Maximum Joint Entropy and Information-Based Collaboration of Automated Learning Machines
We are working to develop automated intelligent agents, which can act and react as learning machines with minimal human intervention. To accomplish this, an intelligent agent is viewed as a question-asking machine, which is designed by coupling the p…
Authors: N. K. Malakar, K. H. Knuth, D. J. Lary
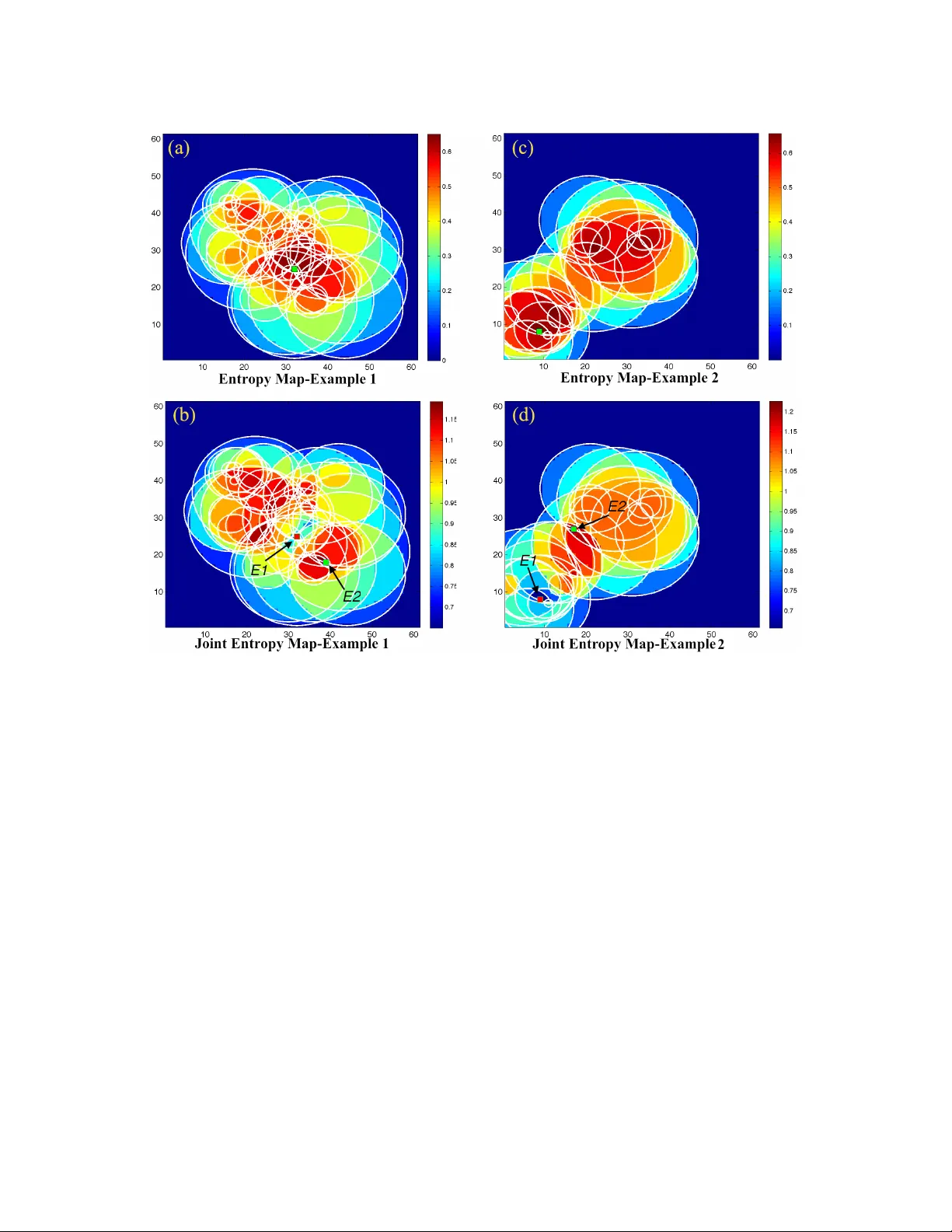
Maximum J oint Entr opy and Inf ormation-Based Collaboration of A utomated Lear ning Machines N. K. Malakar ∗ , K. H. Knuth † , ∗∗ and D. J. Lary ∗ ∗ Department of Physics, University of T exas at Dallas † Department of Physics, University at Albany (SUNY) ∗∗ Department of Informatics, University at Albany (SUNY) Abstract. W e are w orking to de velop automated intelligent agents, which can act and react as learning machines with minimal human intervention. T o accomplish this, an intelligent agent is viewed as a question-asking machine, which is designed by coupling the processes of inference and inquiry to form a model-based learning unit. In order to select maximally-informativ e queries, the intelligent agent needs to be able to compute the relev ance of a question. This is accomplished by employing the inquiry calculus, which is dual to the probability calculus, and extends information theory by e xplicitly requiring conte xt. Here, we consider the interaction between two question- asking intelligent agents, and note that there is a potential information redundancy with respect to the two questions that the agents may choose to pose. W e show that the information redundancy is minimized by maximizing the joint entropy of the questions, which simultaneously maximizes the relev ance of each question while minimizing the mutual information between them. Maximum joint entropy is therefore an important principle of information-based collaboration, which enables intelligent agents to efficiently learn together . Keyw ords: Joint Entropy , Collaboration, Information, Question, Automation. P A CS: 02.50Tt, 07.05.Bx, 07.07.T w , 07.05.Fb, 07.05.Hd, 07.05.Kf. INTR ODUCTION Present day scientific explorations in volv e gathering data at an ever -increasing rate, thereby requiring autonomy as a vital part of exploration. For example, remote science operations require automated systems that can both act and react with minimal human intervention. Our vision is to construct an autonomous intelligent instrument system (AIIS) that collects data in an automated fashion, learns from that data, and then, based on the learning goal, decides which ne w measurements to take. Such a system would constitute a learning machine that could act and react with minimal human interv ention. This is made possible by the comprehensiv e successes of Bayesian inference, the deci- sion theoretic approach to experimental design [1, 2, 3, 4], and the dev elopment of the inquiry calculus [5, 6, 7, 8]. Our ef forts to construct such autonomous systems [9, 10, 11] hav e considered the process of data collection and the process of learning in two distinct phases: the inquiry phase and inference phase. By coupling these processes of inference and inquiry one can form a model-based learning unit that cyclically collects data and learns from that data by updating its models. At this stage, the inference phase, which is based on Bayesian probability theory , is suf ficiently well-understood so that our current focus is on inquiry . For this reason, we tend to vie w the AIIS as a question-asking machine. In this paper , we build upon our pre vious work [9, 10] and consider the problem of coordinating two question-asking intelligent agents. W ithout coordination, after each agent has independently solv ed the presented problem, there will be a redundancy in the information obtained by the two agents. In addition, during the question-asking process, there is a great potential for redundancy in terms of the questions that they pose. W e sho w that collectiv ely this redundancy is minimized at each step of the question-asking process by maximizing the joint entropy of the two questions that the agents plan to ask. This has the tendency to simultaneously maximize the relev ance of each of the two questions posed while minimizing the mutual information between them. W e illustrate the process via simulation and sho w that maximization of the joint entropy is an important principle of information-based collaboration, which enables intelligent agents to efficiently learn together . THE INQUIR Y CALCULUS In this section, we briefly revie w the inquiry calculus. The dev elopment of this calculus relies on sev eral order-theoretic notions, which are more thoroughly discussed in papers outlining the theoretical de velopment [7, 8]. Central to this dev elopment is the concept of a partially ordered set, which is a set of elements in conjunction with a binary ordering relation. Related, is a special case of a partially ordered set called a lattice, which is endo wed with a pair of operations called the join and the meet so that the lattice can be thought of as an algebra where the join and meet are algebraic operators. Here we will consider elements that can be described in terms of sets. So that the main concepts can be described in terms of subsets ordered by subset inclusion, the set union (join) and the set intersection (meet). W e consider three spaces: the state space, the hypothesis space, and the inquiry space. The state space describes the possible states of the system itself. In the situations we will consider , the elements of the state space are mutually exclusi ve so that in terms of a partially ordered set, they can be represented as an antichain. The hypothesis space describes what can be known about a system. Its elements are sets of potential states of the system. As such, it is a Boolean lattice (or a Boolean alge- bra) constructed by taking the po wer set of the set of states and ordering them according to set inclusion. In this space, the logical OR operation is implemented by set union (join) and the logical AND operation by set intersection (meet). Logical deduction is straightforward in this frame work, since implication is implemented by subset inclusion so that a statement in the lattice implies ev ery statement that includes it in terms of subset inclusion. General logical induction is implemented by quantifying degree to which one statement implies another with a real-v alued bi-valuation, probability , which quantifies the degree to which one statement implies another . The inquiry space describes what can be ask ed about a system. Its elements are sets of statements, which are called questions, such that if a set contains a given statement, then it also contains all the statements that imply it. In this sense, a question can be thought of as a set of potential statements that can be made. It is constructed by taking down-sets of statements and ordering them by set inclusion resulting in a fr ee distrib utive lattice . Just as some statements imply other statements, some questions answer other questions. Specifically , if question A is a subset of question B , A ⊂ B , then by answering question A , we will hav e necessarily answered question B . Questions, which include all atomic statements as potential answers, are assured to be answerable by a true statement. Cox had termed such questions as real questions [5]. If one considers the sub-space formed from the real questions, the minimal real question is defined as the central issue, I = n [ i = 1 X i , (1) where X i = {{ x i }} and x i is the statement ‘ The system is in state x i ’. The central issue can then be e xpressed as the question ‘ Is the system in state x 1 or in state x 2 ... or in state x n ? ’ Since it is the minimal real question, answering the central issue will necessarily answer all other real questions. In practice, howe ver , we cannot always pose the central issue directly . A special class of real questions are the partition questions , which partition the set of answers. For example, giv en a set of atomic statements indexed by integers 1 through n , we can partition this set in p ( n ) w ays, where p ( n ) can be defined in terms of a generating function ∞ ∑ n = 0 p ( n ) x n = ∞ ∏ k = 1 1 1 − x k , (2) which blo ws up rapidly . For example, for three atomic statements we hav e the set { 1 , 2 , 3 } that can be partitioned as { 1 }{ 2 }{ 3 } which results in the central issue I = X 1 ∪ X 2 ∪ X 3 . (3) Another possible partitioning is { 1 }{ 2 , 3 } , which represents the binary question ‘ Is the system in state x 1 or not x 1 ? ’ denoted P 1 | 23 = X 1 ∪ X 2 X 3 , (4) where X 1 = { x 1 } and X 2 X 3 = { x 2 , x 3 , x 2 ∨ x 3 } . In this way by answering x 2 , x 3 , or x 2 ∨ x 3 = ¬ x 1 one has provided the information that the system is not in state x 1 . Other partition questions are written similarly . V aluations are handled in a way that is analogous to probability in the lattice of state- ments comprising the hypothesis space. Howe ver , due to multiple competing constraints, a bi-valuation can only be consistently assigned to the partition sublattice of the real questions. This bi-v aluation is called the relev ance, and is denoted d ( Q | P ) , which is read as ‘the de gree to which P answers Q ’ [8]. In the special case where P ⊆ Q , we hav e that the relev ance is maximal, which enables one to choose a grade so that d ( Q | P ) = 1. Otherwise, the rele v ance takes on a v alue between 0 and 1. The relev ance of a partition question depends on the probability of its particular partition of answers. One can sho w that the relev ance of the question P with respect to the central issue is giv en by the entropy of that partition of probabilities [8]. In the case of the partition question P 1 | 23 described in (4) we hav e that d ( I | P 1 | 23 ) ∝ H ( p 1 , p 2 + p 3 ) (5) where H is the Shannon entropy , and p i = Pr ( x i |> ) which is the probability that the system is in state x i . The proportionality constant is the in verse of the rele vance d ( I | I ) ∝ H ( p 1 , p 2 , p 3 ) (6) so that d ( I | P 1 | 23 ) = H ( p 1 , p 2 + p 3 ) H ( p 1 , p 2 , p 3 ) (7) and d ( I | I ) = H ( p 1 , p 2 , p 3 ) H ( p 1 , p 2 , p 3 ) = 1 . (8) A UT OMA TED EXPERIMENT AL DESIGN Pre viously , we demonstrated a robotic arm, built with the LEGO MINDST ORMS NXT system, capable of autonomously locating and characterizing a white circle on a dark background [9, 10]. Here we aim to extend this problem by introducing two robots that work in a collaborati ve ef fort to solve the same problem. Computing with Questions The white circle is characterized by three unkno wn parameters { x o , y o , r o } . W e are interested in asking questions about the center position of the circle { x o , y o } as well as its radius r o by taking light intensity measurements centered at locations determined by the inquiry system. Model-based descriptions enable one to make predictions about the outcomes of potential experiments. Gi ven the joint posterior probability of the circle location and radius, one can determine the probability that a gi ven intensity measurement at a position ( x i , y i ) , will result in a “white" or “black" intensity reading. This is easily done with sampling by maintaining a set of sampled circles and noting how many circles contain the proposed measurement location and would result in a white intensity reading, and how many circles do not contain the measurement circle resulting in a black intensity reading. Such predictions can be made more precise by modeling the spatial sensitivity of the light sensor and computing the predicted numerical result of the sensor given the measurement location and the hypothesized characteristics of the white circle [12]. Furthermore, the entrop y associated with such a measurement can be computed as the entropy of the probability distrib ution of predicted measurement intensities. This can be rapidly computed by generating a set of predicted measurements from the set of circles sampled from the posterior . By generating a histogram of this set of predicted intensities, one has a model of the density function of predicted measurements. The entropy of this histogram is computed and serves as an excellent estimate of the entropy associated with the question posed by recording the intensity at a particular measurement location. By computing the entropy associated with a large set of measurement locations, one can create an entropy map based on the sampled circles and the known characteristics of the light sensor . For increased speed, we also hav e dev eloped an entropy-based search algorithm to intelligently search the entropy space without computing it ev erywhere [13]. W e begin by encoding the questions one might ask in terms of sets of circle param- eters. The central issue considers all possible circle parameter v alues, and in doing so asks the question “Precisely where is the circle?” In practice, this is a finite set since one can only measure to finite precision, and in the simulations we force it to be finite by considering a discrete grid of possible circle center positions and radii. The central issue I can be written as I = {{ x 1 , y 1 , r 1 } , { x 2 , y 2 , r 2 } , ... } , (9) where each element of the set, such as { x i , y i , r i } , represents a potential precise answer to the question. One way to solve this problem is to simply ask all of the binary questions ‘Is the circle in state { x i , y i , r i } ?’ Ho wev er , this is not very efficient. Moreover , faced with measurement uncertainties, we do not kno w the exact answer to Eq. (9), as we cannot measure the exact v alues of the parameters of interest. Since we cannot directly perform a single, or e ven a small number, of measurements that directly answer the central issue. Instead, we must identify measurements that can be performed that are maximally relev ant to the central issue. This in volv es finding measurement locations that hav e the maximum entropy as computed from the posterior probability of the circle states. W e note that any giv en measurement location ( x e 1 , y e 1 ) divides the space of circles into two regions: the set of circles that contain the measurement location, and the set of circles that do not contain the measurement location Q ( x , y , r ) = [ ( x e 1 , y e 1 ) ∈ circl e { x i , y i , r i } , [ ( x e 1 , y e 1 ) / ∈ circl e x j , y j , r j . (10) Similarly , a second robot choosing a different measurement location, ( x e 2 , y e 2 ) , partitions the question space dif ferently into two sets defining a dif ferent binary partition. Jointly , the two distinct measurement locations partition the space of circles into four regions, say a , b , c and d : a = { whi t e , whit e } , b = { whi t e , bl ack } , c = { bl ack , whit e } , d = { bl ack , bl ac k } , (11) where, for example, { whi t e , bl ac k } refers to the set of circles that contain ( x e 1 , y e 1 ) so that a measurement there will be predicted to result in a white intensity , but do not contain ( x e 2 , y e 2 ) so that a measurement there will be predicted to result in a black intensity . The circles where the first robot measures white belong to the set a ∪ b . W e can then define the elementary questions as AB = { a ∨ b , a , b } , C D = { c ∨ d , c , d } , A C = { a ∨ c , a , c } , BD = { b ∨ d , b , d } . (12) and write the question that the first robot poses as AB ∪ C D = { a ∨ b , c ∨ d , a , b , c , d } ≡ {{ w , •} , { b , •}} , (13) and the question the second robot poses as A C ∪ BD = { a ∨ c , b ∨ d , a , b , c , d } ≡ {{• , w } , {• , b }} , (14) where the expressions on the right illustrate what the robots are measuring with • signifying either black or white. Jointly the robots partition the space into four sets, ( AB ∪ C D ) ∩ ( A C ∪ BD ) = ( A ∪ B ∪ C ∪ D ) . (15) Therefore, the rele v ance of the joint question, with respect to the central issue, is giv en by the joint entropy of the predictions of the two measurements E 1 = ( AB ∪ C D ) and E 2 = ( A C ∪ BD ) [11] d ( I | E 1 ∩ E 2 ) = d ( I | A ∨ B ∨ C ∨ D ) = H ( Pr ( A ) , Pr ( B ) , Pr ( C ) , Pr ( D )) , (16) where, gi ven that robot 1 measures at ( x e 1 , y e 1 ) and robot 2 measures at ( x e 2 , y e 2 ) , Pr ( A ) denotes the probability that both the first and the second robot’ s measurement locations result in a white intensity , Pr ( B ) denotes the probability that the first measurement results in white and the second in black, Pr ( C ) denotes the probability that the first measurement results in black and the second in white, and Pr ( D ) denotes the probability that both the first and the second measurements result in black. Considered jointly , the predicted measurement results associated with the pair of measurement locations constitute a two-dimensional distrib ution at each point in the four-dimensional space of pairs of measurement locations. The relev ance d ( I | E 1 ∩ E 2 ) dictates that we select measurement locations that maximize the joint entropy of the intensities predicted to be measured by the two robots. RESUL TS In the present case of model based e xploration, giv en a hypothesized circle location and radius, the intensity to be measured at any point in the field can be predicted. By con- sidering 45 posterior samples, we made predictions about the intensities which ga ve a distribution of 45 predicted intensities. The entropy associated each possible measure- ment location was computed by estimating the entropy of the histogram of predicted intensities at that position in the field. This enables us to produce an entropy map for a single proposed measurement. Joint entropy maps would require four dimensions to display . Instead, we plot the joint entropy of the two measurements for the case where the first e xperiment E1 is determined. This map then represents a two-dimensional slice through the four-dimensional space of pairs of measurements. The mutual information maps (not sho wn) can be made similarly . Figure 1 sho ws two examples, where we considered dif ferent degrees of o verlap of the sample circles. The figures on the left column represent the case with more correlated circles than those on the right. Each of the figures show a set of circles drawn from the posterior probability . Overlaid on this are the entropy maps (a and c), and the joint entropy maps (b and d). FIGURE 1. Figures illustrating two set of examples where we implement the information-based col- laboration for experimental design in the problem where two robots are to characterize a circle using light sensors. Figures (a) and (b) show the cases where circles are highly correlated, whereas figures (c) and (d) show the cases where circles are less correlated. In both cases, we hav e drawn a set circles from the posterior samples and used these circles to make predictions about the expected measured light intensity at each point. The top figures (a and c) sho w the entropy map, which illustrates the optimal measurement location in the case where only one measurement is to be taken. The botom figures (b and d) illustrate the joint entropy map of measurement location E 2 shares with measurement location E 1 fixed. Note that the selected location of meaurement E 2 maximizes the joint entropy , which in volv es finding an informativ e measurement location that does not provide information redundant to E 1. The entropy maps in (Figures 1a and 1c) show the measurement location that would be selected in the ev ent that only one measurement was being performed. The joint entropy maps (Figure 1b and 1d) show the locations of the second measurement E 2 that maximize the relev ance of the question d ( I | E 1 ∩ E 2 ) giv en that the location of E 1 has been selected. By comparing the locations of E 2 in the joint entropy map with the corresponding values of entropy and mutual information, one can see that the selected measurement locations for E 2 fa vor regions of high entropy while av oiding locations that share mutual information with E 1. Maximizing the joint rele vance naturally chooses informati ve measurement locations that promise to provide independent information. The two measurement locations E 1 and E 2 that maximize the relev ance of the joint question d ( I | E 1 ∩ E 2 ) are indicated by arro ws. CONCLUSIONS AND FUTURE APPLICA TIONS In this paper , we have presented the method of information-based collaboration for Automated Intelligent Instruments System (AIIS). W e ha ve considered the intelligent agent as a question-asking machine and hav e focused on the inquiry phase, where our aim has been to select maximally informativ e queries with respect to a gi ven goal. W e hav e e xtended the order-theoretic approach [7, 8] to assign the rele vance of questions for collaborati ve AIIS. W e hav e shown that the joint entropy gi ves the relev ance of the joint question posed by the agents. Maximum joint entropy is an important principle of information-based collaboration, which enables intelligent agents to efficiently learn together . Currently our team in UTD is working on to develop a fleet of aircrafts to deploy in the field using the technique of collaboration dev eloped in this paper . The aircraft fleet consists of helicopters as well as the fixed wing small aircrafts. W e aim to use the fleet to characterize and help predict tornado forecasts, assist with the gas leak detection, and monitor the health of cattle. The work is in progress. REFERENCES 1. V . V . Fedorov , Theory of optimal e xperiments , Probability and mathematical statistics, Academic Press, 1972. 2. D. V . Lindley , The Annals of Mathematical Statistics 27 , 986–1005 (1956). 3. J. M. Bernardo, The Annals of Statistics 7 , 686–690 (1979). 4. T . J. Loredo, and D. F . Chernoff, “Bayesian Adapti ve Exploration, ” in Bayesian Infer ence and Maximum Entr opy Methods in Science and Engineering , edited by G. Erickson, and Y . Zhai, AIP , 2003, pp. 330–346. 5. R. T . Cox, “Of inference and inquiry , an essay in inductiv e logic, ” in The Maximum Entr opy F ormalism , edited by R. D. Le vine, and M. T ribus, The MIT Press, Cambridge, 1979, pp. 119–167. 6. R. L. Fry , “The engineering of cybernetic systems, ” in Bayesian Infer ence and Maximum Entropy Methods in Science and Engineering , edited by R. L. Fry , AIP , 2002, vol. 617, pp. 497–528. 7. K. H. Knuth, “What is a question?, ” in Bayesian Infer ence and Maximum Entropy Methods in Science and Engineering , edited by C. W illiams, AIP , 2003, pp. 227–242. 8. K. H. Knuth, “V aluations on lattices and their application to information theory , ” in Pr oceedings of the 2006 IEEE W orld Congr ess on Computational Intelligence (IEEE WCCI ) , 2006. 9. K. H. Knuth, P . M. Erner , and S. Frasso, “Designing Intelligent Instruments, ” in Bayesian Infer ence and Maximum Entr opy Methods in Science and Engineering , edited by K. Knuth, A. Caticha, J. Center , A. Giffin, and C. Rodriguez, AIP , 2007, vol. 954, pp. 203–211. 10. K. H. Knuth, and J. L. Center , “ Autonomous science platforms and question-asking machines, ” in 2nd International W orkshop on Cognitive Information Pr ocessing (CIP) , 2010, pp. 221 –226, ISSN 2150-4938. 11. N. K. Malakar , and K. H. Knuth (2011), in preparation. 12. N. K. Malakar , A. J. Mesiti, and K. H. Knuth, “The spatial sensitivity function of a light sensor, ” in Bayesian Infer ence and Maximum Entr opy Methods in Science and Engineering , edited by P . Gog- gans, and C.-Y . Chan, AIP , New Y ork, 2009, pp. 352–359. 13. N. K. Malakar , and K. H. Knuth, “Entropy-Based Search Algorithm for Experimental Design, ” in Bayesian Inference and Maximum Entr opy Methods in Science and Engineering , edited by A. M. Djafari, J. F . Bercher , and P . Bessiére, AIP , 2011, vol. 1305, pp. 157–164.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment