e American American American American Amer ican Vietnamese American 8 . 2 × 10 − 7 5 . 0 × 10 − 9 1 . 5 × 10 − 8 < 5 . 0 × 10 − 9 < 5 . 0 × 10 − 9 African American 6 . 5 × 10 − 8 < 5 . 0 × 10 − 9 < 5 . 0 × 10 − 9 < 5 . 0 × 10 − 9 Europ ean American 1 . 5 × 10 − 7 1 . 5 × 10 − 8 1 . 0 × 10 − 8 Latino American 1 . 3 × 10 − 7 5 . 0 × 10 − 9 Nativ e American < 5 . 0 × 10 − 9 T able 2: F alse p ositive sibli ng identification rates b et ween pai rs of unrelated indivi duals simulated from all pairs of p opulation sam ples. Vietnamese African Europ ean Latino N ativ e American American American American Amer ican Vietnamese American 1 . 1 × 10 − 5 < 5 . 0 × 10 − 9 1 . 0 × 10 − 8 5 . 0 × 10 − 9 < 5 . 0 × 10 − 9 African American 1 . 7 × 10 − 7 < 5 . 0 × 10 − 9 5 . 0 × 10 − 9 1 . 0 × 10 − 8 Europ ean American 1 . 7 × 10 − 7 1 . 5 × 10 − 8 4 . 0 × 10 − 8 Latino American 4 . 3 × 10 − 7 2 . 0 × 10 − 8 Nativ e American < 5 . 0 × 10 − 9 T able 3: P arent-offspring test i den tification rates for di ff erent Y-sharing rel atives and p opulation sam- ples Vietnamese African Europ ean Latino Nativ e American American American American American paren t-offspr ing 0.9974 58 0.9893 36 0.987365 0.9881 30 0.9988 09 sibling 0.2636 59 0.2440 48 0.255853 0.2484 39 0.3483 73 half-sib 0.0561 35 0.0457 46 0.050528 0.0470 72 0.1050 56 cousin 0.0093 11 0.0064 51 0.007765 0.0070 39 0.0271 39 half-cousin 0.0033 37 0.0020 19 0.002506 0.0020 95 0.0127 16 second cousin 0.0019 71 0.0009 97 0.001423 0.0011 45 0.0085 80 T able 4: Sibling test identification rates for different Y-sharing relatives and p opul ation sample s Vietnamese African Europ ean Latino Nativ e American American American American American sibling 0.89156 6 0.819365 0.7930 25 0.798273 0.9 25786 paren t-offspr ing 0.9070 37 0.8133 99 0.767383 0.7773 60 0.9429 95 half-sib 0.3038 88 0.1635 25 0.138446 0.1401 61 0.4235 58 cousin 0.0995 29 0.0334 60 0.028376 0.0279 85 0.1816 87 half-cousin 0.0444 57 0.0104 45 0.009258 0.0089 78 0.1006 43 second cousin 0.0271 39 0.0049 34 0.004582 0.0043 32 0.0707 61 18 0.0 0.2 0.4 0.6 0.8 1.0 parent−offspring test true relationship positiv e identification rate second cousins half cousins cousins half− siblings siblings parent− offspring Vietnamese Am. African Am. European Am. Latino Am. Nativ e Am. 0.0 0.2 0.4 0.6 0.8 1.0 sibling test true relationship positiv e identification rate second cousins half− cousins cousins half− siblings parent− offspring siblin gs Vietnamese Am. African Am. European Am. Latino Am. Nativ e Am. 0.0 0.1 density Vietnamese Am. 0.0 0.1 density African Am. 0.0 0.1 density European Am. 0.0 0.1 density Latino Am. 0.0 0.1 density −10 0 10 20 log(LR) −10 0 10 20 log(LR) −10 0 10 20 log(LR) −10 0 10 20 log(LR) −10 0 10 20 log(LR) Native Am. assumed population sample Supp orting Information F ile S1 The influence of relativ es on the efficiency and error rat e of familial search ing Rori V. Rohlfs a , Erin Mur p h y b , Y un S. S ong c,d , Mont gomery Slatkin a a Department of Integrative Biolo gy , Univ ersity of C a lifornia, Berkeley , CA 9 4720, USA b School o f Law, New Y or k Universit y , New Y or k, NY 10012 , USA c Computer Science Divisio n, Universit y of Califor nia, Berkeley , CA 94720 , USA d Department of Statistics, Universit y of California, Berkeley , CA 94 720, USA Suppor ting T ables T able S1: Normalized California census an