Spectral Clustering with Epidemic Diffusion
Spectral clustering is widely used to partition graphs into distinct modules or communities. Existing methods for spectral clustering use the eigenvalues and eigenvectors of the graph Laplacian, an operator that is closely associated with random walk…
Authors: Laura M. Smith, Kristina Lerman, Cristina Garcia-Cardona
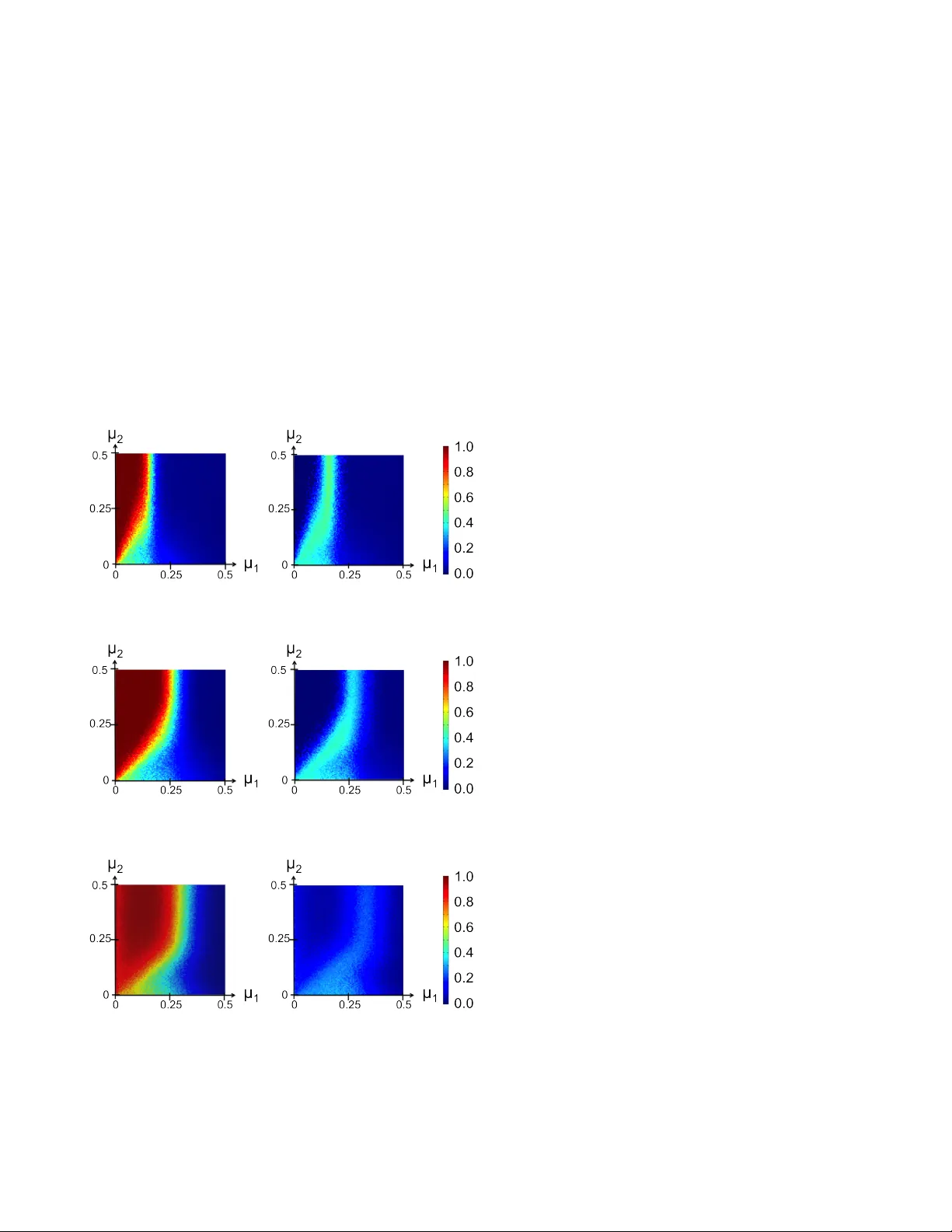
APS/123-QED Sp ectral Clustering with Epidemic Diffusion Laura M. Smith 1 , Kristina Lerman 2 , Cristina Garcia-Cardona 3 , Allon G. Percus 3 , and Rumi Ghosh 4 1. California State University, F ul lerton, California 2. USC Information Scienc es Institute, Marina del R ey, California 90292 3. Clar emont Graduate University 4. HP L abs, Page Mil l R o ad, Palo Alto, California (Dated: Septem b er 10, 2018) Sp ectral clustering is widely used to partition graphs in to distinct mo dules or communities. Ex- isting methods for sp ectral clustering use the eigenv alues and eigenv ectors of the graph Laplacian, an op erator that is closely associated with random walks on graphs. W e prop ose a new spectral partitioning metho d that exploits the properties of epidemic diffusion. An epidemic is a dynamic pro cess that, unlike the random walk, sim ultaneously transitions to all the neigh b ors of a giv en no de. W e sho w that the replicator, an operator describing epidemic diffusion, is equiv alent to the symmetric normalized Laplacian of a reweigh ted graph with edges rew eighted by the eigenv ector cen tralities of their incident nodes. Thus, more weigh t is giv en to edges connecting more cen tral no des. W e describe a metho d that partitions the no des based on the comp onen twise ratio of the replicator’s second eigenv ector to the first, and compare its p erformance to traditional sp ectral clus- tering tec hniques on synthetic graphs with kno wn communit y structure. W e demonstrate that the replicator giv es preference to dense, clique-lik e structures, enabling it to more effectively discov er comm unities that may b e obscured by dense intercomm unity linking. P ACS num b ers: 05.45.Xt, 89.75.Hc, 89.75.-k, 89.65.Ef, 89.75.Fb, 02.10.Ud I. INTR ODUCTION Graph partitioning is used in man y applications, in- cluding comm unity detection [1], image segmen tation [2], and data mining [3], where it is necessary to partition a graph into mo dules or clusters of similar, or similarly b eha ving, no des. Spectral partitioning uses the eigen- v ectors associated with the k smallest eigen v alues of the graph Laplacian matrix (or its normalized version) to partition the graph into k clusters [4–7]. Existing metho ds for spectral partitioning are closely asso ciated with random w alks on graphs. A random w alk is a sto c hastic dynamic pro cess where transitions take place from a no de to a random neigh b or of that no de, and it is describ ed by the (normalized) graph Laplacian. The existence of a go o d partition implies that random walks tak e a long time to reach a stationary distribution on the graph [2, 8], because they sp end a long time within a mo dule and seldom pass b et w een modules [9]. This forms a basis for ob jectiv e functions used to select which edges to cut so as to partition the graph, suc h as normalized cut and conductance, though these functions hav e trouble partitioning real-w orld graphs where man y inter-module edges obscure the underlying structure [1]. Epidemic diffusion is another t yp e of dynamic pro cess on a graph. An epidemic undergo es transitions simulta- neously to all the neighbors of a giv en node, rather than a single neigh b or, and is often used to mo del the spread of a virus or an innov ation through a so cial net work [10, 11]. Recen tly , Lerman and Ghosh in tro duced the replicator matrix [12], an analog of the graph Laplacian, to describ e epidemic diffusion on graphs. They used the replicator to simulate dynamics of synchronization in a net work of oscillators, showing that oscillators coupled via epidemic diffusion sync hronize into different structures than oscil- lators coupled via random walk-lik e diffusion. W e prop ose a metho d for sp ectral graph partition- ing based on epidemic diffusion. First, w e show that the replicator is equiv alent to the symmetric normalized Laplacian of a reweigh ted graph, where new edge weigh ts are the product of old edge weigh ts and the eigen vector cen tralities of the tw o end p oints. The eigenv ector cen- tralit y [13] of a graph is given b y the eigen vector corre- sp onding to the largest eigenv alue of the adjacency ma- trix. Therefore, edges linking central no des are given a higher w eigh t b y the reweigh ting scheme. The equiv alence b et ween the replicator and symmetric normalized Laplacian of a reweigh ted graph allows us to exploit well-kno wn relationships b etw een sp ectral clus- tering and graph partitioning. T o use the replicator for sp ectral partitioning, we give a computationally efficien t pro cedure that orders no des based on the comp onen t- wise ratio of the second to first eigenv ectors and selects a partition that minimizes a quality function computed on the rew eigh ted graph. This tends to preserve dense structures, since edges linking more central no des in suc h dense clusters are less likely to b e cut. W e study the p erformance of the prop osed sp ectral partitioning metho d using syn thetic graphs with known comm unity structure. W e demonstrate that sp ectral clustering based on epidemics leads to a b etter recov ery of ground truth communities than traditional metho ds based on the graph Laplacian, esp ecially in graphs that are more challenging b ecause of the presence of many edges b et ween clusters. Our w ork suggests that epidemic diffusion can b e a useful probe of graph structure, as it can illuminate properties of graphs that are distinct from those found by metho ds based on the random walk. 2 I I. SPECTRAL CLUSTERING An unw eighted graph G = ( V , E ), with vertices (or no des) V and edges (or links) E , can be represented by a | V | × | V | adjacency matrix A , with A ij = 1 if the edge ( i, j ) ∈ E , and A ij = 0 otherwise. By con v ention A ii = 0. W e consider undirected graphs, where A ij = A j i . The degree of no de i is defined as the n umber of edges incident on it, d i = P j A ij . Other useful constructs are D , a diagonal degree matrix where D ii = d i , and the iden tity matrix I . A. Graph Laplacian and Sp ectral Clustering The graph Laplacian matrix is defined as L = D − A . The eigen v alues and eigen vectors of L capture man y prop erties of the graph. In the simplest case, if the graph has k disjoin t comp onen ts, the k smallest eigen v alues of L are zero, and the asso ciated eigenv ectors are indicator functions assigning nodes to their resp ective cluster or comm unity [7]. Ev en if the k smallest eigen v alues are not all zero, their corresp onding eigenv ectors can b e used to partition no des into k clusters b y pro jecting these no des on to a subspace of the first k eigenv ectors and using stan- dard clustering tec hniques such as k -means [2, 5]. The simplest spectral clustering metho d, spectral bisection, partitions no des based on the v alues of the second eigen- v ector v of the adjacency matrix or the graph Laplacian. A splitting v alue c is used to divide the nodes into dif- feren t clusters based on whether v i < c or v i ≥ c [6]. A range of splitting v alues ha v e b een used, including zero, the median v alue within the v ector, the largest gap, and the v alue pro ducing the b est ratio cut, b est conduc- tance [14], or another measure. In practice, normalized versions of the graph Lapla- cian pro duce better results in sp ectral clustering appli- cations [3, 5]. Two examples are the symmetric normal- ized Laplacian L s = I − D − 1 / 2 AD − 1 / 2 and the random w alk Laplacian L rw = I − D − 1 A , so named b ecause the matrix of transition probabilities for a random walk on a graph is given by D − 1 A . B. Graph Cuts and Their Quality Measures In tuitively , a cluster is a set of nodes S ⊂ V that are more tigh tly connected to each other than to nodes out- side of the cluster. W e use ¯ S = V \ S to denote the complemen t of S , which consists of no des that are not in S . In order to bisect the graph into tw o disjoint clusters, one typically wan ts to minimize the n umber of cut edges b et ween clusters, E ( S, ¯ S ) = X i ∈ S,j ∈ ¯ S A ij , while maximizing cluster size, whic h may b e measured b y the n umber of no des it contains, | S | , or the sum of the degrees of the no des in the set, ν ( S ) = P i ∈ S d i , also called vol ume of the set. Sev eral functions hav e b een prop osed for measuring the quality of a graph cut. The b est kno wn of these are ratio cut R ( S ) and normalized cut N ( S ): R ( S ) = 1 | S | + 1 | ¯ S | E ( S, ¯ S ) (1) N ( S ) = 1 ν ( S ) + 1 ν ( ¯ S ) E ( S, ¯ S ) . (2) There is a relationship betw een graph cuts and sp ectral clustering. Deciding which edges to cut to optimize an y of these qualit y functions is an NP-complete problem. Sp ectral clustering solv es a relaxation of the problem, where the discrete indicator v ariables that assign no des to clusters b ecome contin uous. Although in general there are no useful b ounds for the appro ximation pro duced by this relaxation [7], in practice it often provides a simple and effective clustering metho d. Solutions to the relaxed optimization problem are given by the second eigen vector of the graph Laplacian L or the normalized graph Lapla- cian L s [6]. Relaxing ratio cut leads to sp ectral clustering using L , while relaxing normalized cut leads to sp ectral clustering using L s [2, 7]. Such relaxation methods hav e also been applied productively to the p opular modularity maximization metho d for comm unity detection [15, 16]. By analogy with sp ectral bisection [6], the leading eigen- v ector approac h assigns no des to clusters based on the sign of the comp onents of the leading eigenv ector of the mo dularit y matrix. C. Sp ectral Clustering and Random W alks There exists a further relationship b etw een sp ectral clustering, the partition quality function, and prop erties of random walks. A random walk on a graph is a sto c has- tic process where transitions take place to a randomly c hosen neigh b or of a giv en node. Cluster properties of the graph can b e expressed in terms of the transition matrix D − 1 A [17] of a random walk. Sp ectral clustering finds a partition suc h that a random w alk stays within the same cluster for a long time and seldom jumps b e- t ween clusters [2, 9]. Therefore, the presence of a go o d partition (low normalized cut v alue) implies that it will tak e a random walk a long time to reach its equilibrium distribution. I II. EPIDEMIC DIFFUSION ON GRAPHS An epidemic is a dynamic pro cess that sim ultaneously undergo es transitions to every neighbor of the current no de. Epidemics are used to mo del the spread of dis- ease [18] and innov ation [11] in so cial netw orks. Epi- demics differ from random walks in important wa ys. 3 First, rather than choosing a single neighbor to tran- sition to or “infect” as the random w alk do es, an epi- demic will attempt to “infect” every neighbor of a node. In a random walk, the probability of finding the w alker in a given lo cation is a conserv ed quantit y that diffuses through the graph, and the random walk transition ma- trix is a stochastic matric. Epidemics, on the other hand, replicate themselv es with each successful transmission, without follo wing a conserv ation law [12]. Lerman and Ghosh [12] introduced the replicator op- erator R = λ max I − A to describ e dynamics of syn- c hronization in a net work of no des coupled via epidemic diffusion. Here λ max is the largest eigen v alue of A , also kno wn as the epidemic threshold [19]. In this system, a dynamic v ariable u i asso ciated with node i can c hange its v alue based on the v alues of its neighbors according to: d u dt = − Ru , (3) where R replaces the Laplacian used in the analogous heat equation that gives the (diffusive) evolution of a random walk on a graph [20]. By construction, the repli- cator has a steady state given b y θ , the eigenv ector of A asso ciated with λ max : Aθ = λ max θ . θ is also known as the eigenve ctor c entr ality [13], and was introduced by Bonacic h to explain the imp ortance of actors in a so cial net work based on the imp ortance of the actors to which they were connected. Clusters of no des with similar v alues of the dynamic v ariable u emerge as the system of coupled no des ev olves to wards the steady state [12]. This motiv ates a commu- nit y detection metho d with no des classified according to the rate of conv ergence to their steady-state v alues. F or large time t , we approximate the solution to Eq. 3 using the tw o leading eigenv ectors θ and ψ of R , u i ( t ) ≈ c 1 θ i + c 2 e − λ 2 t ψ i = c 1 θ i 1 + c 2 c 1 e − λ 2 t ψ i θ i , where c 1 and c 2 are constants, and λ 2 is the second small- est eigen v alue of R associated with eigenv ector ψ , guar- an teed to b e nonzero if the graph is connected. Therefore, con vergence depends on ψ i /θ i , the comp onen twise ratio of the second to fir st eigen v ectors. Note that eigen v e ctors of R corresp onding to R ’s t wo smallest eigen v alues are the same as the eigen vectors of A corresp onding to A ’s t wo largest eigen v alues. A. Replicator as the Symmetric Normalized Laplacian of a Rew eighted Graph In a so cial net work, one migh t exp ect nodes of high “imp ortance” to attract other no des, resulting in com- m unities forming around no des with large eigenv ector cen trality v alues θ i . In this section w e propose a mo difi- cation of our graph, conv erting the unw eighted netw ork in to a weigh ted one where weigh ts are given b y the pro d- uct of the eigenv ector cen tralities of an edge’s end p oin ts: ˜ A ij = A ij θ i θ j . Moreo ver, we show that the replicator on the un weigh ted graph given b y A is in fact exactly equiv alent to the symmetric normalized Laplacian of the rew eighted graph giv en b y e A . In the rew eighted graph, the degree of no de i is given b y ˜ d i = X j A ij θ i θ j = θ i X j A ij θ j = λ max θ 2 i . F or con venience, define Θ as the diagonal matrix whose elemen ts are the comp onents of eigenv ector θ , i.e., Θ ii . Then, from ˜ A ij and ˜ d i ab o ve, e A = Θ A Θ and e D = λ max Θ 2 . (4) W e can no w write the symmetric normalized Laplacian of the reweigh ted graph: e L s = I − e D − 1 / 2 e A e D − 1 / 2 = I − 1 √ λ max Θ − 1 Θ A Θ 1 √ λ max Θ − 1 = I − 1 λ max A = 1 λ max R . Hence, R = λ max e L s . The equiv alence betw een epidemics and the diffusive pro cess of random w alks is at first surprising. Diffusiv e pro cesses conserv e the total amount of the substance dif- fusing, whereas no such conserv ation law holds for epi- demics [12]. The intuition for the equiv alence of the tw o pro cesses is the following. A no de’s eigenv ector central- it y giv es the num b er of paths connecting it to all other no des in the graph [21]; hence, the pro duct of eigen v ector cen tralities of a pair of no des captures how muc h of the substance is newly created when the epidemic follo ws the edge linking the pair. By enco ding the amount of non- conserv ation in edge reweigh ting, this sc heme allows the epidemic to b e reduced to diffusion. B. Qualit y Measure for the Replicator The equiv alence pro ved ab o ve allows us to exploit the prop erties of the symmetric normalized Laplacian, along with its relationship to graph partitioning, for epi- demic diffusion. Since the replicator is simply L s of the rew eighted graph e A , sp ectral clustering using the repli- cator corresp onds to a relaxation of normalized cut on this rew eighted graph. The appropriate measure for as- sessing graph cut quality with the replicator is therefore normalized cut on the reweigh ted graph e N ( S ). 4 C. An Illustrativ e Example W e use a simple example to highlight the differences b et ween traditional graph partitioning and one based on epidemics. Consider the graph in Figure 1, which sho ws a dense cluster connected through no de 6 to a sparsely link ed cluster. Such a configuration is common in so cial net works, where a high-degree hub linking different com- m unities may obscure communit y b oundaries. W e ex- p ect a go o d partition to group no de 6 with other no des in its clique. Ho wev er, the cut ( B ) that minimizes nor- malized cut ( N ( S )) groups no de 6 with nodes 1–5 and assigns nodes 7–11 to the other cluster. Multiple cuts minimize ratio cut ( R ( S )), including one that groups to- gether no des 3–5. No de 6 has the highest eigen vector cen trality . F ur- thermore, no des that b elong to the clique hav e higher cen trality v alues than other nodes. Consequen tly , in the r eweighte d graph, the edges linking node 6 to the rest of the clique are more “exp ensive” to cut, and no des 6–11 are group ed together b y the preferred cut ( A ) that min- imizes both the ratio cut e R ( S ) and the normalized cut e N ( S ) on the reweigh ted graph. The qualit y measures of the cuts are sho wn in the table in Fig. 1. By giving edges linking central no des a higher weigh t, epidemic- based graph partitioning thus preserves dense, clique-like structures. Accordingly , deleting these edges will hav e the greatest impact on reducing the spread of an epi- demic [22]. Qualit y Cut A Cut B Original gr aph R ( S ) 1.83 1.83 N ( S ) 0.528 0.417 R eweighte d gr aph e R ( S ) 11.4 32.3 e N ( S ) 0.747 0.778 FIG. 1. (Color Online)(Left) An example graph. The p ossible cuts are sho wn b y the dotted curv es A and B. (Right) Qualit y measures of cuts A and B on the original and reweigh ted graph. D. Efficien t Sp ectral P artitioning W e now describ e an efficient metho d for sp ectral clus- tering using epidemic diffusion based on sp ectral bisec- tion [6]. First, w e create a v ector v that is the comp onen- t wise ratio of the second eigen vector ψ to the first eigen- v ector θ of the operator R and sort its v alues. Next, we examine all N − 1 cuts in this ordering (where N = | V | ) and pick one corresp onding to the partition that mini- mizes an appropriate qualit y measure. The qualit y mea- sure we use with R is normalized cut on the rew eighted graph ( e N ( S )). W e compare the resulting partition with those pro duced b y applying an analogous splitting pro- cedure to L , with qualit y measure R ( S ), and L s , with qualit y measure N ( S ) (on the original graph). The prop osed optimization pro cedure is exhaustive, since it tests all N − 1 possible cuts within the ordering pro duced by v . It may seem that there w ould be some loss in accuracy from restricting our searc h to cuts in a one-dimensional pro jection, rather than searc hing ov er the entire subspace spanned by the first tw o eigenv ectors θ and ψ . Ho wev er, it has b een observed [2, 23] that the comp onen twise ratio of the second to first eigenv ector of L s is precisely equal to the second eigenv ector of the random walk Laplacian L rw , whose first eigenv ector is a constan t v ector. Th us, our algorithm is effective b ecause it is a computationally efficien t pro cedure for finding the b est normalized cut in the tw o-dimensional eigenspace of e L rw , i.e., L rw on the reweigh ted graph. The adv antages of using L rw in sp ectral clustering are discussed in [7]. IV. EV ALUA TION ON SYNTHETIC GRAPHS W e use syn thetic graphs to gain b etter insigh t into the differences b etw een op erators L , L s , and R and the characteristics of graphs for which differen t op era- tors find b etter solutions. Lancic hinetti and F ortunato ha ve prop osed an algorithm to generate random graphs with known hierarchical comm unity structure [24]. The N nodes are divided into macro communities, which are themselv es comp osed of micro communities, and then edges b et ween no des are created using mixing parame- ters µ 1 and µ 2 . The parameter µ 1 designates the fraction of a node’s edges that will connect to no des in a differ- en t macro comm unity , and µ 2 giv es the fraction of edges that will connect to no des in a differen t micro comm u- nit y within the same macro communit y . The remaining (1 − µ 1 − µ 2 ) fraction of edges link to other nodes within the same micro and macro communities. These b enc h- mark net w orks allo w us to systematically explore th e p er- formance of different sp ectral clustering approaches. FIG. 2. Eac h pixel represen ts the mean av erage clustering co efficien t (left) and the standard deviation (right) across 1 00 runs for fixed ( µ 1 , µ 2 ). Using soft w are av ailable on [25], we generated 100 graphs for each set of parameter v alues. W e to ok N = 5 100 with t wo macro communities. W e v aried µ 1 and µ 2 b et ween 0 and 0 . 5. The a verage clustering co efficient ranged betw een 0.23 and 0.6421, suggesting that the syn- thetic graphs ha ve properties similar to those often found in real world netw orks [26]. W e partition each benchmark graph using L , L s , and R b y minimizing their respective quality measures. T o ev aluate the resulting partitions, we use the Normalized Mutual Information (NMI) measure [27], which compares the partition to the ground truth comm unities. When the v alue of this measure is 1.0, the partitioning metho d has successfully recov ered the underlying comm unity struc- ture. W e calculate the av erage and standard deviation of the NMI scores for a fixed set of parameters and display the results in Figure 3. Laplacian L : Ratio Cut Symmetric Normalized Laplacian L s : Normalized Cut Replicator R : Normalized Cut (reweigh ted) FIG. 3. NMI scores for minimizing the resp ectiv e op erators’ qualit y measure. Each pixel represents the av erage (left) or standard deviation (right) NMI score across 100 runs for fixed ( µ 1 , µ 2 ). As the prop ortion of a no de’s edges that connect to individuals in the opposite comm unity , µ 1 , increases, it b ecomes more difficult to divide the netw ork in to the correct comm unities. W e find that L and L s giv e b et- ter results when µ 1 is small (very few links betw een the t wo comm unities). As µ 1 increases, R dominates with a higher NMI score. Additionally , R has the low est stan- dard deviation of the three operators, indicating a consis- ten t performance in identifying the underlying comm u- nities. V. CONCLUSION Sp ectral partitioning traditionally uses the graph Laplacian. In this paper, w e hav e introduced a method for spectral partitioning using the replicator, an op erator describing epidemic diffusion on graphs. W e hav e sho wn that this op erator is equiv alent to the symmetric nor- malized Laplacian on a different graph, where edges are rew eighted according to the eigenv ector cen trality mea- sure. By reweigh ting the edges, a higher weigh t is placed on globally imp ortant nodes. Thus, this metho d tends to preserve cliques and other dense clusters. W e hav e in tro duced a sp ectral bisection approach based on the component wise ratio of the second to the first eigenv ector of R , choosing the partition b y splitting the sorted v ector so as to minimize an appropriate qualit y measure. Comparing the performance of different meth- o ds on synthetic graphs with known communit y struc- ture, w e hav e shown that sp ectral partitioning using the replicator is b etter able to reco ver the underlying com- m unity structure, esp ecially in cases where more edges b et ween the tw o macro communities make it more diffi- cult for the Laplacian and symmetric normalized Lapla- cian to iden tify comm unities. By reweigh ting the edges using eigenv ector cen tralit y , the replicator assigns more imp ortance to cen tral nodes. Thus, the edges that pass b et ween clusters are giv en less influence if they do not link no des of high centralit y . By limiting the cuts to influen tial edges, the metho d leads to a more accurate reconstruction of the communit y structure. Ac knowledgemen ts The authors are grateful to Arjuna Flenner, Yv es v an Gennip, and Blak e Hun ter for many instructiv e con ver- sations and suggestions. KL and RG are also greatly in- debted to Shanghua T eng, whose insights and en thusiasm con tinue to inspire them. This work has been funded by the Air F orce Office of Scientific Researc h under con tracts F A9550-10-1-0569 and F A9550-10-1-0102, D ARP A under Con tract No. W911NF-12-1-0034, the National Science F oundation under grant 1217605, and the Department of Energy Office of Science Adv anced Computing Research (ASCR) program in Applied Mathematics. 6 [1] J. Lesk ov ec, K. J. Lang, A. Dasgupta, and M. W. Ma- honey , in Pr oc e e dings of 17th International World Wide Web Confer enc e (WWW2008) (2008). [2] J. Shi and J. Malik, IEEE T ransactions on Pattern Anal- ysis and Machine Intelligence 22 (8), 888 (2000). [3] A. Bertozzi and A. Flenner, Multiscale Mo deling & Sim- ulation 10 (3), 1090 (2012). [4] F. R. K. Ch ung, Sp ectr al Gr aph The ory , vol. 92 of CBMS R e gional Confer enc e Series in Mathematics (American Mathematical So ciet y , 1996). [5] A. Y. Ng, M. I. Jordan, and Y. W eiss, in A dvanc es in Neur al Information Pr o c essing Systems (2001), v ol. 14, pp. 849–856. [6] D. A. Spielman and S.-H. T eng, Linear Algebra and its Applications 421 (2-3), 284 (Mar. 2007). [7] U. von Luxburg, Statistics and Computing 17 (4), 395 (2007). [8] M. Jerrum and A. Sinclair, in Pr o c. ACM Symp osium on The ory of Computing (1988), STOC ’88, pp. 235–244. [9] M. Rosv all and C. T. Bergstrom, Pro c. National Academ y of Sciences 105 (4), 1118 (2008). [10] R. M. Anderson and R. Ma y , Infe ctious dise ases of hu- mans: dynamics and contr ol (Oxford Univ ersit y Press, 1991). [11] E. M. Rogers, Diffusion of Innovations, 5th Edition (F ree Press, 2003). [12] K. Lerman and R. Ghosh, Phys. Rev. E 86 (026108) (2012). [13] P . Bonacich and P . Llo yd, So cial Netw orks 23 (3), 191 (2001). [14] R. Kannan and S. V empala, Sp e ctr al Algorithms , v ol. 4 of F oundations and T r ends in The or etic al Computer Science (Publishers Inc., Hanov er, MA, 2009). [15] M. E. J. Newman, Pro c. National Academy of Sciences 103 (23), 8577 (2006). [16] S. F ortunato, Physics Reports 486 , 75 (2010). [17] L. Lov´ asz, Random Walks on Gr aphs: A Survey (1993), pp. 353–397. [18] H. W. Hethcote, SIAM Review 42 (4), 599 (2000). [19] Y. W ang, D. Chakrabarti, C. W ang, and C. F aloutsos, in Pr o c. 22nd Symp osium on R eliable Distribute d Systems (IEEE, 2003), pp. 25–34. [20] F. Chung, Pro c. National Academy of Sciences 104 (50), 19735 (2007). [21] R. Ghosh and K. Lerman, Phys. Rev. E 83 (6), 066118 (2011). [22] H. T ong, B. A. Prak ash, T. Eliassi-Rad, M. F alout- sos, and C. F aloutsos, in Pr o c. 21st A CM International Confer enc e on Information and know le dge management (2012), CIKM ’12, pp. 245–254. [23] Y. W eiss, in Pr o c e e dings IEEE International Confer enc e on Computer Vision (1999), pp. 975–982. [24] A. Lancic hinetti and S. F ortunato, Ph ys. Rev. E 80 (1) (2009). [25] S. F ortunato, Benchmark gr aphs to test c ommunity dete c- tion algorithms (October 2011), https://sites.google. com/site/santofortunato/inthepress2 . [26] D. J. W atts, The American Journal of So ciology 105 (2), 493 (1999). [27] L. Danon, A. D ´ ıaz-Guilera, J. Duch, and A. Arenas, Journal of Statistical Mechanics: Theory and Exp eri- men t (2005).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment