Output-Sensitive Adaptive Metropolis-Hastings for Probabilistic Programs
We introduce an adaptive output-sensitive Metropolis-Hastings algorithm for probabilistic models expressed as programs, Adaptive Lightweight Metropolis-Hastings (AdLMH). The algorithm extends Lightweight Metropolis-Hastings (LMH) by adjusting the pro…
Authors: David Tolpin, Jan Willem van de Meent, Brooks Paige
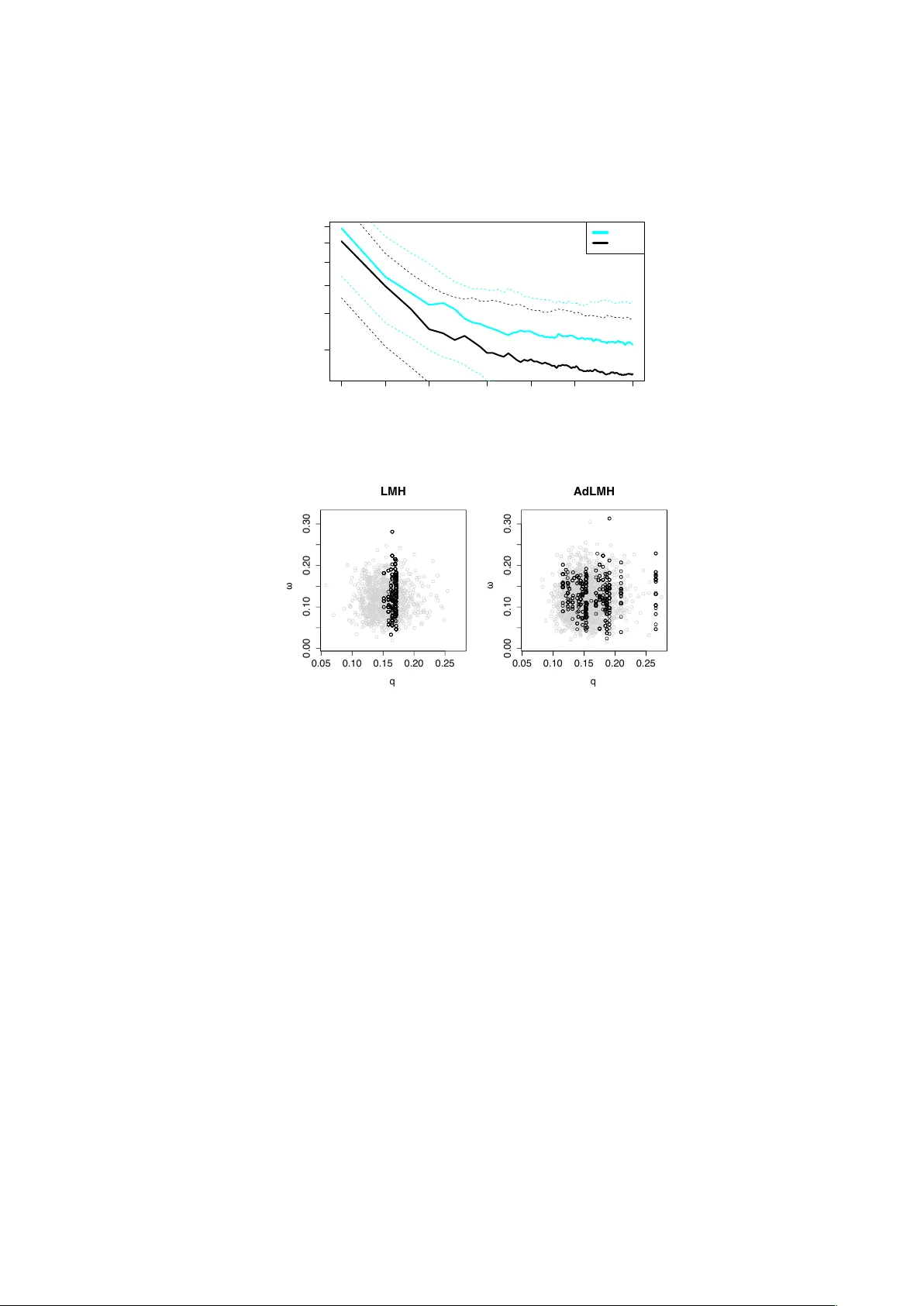
Output-Sensitiv e Adaptiv e Metrop olis-Hastings for Probabilistic Programs Da vid T olpin, Jan Willem v an de Meent, Brooks Paige, and F rank W oo d Univ ersity of Oxford Departmen t of Engineering Science {dtolpin, jwvdm, brooks, fwood}@robots.ox.ac.uk Abstract. W e in tro duce an adaptive output-sensitive Metrop olis-Hast- ings algorithm for probabilistic models expressed as programs, Adap- tiv e Light w eight Metrop olis-Hastings (AdLMH). The algorithm extends Ligh tweigh t Metrop olis-Hastings (LMH) by adjusting the probabilities of proposing random v ariables for modification to improv e con vergence of the program output. W e sho w that AdLMH conv erges to the correct equilibrium distribution and compare conv ergence of AdLMH to that of LMH on several test problems to highlight different asp ects of the adap- tation sc heme. W e observ e consisten t impro vemen t in conv ergence on the test problems. Keyw ords: Probabilistic programming, adaptiv e MCMC 1 In tro duction One strategy for improving con v ergence of Mark ov Chain Monte Carlo (MCMC) samplers is through online adaptation of the proposal distribution [1,2,14]. An adaptation sc heme must ensure that the sample sequence conv erges to the cor- rect equilibrium distribution. In a comp onent wise up dating Metropolis-Hastings MCMC, i.e. Metrop olis-within-Gibbs [5,8,10], the prop osal distribution can be decomp osed in to t wo comp onen ts: 1. A sto c hastic schedule (probabilit y distribution) for selecting the next random v ariable for mo dification. 2. The kernels from which new v alues for each of the v ariables are prop osed. In this pap er w e concentrate on the first comp onen t—adapting the schedule for selecting a v ariable for mo dification. Our primary interest in this work is to impro ve MCMC metho ds for proba- bilistic programming [6,7,11,16]. Probabilistic programming languages facilitate dev elopment of general probabilistic models using the expressiv e pow er of gen- eral programming languages. The goal of inference in such programs is to reason ab out the posterior distribution o ver random v ariates that are sampled during execution, conditioned on observ ed v alues that constrain a subset of program expressions. 2 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od Ligh tw eight Metrop olis-Hastings (LMH) samplers [15] propose a change to a single random v ariable at eac h iteration. The program is then rerun, reusing previous v alues and computation where p ossible, after whic h the new set of sam- ple v alues is accepted or rejected. While re-running the program eac h time ma y w aste some computation, the simplicit y of LMH makes developing probabilistic v arian ts of arbitrary languages relatively straigh tforward. Designing robust Adaptive MCMC metho ds for probabilistic programming is complicated because of diversit y of mo dels expressed b y probabilistic programs. The same adaption sc heme should perform w ell with differen t programs without man ual tuning. Here we presen t an adaptive v ariant of LMH, whic h dynamically adjusts the sc hedule for selecting v ariables for mo dification. First, we review the general structure of a probabilistic program. W e discuss con vergence crite- ria with resp ect to the program output and prop ose a sc heme for tracking the “influence” of eac h random v ariable on the output. W e then adapt the selection probabilit y for each v ariable, b orro wing techniques from the upp er confidence b ound (UCB) family of algorithms for multi-armed bandits [3]. W e sho w that the proposed adaptation sc heme preserves conv ergence to the target distribution under reasonable assumptions. Finally , we compare original and Adaptiv e LMH on several test problems to show how con vergence is improv ed b y adaptation. 2 Preliminaries 2.1 Probabilistic Program A probabilistic program is a stateful deterministic computation P with the fol- lo wing prop erties: – Initially , P exp ects no arguments. – On ev ery call, P returns either a distribution F , a distribution and a v alue ( G, y ), a v alue z , or ⊥ . – Up on returning F , P exp ects a v alue x drawn from F as the argumen t to the next call. – Up on returning ( G, y ) or z , P is in vok ed again without arguments. – Up on returning ⊥ , P terminates. A program is run b y calling P rep eatedly un til termination. Ev ery run of the program implicitly pro duces a sequence of pairs ( F i , x i ) of distributions and v alues of latent random v ariables. W e call this sequence a tr ac e and denote it b y x x x . A trace induces a sequence of pairs ( G j , y j ) of distributions and v alues of observe d random v ariables. W e call this sequence an image and denote it b y y y y . W e call a sequence of v alues z k an output of the program and denote it b y z z z . Program output is deterministic given the trace. The probability of a trace is prop ortional to the pro duct of the probability of all random choices x x x and the likelihoo d of all observ ations y y y p ( x x x ) ∝ | x x x | Y i =1 p F i ( x i ) | y y y | Y j =1 p G j ( y j ) . (1) Output-Sensitiv e Adaptive Metrop olis-Hastings for Probabilistic Programs 3 Algorithm 1 Adaptiv e comp onen t wise MH 1: Select initial p oin t x x x 1 . 