d p rison p opu lation frequencies. sim u lated p opulation Asian African American Europ ean American Latino American Nativ e American Census p opulation .133 .0633 .410 .384 .0102 Prison p opulation .00626 .303 .268 .413 .00940 Note: W e mak e use of these normativ e racial categorical constructs to estimate relev ant p opulation- sp ecific identificati on rates. Ho wev er, it’s clear that members hip in these categories is not mutually exclusiv e. By n ature, assumptions must b e made in the collec tion and tabulation of this sort of data. F ur ther, as with all collect ed so cial data, some groups ma y b e u nder or o v er-repr esen ted in data collection, and categorica l resu lts are sub ject to b iases of rep orting metho d (self-iden tified, inferred, etc.) (Spade and Rohlfs, in r eview ). T able S 2: Pro jected p ercen t of false parent-offspring leads wh ic h in vo lv e at least one ind ividual from eac h p opu lation sample sim u lated p opulation total FPR Vietnamese American African American Europ ean American Latino American Nativ e American Census p opulation 5.73e-0 8 28.3 0.560 3 8.5 38.59 0.114 Prison p opulation 3.84e- 08 0.182 1 6.3 25.3 62. 9 0.122 T able S3: Estimated p ercent of false sibling identificat ions wh ic h in vo lv e at least on e individ ual from eac h p opu lation sample sim u lated p opulation total FPR Vietnamese American African American Europ ean American Latino American Nativ e American Census p opulation 3.01e-0 7 67.9 0.266 1 0.6 22.3 0.0849 Prison p opulation 1.06e- 07 0.459 1 5.2 13.5 73. 1 0.199 T able S4: P arent-o ffsp ring test iden tification rates for d ifferen t Y-sharing r elativ es and p opu lation samples wh ere the set of reference Y-haplot y p es wa s do wn-samp led to 103 haplot yp es p er p opu- lation sample. The similarit y of these r esults to those with the fu ll set of Y-haplot yp es indicates that the v arying reference sample sizes are not driving p opulation-based differences in iden tification rates. Vietnamese American African American Europ ean American Latino American Nativ e American paren t-offspr ing 0.97 1109 0.9174 81 0.900600 0.9047 50 0.9814 29 sibling 0.2605 68 0.238 175 0.24 7218 0.2401 25 0.346 432 half-sib 0.0520 82 0.037 330 0.03 9416 0.0374 30 0.099 234 cousin 0.0081 84 0.004 503 0.00 5204 0.0045 43 0.024 529 half-cousin 0.0028 59 0.001 183 0.00 1447 0.0012 75 0.010 976 second cousin 0.0015 70 0.000 522 0.00 0741 0.0006 16 0.007 245 T able S5: S ibling test identificati on rates for differen t Y-sharing relativ es and p opulation samples where the set of reference Y-h ap lotypes w as down-sampled to 103 haplot yp es p er p opulation sample. The similarit y of these results to those with the fu ll set of Y-haplot yp es in d icates that the v aryin g reference sample sizes are not driving p opulation-based differences in iden tification rates. Vietnamese American African American Europ ean American Latino American Nativ e American sibling 0.7860 12 0.6773 11 0.636255 0.6451 79 0.8314 49 paren t-offspr ing 0.7504 33 0.595 312 0.52 1906 0.5367 82 0.815 689 half-sib 0.1664 90 0.070 316 0.05 5062 0.0567 29 0.240 527 cousin 0.0437 01 0.010 769 0.00 8384 0.0084 58 0.080 298 half-cousin 0.0169 70 0.002 642 0.00 2165 0.0021 75 0.038 323 second cousin 0.0093 40 0.001 130 0.00 0979 0.0009 28 0.024 955
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment