Feedback Message Passing for Inference in Gaussian Graphical Models
While loopy belief propagation (LBP) performs reasonably well for inference in some Gaussian graphical models with cycles, its performance is unsatisfactory for many others. In particular for some models LBP does not converge, and in general when it …
Authors: Ying Liu, Venkat Ch, rasekaran
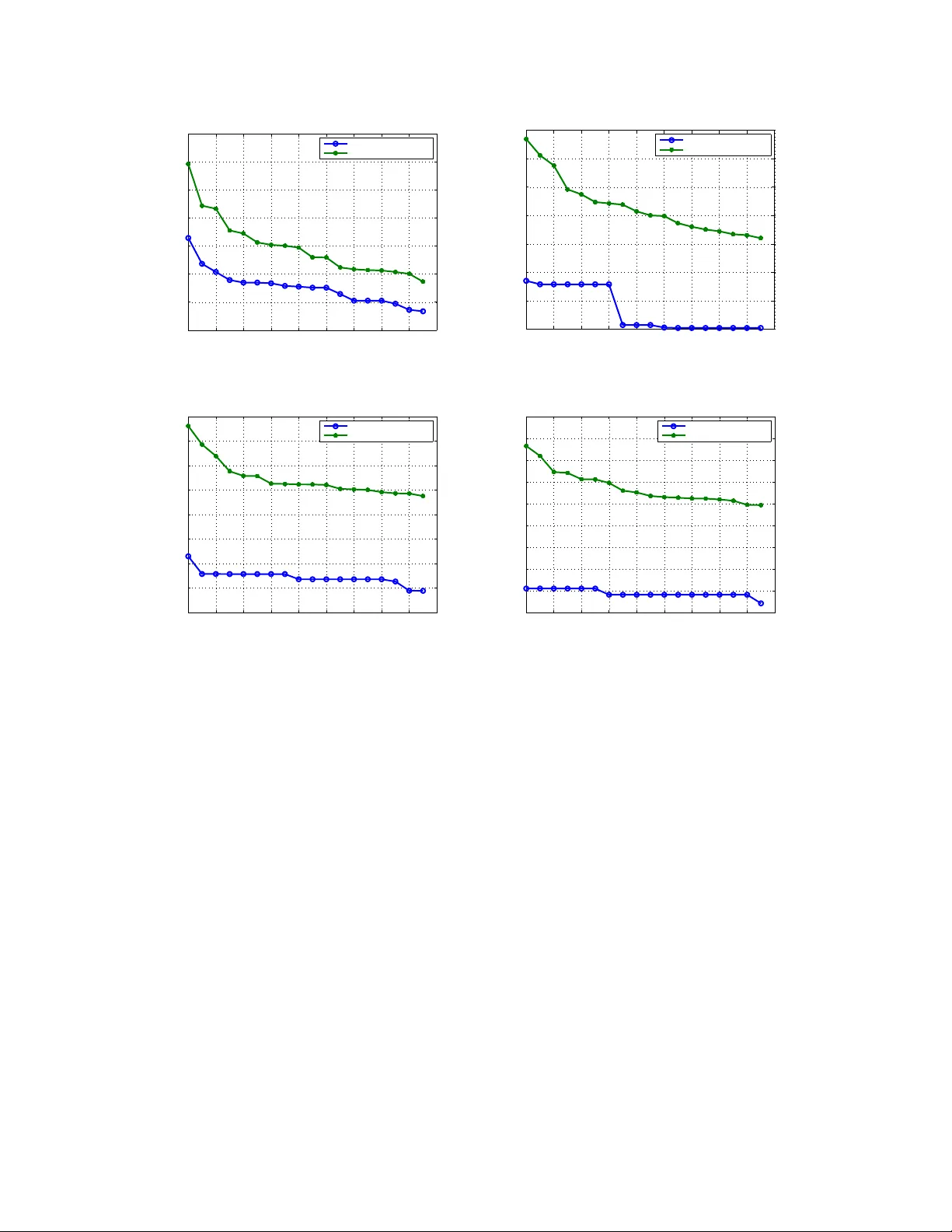
1 Feedback Message P assing for Inferenc e in Gaussian Graphical Models Y ing Liu, Student Member , IEEE, V enk at Chandrasekaran, S tudent Member , IEEE, Animashree Anandkum ar , Member , IEEE, Alan S. W il lsky , F e llow , IEEE Abstract While lo opy belief propag ation (LBP) performs reason ably well for inference in some Gaussian graphica l models with cycles, its per forman ce is unsatisfactory fo r many others. In particu lar fo r som e models LBP does not converge, and in g eneral when it do es con verge, the computed variances are incorrect ( except for cycle- free grap hs for which belief propa gation (BP) is non- iterative and exact). In this paper w e prop ose feedback message passing (FMP), a message-passing algorithm that makes use of a special set of vertices (called a feedba ck verte x set or FVS ) whose removal results in a cycle-free graph. In FMP , standar d BP is employed se veral time s o n the cycle-free subg raph excluding the FVS while a spe cial message-passing scheme is u sed for th e no des in the FVS. Th e compu tational com plexity of exact inference is O ( k 2 n ) , wher e k is the n umber of feed back nodes, and n is the total nu mber of nodes. When the size o f the FVS is very la rge, FMP is intractable. Hence we propo se ap pr oxima te FMP , where a pseu do-FVS is used instead o f an FVS, and wh ere infere nce in the non-cycle-f ree g raph obtained by removing th e pseudo- FVS is carried out ap proxim ately using LBP . W e show that, wh en approx imate FMP conv erges, it y ields exact mean s and variances on the p seudo-FVS and exact mean s throug hout the remainde r of the graph. W e also provide theoretical resu lts on the convergence and accuracy of ap proxim ate FMP . In p articular, we prove error b ounds o n variance computatio n. Based on th ese theoretical results, we de sign efficient alg orithms to select a pseudo-FVS of bou nded size. The choice of the pseud o-FVS allows us to exp licitly trad e off b etween efficiency and accuracy . Ex perimen tal results show that using a pseudo -FVS of size no larger than log( n ) , this proced ure conv erges much m ore often, more quickly , and provide s mo re accura te r esults than LBP on the entire grap h. Index T erms This paper was presente d in part at the 2010 Internat ional Symposium of Information T heory in Austin, T exas, U.S. [1]. Y . Liu, V . Chandrase karan, and A. S. Wi llsky are with the Stocha stic Systems Group, Laboratory for Informati on and Decision Systems, Massachusetts Institut e of T echnology , Cambridge , MA 02139, USA. Email: { liu ying,ve nkatc,wil lsky } @mi t.edu. A. Anandkumar is with the Center for Perv asi ve Communicati ons and Computing, Univ ersity of Ca lifornia , Irvine, CA 92697, USA. Email: a.anandkumar@uc i.edu. This research was supported in part by AFOSR through Grant F A9550-08-1-108 0 and in part by Shell Internat ional Exploration and Production, Inc. October 24, 2018 DRAFT 2 Belief propag ation, feedback vertex set, Gaussian g raphical models, gr aphs with cycles, Markov random field 1 I . I N T RO D U C T I O N Gaussian graphica l models are use d to repre sent the conditional independ ence relationships among a collection of normally distributed r andom variables. They are widely use d in many fie lds such as computer vision an d image p rocessing [2], gene regulatory networks [3], medical diagn ostics [4], oc eanograp hy [5], an d communica tion systems [6]. Inference in Gaussian graph ical models refers to the problem of estimating the mea ns and variances of all rand om variables g i ven the model pa rameters in information form (see Se ction II-A for more details). Exa ct inferen ce in Gaussian graphical models can be solved by direct matrix in version for problems of mod erate sizes. H owe ver , direct matrix in version is intractable for very lar ge prob lems in volving millions of rando m variables, especially if variances a re sought [5], [7], [8]. The development of efficient algorithms for solving suc h large-scale inference problems is thu s of great practical importance. Belief propaga tion (BP) is an ef fi cient message-pas sing algorithm that gi ves exact inferen ce results in linea r time for tree -structured graph s [9]. The Kalman filter for linear Gaussian estimation and the forward-backward algorithm for hidde n Markov models c an be v iewed as sp ecial instance s of B P . Though widely us ed, tree-structured mo dels (also kn own as cycle-free graphical mod els) posse ss limit ed modeling capabilities, an d ma ny s tochastic proc esses and random fields arising in real-world app lications cann ot be well-modeled u sing cycle-free graphs . Loopy be lief propa gation (LBP) is an application of BP on loopy graphs using the same local message update rules. Empirically , it has been observed that LBP performs reason ably we ll for certain graphs with cycles [10], [11]. Indeed, the d ecoding method e mployed for turbo cod es has also b een shown to be a suc cessful instance of LBP [12]. A desirable property of LBP is its distributed n ature – as in BP , messag e upd ates in LBP o nly in volve local model parame ters or local me ssage s, so all nodes can u pdate their messa ges in parallel. Howe ver , the con ver gence a nd c orrectness of LBP are not g uaranteed in g eneral, a nd many researc hers have attempted to study the performanc e of LBP [13]–[16]. For Gaussian graph ical models, even if LBP 1 October 24, 2018 DRAFT 3 con verges, it is known tha t only the mean s conv er ge to the correct values while the variances o btained are incorrect in general [14]. In [16], a walk-sum analysis framework is propo sed to a nalyze the performance of LBP in Gauss ian graphical models . Bas ed o n such a walk-sum ana lysis, other a lgorithms have been proposed to obtain better inferenc e results [17]. LBP has fundamen tal limitations when applied to graphs with cycles: Local information c annot ca pture the globa l structure of cycles, and thus can lead to c on vergence problems a nd inference errors. There are s ev eral questions that arise naturally: Can we u se more memory to track the paths of message s? Are there some nod es that are more important than o ther nodes in terms of re ducing inference errors? C an we design an algorithm ac cordingly without losing too much de centralization? Moti vated by the se qu estions, we consider a pa rticular set o f “important” nod es called a feed back vertex set (FVS). A feedbac k vertex set is a subs et of vertices wh ose removal breaks all the cycles in a graph. In our feedba ck mess age pass ing (FMP) algorithm, node s in the FVS use a different messa ge passing scheme than other no des. More specifica lly , the algorithm we develop co nsists of sev eral stages. In the first stage on the cyc le-free graph (i.e., that excluding the FVS) we e mploy standa rd inference algorithms such as BP but in a non-standa rd mann er: Incorrect estimates for the nodes in the cycle-free portion are c omputed while other quantities are calculated and then fed b ack to the FVS. In the seco nd stage, nodes in FVS use these quantities to perform exac t mean an d variance computations in the FVS and to produ ce qua ntities used to initiate the third stage of BP process ing on the cycle-free portion in order to correct the means an d variances. If the number of feedbac k nodes is bounded , the means a nd variances can be obtained exactly in linea r time by u sing FMP . In gene ral, the complexity is O ( k 2 n ) , where k is the n umber of the feedback nod es and n is the total number of no des. For graph s with lar ge feedbac k vertex se ts (e.g. , for lar ge two-dimensional g rids), FMP become s intractable. W e d ev elop ap pr o ximate FMP us ing a pseudo-FVS (i.e., a set of nodes of moderate size that break so me but not all of the cycles ). Th e res ulting algo rithm ha s the same structure a s the exact algorithm except that the inference algorithm on the rema inder of the graph, (excluding the pse udo- FVS), which co ntains cycles, ne eds to be spec ified. In this paper we simply us e LBP , a lthough any other inference algorithm c ould also be use d. As we will sh ow , assuming con ver g ence of LBP on the re maining graph, the res ulting a lgorithm always yields the correct means and variances on the pseu do-FVS, a nd the correct means elsewhere. U sing these results and ideas mo ti vated by the work on walk-summability (WS) [16], we develop simple rules for selecting nodes for the ps eudo-FVS in orde r to ensure and enha nce con vergence of LBP in the remaining graph (by ens uring WS in the remaining graph) and h igh accu racy (by ensuring tha t o ur algorithm “co llects the most significan t walks”; s ee Section II-C for more details). October 24, 2018 DRAFT 4 This pseudo-FVS selection a lgorithm allo ws us to trade o f f efficiency and a ccuracy in a simple and natural manne r . Expe rimental res ults sugge st that this a lgorithm performs exceeding ly well – including for non-WS models for which LBP on the entire graph fails catastrophica lly – using a pseudo-FVS of size no larger tha n log( n ) . Inference algorithms base d on dividing the nodes of a graphica l model into subse ts have b een explored previously [18], [19]. T he a pproach presented in this p aper is distinguish ed by the fact that our meth- ods can b e na turally modified to provide efficient approximate algorithms with theoretical ana lysis on con vergence and error bo unds. The remaind er o f the pap er is organized a s follo ws. In Se ction 2, we fi rst introduce some bas ic concep ts in graph theory and Gau ssian graphical models. The n we briefly re v iew BP , LB P , and w alk- sum analysis. W e also define the no tion of an F VS a nd s tate s ome relev ant results from the literature. In Section 3, we show tha t for a class of grap hs with small FVS, inference problems ca n be solved efficiently and exactly by FMP . W e start with the single feedback nod e c ase, and illustrate the algorithm using a con crete example. T hen we describe the ge neral algo rithm with multiple feedback nodes . W e also prove that the algorithm conv erges an d produce s correct e stimates of the means and variances. In Section 4, we introduce a pproximate FMP , where we use a p seudo-FVS of b ounded size. W e also p resent theoretical results on c on vergence and accu racy o f approximate FMP . Then we p rovide an algorithm for selecting a good pseud o-FVS. In Se ction 5, we present numerica l resu lts. The experiments are performed on two-dimensiona l grids, which are widely use d in vari ous research a reas including image process ing. W e d esign a se ries of experiments to ana lyze the con vergence a nd accu racy of approx imate FMP . W e also compare the performance of the a lgorithm with dif fere nt choices of pse udo-FVS, an d demonstrate that excellent p erformance c an be achieved with a pse udo-FVS o f modest size c hosen in the manner we d escribe. Finally in Sec tion 6, we co nclude with a discu ssion of our ma in contributions and future research directions. I I . B AC K G RO U N D A. Gauss ian Graphical Models The s et of conditional ind epende nce relationships among a collection o f random variables can be represented by a g raphical model [20]. An undirected graph G = ( V , E ) consists o f a set of nodes (or vertices) V and a set of edg es E . Ea ch node s ∈ V c orresponds to a rand om vari able x s . W e say that a s et C ⊂ V sep arates sets A, B ⊂ V if every path connec ting A and B passes through October 24, 2018 DRAFT 5 x 1 x 2 x 3 x 4 x 5 (a) The sparsity pattern of the underlying graph x 1 x 1 x 2 x 2 x 3 x 3 x 4 x 4 x 5 x 5 (b) T he sparsity pattern of the information matrix Fig. 1. The relationship between the sparsity pattern i n the underlying graph and the sparsity pattern in the information matrix of a Gaussian graphical model. Conditional independences can be directly read from either the sparsity pattern of the graph structure or t he sparsity pattern of the information matrix. C . The ra ndom vector 2 x V is s aid to be Marko v with respec t to G = ( V , E ) if for any subse t A , B , C ⊂ V where C s eparates A and B , we have tha t x A and x B are inde penden t c onditioned on x C , i.e., p ( x A , x B | x C ) = p ( x A | x C ) p ( x A | x C ) . Such Markov models on u ndirected graphs are a lso commonly referred to as undirected graph ical models or Markov rand om fields. In a G aussian grap hical mode l, the random vector x V is jointly Gaus sian. The probab ility dens ity function of a jointly G aussian distribution is gi ven by p ( x ) ∝ exp {− 1 2 x T J x + h T x } , whe re J is the information, conc entration or p r ecision matrix a nd h is the potential v ector . W e refer to thes e parameters as the mo del parameters in information form. The mean vector µ an d covariance matrix P are related to J and h by µ = J − 1 h an d P = J − 1 . For Gaussian grap hical models, the graph structure is spars e with resp ect to the information ma trix J , i.e., J i,j 6 = 0 if a nd on ly if the re is an ed ge between i and j . For exa mple, Figure 1(a) is the unde rlying graph for the information matrix J with sparsity pattern shown in Figu re 1(b). For a non-degene rate Ga ussian d istrib ution, J is pos iti ve de finite. Th e c onditional independ ences of a collection of Ga ussian random v ariables ca n be rea d immediately from the graph as well as from the s parsity pattern of the information matrix. If J ij = 0 , i 6 = j , then x i and x j are independ ent con ditioned on a ll other variables [21]. Inferenc e in Gauss ian graphical mode ls refers to the problem of e stimating the mea ns µ i and variances P ii of every rando m variable x i giv en J and h . 2 W e use the notation x A , where A ⊂ V , to denote the collection of random variables { x s | s ∈ A } . October 24, 2018 DRAFT 6 B. Belief Propagation and Loopy Belief Propagation BP is a mess age passing algorithm for solving inferenc e problems in graphical models. Messa ges are updated a t e ach no de acc ording to inc oming mes sages from neighboring n odes a nd loc al parame ters. It is k nown that for tree-structured graphical models, BP runs in linear time (in the cardinality n = |V | of the node se t) and is exact. When there a re cycles in the graph , LBP is used ins tead, where the same local mes sage update rules as BP a re use d neglecting the existence of cycles. Howev er , con ver g ence and correctness are n ot gua ranteed when there are cycles. In Ga ussian graphica l mo dels, the set of mess ages can be represented by { ∆ J i → j ∪ ∆ h i → j } ( i,j ) ∈E . Consider a Gaussian graphical model: p ( x ) ∝ exp {− 1 2 x T J x + h T x } . BP (or LBP) proce eds as follows [16]: (1) Me ssage Passing : The messag es are initialized as ∆ J (0) i → j and ∆ h (0) i → j , for all ( i, j ) ∈ E . These initializations may be chosen in dif ferent ways. In ou r experiments we initialize all messa ges with the value 0 . At eac h iteration t , the messag es are upda ted based on previous messag es a s ∆ J ( t ) i → j = − J j i ( ˆ J ( t − 1) i \ j ) − 1 J ij , (1) ∆ h ( t ) i → j = − J j i ( ˆ J ( t − 1) i \ j ) − 1 ˆ h ( t − 1) i \ j , (2) where ˆ J ( t − 1) i \ j = J ii + X k ∈N ( i ) \ j ∆ J ( t − 1) k → i , ( 3) ˆ h ( t − 1) i \ j = h i + X k ∈N ( i ) \ j ∆ h ( t − 1) k → i . (4) Here N ( i ) = { j ∈ V : ( i, j ) ∈ E } de notes the s et of neigh bors of no de i . The fixed-point me ssage s are de noted as ∆ J i → j and ∆ h i → j if the me ssage s co n verge. (2) Co mputation of Me ans an d V ariances : The variances and mea ns are compu ted based on the fixed-point messa ges as ˆ J i = J ii + X k ∈N ( i ) ∆ J k → i , (5) ˆ h i = h i + X k ∈N ( i ) ∆ h k → i . (6) The variances and mea ns can then be obtained by P ii = ˆ J − 1 i and µ i = ˆ J − 1 i ˆ h i . October 24, 2018 DRAFT 7 C. W alk-su m Analysis Computing mean s and variances for a Gaus sian graphical mod el correspon ds to solving a se t of linear equations a nd ob taining the diagonal elements of the in verse of J respectively . The re are many ways in which to do this – e .g., by direct solution, or using various iterati ve methods. As we ou tline in this section, one way to interpret the exact or approximate solution o f this p roblem is throug h walk-sum analysis, which is based on a simple power series expa nsion of J − 1 . In [16], [17] walk-sum an alysis is used to interpret the computations of me ans and variances formally a s co llecting all required “walks” in a graph. T he a nalysis in [16] identifies when L BP fail s, in p articular wh en the requ ired walks canno t be summed in arbitrary orde rs, i.e., w hen the model is n ot walk-summable. 3 One of the important benefits of walk-sum a nalysis is tha t it allo ws us to understan d what various a lgorithms co mpute and relate them to the required exact comp utations. For example, as shown in [16], LBP c ollects all o f the required walks for the comp utation of the mean s (and, hence , if it con ver ges alw ays yields the correct means) but only some of the walks required for variance computations for loopy graphs (so, if it conv er ges, its vari ance calculations are not correct). For simplicity , in the rest of the pa per , we assume without los s o f g enerality that the information matrix J has be en n ormalized such that all its diago nal e lements are equal to unity . Let R = I − J , and no te that R has zero dia gonal. The matrix R is called the edge-weight matrix . 