2: Set initial selection probabilities α α α 1 . 3: for t = 1 . . . ∞ do 4: α α α t ← f t ( α α α t , x x x 0 , x x x 1 , . . . , x x x t ). 5: Cho ose k ∈ { 1 , . . . , N } with probability α t k . 6: Generate x x x 0 ∼ q k θ ( x x x | x x x t ). 7: ρ ← min π ( x x x 0 ) q k θ ( x x x t | x x x 0 ) π ( x x x t ) q k θ ( x x x 0 | x x x t ) , 1 8: x x x t +1 ← x x x 0 with probability ρ , x x x t otherwise. 9: end for The ob jectiv e of inference in probabilistic program P is to disco ver the distribu- tion of z z z . 2.2 Adaptiv e Mark ov Chain Mon te Carlo MCMC methods generate a sequence of samples { x x x t } ∞ t =1 b y sim ulating a Mark o v c hain using a transition op erator that leav es a target densit y π ( x x x ) inv ariant. In MH the transition op erator is implemen ted b y dra wing a new sample x x x 0 from a parameterized prop osal distribution q θ ( x x x 0 | x x x t ) that is conditioned on the curren t sample x x x t . The prop osed sample is then accepted with probability ρ = min π ( x x x 0 ) q θ ( x x x t | x x x 0 ) π ( x x x t ) q θ ( x x x 0 | x x x t ) , 1 . (2) If x x x 0 is rejected, x x x t is re-used as the next sample. The conv ergence rate of MH dep ends on parameters θ of the prop osal distri- bution q θ . The parameters can b e set either offline or online. V ariants of MCMC in which the parameters are con tinuously adjusted based on the features of the sample sequence are called adaptive. Challenges in design and analysis of Adap- tiv e MCMC methods include optimization criteria and algorithms for the pa- rameter adaptation, as well as conditions of conv ergence of Adaptive MCMC to the correct equilibrium distribution [13]. Contin uous adaptation of parameters of the prop osal distribution is a well-kno wn research sub ject [1,2,14]. In a comp onen twise MH algorithm [10] whic h targets a densit y π ( x x x ) de- fined on an N -dimensional space X , the components of a random sample x x x = { x 1 , . . . , x N } are updated individually , in either random or systematic order. Assuming the comp onen t i is selected at the step t for mo dification, the pro- p osal x x x 0 sampled from q i θ ( x x x | x x x t ) ma y differ from x x x t only in that comp onent, and x 0 j = x t j for all j 6 = i . Adaptiv e comp onent wise Metrop olis-Hastings (Algo- rithm 1) chooses different probabilities for selecting a comp onent for modification at each iteration. Parameters of this sc heduling distribution may b e view ed as a subset of parameters θ of the prop osal distribution q θ , and adjusted according to optimization criteria of the sampling algorithm. 4 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od V arying selection probabilities based on past samples violates the Marko v prop ert y of { x x x t } ∞ 1 . Ho wev er, provided the adaptation of the selection probabili- ties diminishes, with || α α α t − α α α t − 1 || → 0, then under suitable regularity conditions for the target density (see Section 4) an adaptive comp onent wise MH algorithm will still b e ergo dic [8], and the distribution on x x x induced by Algorithm 1 con- v erges to π . 2.3 Ligh tw eigh t Metropolis-Hastings LMH [15] is a sampling sc heme for probabilistic programs where a single random v ariable drawn in the course of a particular execution of a probabilistic program is mo dified via a standard MH prop osal, and this mo dification is accepted by comparing the v alues of the joint probabilit y of old and new program traces. LMH differs from comp onen t wise MH algorithms in that other random v ariables ma y also hav e to b e mo dified, dep ending on the structural dep endencies in the probabilistic program. LMH initializes a prop osal b y selecting a single v ariable x k from an execution trace x x x and resampling its v alue x 0 k either using a reversible kernel κ ( x 0 k | x k ) or from the conditional prior distribution. Starting from this initialization, the program is rerun to generate a new trace x x x 0 . F or each m > k , the previous v alue x m is reused, provided it still lies in the support of the distribution on x 0 m , rescoring its log probabilit y relative to the new random choices { x 0 1 , . . . , x 0 m − 1 } . When x 0 m cannot b e rescored, a new v alue is sampled from the prior on x 0 m , conditioned on preceding choices. The acceptance probability ρ LMH is obtained b y substituting (1) in to (2): ρ LMH = min 1 , p ( y y y 0 | x x x 0 ) p ( x x x 0 ) q ( x x x | x x x 0 ) p ( y y y | x x x ) p ( x x x ) q ( x x x 0 | x x x ) . (3) W e here further simplify LMH by assuming x 0 k is sampled from the prior condi- tioned on earlier choices and that all v ariables are selected for mo dification with equal probability . In this case, ρ LMH tak es the form [16] ρ LMH = min 1 , p ( y y y 0 | x x x 0 ) p ( x x x 0 ) | x x x | p ( x x x \ x x x 0 | x x x ∩ x x x 0 ) p ( y y y | x x x ) p ( x x x ) | x x x 0 | p ( x x x 0 \ x x x | x x x 0 ∩ x x x ) , (4) where x x x 0 \ x x x denotes the resampled v ariables, and x x x 0 ∩ x x x denotes the v ariables whic h ha ve the same v alues in both traces. 3 Adaptiv e Ligh t w eight Metrop olis-Hastings W e develop an adaptiv e v arian t of LMH, which dynamically adjusts the proba- bilities of selecting v ariables for mo dification (Algorithm 2). Let x x x t b e the trace at iteration t of Adaptive LMH. W e define the probability distribution of se- lecting v ariables for mo dification in terms of a weigh t v ector W W W t that w e adapt, Output-Sensitiv e Adaptive Metrop olis-Hastings for Probabilistic Programs 5 Algorithm 2 Adaptiv e LMH 1: Initialize W W W 0 to a constant. 2: Run the program. 3: for t = 1 . . . ∞ do 4: Randomly select a v ariable x t k according to W W W t . 5: Prop ose a v alue for x t k . 6: Run the program, accept or reject the trace. 7: if accepted then 8: Compute W W W t +1 based on the program output. 9: else 10: W W W t +1 ← W W W t 11: end if 12: end for suc h that the probabilit y α t i of selecting the i th v ariable for mo dification is α t i = W t i | x x x t | P k =1 W t k . (5) Just like LMH, Adaptive LMH runs the probabilistic program once and then selects v ariables for mo dification randomly . Ho wev er, acceptance ratio ρ AdLMH m ust now include selection probabilities α k and α 0 k of the resampled v ariable in the current and the prop osed sample ρ AdLMH = min 1 , p ( y y y 0 | x x x 0 ) p ( x x x 0 ) α 0 k p ( x x x \ x x x 0 | x x x ∩ x x x 0 ) p ( y y y | x x x ) p ( x x x ) α k p ( x x x 0 \ x x x | x x x 0 ∩ x x x ) . (6) This high-lev el description of the algorithm do es not detail ho w W W W t is com- puted for each iteration. Indeed, this is the most essential part of the algorithm. There are tw o different asp ects here — on one hand, the influence of a given c hoice on the output sequence m ust be quan tified in terms of con vergence of the sequence to the target distribution. On the other hand, the influence of the c hoice m ust b e translated in to re-computation of weigh ts of random v ariables in the trace. Both parts of re-computation of W W W t are explained b elo w. 3.1 Quan tifying Influence Extensiv e research literature is av ailable on criteria for tuning parameters of Adaptiv e MCMC [1,2,14]. The case of inference in probabilistic programs is differen t: the user of a probabilistic program is interested in fast conv ergence of the program output { z z z t } rather than of the v ector of the program’s random v ariables { x x x t } . In adaptive MCMC v ariants the acceptance rate can b e efficien tly used as the optimization ob jective [14]. Ho wev er, for con vergence of the output sequence an accepted trace that pro duces the same output is indistinguishable from a 6 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od rejected trace. Additionally , while optimal v alues of the acceptance rate [1,14] can b e used to tune parameters in adaptive MCMC, in Adaptiv e LMH w e do not c hange the parameters of prop osal distributions of individual v ariables, and assume that they are fixed. How ever, proposing a new v alue for a random v ariable ma y or may not c hange the output ev en if the new trace is accepted. By c hanging v ariable selection probabilities w e attempt to maximize the change in the output sequence so that it con verges faster. In the p edagogical example x 1 ∼ Bernoulli(0 . 5) , x 2 ∼ N ( x 1 , 1) , z 1 ← ( x 1 , x 2 ) , selecting the Bernoulli random choice for mo dification changes the output only when a differen t v alue is sampled, while selecting the normal random choice will c hange the output almost alwa ys. Based on these considerations, w e quantif y the influence of sampling on the output sequence by measuring the c hange in the output z z z of the probabilistic program. Since probabilistic programs ma y produce output of an y t ype, w e c hose to discern b et ween identical and differen t outputs only , rather than to quantify the distance by introducing a type-dep enden t norm. In addition, when | z z z | > 1, w e quantify the difference by the fraction of comp onen ts of z z z with changed v alues. F ormally , let { z z z t } ∞ 1 = { z z z 1 , . . . , z z z t − 1 , z z z t , . . . } b e the output sequence of a probabilistic program. Then the influenc e of a choice that pro duced z z z t is defined b y the total rew ard R t , computed as normalized Hamming distance b et ween the outputs R t = 1 | z z z t | | z z z t | X i = k 1 1 ( z t k 6 = z t − 1 k ) . (7) In the case of a scalar z z z , the rew ard is 1 when outputs of subsequent samples are different, 0 otherwise. The reward is used to adjust the v ariable selection probabilities for the sub- sequen t steps of Adaptive LMH b y computing W W W t +1 (line 8 of Algorithm 2). It ma y seem sufficient to assign the reward to the last choice and use a v erage c hoice rewards as their weigh ts, but this approac h will not w ork for Adaptiv e LMH. Consider the generative mo del x 1 ∼N (1 , 10) , x 2 ∼ N ( x 1 , 1) , y 1 ∼N ( x 2 , 1) , z 1 ← x 1 , where we observ e the v alue y 1 = 2. Mo difying x 2 ma y result in an accepted trace, but the v alue of z 1 = x 1 , predicted by the program, will remain the same as in the previous trace. Only when x 1 is also mo dified, and a new trace with the updated v alues for both x 1 and x 2 is accepted, the earlier change in x 2 is indirectly reflected in the output of the program. In the next section, we discuss propagation of rew ards to v ariable selection probabilities in detail. Output-Sensitiv e Adaptive Metrop olis-Hastings for Probabilistic Programs 7 3.2 Propagating Rew ards to V ariables Both LMH and Adaptiv e LMH mo dify a single v ariable p er trace, and either re-use or recompute the probabilities of v alues of all other v ariables (except those absent from the previous trace or ha ving an incompatible distribution, for whic h new v alues are also sampled). Due to this up dating sc heme, the influence of mo difying a v ariable on the output can b e delay ed by sev eral iterations. W e prop ose the following propagation sc heme: for eac h random v ariable x i , the re- w ard r i and count c i are kept in a data structure used to compute W W W . The set of v ariables selected for modification, called here the history , is main tained for eac h comp onen t z k of output z z z . When the v alue of z k c hanges, the rew ard is distributed betw een all of the v ariables in the history , and the history is emp- tied. When z k do es not c hange, the selected v ariable is p enalized b y zero rew ard. This scheme, for the case of scalar output for simplicity , is shown in Algorithm 3 whic h expands line 8 of Algorithm 2. When z z z has multiple components, histories for each comp onen t are maintained independently . Algorithm 3 Propagating Rewards to V ariables 1: App end x k to the history of v ariables selected for mo dification. 2: if z z z t +1 6 = z z z t then 3: w ← 1 | history | 4: for x m in history do 5: r m ← r m + w, c m ← c m + w 6: end for 7: Flush the history . 8: else 9: c k ← c k + 1 10: end if Rew arding all of the v ariables in the history ensures that while v ariables whic h cause changes in the output more often get a greater reward, v ariables with low er influence on the output are still selected for mo dification sufficiently often. This, in turn, ensures ergo dicity of sampling sequence, and helps establish conditions for conv ergence to the target distribution, as we discuss in Section 4. Let us show that under certain assumptions the prop osed reward propaga- tion sc heme has a non-degenerate equilibrium for v ariable selection probabilities. Indeed, assume that for a program with t wo v ariables, x 1 , and x 2 , pr ob ability matching , or selecting a choice with the probabilit y prop ortional to the unit rew ard ρ i = r i c i , is used to compute the weigh ts, that is, W i = ρ i . Then, the follo wing lemma holds: Lemma 1 Assume that for variables x i , wher e i ∈ { 1 , 2 } : – α i is the sele ction pr ob ability; – β i is the pr ob ability that the new tr ac e is ac c epte d given that the variable was sele cte d for mo dific ation; 8 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od – γ i is the pr ob ability that the output change d given that the tr ac e was ac c epte d. Assume further that α i , β i , and γ i ar e c onstant. Then for the c ase γ 1 = 1 , γ 2 = 0 : 0 < α 2 α 1 ≤ 1 3 (8) Pr o of. W e shall pro of the lemma in three steps. First, w e shall analyse a sequence of samples betw een tw o subsequen t arriv als of x 1 . Then, w e shall deriv e a form ula for the exp ected unit reward of x 2 . Finally , w e shall b ound the ratio α 2 α 1 . Consider a sequence of k samples, for some k , b et ween t wo subsequen t arriv als of x 1 , including the sample corresp onding to the second arriv al of x 1 . Since a new v alue of x 1 alw ays ( γ 1 = 1) and x 2 nev er ( γ 2 = 0) causes a change in the output, at the end of the sequence the history will contain k occurrences of x 2 . Let us denote b y ∆r i , ∆c i the increase of rew ard r i and coun t c i b et w een the b eginning and the end of the sequence. Noting that x 2 is p enalized eac h time it is added to the history (line 9 of Algorithm 3), and k o ccurrences of x 2 are rew arded when x 1 is added to the history (line 5 of Algorithm 3), w e obtain ∆r 1 = 1 k + 1 , ∆c 1 = 1 k + 1 ∆r 2 = k k + 1 , ∆c 2 = k + k k + 1 (9) Consider now a sequence of M such sequences. When M → ∞ , r iM c iM approac hes the exp ected unit reward ρ i , where r iM and c iM are the rew ard and the coun t of x i at the end of the sequence. ρ i = lim M →∞ r iM c iM = lim M →∞ r iM M c iM M = lim M →∞ P M m =1 ∆r im M P M m =1 ∆c im M = ∆r i ∆c i (10) Eac h v ariable x i is selected randomly and indep enden tly and pro duces an accepted trace with probability p i = α i β i α 1 β 1 + α 2 β 2 . (11) Acceptances of x 1 form a Poisson process with rate 1 p 1 = α 1 β 1 + α 2 β 2 α 1 β 1 . k is dis- tributed according to the geometric distribution with probabilit y p 1 , Pr[ k ] = (1 − p 1 ) k p 1 . Since ∆r 1 = ∆c 1 for any k , the expected unit reward ρ 1 of x 1 is 1. W e shall substitute ∆r i and ∆c i in to (10) to obtain the exp ected unit reward ρ 2 of x 2 : ∆r 2 = ∞ X k =0 k k + 1 (1 − p 1 ) k p 1 ∆c 2 = ∞ X k =0 k + k k + 1 (1 − p 1 ) k p 1 = 1 − p 1 p 1 | {z } k + ∞ X k =0 k k + 1 (1 − p 1 ) k p 1 (12) Output-Sensitiv e Adaptive Metrop olis-Hastings for Probabilistic Programs 9 ρ 2 = ∆r 2 ∆c 2 = ∞ P k =0 k k +1 (1 − p 1 ) k p 1 1 − p 1 p 1 + ∞ P k =0 k k +1 (1 − p 1 ) k p 1 = 1 − A z }| { ∞ X k =0 1 k + 1 (1 − p 1 ) k p 1 1 p 1 − ∞ X k =0 1 k + 1 (1 − p 1 ) k p 1 | {z } A (13) F or probability matching, selection probabilities are prop ortional to exp ected unit rewards: α 2 α 1 = ρ 2 ρ 1 (14) T o prov e the inequalit y , we shall deriv e a closed-form representation for ρ 2 , and analyse solutions of (14) for α 2 α 1 . W e shall eliminate the summation A in (13): A = ∞ X k =0 k k + 1 (1 − p 1 ) k p 1 = p 1 1 − p 1 ∞ X k =0 1 k + 1 (1 − p 1 ) k +1 = p 1 1 − p 1 ∞ X k =0 Z 1 p 1 (1 − ξ ) k dξ = p 1 1 − p 1 Z 1 p 1 ∞ X k =0 (1 − ξ ) k dξ = − p 1 1 − p 1 log p 1 (15) By substituting A into (13), and then ρ 1 and ρ 2 in to (14), we obtain α 2 α 1 = ρ 2 ρ 1 = ρ 2 = 1 + p 1 log p 1 1 − p 1 1 p 1 + p 1 log p 1 1 − p 1 ) B ( p 1 ) (16) The righ t-hand side B ( p 1 ) of (16) is a monotonic function for p 1 ∈ [0 , 1], and B (0) = 0, B (1) = 1 3 (see App endix for the analysis of B ( p 1 )). According to (11), α 2 α 1 = 0 implies p 1 = 1, hence α 2 α 1 6 = 0, and 0 < α 2 α 1 ≤ 1 3 . u t By noting that an y subset of v ariables in a probabilistic program can b e considered a single random v ariable drawn from a m ulti-dimensional distribution, Lemma 1 is generalized to any num ber of v ariables b y Corollary 1: Corollary 1 F or any p artitioning of the set x x x of r andom variables of a pr ob- abilistic pr o gr am, A dLMH with weights pr op ortional to exp e cte d unit r ewar ds sele cts variables fr om e ach of the p artitions with non-zer o pr ob ability. T o ensure conv ergence of W W W t to exp ected unit rewards in the stationary distribution, w e use upp er confidence b ounds on unit rew ards to compute the v ariable selection probabilities, an idea whic h w e b orro wed from the UCB family of algorithms for multi-armed bandits [3]. F ollowing UCB1 [3], w e compute the upp er confidence b ound ˆ ρ i as the sum of the unit rew ard and the exploration term ˆ ρ i = ρ i + C s log P | x x x | i =1 c i c i , (17) 10 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od where C is an exploration factor. The default v alue for C is √ 2 in UCB1; in practice, a lo wer v alue of C is preferable. Note that v ariable selection in Adaptiv e LMH is differen t from arm selection in multi-armed bandits: unlike in bandits, where we wan t to sample the b est arm at an increasing rate, in Adaptive LMH w e expect W W W t to conv erge to an equilibrium in which selection probabilities are prop ortional to exp ected unit rew ards. 4 Con v ergence of Adaptive LMH As adaptiv e MCMC algorithms ma y dep end arbitrarily on the history at eac h step, showing that a given sampler correctly dra ws from the target distribution can b e non-trivial. General conditions under which adaptiv e MCMC sc hemes are still ergo dic, in the sense that the distribution of samples con verges to the target π in total v ariation, are established in [13]. The fundamen tal criteria for v alidit y of an adaptiv e algorithm are diminishing adaptation , which (informally) requires that the amount whic h the transition op erator c hanges each iteration m ust asymptotically decrease to zero; and c ontainment , a technical condition whic h requires that the time un til con v ergence to the target distribution m ust b e b ounded in probability [4]. The class of mo dels representable b y probabilistic programs is very broad, allo wing sp ecification of completely arbitrary target densities; ho w ever, for man y mo dels the adaptiv e LMH algorithm reduces to an adaptiv e random scan Metro- p olis-within-Gibbs in Algorithm 1. T o discuss when this is the case, w e in v oke the concept of structur al v ersus structur e-pr eserving random c hoices [17]. Crucially , a structur e-pr eserving random c hoice x k do es not affect the existence of other x m in the trace. Supp ose w e w ere to restrict the expressiveness of our language to admit only programs with no structural random c hoices: in such a language, the LMH al- gorithm in Algorithm 2 reduces to the adaptive comp onen twise MH algorithm. Conditions under which such an adaptiv e algorithm is ergo dic hav e b een estab- lished explicitly in [8, Theorems 4.10 and 5.5]. Giv en suitable assumptions on the target density defined by the program, it is necessary for the probabilit y v ector || α t − α t − 1 || → 0, and that for any particular comp onent k we ha ve probability α t k > > 0. Both of these are satisfied by our approach: from Corollary 1, we ensure that the unit rew ard across each x i con verges to a p ositiv e fixed p oin t. While any theoretical result will require language restrictions such that pro- grams only induce distributions satisfying regularit y conditions, we conjecture that this sc heme is broadly applicable across most non-pathological programs. W e leav e a precise theoretical analysis of the space of probabilistic programs in whic h adaptive MCMC schemes (with infinite adaptation) may b e ergo dic to future w ork. Empirical ev aluation presented in the next section demonstrates practical conv ergence of Adaptive LMH on a range of inference examples, in- cluding programs con taining structural random c hoices. Output-Sensitiv e Adaptive Metrop olis-Hastings for Probabilistic Programs 11 5 Empirical Ev aluation W e ev aluated Adaptiv e LMH on many probabilistic programs and observ ed con- sisten t improv emen t of conv ergence rate compared to LMH. W e also verified on a num b er of tests that the algorithm conv erges to the correct distribution obtained by indep enden t exact methods. In this section, w e compare Adaptiv e LMH to LMH on several represen tative examples of probabilistic programs. The rates in the comparisons are presen ted with resp ect to the n umber of samples, or sim ulations, of the probabilistic programs. The additional computation required for adaptation takes negligible time, and the computational effort per sample is appro ximately the same for all algorithms. Our implementation of the inference engine is a v ailable at https://bitbucket.org/dtolpin/embang . In the following case studies differences b et ween program outputs and target distributions are presen ted using KullBack-Leibler (KL) div ergence, Kolmogorov- Smirno v (KS) distance, or L2 distance, as appropriate. In cases where target distributions cannot b e up dated exactly , they w ere approximated by running a non-adaptiv e inference algorithm for a long enough time and with a sufficient n umber of restarts. In each of the ev aluations, all of the algorithms w ere run with 25 random restarts and 500 000 simulations of the probabilistic program p er restart. The difference plots use the logarithmic scale for both axes. In the plots, the solid lines corresp ond to the median, and the dashed lines to 25% and 75% p ercen tiles, taken o ver all runs of the corresp onding inference algorithm. The exploration factor for computing upp er confidence b ounds on unit rewards (Equation 17) w as fixed at C = 0 . 5 for all tests and ev aluations. The first example is a laten t state inference problem in an HMM with three states, one-dimensional normal observ ations (0.9, 0.8, 0.7, 0, -0.025, 5, 2, 0.1, 0, 0.13, 0.45, 6, 0.2, 0.3, -1, -1) with v ariance 1.0, a known transition matrix, and kno wn initial state distribution. There are 18 distinct random choices in all traces of the program, and the 0th and the 17th state of the mo del are predicted. The results of ev aluation are shown in Figure 1 as KL divergences b etw een the inference output and the ground truth obtained using the forw ard-backw ard algorithm. In addition, bar plots of unit reward and sample coun t distributions among random choices in Adaptiv e LMH are sho wn for 1000, 10 000, and 100 000 samples. As can b e seen in the plots, Adaptive LMH (blac k) exhibits faster conv ergence o ver the whole range of ev aluation, requiring half as many samples as LMH (cy an) to achiev e the same approximation, with the median of LMH ab o ve the 75% quantile of Adaptive LMH. In addition, the bar plots show unit rewards and sample counts for different random choices, providing an insight on the adaptiv e b eha vior of AdLMH. On the left-hand bar plots, red bars are normalized unit rew ards, and blue bars are normalized sample counts. On the righ t-hand bar plots, the total heigh t of a bar is the total sample coun t, with green section corresp onding to the accepted, and y ellow to the rejected samples. A t 1 000 samples, the unit rewards hav e not yet con verged, and exploration supersedes exploitation: random choices with low er acceptance rate are selected more often (choices 7, 8 and 13 corresp onding to 12 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od 5e+04 1e+05 2e+05 5e+05 1e−04 5e−04 2e−03 samples KL divergence LMH AdLMH 1 3 5 7 9 11 13 15 17 0.00 0.06 0.12 rewards selected 1 3 5 7 9 11 13 15 17 0 40 80 accepted rejected 1000 samples 1 3 5 7 9 11 13 15 17 0.00 0.06 1 3 5 7 9 11 13 15 17 0 400 10000 samples 1 3 5 7 9 11 13 15 17 0.00 0.06 0.12 1 3 5 7 9 11 13 15 17 0 4000 8000 100000 samples Fig. 1. HMM, predicting the 0th and 17th state states 6, 7 and 12). A t 10 000 samples, the unit rew ards b ecome close to their final v alues, and choices 1 and 18, immediately affecting the predicted states, are selected more often. At 100 000 samples, the unit rewards con verge, and the sample coun ts corresp ond closely to the equilibrium state outlined in Lemma 1. The second case study is estimation of h yp erparameters of a Gaussian Pro- cess. W e define a Gaussian Pro cess of the form f ∼G P ( m, k ) , where m ( x ) = ax 2 + bx + c, k ( x, x ) = de ( x − x 0 ) 2 2 g . The pro cess has five hyperparameters, a, b, c, d, g . The program infers the p oste- rior v alues of the h yp erparameters by maximizing marginal likelihoo d of 6 ob- serv ations (0 . 0 , 0 . 5), (1 . 0 , 0 . 4), (2 . 0 , 0 . 2), (3 . 0 , − 0 . 05), (4 . 0 , − 0 . 2), and (5 . 0 , 0 . 1). P arameters a, b, c of the mean function are predicted. Maxim um of KS distances b et w een inferred distributions of eac h of the predicted parameters and an ap- pro ximation of the target distributions is sho wn in Figure 2. The approximation w as obtained b y running LMH with 2 000 000 samples p er restart and 50 restarts, and then taking eac h 100th sample from the last 10 000 samples of eac h restart, 5000 samples total. Just as for the previous case study , bar plots of unit rewards and sample coun ts are shown for 1000, 10 000, and 100 000 samples. Here as w ell, Adaptive LMH (black) con v erges faster ov er the whole range of ev aluation, outperforming LMH by a factor 2 o v er the first 50 000 samples. Bar plots of unit rewards and sample counts for different num ber of c hoices, again, show the dynamics of sample allocation among random choices. Choices a , b , and c are predicted, while c hoices d and g are required for inference but not predicted. Choice a has the low est acceptance rate (ratio b etw een the total heigh t of the bar and the green part on the righ t-hand bar plot), but the unit rew ard is close the unit reward of c hoices b and c . At 1 000 samples, c hoice a is Output-Sensitiv e Adaptive Metrop olis-Hastings for Probabilistic Programs 13 5e+03 2e+04 5e+04 2e+05 5e+05 0.1 0.2 0.5 1.0 samples KS distance LMH AdLMH a b c d g 0.00 0.15 0.30 rewards selected a b c d g 0 100 250 accepted rejected 1000 samples a b c d g 0.00 0.15 0.30 a b c d g 0 1000 2500 10000 samples a b c d g 0.00 0.15 a b c d g 0 10000 25000 100000 samples Fig. 2. Gaussian process hyperparameter estimation selected with the highest probabilit y . Ho w ever, close to the con v erged state, at 100 000 samples, choices a , b , and c are selected with similar probabilities. At the same time, c hoices 4 and 5 are selected with a lo wer probability . Both the exploration-exploitation dynamics for c hoices a – b and probability matc hing of selection probabilities among all c hoices secure improv ed conv ergence. The third case study in volv es a larger amount of data observed during each sim ulation of a probabilistic program. W e use the well-kno wn Iris dataset [9] to fit a mo del of classifying a given flow er as of the species Iris setosa, as opp osite to either Iris virginica or Iris v ersicolor. Eac h record in the dataset corresponds to an observ ation. F or each observ ation, we define a feature vector x and an indicator v ariable z i , which is 1 if and only if the observ ation is of an Iris setosa. W e fit the mo del with fiv e regression co efficien ts β 1 , . . . , β 5 , defined as σ 2 ∼ In vGamma(1 , 1) , β j ∼ Normal(0 , σ ) , p ( z i = 1) = 1 1 + e − β T x . T o assess the con v ergence, w e perform sh uffle split leav e-2-out cross v alidation on the dataset, selecting one instance b elonging to the sp ecies Iris setosa and one b elonging to a differen t sp ecies for eac h run of the inference algorithm. The classification error is shown in Figure 3 ov er 100 runs of LMH and Adaptive LMH. The results are consistent with other case studies: Adaptiv e LMH exhibits a faster con vergence rate, requiring half as many samples to ac hiev e the same classification accuracy as LMH. 14 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od 5e+03 1e+04 2e+04 5e+04 1e+05 2e+05 5e+05 0.03 0.04 0.05 0.07 samples Classification error LMH AdLMH Fig. 3. Logistic regression on Iris dataset. 0.05 0.10 0.15 0.20 0.25 0.00 0.10 0.20 0.30 LMH q ω 0.05 0.10 0.15 0.20 0.25 0.00 0.10 0.20 0.30 AdLMH q ω Fig. 4. Kalman filter, 500 samples after 10 000 samples of burn-in. As a final case study w e consider a linear dynamical system (i.e. a Kalman smo othing problem) that w as previously describ ed in [12] x t ∼ Norm( A · x t − 1 , Q ) , y t ∼ Norm( C · x t , R ) . In this problem w e assume that 16-dimensional observ ations y t are conditioned on 2-dimensional latent states z t . W e imp ose additional structure by assuming that the transition matrix A is a simple rotation with angular velocity ω , whereas the transition co v ariance Q is a diagonal matrix with co efficient q , A = cos ω − sin ω sin ω cos ω , Q = q 0 0 q . W e predict p osterior v alues for ω , and q in a setting where C and R are as- sumed known, under mildly informativ e priors ω ∼ Gamma(10 , 2 . 5) and q ∼ Gamma(10 , 100). Posterior inference is p erformed conditioned on a sim ulated Output-Sensitiv e Adaptive Metrop olis-Hastings for Probabilistic Programs 15 sequence y 1: T of T = 100 observ ations, with ω ∗ = 4 π /T , and q ∗ = 0 . 1. The observ ation matrix C and co v ariance R are sampled ro w-wise from symmetric Diric hlet distributions with parameters c = 0 . 1, and r = 0 . 01 resp ectiv ely . Figure 4 sho ws a qualitativ e ev aluation the mixing rate in the form of 500 consecutiv e samples ( ω , q ) from an LMH and AdLMH c hain after 10 000 samples of burn-in. The LMH sequence exhibits goo d mixing ov er ω but is strongly correlated in q , whereas the AdLMH sequence obtains a muc h better co verage of the space. T o summarize, Adaptiv e LMH consistently attained faster con vergence than LMH, measured by differences b etw een the ongoing output distribution of the random program and the target indep enden tly obtained distribution, assessed using v arious metrics. V ariable selection probabilities computed b y Adaptiv e LMH are dynamically adapted during the inference, com bining exploration of the model represented b y the probabilistic program and exploitation of influence of random v ariables on program output. 6 Con tribution and F uture W ork In this pap er we in tro duced a new algorithm, Adaptiv e LMH, for appro ximate inference in probabilistic programs. This algorithm adjusts sampling parame- ters based on the output of the probabilistic program in which the inference is p erformed. Con tributions of the pap er include – A scheme of rewarding random c hoice based on program output. – An approac h to propagation of c hoice rewards to MH proposal scheduling parameters. – An application of this approach to LMH, where the probabilities of selecting eac h v ariable for mo dification are adjusted. Adaptiv e LMH w as compared to LMH, its non-adaptive counterpart, and was found to consistently outperform LMH on several probabilistic programs, while still being almost as easy to implemen t. The time cost of additional computation due to adaptation was negligible. Although presented in the context of a particular sampling algorithm, the adaptation approach can be extended to other sampling metho ds. W e b eliev e that v arious sampling algorithms for probabilistic programming can b enefit from output-sensitiv e adaptation. Additional p oten tial for impro vemen t lies in ac- quisition of dependencies betw een predicted expressions and random v ariables. Exploring alternative approaches for guiding exploration-exploitation compro- mise, in particular, based on Ba y esian inference, is another promising researc h direction. Ov erall, output-sensitiv e appro ximate inference app ears to bring clear adv an- tages and should be further explored in the con text of probabilistic programming mo dels and algorithms. 16 Da vid T olpin, Jan Willem v an de Meent, Bro oks Paige, and F rank W o od 7 Ac kno wledgments This work is supp orted under DARP A PP AML through the U.S. AFRL under Co operative Agreemen t n umber F A8750-14-2-0004. References 1. Andrieu, C., Thoms, J.: A tutorial on adaptive MCMC. Statistics and Computing 18(4), 343–373 (2008) 2. A tchad ´ e, Y., F ort, G., Moulines, E., Priouret, P .: Adaptive Marko v c hain Monte Carlo: theory and metho ds. In: Barber, D., Cemgil, A.T., Chiappa, S. (eds.) Ba yesian Time Series Mo dels, pp. 32–51. Cam bridge Universit y Press (2011), cam- bridge Bo oks Online 3. Auer, P ., Cesa-Bianchi, N., Fischer, P .: Finite-time analysis of the Multiarmed Bandit problem. Machine Learning 47(2–3), 235–256 (2002) 4. Bai, Y., Roberts, G.O., Rosen thal, J.S.: On the con tainment condition for adaptiv e Mark ov chain Mon te Carlo algorithms. Adv ances and Applications in Statistics 21(1), 1–54 (2011) 5. Gamerman, D., Lop es, H.F.: Marko v Chain Monte Carlo: Stochastic Simulation for Bay esian Inference. Chapman and Hall/CRC (2006) 6. Go odman, N.D., Mansinghk a, V.K., Roy , D.M., Bonawitz, K., T enen baum, J.B.: Ch urch: a language for generative models. In: Pro c. of Uncertaint y in Artificial In telligence (2008) 7. Gordon, A.D., Henzinger, T.A., Nori, A.V., Ra jamani, S.K.: Probabilistic program- ming. In: International Conference on Softw are Engineering (ICSE, F OSE track) (2014) 8. Latuszy ´ nski, K., Rob erts, G.O., Rosenthal, J.S.: Adaptiv e Gibbs samplers and related MCMC metho ds. Annals of Applied Probabilit y 23(1), 66–98 (2013) 9. Lauritzen, S.: Graphical Mo dels. Clarendon Press (1996) 10. Levine, R.A., Y u, Z., Hanley , W.G., Nitao, J.J.: Implementing component wise hast- ings algorithms. Computational Stastistics & Data Analysis 48(2), 363–389 (2005) 11. Mansinghk a, V.K., Selsam, D., Pero v, Y.N.: V enture: a higher-order probabilistic programming platform with programmable inference. CoRR abs/1404.0099 (2014) 12. v an de Meen t, J.W., Y ang, H., Mansinghk a, V., W o o d, F.: P article Gibbs with An- cestor Sampling for Probabilistic Programs. In: Artificial In telligence and Statistics (2015), 13. Rob erts, G.O., Rosen thal, J.S.: Coupling and ergo dicit y of adaptiv e MCMC. Jour- nal of Applied Probability 44, 458–475 (2007) 14. Rob erts, G.O., Rosen thal, J.S.: Examples of adaptiv e MCMC. Journal of Compu- tational and Graphical Statistics 18(2), 349–367 (2009) 15. Wingate, D., Stuhlm ¨ uller, A., Go odman, N.D.: Light weigh t implemen tations of probabilistic programming languages via transformational compilation. In: Pro c. of the 14th Artificial Intellig ence and Statistics (2011) 16. W o od, F., v an de Meent, J.W., Mansinghk a, V.: A new approac h to probabilistic programming inference. In: Artificial In telligence and Statistics (2014) 17. Y ang, L., Hanrahan, P ., Go odman, N.D.: Generating efficient MCMC kernels from probabilistic programs. In: Pro ceedings of the Seven teenth International Confer- ence on Artificial Intelligence and Statistics. pp. 1068–1076 (2014)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment