Autonomy and Reliability of Continuous Active Learning for Technology-Assisted Review
We enhance the autonomy of the continuous active learning method shown by Cormack and Grossman (SIGIR 2014) to be effective for technology-assisted review, in which documents from a collection are retrieved and reviewed, using relevance feedback, until substantially all of the relevant documents have been reviewed. Autonomy is enhanced through the elimination of topic-specific and dataset-specific tuning parameters, so that the sole input required by the user is, at the outset, a short query, topic description, or single relevant document; and, throughout the review, ongoing relevance assessments of the retrieved documents. We show that our enhancements consistently yield superior results to Cormack and Grossman’s version of continuous active learning, and other methods, not only on average, but on the vast majority of topics from four separate sets of tasks: the legal datasets examined by Cormack and Grossman, the Reuters RCV1-v2 subject categories, the TREC 6 AdHoc task, and the construction of the TREC 2002 filtering test collection.
💡 Research Summary
This paper presents a significant advancement in Technology-Assisted Review (TAR) by introducing a fully autonomous version of the Continuous Active Learning (CAL) method, dubbed “AutoTAR.” The core innovation lies in eliminating all topic-specific and dataset-specific tuning parameters that were required in prior approaches, including the authors’ own earlier CAL system. The user’s role is simplified to providing only an initial seed (a short query, topic description, or a single relevant document) and then giving ongoing relevance judgments for documents presented by the system. This shift maximizes autonomy, making the tool accessible to domain experts without information retrieval expertise.
The authors contextualize their work within the high-recall retrieval landscape, reviewing historical efforts like Boolean search in eDiscovery, the TREC pooling method, Interactive Search and Judging (ISJ), and relevance feedback techniques. They position their prior CAL method as a strong baseline for autonomous TAR but identify limitations regarding seed query sensitivity, performance across varying data richness, and generalizability.
The AutoTAR system is designed based on hypotheses to address these limitations. It automates all critical engineering choices within the CAL framework—such as classifier training, document scoring, and batch selection—using fixed, data-driven rules that require no manual intervention. The primary goal is not only to improve average performance but, crucially, to minimize the probability of failure on any given specific task, a vital requirement for real-world applications like legal discovery or systematic reviews where an average success rate is insufficient.
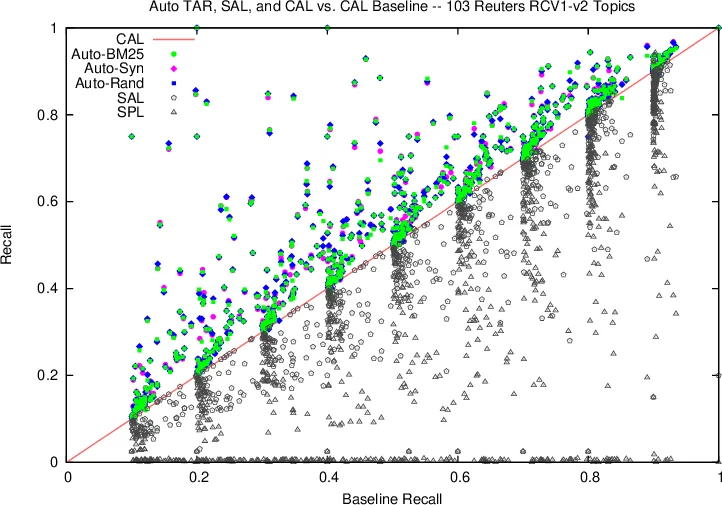
A comprehensive empirical evaluation demonstrates AutoTAR’s effectiveness and reliability across four diverse benchmark sets: 1) real legal case datasets from prior work, 2) the 103 topic categories of the Reuters RCV1-v2 corpus, 3) the 50 topics of the TREC 6 AdHoc task, and 4) the data from the construction of the TREC 2002 Filtering test collection. AutoTAR is compared against strong baselines, including the original CAL implementation, state-of-the-art text categorization (SVM), and the best manual search efforts reported at TREC.
The results consistently show that AutoTAR achieves superior or comparable performance to these baselines across the vast majority of individual topics at various recall levels (from 0.1 to 0.9). It proves robust across different domains and dataset characteristics, effectively handling topics with both high and low prevalence of relevant documents. The study provides strong evidence that fully autonomous, reliable, and high-performing TAR is achievable, moving the field closer to a “push-button” solution for high-recall information retrieval tasks. The paper concludes by discussing the implications of these findings and suggesting directions for future research.
Comments & Academic Discussion
Loading comments...
Leave a Comment