4 A walk of length l ≥ 0 is define d as a s equen ce o f vertices w = ( w 0 , w 1 , w 2 , ..., w l ) wh ere each step ( w i , w i +1 ) is an edg e in the graph. The weight of a w alk is de fined as the product of the edge weights, φ ( w ) = l ( w ) Y l =1 R w l − 1 ,w l , (7) where l ( w ) is the len gth of walk w . Also, we de fine the weigh t of a zero-leng th walk, i.e., a single node , as one . By the Ne umann power series for matrix in version, the cov ariance matrix can be expressed as P = J − 1 = ( I − R ) − 1 = ∞ X l =0 R l . (8) This formal series c on verges (although not ne cessa rily ab solutely) if the spec tral radius, ρ ( R ) , i.e., the magnitude of the largest eigen value of R , is les s than 1 . 3 W alk-summability corresp onds to the abso lute con ver gence of the series co rresponding to the walk-sums ne eded for v ariance computation in a graphical model [16 ]. 4 The matrix R , which has the same off-diagonal sparsity pattern as J , is a matrix of partial correlation coefficients: R ij is the conditional correlation coefficient between x i and x j conditioned on all of the other v ariables in the graph. October 24, 2018 DRAFT 8 Let W be a set of walks. W e define the walk-sum of W as φ ( W ) ∆ = X w ∈W φ ( w ) . (9) W e use φ ( i → j ) to denote the sum of all walks from node i to n ode j . In particular , we c all φ ( i → i ) the se lf-r etur n walk-sum of no de i . It is easily checked that the ( i, j ) e ntry of R l equals φ l ( i → j ) , the sum of a ll walks of length l from node i to node j . Hence P ij = φ ( i → j ) = ∞ X l =0 φ l ( i → j ) . (10) A Gaus sian gra phical model is wa lk-summable (WS) if for all i, j ∈ V , the walk-sum φ ( i → j ) con verges for any o rder o f the su mmands in (10 ) (note that the su mmation in (10) is ordere d by walk- length). In walk-summable mo dels, φ ( i → j ) is well-defined for all i, j ∈ V . Th e covari ances and the mea ns can be expressed as P ij = φ ( i → j ) , (11) µ i = X j ∈V h j P ij = X j ∈V h j φ ( i → j ) . (12) As shown in [16] for non-WS models, LBP may not co n verge a nd can, in fact, yield oscillatory variance estimates that take on negativ e values. Here we list some useful results from [16] that will be use d in this pa per . 1) The following conditions are equiv alen t to walk-summability: (i) P w ∈W i → j | φ ( w ) | co n verges for all i, j ∈ V , where W i → j is the s et of walks from i to j . (ii) ρ ( ¯ R ) < 1 , whe re ¯ R is the matrix whose elements a re the ab solute v alues of the c orresponding elements in R . 2) A Gauss ian grap hical model is walk-summable if it is attracti ve, i.e., every ed ge weight R ij is nonnegative. Th e model is also walk-summable if the graph is cycle-free. 3) For a walk-summable Gau ssian graphical model, LB P conv erges and g i ves the correct mea ns. 4) In walk-summable mode ls, the estimated variance from LBP for a node is the sum over all backtracking walks 5 , which is a su bset of all self-return walks nee ded for comp uting the correct variance. 5 A backtracking walk of a node is a self-return walk that can be reduced consecuti vely to a single node. Each reduction is to replace a subw alk of the form { i, j, i } b y the single nod e { i } . For example, a self-return w alk of the form 12321 is backtrack ing, but a walk of the form 1231 is not. October 24, 2018 DRAFT 9 1 P S f r a g r e p l a c e m e n t s 1 (a) A graph with an FVS of si ze one 1 2 P S f r a g r e p l a c e m e n t s 1 2 (b) A graph wi th an FVS of size two Fig. 2. Examples of FVS’s of different sizes. After removing the nodes in an F VS and their incident edges, the reminder of the graph is cycle-free. D. F eedback V ertex Set A feedback ver tex set (FVS), also called a loop cutset, is defined as a set of vertices who se removal (with the removal of incide nt e dges) re sults in an cycle-free graph [22]. For example, in Figu re 2 (a), node 1 forms an F VS by itself sinc e it breaks a ll cycles . In F igure 2(b), the set c onsisting of nod es 1 and 2 is an FVS. The problem of finding the FVS of the minimum size is called the m inimum feedback vertex s et problem, which has been widely studied in graph theory and compu ter science. For a general graph, the d ecision version of the minimum F VS problem, i.e., dec iding whe ther there exists a n FVS of size at most k , has be en proved to be NP-complete [23]. Finding the minimum FVS for gene ral graphs is still an activ e research area. T o the best of the a uthors’ kn owledge, the fastest algorithm for finding the minimum FVS runs in time O (1 . 7548 n ) , where n is the number of n odes [24]. Despite the difficulty of obtaining the minimal FVS , ap proximate algorithms have b een proposed to giv e a n FVS whose size is b ounded by a factor times the minimum possible size [25]–[27]. In [27 ], the authors propos ed an algorithm that gi ves an FVS of size at most two times the minimum size. The complexity of this algorithm is O (min { m log n , n 2 } ) , where m and n are res pectively the number of edges and vertices. In addition, if one is giv en prior knowledge of the graph structure, optimal or near optimal solutions can be foun d ef ficiently or even in linear time for ma ny spe cial graph structures [28]– [30]. Fixed-parameter polynomial-time algorithms are als o developed to find the minimum F VS if the minimum size is known to be b ounded by a parameter [31]. October 24, 2018 DRAFT 10 I I I . E X A C T F E E D B A C K M E S S A G E P A S S I N G In this section, we describe the exact FMP algorithm (or simply FMP) which giv es the exac t inference results for all nod es. W e init ialize FMP b y selecting an FVS, F , using any one of the algorithms mentioned in Sec tion II-D. The nodes in the F VS are c alled feedba ck nodes. W e use a special messa ge u pdate sche me for the feed back nodes while us ing standa rd BP messag es (although, as we will see , not in a standard way) for the non-feedba ck no des. In FMP , two rounds of BP messag e pa ssing are performed with different parameters. In the first round of BP , we ob tain inaccurate “partial variances” a nd “pa rtial me ans” for the nodes in the cycle-free graph as well as some “fee dback gains” for the non-feed back node s. Next we c ompute the exact inference res ults for the feedbac k node s. In the se cond round of s tandard BP , we make corrections to the “partial variances” a nd “pa rtial means” of the non-feedbac k no des. Exact inference results are then obtained for a ll nodes . Before de scribing F MP , we introduce some notation. W ith a particular choice , F , of FVS a nd with T = V / F as the remaining cycle-free graph , we can defi ne su bmatrices and su bvectors respec ti vely o f J and h . In particular , let J F denote the information matrix restricted to nodes of F – i.e., for co n venienc e we as sume we have o rdered the nodes in the graph s o that F consists of the first k nod es in V , s o that J F correspond s to the upp er- left k × k block of J , an d similarly J T , the information matrix restricted to nod es in T correspond s to the lower right ( n − k ) × ( n − k ) block of J . W e can a lso de fine J T F , the lo wer left cros s-information matrix, and its transpose (the uppe r -right c ross-information matrix) J F T . Analogous ly we can define the subvectors h F and h T . In add ition, for the graph G an d any node j , let N ( j ) deno te the neighbo rs of j , i.e., the node s connec ted to j by e dges. In this se ction we first de scribe FMP for the example in Figure 3(a), in which the F VS con sists of a single node. Then we describe the g eneral FMP algorithm with multiple fee dback nodes. W e also prove the co rrectness and analyz e the co mplexity . A. The S ingle F eedback Nod e Case Consider the loopy graph in Figure 3(a) and a Gauss ian graphica l mod el, with information matrix J and poten tial vector h , defined on it. Let J and h be the information matrix and p otential vector of the model res pectiv ely . In this graph every cycle pa sses through n ode 1 , and thus node 1 forms an FVS b y itself. W e use T to d enote the sub graph exclud ing node 1 a nd its inc ident edg es. Gra ph T is a tree, which do es not h ave any cycles. 6 Using no de 1 as the feedb ack node, FMP consists of the follo wing 6 More generally , the cycle-free graph used in FMP can be a collection of disconnected trees, i.e., a forest. October 24, 2018 DRAFT 11 steps: Step 1 : Initialization W e construct an ad ditional potential vector h 1 = J T , 1 on T , i.e. h 1 is the s ubmatrix (column vec tor) of J with c olumn index 1 and ro w indices corresp onding to T . Note that, sinc e in this case F = { 1 } , this n ew p otential vec tor is precisely J T F . In the general ca se J T F will c onsist of a set of columns, one for each element of the FVS, where each o f tho se columns is indexed by the n odes in T . Note that h 1 i = J 1 i , for all i ∈ N (1) and h 1 i = 0 , for a ll i / ∈ N (1) ∪ { 1 } . W e can vie w this step as node 1 send ing messag es to its neigh bors to obtain h 1 . See Figure 3(b) for an illustration. Step 2 : First Roun d of BP o n J T (Figure 3(c)) W e n ow perform BP on T twice, both times using the information matrix J T , but two different potential vectors. The first of these is simply the original poten tial vector restricted to T , i.e., h T . The s econd uses h 1 as c onstructed in Step 1. 7 The res ult of the former of these BP sweeps yields for eac h node i in T its “ partial variance” P T ii = ( J − 1 T ) ii and its “partial mean” µ T i = ( J − 1 T h T ) i by stan dard BP messag e pa ssing on T . Note that the se results are not the true variances a nd means since this step d oes not in volv e the contributions of no de 1 . At the same time, BP using h 1 yields a “feedb ack gain” g 1 i , where g 1 i = ( J − 1 T h 1 ) i by s tandard BP on T . 8 Since T is a tree-s tructured grap h, BP terminates in linear time. Step 3 : Exac t Inferenc e for the Feedba ck N ode Feedba ck node 1 collects the “feed back gains ” from its neighbo rs as shown in Figure 3(d). Node 1 then calcu lates its exact vari ance and mean as follows: P 11 = ( J 11 − X j ∈N (1) J 1 j g 1 j ) − 1 , (13) µ 1 = P 11 ( h 1 − X j ∈N (1) J 1 j µ T j ) . (14) In this step, all the computations in volv e only the parameters local to node i , the “ feedbac k gains” from, and the “partial me ans” of node 1 ’ s neighbo rs. Step 4 : Feed back Mes sage Passing (Figure 3(e) ) 7 Note that since both BP passes here – and, in the general case, the set of k + 1 BP passes in this step – use the same information matrix. Hence there are economies in the actual BP message-passing as the variance computations are the same for all. 8 The superscript 1 of g 1 i means this f eedback gain corresponds to the feedback node 1 , notation we need in the general case October 24, 2018 DRAFT 12 After fee dback nod e 1 ob tains its own variance and mea n, it pa sses the res ults to all othe r node s in order to correct their “ partial variances” P T ii and “pa rtial means” µ T i computed in S tep 2. The neigh bors of node 1 revise their node po tentials as follows: e h j = h j − J 1 j µ 1 , ∀ j ∈ N (1) , h j , ∀ j / ∈ N (1) . (15) From (15) we see that only node 1 ’ s neighbors revise their node potentials. The revised p otential vector e h T and J T are then used in the secon d round of BP . Step 5 : Seco nd Ro und of B P on J T (Figure 3(f)) W e perform BP on T with J T and e h T ). The mean s µ i = ( J − 1 T e h T ) i , obtaine d from this round of BP are the e xact mean s. The exact variances can be c omputed by ad ding correction terms to the “p artial variances” as P ii = P T ii + P 11 ( g 1 i ) 2 , ∀ i ∈ T , (16) where the “p artial variance” P T ii and the “ feedback gain” g 1 i are co mputed in Step 2 . There is only one correction term in this single feedback node ca se. W e will se e that wh en the size o f FVS is larger than one, there will be multiple correction terms. B. F eedback Me ssage P assing for Ge neral Graphs For a gene ral grap h, the remov al o f a single node may not break all cycles. Hence , the FVS may consist of multiple nodes. In this ca se, the FMP algo rithm for a sing le feedbac k nod e can be gene ralized by adding extra feedbac k messa ges, wh ere ea ch extra message corresponds to one extra feedbac k node in the FVS. Assume an FVS, F , has been selec ted, and, as indicated pre viously , we order the nodes such that F = { 1 , . . . , k } . T he FMP algorithm with mu ltiple feedback nodes is e ssentially the same as the FMP algorithm with a s ingle feed back node. Whe n there are k feedbac k no des, we c ompute k sets of feedback gains ea ch co rresponding to one feedba ck node. More precisely , Step 1 in the algorithm now in volv es performing BP on T k + 1 times, all with the same information matrix, J T , but with dif ferent potential vectors, namely h T and h p , p = 1 , , k , where thes e are the succes siv e co lumns of J T F . T o obtain the exact inferenc e res ults for the feedb ack no des, we then nee d to solve a n inferenc e problem on a smaller graph, n amely F , o f size k , so that Step 3 in the algorithm becomes one of solving a k -dimensional linear system. Step 4 then is simply modified from the single-no de cas e to provide a revised poten tial vector on T taking into ac count co rrections from e ach of the node s in the FVS. Step 5 then in volves a October 24, 2018 DRAFT 13 (a) A graph with cycles (b) Message initialization (c) First round of BP (d) Forward messages (e) Feedback messages (f) S econd round of BP Fig. 3. The FMP al gorithm with a single feedback node single swee p of BP on T us ing this revised pote ntial vector to co mpute the exact means on T , and the feedback gains , together with the variance computation o n the FVS, provide corrections to the pa rtial variances for each node in T . The general FMP algorithm with a given F VS F is s ummarized in Figure 4. C. Correctness an d Complexity of FMP In this subsection, we a nalyze the correctness and compu tational complexity of FMP . Theorem 1. The feedback mess age passing algorithm des cribed in F igur e 4 results in the exact means and exact varianc es for all no des. Pr oo f: T o make the notation in what follo ws somewhat less cluttered, let J M = J T F so that we can write J = J F J ′ M J M J T and h = h F h T . (17) October 24, 2018 DRAFT 14 Input : information matrix J , p otential vector h and feedba ck vertex set F of size k Output : mea n µ i and variance P ii for every node i 1. Cons truct k extra poten tial vectors: ∀ p ∈ F , h p = J T ,p , each corresp onding to one feedback node. 2. Perform BP on T with J T , h T to obtain P T ii = ( J − 1 T ) ii and µ T i = ( J − 1 T h T ) i for e ach i ∈ T . W ith the k extra potential vectors, calculate the feedba ck gains g 1 i = ( J − 1 T h 1 ) i , g 2 i = ( J − 1 T h 2 ) i , . . . , g k i = ( J − 1 T h k ) i for i ∈ T by BP . 3. Obtain a size- k s ubgraph with b J F and b h F giv en by ( b J F ) pq = J pq − X j ∈N ( p ) ∩T J pj g q j , ∀ p, q ∈ F , ( b h F ) p = h p − X j ∈N ( p ) ∩T J pj µ T j , ∀ p ∈ F , and solve the inferen ce problem o n the s mall graph by P F = b J − 1 F and µ F = b J − 1 F b h F . 4. Revise the potential vector on T by ˜ h i = h i − X j ∈N ( i ) ∩F J ij ( µ F ) j , ∀ i ∈ T . 5. Anothe r round of BP with the re vised po tential vector e h T giv es the exact means for nodes on T . Add c orrection terms to obtain the exact variances for n odes in T : P ii = P T ii + X p ∈F X q ∈F g p i ( P F ) pq g q i , ∀ i ∈ T . Fig. 4. The FMP al gorithm with a giv en FVS Similarly , we can write P = P F P ′ M P M P T and µ = µ F µ T . (18) By the c onstruction of h 1 , h 2 , . . . , h k in FMP and (17), J M = [ h 1 , h 2 , . . . , h k ] . (19) The feedback gains g 1 , g 2 , . . . , g k in FMP are computed by BP with h 1 , h 2 , . . . , h k as potential vectors. Since BP gi ves the exact means on tree s, [ g 1 , g 2 , . . . , g k ] = h J − 1 T h 1 , J − 1 T h 2 , . . . , J − 1 T h k i = J − 1 T J M . (20) October 24, 2018 DRAFT 15 In FMP , µ T is comp uted by BP w ith potential vec tor h T , so µ T = J − 1 T h T . (21) The diago nal of J − 1 T is also calculated exactly in the first round of BP in FMP as P T ii = ( J − 1 T ) ii . Since P = J − 1 , by ma trix computations , we have P T = J − 1 T + ( J − 1 T J M ) P F ( J − 1 T J M ) ′ . (22) Substituting (20) into (22), we hav e P ii = P T ii + X p ∈F X q ∈F g p i ( P F ) pq g q i , ∀ i ∈ T , (23) where P T ii is the “ partial variance” of node i and g p i the “feedb ack gain” in FMP . He re P F is the exact covari ance ma trix of the fee dback nodes in F . This is the same equation as in Step 5 o f FMP . W e need to show that P F is indee d calculated exactly in F MP . By Sc hur’ s complemen t, b J F ∆ = P − 1 F = J F − J ′ M J − 1 T J M and b h F ∆ = P − 1 F µ F = h F − J ′ M J − 1 T h T . (24) By (20) and (21), b J F = J F − J ′ M [ g 1 , g 2 , . . . , g k ] and b h F = h F − J ′ M µ T , (25) which is exactly the same formula a s in Step 3 of FMP . Therefore, we obtain the exac t covariance matrix and exact means for nodes in F by solving P F = ( b J F ) − 1 and µ F = P F b h F . Since µ = J − 1 h , from (17) and (18) we can get µ T = J − 1 T ( h T − J M µ F ) . (26) W e define e h T = h T − J M µ F , i.e., ( e h T ) i = h i − X j ∈N ( i ) ∩F J ij ( µ F ) j , (27) where µ F is the exact me an of nodes in F . This s tep is equiv a lent to performing BP with pa rameters J T and the revised poten tial vector e h T as in S tep 4 o f FMP . This comp letes the proof. W e n ow an alyze the computational co mplexity of FMP with k denoting the size of the FVS a nd n the total number of nod es in the graph. In Step 1 and Step 2, BP is p erformed on T with k + 2 me ssage s (one for J , one with h T , an d one for ea ch h p ). The total complexity is O ( k ( n − k )) . In s tep 3, O ( k 2 ( n − k )) computations a re ne eded to obtain b J F and b h F and O ( k 3 ) o perations to solve the inference problem o n October 24, 2018 DRAFT 16 a graph of size k . In Step 4 an d Step 5, it takes O ( k ( n − k )) computations to gi ve the exact me ans and O ( k 2 ( n − k )) comp utations to a dd correction terms. Therefore, the total complexity is O ( k 2 n ) . The refore, the c omputational comp lexity of FMP is O ( k 2 n ) . Th is is a significa nt reduction from O ( n 3 ) of direct matrix in version wh en k is small. I V . A P P R O X I M AT E F E E D BA C K M E S S AG E P A S S I N G As we have see n from Theorem 1, FMP always gi ves correct inference results. Howe ver , FMP is intractable if the size of the FVS is very lar ge. This motiv ates our development of a ppr oximate FMP , which use s a pse udo-FVS instead of a n FVS. A. Approximate FMP with a Pse udo-FVS There are at lea st two ste ps in FMP w hich are computationally inten siv e when k , the s ize of the FVS, is lar ge: s olving a size - k inference problem in Step 3 and a dding k 2 correction terms to each non-feedba ck node in Step 5. One natural approximation is to use a set of fee dback nod es o f smaller s ize. W e define a pseudo -FVS as a subset of an FVS that do es not break all the cycles. A us eful pseud o-FVS ha s a small size, but breaks the most “crucial” cycles in terms of the resulting inference errors. W e will discu ss how to select a good ps eudo-FVS in Section IV -D. In this su bsection, we assu me that a pseudo-FVS is gi ven. Consider a Gaussian grap hical mod el Markov on a graph G = ( V , E ) . W e u se e F to d enote the g i ven pseudo -FVS, and use e T to de note the pseudo-tree (i.e., a g raph with cycle s) o btained b y eliminating nodes in e F from G . W ith a slight abuse of terminology , we still refer to the nod es in e F as the fee dback nodes. A natural extension is to replace BP by LBP in S tep 2 a nd Step 5 of FMP . 9 The total complexity of app roximate FMP depends on the size of the graph, the cardinality of the pseudo -FVS, a nd the numbe r of iterations of LBP within the p seudo -tree. Let k be the size of the pseudo -FVS, n be the numbe r of nodes, m b e the numbe r of edge s in the g raph, a nd D be the maximum number of iterations in Step 2 and Step 5. By a similar analysis a s for FMP , the total c omputational complexity for ap proximate FMP is O ( k 2 n + k mD ) . Assu ming that we are dea ling with relati vely sparse graphs, so tha t m = O ( n ) , reductions in co mplexity as compared to a use of a full FVS rely on both k and D being of mod erate s ize. Of co urse the ch oices of thos e q uantities must a lso take into acc ount the tradeoff with the ac curacy of the computations . 9 Of course, one can insert other algorithms for Steps 2 and 5 – e. g., iterative algorithms such as embedd ed trees [17] which can yield exact answers. Howe ver , here we focus on the use of LBP for simplicity . October 24, 2018 DRAFT 17 B. Con verg ence a nd Accu racy In this subse ction, we provide theoretical results on co n vergence and accuracy of approx imate FMP . W e first provide a result assuming con vergence that makes several cruc ial points, namely on the exactnes s of means throughout t he entire graph, the exactness of variances on the pseudo-FVS, and on the interpretation of the variances on the remainde r of the grap h as a ugmenting the LBP c omputation with a rich se t of additional walks, roughly s peaking those that go throug h the p seudo-FVS : Theorem 2. Cons ider a Gaus sian graphical mo del with pa rameters J a nd h . If app r ox imate FMP con v erg es with a pseu do-FVS e F , it give s the correct means for all nodes and the correct varian ces on the pseudo -FVS. The variance of node i in e T calculated by this algorithm equals the sum of all the backtrac king walks of nod e i within e T plus all the self-r eturn walks of no de i that visit e F , so that the only walks missed in the comp utation of the varianc e at node i are the non-backtracking walks within e T . Pr oo f: W e have J = J e F J ′ M J M J e T and h = h e F h e T . (28) By Result 3) in Section II- C, when LBP con verges, it gives the correct means. Hence, after con ver gence , for i = 1 , 2 , . . . , k , we have g i = J − 1 e T J e T ,i , and µ e T = J − 1 e T h e T , where g i is the feedba ck gain corresponding to feedback node i and µ e T is the partial mean in app roximate FMP . The se quantities are exact after conv ergence. Since g i and µ e T are c omputed exac tly , following the sa me s teps as in the proof of Theorem 1, we can obtain the exact means and v ariances for n odes in e F . From the proof of Theorem 1, we a lso have µ e T = J − 1 e T ( h e T − J M µ e F ) . (29) W e have sh own that µ e F is comp uted exactly in Step 3 in app roximate F MP , so h e T − J M µ e F is computed exac tly . Since LBP on e T gi ves the exact means for any poten tial vector , the means of a ll nodes in e T are exact. As in the proof of Theorem 1, we have that the exact covariance matrix o n e T is g i ven by P e T = J − 1 e T + ( J − 1 e T J M ) P e F ( J − 1 e T J M ) ′ . (30) October 24, 2018 DRAFT 18 As noted previously , the exact variance of node i ∈ e T e quals the sum of all the s elf-return walks of node i . W e pa rtition these walks into two clas ses: self-return walks of node i within e T , and self-returns walks that visit at leas t one node in e F . The diagona l of J − 1 e T captures exa ctly the first clas s o f walks. Hence, the second term in the right-hand side of (30) corresponds to the sum of the second class of walks. Let us compare eac h o f these terms to what is c omputed by the approx imate FVS algorithm. By Result 4) in Se ction II-C, LBP on e T gives the s ums o f all the bac ktracking walks after con ver g ence. So the first term in (30) is a pproximated b y ba cktracking walks. However , note that the terms J − 1 e T J M and P e F are obtained exac tly . 10 Hence, the approx imate FMP algorithm computes the sec ond term exactly and thus p rovides precisely the second set of walks. As a result, the only walks missing from the exac t computation of vari ances in e T are non -backtracking walks within T . This completes the proof. W e now state several conditions unde r which we can guaran tee con vergence. Proposition 1. Consider a Gaussian graphical mo del with graph G = ( V , E ) and model parameters J and h . If the mod el is walk-su mmable, appr ox imate FMP con v erg es for any pseu do-FVS e F ⊂ V . Pr oo f: Let R = I − J and ( ¯ R ) ij = | R ij | . In approx imate FMP , LBP is pe rformed on the p seudo -tree induced by e T = V \ e F . Th e information matrix on the pseud o-tree is J e T , which is a s ubmatrix of J . By Corollary 8.1.2 0 in [32] , for a ny e T ρ ( ¯ R e T ) ≤ ρ ( ¯ R ) < 1 . (31) By Result 3) in Section II-C, LBP on e T is guaranteed to con verge. All other c omputations in approxi- mate FMP terminate in a fin ite number of steps . He nce, ap proximate F MP con verges for any pseud o-FVS e F ⊂ V . For the rema inder of the paper we will refer to the quan tities a s in (31) as the sp ectral radii of the correspond ing grap hs (in this case e T and the original graph G ). W alk-summa bility on the en tire graphical model is actually far stronger than is needed for approx imate FMP to con verge. As the proo f of Prop osition 1 suggests , all we rea lly need is for the grap hical mod el on the g raph exc luding the pseud o-FVS to be walk-summable. As we will dis cuss in Section IV -D , this objectiv e provides one of the driv ers for a very simple algorithm for choosing a pse udo-FVS in order to enh ance the walk-summability of the remaining graph and as well as accuracy of the res ulting LBP variance computations . 10 Note t hat the columns of the former are just the feedback gains computed by LBP for each of the additional potential vectors on e T corresponding to columns of J e T e F , which we hav e already seen are computed ex actly , as we hav e f or the cov ariance on the pseudo-FVS. October 24, 2018 DRAFT 19 Remarks: Th e followi ng two res ults follo w directly from Propo sition 1. 1) Consider a walk- summable Gaussian graphical mode l. Le t e F j be a ps eudo-FVS c onsisting of j nodes and ∅ 6 = e F 1 ⊆ e F 2 ⊆ · · · ⊆ e F k ⊆ F , where F is an FVS, then W LBP i ⊆ W e F 1 i ⊆ W e F 2 i ⊆ . . . ⊆ W e F k i ⊆ W F i for any n ode i in the g raph. Here W LBP i is the set of walks captured by LBP for calculating the v ariance of n ode i ; W e F j i is the s et of walks ca ptured by approximate FMP with pseudo -FVS e F j ; and W F i is the set of walks ca ptured by FMP with FVS F . 2) Consider an attracti ve Gaussian graphical model (i.e., one in which all elements of R are non- negati ve). Let e F 1 ⊆ e F 2 ⊆ · · · ⊆ e F k ⊆ F deno te the pseudo-FVS (FVS), and P LBP ii , P e F 1 ii , . . . , P e F k ii , P F ii denote the correspond ing vari ances ca lculated for node i by LBP , ap proximate FMP and FMP respe cti vely . P ii represents the exact variance of node i . W e have P LBP ii ≤ P e F 1 ii ≤ P e F 2 ii ≤ · · · ≤ P e F k ii ≤ P F ii = P ii for any node i in V . The above results show that with app roximate FMP , we can effecti vely trade of f complexity and accuracy by selecting p seudo-FVS of dif feren t sizes . C. Err or Bounds for V arian ce Computation W e define the mea sure of the error of a n inference algorithm for Gaussian graph ical models as the av erage abso lute error of variances for all nodes: ǫ = 1 n X i ∈V | b P ii − P ii | , (32) where n is the number of nodes , b P ii is the computed vari ance of node i by the algorithm and P ii is the exact v ariance of no de i . Proposition 2. Conside r a walk-summa ble Gaussian graphical model with n nodes. Ass ume the infor- mation matr ix J is normalized to ha ve unit diagonal. Le t ǫ FMP denote the err or of appr oximate FMP and b P FMP ii denote the estimated varianc e o f node i . Then ǫ FMP = 1 n X i ∈V | b P FMP ii − P ii | ≤ n − k n ˜ ρ ˜ g 1 − ˜ ρ , where k is the n umber of fee dback node s, ˜ ρ is the spectral radius corresponding to the su bgraph e T , and ˜ g den otes the girth of e T , i.e., the length o f the sho rtest cycle in e T . In particular , when k = 0 , i.e., LBP is use d on the e ntir e graph, we have ǫ LBP = 1 n X i ∈V | b P LBP ii − P ii | ≤ ρ g 1 − ρ , October 24, 2018 DRAFT 20 where the no tation is s imilarly defined . Some of the followi ng p roof techniques are moti vated by the proof of the error bound on determinant estimation with the so-called orbit-product representation in [33]. Pr oo f: By Theorem 2, ǫ LBP = 1 n X i ∈V | φ ( i NB − → i ) | , (33) where φ ( i NB − → i ) denotes the su m of all non-back tracking s elf-return walks of no de i . W e have ǫ LBP = 1 n X i ∈V | φ ( i NB − → i ) | ≤ 1 n X i ∈V ¯ φ ( i NB − → i ) , (34) where ¯ φ ( · ) den otes the s um of ab solute weight of walks, or walk-sums defi ned on ¯ R . Non-backtrack ing self-return walks must contain a t lea st one cycle. So the minimum length of a non-back tracking walk is g , which is the minimum leng th of cycles. Thus ǫ LBP ≤ 1 n X i ∈V ¯ φ ( i NB − → i ) ≤ 1 n X i ∈V ∞ X m = g ( ¯ R m ) ii (35) = 1 n T r( ∞ X m = g ( ¯ R m )) = 1 n ∞ X m = g T r( ¯ R m ) . (36) Let λ i ( · ) denotes the i th largest eigen value of a matrix. S ince λ i ( ¯ R m ) = λ i ( ¯ R ) m and λ i ( ¯ R ) ≤ ρ , we have T r( ¯ R m ) = n X i =1 λ i ( ¯ R ) m ≤ nρ m . (37) Therefore, ǫ LBP ≤ 1 n ∞ X m = g nρ m = ρ g 1 − ρ . (38) When app roximate FMP is used with a size- k ps eudo-FVS, the variances of n odes in the pseudo-FVS are computed exac tly , while the vari ance errors for other nodes are the same as p erforming LBP on the subgraph excluding the ps eudo-FVS. The refore, ǫ FMP = 1 n X i ∈V | ˆ P ii − P ii | = 1 n X i ∈ e T | ˆ P ii − P ii | (39) = 1 n ( n − k ) ǫ L B P ≤ n − k n ˜ ρ ˜ g 1 − ˜ ρ . (40 ) An immediate conclusion of Proposition 2 is that if a graph is cycle-free (i.e., g = ∞ ), the error ǫ LBP is ze ro. October 24, 2018 DRAFT 21 W e can also a nalyze the performance of FMP on a Gaussian g raphical mod el tha t is Markov on a Erd ˝ os-R ´ enyi random graph G ( n, c/n ) . Each edg e in such a random g raph with n nodes appe ars with probability c/n , independe nt of every other edge in the graph [34]. Proposition 3. Consider a se quence of graphs {G n } ∞ n =1 drawn fr om Er dos-Reny i model G ( n, c/n ) with fixed c . Su ppose we ha ve a seque nce of Gaussian g raphical models parameterized by { ( J n , h n ) } ∞ n =1 that ar e Markov on { G n } ∞ n =1 and a r e strictly walk-su mmable (i.e., the spectral radii ρ ( ¯ R n ) are uniformly upper bounde d away fr om unity). The n as ymptotically a lmost surely ther e exists a s equenc e of pseudo - FVS { e F n } ∞ n =1 with e F n of s ize O (log n ) , with w hich the err or of ap pr o ximate FMP as in (32) appr oaches zer o. Pr oo f: W e can obtain a graph with girth greater than l by removing one n ode a t ev ery cyc le of length up to l . The numb er of cycles of length up to l in G ( n, c/n ) is O ( c l ) as ymptotically almos t su rely (Corollary 4.9 in [34]). S o we can ob tain a graph of girth log log n by re moving O (log n ) nodes. By Proposition 2, the error a pproache s zero wh en n approache s infinity . D. F ind ing a go od Pseu do-FVS of Bounde d Size One goal of choosing a go od ps eudo-FVS is to e nsure that LBP c on verges on the remaining subgraph; the othe r g oal is to obta in smaller inference errors. In this subsec tion we d iscuss a loca l selec tion criterion moti vated by these two go als and show that the two g oals are co nsistent. Let ¯ R deno te the abso lute edge weight matrix. Since ρ ( ¯ R ) < 1 is a sufficient condition for LBP to con verge on graph G , o btaining c on vergence red uces to that of removing the minimum nu mber of nodes such that ρ ( ¯ R e T ) < 1 for the rema ining graph e T . Howev er , searching a nd checking this c ondition over all p ossible se ts of pseudo-FVS’ s up to a desired cardinality is a prohibiti vely expensiv e, a nd instead we seek a local me thod (i.e., using only q uantities associate d with individual node s) for choo sing n odes for our pseudo -FVS, one at a time, to en hance con vergence. The principal motiv ation for our ap proach is the following bound [32] on the s pectral radius of a nonnegative ma trix: min i X j ¯ R ij ≤ ρ ( ¯ R ) ≤ m ax i X j ¯ R ij . (41) W e further s implify this prob lem by a greedy he uristic: one feedb ack node is chose n a t eac h iteration. This provides a basis for a simple greed y metho d for cho osing nod es for our pse udo-FVS. In particular , at each stage , we exa mine the graph excluding the node s already included in the p seudo -FVS a nd s elect the node with the largest sum of edge we ights, i.e., argmax i P j ¯ R ij . W e then remove the node from October 24, 2018 DRAFT 22 Input: information matrix J an d the maximum size k o f the pse udo-FVS Output: a p seudo -FVS e F 1. Let e F = ∅ a nd normalize J to hav e unit diagon al. 2. Repeat until | e F | = k or the remaining graph is empty . (a) C lean up the current g raph by eliminating all the tree branche s. (b) Up date the scores s ( i ) = P j ∈N ( i ) | J ij | . (c) P ut the node with the lar gest s core into e F and remove it from the cu rrent graph. Fig. 5. The pseudo-FVS selection criterion the graph a nd put it into e F . W e continue the sa me procedure on the remaining grap h until the ma ximum allowed s ize k o f ˜ F is reached or the remaining graph does not h av e any cycles. The selec tion algorithm is summarized in Figure 5. Note that while the moti vati on just g i ven for this method is to enhance con vergence of LBP on e T , we a re also enha ncing the accuracy of the res ulting algorithm, as Proposition 2 s uggests , sinc e the sp ectral radius ρ ( ¯ R ) is reduce d with the removal of nodes. In a ddition, as shown in T heorem 2, the only approximation our algorithm makes is in the computation o f variances for n odes in e T , and those errors correspond to non-back tracking s elf-return walks confined to e T (i.e., we do capture non-backtrack ing self-return walks that exit e T and visit nodes in the pse udo-FVS). Thus, as we procee d with our selection of nodes for o ur pse udo-FVS, it makes s ense to n odes with the lar gest e dge-weights to n odes that a re left in e T , which is precisely wha t this app roach accomp lishes. The complexity of the selection algorithms is O ( k m ) , where m is the number of edges a nd k is the size o f the pseudo FVS. As a res ult, cons tructing a pseudo-FVS in this ma nner is compu tationally simple and negligible comp ared to the inferenc e algorithm that then exploits it. Finding a suitab le pse udo-FVS is important. W e will se e in Section V that there is a hu ge pe rformance dif ference between a go od s election a nd a bad selection of ˜ F . In addition, expe rimental results show that with a go od choice of ps eudo-FVS (us ing the algorithms just d escribed), we not o nly can get excellent con vergence and accuracy res ults but ca n do this with ps eudo-FVS of cardina lity k a nd n umber of iterations D that scale well with the graph size n . Empirically , we find that we only ne ed O (log n ) feedback nodes a s we ll as very few iterations to obtain exc ellent performance, and thus the complexity is O ( n log 2 ( n )) . October 24, 2018 DRAFT 23 V . N U M E R I C A L R E S U LT S In this se ction, we apply approx imate FMP to graphica l models tha t a re Markov on two-dimension al grids and pres ent results detailing the con vergence and c orrectness of our propo sed algorithm. T w o- dimensional grids are sparse since e ach node is connected to a ma ximum of four neighbors. There hav e been many studies of inferenc e problems on grids [35]. Ho wev er , inference can not, in general, be solved exactly in linear time due to the existence of many cycles of various lengths . It is kn own that the size of the FVS for a grid grows linea rly with the numbe r of node s on the grid [36]. Hence , we use a pproximate FMP with a pse udo-FVS of bounde d size to e nsure that inferenc e is tractable. In our s imulations, we c onsider l × l grids with dif feren t values of l . Th e size of the graph is thu s n = l 2 . W e rand omly ge nerate an information ma trix J tha t has the sparsity pattern corresp onding to a grid. Its no nzero off -diagonal entries are drawn from an i.i.d. uniform dis trib u tion with support in [ − 1 , 1] . W e ens ure J is p ositi ve definite by ad ding λI for su f ficiently large λ . W e also generate a potential vector h , wh ose entries are drawn i.i.d. from a uniform d istrib u tion with sup port in [ − 1 , 1] . W ithout loss of generality , we then normalize the information matrix to h av e unit diagon al. A. Con verg ence o f Approximate FMP In Figure 6, we ill ustrate our pse udo-FVS sele ction procedure to remove one node at a time for a graphical model con structed as just-des cribed on a 10 × 10 grid. The remaining graph s, a fter removing 0 , 1 , 2 , 3 , 4 , and 5 nodes , and their correspon ding s pectral radii ρ ( ¯ R ) are s hown in the figures. LBP does no t co n verge on the e ntire graph and the correspon ding s pectral radius is ρ ( ¯ R ) = 1 . 0477 . When on e feedback node is cho sen, the spe ctral radius c orrespond ing to the rema ining graph is red uced to 1 . 0415 . After removing one more node from the g raph, the sp ectral radius is further reduced to 0 . 972 49 , which ensures conv ergence. In all experiments on 10 × 10 g rids, we obse rve that by choos ing only a few no des (at most three empirically) for our pseudo-FVS, we can obtain con vergence even if LBP on the original graph diver ge s. In Figure 7 we show that the spe ctral rad ius and its upper bound given in (41) d ecrease when more nodes are included in the pseudo-FVS. Con ver gence of a pproximate FMP is immed iately guarante ed when the s pectral radius is less than one. B. Accu racy o f Approximate FMP In this s ubsection, we show numerical resu lts of the inferenc e e rrors define d in (32). On e ach grid, LBP and the ap proximate FMP algorithms with two different s ets of feedb ack n odes are performed. One October 24, 2018 DRAFT 24 1 n o d e re m o ve d : ρ =1 .0 4 1 5 5 n o d e s re m o ve d : ρ =0 .8 6 6 7 3 4 n o d e s re m o ve d : ρ =0 .9 5 6 3 1 3 n o d e re m o ve d : ρ =0 .9 5 6 3 8 2 n o d e s re m o ve d : ρ =0 .9 7 2 4 9 O ri g i n a l g ra p h : ρ = 1 .0 4 77 Fig. 6. Size of the pseudo-FVS and t he spectral radius of t he corresponding remaining graph set has k = ⌈ log n ⌉ fee dback nodes wh ile the other has k = √ n feedbac k node s. T he horizontal axis shows the nu mber o f me ssage pa ssing iterations. Th e vertical axis shows the errors for both variances and mean s on a logarithmic scale. 11 In Figures 8 to 12, nume rical results are shown for 10 × 10 , 20 × 20 , 40 × 40 and 80 × 80 grids respectively . 12 Except for the model in Figure 8, LBP fail s to con ver ge for all mode ls. W ith k = ⌈ log n ⌉ feedback nodes, approximate FMP conv erges for all the grids and giv es much better acc uracy than LBP . In Figure 8 w here LBP conv er ges o n the original graph , we obtain more acc urate variances and improved conv er gence rates using approximate F MP . In Figure 9 to 12, LBP diver ge s while approximate FMP gives inference results with small e rrors. When k = √ n feed back node s are use d, we obtain even better a pproximations b ut with more compu tations in each iteration. W e performed approximate FMP on d if fe rent g raphs with different parame ters, an d emp irically obs erved that k = ⌈ log n ⌉ fee dback nodes seem to be sufficient to giv e a conv er gent algorithm a nd good ap proximations. Remarks: The question, of course, arises as to whether it is simply the size of the pseud o-FVS that 11 The error of means is defined in the manner as variances – the ave rage of the absolute errors of means for all nodes. 12 Here we use shorthand terminology , where k -F VS refers t o running our approximate FMP algorithm with a pseudo-FVS of cardinality k . October 24, 2018 DRAFT 25 0 2 4 6 8 10 12 14 16 18 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 Number of selected feedback nodes Value spectral radius bound of spectral radius (a) 10 × 10 grid 0 2 4 6 8 10 12 14 16 18 0.9 1 1.1 1.2 1.3 1.4 1.5 1.6 Number of selected feedback nodes Value spectral radius bound of spectral radius (b) 20 × 20 grid 0 2 4 6 8 10 12 14 16 18 0.8 0.9 1 1.1 1.2 1.3 1.4 1.5 1.6 Number of selected feedback nodes Value spectral radius bound of spectral radius (c) 40 × 40 grid 0 2 4 6 8 10 12 14 16 18 0.9 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 Number of selected feedback nodes Value spectral radius bound of spectral radius (d) 80 × 80 grid Fig. 7. Number of selected feedback nodes v .s. the spectral radius and it s bound is important. However , numerical results show that approximate FMP do es not give satisfactory results if we choose a “ bad” pseudo -FVS. In Figure 13, we present res ults to demonstrate that the a pproximate FMP algo rithm with a ba dly se lected pseud o-FVS indeed performs poorly . Th e pseud o-FVS is s elected by the oppos ite criterion o f the algorithm in Figure 5, i.e., the node with the sma llest s core is selec ted at ea ch iteration. W e c an see that LBP , 7-FVS, and 40-FVS algorithms all fail to c on verge. T hese results sugges t that when a suitable s et of feedbac k node s are selected, we can le verage the g raph s tructure an d model parameters to dramatically improve the qua lity of inference in Gaussian grap hical models. V I . C O N C L U S I O N S A N D F U T U R E D I R E C T I O N S In this pa per we have d ev eloped the feedback messag e pa ssing algorithm where we first identify a set of feedback nodes. The algorithm structure in volv es first employing BP algorithms on the remaining graph October 24, 2018 DRAFT 26 1 2 3 4 5 6 7 8 9 10 −6.5 −6 −5.5 −5 −4.5 −4 −3.5 −3 −2.5 −2 −1.5 LBP 5−FVS 10−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of variances fo r 10 × 1 0 grid (a) Evo lution of v ariance errors with iterations 1 2 3 4 5 6 7 8 9 10 −14 −12 −10 −8 −6 −4 −2 0 LBP 5−FVS 10−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 10 × 10 gr id (b) E volution of mean errors with iterati ons Fig. 8. Inference errors of a 10 × 10 grid 0 5 10 15 20 25 30 35 40 −8 −6 −4 −2 0 2 4 6 LBP 5−FVS 10−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of variances fo r 10 × 1 0 grid (a) Evo lution of v ariance errors with iterations 0 5 10 15 20 25 30 35 40 −40 −35 −30 −25 −20 −15 −10 −5 0 5 LBP 5−FVS 10−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 10 × 10 gr id (b) E volution of mean errors with iterati ons Fig. 9. Inference errors of a 10 × 10 grid (excluding the FVS), although with several dif ferent s ets of node potentials at n odes tha t a re neighbors of the FVS; then using the results of these co mputations to p erform exact inferenc e on the FVS; an d then employing BP on the remaining graph ag ain in order to correct the answe rs on those node s to yield exa ct answers. The fee dback mess age pa ssing algorithm solves the inferenc e problem exactly in a Gaussian graphical mode l in linear time if the graph h as a FVS of bound ed s ize. Henc e, for a graph with a large FVS, we propose an approximate feedback message pass ing algorithm that cho oses a sma ller “p seudo - FVS” and replac es BP on the remaining graph with its loopy counterpa rt LBP . W e provide theoretical results that s how that, assuming con vergence of the LBP , we still obtain exact inference results (means October 24, 2018 DRAFT 27 0 10 20 30 40 50 60 70 80 −6.5 −6 −5.5 −5 −4.5 −4 −3.5 −3 −2.5 −2 LBP 6−FVS 20−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of variances fo r 20 × 2 0 grid (a) Evo lution of v ariance errors with iterations 0 10 20 30 40 50 60 70 80 −40 −35 −30 −25 −20 −15 −10 −5 0 LBP 6−FVS 20−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 20 × 20 gr id (b) E volution of mean errors with iterati ons Fig. 10. Inference errors of a 20 × 20 grid 0 5 10 15 20 25 30 35 40 −6 −5.5 −5 −4.5 −4 −3.5 −3 −2.5 −2 −1.5 LBP 7−FVS 40−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 40 × 40 gr id (a) Evo lution of v ariance errors with iterations 0 5 10 15 20 25 30 35 40 −40 −35 −30 −25 −20 −15 −10 −5 0 5 10 LBP 7−FVS 40−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 40 × 40 gr id (b) E volution of mean errors with iterati ons Fig. 11. Inference errors of a 40 × 40 grid 0 10 20 30 40 50 60 70 80 −5.5 −5 −4.5 −4 −3.5 −3 −2.5 LBP 9−FVS 80−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 80 × 80 gr id (a) Evo lution of v ariance errors with iterations 0 10 20 30 40 50 60 70 80 −35 −30 −25 −20 −15 −10 −5 0 5 LBP 9−FVS 80−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 80 × 80 gr id (b) E volution of mean errors with iterati ons Fig. 12. Inference errors of an 80 × 80 grid October 24, 2018 DRAFT 28 0 5 10 15 20 25 30 35 40 −3.5 −3 −2.5 −2 −1.5 −1 −0.5 0 0.5 LBP 7−FVS 40−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of variances fo r 40 × 4 0 grid (a) Evo lution of v ariance errors with iterations 0 5 10 15 20 25 30 35 40 −3 −2 −1 0 1 2 3 4 5 6 LBP 7−FVS 40−FVS P S f r a g r e p l a c e m e n t s Iterations Log of error Error of means for 40 × 40 gr id (b) E volution of means errors with iterati ons Fig. 13. Inference errors w ith a bad selection of feedback nodes and variances) on the pseudo-FVS, exact means on the entire graph , and approximate variances o n the remaining n odes that have precise interpretations in terms of the additional “walks” that are c ollected a s compared to LBP on the entire g raph. W e also provide bound s on accuracy , and these, togethe r with an examination of the walk-summability co ndition, provide an a lgorithm for choosing nod es to include in the pseudo -FVS. Our experimental resu lts demo nstrate that these algorithms lead to excellent performance (including for mode ls in which LBP diver ges ) with pseudo-FVS size that grows only logarithmically with graph s ize. There are many future research directions based on the ideas of t his pape r . For examples, more extensiv e study of the performance of approximate FMP on random graphs is of great interes t. In add ition, a s we have pointed out, LB P is o nly one pos sibility for the inference algorithm used on the remaining grap h after a pseudo-FVS is cho sen. One intriguing possibility is to indeed use app roximate FMP itself on this remaining graph – i.e., nes ting a pplications o f this a lgorithm. This is cu rrently un der in ves tigation, as are the use o f these algorithmic constructs for othe r important prob lems, inc luding the learning of graph ical models with small FVS’ s and using an FVS or p seudo-FVS for efficient sampling of Gaussian graph ical models. V I I . A C K N O W L E D G M E N T W e thank Deva vrat Shah , Justin Dauwels, a nd V incent T an for helpful dis cussions . October 24, 2018 DRAFT 29 R E F E R E N C E S [1] Y . Liu, V . Chandrasekaran, A. Anandkumar , and A. W illsky , “Feedb ack message passing f or inference in Gaussian graphical models, ” in P r oc. of IEEE ISIT , Austin, USA, Jun. 2010. [2] M. Sonka, V . Hlav ac, and R. Boyle, Image pro cessing, analysis, and machine vision, second edition . International Thomson, 1999. [3] A. W erhli, M. Grzegorczyk , and D. Husmeier, “Comparativ e ev aluation of reverse engineering gene regulatory networks with relev ance networks, graphical Gaussian models and Bayesian networks , ” Bioinformatics , vol. 22, no. 20, p. 2523, 2006. [4] D. Heckerman and J. Breese, “Causal i ndepend ence for probability assessment and inference using Bayesian networks, ” IEEE T ransa ctions on Systems, Man, and Cybernetics, P art A: Systems and Humans , vol. 26, no. 6, pp. 826–831, 1996 . [5] C. Wu nsch and P . Heimbach, “Practical global oceanic state estimation, ” Physica D: Nonlinear Phenomena , vol. 230, no. 1-2, pp. 197–208, 2007. [6] H. El Gamal and A. Hammons, “Analyzing the t urbo decoder using the Gaussian approximation, ” IEE E T ransa ctions on Information Theory , vo l. 47, no. 2, pp. 671–6 86, 2001. [7] J. Fry and E . Gaztanaga, “Biasing and hierarchical statistics in large-scale str ucture, ” The Astr ophysical Jou rnal , vol. 413, p. 447, 1993. [8] L. Y ang, X. Liu, C. Jursa, M. Holliman, A. Rader, H. Karimi, and I. Bahar , “iGNM: a database of protein functional motions based on Gaussian Network Model, ” Bioinformatics , vol. 21, no. 13, p. 2978, 2005. [9] M. Jordan, “Graphical models, ” Statistical Science , pp. 140–155 , 2004. [10] K. Murp hy , Y . W eiss, and M. Jordan, “Loop y belief propagation for approximate inference: an empirical study, ” in Pr oceedings of Uncertainty i n Artificial Intelli genc e , 1999, pp. 467–475. [11] C. Crick and A. Pfeffer , “Loopy belief propagation as a basis for communication i n sensor networks, ” i n Uncertainty in Artificial Intelligence , vol. 18, 2003. [12] R. McEliece, D. MacKay , and J. Cheng, “Turb o decoding as an instance of P earl’ s belief propag ation algorithm, ” IEEE J ournal on Selected Areas i n Communications , vol. 16, no. 2, pp. 140–1 52, 1998. [13] A. Ihler, J. Fisher , and A. Willsky , “L oopy belief propagation: Con verg ence and effects of message errors, ” Jo urnal of Mach ine Learning Resear ch , vol. 6, no. 1, p. 905, 2006. [14] Y . W eiss and W . Freeman, “Correctness of belief propagation in Gaussian graphical models of arbitrary topology, ” Neural Computation , vol. 13, no. 10, pp. 2173–2200, 2001. [15] S. T atiko nda and M. Jordan, “Loopy belief propagation and Gibbs measures, ” in Uncertainty in Artificial Intell igence , vol. 18, 2002, pp. 493–500. [16] D. Malioutov , J. Johnson, and A. Willsky , “W alk-sums and belief propagation in G aussian graphical models, ” Journal of Mach ine Learning Resear ch , vol. 7, pp. 2031–2064, 2006. [17] V . Chandrasekaran, J. Johnson , and A. W il lsky , “Estimation i n Gaussian graphical models using tractable subgrap hs: A walk-sum analysis, ” Signal Pr ocessing, IEE E T ransactions on , vol. 56, no. 5, pp. 1916–1 930, 2008. [18] J. Pearl, “A constraint propagation approach to probabilistic reasoning, ” In Uncertainty in Arti ficial Intelligence , 1986. [19] A. Darwiche, “Recursi ve conditioning, ” A rtificial Intelligence , vol. 126, no. 1-2, pp. 5–41, 2001. [20] S. Lauritzen, Graphical models . Oxford U ni versity Press, USA, 1996. [21] T . Speed and H. Kiiveri, “Gaussian Marko v distribution s ov er finite graphs, ” The Annals of Statistics , vo l. 14, no. 1, pp. 138–15 0, 1986. October 24, 2018 DRAFT 30 [22] V . V azirani, A ppr oximation algorithms . Springer , 2004. [23] R. Karp, “Redu cibility among co mbinatorial problems, ” Complexity of Compu ter Computations , vol. 43, pp. 85–1 03, 1972. [24] F . Fomin, S. Gaspers, A. Pyatkin, and I. Razgon, “On the minimum feedback vertex set problem: exact and enumeration algorithms, ” Algorithmica , vo l. 52, no. 2, pp. 293–307, 2008. [25] P . Erd ˝ os and L. P ´ osa, “On the maximal number of disjoint circuits of a graph, ” Publicationes Mathematicae Debr ecen , vol. 9, pp. 3–12, 1962. [26] R. Bar-Y ehu da, D. Geiger, J. Naor , and R. Roth, “Approximation algorithms for the verte x feedback set problem with applications to constraint satisfaction and Bayesian inference, ” in Procee dings of the 5th Annual ACM-SIAM Symposium on Discrete Algorithms . Society for Industrial and Applied Mathematics, 1994, pp. 344–354 . [27] V . Bafna, P . Berman, and T . Fujit o, “A 2-approximation algorithm for the undirected feedback vertex set problem, ” SIAM J ournal on Discr ete Mathematics , vol. 12, p. 289, 1999. [28] A. Shamir , “A linear time algorithm for finding minimum cutsets in reducible graphs, ” SIAM J ournal on C omputing , vol. 8 , p. 645, 1979. [29] C. W ang, E. Lloyd , and M. S off a, “Feedback vertex sets and cyclically reducible graphs, ” J ournal of t he ACM , vol. 32, no. 2, pp. 296–31 3, 1985. [30] D. Kratsch, H. M ¨ uller , and I. T odinca, “F eedback vertex set on A T -free graphs, ” Discr ete Applied Mathematics , vo l. 156, no. 10, pp. 1936–194 7, 2008. [31] F . Dehne, M. Fellows, M. L angston, F . Rosamond, and K. Stev ens, “An O ( 2 O ( k ) n 3 ) FPT algorithm for the undirected feedback vertex set problem, ” Theory of Computing Systems , vo l. 41, no. 3, pp. 479–492 , 2007. [32] R. Horn and C. Johnson , Matrix analysis . Cambridge Univ ersity P ress, 1990. [33] J. Johnson, V . Cherny ak, and M. Chertkov , “Orbit-produc t representation and correction of Gaussian belief propagation, ” in Pro ceedings of the 26th Annual International Confer ence on Machin e L earning . ACM , 2009, pp. 473–48 0. [34] B. Bollob ´ as, Random grap hs . Cambridge Univ ersity Press, 2001. [35] A. George, “Nested dissection of a regular fi nite element mesh, ” SIAM Journal on Numerical Analysis , vol. 10, no. 2, pp. 345–36 3, 1973. [36] F . Madelaine and I. S tew art , “Improved upper and lower bounds on t he feedback vertex numbers of grids and butterflies, ” Discr ete Mathematics , vo l. 308, no. 18, pp. 4144– 4164, 2008. October 24, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment